
Fast binary logistic regression
- Published
- Accepted
- Received
- Academic Editor
- Charles Elkan
- Subject Areas
- Data Mining and Machine Learning, Data Science
- Keywords
- Logistic regression, Low-rank, Singular value decomposition, Lf-norm regularization
- Copyright
- © 2025 Saran and Nar
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Fast binary logistic regression. PeerJ Computer Science 11:e2579 https://doi.org/10.7717/peerj-cs.2579
Abstract
This study presents a novel numerical approach that improves the training efficiency of binary logistic regression, a popular statistical model in the machine learning community. Our method achieves training times an order of magnitude faster than traditional logistic regression by employing a novel Soft-Plus approximation, which enables reformulation of logistic regression parameter estimation into matrix-vector form. We also adopt the Lf-norm penalty, which allows using fractional norms, including the L2-norm, L1-norm, and L0-norm, to regularize the model parameters. We put Lf-norm formulation in matrix-vector form, providing flexibility to include or exclude penalization of the intercept term when applying regularization. Furthermore, to address the common problem of collinear features, we apply singular value decomposition (SVD), resulting in a low-rank representation commonly used to reduce computational complexity while preserving essential features and mitigating noise. Moreover, our approach incorporates a randomized SVD alongside a newly developed SVD with row reduction (SVD-RR) method, which aims to manage datasets with many rows and features efficiently. This computational efficiency is crucial in developing a generalized model that requires repeated training over various parameters to balance bias and variance. We also demonstrate the effectiveness of our fast binary logistic regression (FBLR) method on various datasets from the OpenML repository in addition to synthetic datasets.
Introduction
Classification has been extensively investigated in statistical learning as a supervised learning task. As pioneering works, the contributions of Berkson (1944) and Cox (1958) to the field of logistic regression are recognized as foundational. Berkson applied the logistic function to bio-assay, while Cox introduced regression analysis of binary sequences. Different forms of logistic regression are available to handle outputs in binary, multinomial, and ordinal formats, making it a versatile machine learning algorithm capable of addressing a wide range of classification tasks such as marketing, finance, healthcare, and fraud detection. With the rapid development of machine learning, highly flexible models such as extreme gradient boosting (XGBoost), support vector machine (SVM), and neural networks have become prominent (Cioffi et al., 2020). However, studies indicating logistic regression’s superior performance in some scenarios (de Hond et al., 2022; Jiang, Hu & Jia, 2023; Nusinovici et al., 2020; Zabor et al., 2022) and continuous usage of it (Jaskie, Elkan & Spanias, 2019; Lu, 2024) underscore the statistical machine learning community’s continued interest in this method.
Several improvements to the original logistic regression method are proposed (Berkson, 1944), such as weight regularization to obtain a generalized model or adapt the method for large data (Jiang, Hu & Jia, 2023; Bertsimas, Pauphilet & Van Parys, 2021; Tibshirani, 1996; Zaidi et al., 2016). Achieving a generalized model is closely tied to the bias-variance tradeoff where high-bias models risk oversimplification and underfitting, while low-bias models can overfit, exhibiting high variance. The tradeoff involves balancing these extremes to ensure the model generalizes well to unseen data without overfitting or underfitting. The optimal tradeoff is achieved by selecting appropriate model parameters that yield the most effective model complexity for training and validation sets, using techniques such as cross-validation and bootstrapping (Wahba et al., 1998; Gong, 2006; Mohr & van Rijn, 2023). It can be summarized that there must be a match between model complexity and data complexity to ensure that a model trained on training data performs well on unseen test data (Geman, Bienenstock & Doursat, 1992). Identifying optimal model parameters necessitates multiple training iterations with data subsets or random subsamples, a computationally intensive process for various parameter combinations, particularly with large datasets (Mohr & van Rijn, 2023; Emmert-Streib & Dehmer, 2019).
Logistic regression assumes a linear relationship between features and class distributions without demanding a specific statistical distribution. However, it is strictly required that features exhibit no multicollinearity. Regularization emerges as a vital solution to address multicollinearity and effectively manage model complexity. Aside from the intercept term, weight regularization applied to features encourages sparsity in the weight vector, resulting in fewer and more distinct features. This reduces multicollinearity and complexity, improving the model’s generalization abilities (Shi et al., 2010; Zhang et al., 2021; Avalos, Grandvalet & Ambroise, 2003). Additionally, in scenarios with numerous features available but limited training data, the risk of overfitting can arise without an effective regularization technique (Vapnik, 2006). Thus, pursuing a sparse solution is crucial to reduce overfitting and prevent data’s random pattern memorization (Zhang et al., 2021).
-norm (also known as Ridge) regularization, first introduced by Tikhonov (1963), penalizes the magnitudes of the weights to enforce smaller values, thereby increasing model robustness. In the literature, other weight regularization techniques (Tikhonov & Arsenin, 1979; Morozov, 2012; Bertero, 1986) also enforce sparsity for better robustness and increased model generalization. Among these techniques, -norm1 , provide most sparse solutions (Wang, Chen & Yang, 2022; Greenwood et al., 2020). Nevertheless, using -norm is challenging since it is not convex. Thereby, -norm, namely least absolute shrinkage and selection operator (LASSO) (Tibshirani, 1996), is proposed as a convex relaxation of non-convex -norm. Each regularization approach imposes different constraints on the model training. For example, -norm imposes a squared penalty (Hoerl & Kennard, 1970) and -norm imposes an absolute penalty on the model’s parameters (Ozgur, Nar & Erdem, 2018; Wei et al., 2019; Xie et al., 2023) while -norm imposes a constant penalty for all non-zero weights (Wang, Chen & Yang, 2022; Greenwood et al., 2020). Note that the Bayesian information criterion (BIC) (Schwarz, 1978) and the Akaike information criterion (AIC) (Akaike, 1998), well-known model selection criteria, are special cases of -norm regularization. So, sparse models using -norm and -norm enforce many coefficients to shrink to exactly zero while -norm tends to produce model parameters closer but not precisely zero (Pereyra et al., 2017). Thus, -norm and -norm are employed in feature selection to avoid overfitting. On the contrary, -norm has better computational efficiency than -norm and is even more efficient than -norm. Thereby, several studies prefer to use -norm or -norm regularized logistic regression for large scale data (Koh, Kim & Boyd, 2007; Shi et al., 2010; Jovanovich & Lazar, 2012; Su, 2020). Elastic-net combines the -norm and -norm penalties, so it tends to choose more features than LASSO, but computational efficiency becomes similar to Ridge. Recently, some studies tackled the -norm regularization for logistic regression while dealing with challenges of using non-convex -norm regularization term (Ming & Yang, 2024; Hazimeh, Mazumder & Nonet, 2023; Knauer & Rodner, 2023; Deza & Atamturk, 2022). Although not proposed for logistic regression, the use of fractional norm as a penalty term was proposed as a flexible and practical approach for enforcing smoothness on the image denoising (Ozcan, Sen & Nar, 2016), where it is also better suited for handling the generalized Gaussian distribution of the variables (Bernigaud et al., 2021).
As already stated in the literature, the maximum likelihood estimation of the logistic regression has some shortcomings:
It may struggle to handle massive sparse datasets (Holland & Welsch, 1977; Li, Zhu & Wang, 2023) effectively.
Logistic regression often struggles with imbalanced data, tending to favor the majority class and resulting in poor performance on the minority class (King & Zeng, 2001).
For the training set where the number of samples is smaller than the number of features, directly solving the logistic regression is an ill-posed problem (Liu, Chen & Ye, 2009).
It is sensitive to anomalous data and collinearity (Feng et al., 2014; Midi, Sarkar & Rana, 2010).
Oversampling data instances may decrease estimation performance and increase computational expenses (Wang, 2020).
One strategy to mitigate these challenges involves utilizing the iteratively reweighted least squares method with an appropriate solver to construct binary logistic regression classifiers, particularly for large-scale datasets (Paciorek, 2007; Rouhani-Kalleh, 2007). Employing appropriate numerical solvers can also address these problems. Hence, numerous numerical solvers have been deployed to tackle these challenges, such as gradient descent and its variants, Newton’s method, and quasi-Newton methods. These solvers play a crucial role in training models efficiently by iteratively adjusting parameters to minimize a specified objective function. Although these approaches attempt to eliminate anomalies or collinearity problems in the data, working with many solvers with different regularizers poses a challenging issue for researchers (Liu, Chen & Ye, 2009). The selection of the solver typically depends on the specific characteristics of the data and the nature of the problem under consideration.
Scikit-learn (Pedregosa et al., 2011), a versatile Python library integrating a wide range of state-of-the-art machine learning algorithms, has become one of the most popular choices among many libraries due to its simplicity, comprehensive documentation, and extensive community support. The LogisticRegression class in scikit-learn already incorporates several optimization methods (see Table 1), each tailored for different regularizers, data sizes, and computational needs. Similarly, other open-source libraries, including cuML and Statsmodels, provide their own implementations of logistic regression, each with a variety of solvers and parameter configurations to enhance flexibility and efficiency. In particular, cuML offers graphics processing unit (GPU)-accelerated solvers for large-scale computations and Statsmodels provides robust statistical modeling options for binary response variables.
| ElasticNet | No regularization | |||
|---|---|---|---|---|
| LBFGS1 | ✓ | ✓ | ||
| LIBLINEAR (Fan et al., 2008) | ✓ | ✓ | ||
| Newton-CG1 | ✓ | ✓ | ||
| Newton-Cholesky1 | ✓ | ✓ | ||
| SAG (Schmidt, Roux & Bach, 2017) | ✓ | ✓ | ||
| SAGA (Defazio, Bach & Lacoste-Julien, 2014) | ✓ | ✓ | ✓ | ✓ |
Note:
With increasing dataset sizes, logistic regression needs to improve in terms of efficiency and scalability. In response, advanced versions have emerged, designed to prioritize speed and accuracy. These innovative approaches accelerate learning by leveraging techniques such as dimensionality reduction, parallel processing, and advanced data structures.
Logistic regression training is formulated to solve an optimization problem based on likelihood maximization. However, calculating the gradient with all training data in each iteration for large datasets becomes computationally demanding. Therefore, Song et al. (2021) proposed an adaptive sampling method in which the gradient estimation is divided into several sub-problems according to the data size, and then each sub-problem is solved independently before combining the results of all sub-problems. Shi et al. (2010) suggested a hybrid algorithm that merges two optimization iterations: one that is fast and memory-efficient and another that is slower but yields more precise results.
Various approaches have been proposed to enhance the speed of logistic regression, which can generally be categorized into efficient numerical methods and software-based improvements. Table 1 summarizes the solvers employed in scikit-learn. A notable earlier study by Komarek & Moore (2003) utilizes Cholesky decomposition to accelerate logistic regression. However, since many contemporary methods now incorporate Cholesky decomposition within NumPy or employ more advanced solvers, this study has yet to be considered state-of-the-art. Additionally, some approaches leverage field programmable gate array (FPGA) and GPU (Wienbrandt et al., 2019), stochastic gradient descent, and mini-batch (Yang et al., 2019; Liang et al., 2020; Jurafsky & Martin, 2024) methods to improve the speed of logistic regression. These techniques are often complementary and can be integrated with other methods, representing practical efforts to accelerate logistic regression further.
We introduce a novel numerical approach that remarkably improves the training efficiency of binary logistic regression without relying on dimension reduction or parallel processing and without requiring feature independence. This efficiency is obtained by employing a novel Soft-Plus approximation, which enables reformulation of logistic regression parameter estimation into matrix-vector form. Additionally, unlike the multiple solvers employed in scikit-learn’s logistic regression for different regularization schemas, we present a single flexible -norm regularization approach that also provides flexibility to include or exclude penalization of the intercept term. Our regularization approach supports a range of weight penalties through a unified codebase with a specifically designed numerical minimizer. To demonstrate the computational efficiency of our method, we conducted several quantitative experiments, comparing our method against the widely used scikit-learn library. Here, we used benchmark data from OpenML, an open machine learning data repository, and synthetic data designed for controlled experiments. Experiments demonstrate that our method effectively handles collinear features and large data while providing superior efficiency with minimal to no loss in accuracy. Our fast binary logistic regression (FBLR) exclusively utilizes the Python NumPy library. As a result, it benefits from all current capabilities of NumPy and upcoming enhancements while keeping the codebase simple. This streamlined yet powerful approach allows it to surpass the performance of scikit-learn’s logistic regression (LR) implementation in processing speed, which relies on well-established and highly optimized libraries. Our experiments demonstrate that FBLR achieves an average speedup of an order of magnitude faster, with the maximum observed speedup reaching times.
Proposed method
Fast binary logistic regression
For logistic regression, the likelihood function in the context of maximum likelihood estimation (MLE) is formulated based on the assumption that each observation is an independent Bernoulli trial. Consider a dataset with observations , where each pairs with a binary outcome . Here, is the data index, and is the number of features, including the intercept. Then, the logistic regression model predicts the probability of the outcome being 1 is defined as:
(1) where represents the model parameters, namely the weight vector and is the data vector. For the binary classification using logistic regression, likelihood of observing the entire dataset given is the product of the probabilities for each observation that is given in Eq. (2):
(2)
The optimum model parameter is found by maximizing the with respect to weight vector for the given input data and corresponding target class labels, known as MLE:
(3)
Optimizing presents challenges due to the presence of product terms. However, instead of maximizing , one can opt to minimize . This approach is feasible because the maximum of corresponds to the minimum of , and is significantly easier to optimize. Then, we simplify as below:
(4)
To develop an efficient minimizer for , we approximate the Soft-Plus function, , at to obtain a quadratic form where is a proxy constant for . Details of our novel quadratic Soft-Plus approximation are provided in “Approximation of Soft-Plus”. By substituting this Soft-Plus approximation into Eq. (4), we derive the following form of :
(5) where
(6)
Finally, we put Eq. (5) into matrix-vector form as below:
(7) where is input data in matrix form, is target data in vector form, is weight vector, is a diagonal matrix form of .
Various forms of weight regularization have been proposed in the literature for logistic regression, each requiring distinct numerical approaches. Alternatively, we use smooth -norm (Ozcan, Sen & Nar, 2016) regularization to achieve a unified framework that only requires a single numerical approach, incorporating Ridge, pseudo ElasticNet, LASSO, -norm (notably, a pseudo-norm), and other fractional norm regularizations.
For quadratic approximation, let be a constant proxy for and define as a constant coefficient, . Then, quadratically approximated -norm is
(8)
Refer to “Approximation of Lf-Norm” for details and justification of the quadratic -norm approximation.
An iterative minimization approach (solver) is now required as we utilize quadratic approximations of (Soft-Plus) and a smooth -norm. Both approximations are performed on for each iteration, where the applied approximations are accurate near the point of approximation, namely which is a proxy constant for . To ensure that the new solution remains close to the approximation point at the current iteration, we introduce a slow-step-regularization (SSR) term with a coefficient . Finally, we normalize the terms by the data count and weight vector dimension.
(9) where is the iteration index, is weight vector, is a proxy constant for at iteration, is the SSR coefficient, and is -norm regularization coefficient. Here, is the vector used to prevent penalizing the intercept term, defined as , where is for the intercept (to avoid penalizing it) and 1 for all other coefficients. Then, is approximated as:
(10) where is a diagonal matrix form of values that is defined as below ( is a small positive constant with default as ):
(11)
The obtained cost function , comprising only quadratic terms, linear terms, and constants, can be expressed in a matrix-vector form.
(12)
Afterwards, we can minimize with respect to at iteration by taking the derivative of with respect to and equalizing it to zero:
(13) which can be arranged as:
(14) where is the identity matrix. Note that Eq. (14) can be represented as a linear system . Finally, the solution can be represented as below where and are updated in each iteration. In our case, is a symmetric matrix, and is a constant vector that can be computed before the iterative minimization.
| Initialization | Iteration |
|---|---|
Data matrix can be rank-deficient due to colinear features or insufficient data samples. When the data matrix is rank-deficient, and no regularization technique is applied ( ), the matrix may become a symmetric positive semi-definite matrix. Nonetheless, if is of full rank or a regularization is applied ( ), the matrix becomes symmetric positive definite. To mitigate the challenges due to rank-deficiency and the subsequent numerical instabilities, we utilized low-rank approximation using singular value decomposition (SVD) (Lawson & Hanson, 1995; Hansen, 1990) for approximating the data matrix (Ye, 2005).
(15) where , , , and . Then
(16)
We use -rank approximation of , , and matrices such that . Note that, , , and denotes low-rank approximations of the , , and matrices, respectively. Here, and are orthonormal matrices and is a diagonal matrix. In this low-rank approximation, is the rank such that and is chosen such that almost all of the energy (by eigenvalues) is preserved.
We initialize using least-square to start from a reasonable initial point. For computational efficiency, we also use the SVD decomposition on the least-square equation:
(17)
To circumvent numerical challenges and gain further computational efficiency, we employ a low-rank approximation as where . Computing is computationally efficient since the inverse of the diagonal matrix is computationally cheap. Also, computing is cheap as well. For both with and without regularization, a common initialization is defined as follows:
| , , since |
| Determine rank such that |
| where |
There are paths for the developed iterative minimization: (a) with regularization and (b) without regularization. It should be noted that applying -norm regularization requires setting a positive value, which in turn necessitates assigning a positive parameter to enable SSR regularization.
a) With regularization ( and )
Recall, first we need to construct matrix and vector then solve the linear system . Using the we have:
(18)
With , low-rank approximation of leads to :
(19)
Let compute in order to compute and use -rank approximation of as below:
(20)
Finally, the numerical minimization approach with regularization is as follows:
| Initialization | Iteration |
|---|---|
| where | |
| with low-rank estimation using SVD | |
Thanks to the low-rank approximation applied to the data matrix in addition to applied -norm and SSR regularization, the proposed cost function becomes strictly convex. So, the linear system is well-conditioned, ensuring a unique solution for , whereas the logistic regression cost function remains only convex due to potential rank deficiencies in .
b) Without regularization ( and )
First and are constructed then linear system is solved.
(21)
Let us use low-rank approximation of :
(22)
The final iterative numerical minimization approach without regularization is as follows:
| Initialization | Iteration |
|---|---|
Note that is a diagonal matrix with all positive entries, making its inverse extremely efficient to compute. Additionally, can be calculated efficiently, as computing requires only operations, and multiplying by the resulting vector requires only operations. As a result, each iteration without regularization remains highly efficient. In addition to computational efficiency, it is guaranteed that is always well-conditioned, and a unique solution for exists since , as a diagonal matrix with positive entries, is always invertible. Thus, the employed low-rank approximation regularizes the solution to mitigate possible collinearity in the data matrix .
Implementation
This section outlines the implementation of the proposed method, with the Low-Rank approximation described in the Algorithm 1 and the proposed FBLR method presented in the Algorithm 2. In the Algorithm 1, is input data matrix, is energy-percentile (default is 99.9999) the DIMENSION function returns the number of rows ( ) and the number of features ( ). The SVD(∗) function carries out singular value decomposition, choosing the most suitable variant—either truncated or randomized SVD (refer to “Randomized SVD”), or SVD with row reduction (SVD-RR) (refer to “SVD with Row Reduction”)—based on an evaluation of and . Lastly, the RANK function (see “Determining the Rank”) in the Algorithm 1 finds the matrix’s rank by analyzing the eigenvalues derived from , consequently generating matrices of low rank.
| 1: procedure LowRankApproximation ( , ξ) |
| 2: Returns the dimension of the data matrix |
| 3: DIMENSION : #row, d: #feature |
| 4: Utilizing either Truncated SVD or Randomized SVD |
| 5: SVD(∗) see “SVD with Row Reduction (SVD-RR) & Randomized SVD” |
| 6: Computes the rank of matrix using eigenvalues |
| 7: RANK see “Determining the Rank” |
| 8: The low-rank components of the matrices are extracted |
| 9: |
| 10: |
| 11: |
| 12: return |
| 13: end procedure |
| 1: procedure FBLR( , y, f, λ, γ, ξ, K, Ctolerance) |
| 2: Initialization |
| 3: LowRankApproximation |
| 4: |
| 5: Initializing weights via the pseudo-inverse |
| 6: if or then |
| 7: |
| 8: |
| 9: else |
| 10: |
| 11: end if |
| 12: Iteration |
| 13: for to K do |
| 14: |
| 15: diag(z) = vector , Eq. (6) |
| 16: if or then |
| 17: diag(h) = vector , Eq. (11) |
| 18: |
| 19: |
| 20: solve Applying Cholesky decomposition for solving |
| 21: else |
| 22: |
| 23: end if |
| 24: if and then |
| 25: break |
| 26: end if |
| 27: end for |
| 28: Finalization |
| 29: return w |
| 30: end procedure |
The pseudocode for the proposed FBLR method is given in Algorithm 2. In this algorithm, operations that remain constant throughout iterations are performed upfront in the initialization phase. First, low-rank approximation of the matrix is obtained using Algorithm 1. Depending on whether regularization is applied, various matrices and vectors are precomputed accordingly. Subsequently, at each iteration, a dense linear system is constructed and solved using the Cholesky decomposition, leveraging the fact that is a symmetric positive definite matrix when regularization is employed (line 20 in Algorithm 2). Even when regularization is not employed, computing is still well-conditioned (line 22 in Algorithm 2) since is a diagonal matrix with all positive entries.
Using Python v3.12.1, NumPy v1.26.4, and scikit-learn v1.3.2, proposed FBLR method in Algorithm 2, is implemented as the Python class FastLogisticRegressionLowRank extending scikit-learn’s abstract BaseEstimator and ClassifierMixin classes. We use NumPy for all matrix and vector operations where our NumPy configuration uses OpenBLAS as the backend for basic linear algebra subprograms (BLAS) operations in our environment. For additional efficiency, NumPy also utilizes CPU instructions such as single instruction multiple data (SIMD).
Computational complexity analysis
In the Algorithm 2, the time complexity of the initialization phase is since the time complexity of both the SVD used in the low-rank approximation and is . At the same time, the remaining operations have lower time complexity. Furthermore, the computational complexity per iteration is when incorporating regularization ( -norm & SSR) and without regularization. Noting that represents the number of iterations executed until the Algorithm 2 converges, the total time complexity of the FBLR method is for cases with regularization and when no regularization is applied. In the case without regularization, the time complexity is obtained since the computational complexity of the initialization is , and the complexity per iteration is . The total computational complexity is , which simplifies to . For the proposed FBLR method, is typically less than or equal to the maximum iteration (K) with a default value of 10.
Our time complexity analysis reveals that the FBLR method has linear time complexity with respect to the number of rows ( ) and at most quadratic time complexity with respect to the data dimension ( ). Furthermore, for the proposed FBLR method, the maximum number of iterations is only , which is considerably low. Thus, the maximum iteration count of the proposed FBLR method is small compared to logistic regression in scikit-learn with various solvers (see Table 2), demonstrating its efficiency.
| Solver | Default maximum iteration (K) | Typical iteration count |
|---|---|---|
| LIBLINEAR | 100 | 100 to 1,000 |
| LBFGS | 100 | 100 to 500 (up to 1,000) |
| Newton-CG | ||
| Newton-cholesky | ||
| SAG | 1,000 | 1,000 to 5,000 |
| SAGA |
The space complexity of the proposed FBLR method is at least the size of the input data matrix . So, we ignore the vectors employed in the FBLR method, as they have dimensions of or , which are much smaller than , size of the data matrix . So, we will focus only on the matrices employed in the FBLR method, as outlined below:
and are dense matrices space complexity is
and are sparse diagonal matrices space complexity is .
Therefore, space complexity of the proposed FBLR method is .
Results
We conducted experiments on a system running Ubuntu Linux 20.04 with an Intel Core i9-10900KF CPU (10 cores) and 64 GB of RAM. Note that NumPy leverages SIMD extensions supported by a CPU to a reasonable extent. For Intel Core i9-10900KF CPU, utilized SIMD extensions by NumPy are SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX22, F16C, and FMA3.
For the proposed FBLR method, and parameters are set to zero for all experiments unless stated otherwise. Also, fixed default values are used for the parameters , , K, and . The parameter , a small positive constant for the applied -norm approximation, is set to . Also, , representing the energy percentile for low-rank approximation, is , excluding zeros or very small eigenvalues. The maximum number of iterations is set to , and the convergence tolerance is set to . From this point forward, whenever logistic regression (LR) is mentioned in the text, it refers specifically to the logistic regression within scikit-learn.
Datasets
Realworld dataset
We used datasets with binary labels from the OpenML in the experiments. We focused on datasets with no missing data and training times exceeding s when utilizing LR. This strategy focused on selecting datasets that would benefit the most from speed enhancements. Our analysis compared the classification performance and execution efficiency between LR and our FBLR method across different scenarios, such as balanced and imbalanced datasets of medium to large sizes. Additionally, we evaluated the LR and FBLR method on the UCI’s HEPMASS dataset, which features rich data from key physics experiments targeting exotic particle discovery and poses a binary classification challenge. Detailed information on the datasets used with their attributes is provided in Table 3. In a binary dataset, the term ‘majority’ denotes a frequency between and for the class with more occurrences than the other class. In Table 3, creditcard dataset is imbalanced since it has a high majority value.
| Name | n (#samples) | d (#features) | Majority% |
|---|---|---|---|
| Kits | 1,000 | 27,648 | 52% |
| Road-safety | 111,762 | 32 | 50% |
| Creditcard | 284,807 | 30 | 99% |
| Airlines | 539,383 | 7 | 55% |
| Colon | 5,100,000 | 62 | 50% |
| HEPMASS | 10,500,000 | 28 | 50% |
Synthetic dataset
The make_classification method in the scikit-learn library is a mechanism for creating random synthetic data with a desired number of classes, samples, and features. n_redundant is responsible for generating linear combinations of informative features, weights sets the sample distribution across classes to introduce imbalance, and flip_y alters the class of a specified fraction of samples at random, introducing noise and increasing the complexity of the classification task.
Experiment design
Using real-world data, three experiments were designed to evaluate classification performance and execution time of LR and FBLR: (a) experiment on HEPMASS data with multiple performance metrics (b) a single-run experiment without regularization on OpenML datasets and (c) an experiment incorporating regularization through various parameters on OpenML datasets. Optimizing hyperparameters is crucial to improve the model’s classification performance. We employed the grid search cross-validation (GridSearchCV) method in scikit-learn to find the best models for LR and FBLR, specifically to analyze the impact of regularization on accuracy metrics and execution time.
We also examined the alignment between theoretical computational complexity and practical execution times on synthetic datasets, as these allow for greater control over the data.
Performance metrics
There exist several performance metrics. Accuracy measures the proportion of true results among all samples, providing an overall view of classification accuracy.
where TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives, and FN is the number of false negatives.
Precision measures the proportion of TP in all positive predictions, recall measures the proportion of actual positives that are correctly identified, and F1-score is the harmonic mean of precision and recall.
The area under the curve (AUC) is determined by plotting the true positive rate (TPR) vs. the false positive rate (FPR) at various thresholds and calculating the area beneath this curve.
Impact of solver selection on LR performance
The LogisticRegression class in scikit-learn employs several optimization methods (see Table 1), each tailored for different regularizers, data sizes, and computational needs. However, this leads to differences in execution time and accuracy across the solvers. As seen in Table 4, the execution time of Logistic Regression in scikit-learn varies significantly (from 3.575 to 99.339 s). The Newton-CG and LIBLINEAR solvers demonstrate good accuracy, while the limited-memory Broyden-Fletcher-Goldfarb-Shanno (LFBGS) algorithm, stochastic average gradient (SAG), and stochastic average gradient descent (SAGA) have lower accuracy due to inadequate default iteration limits. It is important to note that in this experiment, we did not use GridSearchCV; instead, each solver was executed individually with its default parameters.
| Solver | Penalty | Time (s) | Accuracy |
|---|---|---|---|
| Newton-CG | 6.7949 | 0.6949 | |
| Newton-CG | No regularization | 5.5673 | 0.6949 |
| LBFGS | 59.4638 | 0.6211 | |
| LBFGS | No regularization | 55.8338 | 0.6290 |
| LIBLINEAR | 39.889 | 0.6949 | |
| LIBLINEAR | 3.5751 | 0.6935 | |
| SAG | 42.6379 | 0.5819 | |
| SAG | No regularization | 42.5621 | 0.5820 |
| SAGA | 99.0867 | 0.5821 | |
| SAGA | 85.0862 | 0.5821 | |
| SAGA | ElasticNet ( ) | 99.3389 | 0.5821 |
| SAGA | No regularization | 85.9067 | 0.5821 |
For the LR implementation, each solver given in Table 1 has different computational complexity, some being quite efficient, like LIBLINEAR, but the required number of iterations is much larger than our method (see Table 2). The execution time of the proposed FBLR method remains tightly bounded (from to s, with an average of s) as the penalty (regularization) varies (see Table 5). This demonstrates the efficiency of our minimization scheme, which is relatively unaffected by the choice of regularizer compared to solvers used within the LR (Table 4).
| Time (s) | Accuracy | |||
|---|---|---|---|---|
| 0 | 0 | 0.001 | 0.2094 | 0.6951 |
| 0 | 0.5 | 0.001 | 0.2653 | 0.6950 |
| 0 | 1 | 0.001 | 0.2447 | 0.6948 |
| 0 | 1.5 | 0.001 | 0.2380 | 0.6950 |
| 0 | 2 | 0.001 | 0.1695 | 0.6949 |
| 1 | 0 | 0.001 | 0.2558 | 0.6950 |
| 1 | 0.5 | 0.001 | 0.2508 | 0.6948 |
| 1 | 1 | 0.001 | 0.2470 | 0.6948 |
| 1 | 1.5 | 0.001 | 0.2550 | 0.6948 |
| 1 | 2 | 0.001 | 0.2688 | 0.6949 |
| 2 | 0 | 0.001 | 0.2602 | 0.6947 |
| 2 | 0.5 | 0.001 | 0.2690 | 0.6948 |
| 2 | 1 | 0.001 | 0.2721 | 0.6947 |
| 2 | 1.5 | 0.001 | 0.2685 | 0.6947 |
| 2 | 2 | 0.001 | 0.2649 | 0.6947 |
We observed that specific solvers within scikit-learn, like LIBLINEAR, lack CPU-level parallelization support, whereas our approach, leveraging NumPy, enables parallelism through scikit-learn’s inherent parallel capabilities. We suggest that scikit-learn developers consider adopting a single NumPy-based solver to simplify maintenance and automatically benefit from NumPy improvements.
Experimental results
For the experiments, we used the real-world data in Table 3 and synthetic data created with make_classification method in the scikit-learn. Real-world data is divided into training data and test data.
Experiments on real-world datasets
Table 6 presents the performance metrics, while Fig. 1 shows the receiver operating characteristic (ROC) curves for LR and FBLR with default parameters on the HEPMASS dataset. In LR, we used the LIBLINEAR solver for faster execution and set the maximum number of iterations to 250 to ensure high accuracy for a fair comparison. We use a single thread, even though FBLR can run with multiple threads, while LR with LIBLINEAR cannot. Experiments were run 10 times to compare LR and FBLR, showing that all metrics evaluated had an accuracy loss not exceeding 0.005, while speedup is obtained.
| Metric | Train | Test | ||
|---|---|---|---|---|
| LR | FBLR | LR | FBLR | |
| Accuracy | 0.83686 | 0.83583 | 0.83646 | 0.83553 |
| Recall | 0.83588 | 0.83124 | 0.83562 | 0.83104 |
| Precision | 0.83759 | 0.83901 | 0.83708 | 0.83863 |
| F1-Score | 0.83673 | 0.83511 | 0.83635 | 0.83481 |
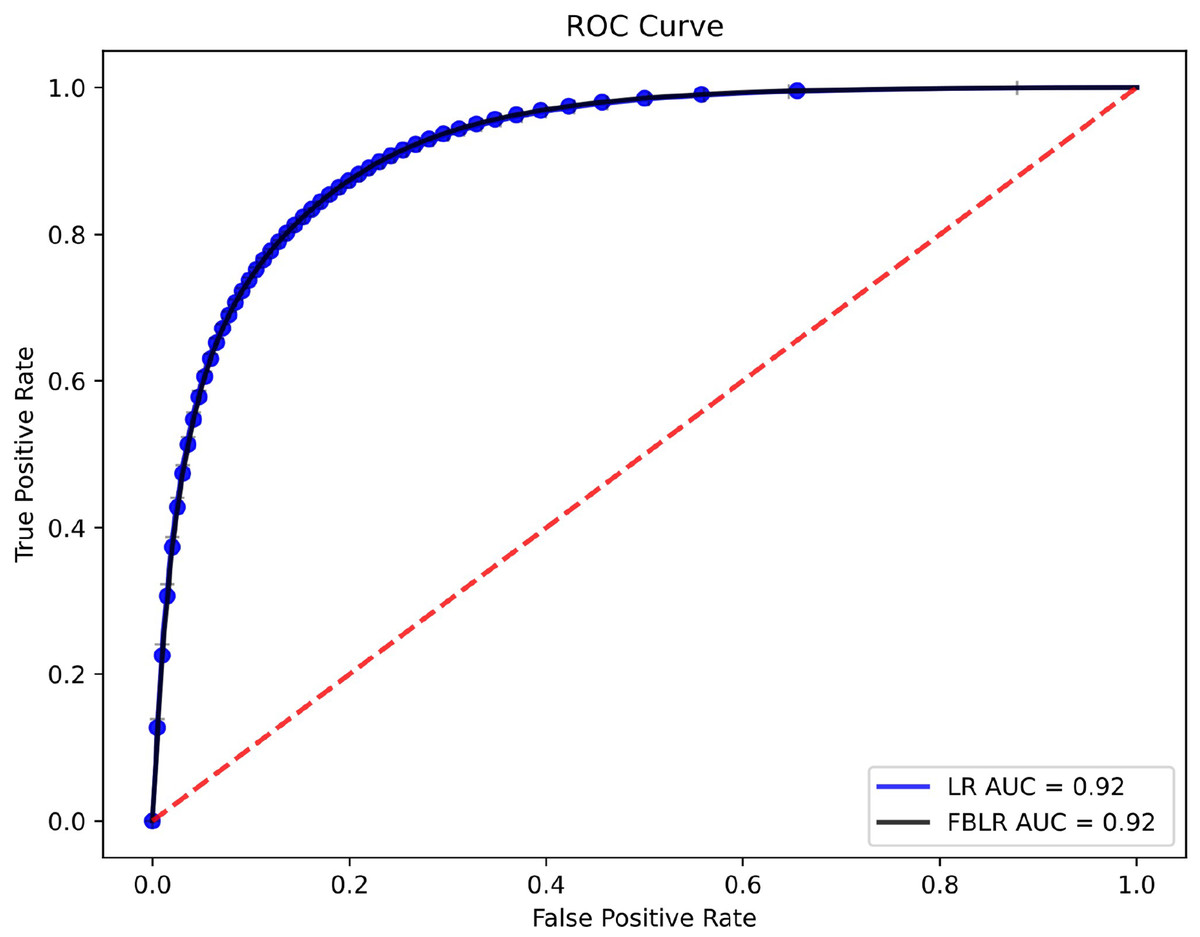
Figure 1: ROC curves and AUC values of LR and FBLR on HEPMASS dataset.
{kind=link}
LR is powered by LIBLINEAR, a highly efficient C/C++ library designed for large-scale linear classification, among other optimized solvers (see Table 1). On the other hand, the proposed FBLR method relies solely on the NumPy package (with openblas64 as the backbone), a core numerical library of Python. This approach ensures that FBLR takes full advantage of NumPy’s efficient handling of array operations and integration with the basic linear algebra subprograms (BLAS)2 .
In Table 7, we give the comparison of LR and FBLR for OpenML datasets in terms of accuracy, time (in seconds), and speedup (LR Time/FBLR Time). No regularization is used in these experiments. In LR, we set LIBLINEAR as a solver parameter and None as a penalty parameter are chosen, while for the other parameters, default values are used. Table 7 gives the significant execution time improvements obtained by comparing FBLR to LR. Our method achieves training times up to times faster, on average, an order of magnitude faster than LR.
| Filename | LR ACC | FBLR ACC | LR time (s) | FBLR time (s) | Speedup |
|---|---|---|---|---|---|
| Kits | 0.5700 | 0.5633 | 4.5378 | 0.6795 | 6.6780 |
| Road-safety | 0.6935 | 0.6956 | 3.7074 | 0.1517 | 24.4337 |
| Creditcard | 0.9991 | 0.9990 | 3.4729 | 0.2766 | 12.5530 |
| Airlines2 | 0.5965 | 0.5939 | 5.0756 | 0.1051 | 48.3072 |
| Colon | 0.9740 | 0.9680 | 10.6571 | 1.0858 | 9.8149 |
In Table 8, we compare regularized LR and regularized FBLR using GridSearchCV. We used the grid search cross-validation in scikit-learn to find the best models (by searching various parameters) to compare LR and our FBLR method. It is worth mentioning that experimenting with a broader range of parameter combinations could improve both methods’ generalization and accuracy. Nonetheless, as our primary objective was to compare the speed of the methods, we maintained an equal number of experiments for consistency. In GridSearchCV, 5-folds are used. It assesses every combination of parameter values to identify the most effective combination, yielding the best classifier. Due to memory limitations in the experimental setup, results for the kits dataset could not be included for the LR algorithm in Table 8 while FBLR is able to process the kits dataset.
| Filename | LR ACC | FBLR ACC | LR time (s) | FBLR time (s) | Speedup |
|---|---|---|---|---|---|
| Kits | – | 0.5667 | – | 18,761.8684 | – |
| Road-safety | 0.6949 | 0.6951 | 191.0991 | 5.8685 | 32.56 |
| Creditcard | 0.9992 | 0.9990 | 49.9478 | 11.1041 | 4.5 |
| Airlines2 | 0.5965 | 0.5956 | 92.7151 | 5.9504 | 15.58 |
| Colon | 0.9740 | 0.9740 | 145.2604 | 77.7610 | 1.87 |
Table 8 presents the best accuracies and corresponding execution times and speedups for LR and FBLR on 5 OpenML datasets. For LR, we used the solvers (‘lbfgs’, ‘newton-cg’, ‘liblinear’, ‘sag’, ‘saga’) and their penalties (‘l1’, ‘l2’, ‘elasticnet’, None) as GridSearchCV search parameters. As detailed in Table 1, specific solvers may not support certain penalties, so we combine solvers and penalties in GridSearchCV accordingly. To have an equal number of experiments, we limited the FBLR parameters within a specific range and tested 12 combinations. In particular, the parameter settings for FBLR in experiments were set as follows: the norm of -norm, , was varied over the values [0, 0.5, 1, 2] and the -norm regularization coefficient ( ) over the values [0, 1, 2].
The proposed FBLR method is designed to prioritize computational efficiency while maintaining accuracy. We employ SVD for low-rank approximation, and with a high energy percentile (99.9999), it retains significant information. Our novel second-order Soft-Plus approximation provides a good, though not exact, fit, enhancing numerical minimization efficiency and reducing required iterations ( ), with minimal potential accuracy loss. If desired, the weight vector from FBLR can be fine-tuned with an efficient Logistic Regression method in just a few iterations for a precise result.
Experiments on synthetic dataset
Recall that the computational complexity of the proposed FBLR method is when regularization is applied and without regularization. Here, denotes the number of rows, denotes the number of features, denotes the number of iterations, and K denotes the maximum number of iterations. When , the expression simplifies to , given that , where iterates up to a maximum of K. Therefore, computational complexity without regularization becomes . In accordance, Fig. 2 illustrates that the execution time of FBLR scales linearly with and exhibits a near-quadratic growth with respect to . Note that we analyzed the theoretical and computational complexity with respect to practical execution times on synthetic datasets since we have more control over synthetic data.
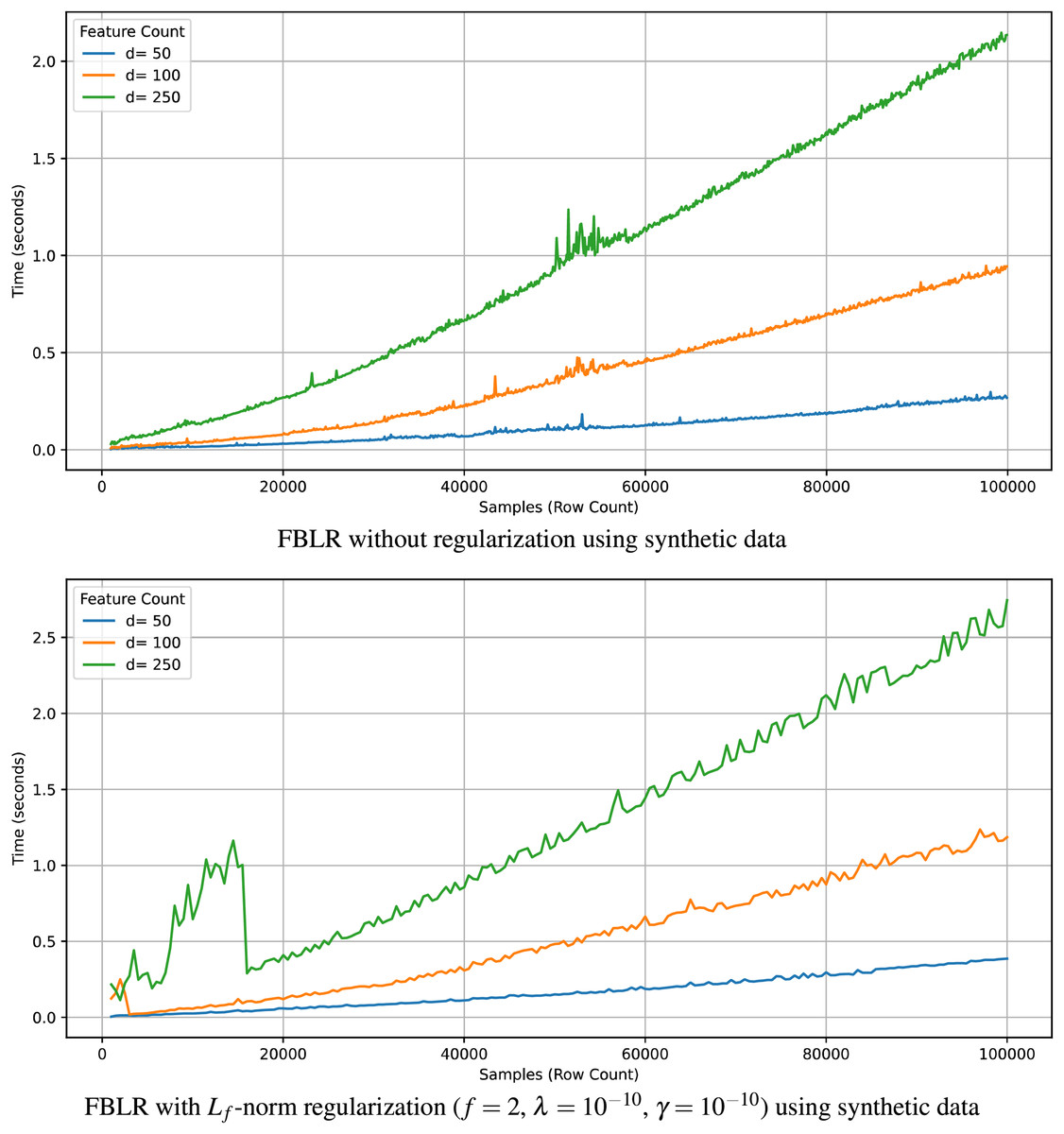
Figure 2: Execution time of FBLR with respect to and using synthetic data.
{kind=link}
Visualization of regularization paths presents change of feature coefficients as the regularization parameter changes. When coefficients of features drop to zero corresponding feature is removed. Figure 3 shows regularization paths for coefficients of the proposed FBLR method under -norm regularization. It illustrates the effect of -norm regularization in promoting sparsity within the model’s parameters ( to ). Sharpness in -norm regularization paths and the reduction of weight coefficients to demonstrate the effectiveness of the proposed -norm regularizer in promoting sparsity for . Note that, the intercept term, , remains unpenalized and almost constant across varying regularization levels determined by the parameter. Applying regularization without penalizing the intercept is one strong feature of the proposed FBLR method which is not directly supported by LR. In scikit-learn, non-penalizing the intercept requires non-trivial parameter tweaking and also very data dependent.
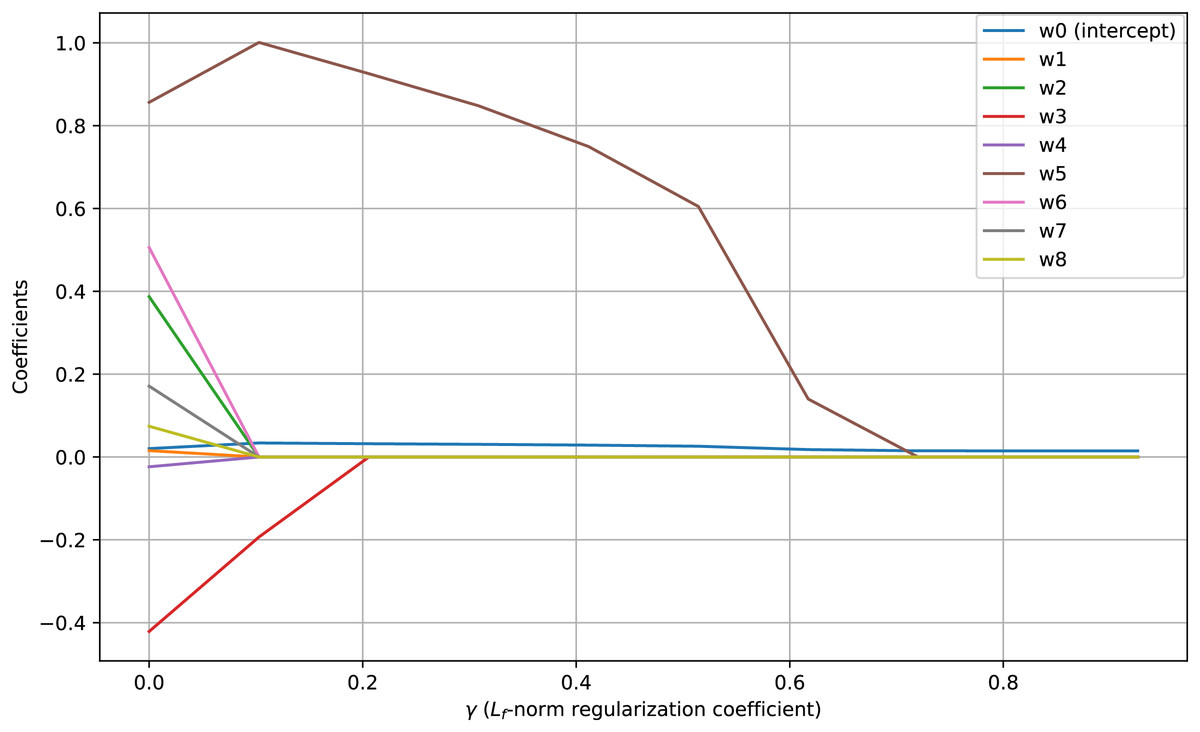
Figure 3: -norm paths using synthetic data which contains 10K samples with seven features and an intercept.
Feature is a linear combination of feature and , and feature is correlated with feature .{kind=link}
Conclusion and discussion
This study presents a novel approach, namely fast binary logistic regression (FBLR), to enhance the training efficiency of binary logistic regression. FBLR reduces training times, achieving speeds that are, on average, an order of magnitude faster than those of scikit-learn’s logistic regression, courtesy of the efficient numerical minimizer we developed. Moreover, unlike scikit-learn’s logistic regression, which utilizes multiple solvers, we propose a single, efficient solver that incorporates a second-order accurate Soft-Plus approximation and flexible -norm regularizer. This approach supports various weight penalties, thereby enhancing the training process for versatile models. Compared to scikit-learn, our approach relies on a single solver, simplifying the code and improving maintainability.
Furthermore, we have devised a low-rank approximation strategy to address collinearity among features. Our low-rank approach harnesses randomized SVD for high-dimensional feature sets and also a novel SVD with row reduction (SVD-RR) approach, tailored specifically for large datasets containing numerous rows. For smaller to moderate-sized datasets, we just employ truncated SVD. Also, we introduce an innovative strategy to determine the optimal transition from truncated SVD to randomized SVD. To mitigate the dominance of overly large eigenvalues, the logarithm of the eigenvalues was employed to establish the rank, , suitable for low-rank approximation. The achieved computational efficiency is crucial for crafting generalized logistic regression models, enabling iterative parameter tuning to achieve an optimal balance between bias and variance.
In addition to existing computational efficiencies, further acceleration can be achieved by applying stochastic gradient descent or mini-batch methods for faster approximate gradient evaluation. Also, parallel computing frameworks such as CuPy, Numba, PyCUDA, or PyTorch can be utilized. Additionally, deploying a caching strategy for SVD and storing the compact diagonal sparse matrix and the dense square matrix in a dictionary can enable efficient reuse. Matrix can be computed using Eq. (41) once diagonal matrix and square matrix are retrieved using the hash code of input data . This is particularly useful for repeated training sessions when performing best-parameter searches in scikit-learn. Originally conceived for binary labels, our method possesses sufficient flexibility to accommodate multinomial classifications using the inherent functions provided by scikit-learn. Nonetheless, our approach offers no advantage over scikit-learn’s logistic regression for handling missing values. Also, similar to scikit-learn’s logistic regression, our method is limited to handling linearly separable data. The matrix-vector form of our cost function, resembling Ridge Regression, allows our method to incorporate kernel methods like Kernel Ridge Regression, enabling nonlinear data handling while supporting linear data in its current form. Such kernel method extension can benefit from techniques such as Random Fourier Features (RFF) (Rahimi & Recht, 2007) to increase execution time performance further.
Appendix
Approximation of soft-plus
The quadratic approximation of at is defined as:
(23) where is a proxy constant for and , , and are all constant coefficients.
First, we determine by substituting to as in Eq. (24):
(24)
(25)
Then, for , we have and using Maclaurin series. Next, for , to find the value of and , we compute the equation at and
(26)
(27)
By subtracting the Eq. (27) from the Eq. (26) we obtain
(28)
Note that,
(29)
Then, we obtain by plugging Eq. (29) into Eq. (28).
Finally plugging and into Eq. (26), we obtain
(30) which leads to the below approximation at point :
(31)
Note that our quadratic Soft-Plus approximation is specifically designed for minimizing and differs from second-order Taylor series-based approximation. Compared to the second-order Taylor approximation, our Soft-Plus approximation more effectively adapts to the shape of the Soft-Plus function, being exact at both the approximation point and the origin. This provides a more accurate quadratic approximation for minimizing the cost function. The second-order Taylor approximation of Eq. (23) at is given as below which is different than our approximation:
(32)
Empirical quadratic approximation of soft-plus
The employed quadratic approximation of the Soft-Plus function given in Eq. (23) at point and are shown in Fig. 4. These approximations are exact at both the approximated point ( ) and the origin ( ), with high accuracy between them, but become less accurate outside this range. In contrast, the second-order Taylor approximation only guarantees exactness at the approximation point .
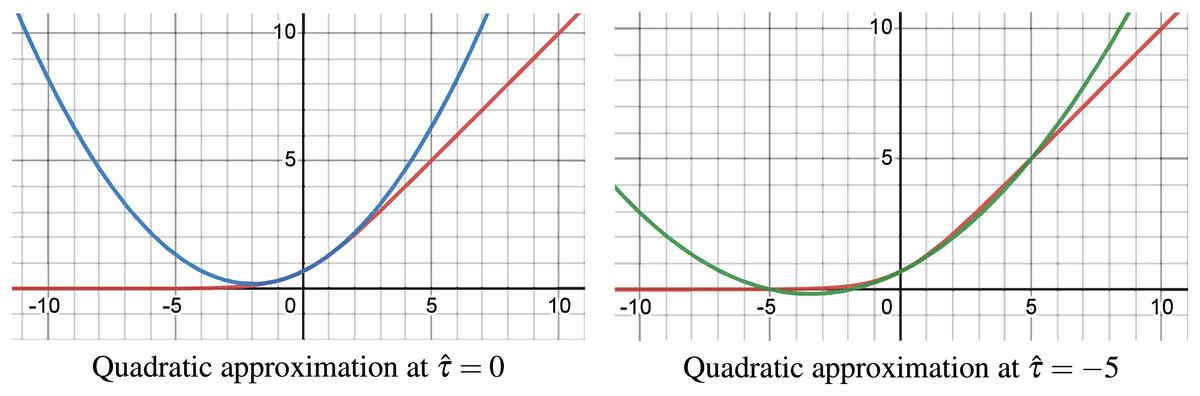
Figure 4: Quadratic approximation of Soft-Plus at and .
{kind=link}
Approximation Of -norm
We also approximated smooth quadratically at a point where is defined as a constant. Here, is a proxy constant for . Quadratic approximation of smooth function is:
(33)
Optimization problems with terms are combinatorial, requiring discrete decisions to minimize non-zero elements, making direct approaches computationally impractical for large-scale issues. Smooth approximations are employed as a solution, substituting the with a continuous, differentiable function that mimics the counting of non-zero elements. Similarly, our -norm approximation smoothly mirrors the -norm for and -norm for , as illustrated in Fig. 5. With our smooth approximation, as gets smaller approximation gets better (default ).
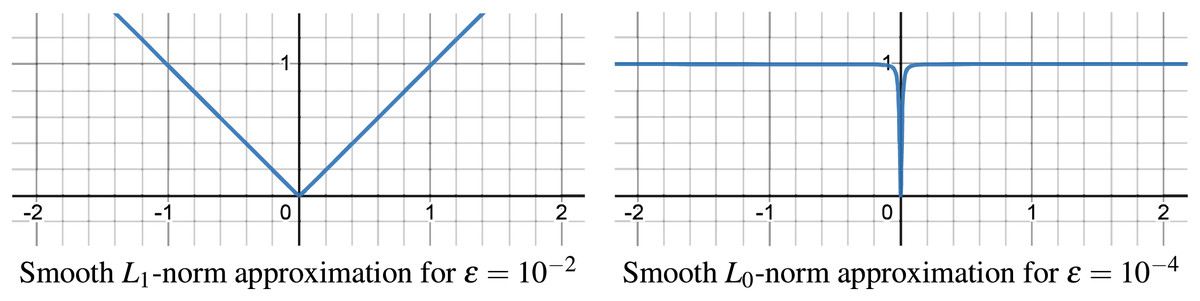
Figure 5: Smooth approximation of -norm for -norm and -norm.
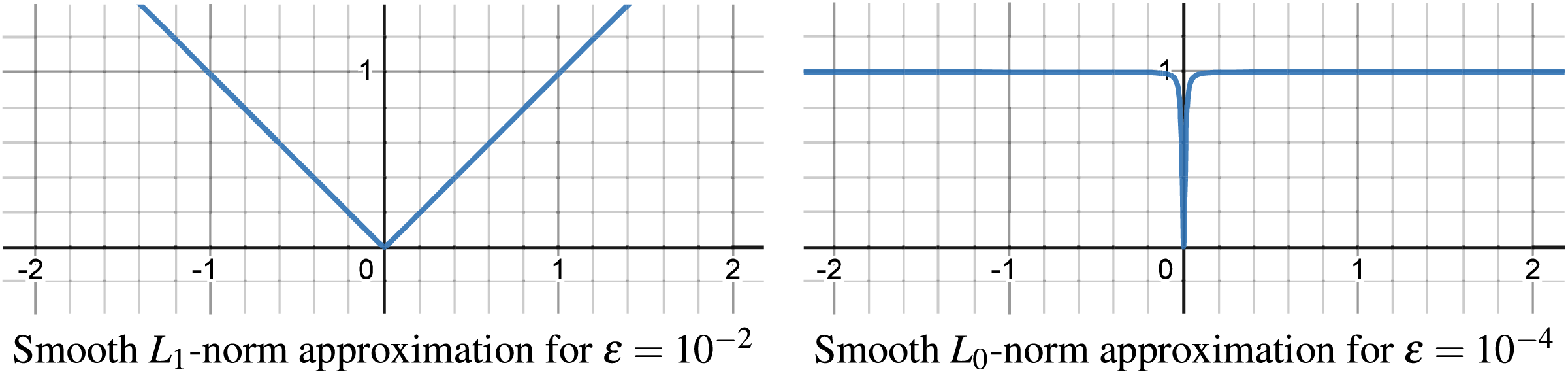{kind=link}
Despite the -norm and -norm approximation in Fig. 5 being precise even for relatively large values ( and ), its direct use is unsuitable within our cost function, leading us to employ a quadratic approximation over this smooth approximation. The quadratic approximations of the -norm for -norm ( ) and for -norm ( ) are depicted in Fig. 6.
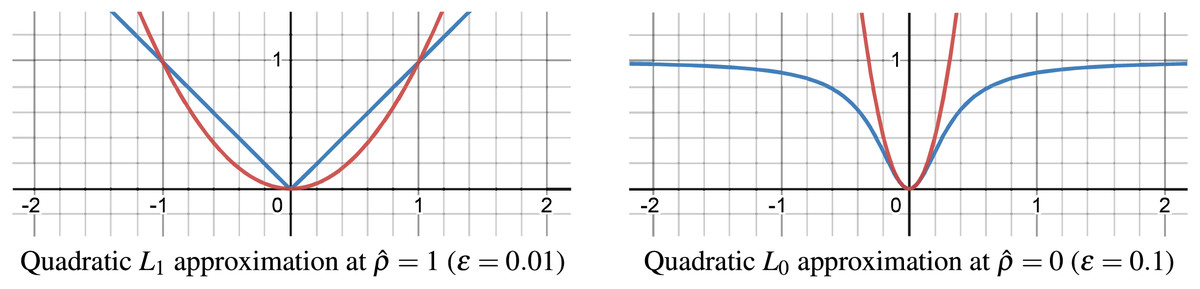
Figure 6: Quadratic approximation of -norm for -norm and -norm.
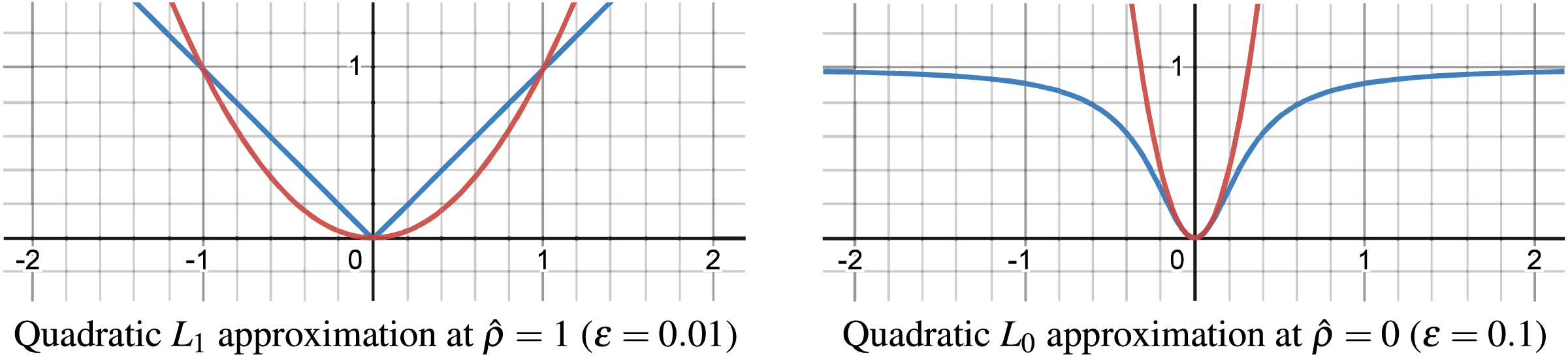{kind=link}
SVD with row reduction
In the case of a large data matrix , truncated SVD is computationally demanding due to its complexity . In scenarios where becomes large, the computational burden of applying SVD is mitigated by utilizing randomized SVD (Halko, Martinsson & Tropp, 2010; Halko et al., 2011; Martinsson et al., 2010). However, this method is less effective in dealing with cases where is large. In such instances, a large subset of the matrix can sufficiently mimic the statistical properties of the full data set. Hence, we sub-sample matrix to create , consisting of rows. This sub-sampling involves randomly or sequentially selecting rows from where we just sub-sampled the first rows. Note that one can employ a sampling mechanism proposed in Menon & Elkan (2011), such as the Drineas, Kannan, and Mahoney method, to obtain better statistical guarantees for the sampled subset. We use a simple sampling mechanism where we set to a sufficiently large value, , ensuring ’s statistical preservation and reducing computational demands for , thus outperforming direct SVD on the full matrix. However, returned by SVD applied on is now instead of and also requires normalization. To address these issues, we define the covariance matrices for the full matrix and the subsampled matrix as follows:
(34)
(35)
Assuming , a large subset of , reflects the dataset’s statistics, their covariances are nearly equal ( ):
(36)
Applying the definition of SVD to both matrices, represented as and respectively, the aforementioned equation can be reformulated as follows:
(37)
The above equation can be simplified to:
(38) where and are eliminated since and . We assume the same eigenvectors for both data matrices:
(39)
Multiplying both sides of the above equation by from left and right and applying simple algebraic simplifications:
(40)
Finally, to compute , we use SVD of given as , then we multiply both sides by , leading to:
(41)
Thereby, we efficiently compute and using truncated SVD on the sub-sampled smaller data matrix and then we also efficiently compute matrix using Eq. (41), matrix using Eq. (40), and matrix using Eq. (39). Thus, proposed SVD-RR enables computing SVD of a large data matrix .
Randomized SVD
For handling a large matrix , where truncated SVD may become computationally slow or unfeasible, the utilization of randomized SVD offers a viable alternative, as described in works by Martinsson et al. (2010) and Halko, Martinsson & Tropp (2010), Halko et al. (2011). Randomized SVD have many uses in machine learning with datasets that are too large to be stored in memory (Halko et al., 2011). In comparison to classic SVD algorithms, randomized techniques for computing low-rank approximations are frequently faster and, unexpectedly, more robust (Halko, Martinsson & Tropp, 2010). Thus, for large datasets where truncated SVD is slow or impractical, so using randomized SVD is suggested by Martinsson et al. (2010).
A critical decision is to determine when to use randomized SVD instead of truncated SVD, taking into account the number of rows, , and the number of features, . To address this issue, we propose to leverage the computational complexities of both approaches as a criterion for decision-making. Computational complexity of the truncated SVD is given as below:
(42)
Similarly, computational complexity of the randomized SVD is:
(43) where is the inherent rank of the matrix . Taking the ratio of randomized and truncated SVD and comparing it with a threshold, we obtained below decision rule (default T is ):
(44)
However, is unknown until SVD is taken. So, as a practical solution, we estimate using as shown below:
(45) where serves as the soft threshold beyond which truncated SVD may begins to exhibit slower performance as exceeds this value. If is larger than then SVD (∗) computes SVD of using SVD-RR (“SVD with Row Reduction”). Otherwise, SVD (∗) method gets the as input, uses Eq. (44) to decide to compute truncated SVD or randomized SVD of the data matrix .
Determining the rank
Finally, we developed Algorithm 3 which determines the rank ( ) using the energy-percentile ( ) and eigenvalues obtained by SVD(∗).
| 1: procedure RANK{ , ξ} |
| 2: |
| 3: CMF: Cumulative Mass Function |
| 4: |
| 5: |
| 6: return r |
| 7: end procedure |