

GWRA: grey wolf based reconstruction algorithm for compressive sensing signals
- Published
- Accepted
- Received
- Academic Editor
- Xiangjie Kong
- Subject Areas
- Artificial Intelligence, Computer Networks and Communications, Network Science and Online Social Networks
- Keywords
- Average normalized mean squared error, Compressive sensing, Greedy-based reconstruction algorithm, Grey wolf optimizer, Mean absolute percentage error, Reconstruction algorithms
- Copyright
- © 2019 Aziz et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2019. GWRA: grey wolf based reconstruction algorithm for compressive sensing signals. PeerJ Computer Science 5:e217 https://doi.org/10.7717/peerj-cs.217
Abstract
The recent advances in compressive sensing (CS) based solutions make it a promising technique for signal acquisition, image processing and other types of data compression needs. In CS, the most challenging problem is to design an accurate and efficient algorithm for reconstructing the original data. Greedy-based reconstruction algorithms proved themselves as a good solution to this problem because of their fast implementation and low complex computations. In this paper, we propose a new optimization algorithm called grey wolf reconstruction algorithm (GWRA). GWRA is inspired from the benefits of integrating both the reversible greedy algorithm and the grey wolf optimizer algorithm. The effectiveness of GWRA technique is demonstrated and validated through rigorous simulations. The simulation results show that GWRA significantly exceeds the greedy-based reconstruction algorithms such as sum product, orthogonal matching pursuit, compressive sampling matching pursuit and filtered back projection and swarm based techniques such as BA and PSO in terms of reducing the reconstruction error, the mean absolute percentage error and the average normalized mean squared error.
Introduction
Exploiting the sparse nature of the signals is highly challenging in various signal processing applications such as signal compression, inverse problems and this motivated the development of compressive sensing (CS) methodologies (Donoho, 2006). CS provides an alternative new method of compressing data, offering a new signal sampling theory which we can adopt in variety of applications including data and sensor networks (Cevher & Jafarpour, 2010), medical systems, image processing and video camera, signal detection, analog-to-digital convertors (Choi et al., 2010) and several other applications.
The CS reconstruction problems are solved by convex algorithms and greedy algorithms (GAs). Convex algorithms are not efficient because they require high complex computations. Thus, most of researchers choose GAs, which are faster and give the same performance as convex algorithms in terms of minimum reconstruction error. On the other hand, GAs do not give a global solution as all heuristics algorithms that execute blind search and usually stuck on local optima. In this paper, we use grey wolf optimizer (GWO), which is considered as a meta heuristic algorithm that is prominent in finding global solution. Only a few works involving swarm algorithms have been proposed to solve CS reconstruction problem such as in Bao et al. (2018) and Du, Cheng & Liu (2013) where the authors used BAT and PSO algorithms to reconstruct the CS data. However, these two algorithms (Bao et al., 2018; Du, Cheng & Liu, 2013) have a number of drawbacks such as slow convergence velocity and tend to fall in local optimum status easily. In contrast, the GWO algorithm showed better performance than other swarm optimization algorithms (Mirjalili, Mohammad Mirjalili & Lewis, 2014).
Problem Formulation
Consider x[n], where n = 1, 2 … N, denotes sensor nodes reading vector set, N represents the count of sensor nodes. Any individual signal in RN can be expressed using basis of N × 1 vectors {Ψi}i=1N. Employing the basis N × N matrix, expressed as =[Ψ1|Ψ2|Ψ3|....|ΨN], together with the vectors Ψi being the columns, we can represent the signal x as given below (Donoho, 2006): (1)
This representation is done in terms of N × N orthonormal basis transform matrix. Here, g denotes the N × 1 sparse presentation of x. CS focuses on signals with a sparse representation. The number of basis vectors of x is S, such that S << N. Also we have, (N − S) values of g are zeros and only S values are non-zeros. Using Eq. (1), the compressed samples y (compressive measurements) can be obtained as: (2)
Here, the compressed samples vector y ∈ RM, with M << N and θ is M × N matrix.
The challenge of solving an undetermined set of linear equations have motivated the researchers to investigate upon this problem and as a result, diverse practical applications emerged to meet this challenge. In CS approach, the main responsibility is to offer an efficient reconstruction method enabling the recovery of the large and sparse signal with the help of a few available measurement coefficients. The reconstruction of signal using this available incomplete set of measurements is really challenging and relies on the sparse representation of signal. An easiest approach for recovering the original inherent sparse signal using its small set of linear measurements as shown in Eq. (2) is to compute the number of non-zero entries obtained by solving ‖L‖0 minimization problem. The reconstruction problem can thus be expressed as (3)
The ‖L‖0 minimization problem works well in theoretical aspects, but in general, it is an NP-hard problem (Mallat & Wavelet, 1999; Candes & Tao, 2006) and hence Eq. (3) is computationally intractable for any vector or matrix.
The main task involved in CS is to reconstruct the compressed sparsely sampled signal, involving solutions to an undetermined set of linear equations, with undefined set of solutions. Therefore, an efficient reconstruction algorithm is required to recover the inherent sparse signal. Main aim of signal reconstruction procedure is to evaluate the possible solutions derived from the inverse equation defined above so that it is possible to find the most appropriate estimate of the original sparse signal. The original signal reconstruction problem can be viewed as an optimization problem and numerous algorithms have been proposed with this intention. According to the CS method, the reconstruction algorithms for recovering the original sparse signal can be broadly categorized into two types: (i) convex relaxation, (ii) GA. Convex relaxation based optimization corresponds to a class of algorithms which make use of linear programming approach to solve the reconstruction problem. These techniques are capable of finding optimal/near optimal solutions to the reconstruction issues, but they have relatively high computational complexity. The examples for such algorithms are least absolute shrinkage and selection operator, basis pursuit and basis pursuit de-noising. In order to overcome the computational complexity of recovering the sparse signal, a family of GA/iterative algorithms have been introduced. GA solves the reconstruction problem in greedy/iterative fashion, with reduced complexity (Chartrand & Yin 2008). Therefore, GA is more adoptable for signal reconstruction in CS. GA techniques are classified into two categories: (i) reversible, (ii) irreversible. Both of them follows identical steps, detects the support-set making use of matched filter (MF) and after that constructs the original sparse signal using least squares (LS) method. In reversible GA, an element inserted to the support-set can be removed anytime, following a backward step. However, in irreversible GA, an element inserted to the support-set will remain there until the search ends. Examples for reversible GA includes sum product (SP; Dai & Milenkovic, 2009), compressive sampling matching pursuit (CoSaMP; Needell & Tropp, 2009) etc., whereas orthogonal matching pursuit (OMP; Tropp & Gilbert, 2007) belongs to the class of irreversible GA algorithms.
The authors of Mirjalili, Mohammad Mirjalili & Lewis (2014) proposed a swarm intelligent technique, GWO, well tested with 29 benchmark functions. The benchmark functions used are minimization functions and are divided into four groups: unimodal, multimodal, fixed-dimension multimodal and composite functions. The GWO algorithm is compared to PSO as an SI-based technique and GSA as a physics-based algorithm. In addition, the GWO algorithm is compared with three EAs: DE, fast evolutionary programing and evolution strategy with covariance matrix adaptation. The results showed that GWO is able to provide highly competitive results compared to well-known heuristics such as PSO, GSA, DE, EP and ES. First, the results on the unimodal functions showed the superior exploitation of the GWO algorithm. Second, the exploration ability of GWO is confirmed by the results on multimodal functions. Third, the results of the composite functions showed high local optima avoidance. Finally, the convergence analysis of GWO confirmed the convergence of this algorithm. Finding the global optimum precisely requires balancing the exploration and exploitation (i.e., good equilibrium) and this balance can be achieved using GWO (Faris et al., 2018).
Here, we propose a new grey wolf based reconstruction algorithm (GWRA) for CS signal reconstruction. GWRA algorithm is inspired from the GWO and the reversible GA. GWRA has two forward steps (GA forward and GWO forward) and one backward step. During the first iteration, GWRA matches filter detection to initialize the support set (GA forward step) and adds q elements to it. Then, GWRA increases the search space in this iteration by selecting extra K elements depending on GWO algorithm (GWO forward step) and then solves the LS equation to select the best k elements from q + K elements (backward step).
Summary of the contributions in this paper:
Develop a novel reconstruction algorithm based on grey wolf optimizer (GWRA) that: (a) utilizes the advantages of GAs to initialize the forward steps and (b) utilizes the advantages of GWO algorithm that enlarges the search space to determine the optimal output and recover the data.
Provide extensive experiments, and the subsequent results illustrate that GWRA exhibit high performance results than the existing techniques in terms of reconstruction error.
The rest of this paper is divided as follows: the related research of the proposed problem is described in the section “Related Research.” In the section “Grey Wolf Optimizer Background” presents the GWO background. Then in section “Grey Wolf Reconstruction Based Algorithm,” we introduce our method to solve the proposed problem with the illustration of a numerical example scenario. The simulation results of our approach and a case study scenario is given in the section “Simulation Results.” Finally, the paper is concluded in the section “Conclusion.” Table 1 explains the abbreviations which are used this manuscript. Table 2 shows the notations used throughout the paper.
| CS | Compressive sensing |
|---|---|
| IoT | Internet of things |
| MAPE | Mean absolute percentage error |
| GA | Greedy algorithm |
| ANMSE | Average normalized mean squared error |
| CoSaMP | Compressive sampling matching pursuit |
| OMP | Orthogonal matching pursuit algorithm |
| GWO | Grey wolf optimizer |
| MP | Matching pursuit |
| FBP | Filtered back projection |
| SP | Sum-product algorithm |
| BP | Basis pursuit |
| Notation | Description |
|---|---|
| x | Original signal |
| M | Number of measurements |
| y | Compressed sample |
| ϕ | CS matrix |
| Ψ | Transform matrix |
| K | Signal sparsity level |
| g | Sparse presentation of x |
| r | Residual of y |
| X | Wolf position |
| Xp | Prey position |
| q | Number of selected columns by Wolf algorithm |
| Xα | α Wolf position |
| Xβ | β Wolf position |
| Xδ | δ Wolf position |
| R | Support set |
| C | Search set |
| φc | Sub-matrix contains columns with indices c from φ matrix |
| best | Best solution or Xα |
| Secbest | Second best solution or Xβ |
| thirbest | Third best solution or Xδ |
| f | Fitness value |
| x′ | Estimated solution |
| t | Number of iterations |
| † | Pseudo-inverse |
| L | Indices set of largest K magnitude entries in |
Grey Wolf Optimizer Background
Grey wolf optimizer can be defined as an intelligent meta-heuristic approach, inspired by group hunting behavior of grey wolves (Mirjalili, Mohammad Mirjalili & Lewis, 2014). The GWO method simulates the social behavior and hierarchy of grey wolves and their hunting method. The hierarchal leadership divides the grey wolves into four categories: (i) alpha (α), (ii) beta (β), (iii) delta (δ) and (iv) omega (ω) as shown in Fig. 1.
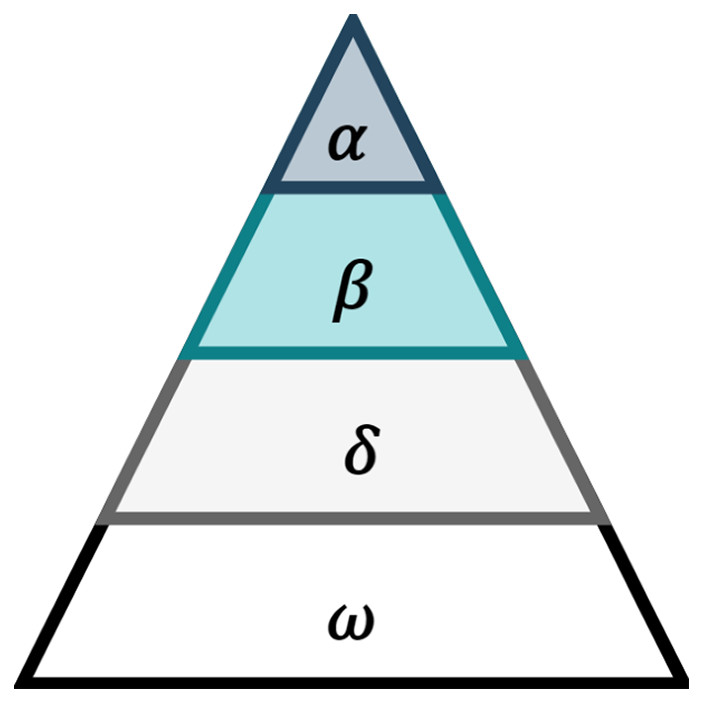
Figure 1: Grey wolfs’ hierarchal leadership (Faris et al., 2018).
{kind=link}
The α grey wolves are principally the leaders of their strict dominant hierarchy, responsible and powerful for decision making and leads the whole group during hunting, feeding, migration etc. The subordinates of alpha wolves are called β wolves and they are placed on the second level of the grey wolves’ hierarchy. They act as advisors and help the alpha wolves in making decisions. Finally, δ wolves execute alpha and beta wolves’ decision and manage ω wolves which are considered as the lowest ranking members of grey wolves hierarchy.
In GWO, α, β and δ guide the optimization process, where GWO considers the best solution and position for α wolves. In addition, the second and third best solutions and positions are assigned for β and δ, respectively. The other solutions are called ω solutions which always follow the solution of the other three wolves.
The mathematical representation of surrounding the prey and hunting process in GWO algorithm can be modelled as follows:
Surrounding the prey
In the hunting process, the first step of grey wolves is “surrounding the prey,” which can be expressed mathematically as: (5) (6)
Equation (5) expresses the distance between the wolf and the prey, where X is the wolf position, Xp is the prey position, t denotes the current iteration and C is coefficient vector which can be calculated using Eq. (7). The wolf’s position is updated using Eq. (6), where A denotes the coefficient vector and it can be calculated using Eq. (8).
(7) (8)Here, r1 and r2 are random values in [0, 1] and the values of a’s linearly decrease from 2 to 0 in each iteration.
GWO hunting process
After surrounding prey process, α, β and δ wolves lead the hunting process. During the hunting process, GWO preserves the first three best solutions (according to their fitness values) for α, β and δ, respectively and according to the position of wolves α, β and δ, the other search agents (ω) estimates their positions. Then, they start to attack the prey. The behavior of this process can be represented mathematically as in Eqs. (9–11) (Faris et al., 2018): (9) (10) (11)
After updating the positions of all wolves, the hunting process starts the next iteration to find the new best three solutions and repeat this process until the stopping condition is satisfied.
Algorithm 1 presents the GWO technique.
1: Initialize the grey wolf population Xi (i = 1, 2, 3,…,n) and t = 1.
2: Initialize C, a, and A using Equations (7) and (8).
3: Calculate the fitness of each search agent.
4: Put the best search agent as Xα,
the second best search agent as Xβ and
the third best search agent as Xδ.
5: while (t < Max number of iterations)
6: for each search agent
7: Modify the current search position using Equation (11).
8: end for
9: Update a, A, and C.
10: Calculate the fitness of all search agents.
11: Modify Xα, Xβ and Xδ.
12: t = t + 1.
13: end while
14: return Xα.
Grey Wolf Reconstruction Based Algorithm
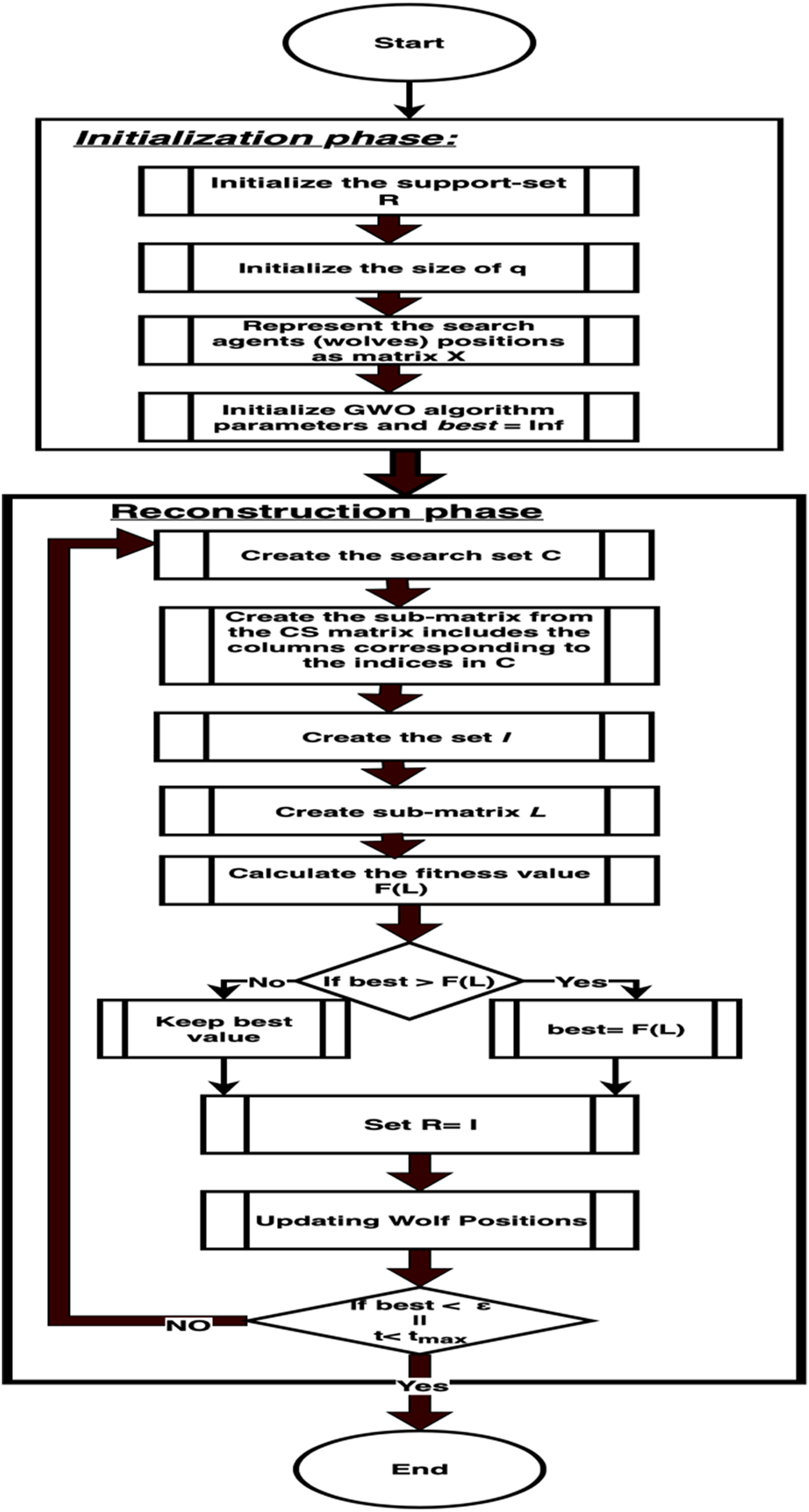
In this section, the proposed GWRA is described. GWRA can be used by the base station to reconstruct the sensors readings again. GWRA algorithm is inspired from the GWO algorithm and the reversible GA. GWRA has two forward steps (GA forward and GWO forward) and one backward step. In the first iteration, GWRA starts like any GA by initializing the support-set R with q elements using MF detection (GA forward step). GWRA increases the search space (search set C) by selecting extra K elements depending on GWO algorithm (GWO forward step). Then, GWRA solves the LS equation to select the best k elements from q + K elements (backward step).
At the end of this iteration, GWRA updates the support-set R with these K elements. From the second iteration, GWRA depends only on GWO forward step to select new k elements and add them to C, i.e., C has 2 * K elements in search space in each iteration to select the best k elements till it reaches the maximum number of iterations. Flow chart of GWRA is shown below in Fig. 2.

Figure 2: GWRA algorithm flow chart.
{kind=link}
The difference between GWRA and the other reversible GA like CoSaMP (Needell & Tropp, 2009) and SP (Dai & Milenkovic, 2009) algorithm is that in each iteration, GWRA uses the strength of GWO algorithm to find the best k according to their fitness values that leads the search toward the optimal solution. GWRA consists of two phases: initialization and reconstruction, as described below.
Initialization phase
Grey wolf reconstruction algorithm performs the following initialization in this phase:
[1]. Initialize the support-set R with indices of φT columns that corresponds to the largest q magnitude components in H, where H = φTy.
[2]. Initialize the size of q to M/2 − K depending on the fact “CS reconstruction problem can be resolved if the sparsity level K ≤ M/2” [2]. Initializations [1] and [2] will be executed only once at the beginning of the GWRA.
[3]. Represent the search agents (wolves) positions as matrix Xi × j, where i = number of wolves and j = K. Each value of this matrix is a randomly selected integer [1, N], where N denotes the count of columns in φ, where each number represents an index of a column in φ without duplication.
[4]. Initialize Xα, Xβ and Xδ as vector 1 × K all of its components equal to 0s.
[5]. Initialize best = Secbest = thirbest = infinity.
[6]. Initialize outer-loop iteration t = 1.
[7]. Initialize the stopping threshold ε = 10−5.
[8]. Initialize the estimated solution x′ = ø.
Reconstruction phase
The details of the reconstruction phase are described as given below:
[1]. For each row i in matrix X do the following:
Create the search set C, where C = R ∪ {Row #i of Xi × j}.
Create the sub-matrix φc from the CS matrix φ. φc includes the columns corresponding to the indices in C.
Create the set I as the K indices in C that have largest amplitude components of φc†y.
Create sub-matrix L = φI, the columns of matrix φ that corresponds to indices in set I (backward step).
Calculate the fitness value f(L), GWRA uses the same fitness function in Du, Cheng & Chen (2014) which can be expressed as follows: (12)
If best > f(L), then best = f(L) and Xα = I.
Otherwise if best < f(L) and Secbest > f(L), then Secbest = f(L) and Xβ = I.
Otherwise if best < f(L), Secbest < f(L) and thirbest > f(L), then thirbest = f(L) and Xδ = I.
Set R = I.
[2]. Updating wolves position: This step updates each search agent’s position according to Eq. (11). The matrix X is updated according to the new position of Xα, Xβ and Xδ.
[3]. In order to keep the values of Matrix X as integer values between [1, N], we modified Eq. (11) as follows: (13)
[4]. Check if t (the number of iterations) is less than the maximum count of iterations tmax or best > ε where ε = 10−5, then t = t + 1 and go to [1] else stop and return x′ where x′I = L†y and x′S−I = 0 where S = [1, 2… N].
Algorithm 2 presents the GWRA algorithm.
| 1: Input: CS matrix φM × N, measurement vector y and sparsity level K. |
| 2: Output: estimated solution set x′: |
| Initialization phase: |
| 3: R ≜ {indices of the q largest magnitude entries in φTy}. |
| 4: Initialize the grey wolf population matrix Xi × K with random integers between [1, N]. |
| 5: Xα = zeros (1, K), Xβ = zeros (1, K), Xδ = zeros (1, K). |
| 6: best = Secbest = thirbest = ∞. |
| 7: x′ = ø, ε = 10−5 and t = 1. |
| Reconstruction phase: |
| 8: while (t < tmax||best > ε) |
| 9: for each row i of the matrix Xi × K do |
| 10: C = Union(R, Row #i of Xi × j) |
| 11: I ≜ {indices of the K largest magnitude entries in φc† y}. |
| 12: L = φI. |
| 13: Calculate the fitness value f(L) using Equation 12. |
| 14. If(best > f(L)), then |
| 15: Xα = I, |
| 16: Else If (best < f(L) && Secbest > f(L)), then |
| 17: Secbest = f(L) and Xβ = I. |
| 18: Else If (best < f(L) && Secbest < f(L) && thirbest > f(L)), then |
| 19: thirbest = f(L) and Xδ = I. |
| 20: End If |
| 21: Set R = I. |
| 22: end for |
| 23: Wolf positions updating step: |
| 24: Update a, A, and C |
| 25: for each search agent |
| 26: Update the position of the current search agent by Equation (13). |
| 27: end for |
| 28: t = t + 1 |
| 29: End while |
| 30: return x′ where x′I = L†y and x′S−I = L†y where S = [1, 2… N]. |
Example scenario
For clarification, we illustrate the actions of GWRA using the following example:
Input: matrix ϕ6 × 10 (M = 6 and N = 10) with elements generated from uniform distribution, y = ϕx ∈ R6 is the compressed samples and the sparsity level K = 2.
Output: estimated signal x′.
Initialization phase execution
-
Support-set R = {10}, the indices of columns of ϕ that correspond to the largest q(= 1) amplitude components in H = φTy, where .
Matrix Xi × K, where i = number of search agents (= 5) and K = 2, will be initialized as follows:
-
Initialize Xα, Xβ and Xδ as Xα = [0 0], Xβ = [0 0] and Xδ = [0 0].
best = Secbest = thirbest = ∞. Number of the outer-loop iteration is initialized to t = 1 and the estimated solution x′ = ø.
Reconstruction phase execution
For each row i in the matrix do: when i = 1
Create the sub-matrix ϕc by selecting the columns from ϕ which correspond to the indices in C.
The set I will be created as the indices of the largest K(= 2) amplitude components in ϕc†y: i.e., I = {5, 10}. And then we create the sub-matrix
Using Eq. (12), the fitness value f(L) of the sub-matrix will be 0.233.
Since best > f(L), best = 0.233, Xα = {5, 10}.
Repeating the same steps for all rows (i = 2, 3, 4, 5) of X, we will have best = 0.233, Xα = I = {5, 10}. R will be updated as R = I = {5, 10}.
Using Eq. (13), the updated position matrix X will be:
-
Since the stop criteria are not satisfied, the iteration number will be updated t = t + 1 and execute Reconstruction phase as follows:
For each row i in the matrix do: (when i = 1)
C = R ∪ {row 1 in X} = {10, 5, 1, 8},
-
Create the sub-matrix ϕc by selecting the columns from matrix ϕ that correspond to indices in C.
Create the set I as the indices of the largest K amplitude components in : i.e., I = {1, 5}.
The sub-matrix L will be:
Using Eq. (12), the fitness value f(L) of the sub-matrix L will be 10−16.
Since best > f(L), then best = 10−16, Xα = {1, 5}.
Repeating the same steps for every row of X (i = 2, 3, 4, 5) in the wolf position matrix X, we will have best = 10−16, Xα = {1, 5}, and updated R = I = {1, 5}.
Update each search agent’s position (matrix X) according to Eq. (13):
According to the stop criteria best <10−5, stops and calculates x′ as following:
Then, the estimated signal x′ will be as follows: which is equals to x.
Therefore, GWRA succeeds to reconstruct the original data without any errors.
Simulation Results
In this section, the MATLAB environment is used for performing all simulations and the reconstruction is investigated by Gaussian matrix Φ, of size M × N, where M = 128 and N = 256. Two types of data are used to evaluate the reconstruction performance of the proposed algorithm: computer generated data and real data set. In the first type, we used data generated from Uniform and Gaussian distribution as an example to evaluate the proposed algorithm. The whole process is repeated over 500 times and then averaged on randomly generated K sparse samples. The performance evaluation of GWRA and its comparison with the baseline algorithms such as CoSaMP (Needell & Tropp, 2009), OMP (Tropp & Gilbert, 2007), SP (Dai & Milenkovic, 2009), FBP (Burak & Erdogan, 2013), BA (Bao et al., 2018) and PSO (Du, Cheng & Liu, 2013) in terms of both average normalized mean squared error (ANMSE) and mean absolute percentage error (MAPE) is given below. The setting of used Parameters is shown in Table 3.
| Parameter | Value |
|---|---|
| Signal length (N) | 256 |
| Measurement vector length (M) | 128 |
| CS matrix (Φ) | 128 × 256 |
| Sparse level (K) | From 5 to 60 with five increment |
| search agents matrix Xi × j | i = 100, j = K |
| Compression ratio | 70%, 60%, 50%, 40% and 30% |
Performance Metrics: The GWRA algorithm reconstruction’s performance is compared with different reconstruction algorithms in terms of the following performance metrics:
Average normalized mean squared error: the average ratio defines the ANMSE, where x represents the initial reading and x′ represents the reconstructed one.
Mean absolute percentage error: the ratio defines the MAPE.
Average normalized mean squared error evaluation
The GWRA algorithm is evaluated in terms of ANMSE and the result is compared with the existing algorithms.
Figure 3 illustrates the results of ANMSE evaluation in which Gaussian distribution is used to generate the non-zero entries of the sparse signal. The results prove that GWRA algorithm provides reduced ANMSE than CoSaMP, OMP, FBP, BA, PSO and SP. Also, the ANMSE of GWRA starts to increase only when K > 57 while it increased when K > 22, K ≥ 19, K ≥ 26, K ≥ 33, K ≥ 46, K ≥ 38 for CoSaMP, OMP, FBP, SP, BA, PSO, respectively as shown in Fig. 3. This is because GWRA applies the grey wolves’ behavior to hunt the prey (k elements) inside search space (CS matrix) according to their fitness values (the best fitness values). Then, in each iteration, the support-set will be updated with the best k elements, i.e., GWRA has the best-estimated solution till it reaches the optimal one.
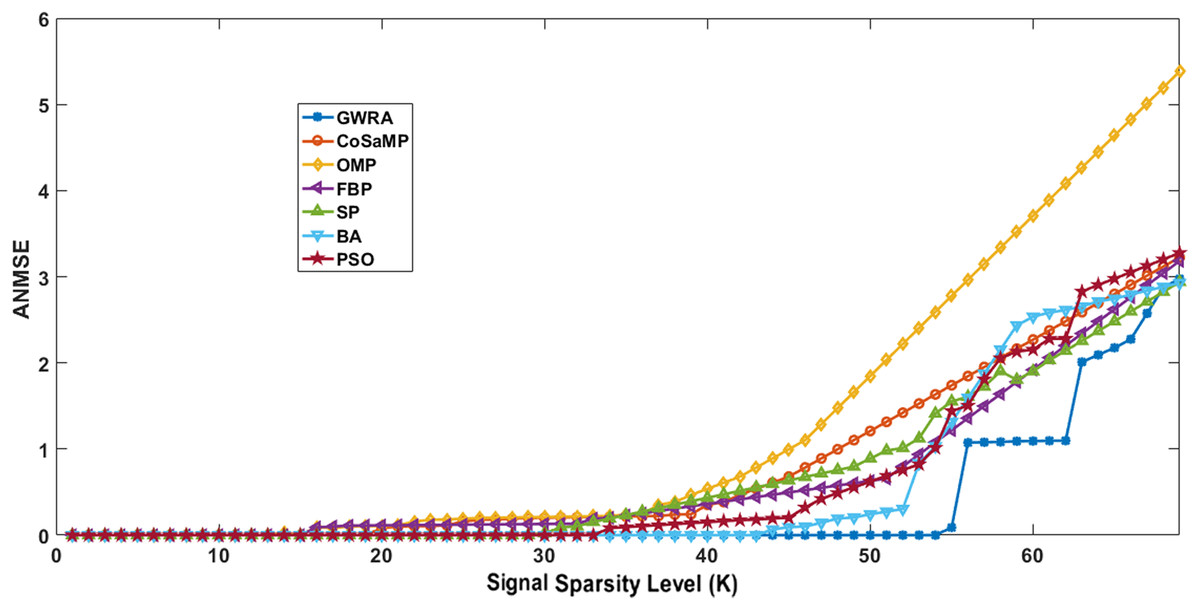
Figure 3: ANMSE in GWRA, CoSaMP, OMP, FBP, SP, BA and PSO algorithms over generated Gaussian sparse vector.
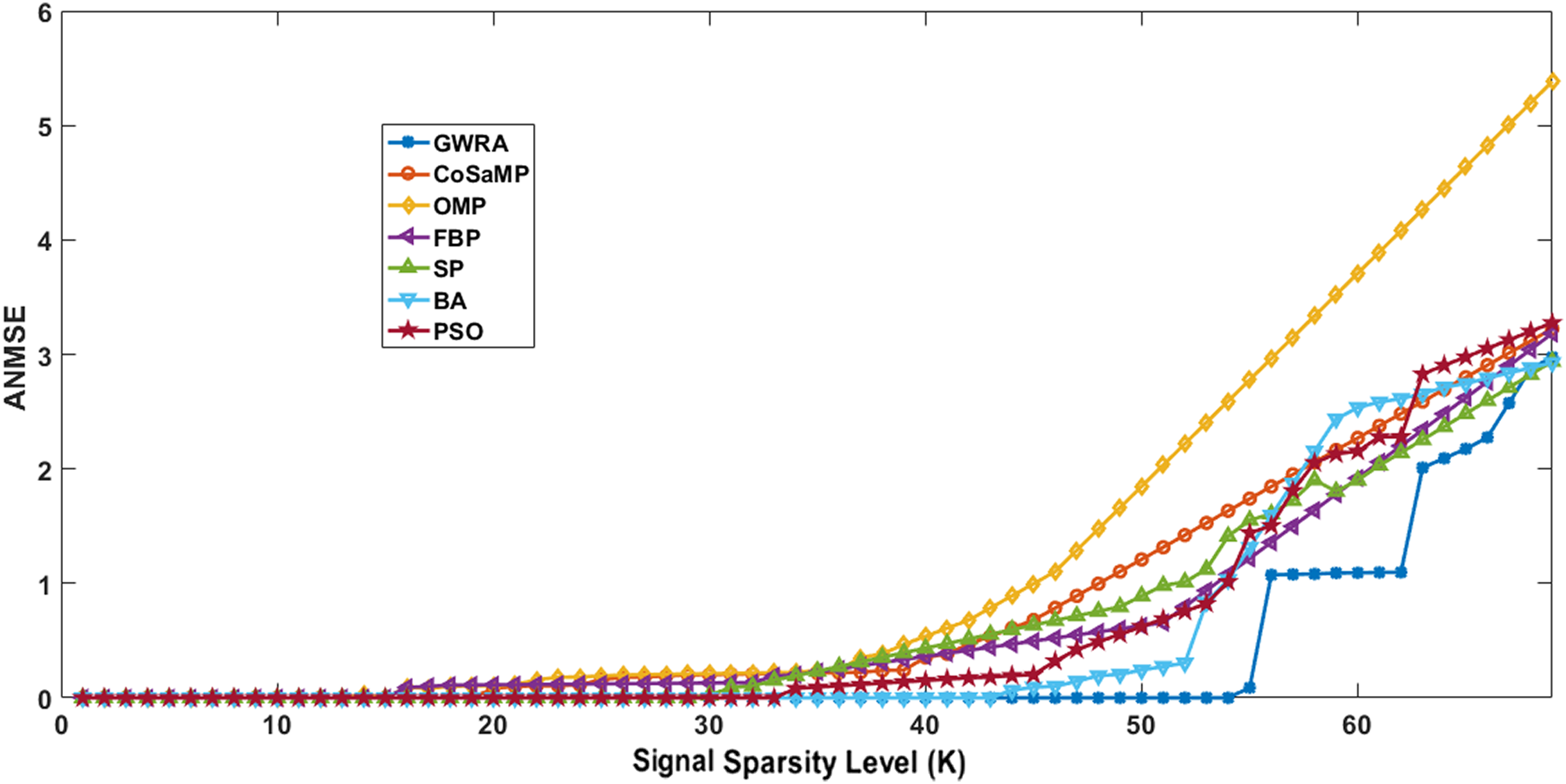{kind=link}
Figure 4 illustrates the results of ANMSE evaluation in which Uniform distribution is used to generate the non-zero entries of the sparse signal. The results prove that GWRA algorithm still gives the lowest ANMSE value than CoSaMP, FBP, OMP, SP, BA, PSO as K > 53, K ≥ 25, K > 20, K > 26, K > 33, K ≥ 45, K > 37, respectively, because what any GA does in one round, GWRA does it for each search agent and then it selects the best one in every iteration to converge at the optimal solution.

Figure 4: ANMSE in GWRA, CoSaMP, OMP, FBP, SP, BA and PSO algorithms over generated Uniform sparse vector.
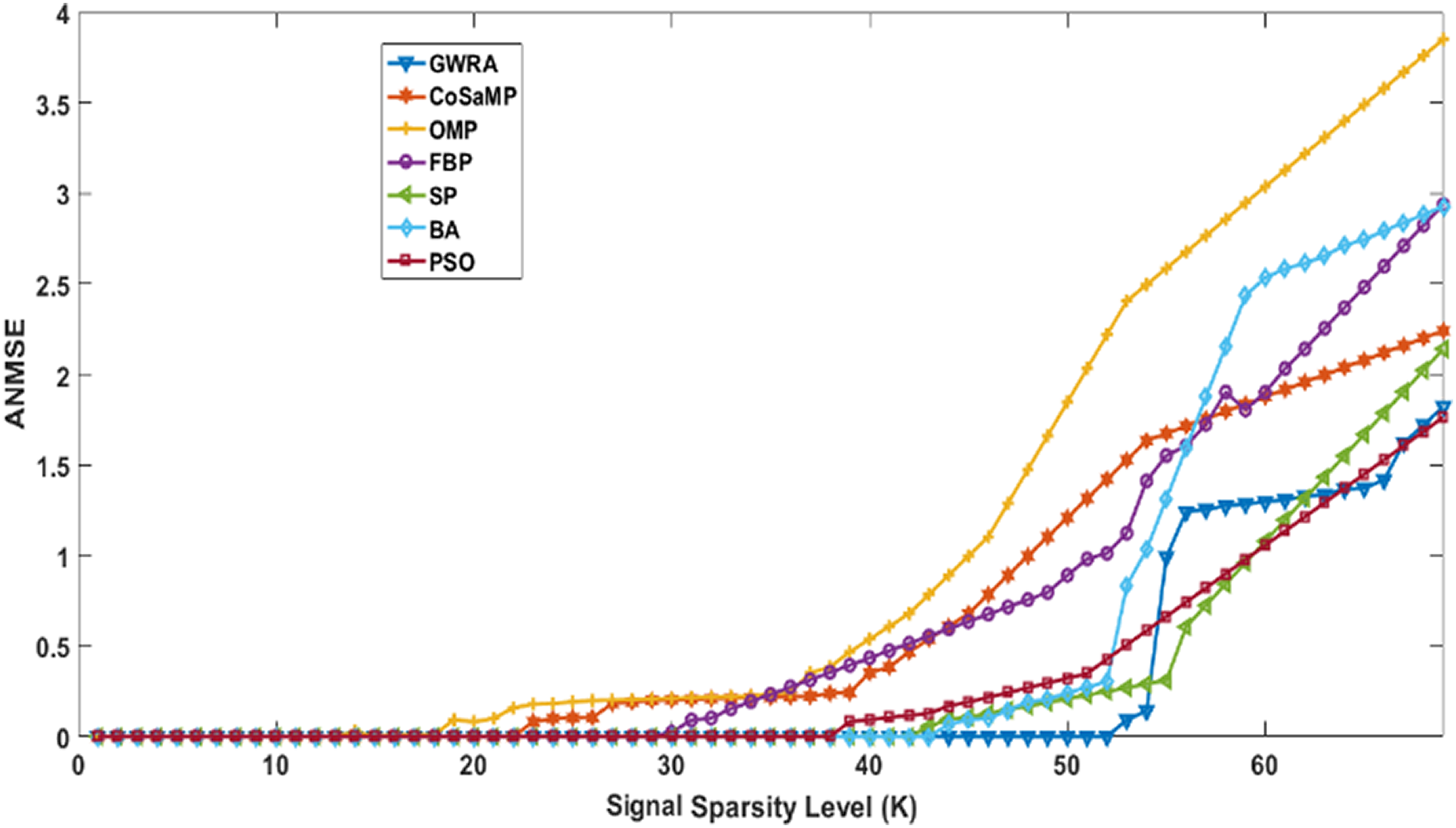{kind=link}
In the second test, we measure the reconstruction performance of GWRA as a function in terms of the length of measurement-vector and then compared the results using CoSaMP, FBP, SP, BA, OMP, PSO. The sparse signals are generated using Gaussian distribution having length N = 120, M values varying from 10 to 60 with increment of 1. Illustration of the reconstruction performance of GWRA, CoSaMP, OMP, FBP, SP, BA and PSO with different measurement vector length, M is given in Fig. 5. From the figure, we observe that GWRA algorithm still gives the lowest ANMSE results compared to the others.
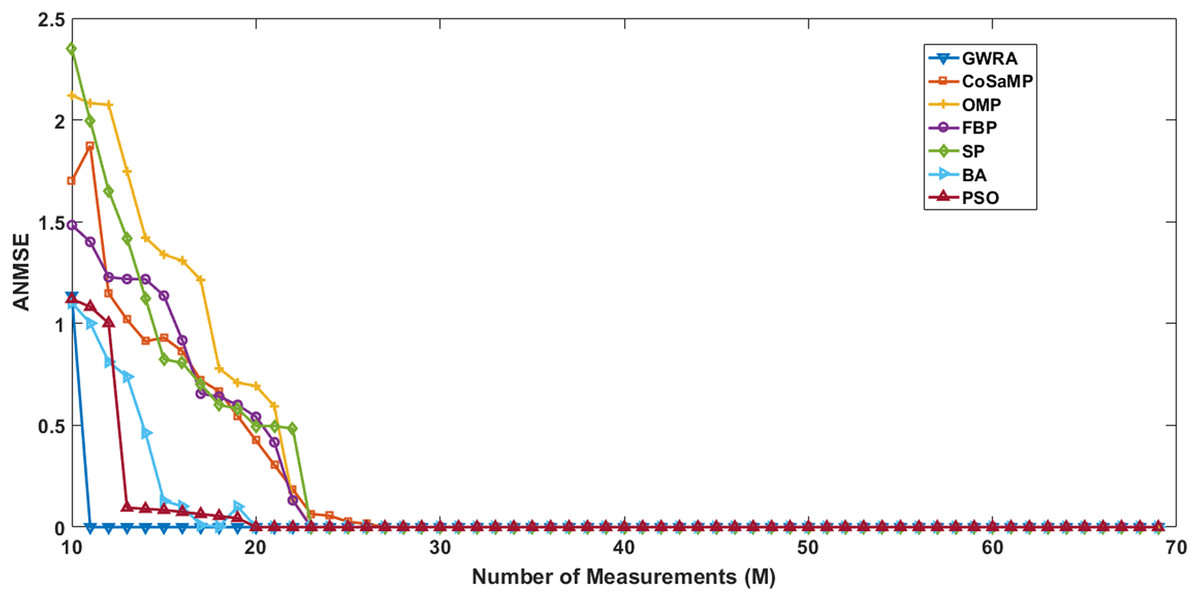
Figure 5: ANMSE in GWRA, CoSaMP, OMP, FBP, SP, BA and PSO algorithms over generated Gaussian matrix with different lengths of M.
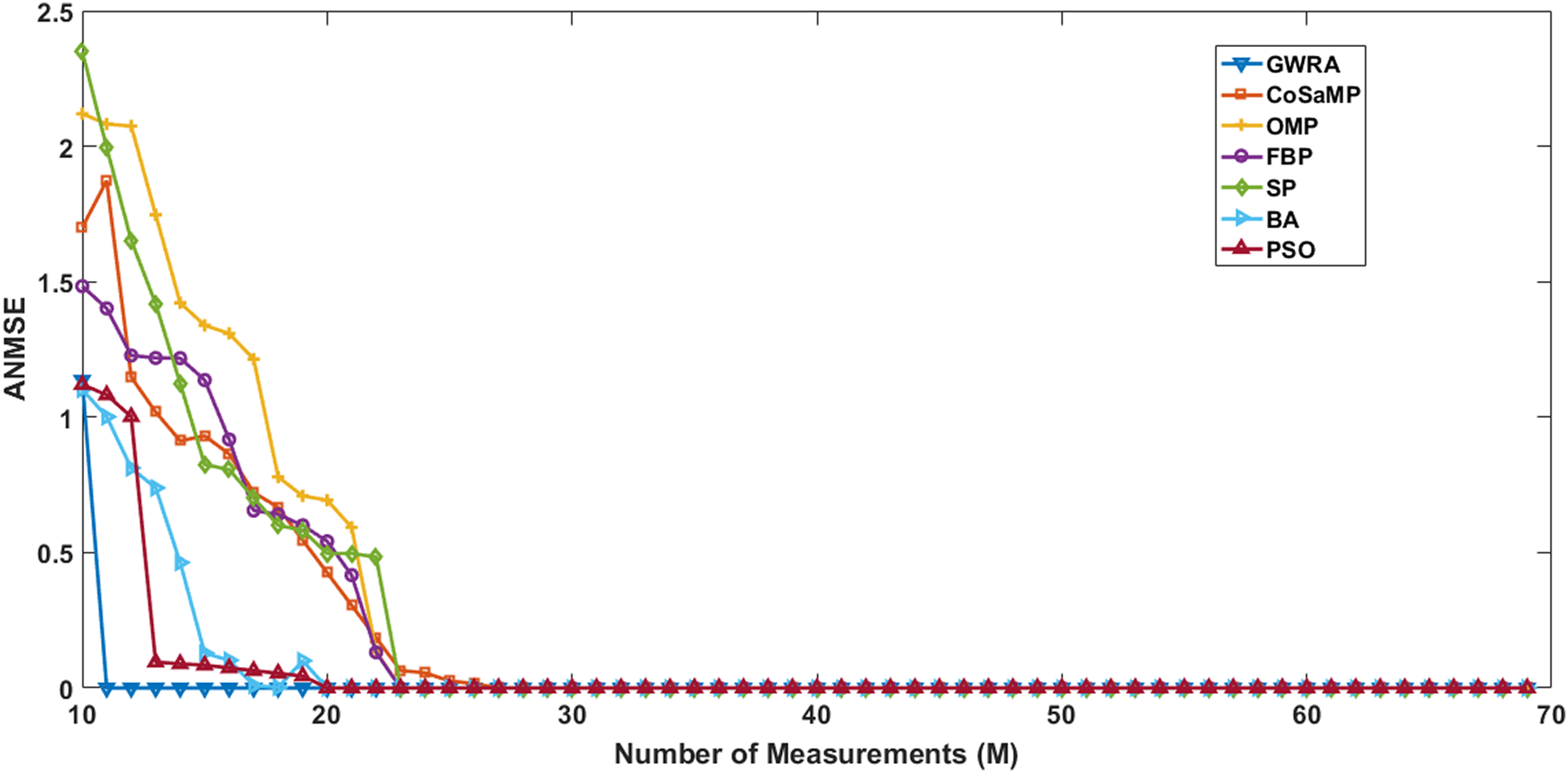{kind=link}
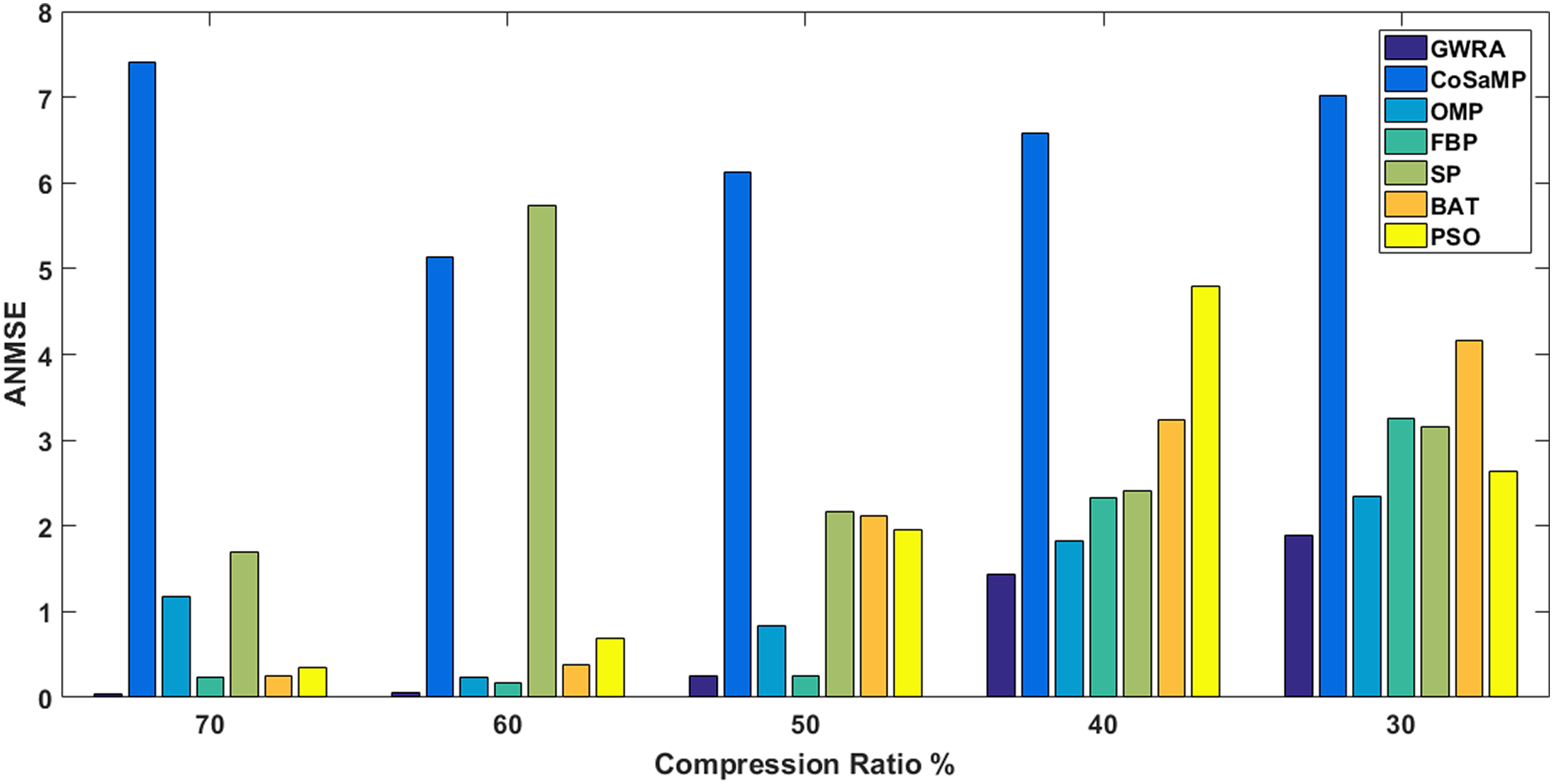
In the third test, reconstruction performance of GWRA is measured in terms of ANMSE as a function of compression ratio over Uniform and Gaussian sparse vectors as shown in Fig. 6 and Table 4, respectively. In this test, we have N = 256 and the different compression ratios are 70%, 60%, 50%, 40% and 30% where K = M/2. Figure 6 shows the ANMSE for GWRA, CoSaMP, OMP, FBP, SP, BA and PSO for different compression ratios. From Fig. 6, we can conclude that GWRA algorithm achieves the best reconstruction performance with different compression ratio. The same performance can be noted from Table 4, where GWRA achieves the minimum reconstruction error in comparison to the other algorithms for different compression ratio values.
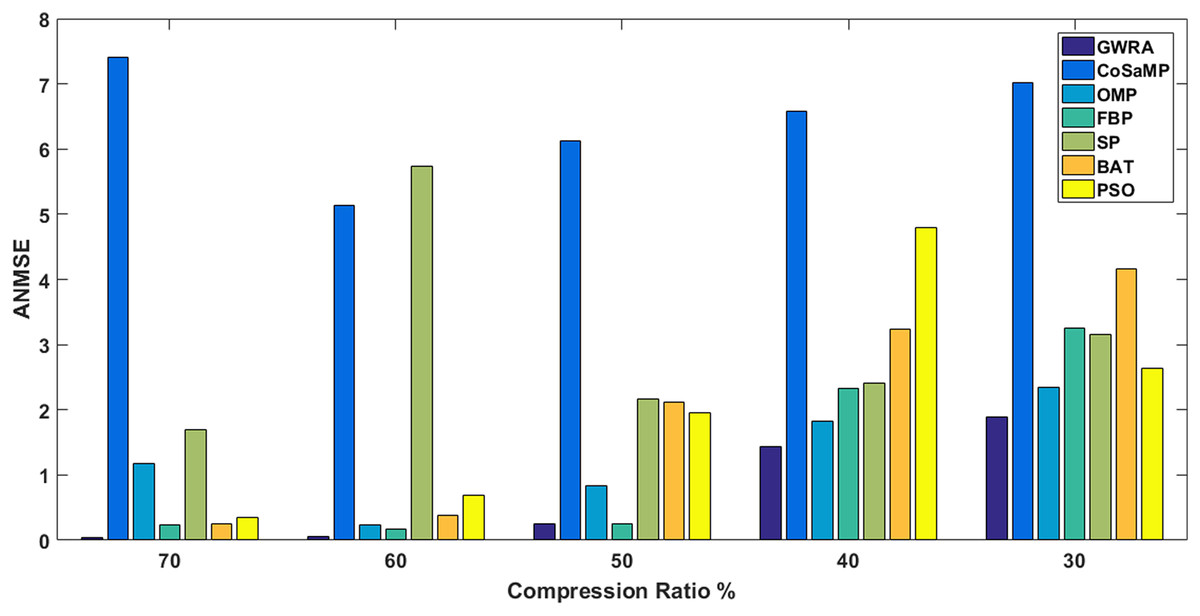
Figure 6: ANMSE in GWRA, CoSaMP, OMP, FBP, SP, BA and PSO algorithms for different compression ratios.
{kind=link}
| Compression ratio (%) | GWRA | COSAMP | OMP | FBP | SP | BA | PSO |
|---|---|---|---|---|---|---|---|
| 70 | 3.10710e−29 | 5.135 | 0.228 | 0.1717 | 1.699 | 0.245 | 0.354 |
| 60 | 0.0583 | 6.1224 | 0.828 | 0.2412 | 2.164 | 0.389 | 0.687 |
| 50 | 0.2515 | 6.575 | 1.125 | 0.2572 | 2.415 | 2.124 | 1.953 |
| 40 | 1.4313 | 7.025 | 1.820 | 2.3341 | 3.156 | 3.245 | 2.644 |
| 30 | 1.894 | 7.4220 | 2.348 | 3.2498 | 5.125 | 4.165 | 4.789 |
Mean absolute percentage error evaluation
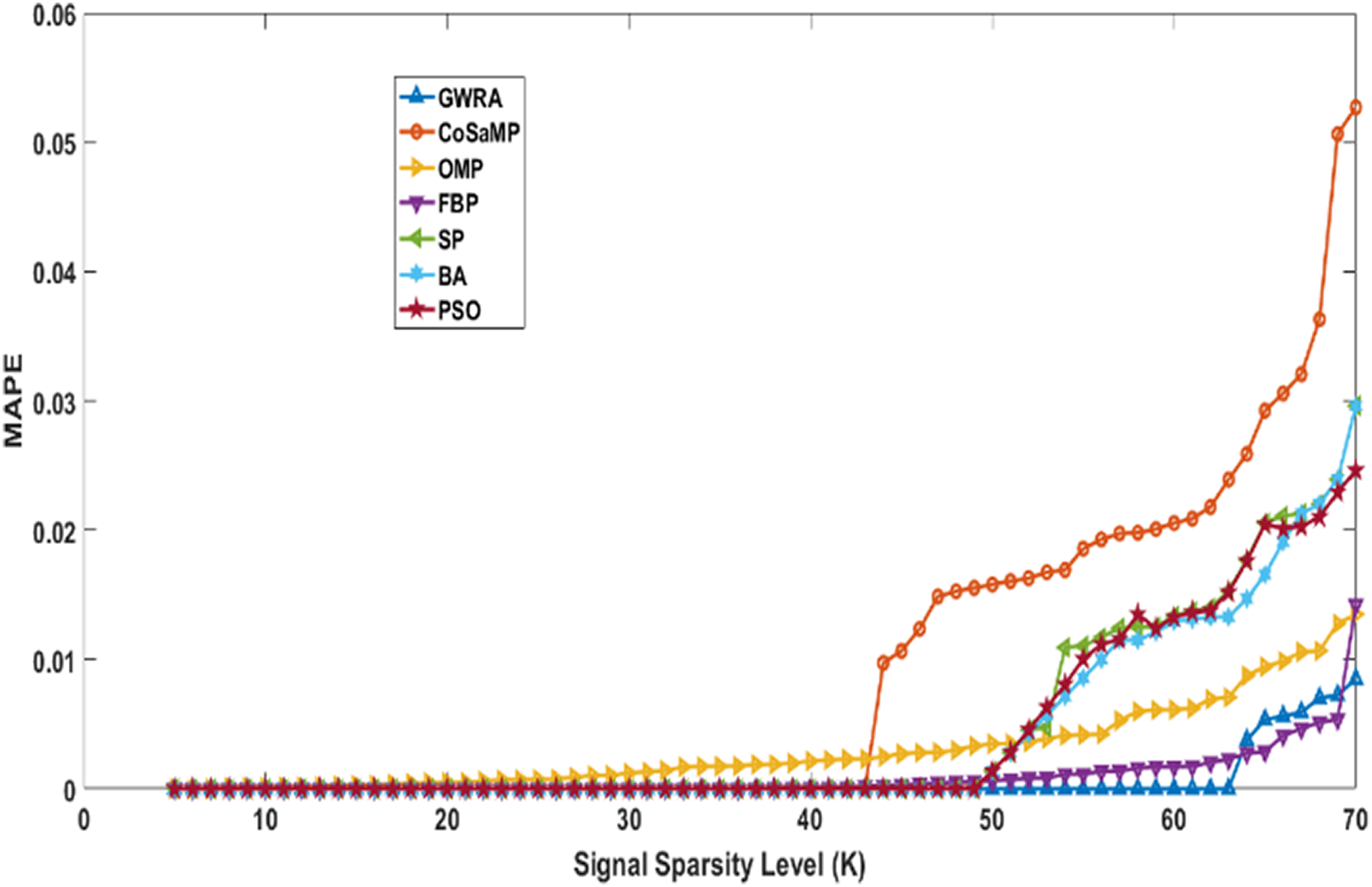
In the fourth test, we measure the reconstruction performance of GWRA in terms of MAPE and the result is compared with other algorithms. Figure 7 shows MAPE results for GWRA, CoSaMP, OMP, FBP, SP, BA, PSO algorithms and it is clear that GWRA exceeds the reconstruction performance of others in terms of reducing the MAPE, because GWRA integrates the advantages of both greedy as well as the GWO algorithm to achieve the best result.
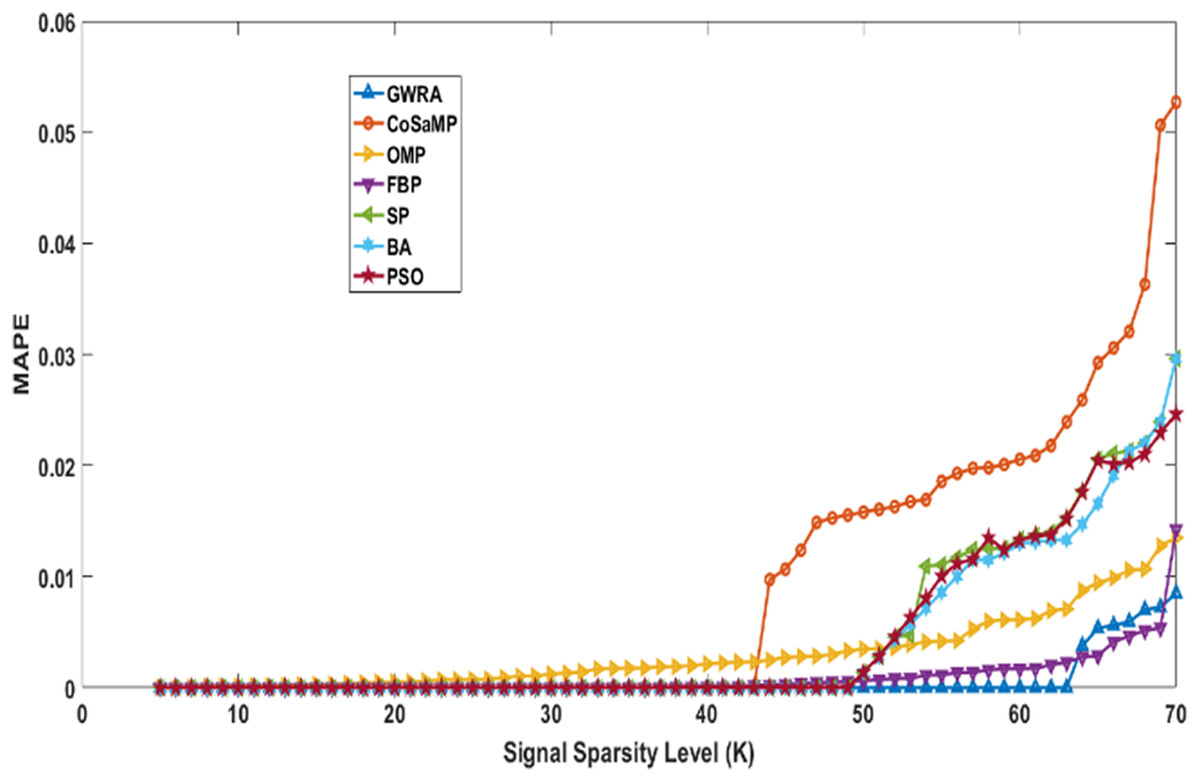
Figure 7: MAPE over sparsity for Uniform sparse vector in GWRA, CoSaMP, OMP, FBP, SP, BA and PSO.
{kind=link}
Case study
Here, we demonstrate the effectiveness of the GWRA algorithm introduced in this paper in reducing ANMSE and MAPE. For this purpose, the proposed algorithm is applied to reconstruct real weather dataset (Ali, Gao & Mileo, 2018). This dataset contains weather observations of Aarhus city, Denmark obtained during February–June 2014 and also August–September 2014.
In this test, we use the weather dataset of February 2014 period as original data. Using CS, February dataset is compressed, then we apply, evaluate and compare the performance of GWRA, CoSaMP, OMP, FBP, LP (Pant, Lu & Antoniou, 2014) and SP to recover it back. In addition, we use DCT (Duarte-Carvajalino & Sapiro, 2009) and FFT (Canli, Gupta & Khokhar, 2006) as sparse domain, as shown in Figs. 8 and 9.
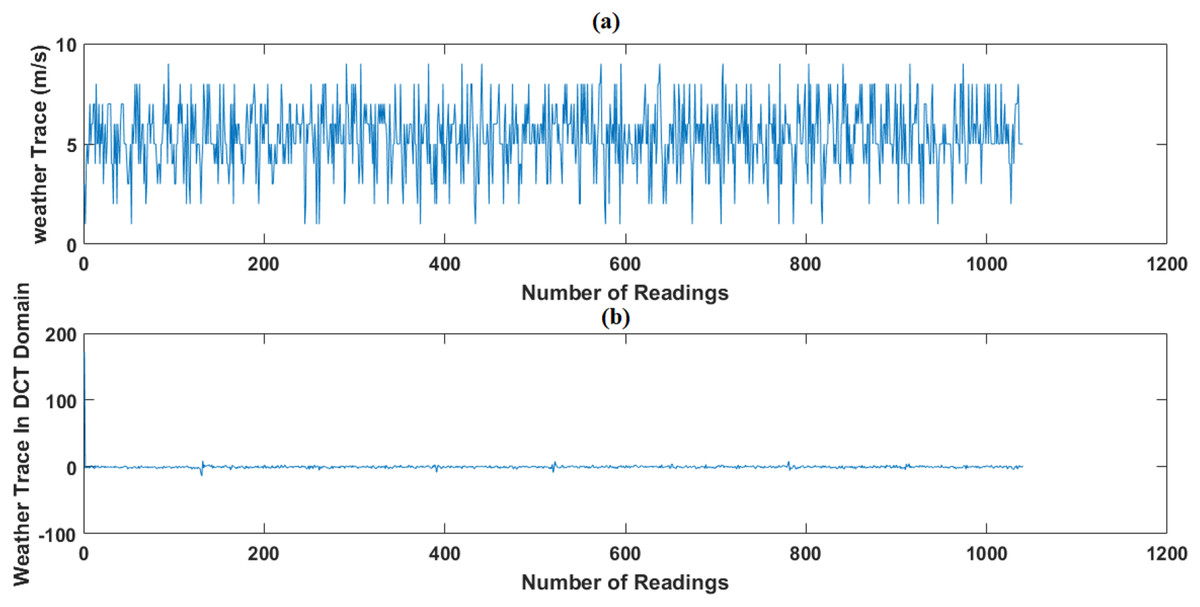
Figure 8: Weather trace in DCT Domain: (A) the original data and (B) the sparse signal representation.
{kind=link}
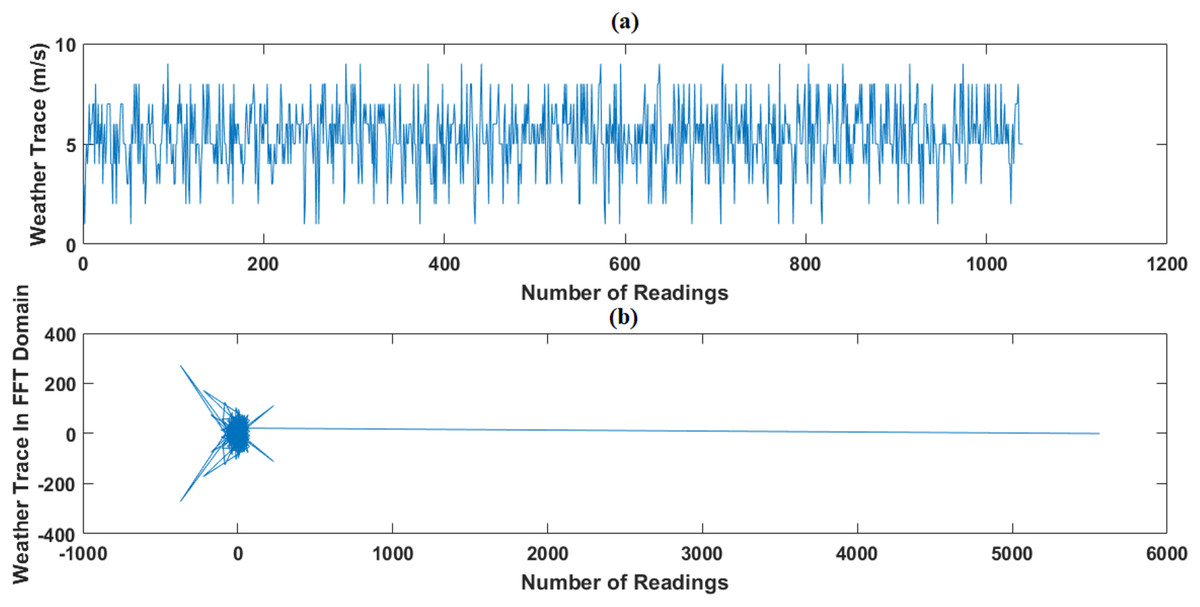
Figure 9: Weather trace in FFT domain: (A) the original data and (B) the sparse signal representation.
{kind=link}
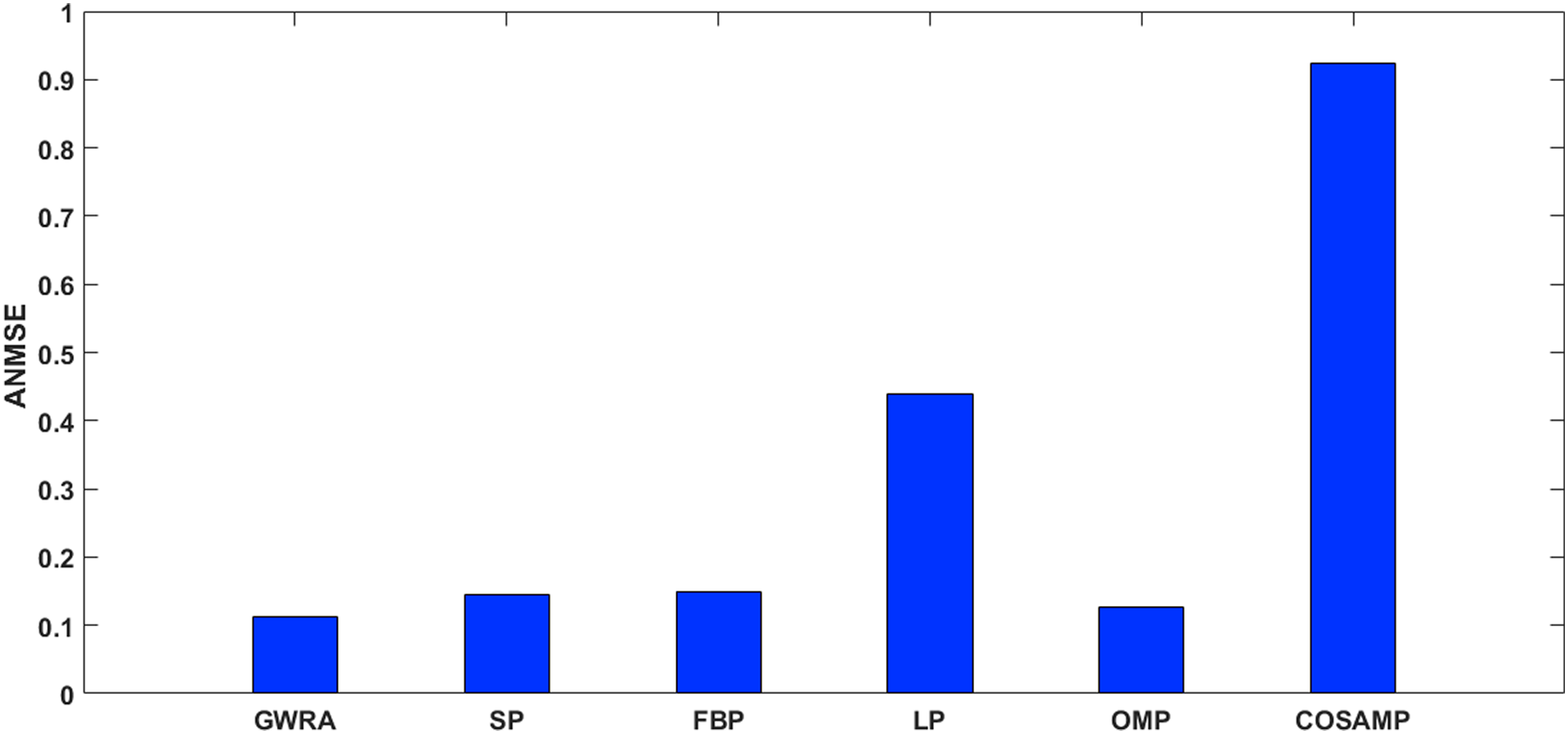
Figure 10 shows the ANMSE of GWRA, CoSaMP, OMP, FBP, LP and SP using DCT domain. It is clear that GWRA achieves the great performance in reducing ANMSE than other algorithms in case of using DCT as a signal transformer. Figure 11 shows that using FFT domain as signal transformer, the ANMSE of all algorithms increases, but still GWRA provides the best performance.
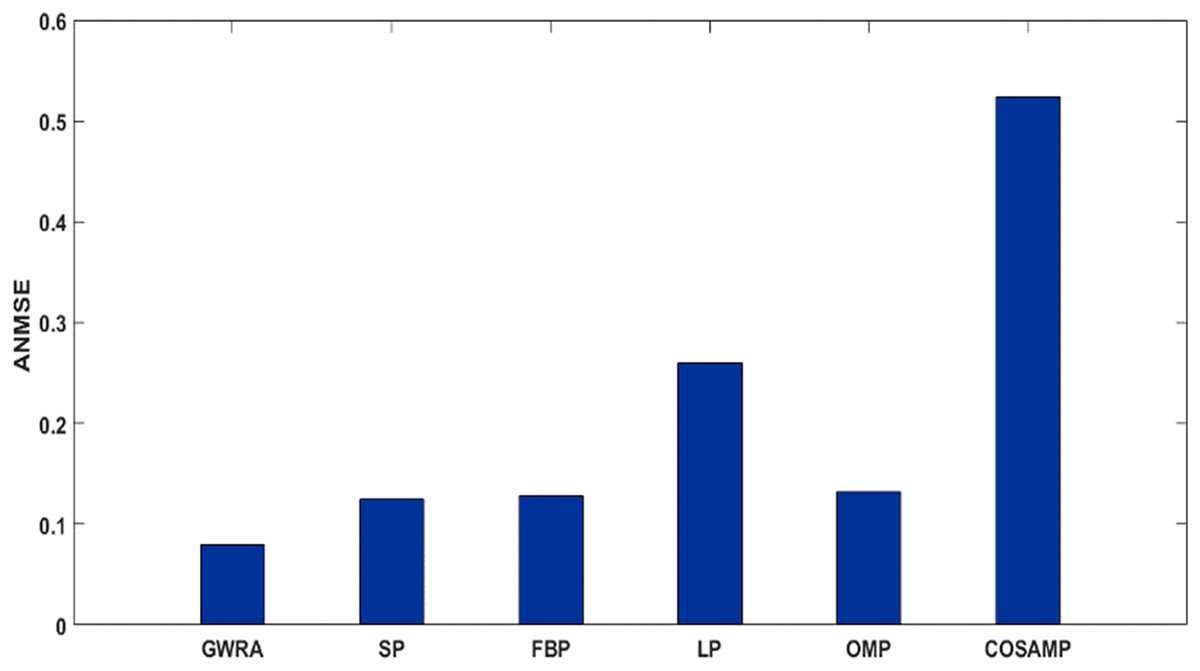
Figure 10: ANMSE in GWRA, SP, FBP, LP, OMP and CoSaMP algorithms using DCT domain (case study).
{kind=link}
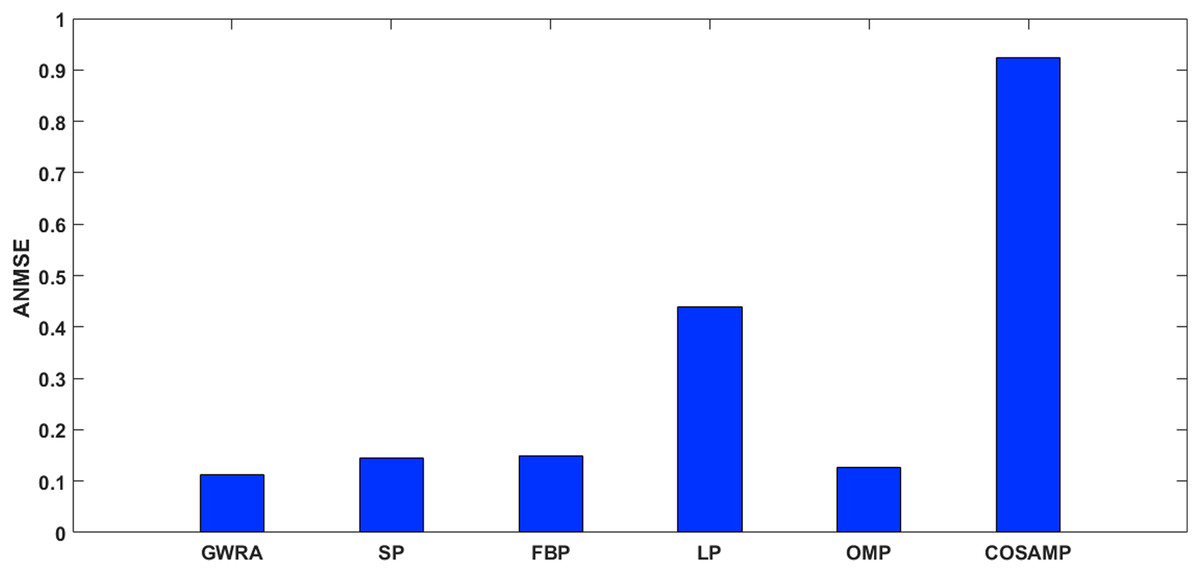
Figure 11: ANMSE in GWRA, SP, FBP, LP, OMP and CoSaMP algorithms using FFT domain (case study).
{kind=link}
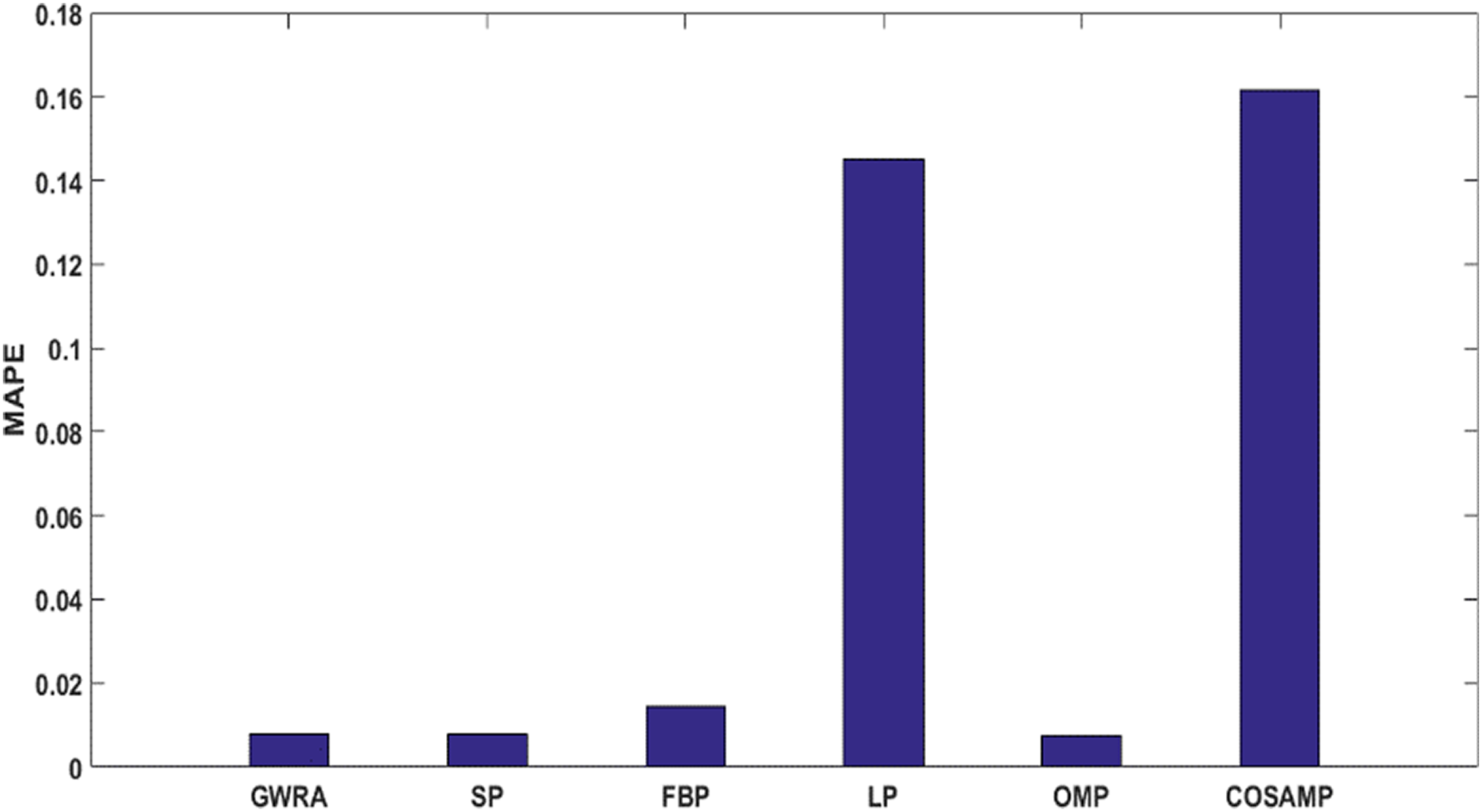
As a last test in case study, the performance of GWRA, SP, FBP, LP, OMP and CoSaMP are evaluated in terms of MAPE. It shows that GWRA still succeeds to be superior in the reconstruction performance than the others in terms of reducing MAPE as shown in Fig. 12.
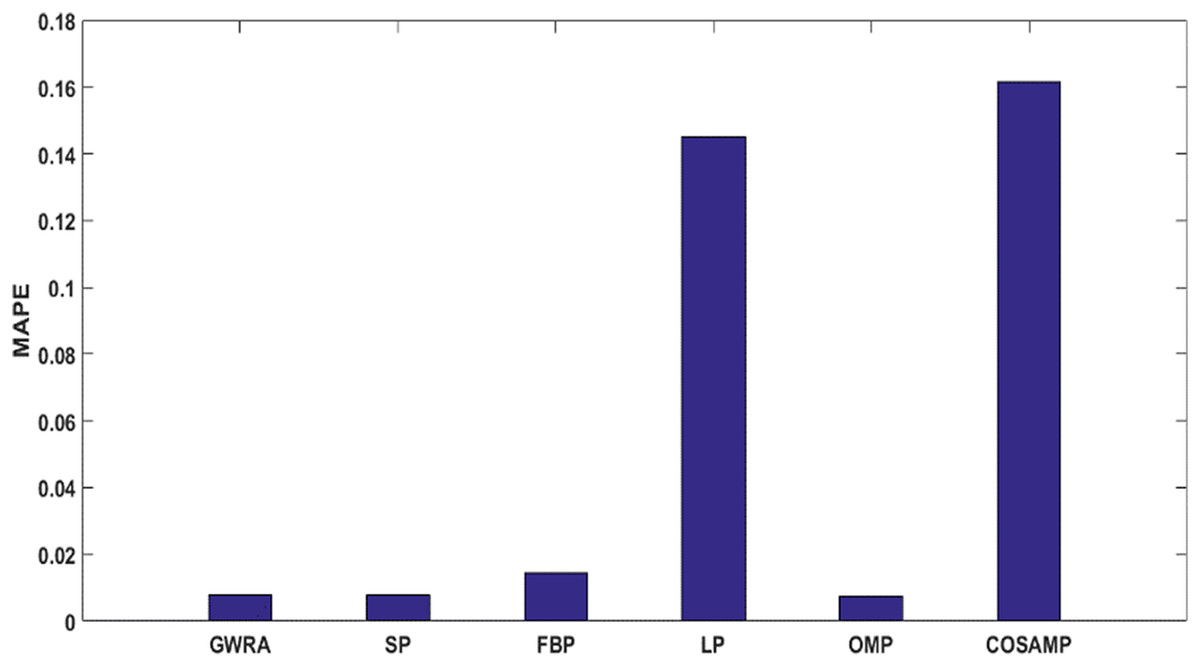
Figure 12: MAPE in GWRA, SP, FBP, LP, OMP and CoSaMP algorithms for weather trace (case study).
{kind=link}
Complexity analysis
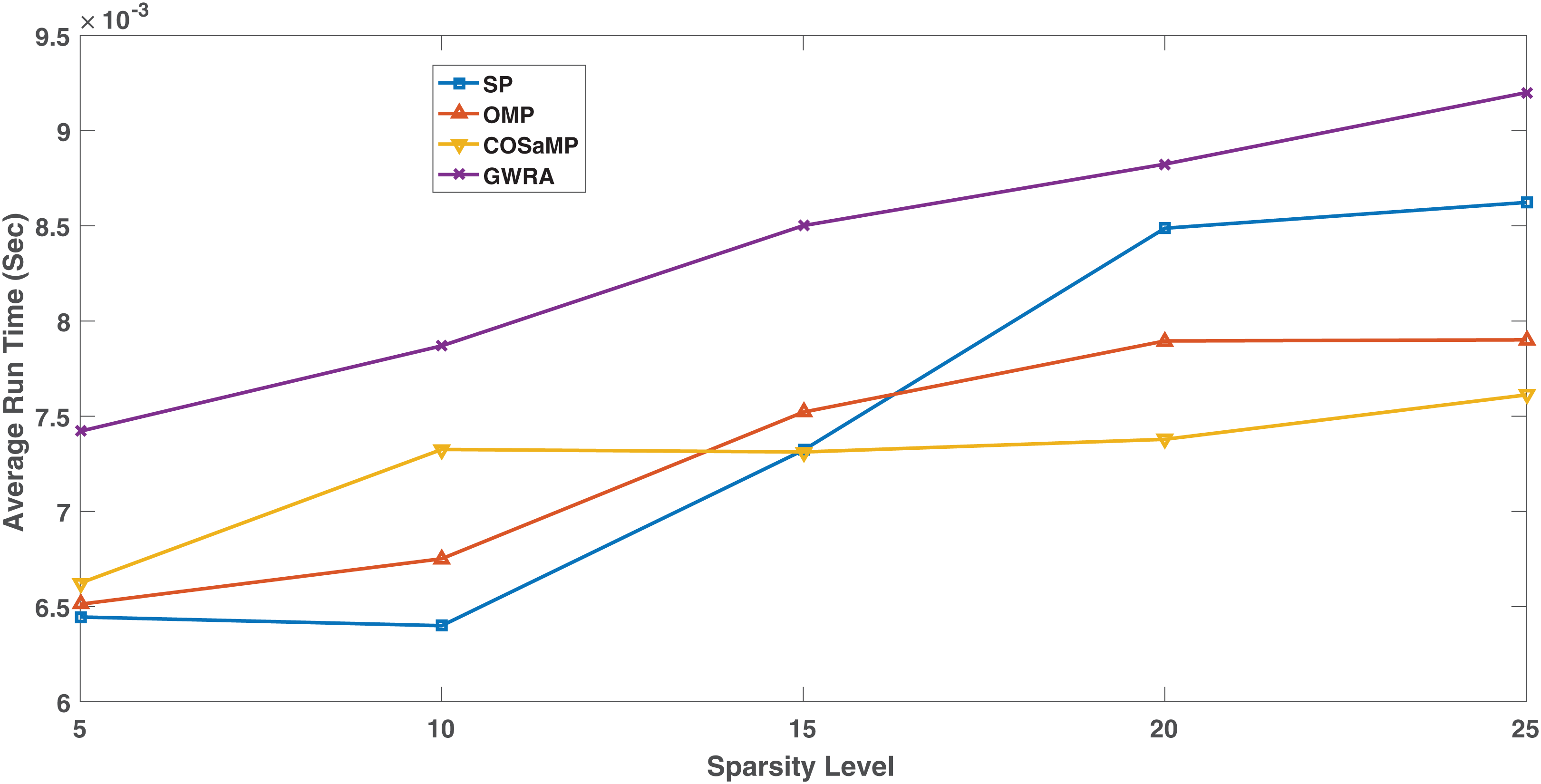
Figure 13 shows the complexity in the GWRA, OMP, CoSaMP and SP algorithms. It is clear that as swarm algorithm, the complexity of the proposed algorithm is higher than the GA but it is more efficient in data reconstruction. However, the high complexity in GWRA does not represent a problem, since the algorithms will be executed at the BS which has enough hardware capability and not energy constraint.
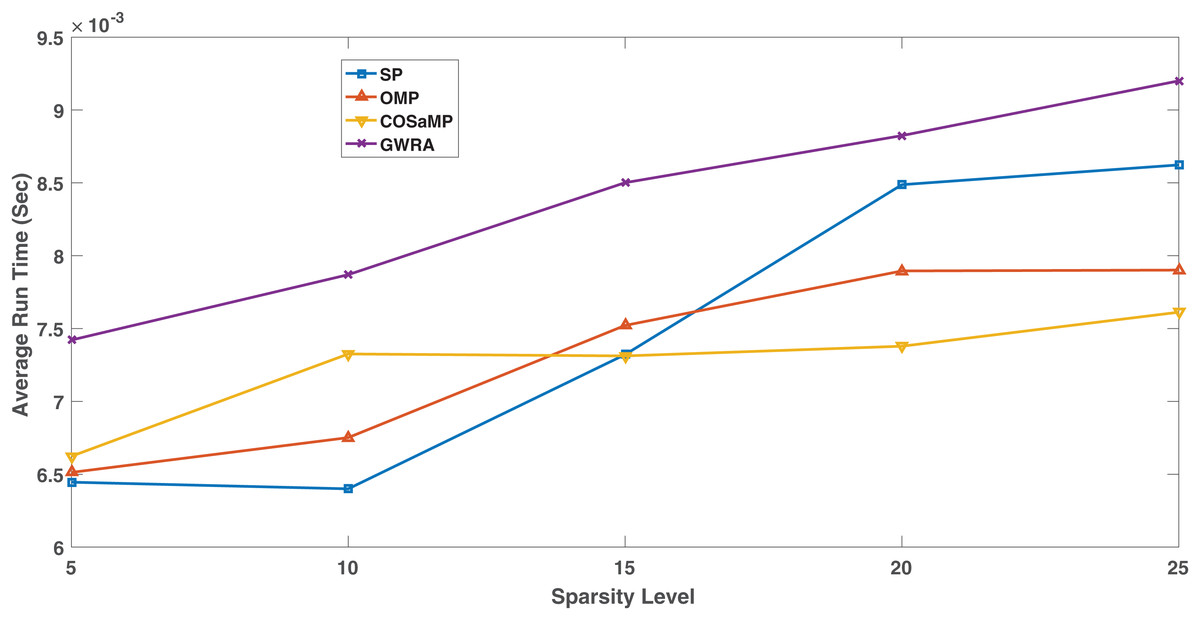
Figure 13: Complexity comparison GWRA, OMP, CoSaMP and SP algorithms.
{kind=link}
Image reconstruction test
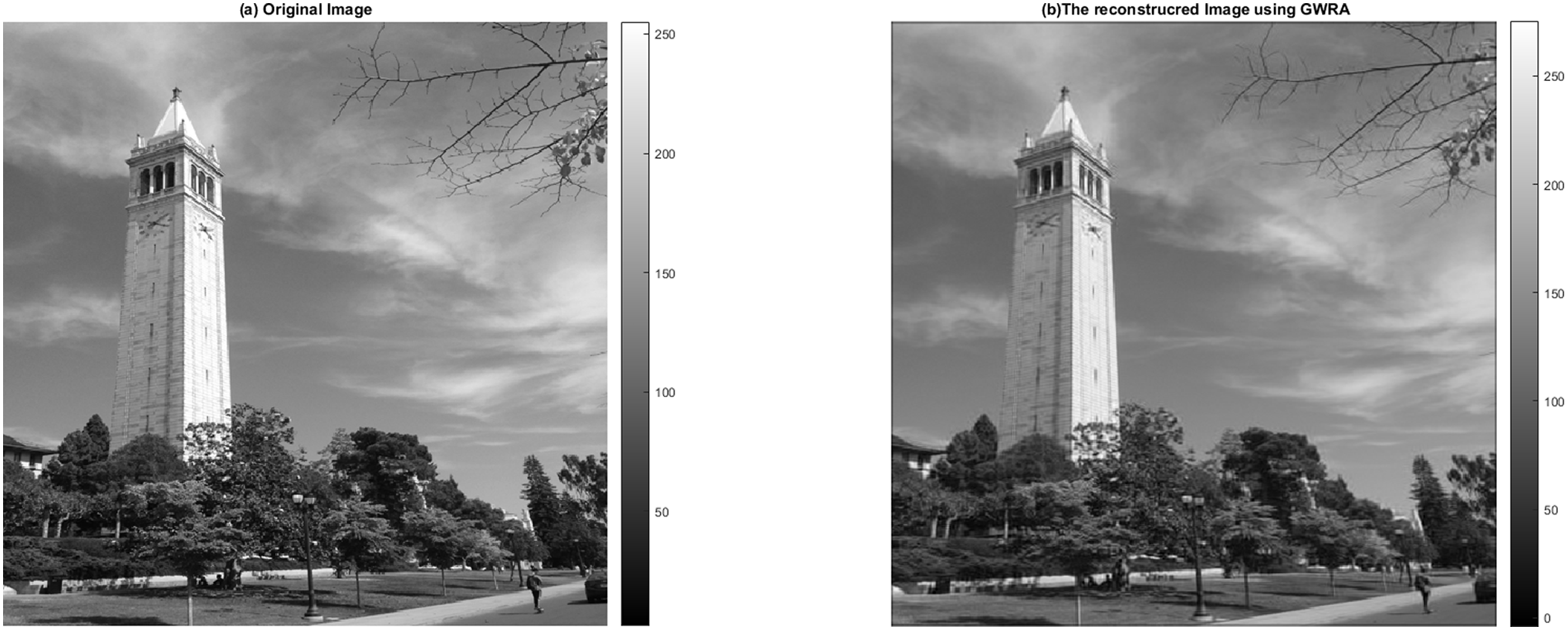
In this test, we aim to evaluate the reconstruction performance of the GWRA, where it is used to reconstruct 512 × 512 campanile image, which is a typical sight on the Berkeley campus (https://github.com/dfridovi/compressed_sensing) (Fridovich-Keil & Kuo, 2019), as shown in Fig. 14. It can be noted that GWRA efficiently succeeds to reconstruct the test image with small error which proves the efficiency of GWRA.
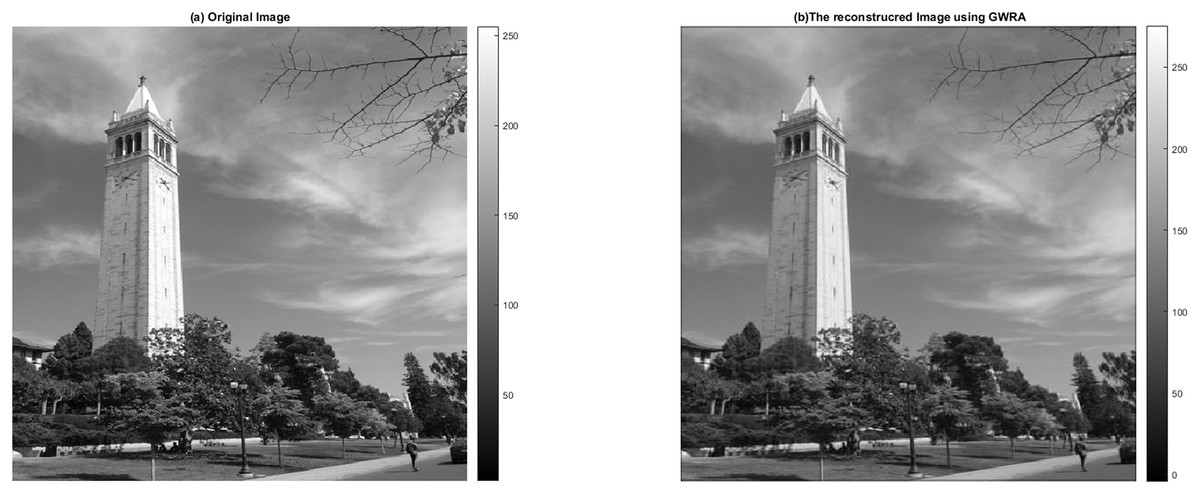
Figure 14: GWRA based image reconstruction test: (A) original image and (B) the reconstructed image.
{kind=link}
Conclusion
In this paper, a novel reconstruction approach for CS signal, based on GWO has been presented which integrates between GA and GWO algorithms to utilize their advantages in fast implementation and finding optimal solutions. In the provided experiments, GWRA exhibited better reconstruction performance for Gaussian and Uniform sparse signals. GWRA achieved overwhelming success over the traditional GA algorithms CoSaMP, OMP, FBP and SP. Also, GWRA provided better reconstruction performance than other swarm algorithms BA and PSO. GWRA successfully reconstructed datasets of weather observations as a case study and it is shown that GWRA succeeded to recover the data correctly with lesser ANMSE and MAPE than compared with existing algorithms. The demonstrated performance prove that GWRA is a promising technique that provides significant reduction in reconstruction errors.