
Enhanced related-key differential neural distinguishers for SIMON and SIMECK block ciphers
- Published
- Accepted
- Received
- Academic Editor
- Kübra Seyhan
- Subject Areas
- Artificial Intelligence, Cryptography, Security and Privacy
- Keywords
- Differential cryptanalysis, Neural distinguisher, Deep learning, SIMON, SIMECK
- Copyright
- © 2024 Wang and Wang
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. Enhanced related-key differential neural distinguishers for SIMON and SIMECK block ciphers. PeerJ Computer Science 10:e2566 https://doi.org/10.7717/peerj-cs.2566
Abstract
At CRYPTO 2019, Gohr pioneered the application of deep learning to differential cryptanalysis and successfully attacked the 11-round NSA block cipher Speck32/64 with a 7-round and an 8-round single-key differential neural distinguisher. Subsequently, Lu et al. (DOI 10.1093/comjnl/bxac195) presented the improved related-key differential neural distinguishers against the SIMON and SIMECK. Following this work, we provide a framework to construct the enhanced related-key differential neural distinguisher for SIMON and SIMECK. In order to select input differences efficiently, we introduce a method that leverages weighted bias scores to approximate the suitability of various input differences. Building on the principles of the basic related-key differential neural distinguisher, we further propose an improved scheme to construct the enhanced related-key differential neural distinguisher by utilizing two input differences, and obtain superior accuracy than Lu et al. for both SIMON and SIMECK. Specifically, our meticulous selection of input differences yields significant accuracy improvements of 3% and 1.9% for the 12-round and 13-round basic related-key differential neural distinguishers of SIMON32/64. Moreover, our enhanced related-key differential neural distinguishers surpass the basic related-key differential neural distinguishers. For 13-round SIMON32/64, 13-round SIMON48/96, and 14-round SIMON64/128, the accuracy of their related-key differential neural distinguishers increases from 0.545, 0.650, and 0.580 to 0.567, 0.696, and 0.618, respectively. For 15-round SIMECK32/64, 19-round SIMECK48/96, and 22-round SIMECK64/128, the accuracy of their neural distinguishers is improved from 0.547, 0.516, and 0.519 to 0.568, 0.523, and 0.526, respectively.
Introduction
In recent years, with the wide application of wireless sensor networks (WSN) and radio frequency identification (RFID) technology in various industries, the data security problem of these resource-constrained devices have become more and more prominent. As a cryptographic solution that can achieve a good balance between security and performance under limited resources, lightweight block ciphers are widely used to protect data security in various resource-constrained devices. The security of block ciphers is closely related to the security of data. In this context, evaluating the security properties of these ciphers has become a popular research topic in the field of computer science and cryptography. Among many cryptanalysis techniques, differential cryptanalysis, proposed by Biham & Shamir (1991b), is one of the most commonly used methods for evaluating the security of block ciphers. This technique focuses on the propagation of plaintext differences during the encryption.
In traditional differential cryptanalysis, the core task of differential cryptanalysis is to find a differential characteristic with high probability. Initially, this task was achieved by manual derivation, which required a lot of effort and time. At EUROCRYPT 1994, Matsui (1994) presented a branch-and-bound method for this task, which replaced manual derivation with automated search techniques for the first time. However, for the block ciphers with large sizes, this method is insufficient to provide useful differential characteristics. This prompts cryptographers to adopt more efficient automated search tools for searching the differential characteristic with high probability, including mixed integer linear programming (MILP) (Sun et al., 2014; Bellini et al., 2023a; Mouha et al., 2012), constraint programming (CP) (Gerault, Minier & Solnon, 2016; Sun et al., 2017), and Boolean satisfiability problem or satisfiability modulo theories (SAT/SMT) (Sun et al., 2017; Lafitte, 2018).
In recent years, with the rapid development of deep learning, cryptanalysts have begun to explore how to harness its power for differential cryptanalysis. At CRYPTO 2019, Gohr (2019) constructed an 8-round differential neural distinguishers by leveraging neural networks to learn the differential properties of block ciphers SPECK32/64 and successfully carried out an 11-round key recovery attack. This pioneering research significantly accelerated the integration of deep learning and differential cryptanalysis. Since this study, the differential neural distinguisher has been widely applied to various block ciphers in single-key and related-key scenarios, including but not limited to SIMON (Bao et al., 2022; Lu et al., 2024; Bellini et al., 2023b), SIMECK (Zhang et al., 2023; Lu et al., 2024), PRESENT (Jain, Kohli & Mishra, 2020; Bellini et al., 2023b; Zhang, Wang & Chen, 2023), GIFT (Shen et al., 2024), ASCON (Shen et al., 2024), and others. In most of these works, the focus is only on the single-key neural distinguishers, while SIMON and SIMECK also focus on the related-key differential neural distinguishers. In this article, we continue to optimize the related-key differential neural distinguishers for SIMON and SIMECK.
So far, there are many studies exploring the differential neural distinguishers for SIMON and SIMECK ciphers, such as Bao et al. (2022), Zhang et al. (2023), Wang et al. (2022), Seong et al. (2022), Gohr, Leander & Neumann (2022), Lyu, Tu & Zhang (2022), Lu et al. (2024). However, most of them focused on the single-key scenario, until the research of Lu et al. (2024) broke this trend. They not only improved the accuracy of their single-key differential neural distinguishers by using the enhanced data format (defined in Eq. (10)), but also constructed the related-key differential neural distinguishers for them. The experimental results show that the related-key differential neural distinguishers outperforms the single-key differential neural distinguishers in terms of the number of analyzed rounds and accuracy. In the single-key scenario, Lu et al. (2024) exhaustively evaluated the input differences with Hamming weights of 1, 2, and 3 by training a differential neural distinguisher for each difference. However, for the related-key scenario, this task has not been explored in depth due to the huge number of input differences that need to be evaluated. Even for the smallest variants SIMON32/64 and SIMECK32/64, the number of input differences with Hamming weights of 1, 2, and 3 already reaches about 200 million. Therefore, it is impractical to train a neural distinguisher for each difference. In this article, we aim to further address this challenge.
Our contributions
In this article, we first present a framework to construct the basic related-key differential neural distinguishers for SIMON and SIMECK. This framework is comprised of five components: differences selection, sample generation, network architecture, distinguisher training, and distinguisher evaluation. For comparison with the baseline work of Lu et al. (2024), we keep sample generation, network architecture, distinguisher training, and distinguisher evaluation as in Lu et al. (2024). Our attention is mainly on differences selection. We provide a method for approximately assessing the suitability of different input differences with weighted bias scores instead of training a neural distinguisher for every input difference as Lu et al. (2024). This allows us to approximate the applicability of the different differences without training the model, which can significantly accelerates the process of differences selection. Our meticulous selection of the input difference can make the accuracy of the basic related-key differential neural distinguisher match or surpass previous results. In particular, the accuracy for the 12-round and 13-round distinguishers of SIMON32/64 is improved from 0.648 and 0.526 to 0.678 and 0.545, respectively, as shown in Table 1.
| Cipher | Round | Model | Acc | TPR | TNR | Source |
|---|---|---|---|---|---|---|
| SIMON32/64 | 12 | 0.648 | 0.652 | 0.644 | Lu et al. (2024) | |
| 0.678 | 0.685 | 0.671 | “Basic Related-Key Differential Neural Distinguishers” | |||
| 0.740 | 0.729 | 0.750 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| 13 | 0.526 | 0.544 | 0.508 | Lu et al. (2024) | ||
| 0.545 | 0.537 | 0.552 | “Basic Related-Key Differential Neural Distinguishers” | |||
| 0.567 | 0.564 | 0.570 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| SIMON48/96 | 12 | 0.993 | 0.999 | 0.986 | “Basic Related-Key Differential Neural Distinguishers” | |
| 0.997 | 0.998 | 0.996 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| 13 | 0.650 | 0.660 | 0.640 | “Basic Related-Key Differential Neural Distinguishers” | ||
| 0.696 | 0.698 | 0.695 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| SIMON64/128 | 13 | 0.840 | 0.839 | 0.841 | Lu et al. (2024) | |
| 0.916 | 0.910 | 0.922 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| 14 | 0.579 | 0.589 | 0.568 | Lu et al. (2024) | ||
| 0.618 | 0.596 | 0.639 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| SIMECK32/64 | 14 | 0.668 | 0.643 | 0.693 | Lu et al. (2024) | |
| 0.730 | 0.722 | 0.738 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| 15 | 0.547 | 0.517 | 0.576 | Lu et al. (2024) | ||
| 0.568 | 0.553 | 0.582 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| SIMECK48/96 | 18 | 0.551 | 0.456 | 0.646 | “Basic Related-Key Differential Neural Distinguishers” | |
| 0.572 | 0.572 | 0.572 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| 19 | 0.516 | 0.411 | 0.611 | “Basic Related-Key Differential Neural Distinguishers” | ||
| 0.523 | 0.527 | 0.518 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| SIMECK64/128 | 21 | 0.552 | 0.425 | 0.679 | Lu et al. (2024) | |
| 0.572 | 0.580 | 0.563 | “Enhanced Related-Key Differential Neural Distinguishers” | |||
| 22 | 0.518 | 0.391 | 0.646 | Lu et al. (2024) | ||
| 0.526 | 0.523 | 0.529 | “Enhanced Related-Key Differential Neural Distinguishers” |
Note:
Acc, Accuracy; TPR, True positive rate; TNR, True negative rate. : The basic related-key differential neural distinguisher trained with a difference. : The enhanced related-key differential neural distinguisher trained using a pair of differences.
Furthermore, based on the principles of the basic related-key differential neural distinguishers, we propose an enhanced scheme that harnesses two distinct input differences to construct a more powerful related-key differential neural distinguisher for SIMON and SIMECK instead of using only one difference in the phase of sample generation.
Specifically, for the 13-round SIMON32/64, 13-round SIMON48/96, and 14-round SIMON64/128, their accuracy is raised from 0.545, 0.650, and 0.580 to 0.567, 0.696, and 0.618, respectively. Similarly, the neural distinguishers for 15-round SIMECK32/64, 19-round SIMECK48/96, and 22-round SIMECK64/128 also showed significant improvements in accuracy, rising from 0.547, 0.516, and 0.519 to 0.568, 0.523, and 0.526, respectively. All these results illustrate the effectiveness and robustness of our scheme.
Organization
“Preliminaries” commences by introducing the foundational knowledge about the related-key differential neural distinguisher. Following this, “The Framework for Developing Related-Key Differential Neural Distinguishers to SIMON and SIMECK” comprehensively explores the construction of basic and enhanced neural distinguishers for SIMON and SIMECK. Building upon this framework, “Related-Key Differential Neural Distinguishers for Round Reduced SIMON and SIMECK” constructs the improved related-key differential neural distinguishers for SIMON and SIMECK. Finally, “Conclusions and Future Work” concludes this article.
Preliminaries
In this section, we first present the pivotal notations in Table 2. Following this, we offer a succinct overview of the block ciphers SIMON and SIMECK, along with the basic concepts about related-key differential cryptanalysis and convolutional neural networks.
| Notation | Description |
|---|---|
| Circular left and right shift | |
| Bits of cyclic shift | |
| Predefined constants | |
| T | Temporary variable |
| Bit-wise XOR and AND operation | |
| Concatenation | |
| Binary field | |
| Plaintext | |
| Ciphertext | |
| Master key | |
| E, R | Encryption algorithm and rounds |
| Plaintext, key and ciphertext for round | |
| Components of the | |
| Plaintext difference | |
| Ciphertext difference | |
| Master key difference | |
| The -round input difference | |
| The -round ciphertext difference | |
| The -round key difference | |
| Activation function | |
| Input of the -th neuron | |
| Weight of the | |
| Bias of the neuron | |
| The transformation operation of SENet | |
| The squeeze operation of SENet | |
| The excitation operation of SENet | |
| The channel-wise multiplication of SENet | |
| Bias scores for rounds | |
| Approximate bias score calculated using samples for rounds | |
| -rounds weighted bias score | |
| -th ( ) ciphertext pair | |
| Cyclic learning rate for the -th epoch | |
| The parameter for calculating , defaulting to 0.0001, 0.003 and 29, respectively | |
| The parameter for L2 regularization, default 0.00001 | |
| block length and key length |
Notations
Table 2 illustrates the notations utilized in this article.
A brief description of SIMON and SIMECK ciphers
SIMON (Beaulieu et al., 2015) is a lightweight block cipher, designed by the National Security Agency (NSA) in 2013. It employs a Feistel structure, making it suitable for resource-constrained environments. In addition, it supports various block lengths and key sizes, such as SIMON32/64, SIMON48/96, and SIMON64/128, where the first number represents the block length and the second number denotes the key size. The round function of SIMON is composed of three simple operations: bit-wise XOR , bit-wise AND , and circular left shift operations, as shown in Fig. 1. The round function can be formally defined as:
(1) where , and represent the fixed rotation constants that are utilized in the circular left shift operation. For SIMON, the values of these constants are set to 1, 8, and 2, respectively. Given a master key K that comprises four key words, denoted as , the round key is generated through a linear key schedule. This process incorporates predefined constants C and a series of constants , the generation follows the scheme outlined below:
(2)
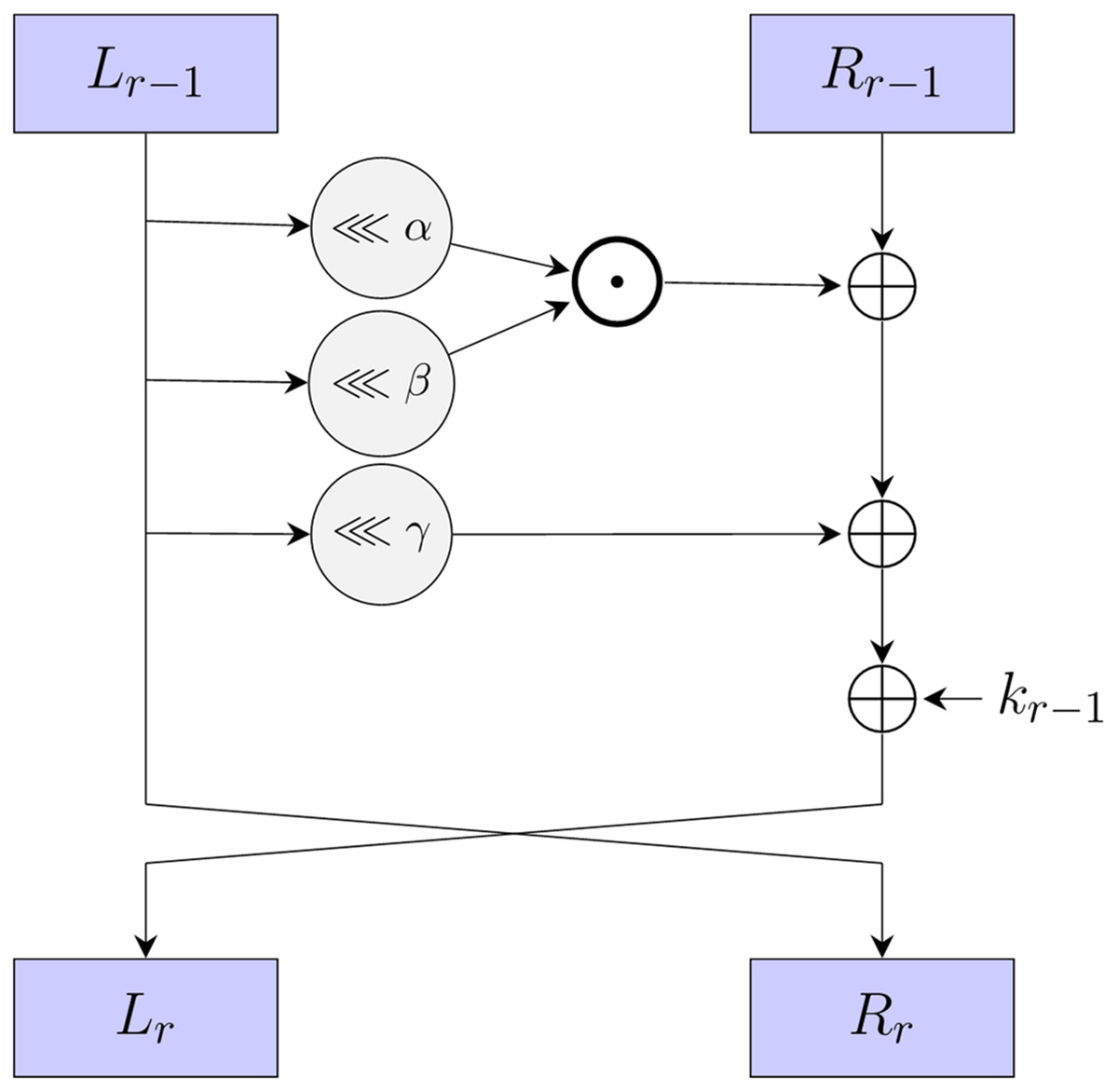
Figure 1: The round function of SIMON and SIMECK.
{kind=link}
SIMON is designed to be highly efficient in terms of both hardware and software implementations. It processes the plaintext and ciphertext blocks in a symmetric manner. Its structure and the choice of operations contribute to its resistance against common attacks like differential cryptanalysis and linear cryptanalysis. Like many lightweight block ciphers, SIMON’s simplicity may make it more susceptible to side-channel attacks, such as power analysis and timing attacks.
The SIMECK (Yang et al., 2015) cipher, presented at CHES in 2015, is a variant of the SIMON. It retains the same Feistel structure and round function as SIMON, but distinguishes itself through the values of , , and , which are set to 0, 5, and 1, respectively. In addition, SIMECK uses the round function to generate the round keys for a given master key , as explained below:
(3) where C and are the predefined constants. For more details, please refer to Yang et al. (2015).
SIMECK is a lightweight block cipher designed specifically for constrained environments. It boasts compact hardware implementations and low power consumption, making it suitable for embedded systems and IoT devices. SIMECK has fixed block size and key length, which facilitate consistent and predictable performance. SIMECK stands out for its efficiency in terms of both area and energy, as well as its resistance to common cryptographic attacks. However, it is worth noting that careful implementation is crucial to mitigate potential side-channel attack.
Related-key differential cryptanalysis
In 1990, Biham & Shamir (1991b) introduced a groundbreaking attack strategy called differential cryptanalysis. This cryptanalysis technique can distinguish the block cipher from the random permutation by studying the propagation properties of the plaintext difference throughout the encryption. Due to its simple principle and excellent efficacy, this approach quickly attracted significant attention among the cryptography community (Biham & Shamir, 1991a, 1992; Biham & Dunkelman, 2007).
In lightweight block ciphers, the key schedule holds paramount importance, as it is responsible for generating and updating the round keys. To delve into the security of this vital component, Biham (1994) proposed a pioneering related-key cryptanalysis method in 1994, which studies the security of block cipher under different keys. The related-key differential cryptanalysis method combines the principles of differential cryptanalysis and related-key cryptanalysis. It investigates differential propagation under different keys instead of the same key. The basic concepts related to block cipher and related-key differential cryptanalysis are summarized as follows.
Assuming E is the -round encryption procedure employed by a block cipher with the block length and the key length , and the plaintext, ciphertext, and master key are denoted as P, C, and K, respectively. The formalized encryption process of this block cipher can be expressed as , which indicates that the ciphertext C results from encrypting the plaintext P for rounds using the master key K. For iterative block ciphers, their encryption process is derived by repeatedly applying the round function , where represents the round key for the -th iteration, whereas denotes the input to this iteration. Consequently, the encryption process of iterative block cipher is given in Eq. (4).
(4)
Definition 1 (Plaintext Difference, Ciphertext Difference, and Key Difference. Matsui (1994)) For a block cipher, the plaintext difference of the plaintext pair is . Similarly, the ciphertext difference of the ciphertext pair is , and the key difference of the key pair is .
Definition 2 (Related-key Differential Characteristic. Jakimoski & Desmedt (2003)) Given a plaintext pair ( ) and a key pair ( ) with the difference of and , let ( ) be the cipher pair obtained by encrypting the ( ) with ( ) for i rounds, the -round related-key differential characteristic of the block cipher is ( ), where .
Definition 3 (Related-key Differential Probability. Jakimoski & Desmedt (2003)) The related-key differential probability of the block cipher with the plaintext difference , master key difference , and ciphertext difference is
(5)
where and .
Definition 4 (Hamming Weight. Wang, Wang & He (2021)) Assuming , the hamming weight of is the number of non-zero bits within its binary representation. Mathematically, it can be formulated as , where denotes the -th bit in the binary of X.
Convolutional neural network
Convolutional Neural Network (CNN), as a feed-forward neural network with convolutional structure, has been widely applied in numerous domains, including but not limited to image recognition (Chauhan, Ghanshala & Joshi, 2018), video analysis (Ullah et al., 2017), and natural language processing (Yin et al., 2017), and among others. A convolutional neural network usually consists of the input layer, convolutional layer, pooling layer, fully connected layer, and output layer. The convolutional layer is used to extract features, the pooling layer is used to achieve data dimensionality reduction through subsampling, the fully connected layer integrates the previously extracted features for tasks such as classification or regression, and the output layer is responsible for producing the final results.
LeNet-5 is a convolutional neural network designed by LeCun et al. (1998) for handwritten digit recognition, and it is one of the most representative results of the early convolutional neural network. It consists of one input layer, one output layer, two convolutional layers, two pooling layers, and two fully connected layers, as shown in Fig. 2. Its input is a image of . After two convolution and subsampling operations, this input becomes a feature map of . The convolution kernels are all with stride 1. The subsampling function used for the pooling layers is maxpooling. Then it passes through two fully connected layers with sizes of 120 and 64 to reach the output layer.
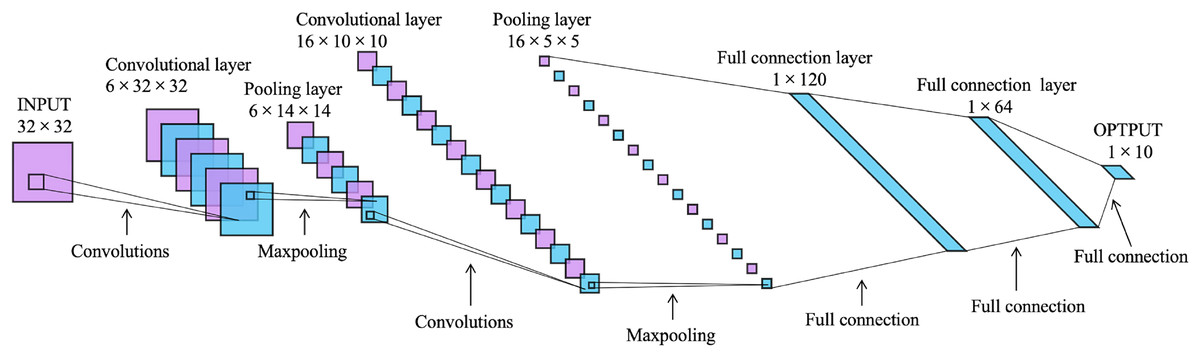
Figure 2: The architecture of LeNet-5 (LeCun et al., 1998).
{kind=link}
Later, based on LeNet-5, many improved convolutional neural networks have been proposed, such as AlexNet (Krizhevsky, Sutskever & Hinton, 2017), GoogleLeNet (Szegedy et al., 2015), ResNet (He et al., 2016), and so on. The main components used in this article are convolutional layers, activation functions, fully connected layers, as well as the advanced architectures including the Residual Network (ResNet) (He et al., 2016) and the Squeeze-and-Excitation Network (SENet) (Hu, Shen & Sun, 2018).
Convolution layer
Convolutional layers are the core component of convolutional neural networks. It is responsible for extracting features from input data through convolution operations. In a convolution operations, a convolutional kernel (also known as a filter) continuously slides over the input feature map. At each step, it calculates the sum of the product of the values at each position and takes it as the value in the corresponding position on the output feature map.
Activation function
In neural networks and deep learning, the activation function plays a crucial role in introducing nonlinear properties that enable the neural network to learn complex patterns in the data. The activation functions Sigmoid (Little, 1974) and rectified linear unit (ReLU) (Nair & Hinton, 2010) are used in this article. The Sigmoid function can map any real value to an output between 0 and 1. Therefore, it is a common choice for the output layer in binary classification problems. The ReLU function returns the input value itself for the positive inputs and zero for the negative inputs. It performs well in many deep learning tasks because of its effectiveness in mitigating the gradient vanishing problem. Their mathematical formulations are as follows:
(6)
Fully connected layer
The fully connected layer (also known as dense layer) is a fundamental element of neural networks. In this layer, every neuron establishes a connection to each neuron in the preceding layer. This connection ensures that all the outputs from the previous layer are the inputs to every neuron in the current layer. This structure allows the fully connected layer to execute a weighted combination of input features, effectively capturing the intricate relationships between them. For a single neuron in the fully connected layer, its output can be represented as , where is the total number of neurons, represents the activation function, denotes the input of the -th neuron, corresponds to the weight of the connection, and is the bias of the neuron.
Residual network
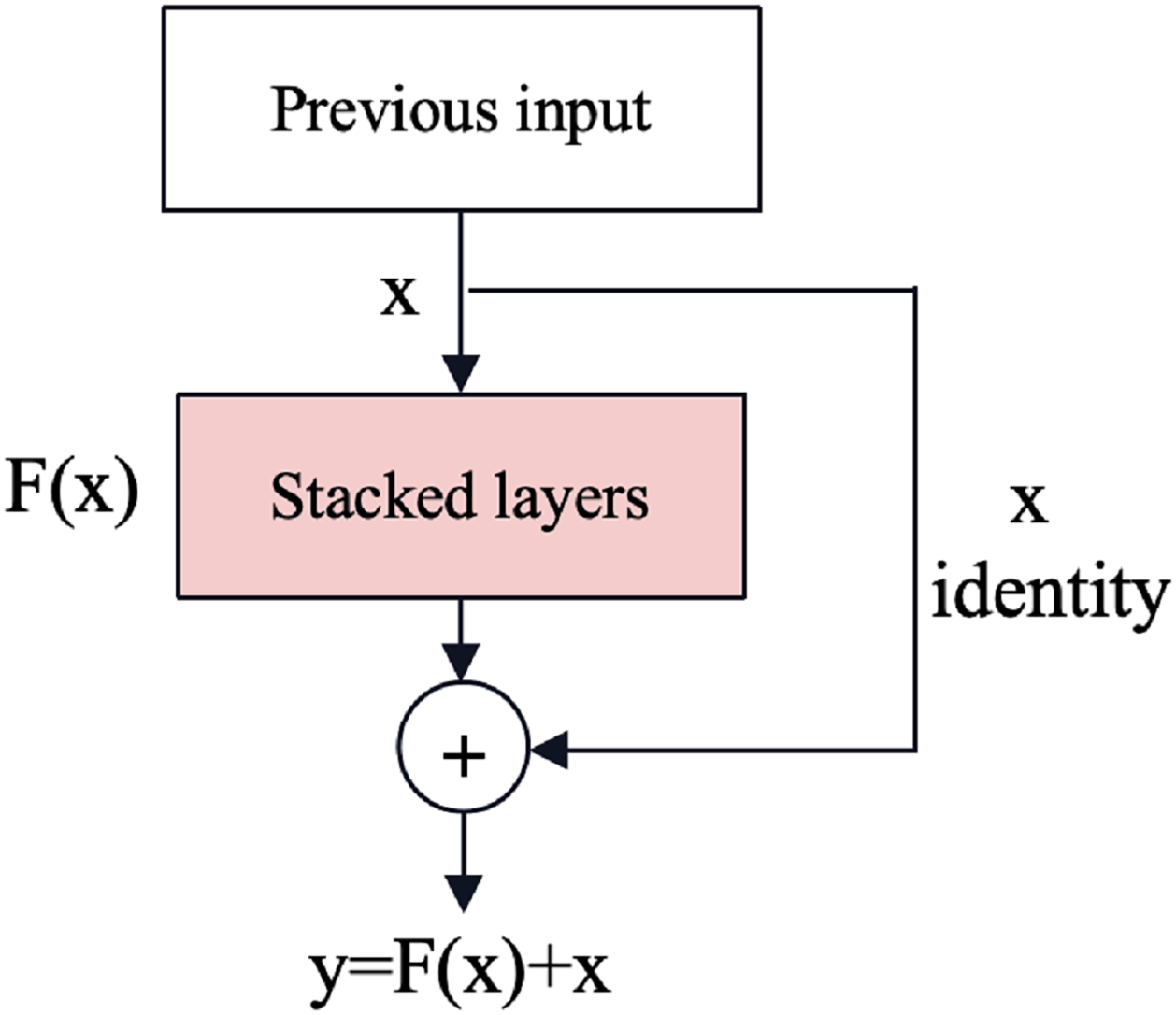
Gradient vanishing and explosion are issues in deep neural networks where gradients become extremely small or large during back-propagation, respectively, hindering effective training. The residual neural network (ResNet) (He et al., 2016) is an effective deep learning model that solves the problem of gradient vanishing and gradient explosion by introducing shortcut connections as shown in Fig. 3. Shortcut connections can mitigate these problems by providing alternative paths for gradient flow, reducing the dependency on gradients passing through all intermediate layers and improving information flow through the network.
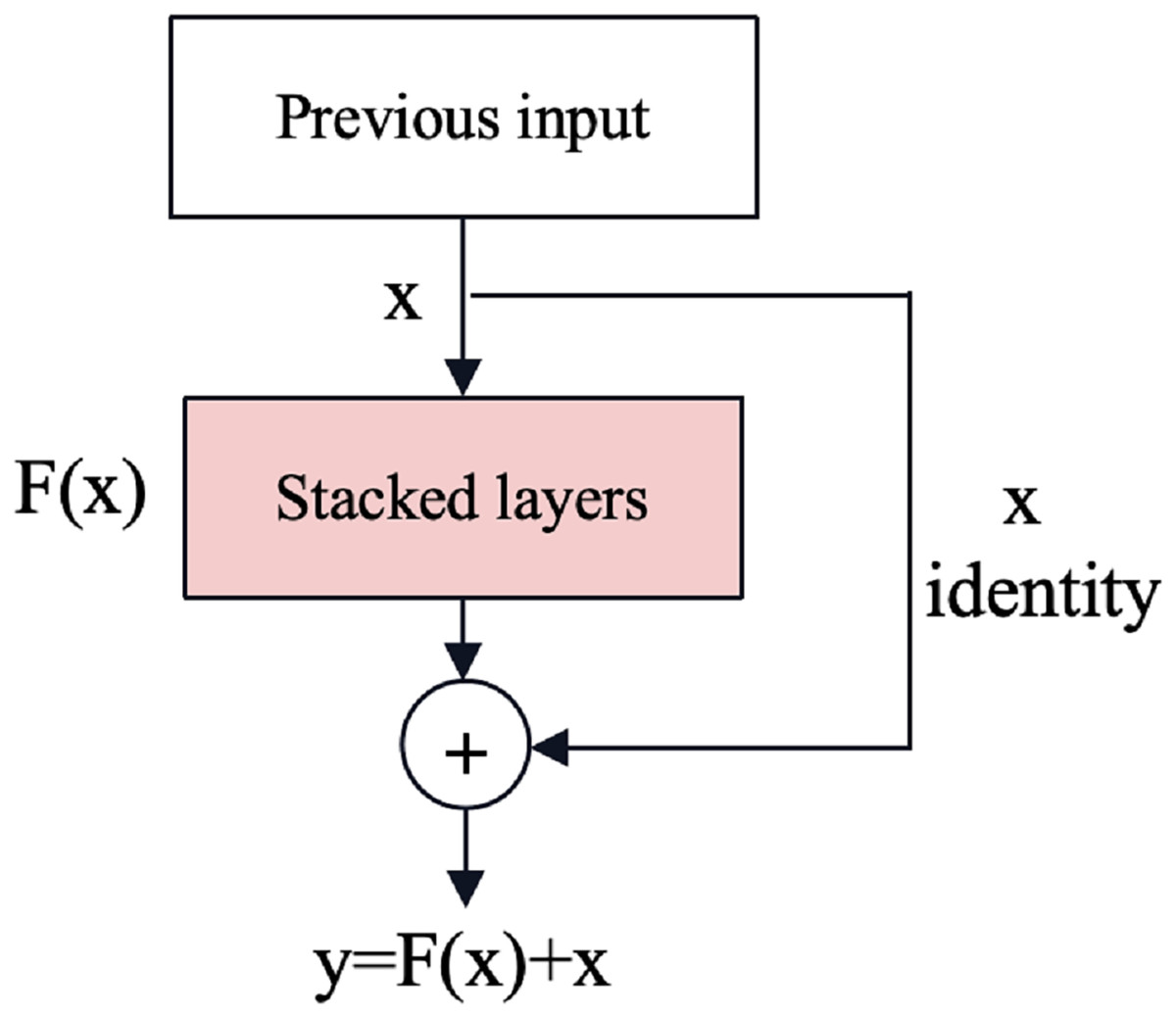
Figure 3: The shortcut connections of ResNet (He et al., 2016).
{kind=link}
Squeeze-and-excitation network (SENet)
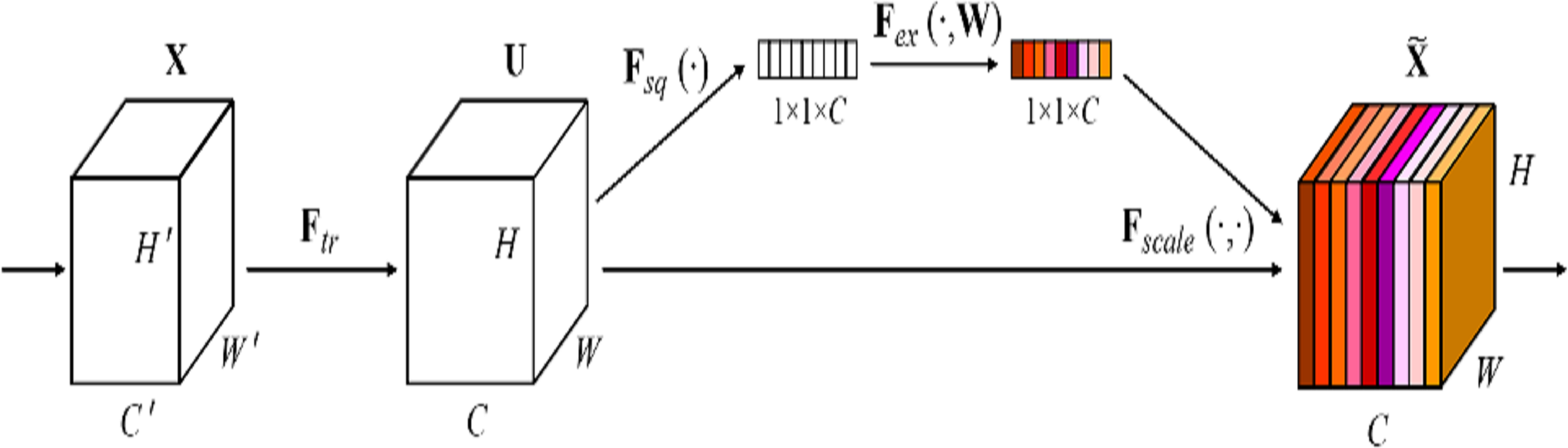
The Squeeze-and-Excitation (SE) block (Hu, Shen & Sun, 2018) is a plug-and-play channel attention mechanism that can be integrated into any network, as shown in Fig. 4. It can adjust the weights of each channel and improves the attention to important channels, which is particularly beneficial in deep residual architectures. In this article, the SE block is directly integrated with the residual network to form the SE-ResNet architecture. This integration allows SE-ResNet to achieve improved performance in differential cryptanalysis, by making the network more sensitive to informative features and more robust to variations in input data.
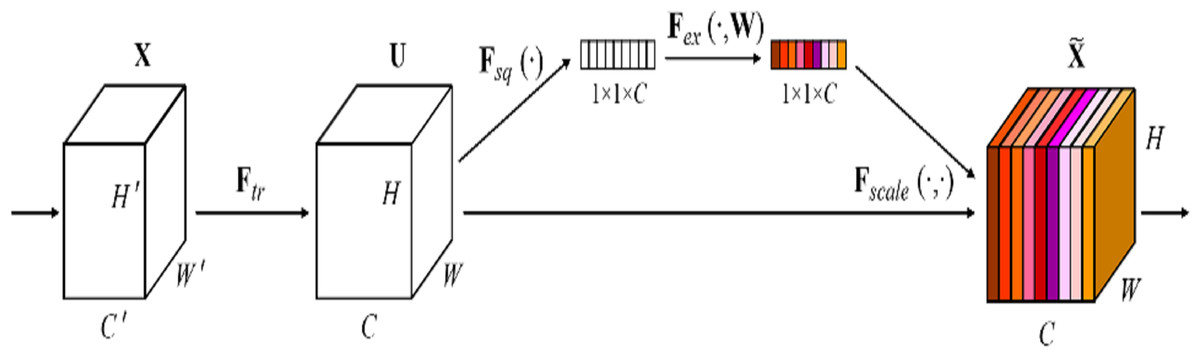
Figure 4: The squeeze-and-excitation block of SENet (Hu, Shen & Sun, 2018).
{kind=link}
The framework for developing related-key differential neural distinguishers to simon and simeck
The development of related-key differential neural distinguisher consists of four steps: differences selection, sample generation, network architecture design, distinguisher training and distinguisher evaluation, as shown in Fig. 5. In this section, we first introduce how to use a difference to construct the basic related-key differential neural distinguishers for SIMON and SIMECK from these steps. Subsequently, we introduce an advanced technique to construct the enhanced related-key differential neural distinguisher using a pair of distinct differences.
Figure 5: The framework of basic and enhanced related-key differential neural distinguishers.
{kind=link}
Basic related-key differential neural distinguishers
Differences selection
Selecting an appropriate plaintext difference and a master key difference for sample generation is a crucial step in the development of basic related-key differential neural distinguishers, since it significantly influences the features embodied within the samples. The study of Gohr, Leander & Neumann (2022), Bellini et al. (2023b) indicates that the differences that can yield the ciphertext differences with high bias scores may be more suitable for constructing neural distinguishers. In the related-key scenario, the -round exact bias score of ciphertext difference is defined as follows.
Definition 5 (Exact bias score. Gohr, Leander & Neumann (2022)) For a cipher primitive , the -round bias score of the plaintext difference and master key difference is the sum of the biases of each bit position in the resulting ciphertext differences, i.e.,
(7)
However, due to the immense computational demands posed by the exhaustive enumeration of all possible plaintexts and keys, computing the exact bias score is impractical. Therefore, we have to adopt more efficient methods to do this work. One promising approach is statistical sampling techniques, which is employed in Gohr, Leander & Neumann (2022). By employing random sampling method, we could reduce the time and resources required for data collection and analysis while maintaining a high level of accuracy and reliability. By randomly selecting samples from the plaintext and key space, we can obtain an approximate bias score as follow:
(8)
In addition, to mitigate the instance where certain differences have low bit bias in the initial few rounds but exhibit favorable bit bias in subsequent rounds, a practical strategy is to calculate the bias score from the initial round and adopt their weighted bias score as the final the final metric for evaluation. This approach can enhance the robustness of the differential evaluation. Specifically, the R-rounds weighted bias score for a given plaintext difference and master key difference is the sum of the product of the number of rounds and their bias score. The mathematical expression is as follows:
(9)
Sample generation
The related-key differential neural distinguisher is a supervised binary classifier. Thus, its dataset consists of positive and negative samples, labeled as 1 and 0, respectively. The positive samples are obtained by encrypting the plaintext pairs using the key pairs that exhibit the plaintext difference and key difference . In contrast, the negative samples are derived from encrypting the random plaintext pairs using the random key pairs.
Following the work of Lu et al. (2024), we use eight ciphertext pairs with boosted data formats to train the related-key differential neural distinguishers for SIMON and SIMECK. Specifically, the -th ( ) -round ciphertext pair , derived from the -th plaintext pair and key pair , can be extended to , denoted as , where
(10)
The label Y of the sample can be expressed as
(11)
Network architecture
We evaluate the various neural network architectures for the SIMON and SIMECK, such as neural network architectures used in Gohr (2019), Bao et al. (2022), Lu et al. (2024) and Zhang, Wang & Chen (2023), the architecture shown in Fig. 6 can achieve best accuracy under the same conditions. It consists of the following components:
-
Input Layer: For the SIMON and SIMECK with a block length of , the input of neural network is a tensor with a shape of .
Reshape Layer: This layer transforms the input tensor into a new shape of to enhance the feature extraction for subsequent convolutional layers.
Conv-1: A convolutional layer with convolutional kernels of size 1, followed by a batch normalization layer and a ReLU activation function.
Dense : Two dense layers implemented sequentially to process the features extracted from the Conv-1. Each dense layer consists of neurons followed by a batch normalization layer and a ReLU activation function.
SE-ResNet 5: A sequence of five SE-ResNet layers. Each SE-ResNet integrates the ResNet and SENet architectures and contains two convolutional layers with 3 × 3 kernels for feature extraction, followed by a batch normalization layer, a ReLU activation function, and a Squeeze-and-Excitation module. The features from different layers are merged by and operations.
Flatten: This layer flattens the multi-dimensional output from the SE-ResNet layer into a one-dimensional tensor.
Dense-128 2: Two fully connected layers with 128 neurons are used to connect all the features and send the output to the Sigmoid classifier in the subsequent layer.
Output: The final layer of the neural network is responsible for generating the final prediction result.
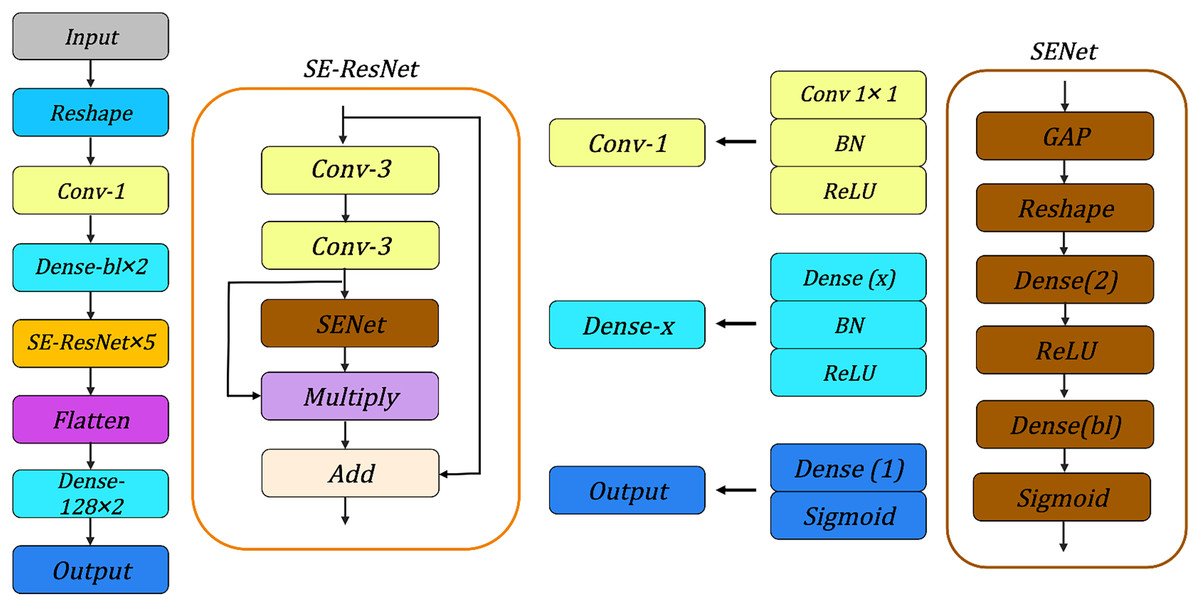
Figure 6: Overview of neural network architectures.
BN, Batch Normalization; GAP, Global Average Pooling.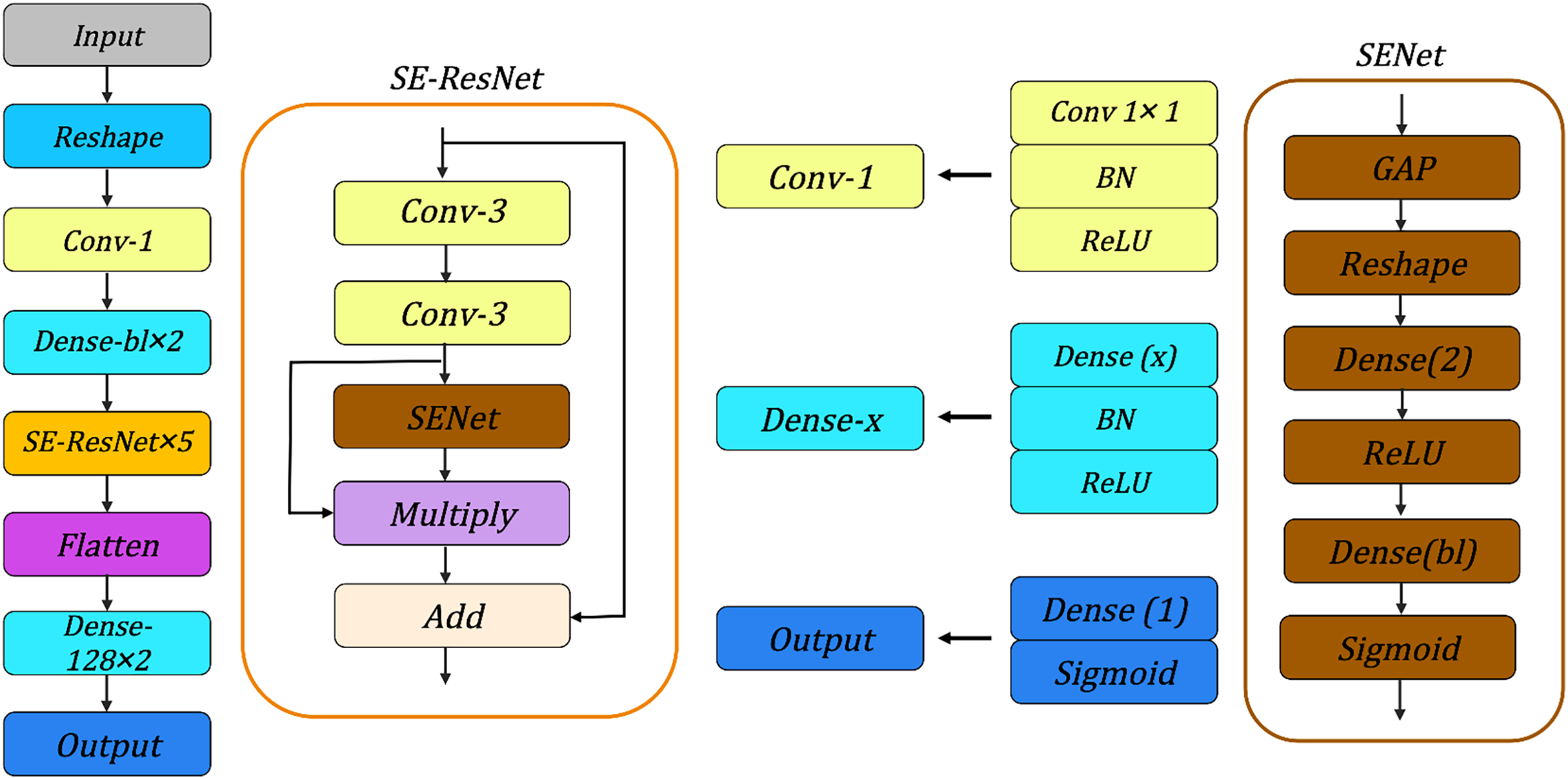{kind=link}
Training and evaluation
The training process of a related-key differential neural distinguisher can be divided into two phases: the offline phase and the online phase. During the offline phase, the attacker aims to train a neural network that can effectively distinguish between positive and negative samples. To achieve this, the attacker first generates training samples and validation samples using selected plaintext difference and master key difference . The training samples are used to train the neural network, while the validation samples are used to evaluate the recognition ability of the neural network. Ultimately, we can determine whether we have successfully constructed an effective neural distinguisher based on whether its accuracy surpasses the threshold of 0.5.
In the online phase, the neural distinguisher trained in the offline phase is employed to distinguish the ciphertext data generated by a block cipher or a random function. If the score of more than half of the samples exceeds 0.5, we consider the ciphertext data comes from the block cipher. Otherwise, these data are considered to originate from the random function.
Parameter setting
The number of training samples and validation samples used in this article is and . In addition, we set the number of epochs to , and each epoch contains multiple batches, each containing 30,000 samples. In order to adjust the learning rate more efficiently, we adopt the cyclic learning rate. Specifically, for the -th epoch, its learning rate is dynamically calculated by where , , and . Moreover, we choose Adam (Kingma & Ba, 2014) as the optimizer and Mean Squared Error (MSE) as the loss function. To prevent the model from overfitting, we use L2 regularization with the parameter of 0.00001.
Enhanced related-key differential neural distinguishers
Motivation
Benamira et al. (2021) found that Gohr’s neural distinguisher showed a superior recognition ability for the ciphertext pairs exhibiting truncated differences with high probability in the last two rounds, suggesting a potential understanding and learning of differential-linear characteristics in the ciphertext pairs. Subsequently, Gohr, Leander & Neumann (2022) expanded their study to five different block, including SIMON, Speck (Beaulieu et al., 2015), Skinny (Beierle et al., 2016), PRESENT Bogdanov et al. (2007), Katan (De Canniere, Dunkelman & Knežević, 2009), and ChaCha (Bernstein, 2008). Notably, their research highlights the close connection between the accuracy of the neural distinguisher and the mean absolute distance of the ciphertext differential distribution and the uniform distribution. In light of these investigations, we enhance the basic differential neural distinguisher by using two distinct non-zero plaintext differences and master key differences, symbolically represented as ( ).
The primary rationale behind selecting two input differences instead of one or more stems from the objective of minimizing conflicts among the output differences arising from positive and negative samples. When an input difference is chosen, as the number of rounds increases, some output differences will tend to be uniformly distributed due to the inherent confusion and diffusion properties of the block cipher. This poses a great challenge for the neural network to distinguish them from the uniformly distributed negative samples. However, if the negative samples are generated from another good difference, the mean absolute distance between the positive and negative samples may become more significant, which can allow the neural network to distinguish them more effectively. There are two reasons for limiting the number of input differences to two rather than more: firstly, the input differences that can maintain their unique distribution across several rounds are rare; secondly, an increase in the variety of ciphertext data may heighten the likelihood of collisions.
Differences selection
To develop an efficient and enhanced neural distinguisher, ( ) needs to satisfy two pivotal requirements. Firstly, they must exhibit a favorable weighted bias score after several rounds, ensuring that the resulting ciphertext data possess distinct and discernible features. This can be straightforwardly accomplished by adopting the differential evaluation scheme detailed in “Basic Related-Key Differential Neural Distinguishers”. Second, the disparity between the ciphertext data derived from the input differences ( ) and ( ) should be maximized, thereby ensuring that there are sufficient features for the neural network to leverage during the learning process.
Inspired by the role of weighted bias scores, we try to directly utilize their relative weighted bias scores, denoted as , as a rough metric to evaluate the suitability of for building the enhanced neural distinguishers, where
(12)
(13)
However, the outcomes are disappointing, primarily due to the fact that the relative weighted bias scores among all combinations derived from two input differences with weighted high bias scores have a high degree of similarity.
Fortunately, the differences that have high weighted bias scores are generally scarce. For a set of input differences, the total number of potential combinations is . Consequently, when is small, the exhaustive approach that compares all potential combinations to identify the optimal one is feasible. Nonetheless, as the value of increases, the number of combinations grows rapidly. Specifically, when is 32, it is a daunting task to train 496 neural distinguishers. Given that the training of a single neural distinguisher takes about an hour and a half, the aggregate time required for this task approximating 31 days, which is impractical and and unacceptable for most researchers. Therefore, the adoption of a more efficient and targeted strategy for selecting promising combinations becomes imperative.
An available greedy strategy is to fix as the optimal or top-ranked input difference that can be used to construct the most effective basic neural distinguisher. Subsequently, is chosen from the remaining differences with good weighted bias score. This strategy can ensure that the ciphertext data generated with have discernible and distinctive features. In this article, we adopt the exhaustive approach for SIMON32/64 and SIMON32/64. For the remaining variants, we adopt this greedy strategy to speed up the process of differences selection.
Sample generation
The sample generation for enhanced neural distinguisher is different from method outlined for the basic neural distinguisher in “Basic Related-Key Differential Neural Distinguishers”. For the enhanced neural distinguisher, the positive and negative samples are ciphertext data generated from the plaintext pairs and key pairs with the differences and . The label of a sample is represented as
(14)
The neural network architecture and the process of training and evaluation remain consistent with that in “Basic Related-Key Differential Neural Distinguishers”.
Related-key differential neural distinguishers for round-reduced simon and simeck
In this section, we adopt the framework and strategies in “The Framework for Developing Related-Key Differential Neural Distinguishers to SIMON and SIMECK” to develop the basic and enhanced related-key differential neural distinguishers for SIMON and SIMECK.
Differences selection for SIMON
The differences with Hamming weights of 1 and 2
For a block cipher with block length and key length , the number of input differences we need to evaluate is . Even for the smallest variants, i.e., SIMON32/64 and SIMECK32/64, the number of differences that need to be evaluated reaches , which would take a lot of time. Therefore, we first evaluate the weighted bias scores for all the differences with Hamming weights of 1 and 2.
For the 8-round SIMON32/64, there are 16 input differences with weighted bias scores around 11.0, which are . This is followed by another 16 input differences with a weighted bias score of about 10.8, specified as . The score for all remaining input differences with Hamming weights of 1 and 2 is less than 10.00.
For the 8-round SIMON48/96, there are 24 input differences with a Hamming weight of 1 that have a weighted bias score between 15.3 and 14.4: For differences with a Hamming weight of 2, only 11 input differences yield weighted bias scores greater than 14.4. They are , , and .
For the 8-round SIMON64/128, there are 32 differences with a Hamming weight of 1 that exhibit scores around 13.4. These differences are denoted as . After that, there are 32 differences with Hamming weight 2 that have scores close to 12.6 or 12.5, which are , and , respectively. The scores for all remaining differences are below 12.2.
Structural features of SIMON
For SIMON32/64, SIMON48/96, and SIMON64/128, the input differences with high weighted bias scores are those with the structure and . By analyzing the propagation process of the difference in SIMON, we can find that the plaintext differences and key differences cancel each other out in the first round. In the next three rounds, both plaintext difference and key difference are zero. Only in the fifth round, the key difference is re-injected, and the plaintext difference is still zero. The detailed differential propagation process is given in Table 3. This is easily verified by analyzing the transformations of the plaintext difference and the key difference in the round function and the round key.
| Round | ||
|---|---|---|
| 1 | (0×0, ) | |
| 2 | (0×0, 0×0) | 0×0 |
| 3 | (0×0, 0×0) | 0×0 |
| 4 | (0×0, 0×0) | 0×0 |
| 5 | (0×0, 0×0) |
The differences with a Hamming weight greater than 2
Based on the structural feature of SIMON, for differences with a weight greater than 2, we only consider the differences with a structure of and . For 8-round SIMON32/64, there are only 32 differences with Hamming weights of 3 that have weighted bias scores greater than 10.0. Specifically, they are , with scores between 10.7 and 10.3. For the 8-round SIMON48/96 and SIMON64/128, the weighted bias scores for all differences with a Hamming weight greater than two are less than 14.4 and 12.2, respectively.
Differences selection for SIMECK
The differences with Hamming weights of 1 and 2
Following the experiments on SIMON, we first explore the applicability of the input differences with Hamming weights of 1 and 2 in constructing neural distinguishers for SIMECK. For 10-round SIMECK32/64, 16 differences with a Hamming weight of 1, denoted as , achieve the optimal weighted bias score around 16.3. Then there are 32 differences with Hamming weight of 2, , with scores greater than 13.0. The rest of the differences are scored below 13.0.
For the 12-round SIMECK48/96, there are 24 differences with a Hamming weight of 1, , that have a weighted bias score between 30.4 and 26.6. For differences with a Hamming weight of 2, there are 33 differences with scores greater than or equal to 26.6. They are , , , and . The scores of all remaining differences are all less than 26.5.
For the 15-round SIMECK64/128, the best weighted bias score around 30.1 is achieved by 32 differences with a Hamming weight of 1, which are . Then there are 32 differences, , with scores close to 26.7. All the other differences have scores below 26.0.
Structural features of SIMECK
Similar to SIMON, for all variants of SIMECK, the input differences that exhibit good weighted bias scores adhere to the format: and . This is also due to the fact, as shown in Table 4, that the plaintext difference and key difference cancel each other out in the first round, and in the subsequent three rounds, both the plaintext difference and key difference are zero. It is not until the fifth round that the key difference , resulting from the operation of and , is reintroduced.
| Round | ||
|---|---|---|
| 1 | (0×0, ) | |
| 2 | (0×0, 0×0) | 0×0 |
| 3 | (0×0, 0×0) | 0×0 |
| 4 | (0×0, 0×0) | 0×0 |
| 5 | (0×0, 0×0) |
The differences with a Hamming weight greater than 2
For the 10-round SIMECK32/64 and 15-round SIMECK64/128, none of the differences with a Hamming weight of more than two yields a weighted bias score above 12.5 and 24.5, respectively. For 12-round SIMECK48/96, there are only three differences with a Hamming weight of three that have a score of 26.8, which are , . The scores for all remaining differences with a Hamming weight of three or higher are all below 26.6.
Basic related-key differential neural distinguishers
For the SIMON32/64, the 16 most effective 13-round related-key differential neural distinguishers are trained using the candidate differences where i ranges from 0 to 15. Their accuracy is , while it is for the distinguishers built from the candidate differences . The best 13-round neural distinguisher is constructed by with an accuracy of 0.545. Its 12-round neural distinguisher achieves an accuracy of 0.678. Compared with the related-key differential neural distinguisher in Lu et al. (2024), our differential selection strategy enables us to yield the superior distinguisher, as shown in Table 1.
For SIMON48/96, the best 13-round related-key differential neural distinguisher with an accuracy of 0.650 is constructed with and . Its 12-round neural distinguisher can achieve an accuracy of 0.993. For the remaining 23 candidate differences with a Hamming weight of 1, the accuracy of their 13-round neural distinguishers is between 0.640 to 0.650. In contrast, when the candidate differences with Hamming weight 2 in “Differences Selection for SIMON” is adopted, the highest accuracy is only 0.593, which is lower than that of 24 candidate differences with a Hamming weight of 1. Moreover, the three candidate differences with a Hamming weight of three could not construct an effective neural distinguisher for 13 rounds.
For SIMON64/128, the optimal 14-round related-key differential neural distinguisher is constructed using and with an accuracy of 0.580. The accuracy of its 13-round neural distinguisher is 0.840. In addition, the neural distinguishers built from the other 31 candidate differences with a Hamming weight of one exhibit accuracy between 0.577 and 0.580. There are no valid 14-round neural distinguishers achieved when using the candidate differences with a Hamming weight of two in “Differences Selection for SIMON”.
For SIMECK, the maximum number of rounds that can be constructed for related-key differential neural distinguishers is 15 for SIMECK32/64, 19 for SIMECK48/96, and 22 for SIMECK64/128. Their optimal neural distinguishers are constructed using and with an accuracy of 0.547, 0.516, and 0.519, respectively. The accuracies of these neural distinguishers from the previous round are 0.668, 0.551, and 0.552, respectively. The neural distinguishers constructed from other candidate differences with a Hamming weight of one have an accuracy very close to the best neural distinguisher above, with a maximum deviation of only 0.002. The candidate differences with Hamming weights greater than two fail to construct effective neural distinguishers with the maximum number of rounds.
Enhanced related-key differential neural distinguishers
For the SIMON32/64 and SIMECK32/64, we use all possible combinations of the superior candidate differences and , , to construct the related-key differential neural distinguisher. For SIMON32/64, there are five different that can yield the 13-round related-key differential neural distinguisher with an accuracy of 0.567. They are
For the first two instances, the accuracy of their 12-round neural distinguisher is 0.740, while it is 0.738 for the remaining three instances.
For SIMON48/96, SIMON64/128, SIMECK48/96, and SIMECK64/128, we consider combinations of the best differences in Table 5 and the remaining candidate differences of and , to accelerate the construction of our enhanced neural distinguishers. Specifically, for SIMON48/96, there are three pairs of differences that can yield 12-round and 13-round related-key differential neural distinguishers with accuracies of 0.997 and 0.696, respectively. These pairs are and together with and , where . For SIMON64/128, SIMECK48/96, and SIMECK64/128, only one pair of differences can construct 14-round, 19-round, and 22-round related-key neural distinguishers with accuracies of 0.618, 0.523, and 0.526, respectively. They are , , , and . The accuracies of 13-round, 18-round, and 21-round neural distinguishers for these pairs are 0.916, 0.572, and 0.572, respectively, as shown in Table 6.
| Cipher | Round | Acc | TPR | TNR | ||
|---|---|---|---|---|---|---|
| SIMON32/64 | 12 | (0×0, 0×2004) | (0×0, 0×0, 0×0, 0×2004) | 0.678 | 0.685 | 0.671 |
| 13 | (0×0, 0×2004) | (0×0, 0×0, 0×0, 0×2004) | 0.545 | 0.537 | 0.552 | |
| SIMON48/96 | 12 | (0×0, 0×200000) | (0×0, 0×0, 0×0, 0×200000) | 0.993 | 0.999 | 0.986 |
| 13 | (0×0, 0×200000) | (0×0, 0×0, 0×0, 0×200000) | 0.650 | 0.660 | 0.640 | |
| SIMON64/128 | 13 | (0×0, 0×100000) | (0×0, 0×0, 0×0, 0×100000) | 0.840 | 0.834 | 0.845 |
| 14 | (0×0, 0×100000) | (0×0, 0×0, 0×0, 0×100000) | 0.580 | 0.575 | 0.585 | |
| SIMECK32/64 | 14 | (0×0, 0×10) | (0×0, 0×0, 0×0, 0×10) | 0.668 | 0.640 | 0.695 |
| 15 | (0×0, 0×10) | (0×0, 0×0, 0×0, 0×10) | 0.547 | 0.524 | 0.570 | |
| SIMECK48/96 | 18 | (0×0, 0×2) | (0×0, 0×0, 0×0, 0×2) | 0.551 | 0.456 | 0.646 |
| 19 | (0×0, 0×2) | (0×0, 0×0, 0×0, 0×2) | 0.516 | 0.411 | 0.611 | |
| SIMECK64/128 | 21 | (0×0, 0×200000) | (0×0, 0×0, 0×0, 0×200000) | 0.552 | 0.413 | 0.691 |
| 22 | (0×0, 0×200000) | (0×0, 0×0, 0×0, 0×200000) | 0.519 | 0.374 | 0.663 |
| / | / | Round | Acc | TPR | TNR | |
|---|---|---|---|---|---|---|
| SIMON32/64 | (0×0, 0×801) | (0×0, 0×0, 0×0, 0×801) | 12 | 0.740 | 0.729 | 0.750 |
| (0×0, 0×1002) | (0×0, 0×0, 0×0, 0×1002) | 13 | 0.567 | 0.564 | 0.570 | |
| SIMON48/96 | (0×0, 0×200000) | (0×0, 0×0, 0×0, 0×200000) | 12 | 0.997 | 0.998 | 0.996 |
| (0×0, 0×400000) | (0×0, 0×0, 0×0, 0×400000) | 13 | 0.696 | 0.698 | 0.695 | |
| SIMON64/128 | (0×0, 0×100000) | (0×0, 0×0, 0×0, 0×100000) | 13 | 0.916 | 0.910 | 0.922 |
| (0×0, 0×400000) | (0×0, 0×0, 0×0, 0×400000) | 14 | 0.618 | 0.596 | 0.639 | |
| SIMECK32/64 | (0×0, 0×80) | (0×0, 0×0, 0×0, 0×80) | 14 | 0.730 | 0.722 | 0.738 |
| (0×0, 0×2000) | (0×0, 0×0, 0×0, 0×2000) | 15 | 0.568 | 0.553 | 0.582 | |
| SIMECK48/96 | (0×0, 0×2) | (0×0, 0×0, 0×0, 0×2) | 18 | 0.572 | 0.572 | 0.572 |
| (0×0, 0×80000) | (0×0, 0×0, 0×0, 0×80000) | 19 | 0.523 | 0.527 | 0.518 | |
| SIMECK64/128 | (0×0, 0×200000) | (0×0, 0×0, 0×0, 0×200000) | 21 | 0.572 | 0.580 | 0.563 |
| (0×0, 0×200) | (0×0, 0×0, 0×0, 0×200) | 22 | 0.526 | 0.523 | 0.529 |
Comparison and discussion
In this section, we first evaluate the differences with Hamming weights of 1 and 2 for SIMON and SIMECK, using weight bias scores. Then, we further evaluate the differences with Hamming weights greater than two based on the structural features of SIMON and SIMECK. Compared with the exhaustive approach of training a neural distinguisher for each difference in Lu et al. (2024), our scheme is more efficient.
Using these differences, we can obtain 13-round basic related-key differential neural distinguishers, exhibiting superior accuracy than that in Lu et al. (2024), for SIMON32/64. The accuracy of this basic neural distinguisher can be improved from 0.526 to 0.545 due to the effectiveness of our difference selection strategy. For the remaining variants, we can also obtain the basic related-key differential neural distinguishers with the same accuracy as that in Lu et al. (2024), as shown in Table 1. In addition, we obtain multiple basic related-key differential neural distinguishers that have the same or similar accuracy as the best distinguisher. All these results illustrate the effectiveness and usability of our proposed strategy for difference selection.
When constructing the enhanced related-key differential neural distinguishers using our method, all the enhanced differential neural distinguishers achieve higher accuracy than the basic related-key differential neural distinguishers for both SIMON and SIMECK. Compared with the results in Lu et al. (2024), our neural distinguishers all achieve different degrees of improvement in accuracy, as shown in Table 1. Specifically, the accuracy of the 13-round SIMON32/64, 13-round SIMON48/96, and 14-round SIMON64/128 is increased from 0.545, 0.650, and 0.580 to 0.567, 0.696, and 0.618, respectively. Similarly, the neural distinguishers for the 15-round SIMECK32/64, 19-round SIMECK48/96, and 22-round SIMECK64/128 is also demonstrated notable improvements in accuracy, with increases from 0.547, 0.516, and 0.519 to 0.568, 0.523, and 0.526, respectively. These results collectively underscore the effectiveness and robustness of our proposed scheme for constructing the enhanced related-key differential neural distinguishers.
Conclusions and future work
In this article, we first establish a comprehensive framework to construct basic related-key differential neural distinguishers for the SIMON and SIMECK. To choose an appropriate difference to construct this distinguisher, we utilize weighted bias scores to assess the applicability of various differences, which speeds up the process of difference selection and evaluation.
Moreover, we introduce an innovative method that incorporates two distinct differences into the neural distinguisher instead of a differences, which can result in the more robust and effective neural distinguishers. Compared with the distinguishers in Lu et al. (2024), we successfully improve the accuracy of the related-key differential neural distinguisher for both SIMON and SIMECK as shown in Table 1.
Furthermore, we envision several promising directions for future research. Firstly, our framework can be easily extended to other block ciphers, which assists in evaluating the security of other block ciphers. Secondly, the integration of advanced neural network architectures and training techniques could yield even more powerful neural distinguishers.