
Expectation maximization—vector approximate message passing based generalized linear model for channel estimation in intelligent reflecting surface-assisted millimeter multi-user multiple-input multiple-output systems
- Published
- Accepted
- Received
- Academic Editor
- A. Taufiq Asyhari
- Subject Areas
- Algorithms and Analysis of Algorithms, Computer Networks and Communications, Emerging Technologies
- Keywords
- Millimeter wave communication, Approximate message passing, Intelligent reflecting surface, Shrinkage function
- Copyright
- © 2025 K et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Expectation maximization—vector approximate message passing based generalized linear model for channel estimation in intelligent reflecting surface-assisted millimeter multi-user multiple-input multiple-output systems. PeerJ Computer Science 11:e2582 https://doi.org/10.7717/peerj-cs.2582
Abstract
Channel estimation poses a main challenge in intelligent reflecting surface (IRS)-assisted millimeter wave (mmWave) multi-user multiple-input multiple-output (MIMO) systems due to the substantial number of antennas at the base station (BS) and the passive reflective elements within the IRS lacking sufficient signal processing capabilities. This article addresses this challenge by proposing a channel estimation technique for IRS-assisted mmWave MIMO systems. The problem of channel estimation is normally taken as a compressed sensing (CS) problem, typically addressed through algorithms such as Orthogonal Matching Pursuit (OMP), Generalized Approximate Message Passing (GAMP), and Vector Approximate Message Passing with Expectation-Maximization (EM-VAMP). EM-VAMP demonstrates better performance only when a Gaussian mixture (GM) distribution is chosen as the prior for the sparse channel, especially at high signal-to-noise ratios (SNRs). To address this, the article introduces the application of generalized linear models (GLMs), extensions of standard linear models, providing increased flexibility in modeling data that deviates from Gaussian distribution. Numerical results unveil that the proposed Its EM-VAMP-GLM is much more robust to the existing OMP, GAMP and EM-LAMP algorithms.
Introduction
During the past few years, there have been technological advancements and widespread availability of smart devices at affordable cost. These advancements cause gradual enhancements in the number of users connected to the internet. This trend experienced a significant boost in the aftermath of the pandemic, and it has caused congestion in the internet traffic, especially operating at the lower frequency bands (Han et al., 2015; Raghavan et al., 2016). To overcome such demands in the current scenario and to satisfy the needs of the future, researchers across the globe are exploring the potential of millimeter-wave (mmWave) frequency bands (Gao et al., 2017). However, the mmWave frequency band suffers substantial path loss. Large antenna arrays combined with mmWave technology, or massive multi-input, multi-output (MIMO) systems, are introduced to surmount this issue and ensure a higher data rate (He et al., 2018). Using a large antenna array comes with hardware complexity overhead in the form of dedicated radio frequency (RF) chain requirements and increased power consumption. Numerous studies have demonstrated that these effects can be mitigated using different beamforming techniques and an advanced lens antenna array system (Yang et al., 2018).
Intelligent reflecting surface (IRS) has been explored by many researchers because of its abilities to enhance the effectiveness of wireless communication systems. In fact, the effectiveness of wireless communication systems can further be enhanced, if we opt for the integration of IRS and the existing technologies for tackling various issues, such as channel estimation. In Pan et al. (2022), the authors work on the modelling of channel under different conditions by addressing several research issues.
The both passive IRS-aided systems and active IRS-aided systems is discussed below.
Passive IRS
A passive and low-cost reflecting element is capable for accommodating future communication systems. Reconfigurable intelligent surface (RIS)/IRS assists in handling the problem of channel estimation. In IRS, we fabricate cost effective reflective elements that are capable of reflecting signals in the desired directions. Also, IRS have low power requirements because of not requiring a dedicated hardware components like traditional RF chains, which leads to the cost reduction as well. In terms of installment, IRS can easily be installed on buildings, street lamps and ceilings (Wu & Zhang, 2020; Pan et al., 2021). However, the main issue is that it can only work to reflect the incoming signals in the desired directions without amplifying the strength of signals, which is the fundamental difference between the active and passive IRS (Yuan et al., 2021).
Active IRS
Compared to passive IRS, it is able to amplify the signals due to being able to have hardware components like amplifiers or phase shifters (Zhang et al., 2023). Because of having additional hardware components, it consumes more power compared to passive IRS systems. In Zhi et al. (2022), the researchers have discussed the active and passive IRS- aided IRS systems in a detailed way.
In massive MIMO systems, passive IRS has emerged as a relatively new approach for future-generation networks, as it may offer higher capacity, coverage, and energy efficiency (Wu et al., 2021). The IRS contains a large number of antennas which can be independently adjusted based on the data and algorithms. The main components of IRS are low-cost passive reflective elements consisting of a reflector that reflects the incoming signal with reconfigurable levels of angles and peaks (Huang, Mo & Yuen, 2020). This functionality addresses the challenges related to signal blockage, coverage issues, low signal quality and interference. Thus, joining IRS with the mmWave band is a promising method for upcoming transmission/reception systems like multi-user MIMO systems. channel state information (CSI) is crucial for optimal beamforming to realize IRS-aided massive MIMO systems. As there may be an incompatibility in the processing and sensing of pilot signals, the accumulation of CSI is extremely challenging. Each IRS consists of hundreds of larger elements, and these cascaded channels require higher pilot overhead to estimate channels. Hence, In the proposed work, passive RIS-aided mmWave MIMO system is discussed to use low power and reduce the hardware complexity of the systems.
The existing methods and techniques for IRS-aided multi-user MIMO systems need further exploration for enhanced channel estimation accuracy with minimal pilot overhead (Jensen & Carvalho, 2020). In Huang et al. (2019), the authors discuss an optimal IRS pattern with antenna gain, demonstrating improved accuracy in contrast to the on-or-off approach discussed in Mishra & Johansson (2019). However, the proposed system witnesses higher pilot overhead, which limits the performance of the IRS (Wang et al., 2020).
The author proposed RIS-aided massive MIMO systems that work under the scheme of two-timescale transmission. A system model with impact of electromagnetic interference (EMI) and without impact of EMI for spatially independent Rician fading channels is considered and discussed. A closed-form expression is derived for a lower bound to get an achievable rate. In Zhi et al. (2023), the researchers work on the estimation of channel during the uplink transmission by applying the Linear MMSE (LMMSE) estimator. Finally, the researchers propose a low complex MRC detector.
In Zhi et al. (2022), the researchers work on performance of RIS assisted massive MIMO by using ZF detector under the scenario of imperfect channel estimations. They utilize MMSE for the estimation of channel by reducing the overhead with the aim of calculating the channel. They consider the uplink transmission scenario and work on the optimization of sum rate and minimum user rate with the help of the Majorization-Minimization (MM)- based algorithm.
In Ardah et al. (2021), Fazal-E-Asim et al. (2023), the researchers work on proposing a non-iterative RIS assisted based estimation of channel. The proposed framework is based on two stages. They compute the directions of arrival and departures in the initial step. Following the first step, they compute the parameters, such as elevation and azimuth angles, path gains, etc., in the next step. The final results unveil better performances of the proposed framework than existing methodologies.
In Fazal-E-Asim et al. (2021), the researchers work on estimating a frequency selective mmWave channel by proposing a method with the help of butler matrices in analog domain. The final results unveil that the proposed framework exhibit better performances than existing work in terms of delays, gains, and SNR.
In Dai & Wei (2022), passive IRS elements are discussed for the downlink system model. Actually, it is difficult to compute the uplink and downlink channels simultaneously. Therefore, normally, researchers compute the uplink channel first, and then move towards estimating the channel during the downlink transmission. However, some researchers have worked on the estimating of channel during both transmissions in a cascaded way by using algorithms like LS (Mishra & Johansson, 2019), and MMSE (Nadeem et al., 2020). They find out that the pilot overhead gets significantly enhanced during the cascaded channel estimation because of the multiplication of number of RIS elements and antennas at BS.
In some of the works carried out in this direction, a compressive sensing (CS) scheme is used to reduce the pilot overhead by exploiting the spatial characteristics of channels, which uses classical compressive algorithms like Orthogonal Matching Pursuit (OMP) (Liu et al., 2020). However, the channel estimation accuracy falls short in the OMP scheme due to the cascaded and sparse nature of the channels (Tropp & Gilbert, 2007). Pilot overhead may be reduced using Double Structured Orthogonal Matching Pursuit (DS-OMP), which depends on cascading the computation of channels (Dai & Wei, 2022). In DS-OMP, different users are assigned completely non-zero rows and partially non-zero columns, and joint estimation is performed using the traditional OMP (Wei, Shen & Dai, 2021a, 2021b) for channel estimation. In OMP and DS-OMP schemes, higher signal dimension increases the computational complexity and the pilot overhead. This approach, in turn, results in higher channel estimation errors. An iterative CS algorithm, Approximate Message Passing (AMP), is presented in Lecun, Bengio & Hinton (2015), Borgerding, Schniter & Rangan (2017) to overcome the challenges mentioned above. The AMP algorithm effectively reduces the computational complexity as the signal dimension increases, but the channel estimation accuracy may still be improved.
The AMP algorithm offers enhanced performance with low computational complexity by eliminating matrix inversion (Lecun, Bengio & Hinton, 2015). However, the performance depends on using an independent and identically distributed (IID) sub-Gaussian measurement matrix. Even minor deviations in the IID Gaussian measurement matrix can lead to algorithm divergence. In AMP, the severe restriction of the measurement matrices and fixed shrinkage parameters limits the application for solving the CS problem (Borgerding, Schniter & Rangan, 2017; Ali et al., 2023). When applied to channel estimation in mmWave Multi-User MIMO systems, the usage of fixed shrinkage parameters in the AMP technique indirectly degrades the performance of the proposed system. This challenge may be resolved using the learned AMP (LAMP) network proposed recently (Borgerding & Schniter, 2016; Wei, Hu & Dai, 2021). LAMP is a modified version of AMP that uses a deep neural network (DNN) to optimize linear and nonlinear shrinkage parameters. In LAMP, each layer within the iteration has different shrinkage parameters. However, the LAMP network also suffers under the IID sub-Gaussian matrix, which reduces the estimation accuracy. Thus, it is worth noting that using a soft threshold shrinkage function in the LAMP network does not necessarily ensure satisfactory channel estimation accuracy.
In Wei et al. (2019), the researchers discuss an AMP-based network with deep residual learning (LampResNet) for the beam space channel estimation. This work comprises the following major parts: LAMP network and deep residual learning network (ResNet). The preliminary channel computation related matrices are obtained from the first component, and ResNet is employed to reduce the noise by coarse refining. The authors point out two challenging problems that must be addressed in the LAMP network: fixed shrinkage parameter for each layer and the large memory overhead. Thus, a new approach called the hyper network-assisted recurrent LAMP (HNR-LAMP) network is introduced to resolve these challenges. However, in the scenarios involving non-IID Gaussian matrices, understanding and interpreting the parameters learned by the LAMP algorithm is challenging (Wei et al., 2019). As a result, the LAMP algorithm does not provide satisfactory channel estimation accuracy in IRS-assisted millimeter multi-user multiple-input multiple-output systems. Improved versions of the AMP algorithm known as VAMP and bilinear adaptive VAMP (Rangan, Schniter & Fletcher, 2019) have been introduced to address the limitations of LAMP in channel estimation problems. These algorithms exhibit better performance and faster convergence than conventional AMP while maintaining efficiency for a broader class of large random matrices.
The literature review suggests that the AMP-based channel estimation yields favorable outcomes in estimation accuracy in IRS-aided mmWave multi-user MIMO systems, influencing our choice to adopt AMP as a base for the proposed algorithm (Ruan et al., 2022). Likewise, VAMP extends the capabilities of AMP from IID Gaussian matrices to a larger class of rotationally invariant matrices. In the proposed algorithm, The VAMP algorithm with expectation-maximization (EM-VAMP) (Schniter, Rangan & Fletcher, 2016) is considered to avoid specifying detailed prior on channel distribution and noise variance. The investigation results show that the proposed algorithm provides better performance compared to the existing frameworks. Generalized linear models (GLMs) are extensions of the standard linear models that offer increased flexibility in modeling data that does not necessarily follow a Gaussian distribution or exhibit constant variance (Wu & Zhang, 2018).
This article demonstrates how EM-VAMP can be extended with GLM as EM-VAMP-GLM, a novel and robust algorithm against ill-conditioning in the measurement matrix compared to OMP, GAMP, and EM-LAMP. We consider IRS assisted Uplink mmWave multi-user MIMO systems in the article. Firstly, we formulated the signal received at the BS from the end users. As far as channel modelling is concerned, we use Saleh-Valenzuela channel model for modelling the channel between BS to IRS and IRS to end users. Following which we proposed the EM-VAMP-GLM scheme. The final results show that the proposed scheme exhibits low normalized mean square error (NMSE) compared to the existing approaches, such as OMP, GAMP, and EM-LAMP.
System model
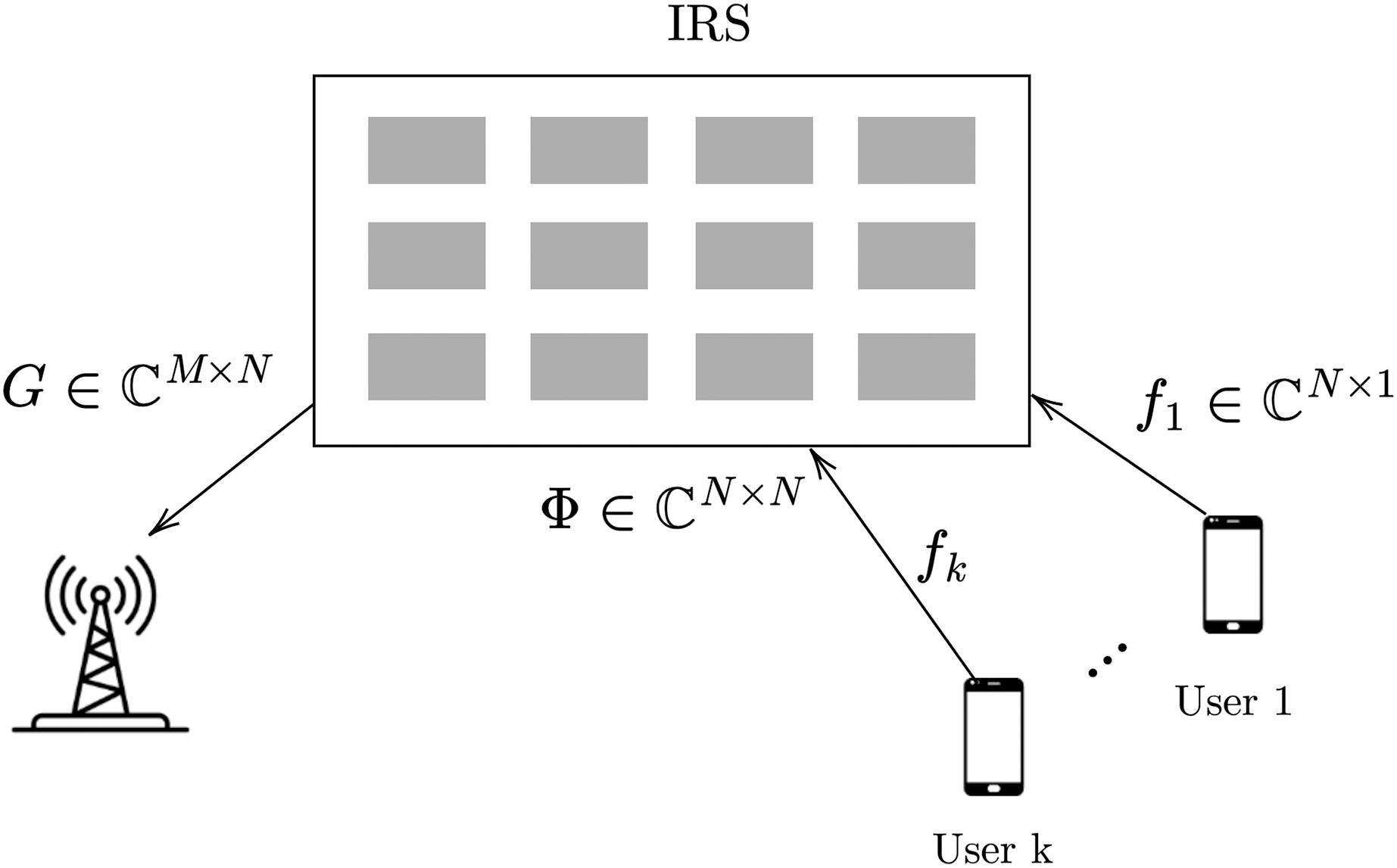
In this article, we consider the uplink scenario for mmWave multi-user MIMO assisted with IRS, as shown in Fig. 1. The number of users, is represented by K. We consider uniform planner array (UPA) with M antennas. IRS is equipped with N reflecting elements, where control of these elements is given to BS (Mishra & Johansson, 2019).
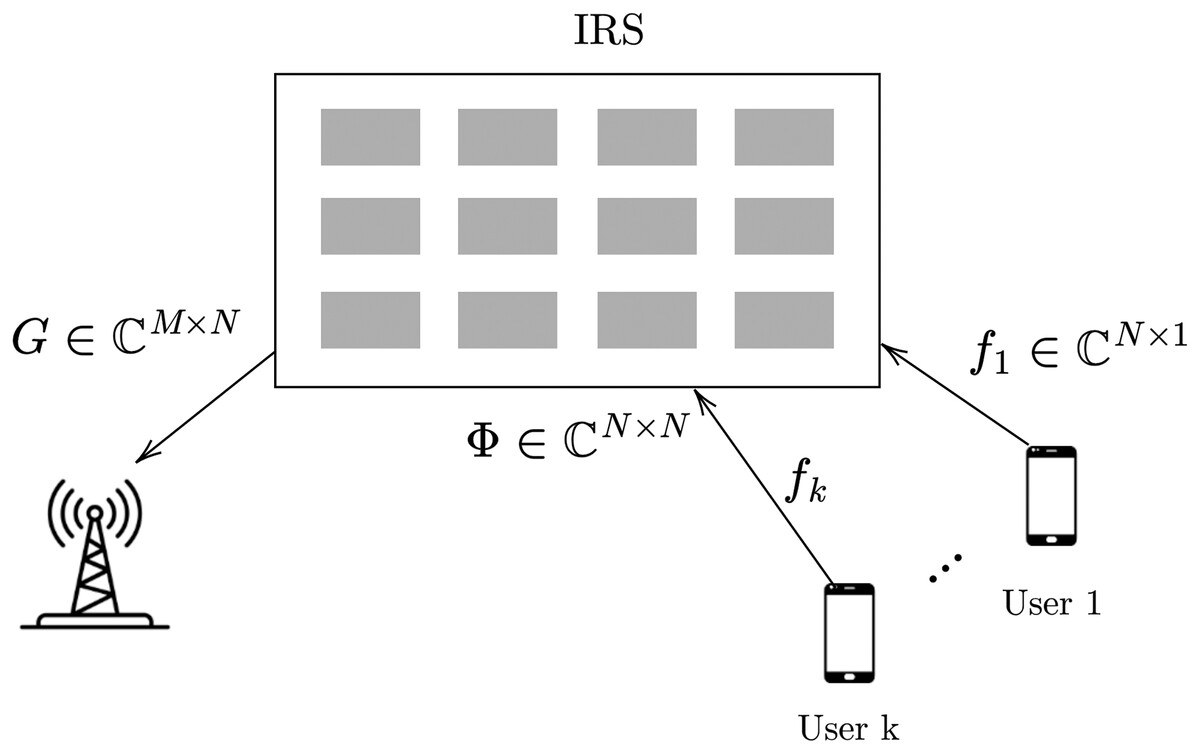
Figure 1: The IRS assisted multi user system (Dai & Wei, 2022).
{kind=link}
In frequency division duplex (FDD), the reciprocity of channels between the uplink and downlink channels does not hold. In this article, we consider FDD scheme, and the channel between users and BS is computed in a traditional way by switching IRS elements off. The main focus is on getting the CSI of reflecting link.
is the channel between IRS and BS, and is the channel from the user ( ) to IRS.
In the uplink transmission signal model, users communicate with the BS. At BS, the received pilot signal can be written as:
(1)
denotes the received signal at the BS, is a precoding vector, is the transmitted signal from the user, and represents the additive noise. represents the reflecting matrix. Assume representing the diagonal reflecting matrix, and is the IRS element.
We set , where and . The Saleh-Valenzuela channel model is utilized for the computation of and . can be written as:
(2)
represents the total paths between IRS and BS. Similarly, we can write as:
(3)
represents the total paths between uses and IRS. represents the gain, represents the azimuth angle, and represents the elevation angle. and are the normalized array steering vector linked with BS and the IRS. For a typical UPA, is expressed as:
(4)
and , λ and d represent the wavelength and spacing between antennas. In this article, we set .
By setting , Eq. (1) can be written as:
(5)
(6)
As mentioned earlier, in this article, we focus mainly on the estimation of cascaded channel by assuming the channel between end users and BS is already known. Where is the uplink cascaded channel for the user.
The IRS has limitations in terms of signal processing; therefore, the cascaded channel computation is discussed in Nadeem et al. (2020), Zymnis, Boyd & Candès (2010). If we do channel estimation separately of and , the computational complexity high. For reducing the computational complexity, we cascade the channel vector and estimated using proposed method. is the same for all end users because of having the common IRS between BS and users.
By decomposing with the help of virtual angular domain, we can write:
(7) where represent the cascaded channel having dimension. The dictionary unitary matrices are expressed as with dimension and with dimension (Mishra & Johansson, 2019).
Dictionary unitary matrix is a complex square matrix, which satisfy the condition and .
The expression for and is given by
In wireless communication systems, particularly those involving IRS and BS, it is crucial for estimation the challenge of channel between them. By dynamically fixing phase shifts, IRS can enhance the efficiency.
In multi-user systems, the channel BS and the IRS remains constant for all users since it depends only on the determined positions.
Since different users communicate with the BS via the common RIS, the channel G from the IRS to the BS is common for all users.
Another solution to reduce the pilot overhead is to directly estimate the corresponding cascaded channels by utilizing the multi-user correlation. Since all users communicate with the BS via the same IRS, the cascaded channels associated with different users have some correlations. Thus, this multi-user correlation can be exploited to reduce the pilot overhead required by the cascaded channel estimation.
It is noted that the reflecting vector at the IRS are the same for all users.
Where represent the cascaded channel having dimension and is estimated for all common users.
Apply compressive sensing techniques in cascade channel matrix to exploit the sparsity of the IRS-BS channels, reducing the required pilot signals for the estimation of channel.
Exploiting the common IRS-BS channel in a multi-user IRS-assisted communication system is a strategic approach to reducing channel estimation overhead.
Problem formulation
The uplink cascaded channel is calculated with the help of known pilot signals that are sent from users to the BS via IRS over time slots. According to Eq. (5), at the time slot, the received pilot signal at the BS can be expressed as:
(8) where represents the pilot signals originated from the end users, and denotes the reflecting vector of the time slot at the IRS, and is the received noise on time slot at the BS that undergoes the complex Gaussian distribution that has a special characteristics of zero mean and the variance as .
Following the transmission of pilots at time slots, the dimensional expectedoverall received pilot vector by assuming can be expressed as:
(9) where and .
As , Eq. (9) is required to be expressed as:
(10)
The is required to be expressed as , and the Eq. (10) is needed to be re-expressed as:
(11)
By denoting and , the received signal is expressed as:
(12) where , , and .
The cascading of and can be re-written as and respectively.
Moreover, the pilot vector at the receiving side is required to be re-expressed as:
(13)
To estimate the channel vector, and is designed as fixed value.Where denotes the reflecting matrix at the IRS.
Thus, similar to the pilot signals or measurement matrix, the is known for both the user and BS during the channel estimation. The has to estimate based on and for the downlink cascaded channel estimation.
Different types of non IID gaussian measurement matrix
For solving problems related to CS, we opt for various kinds of matrixes. In these matrixes, the correlation between columns is high. As a result, they do not exhibit satisfactory performance due to the issues linking with the constructing . For exploring algorithms in terms of robustness, we have the following several kinds of matrixes:
1) Low rank product matrix: With the aim of constructing it, we utilize by setting the ratio for analyzing in terms of robustness.
2) Ill conditioned matrix: With the aim of constructing it, we utilize singular matrix decomposition ( ).
3) Non-zero mean matrix: All entries in follows an IID N(µ,1/M). For measuring the deviation, we utilize mean function.
The approaches like AMP are normally utilized for solving problems related to channel estimation. However, the issue is the minor variations from iid gaussian model leads to the diverge problems (Rangan, Schniter & Fletcher, 2019). Therefore, to tackle this problem, we need various kinds of in terms of evaluating robustness.
Proposed channel estimation algorithm
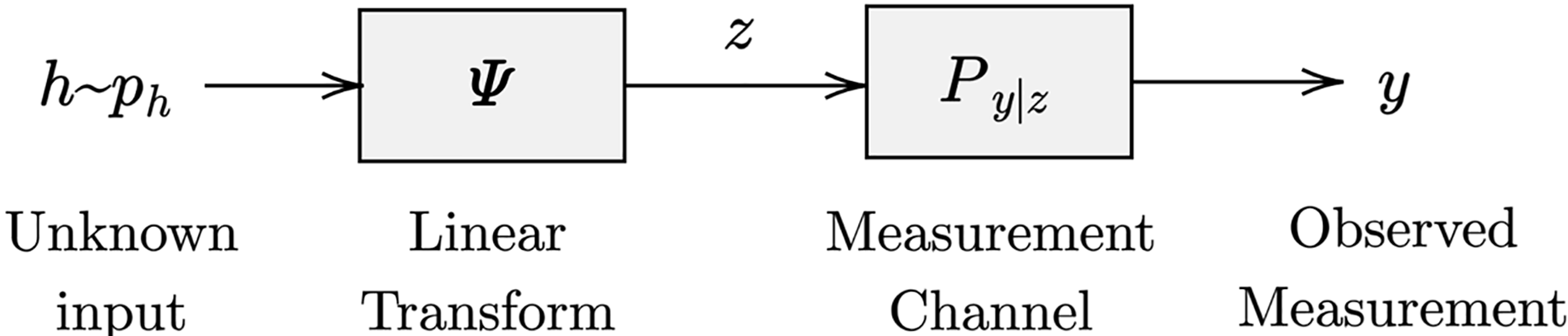
By getting inspiration from the previously outlined channel estimation framework, we can interpret the channel estimation challenge as a variant of noisy quantized compressed sensing. Various strategies have emerged to address this complexity, such as convex relaxation and GAMP (Kamilov, Goyal & Rangan, 2012). However, these approaches heavily rely on the assumed sparsity rate for the channel, which is typically explicitly specified or indirectly inferred through regularization terms or prior distributions. The integration of the generalized linear model (GLM) is illustrated in Fig. 2.
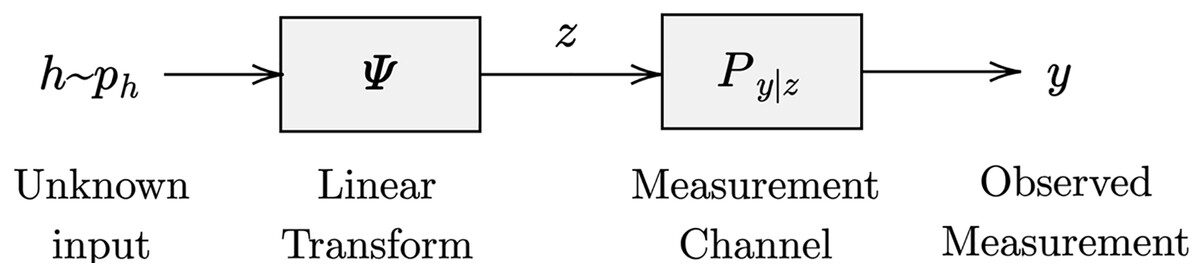
Figure 2: Generalized linear model (GLM) (Schniter, Rangan & Fletcher, 2016).
{kind=link}
Proposed em-vamp-glm algorithm
Within this section, an extension of EM-VAMP to the GLM framework is presented and mathematically derived for the analysis of the proposed methodology’s performance. In this context, the unidentified random channel vector is represented as , observed from its noisy measurements vector denoted as , utilizing a known measurement matrix denoted as . The expressed output measurements vector is formulated as:
(14)
We can recover the channel vector by utilizing VAMP-GLM based technique with the help of the received measurement vector at the output side.
Here, undergoes a prior density and is an additive white Gaussian noise (AWGN) independent of with noise variance . undergoes a prior density and noise variance .
The iterative AMP technique offers a less iterative solution for the aforementioned challenge, particularly when represents a . However, even slight deviations from the IID sub-Gaussian model can make the AMP algorithm sensitive, leading to divergence. Contrary to AMP-based techniques like GAMP, VAMP’s broader applicability in state evolution includes a wider array of matrices , specifically those that possesses (RRI). can be written as by following SVD, where the elements of should be uniformly drawn. This essential distinction leads the VAMP approach to overcome AMP’s main limitation as well as allows stability, even when dealing with ill-conditioned matrices . Hence, VAMP is considered in this article.
For exhibiting its applicability to GLM with respect to small changes, we utilized the following relationship:
(15)
(16)
Here, the two sub-vectors and is the output of at iteration , and the two sub-vectors and is the input to .
denotes the pseudo-measurement model and denotes the pseudo-prior model is used to estimate the h. Likewise, ) denotes the pseudo-measurements and denotes the pseudo-prior is used to estimate the .
As we lack information about the parameters and for obtaining precise values of and . Similarly, we lack knowledge of parameters for acquiring accurate values of and .
is considered as the posterior probability under the prior and message , i.e., . Hence, we can write where and .
In this context, we determine and through the utilization of the denoising function . These values are written as follows:
(17)
(18)
Here, represents the mean coefficient value, specifically . In a general context, the denoising function is employed to remove noise from the pseudo-measurement corrupted by AWGN, with prior knowledge of .
is considered as the posterior probability under the prior and message , i.e., . Hence, we can write where and . Here we have and with the help of noise reducing function :
(19)
(20)
Here . Lines 16–26 of Algorithm 1 implement LMMSE estimation of and the pseudo-prior
(21)
Due to the gaussian nature of prior and likelihood and prior, the estimation of MAP and LMMSE is equivalent:
(22)
(23)
(24)
(25)
(26)
(27)
(28)
(29)
(30)
(31)
Choice of prior distribution
To effectively utilize the EM-VAMP in tackling the estimation challenge assisted by IRS, we choose to embrace an approximating prior family. This family presents two viable choices: a BG distribution or GM distribution, each involving unspecified parameters . This implies of is taken out with the help of the subsequent equations:
(32)
(33)
(34)
(35) where and , is the number of Gaussian distribution mixed in GM; , , and are the weights, means, and variances. The channel coefficient follow the BG distributions for Eqs. (32) and (33), and GM distributions for Eqs. (34) and (35) respectively with unknown parameters and and noise variance and , respectively.
The computational complexity and the performance comparison analysis is shown in Table 1.
| Sl No. | Name of the algorithm | Computational complexity | Comparative analysis |
|---|---|---|---|
| 1. | OMP | The computational complexity is high for high dimensional sensing matrix. | |
| 2. | GAMP | The computational complexity is lower than the OMP scheme, because GAMP uses a simple matrix multiplication process. | |
| 3. | EM-LAMP | The computational complexity is higher than GAMP, because the incorporation of the EM concept with LAMP network improves the channel estimation accuracy. | |
| 4. | EM-VAMP – GLM | The Computational complexity of EM-VAMP–GLM is same with EM-LAMP. EM-VAMP–GLM is deal with vector based prior information and EM-LAMP is deal with scalar based prior information. EM-VAMP-GLM outperforms EM-LAMP and it provide more accurate prior information, better convergence during high-dimensional data. The proposed method can exploit the vectorized structure to process and interpret the data more efficiently. |
Results and discussion
The simulation results for the proposed EM-VAMP-GLM is discussed and compared with the existing OMP, GAMP and EM-LAMP. The simulation parameter is shown in Table 2.
| Parameters | Value |
|---|---|
| N | 256 |
| M | 64,128,256 |
| 5 | |
| 8 |
The azimuth/elevation angles are uniformly generated from (−π/2, π/2) along the pre-discretized virtual angle grids. Equation (3) is utilized for generating the channel . The operating frequency is considered as 28 GHz.
Where the normalized mean square error (NMSE) is defined as .
As shown in Fig. 3, the NMSE with respect to SNR is shown between the proposed EM-VAMP-GLM algorithm and alternative approaches including OMP, GAMP, and EM-LAMP. The results show that GAMP and EM-LAMP algorithms exhibit superior performance compared to the OMP algorithm. In the case of an IID Gaussian matrix , both GAMP and EM-LAMP techniques do not perform well when compared to the proposed EM-VAMP-GLM algorithm.
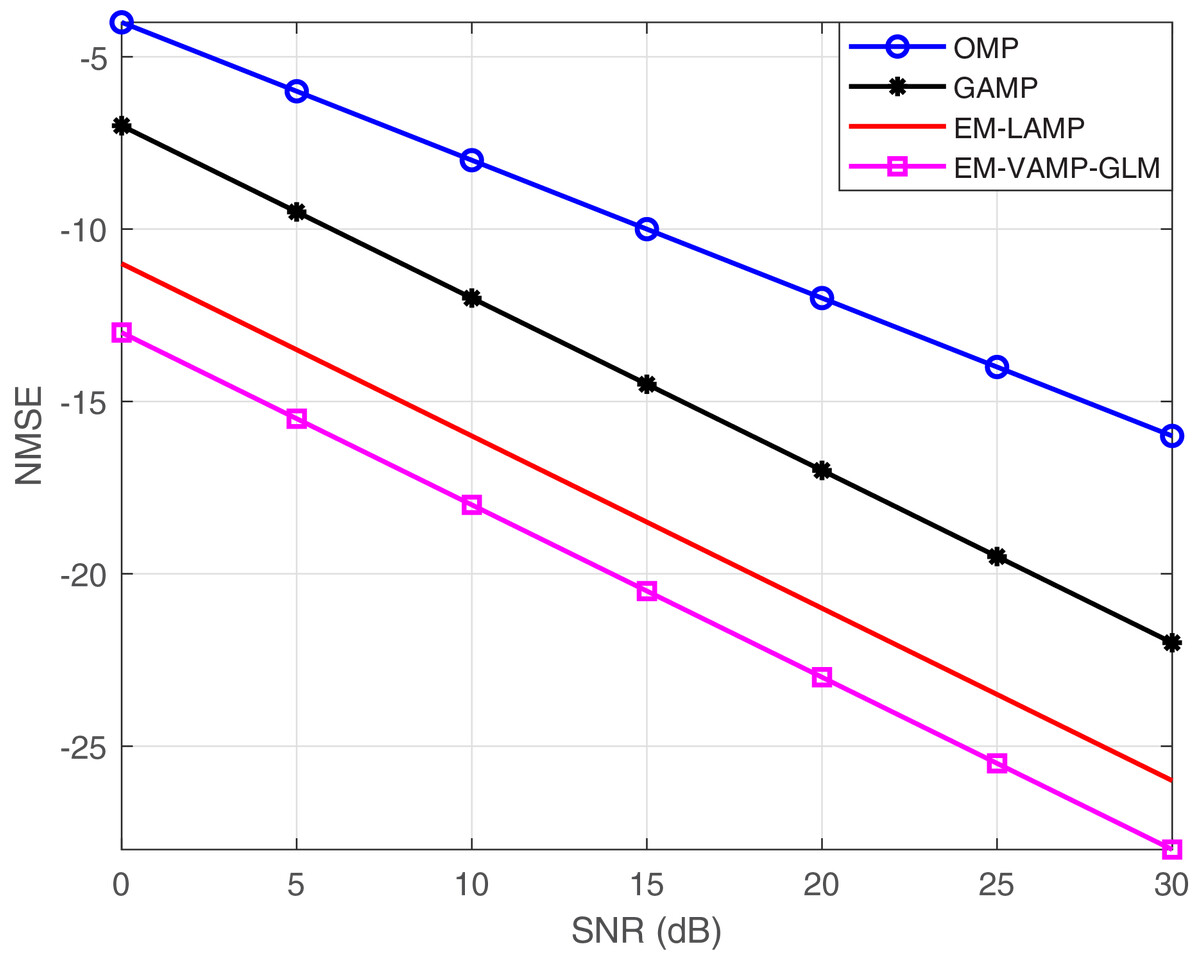
Figure 3: NMSE vs. SNR.
{kind=link}
Figure 4 provides a comprehensive exploration of the NMSE against SNR for various shrinkage function. The performance analysis of various shrinkage functions such as GM, BG, and soft threshold shrinkage function is applied in the proposed EM-VAMP-GLM and EM-LAMP network. The proposed EM-GM-VAMP-GLM, EM-BG-VAMP-GLM and EM-ST-VAMP algorithms, is compared to the existing EM-GM-LAMP, EM-BG-LAMP and EM-ST-LAMP.
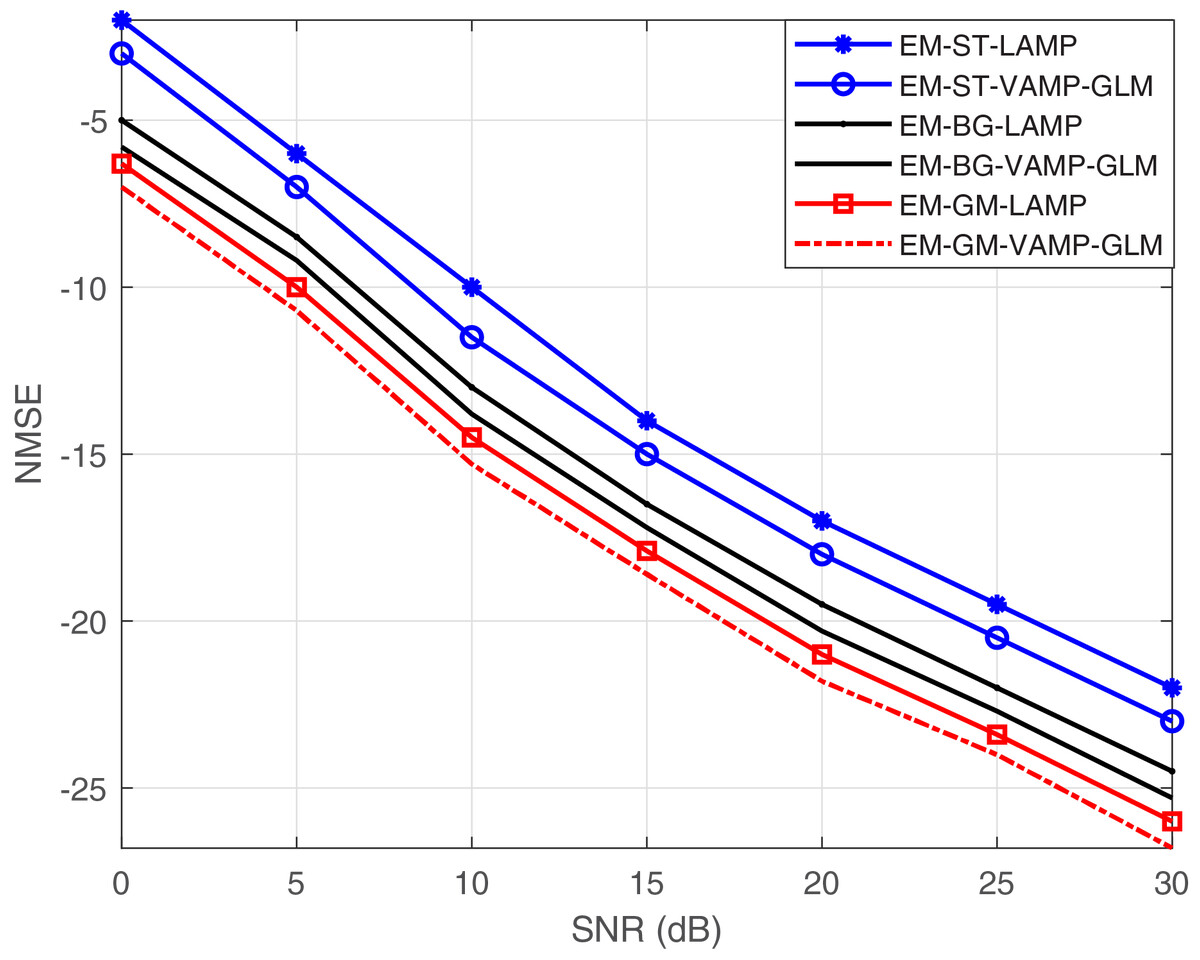
Figure 4: NMSE vs. SNR with different shrinkage functions such as soft threshold, Bernoulli-Gaussian and Gaussian mixture.
{kind=link}
LAMP behaves certainly with IID Gaussian matrix , but less certainly with non-IID-Gaussian . To address the challenge of non-IID-Gaussian signal estimation, we introduce the EM-GM-VAMP-GLM and EM-BG-VAMP-GLM methodologies. In Fig. 4, the usage of BG or GM shrinkage function for proposed algorithm achieve better performance compared to the soft threshold shrinkage function based EM-VALP-GLM algorithm. Even when is not IID Gaussian, EM-GM-VAMP-GLM and EM-BG-VAMP-GLM algorithm perform well compared to the LAMP and GAMP.
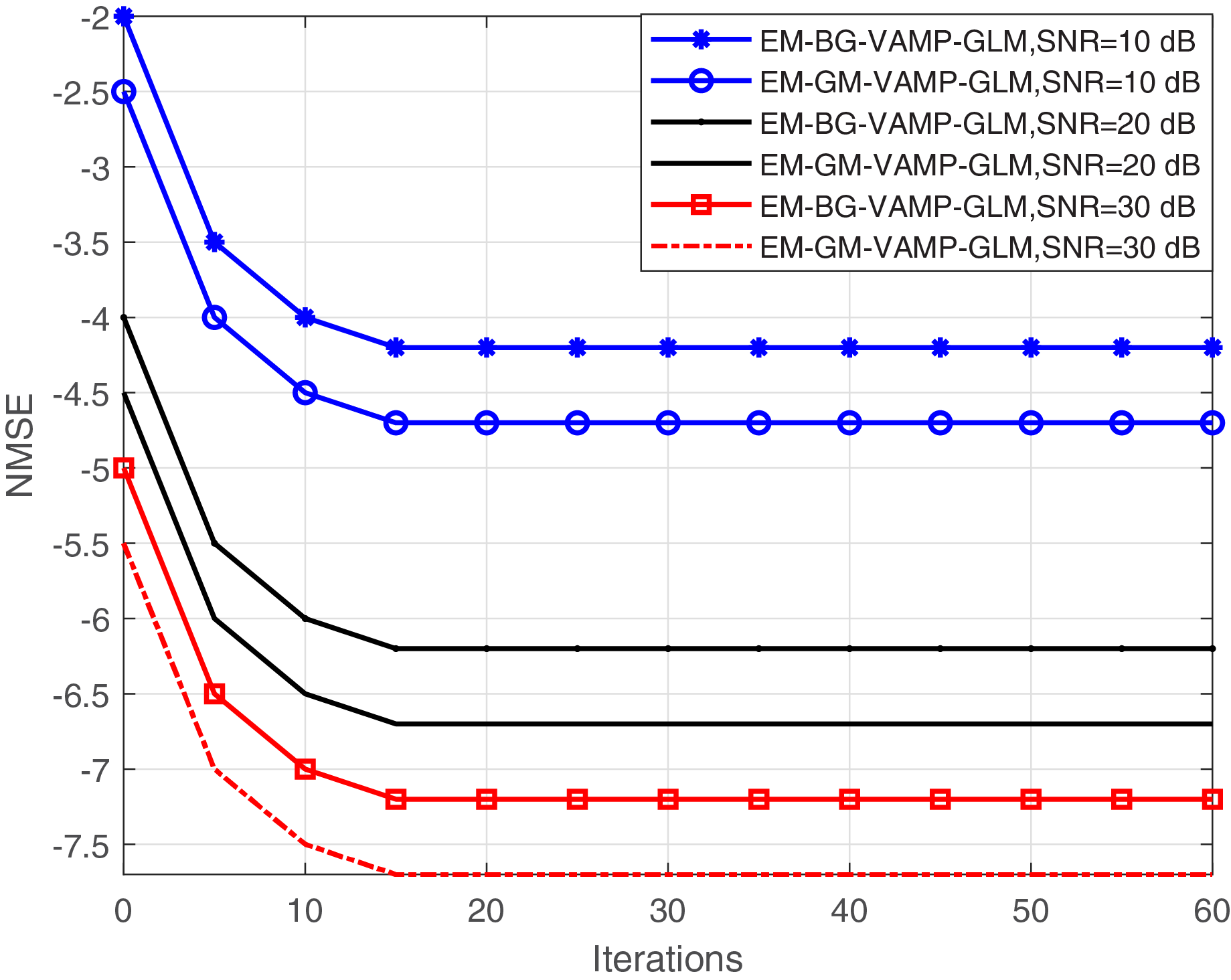
Figure 5 illustrates the relationship between NMSE and the number of iterations for the proposed EM-BG-VAMP-GLM and EM-GM-VAMP-GLM techniques across varying SNRs. Evidently, both the EM-BG-VAMP-GLM and EM-GM-VAMP-GLM algorithms exhibit convergence within a modest span of fewer than 22 iterations. This observation highlights their fast convergence rate, and reduces the computational complexity for BG and GM shrinkage function scenarios. Notably, in both algorithms, an increase in SNR corresponds to an extended the convergence rate with a greater number of iterations, because the BG and GM shrinkage function need additional parameters to be learned in the EM update process of EM-BG-VAMP-GLM and EM-GM-VAMP-GLM algorithms.
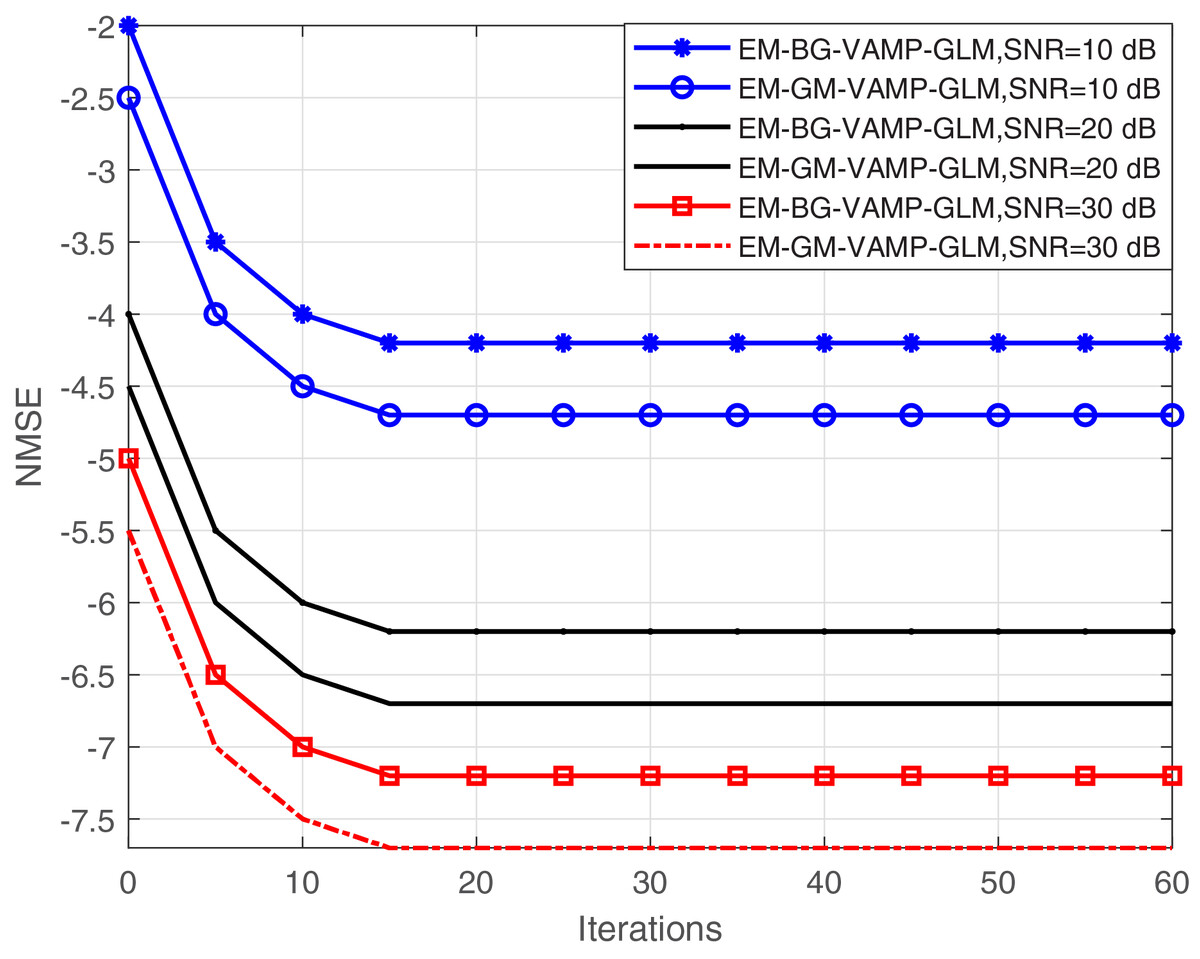
Figure 5: NMSE vs. Iterations.
{kind=link}
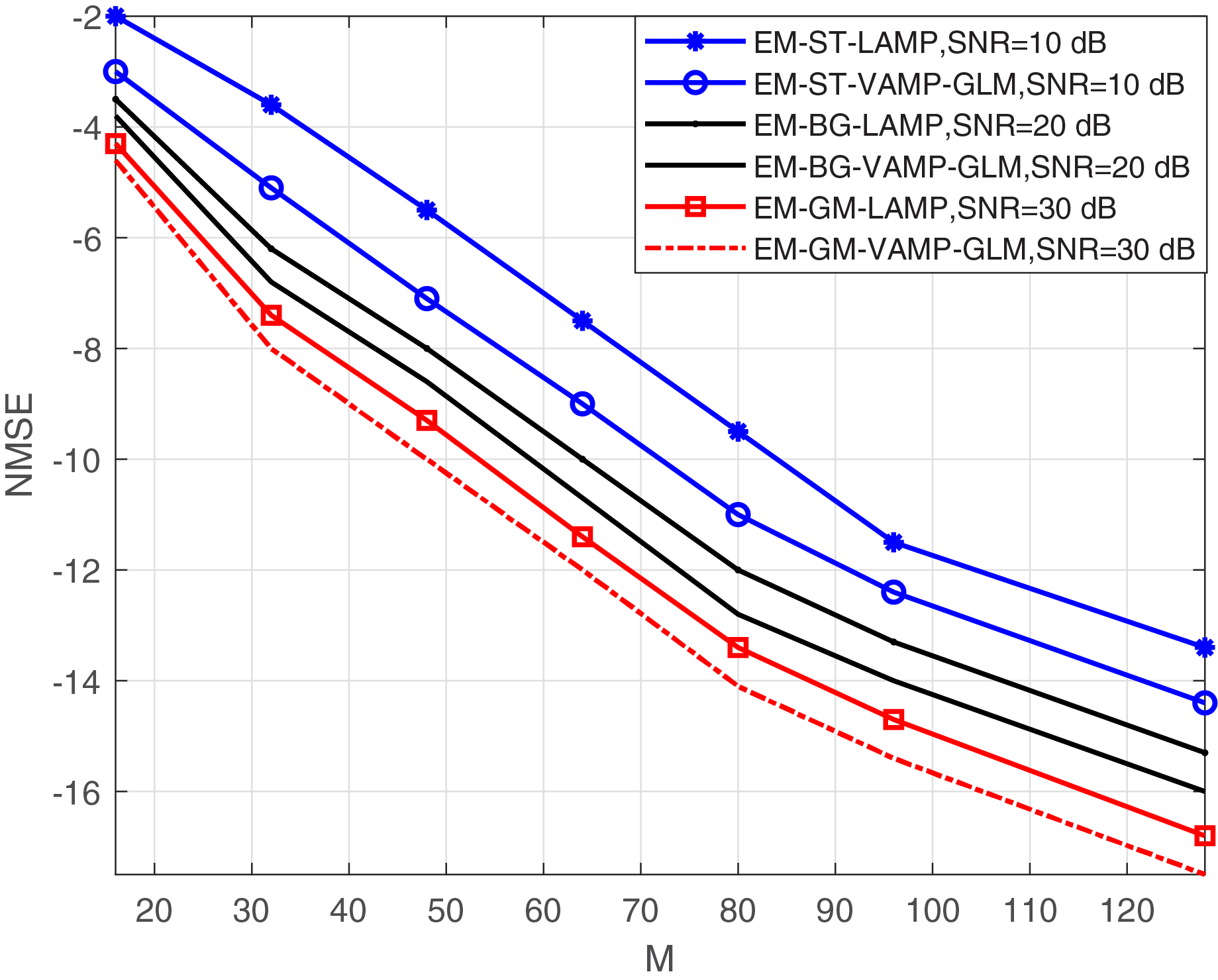
The investigation into NMSE performance vs. the number of BS antennas, denoted as M for both the proposed EM-BG-VAMP-GLM and EM-GM-VAMP-GLM algorithms at different value of SNRs is shown in Fig. 6. For the increased number of antennas M, it is observed that both EM-BG-VAMP-GLM and EM-GM-VAMP-GLM algorithms consistently exhibit reduced NMSE values. The higher SNRs value provide low NMSE value for proposed EM-BG-VAMP-GLM and EM-GM-VAMP-GLM. Under sparser environment, the scattering paths is fixed, so that the number of large non-zero elements is also fixed. The increased number of antennas provide the estimation outcomes are inherently enhanced, under the sparser conditions. Ultimately, these results highlight the practicality and appropriateness of utilizing the suggested EM-BG-VAMP-GLM and EM-GM-VAMP-GLM algorithms for efficient channel estimation with the assistance of IRS in mmWave communication systems. This leverages the benefits derived from angular domain sparsity.
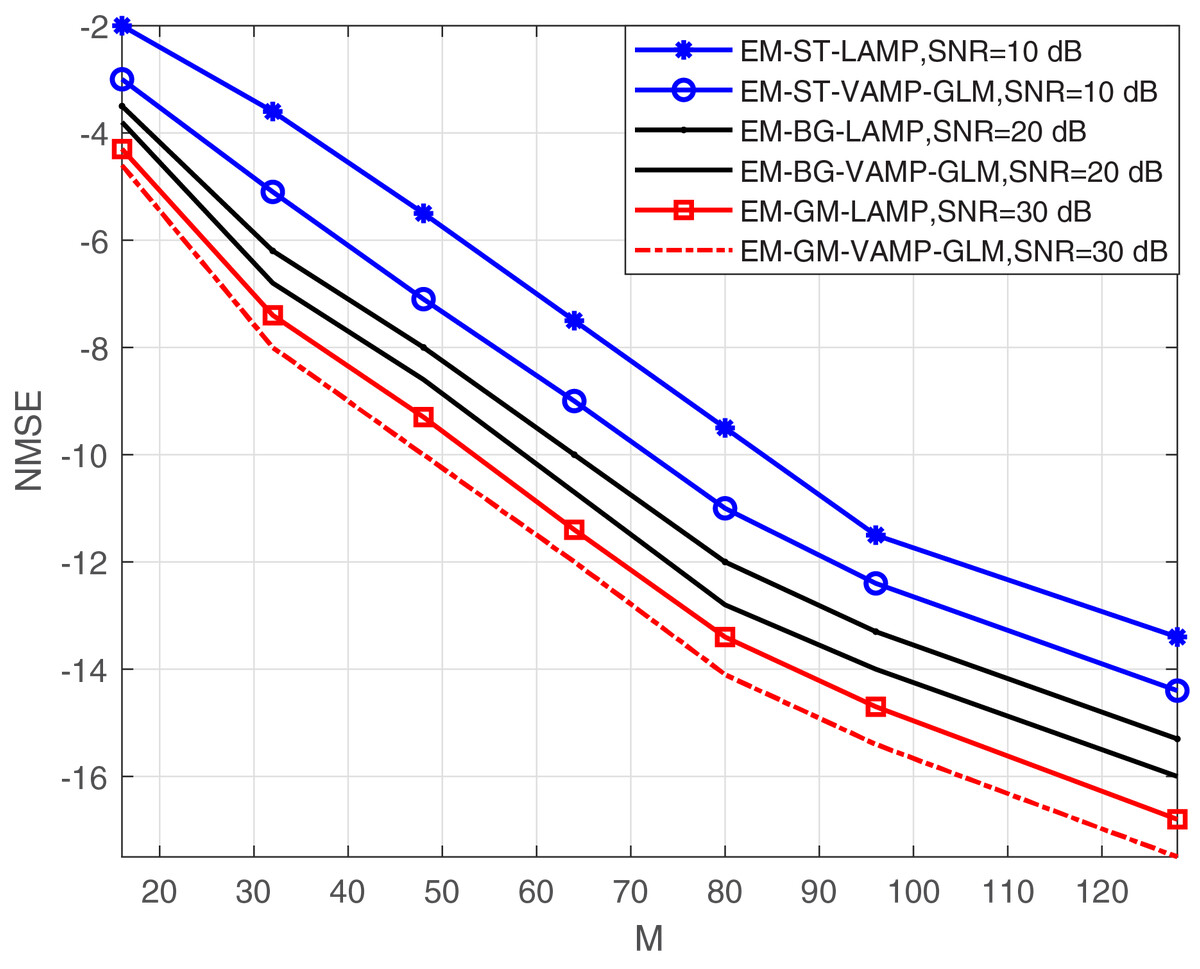
Figure 6: NMSE vs. M with different SNR value.
{kind=link}
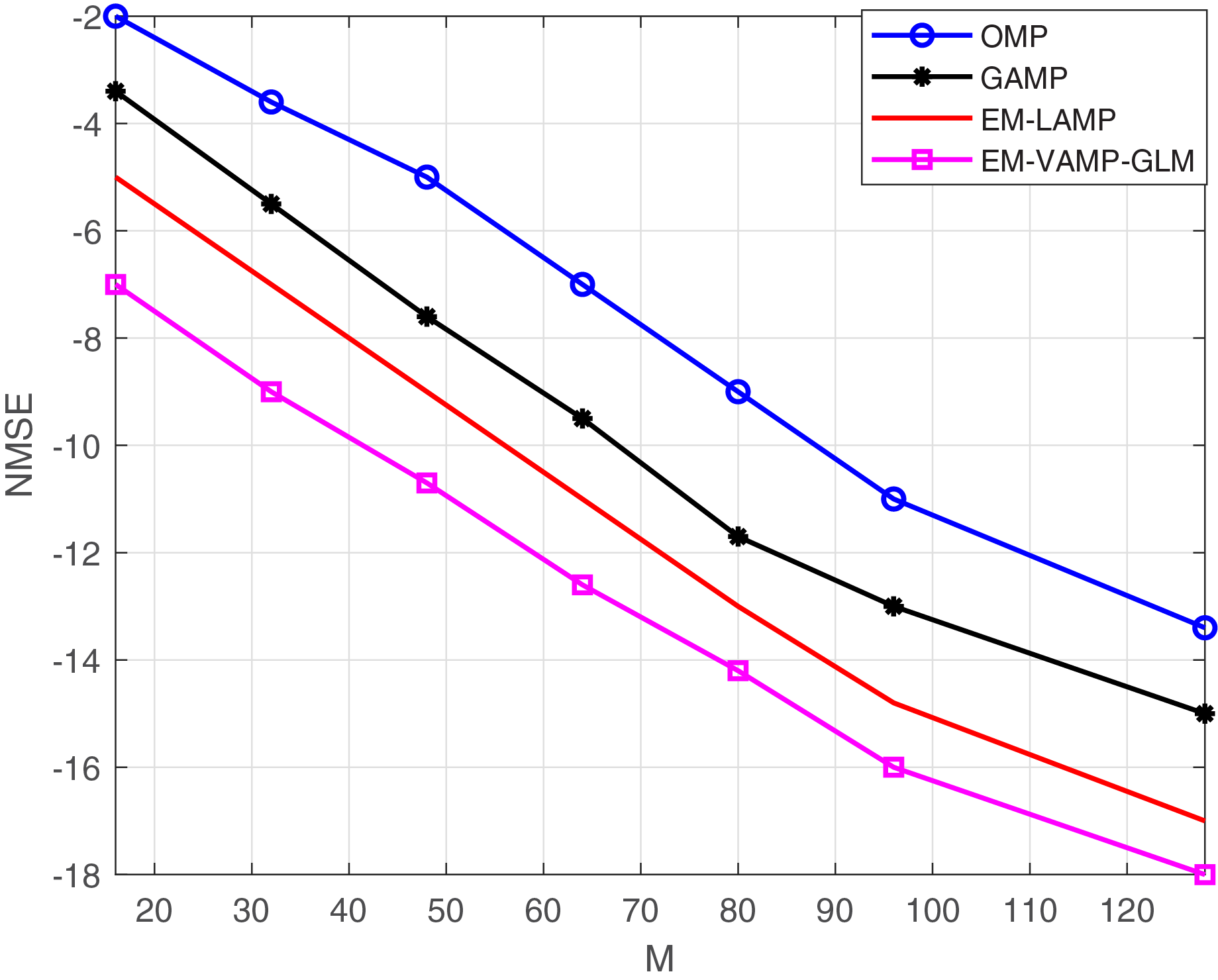
In Fig. 7, we perform the comparison between M and NMSE. As it can be seen in Fig. 7, the proposed approach outscores the existing approaches by exhibiting less NMSE with respect to the increment in the number of antennas.
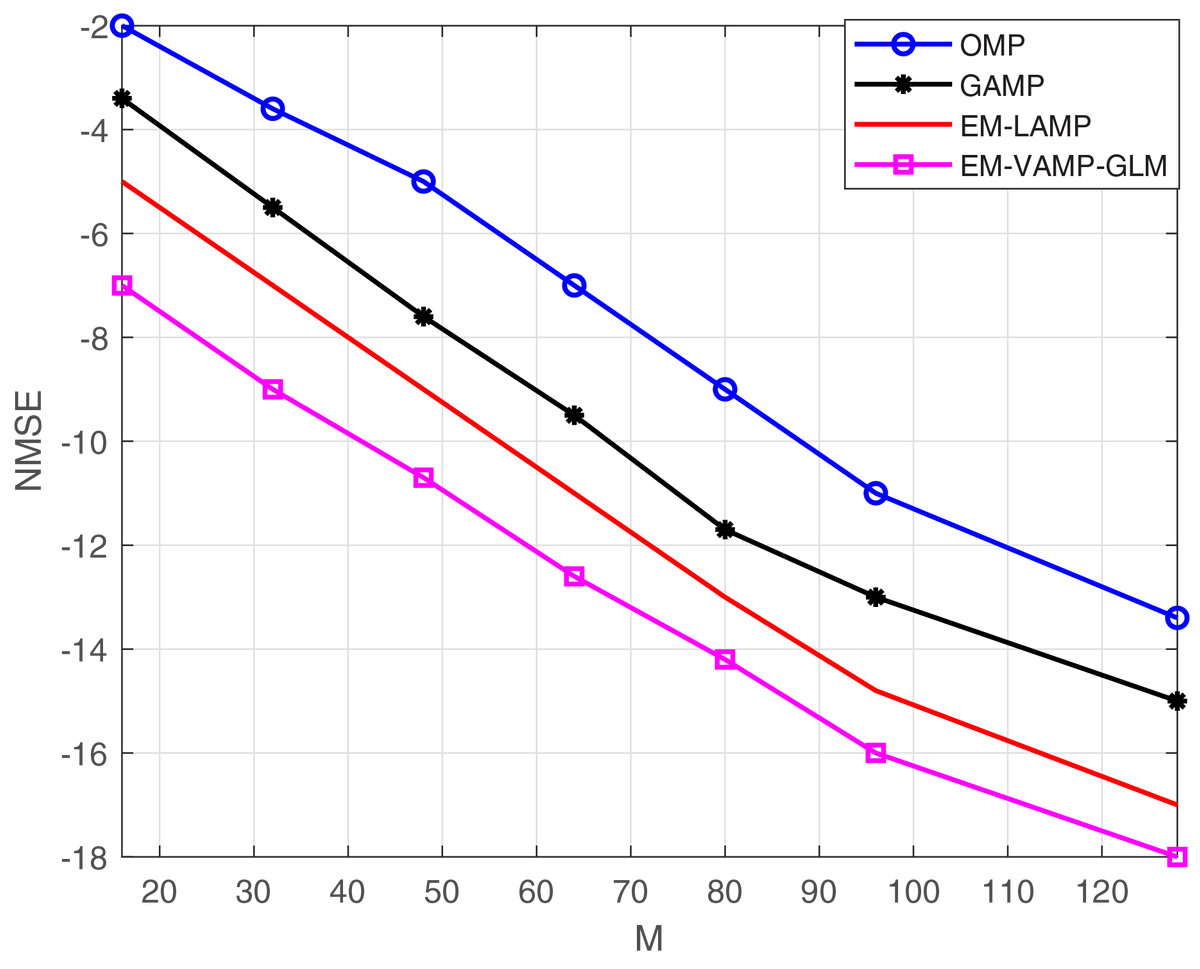
Figure 7: NMSE vs. M.
{kind=link}
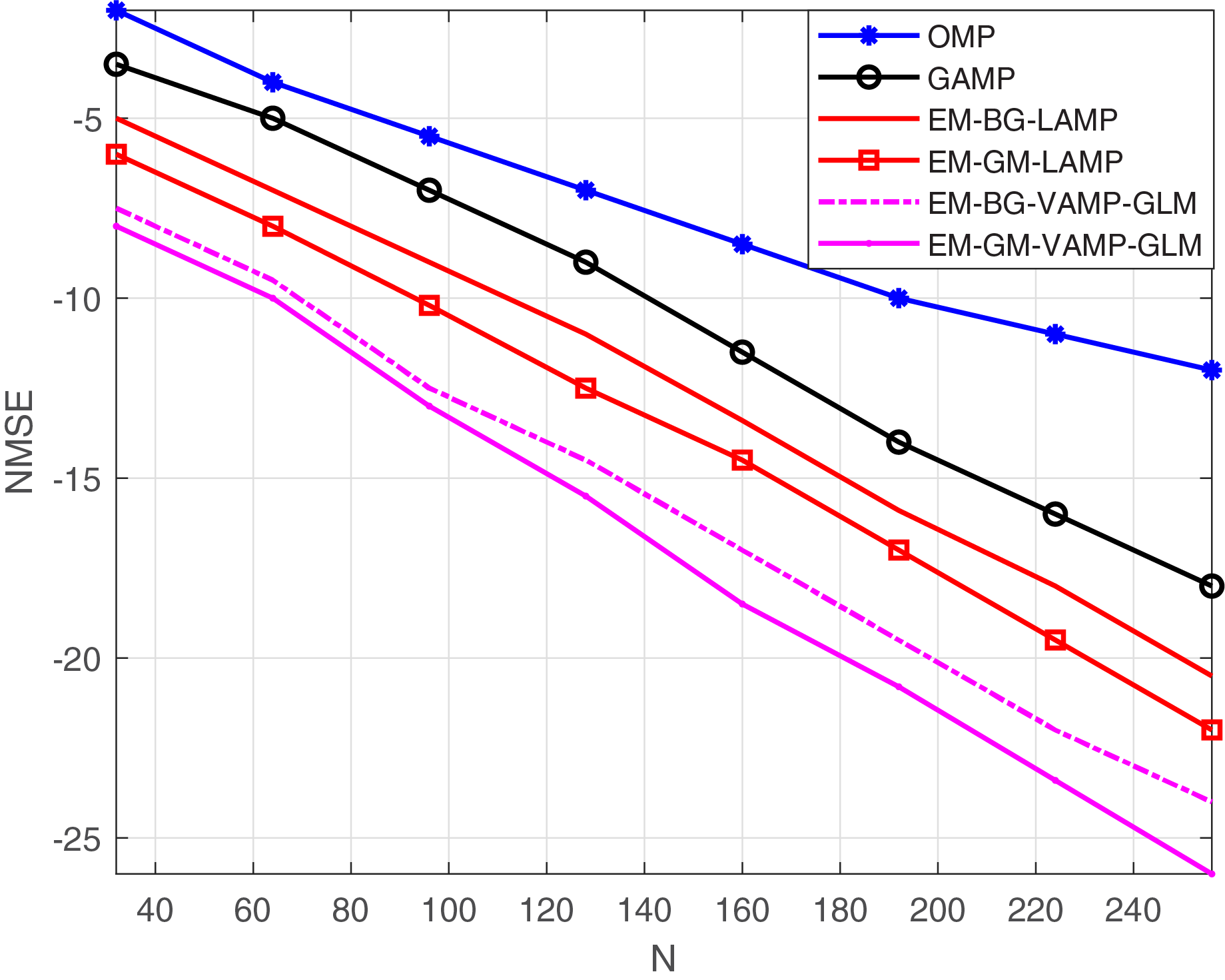
Figure 8 depicts the NMSE against the number of IRS elements, denoted as N, for the EM-BG-VAMP-GLM and EM-GM-VAMP-GLM algorithms. The quantity of IRS elements, N, increases, with both the EM-BG-VAMP-GLM and EM-GM-VAMP-GLM algorithms consistently demonstrating lower NMSE compared to the other techniques.
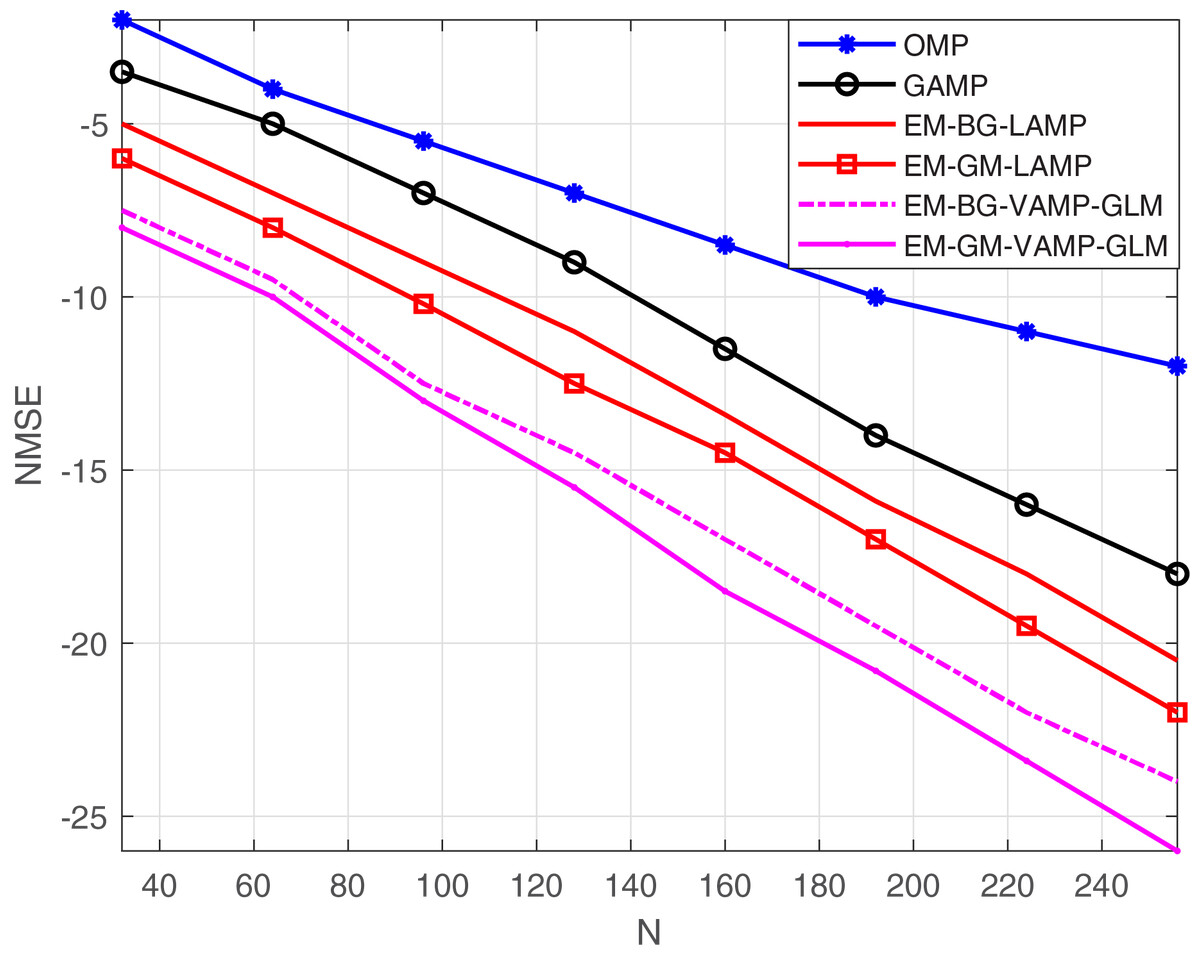
Figure 8: NMSE vs. N.
{kind=link}
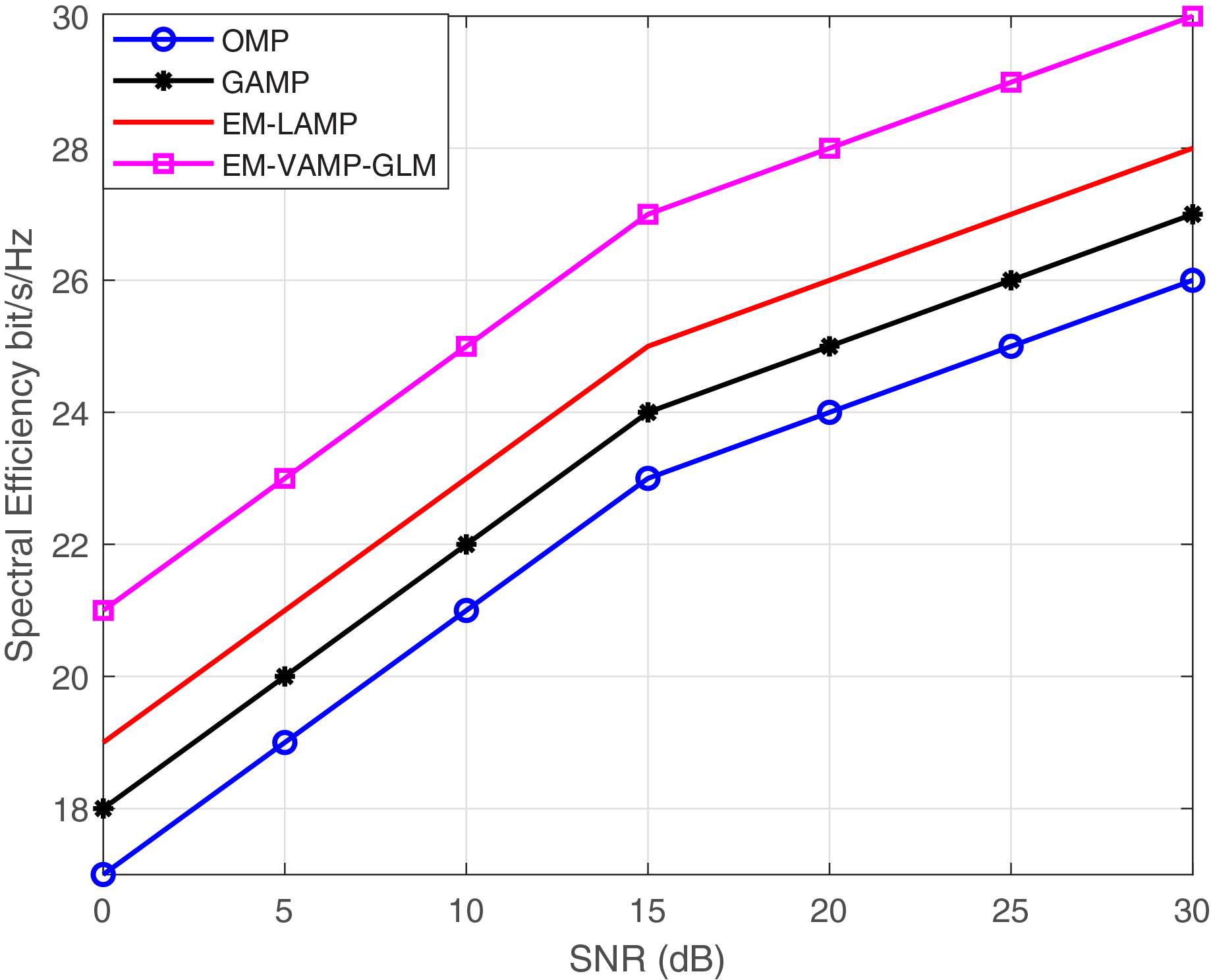
Figure 9 provides the SNR against the Spectral Efficiency for the proposed EM-VAMP-GLM and Existing algorithm such as OMP, GAMP and EM-LAMP algorithm. At 15 dB SNR, the proposed EM-VAMP-GLM algorithm provide 14.8%, 11% and 7%, and 8.5% of enhancement in spectral efficiency compared to OMP, GAMP and EM-LAMP algorithm respectively. The SNRVs Spectral Efficiency is shown in Table 3.
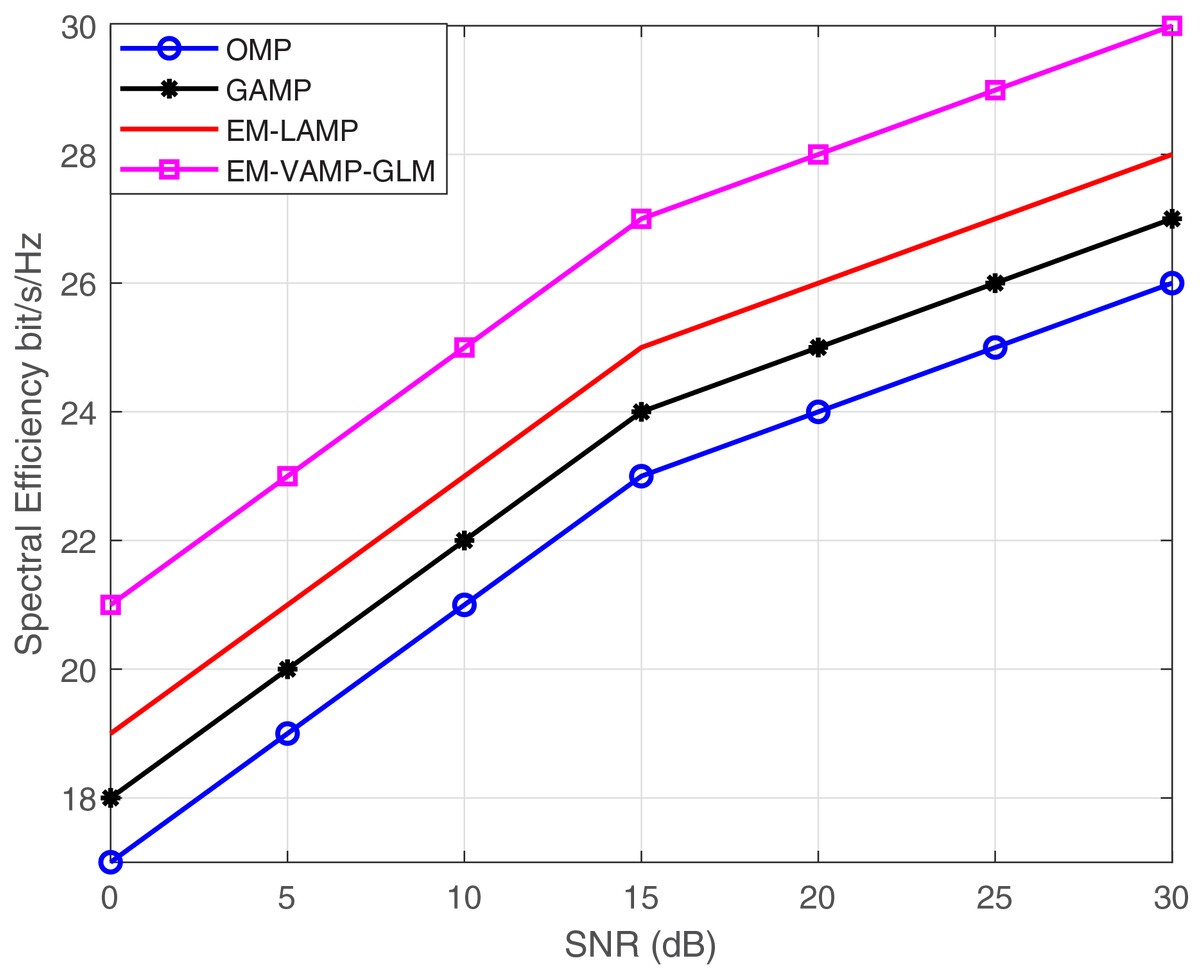
Figure 9: SNR vs. spectral efficiency bits/s/Hz.
{kind=link}
| Sl No. | SNR (dB) | OMP | GAMP | EM-LAMP | EM-VAMP–GLM |
|---|---|---|---|---|---|
| 1. | 0 | 17 | 18 | 19 | 21 |
| 2. | 5 | 19 | 20 | 21 | 23 |
| 3. | 10 | 21 | 22 | 23 | 25 |
| 4. | 15 | 23 | 24 | 25 | 27 |
| 5. | 20 | 24 | 25 | 26 | 28 |
| 6. | 25 | 25 | 26 | 27 | 29 |
| 7. | 30 | 26 | 27 | 28 | 30 |
Conclusions
This research focuses on addressing the channel estimation problem within an IRS-assisted mmWave MIMO system. We present the EM-BG-VAMP-GLM and EM-GM-VAMP-GLM techniques for effectively computing channel vector in this scenario. By utilizing EM-VAMP-GLM, we achieve precise channel estimation without the need for crucial parameters like noise variance and prior distribution parameters. The investigation considers two potential distributions–BG and GM distributions–to identify the most suitable model for characterizing the sparse angular domain channel. We perform the comparison between EM-GM-VAMP-GLM and EM-BG-VAMP-GLM techniques against existing methods such as LAMP, GAMP, and OMP. The experimental results indicate that, especially at higher SNRs, the EM-GM-VAMP-GLM demonstrates superior computation accuracy with rapid convergence.