
Multi-view data visualisation via manifold learning
- Published
- Accepted
- Received
- Academic Editor
- Shibiao Wan
- Subject Areas
- Computational Biology, Algorithms and Analysis of Algorithms, Data Mining and Machine Learning, Data Science, Visual Analytics
- Keywords
- Multi-modal data, Multi-view data, Data visualisation, Data clustering, Manifold learning
- Copyright
- © 2024 Rodosthenous et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. Multi-view data visualisation via manifold learning. PeerJ Computer Science 10:e1993 https://doi.org/10.7717/peerj-cs.1993
Abstract
Non-linear dimensionality reduction can be performed by manifold learning approaches, such as stochastic neighbour embedding (SNE), locally linear embedding (LLE) and isometric feature mapping (ISOMAP). These methods aim to produce two or three latent embeddings, primarily to visualise the data in intelligible representations. This manuscript proposes extensions of Student’s t-distributed SNE (t-SNE), LLE and ISOMAP, for dimensionality reduction and visualisation of multi-view data. Multi-view data refers to multiple types of data generated from the same samples.
The proposed multi-view approaches provide more comprehensible projections of the samples compared to the ones obtained by visualising each data-view separately. Commonly, visualisation is used for identifying underlying patterns within the samples. By incorporating the obtained low-dimensional embeddings from the multi-view manifold approaches into the K-means clustering algorithm, it is shown that clusters of the samples are accurately identified. Through extensive comparisons of novel and existing multi-view manifold learning algorithms on real and synthetic data, the proposed multi-view extension of t-SNE, named multi-SNE, is found to have the best performance, quantified both qualitatively and quantitatively by assessing the clusterings obtained.
The applicability of multi-SNE is illustrated by its implementation in the newly developed and challenging multi-omics single-cell data. The aim is to visualise and identify cell heterogeneity and cell types in biological tissues relevant to health and disease. In this application, multi-SNE provides an improved performance over single-view manifold learning approaches and a promising solution for unified clustering of multi-omics single-cell data.
Introduction
Data visualisation is an important and useful component of exploratory data analysis, as it can reveal interesting patterns in the data and potential clusters of the observations. A common approach for visualising high-dimensional data (data with a higher number of features ( ) than samples ( ), i.e. ) is by reducing its dimensions. Linear dimensionality reduction methods, including principal component analysis (PCA) (Jolliffe & Cadima, 2016) and non-negative matrix factorization (NMF) (Garcia et al., 2018), assume linearity within data sets and as a result these methods often fail to produce reliable representations when linearity does not hold. Manifold learning, an active research area within machine learning, in contrast to the linear dimensionality reduction approaches do not rely on any linearity assumptions. By assuming that the dimensions of the data sets are artificially high, manifold learning methods aim to capture important information with minimal noise, in an induced low-dimensional embedding (Zheng & Xue, 2009). The generated low-dimensional embeddings can be used for data visualisation in the 2-D or 3-D spaces.
Manifold learning approaches used for dimensionality reduction and visualisation, focus on preserving at least one of the characteristics of the data. For example, the stochastic neighbour embedding (SNE) preserves the probability distribution of the data (Hinton & Roweis, 2003). The locally linear embedding (LLE) proposed by Roweis & Saul (2000) is a neighbourhood-preserving method. The isometric feature mapping (ISOMAP) proposed by Tenenbaum, Silva & Langford (2000) is a quasi-isometric method based on multi-dimensional scaling (Kruskal, 1964). Spectral Embedding finds low-dimensional embeddings via spectral decomposition of the Laplacian matrix (Ng, Jordan & Weiss, 2001). The Local Tangent Space Alignment method proposed by Zhang & Zha (2004) learns the embedding by optimising local tangent spaces, which represent the local geometry of each neighbourhood, and uniform manifold approximation and projection (UMAP) preserves the global structure of the data by constructing a theoretical framework based on Riemannian geometry and algebraic topology (McInnes et al., 2018).
This manuscript focuses on data visualisation of multi-view data, which are regarded as different types of data sets that are generated on the same samples of a study. It is very common nowadays in many different fields to generate multiple data-views on the same samples. For example, multi-view imaging data describe distinct visual features such as local binary patterns (LBP), and histogram of oriented gradients (HOG) (Shen, Tao & Ma, 2013), while multi-omics data, e.g. proteomics, genomics, etc, in biomedical studies quantify different aspects of an organism’s biological processes (Hasin, Seldin & Lusis, 2017). Through the collection of multi-view data, researchers are interested in better understanding the collected samples, including their visualisation, clustering and classification. Analysing simultaneously the multi-view data is not a straightforward task, as each data-view has its own distribution and variation pattern (Rodosthenous, Shahrezaei & Evangelou, 2020).
Several approaches have been proposed for the analysis of multi-view data. These include methods on clustering (Kumar, Rai & Hal, 2011; Liu et al., 2013; Sun et al., 2015; Ou et al., 2016; Ye et al., 2018; Ou et al., 2018; Wang & Allen, 2021), classification (Shu, Zhang & Tang, 2019), regression (Li, Liu & Chen, 2019) and dimensionality reduction (Rodosthenous, Shahrezaei & Evangelou, 2020; Sun, 2013; Zhao et al., 2018; Xu, Tao & Xu, 2015). Multi-view approaches have been reviewed and discussed in the overview articles of Xu, Tao & Xu (2013) and Zhao et al. (2017). Another field that has dealt with multi-view data is representation learning. In the multi-view representation learning survey of Li, Liu & Chen (2019) two main strategies were identified: alignment and fusion. Fusion methods include both graphical models and neural network models.
In this manuscript, we focus on the visualisation task through manifold learning. By visualising multi-view data collectively the aim is to obtain a global overview of the data and identify patterns that would have potentially be missed if each data-view was visualised separately. Typically, multiple visualisations are produced, one from each data-view, or the features of the data-views are concatenated to produce a single visualisation. The former could provide misleading outcomes, with each data-view revealing different visualisations and patterns. The different statistical properties, physical interpretation, noise and heterogeneity between data-views suggest that concatenating features would often fail in achieving a reliable interpretation and visualisation of the data (Fu et al., 2008).
A number of multi-view visualisation approaches have been proposed in the literature, with some of these approaches based on the manifold approaches t-SNE and LLE. For example, Xie et al. (2011) proposed m-SNE that combines the probability distributions produced by each data-view into a single distribution via a weight parameter. The algorithm then implements t-SNE on the combined distribution to obtain a single low-dimensional embedding. The proposed solution finds the optimal choice for both the low-dimensional embeddings and the weight parameter simultaneously. Similarly, Kanaan Izquierdo (2017) proposed two alternative solutions based on t-SNE, named MV-tSNE1 and MV-tSNE2. MV-tSNE2 is similar to m-SNE combining the probability distributions through expert opinion pooling.
Portions of this text were previously published as part of a preprint (https://doi.org/10.48550/arXiv.2101.06763). In parallel to our work, Canzar & Hoan Do (2021) proposed a multi-view extension of t-SNE, named j-SNE. Both multi-SNE and j-SNE firstly appeared as preprints in January 2021 https://doi.org/10.1101/2021.01.10.426098. J-SNE produces low-dimensional embeddings through an iterative procedure that assigns each data-view a weight value that is updated per iteration through regularisation.
In addition, Shen, Tao & Ma (2013) proposed multi-view locally linear embeddings (m-LLE) that is an extension of LLE for effectively retrieving medical images. M-LLE produces a single low-dimensional embedding by integrating the embeddings from each data-view according to a weight parameter , which refers to the contribution of each data-view. Similarly to m-SNE, the algorithm optimizes both the weight parameter and the embeddings simultaneously. Zong et al. (2017) proposed MV-LLE that minimises the cost function by assuming a consensus matrix across all data-views.
Building on the existing literature work, we propose here alternative extensions to the manifold approaches: t-SNE, LLE, and ISOMAP, for visualising multi-view data. The cost functions of our proposals are different from the existing ones, as they integrate the available information from the multi-view data iteratively. At each iteration, the proposed multi-SNE updates the low-dimensional embeddings by minimising the dissimilarity between their probability distribution and the distribution of each data-view. The total cost of this approach equals to the weighted sum of those dissimilarities. Our proposed variation of LLE, Multi-LLE, constructs the low-dimensional embeddings by utilising a consensus weight matrix, which is taken as the weighted sum of the weight matrices computed by each data-view. Lastly, the low-dimensional embeddings in the proposed multi-ISOMAP are constructed by using a consensus graph, for which the nodes represent the samples and the edge lengths are taken as the averaged distance between the samples in each data-view. M-ISOMAP is proposed as an alternative ISOMAP-based multi-view manifold learning algorithm. Similar to m-SNE and m-LLE, m-ISOMAP provide a weighted integration of the low-dimensional embeddings produced by the implementation of ISOMAP on each data-view separately.
As the field of multi-view data analysis is relatively new, the literature lacks comparative studies between multi-view manifold learning algorithms. This manuscript makes a novel contribution to the field by conducting extensive comparisons between the multi-view non-linear dimensionality reduction approaches proposed in this manuscript, multi-SNE, multi-LLE, multi-ISOMAP and m-ISOMAP with other approaches proposed in the literature. These comparisons are conducted on both real and synthetic data that have been designed to capture different data characteristics. The aim of these comparisons is to identify the best-performing algorithms, discuss pitfalls of the approaches and guide the users to the most appropriate solution for their data.
We illustrate that our proposals result to more robust solutions compared to the approaches proposed in the literature, including m-SNE, m-LLE and MV-SNE. We further illustrate through the visualisation of the low-dimensional embeddings produced by the proposed multi-view manifold learning algorithms, that if clusters exist within the samples, they can be successfully identified. We show that this can be achieved by applying the K-means algorithm on the low-dimensional embeddings of the data. The K-means (MacQueen, 1967) was chosen to cluster the data points, as it is one of the most famous and prominent partition clustering algorithms (Xu & Tian, 2015). A better clustering performance by K-means suggests a visually clearer separation of clusters. Through the conducted experiments, we show that the proposed multi-SNE approach recovers well-separated clusters of the data, and has comparable performance to multi-view clustering algorithms that exist in the literature.
Materials and Methods
In this section, the proposed approaches for multi-view manifold learning are described. This section starts with an introduction of the notation used throughout this manuscript. The proposed multi-SNE, multi-LLE and multi-ISOMAP are described in Sections “Multi-SNE”, “Multi-LLE” and “Multi-ISOMAP”, respectively. The section ends with a description of the process for tuning the parameters of the algorithms.
Notation
Throughout this article, the following notation is used:
N: The number of samples.
: The number of variables of the design matrix.
: A single-view data matrix, representing the original high-dimensional data used as input; is the data point of X.
M: The number of data-views in a given data set; represents an arbitrary data-view.
: The data-view of multi-view data; is the data point of .
: A low-dimensional embedding of the original data. represents the data point of Y. In this manuscript, , as the focus of the manuscript is on data visualisation.
Multi-SNE
SNE, proposed by Hinton & Roweis (2003), measures the probability distribution, P of each data point by looking at the similarities among its neighbours. For every sample in the data, is taken as its potential neighbour with probability , given by
(1) where represents the dissimilarity between points and . The value of is either set by hand or found by binary search (van der Maaten & Hinton, 2008). Based on this value, a probability distribution of sample , , with fixed perplexity is produced. Perplexity refers to the effective number of local neighbours and it is defined as , where is the Shannon entropy of . It increases monotonically with the variance and typically takes values between and .
In the same way, a probability distribution in the low-dimensional space, Y, is computed as follows:
(2) which represents the probability of point selecting point as its neighbour.
The induced embedding output, , represented by probability distribution, Q, is obtained by minimising the Kullback-Leibler divergence (KL-divergence) between the two distributions P and Q (Kullback & Leibler, 1951). The aim is to minimise the cost function:
(3)
Hinton & Roweis (2003) assumed a Gaussian distribution in computing the similarity between two points in both high and low dimensional spaces. van der Maaten & Hinton (2008) proposed a variant of SNE, called t-SNE, which uses a symmetric version of SNE and a Student t-distribution to compute the similarity between two points in the low-dimensional space Q, given by
(4)
T-SNE is often preferred, because it reduces the effect of crowding problem (limited area to accommodate all data points and differentiate clusters) and it is easier to optimise, as it provides simpler gradients than SNE (van der Maaten & Hinton, 2008).
We propose multi-SNE, a multi-view manifold learning algorithm based on t-SNE. Our proposal computes the KL-divergence between the distribution of a single low-dimensional embedding and each data-view of the data separately, and minimises their weighted sum. An iterative algorithm is proposed, in which at each iteration the induced embedding is updated by minimising the cost function:
(5) where is the combination coefficient of the data-view. The vector acts as a weight vector that satisfies . In this study, equal weights on all data-views were considered, i.e. . The algorithm of the proposed multi-SNE approach is presented in Algorithm 1 of Section 1 in the Supplemental File.
An alternative multi-view extension of t-SNE, called m-SNE was proposed by Xie et al. (2011). M-SNE applies t-SNE on a single distribution in the high-dimensional space, which is computed by combining the probability distributions of the data-views, given by . The coefficients (or weights) share the same role as in multi-SNE and similarly satisfies . This leads to a different cost function than the one in Eq. (5).
Kanaan Izquierdo (2017) proposed a similar cost function for multi-view t-SNE, named MV-tSNE1, given as follows:
(6)
Their proposal is a special case of multi-SNE, with . Kanaan Izquierdo (2017) did not pursue MV-tSNE1 any further, but instead, they proceeded with an alternative solution, MV-tSNE2, which combines the probability distributions (similar to m-SNE) through expert opinion pooling. A comparison between multi-SNE, m-SNE and MV-tSNE2 is presented in Fig. S2 of Section 4.1 in the Supplemental File. Based on two real data sets, multi-SNE and m-SNE outperformed MV-tSNE2, with the solution by multi-SNE producing the best separation among the clusters in both examples.
Multi-SNE avoids combining the probability distributions of all data-views together. Instead, the induced embeddings are updated by minimising the KL-divergence between every data-view’s probability distribution and that of the low-dimensional representation we seek to obtain. In other words, this is achieved by computing and summing together the gradient descent for each data-view. The induced embedding is then updated by minimising the summed gradient descent.
Throughout this article, for all variations of t-SNE we have applied the PCA pre-training step proposed by van der Maaten & Hinton (2008). van der Maaten & Hinton (2008) discussed that by reducing the dimensions of the input data through PCA the computational time of t-SNE is reduced. In this article, the principal components taken retained at least of the total variation (variance explained) in the original data. In addition, as the multi-SNE algorithm is an iterative algorithm we opted for running the algorithm for 1,000 iterations for all analyses conducted. Alternatively, a stopping rule could have been implemented with the iterative algorithm to stop after no significant changes were observed to the cost-function. Both these options are available at the implementation of the multi-SNE algorithm.
Multi-LLE
LLE attempts to discover a non-linear structure of high-dimensional data, X, by computing low-dimensional and neighbourhood-preserving embeddings, Y (Saul & Roweis, 2001). The main three steps of the algorithm are:
-
1.
The set, denoted by , contains the K nearest neighbours of each data point . The most common distance measure between the data points is the Euclidean distance. Other local metrics can also be used in identifying the nearest neighbours (Roweis & Saul, 2000).
-
2.
A weight matrix, W, is computed, which acts as a bridge between the high-dimensional space in X and the low-dimensional space in Y. Initially, W reconstructs X, by minimising the cost function:
(7) where the weights describe the contribution of the data point to the reconstruction. The optimal weights are found by solving the least squares problem given in Eq. (7) subject to the constraints:
(a) , if , and
(b)
-
3.
Once W is computed, the low-dimensional embedding of each data point , is obtained by minimising:
(8)
The solution to Eq. (8), is obtained by taking the bottom non-zero eigenvectors of the sparse matrix, (Roweis & Saul, 2000).
We propose multi-LLE, a multi-view extension of LLE, that computes the low-dimensional embeddings by using the consensus weight matrix:
(9) where , and is the weight matrix for each data-view . Thus, is obtained by solving:
The multi-LLE algorithm is presented in Algorithm 2 of Section 1 in the Supplemental File.
Shen, Tao & Ma (2013) proposed m-LLE, an alternative multi-view extension of LLE. The LLE embeddings of each data-view are combined and LLE is applied to each data-view separately. The weighted average of those embeddings is taken as the unified low-dimensional embedding. In other words, computing the weight matrices and solving , for each separately. Thus, the low-dimensional embedding is computed by , where .
An alternative multi-view LLE solution was proposed by Zong et al. (2017) to find a consensus manifold, which is then used for multi-view clustering via non-negative matrix factorization; we refer to this approach as MV-LLE. This solution minimises the cost function by assuming a consensus weight matrix across all data-views, as given in Eq. (9). The optimisation is then solved by using the Entropic Mirror Descent Algorithm (EMDA) (Beck & Teboulle, 2003). In contrast to m-LLE and MV-LLE, multi-LLE combines the weight matrices obtained from each data-view, instead of the LLE embeddings. No comparisons were conducted between MV-LLE and the proposed multi-LLE, as the code of the MV-LLE algorithm is not publicly available.
Multi-ISOMAP
ISOMAP aims to discover a low-dimensional embedding of high-dimensional data by maintaining the geodesic distances between all points (Tenenbaum, Silva & Langford, 2000); it is often regarded as an extension of Multi-dimensional Scaling (MDS) (Kruskal, 1964). The ISOMAP algorithm comprises of the following three steps:
-
Step 1.
A graph is defined. Let define a neighbourhood graph, with vertices V representing all data points. The edge length between any two vertices is defined by the distance metric , measured by the Euclidean distance. If a vertex does not belong to the K nearest neighbours of , then . The parameter K is given as input, and it represents the connectedness of the graph G; as K increases, more vertices are connected.
-
Step 2.
The shortest paths between all pairs of points in G are computed. The shortest path between vertices is defined by . Let be a matrix containing the shortest paths between any vertices , defined by .
The most efficient known algorithm to perform this task is Dijkstra’s Algorithm (Dijkstra, 1959). In large graphs, an alternative approach to Dijkstra’s Algorithm would be to initialize and replace all entries by .
-
Step 3.
The low-dimensional embeddings are constructed. The component of the low-dimensional embedding is given by , where the component of eigenvector and is the eigenvalue in decreasing order of the the matrix (Tenenbaum, Silva & Langford, 2000). The operator, is defined by , where S is the matrix of squared distances defined by , and H is defined by . This is equivalent to applying classical MDS to , leading to a low-dimensional embedding that best preserves the manifold’s estimated intrinsic geometry.
Multi-ISOMAP is our proposal for adapting ISOMAP on multi-view data. Let be a neighbourhood graph obtained from data-view as defined in the first step of ISOMAP. All neighbourhood graphs are then combined into a single graph, ; this combination is achieved by computing the edge length as the averaged distance of each data-view, i.e. . Once a combined neighbourhood graph is computed, multi-ISOMAP follows steps 2 and 3 of ISOMAP described above. For simplicity, the weights throughout this article were set as . The multi-ISOMAP algorithm is presented in Algorithm 3 of Section 1 in the Supplemental File.
For completion, we have in addition adapted ISOMAP for multi-view visualisation following the framework of both m-SNE and m-LLE. Following the same logic, m-ISOMAP combines the ISOMAP embeddings of each data-view by taking the weighted average of those embeddings as the unified low-dimensional embedding. In other words, the low-dimensional embedding is obtained by computing , where .
Parameter tuning
The multi-view manifold learning algorithms were tested on real and synthetic data sets for which the samples can be separated into several clusters. The true clusters are known and they were used to tune the parameters of the methods. To quantify the clustering performance, we used the following four extrinsic measures: (i) accuracy (ACC), (ii) Normalised Mutual Information (NMI) (Vinh, Epps & Bailey, 2010), (iii) Rand Index (RI) (Rand, 1971) and (iv) Adjusted Rand Index (ARI) (Hubert & Arabie, 1985). All measures take values in the range , with expressing complete randomness, and perfect separation between clusters. The mathematical formulas of the four measures are presented in Section 2 of the Supplemental File.
SNE, LLE and ISOMAP depend on parameters of which their proper tuning ensues to optimal results. LLE and ISOMAP depend on the number of nearest neighbours (NN). SNE depends on the Perplexity ( ) parameter, which is directly related to the number of nearest neighbours. Similarly, the multi-view extensions of the three methods depend on the same parameters. The choice of the parameter can influence the visualisations and in some cases present the data into separate maps (van der Maaten & Hinton, 2012).
By assuming that the data samples belong to a number of clusters that we seek to identify, the performance of the algorithms was measured for a range of tuning parameter values from the set . Note that for all algorithms, the parameter value cannot exceed the total number of samples in the data.
For all manifold learning approaches, the following procedure was implemented to tune the optimal parameters of each method per data set:
-
1.
The method was applied for all parameter values in the set .
-
2.
The K-means algorithm was applied to the low-dimensional embeddings produced for each parameter value
-
3.
The performance of the chosen method was evaluated quantitatively by computing ACC, NMI, RI and ARI for all tested parameter values.
The optimal parameter value was finally selected based on the evaluation measures. Section “Optimal Parameter Selection” explores how the different approaches are affected by their parameter values. For the other subsections of Section “Result”, the optimal parameter choice per approach was used for the comparison of the multi-view approaches. Section “Optimal Parameter Selection” presents the process of parameter tuning on the synthetic data analysed, and measures the performance of single-view and multi-view manifold learning algorithms. The same process was repeated for the real data analysed (Fig. S4 in Section 4.3 of the Supplemental File).
Data
Data sets with different characteristics were analysed to explore and compare the proposed multi-view manifold learning algorithms under different scenarios (Table 1). The methods were evaluated on data sets that have a different number of data-views, clusters and sample sizes. The generated synthetic data are considered homogeneous as they were generated under the same conditions and distributions. Both high-dimensional ( ) and low-dimensional data sets were analysed. Through these comparisons, we wanted to investigate how the multi-view methods perform and how they compare with single-view methods.
| Data description | |||||||
|---|---|---|---|---|---|---|---|
| Views (M) | Clusters ( ) | Features ( ) | Samples (N) | Hetero-geneous | High dimensional | ||
| Data set | |||||||
| Real | Cancer types | 3 | 3 | 22,503 | 253 | ✓ | ✓ |
| Caltech7 | 6 | 7 | 1,984 | 1,474 | ✓ | ✓ | |
| Handwritten digits | 6 | 10 | 240 | 2,000 | ✓ | ✗ | |
| −−−−−−− | |||||||
| Synthetic | MMDS | 3 | 3 | 300 | 300 | ✗ | ✗ |
| NDS | 4 | 3 | 400 | 300 | ✗ | ✓ | |
| MCS | 3 | 5 | 300 | 500 | ✗ | ✗ | |
In this section, we describe the synthetic and real data sets analysed in the manuscript. Some of the real data sets analysed have previously been used in the literature for examining different multi-view algorithms, for example, data integration (Wang et al., 2014) and clustering (Ou et al., 2018).
Synthetic data
A motivational multi-view example was constructed to qualitatively evaluate the performance of multi-view manifold learning algorithms against their corresponding single-view algorithms. Its framework was designed specifically to produce distinct projections of the samples from each data-view. Additional synthetic data sets were generated to explore how the algorithms behave when the separation between the clusters exists, but it is not as explicit as in the motivational example.
All synthetic data were generated using the following process. For the same set of samples, a specified number of data-views were generated, with each data-view capturing different information of the samples. Each data-view, follows a multivariate normal distribution with mean vector and covariance matrix , where is the number of features in the data-view. The matrix represents a identity matrix. For each data-view, different values were chosen to distinguish the clusters. Noise, ε, following a multivariate normal distribution with mean and covariance matrix was added to increase randomness within each data-view. Noise, , increases the variability within a given data-view. The purpose of this additional variability is to assess whether the algorithms are able to equally capture information from all data-views and are not biased towards the data-view(s) with a higher variability. Thus, noise, , was only included in selected data-views and opted out from the rest. Although this strategy is equivalent to sampling once using larger variance, the extra noise explicitly distinguishes the highly variable data-view with the rest.
In other words, , where MV N represents multivariate normal distribution. Distinct polynomial functions (e.g. ) were randomly generated for each cluster in all data-views and applied to the relevant samples to express non-linearity and to distinguish them into clusters (e.g. the same polynomial function was used for all samples that belong in the same cluster). The last step was performed to ensure that linear dimensionality reduction methods (e.g. PCA) would not successfully cluster the data.
The three synthetic data sets with their characteristics are described next.
Motivational multi-view data scenario
Assume that the truth underlying structure of the data separates the samples into three true clusters as presented in Fig. 1. Each synthetic data-view describes the samples differently, which results in three distinct clusterings, none of which reflects the global underlying truth. In particular, the first view separates only cluster C from the others (View 1 in Fig. 1), the second view separates only cluster B (View 2) and the third view separates only cluster A (View 3). In this scenario, only the third data-view contained an extra noise parameter, , suggesting a higher variability than the other two data-views.
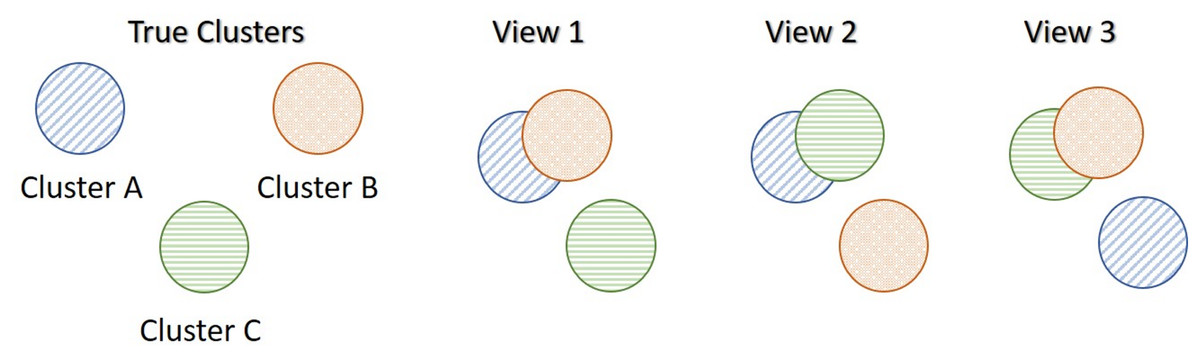
Figure 1: Motivational multi-view data scenario (MMDS).
Each data-view captures different characteristics of the three clusters, and thus produces different clusterings.{kind=link}
Noisy data-view scenario
A synthetic data set which consists of four data-views and three true underlying clusters was generated. The first three data-views follow the same structure as MMDS, while the data-view represents a completely noisy data-view, i.e. with all data points lying in a single cluster. The rationale for creating such a data set is to examine the effect of the noisy data views in the multi-view visualisation and clustering. This data set was used to show that the multi-view approaches can identify not useful data-views and discard them. For equally balanced data samples, the data-views contain features. To summarise, noisy data-view scenario (NDS) adds a noisy data-view to the MMDS data set.
More clusters than data-views scenario
A synthetic data set that was generated similarly to MMDS but with five true underlying clusters instead of three. The true underlying structure of the each data-view is shown in Fig. 2. In this data set, features were generated on , equally balanced data samples. In comparison with MMDS, more clusters than data-views scenario (MCS) contains more clusters, but the same number of data-views. Similarly to MMDS and NDS, in this scenario, only the third data-view contained an extra noise parameter, , suggesting a higher variability than the other two data-views.
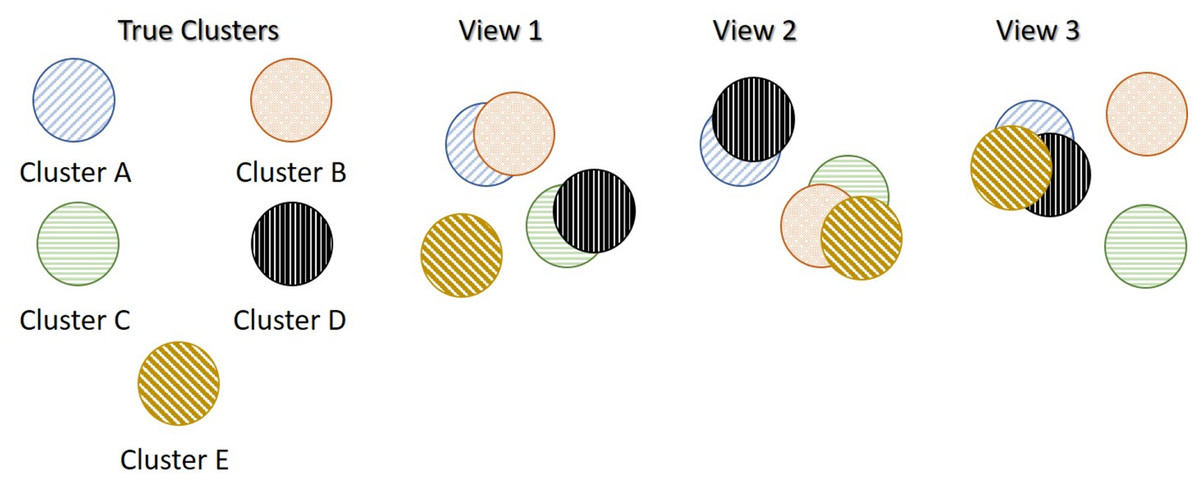
Figure 2: More clusters than data-views Scenario (MCS).
In this example, there are three data views and five true underlying clusters. Each data-view captures different characteristics of the five clusters, and thus produces different clusterings.{kind=link}
Real data
The three real data sets analysed in the study are described below.
Cancer types (http://compbio.cs.toronto.edu/SNF/SNF/Software.html)
This data set includes patients with breast cancer, with kidney cancer and with lung cancer. For each patient the three data-views are available: (a) genomics ( genes), (b) epigenomics ( methylation sites) and (c) transcriptomics ( mi-RNA sequences). The aim is to cluster patients by their cancer type (Wang et al., 2014).
Caltech7 (https://Github.com/yeqinglee/mvdata)
Caltech-101 contains pictures of objects belonging to 101 categories. This publicly available subset of Caltech-101 contains seven classes. It consists of 1,474 objects on six data-views: (a) Gabor ( ), (b) wavelet moments ( ), (c) CENTRIST ( ), (d) histogram of oriented gradients ( ), (e) GIST ( ), and (f) local binary patterns ( ) (Fei-Fei, Fergus & Pietro, 2006).
Handwritten digits (https://archive.ics.uci.edu/ml/datasets/Multiple+Features)
This data set consists of features on handwritten numerals ( ) extracted from a collection of Dutch utility maps. Per class patterns have been digitised in binary images (in total there are 2,000 patterns). These digits are represented in terms of six data-views: (a) Fourier coefficients of the character shapes ( ), (b) profile correlations ( ), (c) Karhunen-Love coefficients ( ), (d) pixel averages in 2 × 3 windows ( ), (e) Zernike moments ( ) and (f) morphological features ( ) (Dua & Graff, 2017).
The handwritten digits data set is characterised by having perfectly balanced data samples; each of the 10 clusters contains exactly numerals. On the other hand, caltech7 is an imbalanced data set with the first two clusters containing many more samples than the other clusters. The number of samples in each cluster is {A: 435, B: 798, C: 52, D: 34, E: 35, F: 64, G: 56}. The performance of the methods was explored on both the imbalanced caltech7 data set and a balanced version of the data, for which samples from clusters A and B were randomly selected.
Results
In this section, we illustrate the application and evaluation of the proposed multi-view extensions of t-SNE, LLE and ISOMAP on real and synthetic data. Comparisons between the multi-view solutions, along with their respective single-view solutions are implemented. A trivial solution would be to concatenate the features of all data-views into a large single dataset and apply on that dataset a single-view manifold learning algorithm; such comparisons are explored in this section. Since it is likely that each data-view has different variance, each data-view was normalised before concatenation to ensure same variability across all data-views. Normalisation was achieved by removing the mean and dividing by the standard deviation of each feature in all data-views.
In the following subsections we have addressed the following:
-
1.
Can multi-view manifold learning approaches obtain better visualisations than single-view approaches? The performance of the multi-view approaches in visualising the underlying structure of the data is illustrated. Section “Optimal Parameter Selection” further illustrates how the underlying structure is misrepresented when individual data sets or the concatenated data set are visualised.
-
2.
The visualisations of multi-view approaches are quantitatively evaluated using K-means. Section “Multi-view Manifold Learning for Clustering” shows how extracting the low dimensional embeddings of the multi-view approaches and inputting them as features in the clustering algorithm K-means. We have quantitatively evaluated the performance of the approaches for identifying underlying clusters and patterns within the data.
-
3.
The effect of the parameter values on the multi-view manifold learning approaches was explored. As discussed the proposed multi-view manifold approaches depend on a parameter that requires tuning. Section “Optimal Parameter Selection” presents a series of experiments that we investigated the effect that the parameter value has on each approach. This was done by exploring both the visualisations produced and by evaluating the clustering of the approaches for different parameter values.
-
4.
Should we use all available data-views? If some data-views contain more noise than signal, should we discard them? These are two crucial questions that concern every researcher working with multi-view data; are all data-views necessary and beneficial to the final outcome? Section “Optimal Number of Data-views” we have addressed these questions by analysing data sets that contain noisy data. By investigating both the produced visualisations and evaluating the clusterings obtained with and without the noisy data, we discuss why it is not always beneficial to include all available data views.
The section ends by proposing alternative variations for the best-performing approach, multi-SNE. Firstly, a proposal for automatically computing the weights assigned to each data-view. In addition, we explore an alternative pre-training step for multi-SNE, where instead of conducting PCA on each data-view, multi-CCA is applied on the multiple data-views for reducing their dimensions into a latent space of uncorrelated embeddings (Rodosthenous, Shahrezaei & Evangelou, 2020).
Comparison between single-view and multi-view visualisations
Visualising multi-view data can be trivially achieved either by looking at the visualisations produced by each data-view, or by concatenating all features into a long vector. T-SNE, LLE and ISOMAP applied on every single data-view of the MMDS data set separately capture the correct local underlying structure of the respective data-view (Fig. 3). However, by design, they cannot capture the global structure of the data. , and represent the trivial solutions of concatenating the features of all data-views before applying t-SNE, LLE and ISOMAP, respectively. These trivial solutions capture mostly the structure of the third data-view, because that data-view has a higher variability between the clusters than the other two.
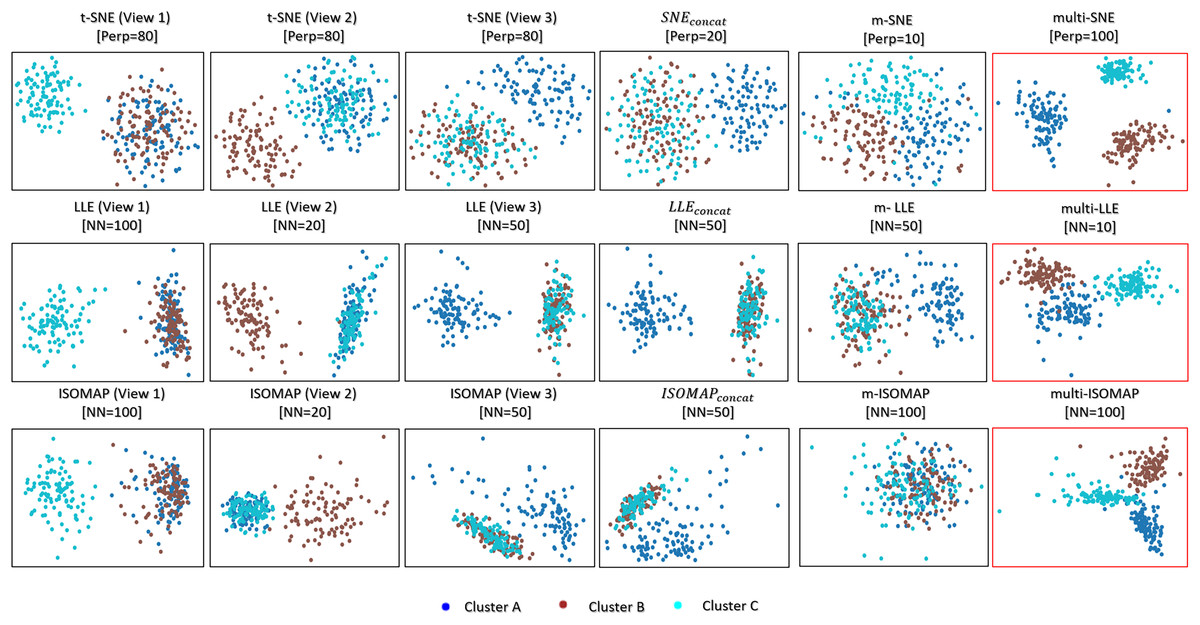
Figure 3: Visualisations of MMDS.
Projections produced by the SNE, LLE, ISOMAP based algorithms. The projections within the red frame present our proposed methods: multi-SNE, multi-LLE and multi-ISOMAP. The parameters and NN refer to the optimised perplexity and number of nearest neighbours, respectively.{kind=link}
Multi-SNE, multi-LLE and multi-ISOMAP produced the best visualisations out of all SNE-based, LLE-based and ISOMAP-based approaches, respectively. These solutions were able to separate clearly the three true clusters, with multi-SNE showing the clearest separation between them. Even though m-SNE separates the samples according to their corresponding clusters, this separation would not be recognisable if the true labels were unknown, as the clusters are not sufficiently separated. The visualisation by m-LLE was similar to the ones produced by single-view solutions on concatenated features, while m-ISOMAP bundles all samples into a single cluster.
By visualising the MMDS data set via both single-view and multi-view clustering approaches, multi-SNE has shown the most promising results (Fig. 3). We have shown that single-view analyses may lead to conflicting results, while multi-view approaches are able to capture the true underlying structure of the synthetic MMDS.
Multi-view manifold learning for clustering
It is very common in studies to utilise the visualisation of data to identify any underlying patterns or clusters within the data samples. Here, it is illustrated how the multi-view approaches can be used to identify such clusters. To quantify the visualisation of the data, we applied the K-means algorithm on the low-dimensional embeddings produced by multi-view manifold learning algorithms. If the two-dimensional embeddings can separate the data points to their respective clusters quantitatively with high accuracy via a clustering algorithm, then those clusters are expected to be qualitatively separated and visually shown in two dimensions. For all examined data sets (synthetic and real), the number of clusters (ground truth) within the samples is known, which attracts the implementation of K-means over alternative clustering algorithms. The number of clusters was used as the input parameter, K, of the K-means algorithm and by computing the clustering measures we evaluated whether the correct sample allocations were made.
The proposed multi-SNE, multi-LLE, and multi-ISOMAP approaches were found to outperform their competitive multi-view extensions (m-SNE, m-LLE, m-ISOMAP) as well as their concatenated versions ( , , ) (Tables 2 and 3). For the majority of the data sets the multi-SNE approach was found to overall outperform all other approaches.
| Data Set | Algorithm | Accuracy | NMI | RI | ARI |
|---|---|---|---|---|---|
| Handwritten digits | (Perp = 10) | 0.717 (0.032) | 0.663 (0.013) | 0.838 (0.005) | 0.568 (0.026) |
| m-SNE (Perp = 10) | 0.776 (0.019) | 0.763 (0.009) | 0.938 (0.004) | 0.669 (0.019) | |
| multi-SNE* (Perp = 10) | 0.882 (0.008) | 0.900 (0.005) | 0.969 (0.002) | 0.823 (0.008) | |
| (NN = 10) | 0.562 | 0.560 | 0.871 | 0.441 | |
| m-LLE (NN = 10) | 0.632 | 0.612 | 0.896 | 0.503 | |
| multi-LLE (NN = 5) | 0.614 | 0.645 | 0.897 | 0.524 | |
| (NN = 20) | 0.634 | 0.619 | 0.905 | 0.502 | |
| m-ISOMAP (NN = 20) | 0.636 | 0.628 | 0.898 | 0.477 | |
| multi-ISOMAP (NN = 5) | 0.658 | 0.631 | 0.909 | 0.518 | |
| Caltech7 | (Perp = 50) | 0.470 (0.065) | 0.323 (0.011) | 0.698 (0.013) | 0.290 (0.034) |
| m-SNE* (Perp = 10) | 0.542 (0.013) | 0.504 (0.029) | 0.757 (0.010) | 0.426 (0.023) | |
| multi-SNE (Perp = 80) | 0.506 (0.035) | 0.506 (0.006) | 0.754 (0.009) | 0.428 (0.022) | |
| (NN = 100) | 0.425 | 0.372 | 0.707 | 0.305 | |
| m-LLE (NN = 5) | 0.561 | 0.348 | 0.718 | 0.356 | |
| multi-LLE (NN = 80) | 0.638 | 0.490 | 0.732 | 0.419 | |
| (NN = 20) | 0.408 | 0.167 | 0.634 | 0.151 | |
| m-ISOMAP (NN = 5) | 0.416 | 0.306 | 0.686 | 0.261 | |
| multi-ISOMAP (NN = 10) | 0.519 | 0.355 | 0.728 | 0.369 | |
| Caltech7 (balanced) | (Perp = 80) | 0.492 (0.024) | 0.326 (0.018) | 0.687 (0.023) | 0.325 (0.015) |
| m-SNE (Perp = 10) | 0.581 (0.011) | 0.444 (0.013) | 0.838 (0.022) | 0.342 (0.016) | |
| multi-SNE* (Perp = 20) | 0.749 (0.008) | 0.686 (0.016) | 0.905 (0.004) | 0.619 (0.009) | |
| (NN = 20) | 0.567 | 0.348 | 0.725 | 0.380 | |
| m-LLE (NN = 10) | 0.403 | 0.169 | 0.617 | 0.139 | |
| multi-LLE (NN = 5) | 0.622 | 0.454 | 0.710 | 0.391 | |
| (NN = 5) | 0.434 | 0.320 | 0.791 | 0.208 | |
| m-ISOMAP (NN = 5) | 0.455 | 0.299 | 0.797 | 0.224 | |
| multi-ISOMAP (NN = 5) | 0.548 | 0.368 | 0.810 | 0.267 | |
| Cancer types | (Perp = 10) | 0.625 (0.143) | 0.363 (0.184) | 0.301 (0.113) | 0.687 (0.169) |
| m-SNE (Perp = 10) | 0.923 (0.010) | 0.839 (0.018) | 0.876 (0.011) | 0.922 (0.014) | |
| multi-SNE* (Perp = 20) | 0.964 (0.007) | 0.866 (0.023) | 0.902 (0.005) | 0.956 (0.008) | |
| (NN = 10) | 0.502 | 0.122 | 0.091 | 0.576 | |
| m-LLE (NN = 20) | 0.637 | 0.253 | 0.235 | 0.647 | |
| multi-LLE (NN = 10) | 0.850 | 0.567 | 0.614 | 0.826 | |
| (NN=5) | 0.384 | 0.015 | 0.009 | 0.556 | |
| m-ISOMAP (NN = 10) | 0.390 | 0.020 | 0.013 | 0.558 | |
| multi-ISOMAP (NN = 50) | 0.514 | 0.116 | 0.093 | 0.592 |
| Data set | Algorithm | Accuracy | NMI | RI | ARI |
|---|---|---|---|---|---|
| NDS | (Perp = 80) | 0.747 (0.210) | 0.628 (0.309) | 0.817 (0.324) | 0.598 (0.145) |
| m-SNE (Perp = 50) | 0.650 (0.014) | 0.748 (0.069) | 0.766 (0.022 | 0.629 (0.020) | |
| multi-SNE* (Perp = 80) | 0.989 (0.006) | 0.951 (0.029) | 0.969 (0.019) | 0.987 (0.009) | |
| (NN = 5) | 0.606 (0.276) | 0.477 (0.357) | 0.684 (0.359) | 0.446 (0.218) | |
| m-LLE (NN = 20) | 0.685 (0.115) | 0.555 (0.134) | 0.768 (0.151) | 0.528 (0.072)) | |
| multi-LLE (NN = 20) | 0.937 (0.044) | 0.768 (0.042) | 0.922 (0.028) | 0.823 (0.047) | |
| (NN = 100) | 0.649 (0.212) | 0.528 (0.265) | 0.750 (0.286) | 0.475 (0.133) | |
| m-ISOMAP (NN = 5) | 0.610 (0.234) | 0.453 (0.221) | 0.760 (0.280) | 0.386 (0.138) | |
| multi-ISOMAP (NN = 300) | 0.778 (0.112) | 0.788 (0.234) | 0.867 (0.194) | 0.730 (0.094) | |
| MCS | (Perp = 200) | 0.421 (0.200) | 0.215 (0.185) | 0.711 (0.219) | 0.173 (0.089) |
| m-SNE (Perp = 2) | 0.641 (0.069) | 0.670 (0.034) | 0.854 (0.080) | 0.575 (0.055) | |
| multi-SNE* (Perp = 50) | 0.919 (0.046) | 0.862 (0.037) | 0.942 (0.052) | 0.819 (0.018) | |
| (NN = 50) | 0.569 (0.117) | 0.533 (0.117) | 0.796 (0.123) | 0.432 (0.051) | |
| m-LLE (NN = 20) | 0.540 (0.079) | 0.627 (0.051) | 0.819 (0.077) | 0.487 (0.026) | |
| multi-LLE (NN = 20) | 0.798 (0.059) | 0.647 (0.048) | 0.872 (0.064) | 0.607 (0.022) | |
| (NN = 150) | 0.628 (0.149) | 0.636 (0.139) | 0.834 (0.167) | 0.526 (0.071) | |
| m-ISOMAP (NN = 5) | 0.686 (0.113) | 0.660 (0.106) | 0.841 (0.119) | 0.565 (0.051) | |
| multi-ISOMAP (NN = 300) | 0.717 (0.094) | 0.630 (0.101) | 0.852 (0.118) | 0.570 (0.044) |
Figure 4 shows a comparison between the true clusters of the handwritten digits data set and the clusters identified by K-means. The clusters reflecting the digits 6 and 9 are clustered together, but all remaining clusters are well separated and agree with the truth.
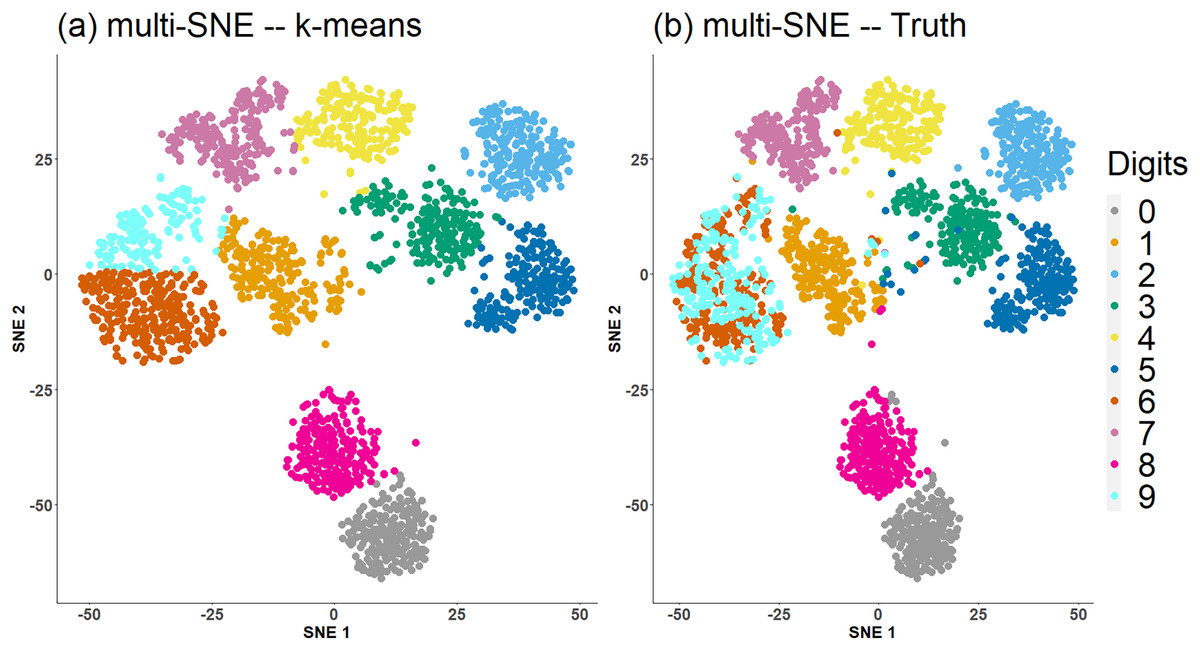
Figure 4: Multi-SNE visualisations of handwritten digits.
Projections produced by multi-SNE with perplexity . Colours present the clustering on the data points by (A) K-means, and (B) ground truth.{kind=link}
Multi-SNE applied on caltech7 produces a good visualisation, with clusters A and B being clearly separated from the rest (Fig. 5B). Clusters C and G are also well-separated, but the remaining three clusters are bundled together. Applying K-means to that low-dimensional embedding does not capture the true structure of the data (Table 2). It provides a solution with all clusters being equally sized (Fig. 5A) and thus its quantitative evaluation is misleading. Motivated by this result, we have further explored the performance of proposed approaches on a balanced version of the caltech7 data set (generated as described in the Section “Real Data”).
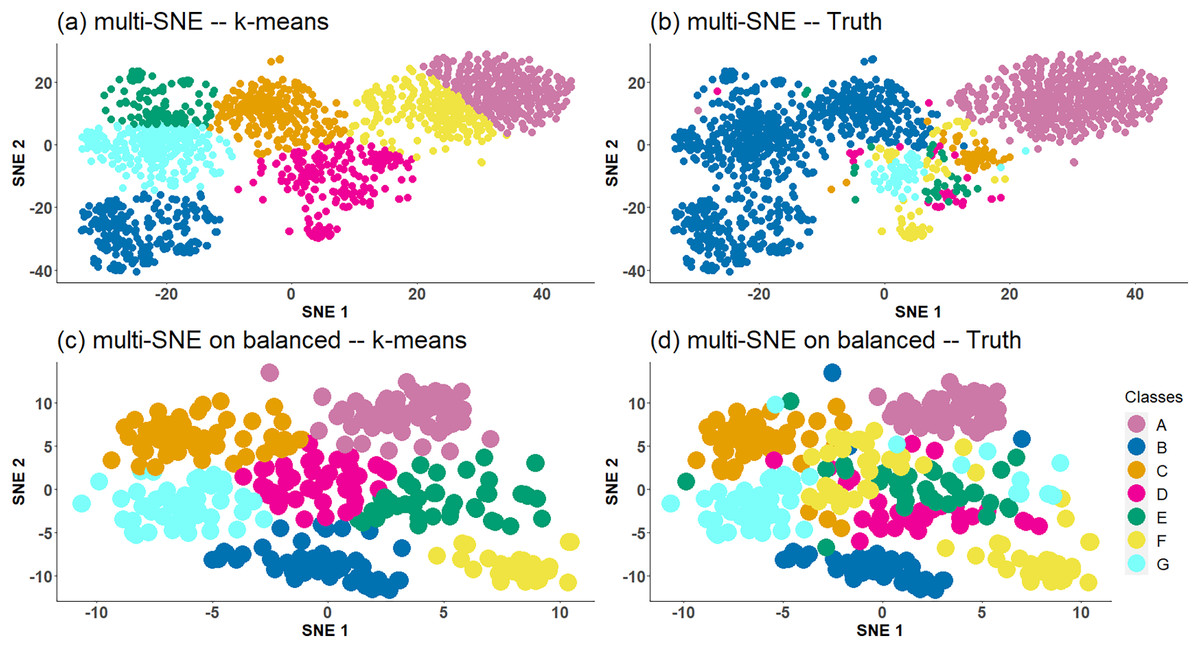
Figure 5: Multi-SNE visualisations of caltech7 and its balanced subset.
Projections produced by multi-SNE with perplexity and for the original and balanced caltech7 data set, respectively. Colours present the clustering on the data points by (A, C) K-means, and (B, D) Ground truth. (A, B) present the data points on the original caltech7 data set, while (C, D) are on its balanced subset.{kind=link}
Similarly to the visualisation of the original data set, the visualisation of the balanced caltech7 data set shows clusters A, B, C and G to be well-separated, while the remaining are still bundled together (Figs. 5C and 5D).
Through the conducted work, it was shown that the multi-view approaches proposed in the manuscript generate low-dimensional embeddings that can be used as input features in a clustering algorithm (as for example the K-means algorithm) for identifying clusters that exist within the data set. We have illustrated that the proposed approaches outperform existing multi-view approaches and the visualisations produced by multi-SNE are very close to the ground truth of the data sets.
Alternative clustering algorithms, that do not require the number of clusters as input, can be considered as well. For example, Density-based spatial clustering of applications with noise (DBSCAN) measures the density around each data point and does not require the true number of clusters as input (Ester et al., 1996). In situations, where the true number of clusters is unknown, DBSCAN would be preferable over K-means. For completeness of our work, DBSCAN was applied on two of the real data sets explored, with similar results observed as the ones with K-means. The proposed multi-SNE approach was the best-performing method of partitioning the data samples. The analysis using DBSCAN can be found in Figs. S9 and S10 of Section 4.8 in the Supplemental File.
An important observation made was that caution needs to be taken when data sets with imbalanced clusters are analysed as the quantitative performance of the approaches on such data sets is not very robust.
Optimal parameter selection
SNE, LLE and ISOMAP depend on a parameter that requires tuning. Even though the parameter is defined differently in each algorithm, for all three algorithms it is related to the nearest number of global neighbours. As described earlier, the optimal parameter was found by comparing the performance of the methods on a range of parameter values, . In this section, the synthetic data sets, NDS and MCS, were analysed, because both data sets separate the samples into known clusters by design and evaluation via clustering measures would be appropriate.
To find the optimal parameter value, the performance of the algorithms was evaluated by applying K-means on the low-dimensional embeddings and comparing the resulting clusterings against the truth. Once the optimal parameter was found, we confirmed that the clusters were visually separated by manually looking at the two-dimensional embeddings. Since the data in NDS and MCS are perfectly balanced and were generated for clustering, this approach can effectively evaluate the data visualisations.
On NDS, single-view SNE, LLE and ISOMAP algorithms produced a misclustering error of , meaning that a third of the samples was incorrectly clustered (Fig. 6B). This observation shows that single-view methods capture the true local underlying structure of each synthetic data-view. The only exception for NDS is the fourth data-view, for which the error is closer to , i.e. randomly assigns the clusters (which follows the simulation design, as it was designed to be a random data-view). After concatenating the features of all data-views, the performance of single-view approaches remains poor (Fig. 6A). The variance of the misclustering error on this solution is much greater, suggesting that single-view manifold learning algorithms on concatenated data are not robust and thus not reliable. Increasing the noise level (either by incorporating additional noisy data-views, or by increasing the dimensions of the noisy data-view) in this synthetic data set had little effect on the overall performance of the multi-view approaches (Table S2, Figs. S5, S6 in Section 4.4. of the Supplemental File).
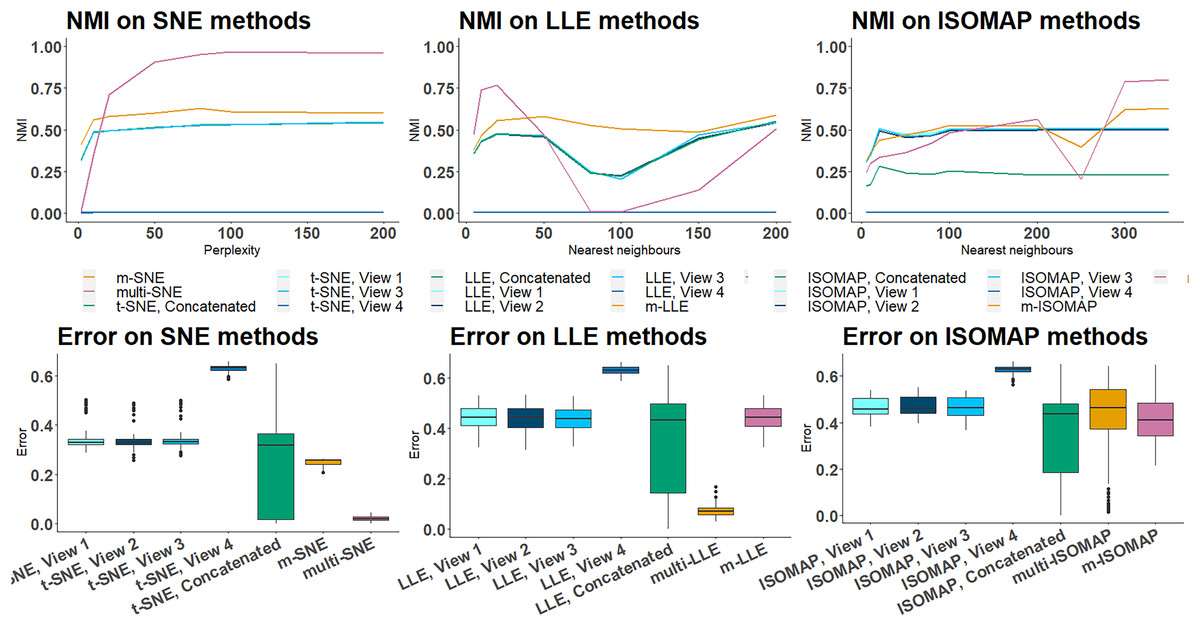
Figure 6: NDS evaluation measures.
(A) NMI values along different parameter values on all manifold learning algorithms and (B) Misclustering error on the optimal parameter values.{kind=link}
On both NDS and MCS, multi-LLE and multi-SNE were found to be sensitive to the choice of their corresponding parameter value (Figs. 6A and 7). While multi-LLE performed the best when the number of nearest neighbours was low, multi-SNE provided better results as perplexity was increasing. On the other hand, multi-ISOMAP had the highest NMI value when the parameter was high.
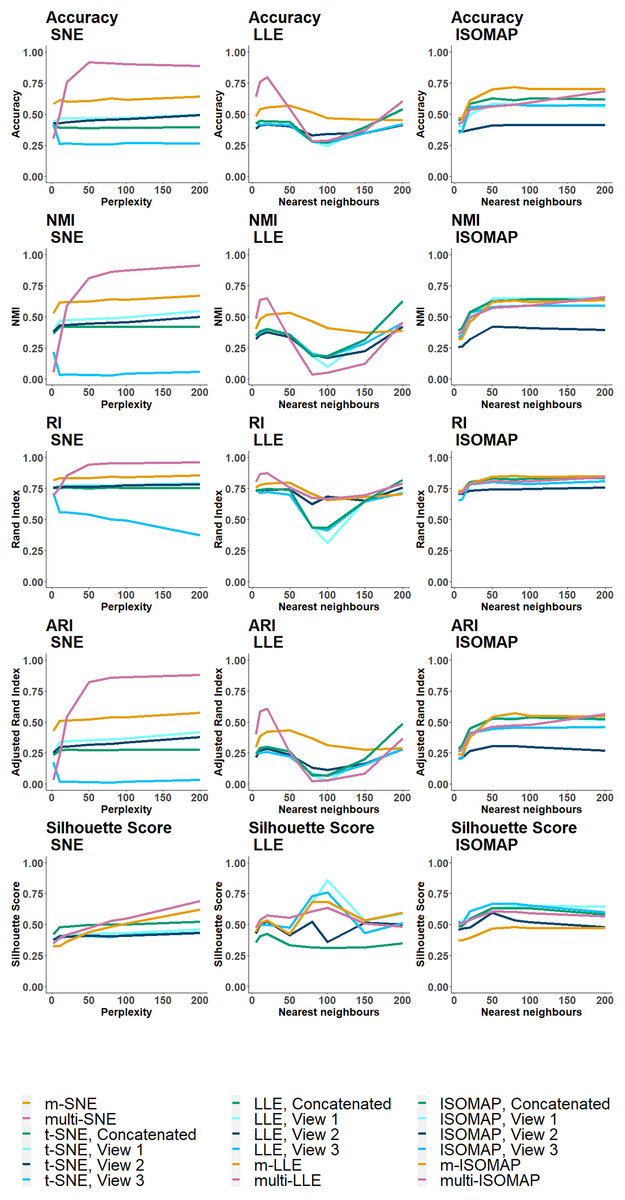
Figure 7: MCS evaluation measures.
The clustering evaluation measures are plotted against different parameter values on the all SNE, LLE and ISOMAP based algorithms.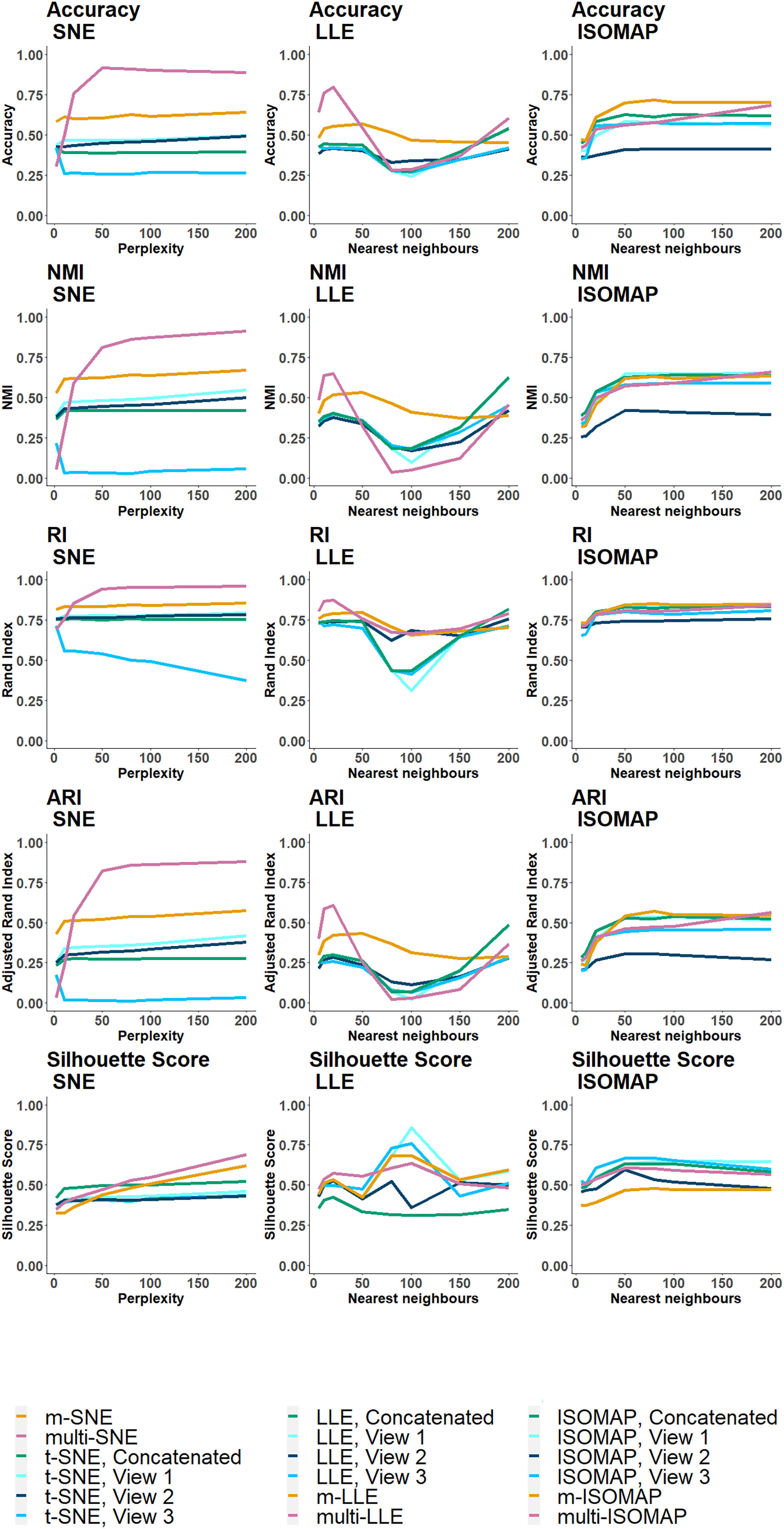{kind=link}
Overall, ISOMAP-based multi-view algorithms were found to be more sensitive to their tuning parameter (number of nearest neighbours). This observation is justified by the higher variance observed in the misclustering error on the optimal parameter value throughout the simulation runs (Fig. 6B). The performance of ISOMAP-based methods improved as the parameter value increased (Fig. 7). However, they were outperformed by multi-LLE and multi-SNE for both synthetic data sets.
Out of the three manifold learning foundations, LLE-based approaches mostly depend on their parameter value to produce the optimal outcome. Specifically, their performance dropped when the parameter value was between and (Fig. 6A). When the number of nearest neighbours was set to be greater than their performance started to improve. Out of all LLE-based algorithms, the highest NMI and lowest misclustering error was obtained by multi-LLE (Figs. 6 and 7). Our observations on the tuning parameters of LLE-based approaches are in agreement with earlier studies (Karbauskaitė, Kurasova & Dzemyda, 2007; Valencia-Aguirre et al., 2009). Both Karbauskaitė, Kurasova & Dzemyda (2007) and Valencia-Aguirre et al. (2009) found that LLE performs best with low nearest number of neighbours and their conclusions reflect the performance of multi-LLE; best performed on low values of the tuning parameter. Even though m-SNE performed better than single-view methods in terms of both clustering and error variability, multi-SNE produced the best results (Figs. 6 and 7). In particular, multi-SNE outperformed all algorithms presented in this study on both NDS and MCS. Even though it performed poorly for low perplexity values, its performance improved for . Multi-SNE was the algorithm with the lowest error variance, making it a robust and preferable solution.
The four implemented measures (Accuracy, NMI, RI and ARI) use the true clusters of the samples to evaluate the clustering performance. In situations where cluster allocation is unknown, alternative clustering evaluation measures can be used, such as the Silhouette score (Rousseeuw, 1987). The Silhouette score in contrast to the other measures does not require as input the cluster allocation and is a widely used approach for identifying the best number of clusters and clustering allocation in an unsupervised setting.
Evaluating the clustering performance of the methods via the Silhouette score agrees with the other four evaluation measures, with multi-SNE producing the highest value out of all multi-view manifold learning solutions. The Silhouette score of all methods applied on the MCS data set can be found in Fig. S8 of Section 4.7 in the Supplemental File.
The same process of parameter tuning was implemented for the real data sets and their performance is presented in Fig. S4 of Section 4.3 in the Supplemental File. In contrast to the synthetic data, multi-SNE on cancer types data performed the best at low perplexity values. For the remaining data sets, its performance was stable for all parameter values. With the exception of cancer types data, the performance of LLE-based solutions follows their behaviour on synthetic data.
Optimal number of data-views
It is common to think that more information would lead to better results, and in theory that should be the case. However, in practice that is not always true (Kumar, Rai & Hal, 2011). Using the cancer types data set, we explored whether the visualisations and clusterings are improved if all or a subset of the data-views are used. With three available data-views, we implemented a multi-view visualisation on three combinations of two data-views and a single combination of three data-views.
The genomics data-view provides a reasonably good separation of the three cancer types, whereas miRNA data-view fails in this task, as it provides a visualisation that reflects random noise (first column of plots in Fig. 8). This observation is validated quantitatively by evaluating the produced t-SNE embeddings (Table S3 in Section 4.5 of the Supplemental File). Concatenating features from the different data-views before implementing t-SNE does not improve the final outcome of the algorithm, regardless of the data-view combination.
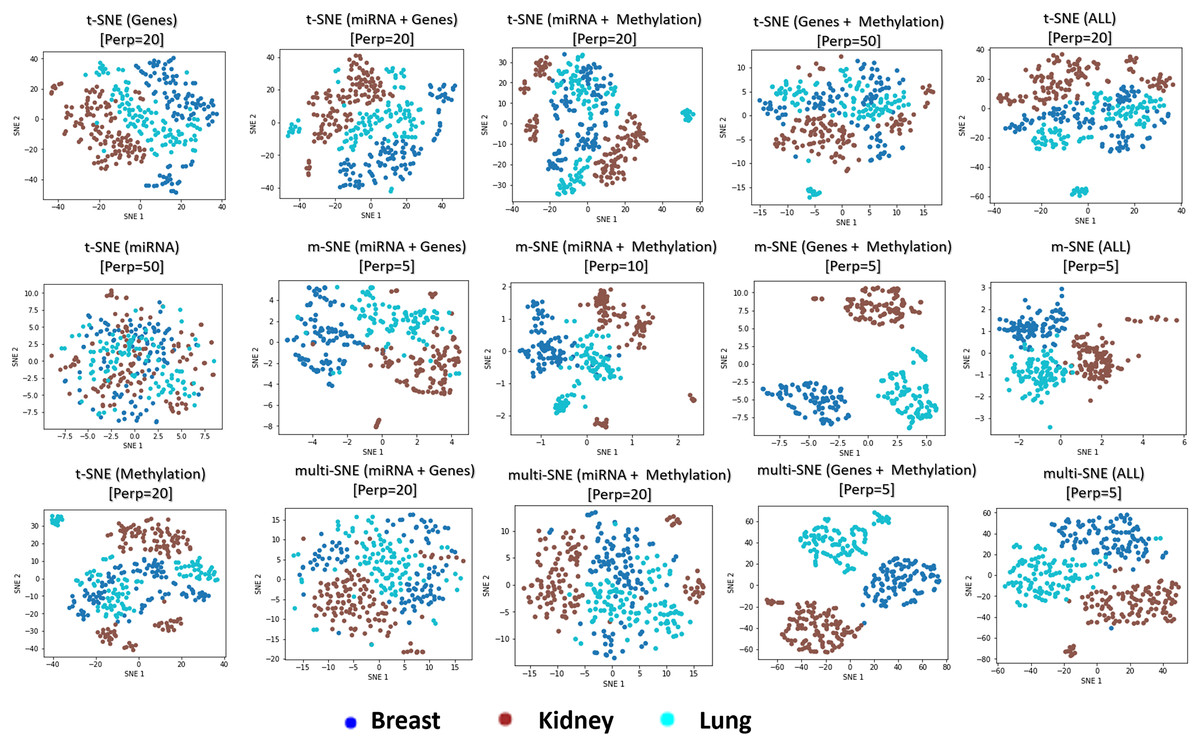
Figure 8: Visualisations of cancer types.
Projections produced by all SNE-based manifold learning algorithms on all possible combinations between the three data-views in the cancer types data set. The parameter refers to the selected perplexity, which was optimised for the corresponding methods.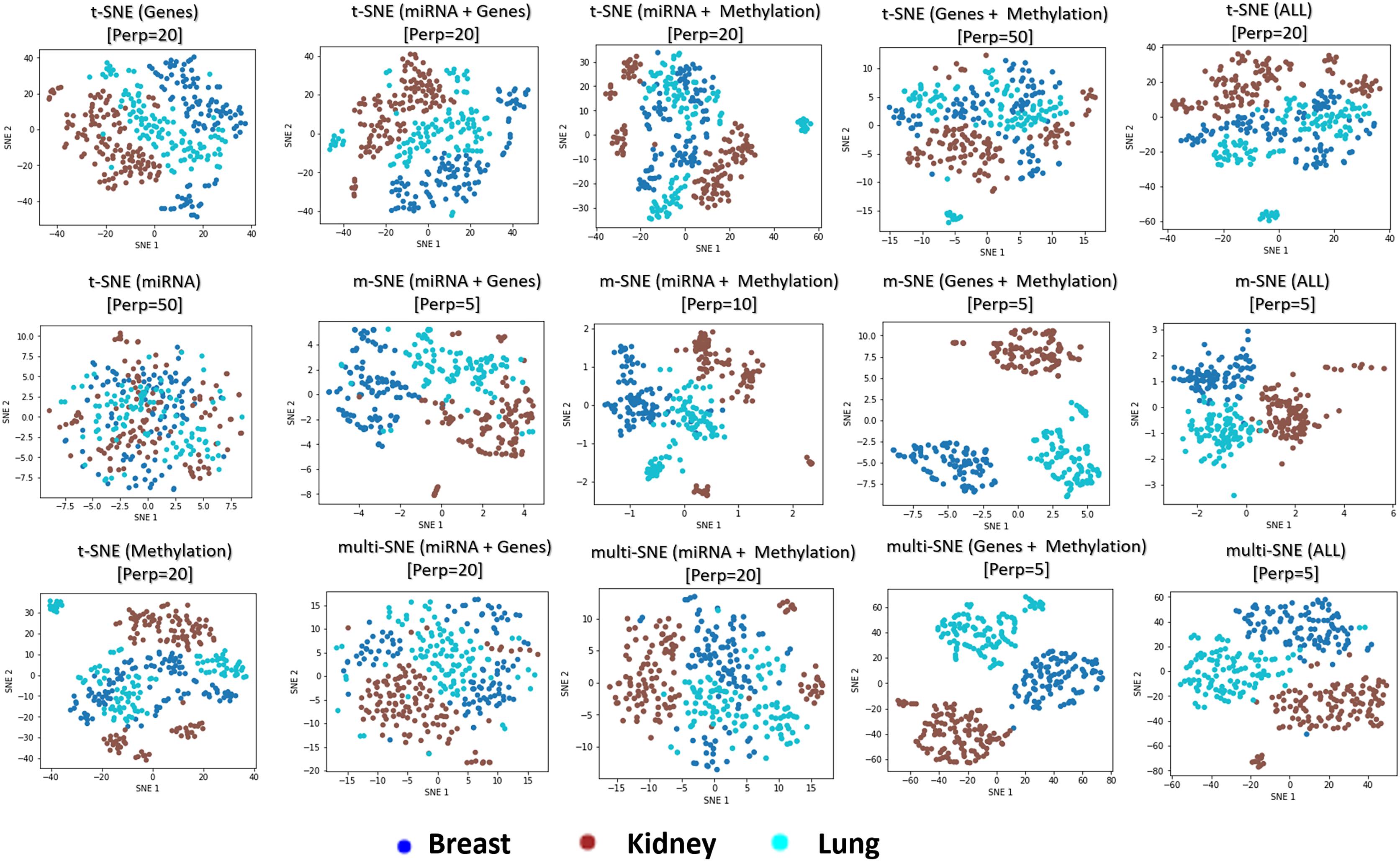{kind=link}
Overall, multi-view manifold learning algorithms have improved the data visualisation to a great extent. When all three data-views are considered, both multi-SNE and m-SNE provide a good separation of the clusters (Fig. 8). However, the true cancer types can be identified perfectly when the miRNA data-view is discarded. In other words, the optimal solution in this data set is obtained when only genomics and epigenomics data-views are used. That is because miRNA data-view contains little information about the cancer types and adds random noise, which makes the task of separating the data points more difficult.
This observation was also noted between the visualisations of MMDS and NDS (Fig. 9). The only difference between the two synthetic data sets is the additional noisy data-view in NDS. Even though NDS separates the samples to their corresponding clusters, the separation is not as clear as it is in the projection of MMDS via multi-SNE. In agreement with the exploration of the cancer types data set, it is favourable to discard any noisy data-views in the implementation of multi-view manifold learning approaches.
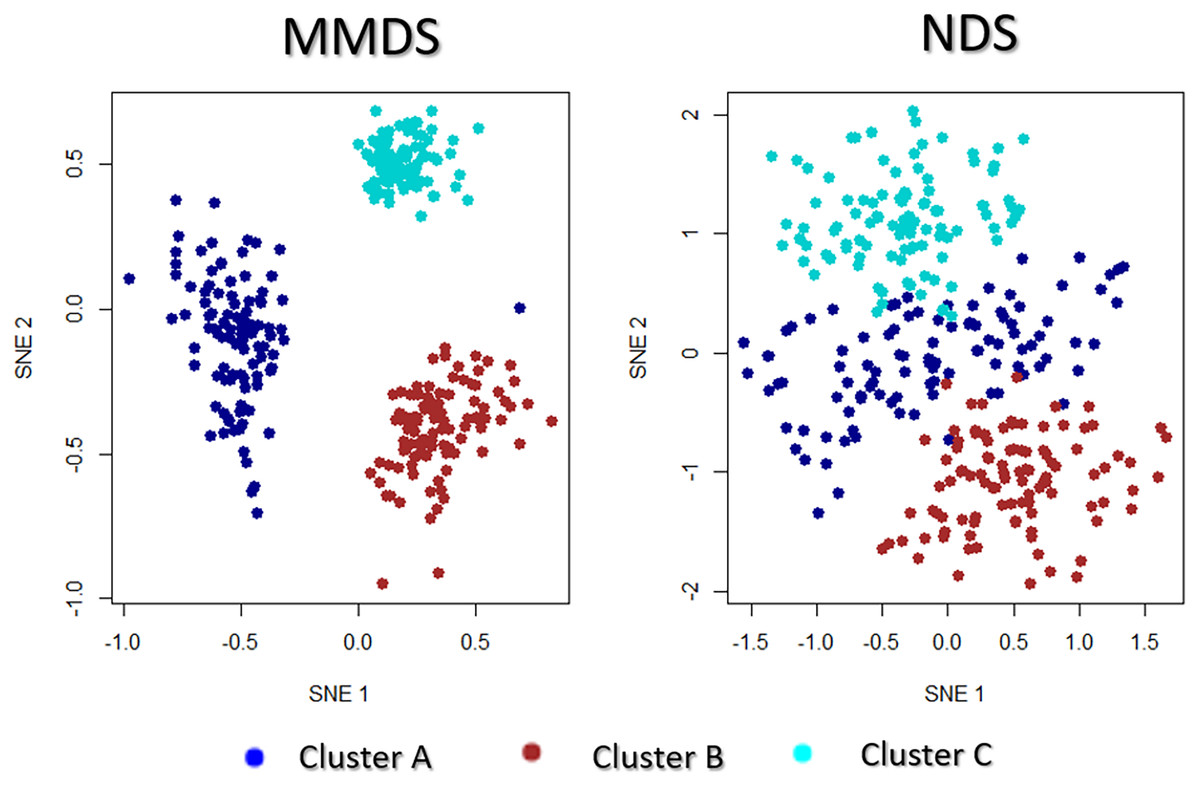
Figure 9: Multi-SNE visualisations of MMDS and NDS.
Projections produced by multi-SNE with perplexity for both MMDS and NDS.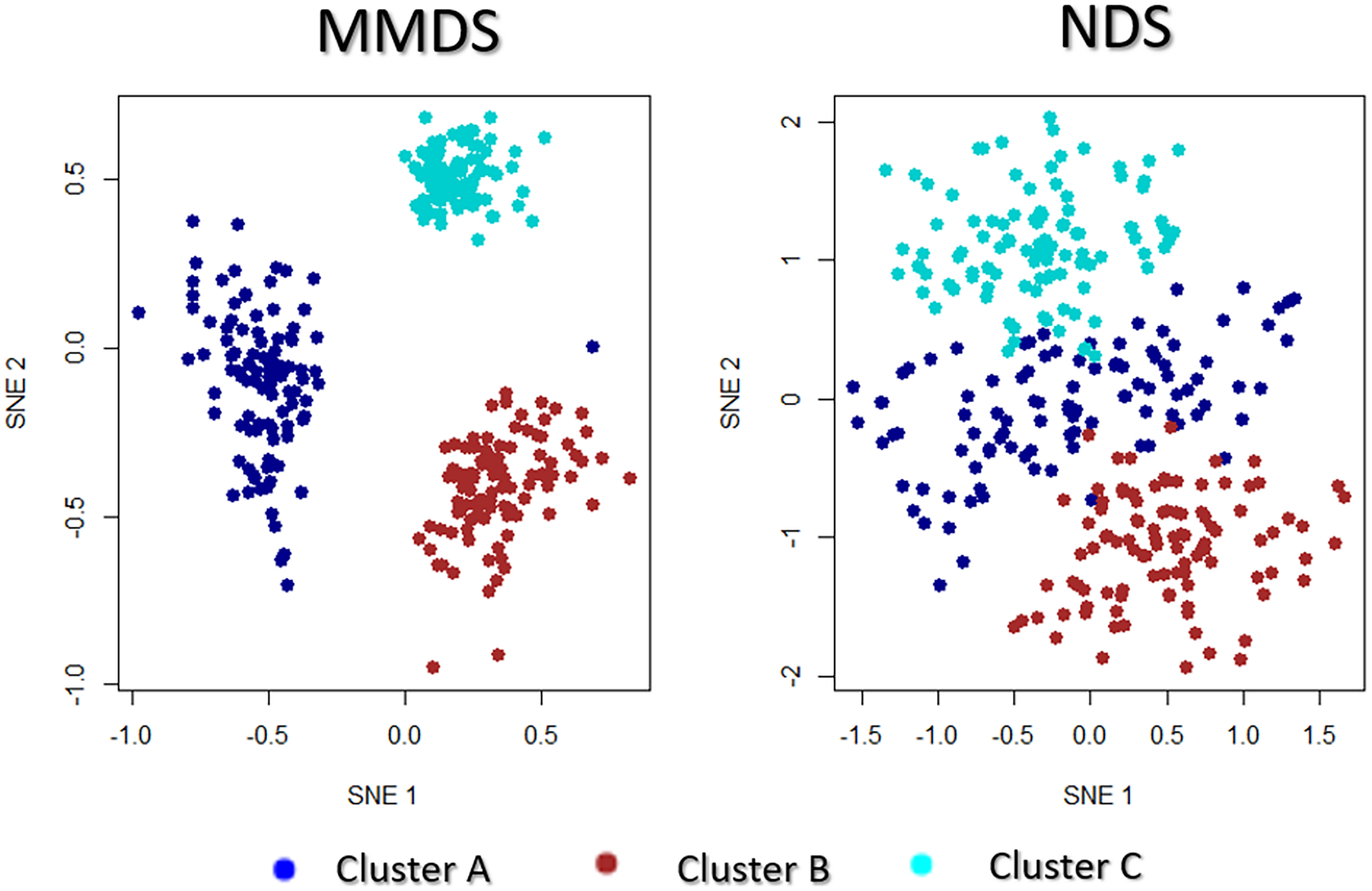{kind=link}
It is not always a good idea to include all available data-views in multi-view manifold learning algorithms; some data-views may provide noise which would result in a worse visualisation than discarding those data-views entirely. The noise of a data-view with unknown labels may be viewed in a single-view t-SNE plot (all data-points in a single cluster), or identified, if possible, via quantification measures such as signal-to-noise ratio.
Multi-SNE variations
This section presents two alternative variations of multi-SNE, including automatic weight adjustments and multi-CCA as a pre-training step for reducing the dimensions of the input data-views.
Automated weight adjustments
A simple weight-updating approach is proposed based on the KL-divergence measure from each data-view. This simple weight-updating approach guarantees that more weight is given to the data-views producing lower KL-divergence measures and that no data-view is being completely discarded from the algorithm.
Recall that , with , if the two distributions, P and Q, are perfectly matched. Let be a vector, where and initialise the weight vector by . To adjust the weights of each data-view, the following steps are performed at each iteration:
-
1.
Normalise KL-divergence by . This step ensures that and that .
-
2.
Measure the weights for each data-view by . This step ensures that the data-view with the lowest KL-divergence value receives the highest weight.
Based on the analysis in Section “Optimal Number of Data-views”, we know that cancer types and NDS data sets contain noisy data-views and thus multi-SNE performs better when they are entirely discarded. Here, we assume that this information is unknown and the proposed weight-updating approach is implemented on those two data sets to test if the weights are being adjusted correctly according to the noise level of each data-view.
The proposed weight-adjustment process, which looks at the produced KL-divergence between each data-view and the low-dimensional embeddings, distinguishes which data-views contain the most noise and the weight values are updated accordingly (Fig. 10B). In cancer types, transcriptomics (miRNA) receives the lowest weight, while genomics (Genes) was given the highest value. This weight adjustment comes in agreement with the qualitative (t-SNE plots) and quantitative (clustering) evaluations performed in Section “Optimal Number of Data-views”. In NDS, which represents the noisy data-view received the lowest weight, and the other data-views had around the same weight value, as they all impact the final outcome equally.
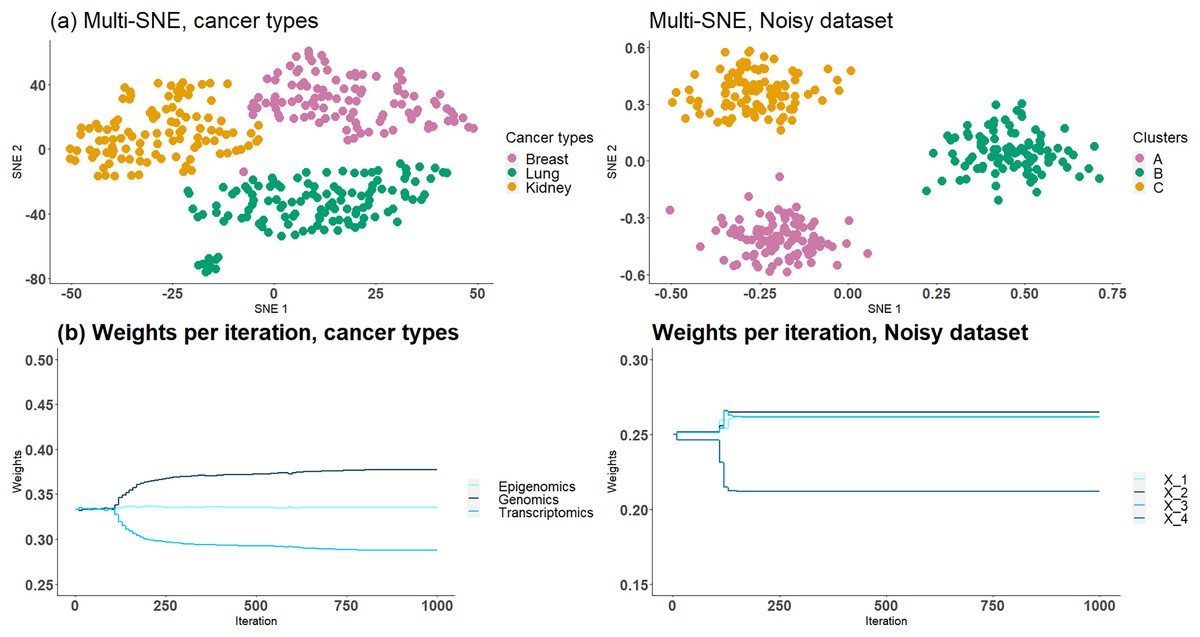
Figure 10: Cancer types and NDS with automated weight adjustments.
The first row presents the produced visualisations of multi-SNE with the automated weight adjustment procedure implemented. The second row of figures presents the weights assigned to each data-view at each step of the iteration. For both data the iterations ran for a maximum of 1,000 steps.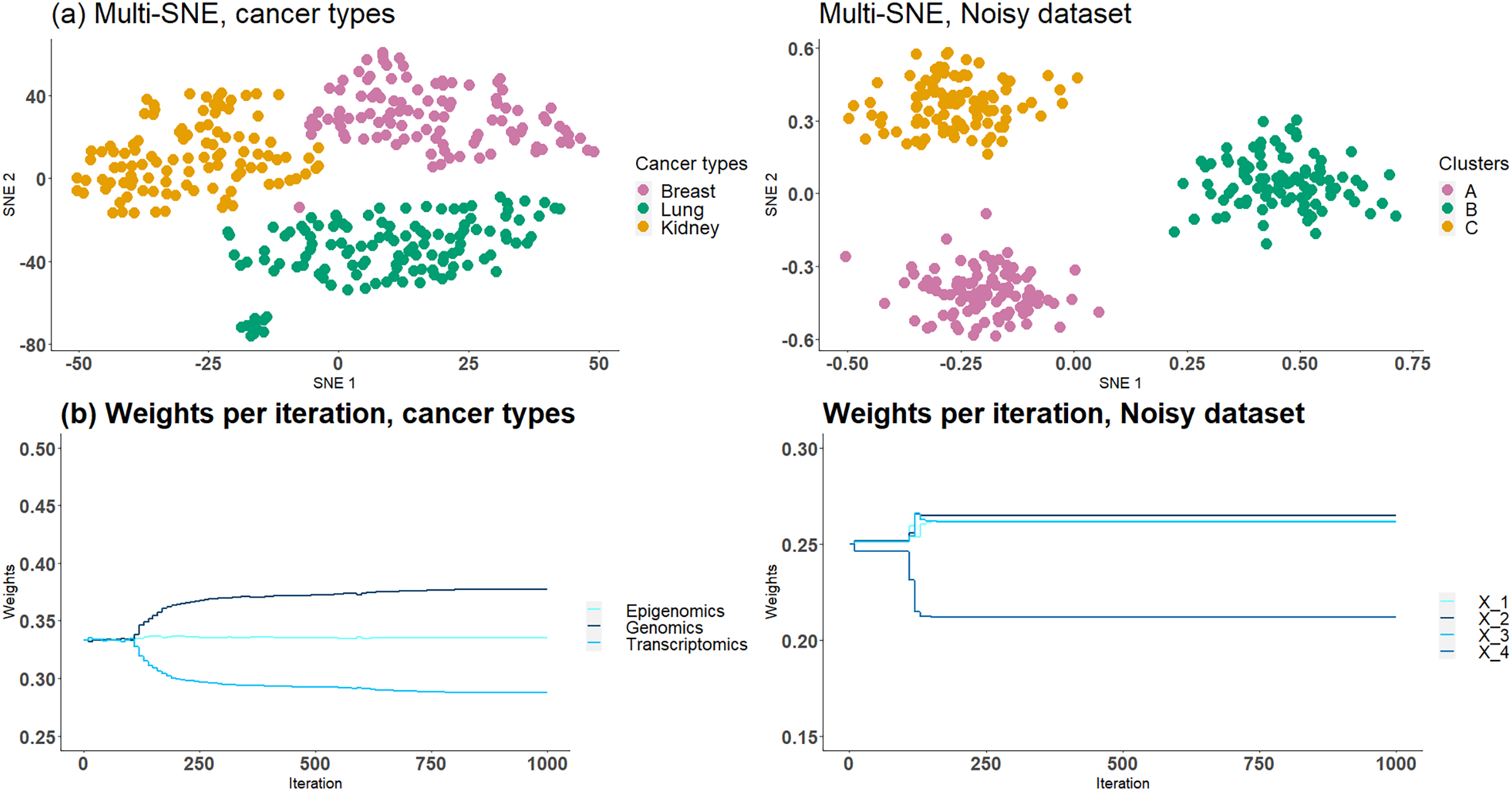{kind=link}
The proposed weight-adjustment process updates the weights at each iteration. For the first iterations, the weights are not changing, as the algorithm adjusts to the produced low-dimensional embeddings (Fig. 10B). In NDS, the weights converge after iterations, while in cancer types, they are still being updated even after iterations. The changes recorded are small and the weights can be said to have stabilised.
The low-dimensional embeddings produced in NDS with weight adjustments separate clearly the three clusters, an observation missed without the implementation of the weight-updating approach (Fig. 10A); it resembles the MMDS (i.e. without noisy data-view) multi-SNE plot (Fig. 9). The automatic weight-adjustment process identifies the informative data-views, by allocating them a higher weight value than to the noisy data-views. This observation was found to be true even when a dataset contains more noise than informative data-views (Table S2, Figs. S5, S6 in Section 4.4 of the Supplemental File).
The embeddings produced using multi-SNE with the automated weight adjustments in cancer types do not separate the three clusters as clearly as multi-SNE without the noisy data-view. A more clear separation is obtained compared to multi-SNE on the complete data set without weight adjustments.
The weights produced by this weight adjustment approach can indicate the importance of each data-view in the final lower-dimensional embedding. For example, data-views with very low weights may be assumed futile and a better visualisation may be produced if those data-views are discarded. The actual weights assigned to each data-view do not have any further meaning.
Multi-CCA as pre-training
As mentioned earlier, van der Maaten & Hinton (2008) proposed the implementation of PCA as a pre-training step for t-SNE to reduce the computational costs, provided that the fraction of variance explained by the principal components is high. In this article, pre-training via PCA was implemented in all variations of SNE. Alternative linear dimensionality reduction methods may be considered, especially for multi-view data. In addition to reducing the dimensions of the original data, such methods can capture information between the data-views. For example, canonical correlation analysis (CCA) captures relationships between the features of two data-views by producing two latent low-dimensional embeddings (canonical vectors) that are maximally correlated between them (Hotelling, 1936; Rodosthenous, Shahrezaei & Evangelou, 2020). Rodosthenous, Shahrezaei & Evangelou (2020) demonstrated that multi-CCA, an extension of CCA that analyses multiple (more than two) data-views, would be preferable as it reduces over-fitting.
This section demonstrates the application of multi-CCA as pre-training in replacement of PCA. This alteration of the multi-SNE algorithm was implemented on the handwritten digits data set. Multi-CCA was applied on all data-views, with six canonical vectors produced for each data-view (in this particular data set ). The variation of multi-CCA proposed by Witten & Tibshirani (2009) was used for the production of the canonical vectors, as it is computationally cheaper compared to others (Rodosthenous, Shahrezaei & Evangelou, 2020). By using these vectors as input features, multi-SNE produced a qualitatively better visualisation than using the principal components as input features (Fig. 11). By using an integrative algorithm as pre-training, all clusters are clearly separated, including six and nine. Quantitatively, clustering via K-Means was evaluated with ACC = 0.914, NMI = 0.838, RI = 0.968, ARI = 0.824. This evaluation suggests that quantitatively, it performed better than the -dimensional embeddings produced multi-SNE with PCA as pre-training.
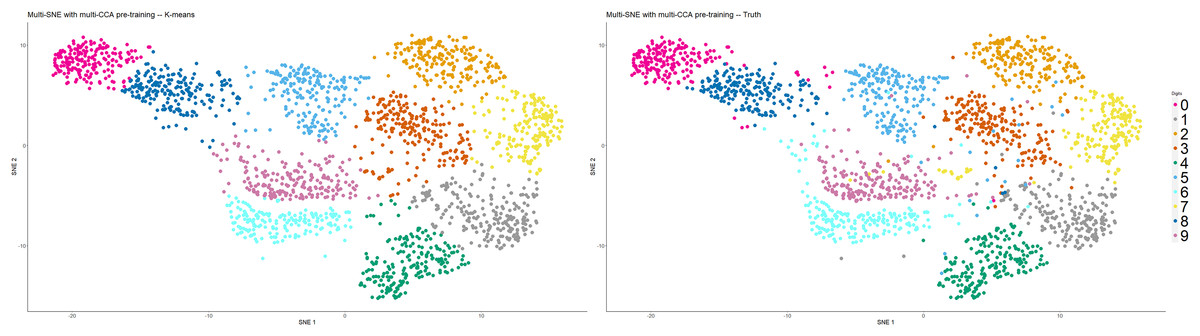
Figure 11: Multi-SNE on handwritten digits, with multi-CCA as pre-training.
Projections of handwritten digits data sets, produced by multi-SNE. Multi-CCA was implemented on all data-views with their respective canonical vectors acting as input features for multi-SNE.{kind=link}
Comparison of multi-SNE variations
Section “Multi-SNE” introduced multi-SNE, a multi-view extension of t-SNE. In Sections “Automated weight adjustments” and “Multi-CCA as pre-training”, two variations of multi-SNE are presented. The former implements a weight-adjustment process which at each iteration updates the weights allocated for each data-view, and the latter uses multi-CCA instead of PCA as a pre-training step. In this section, multi-SNE and its two variations are compared to assess whether the variations introduced to the algorithm perform better than the initial proposal.
The implementation of the weight-adjustment process improved the performance of multi-SNE on all real data sets analysed (Table 4). The influence of multi-CCA as a pre-training step produced inconsistent results; in some data sets this step boosted the clustering performance of multi-SNE (e.g. handwritten digits), while for the other data sets, it did not (e.g. cancer types). From this analysis, we conclude that adjusting the weights of each data-view always improves the performance of multi-SNE. On the other hand, the choice of pre-training, either via PCA or multi-CCA, is not clear, and it depends on the data at hand.
| Variation | Handwritten digits | Cancer types | Caltech7 original | Caltech7 balanced | NDS | MCS |
|---|---|---|---|---|---|---|
| Multi-SNE without weight-adjustment | 0.822 | 0.964 | 0.506 | 0.733 | 0.989 (0.006) | 0.919 (0.046) |
| Multi-SNE with weight-adjustment | 0.883 | 0.994 | 0.543 | 0.742 | 0.999 (0.002) | 0.922 (0.019) |
| Multi-CCA multi-SNE without weight-adjustment | 0.901 | 0.526 | 0.453 | 0.713 | 0.996(0.002) | 0.993 (0.005) |
| Multi-CCA multi-SNE with weight-adjustment |
0.914 | 0.562 | 0.463 | 0.754 | 0.996 (0.002) | 0.993 (0.005) |
Multi-omics single-cell data analysis
An important area of active current research, where manifold learning approaches, such as t-SNE, as visualisation tools are commonly used is single-cell sequencing (scRNA-seq) and genomics. Last few years, have seen fast developments of multi-omics single-cell methods, where for example for the same cells multiple omics measurements are being obtained such as transcripts by scRNA-seq and chromatin accessibility by a method known as scATAC-seq (Stuart et al., 2019). As recently discussed the integration of this kind of multi-view single-cell data poses unique and novel statistical challenges (Argelaguet et al., 2021). We, therefore, believe our proposed multi-view methods will be very useful in producing an integrated visualisation of cellular heterogeneity and cell types studied by multi-omics single-cell methods in different tissues, in health and disease.
To illustrate the capability of multi-SNE for multi-omics single-cell data, we applied multi-SNE on a representative data set of scRNA-seq and ATAC-seq for human peripheral blood mononuclear cells (PBMC) (https://support.10xgenomics.com/single-cell-multiome-atac-gex/datasets/1.0.0/pbmc_granulocyte_sorted_10k) (Fig. 12). Multi-SNE produced more intelligible projections of the cells compared to m-SNE and achieved higher evaluation scores (Fig. S1 in Section 3 of the Supplemental File).
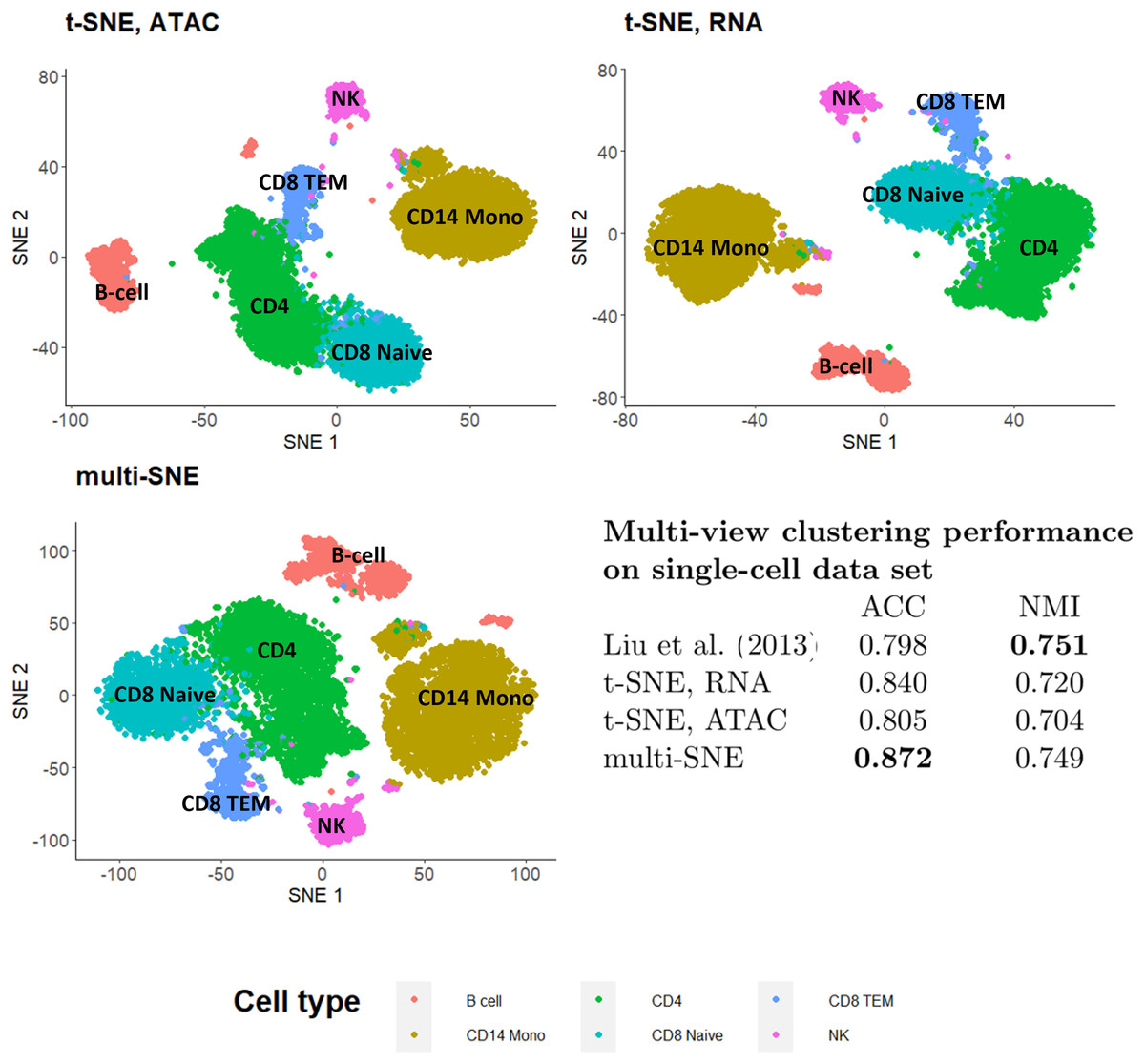
Figure 12: Visualisations and clustering performance on single-cell multi-omics data.
Projections produced by t-SNE on RNA, ATAC and multi-SNE on both data-views with perplexity for the two t-SNE projections and for multi-SNE. The clustering performance of the data by Liu et al. (2013), t-SNE and multi-SNE are presented.{kind=link}
To test the quality of the obtained multi-view visualisation, we compared its performance against the multi-view clustering approach proposed by Liu et al. (2013) on this single-cell data. A balanced subset of this data set was used, which consists of two data-views on 9,105 cells (scRNA-seq and ATAC-seq with 36,000 and 108,000 features, respectively). A detailed description of this data set, the pre-processing steps performed, and the projections of t-SNE and multi-SNE on the original data are provided in Fig. S1 of Section 3 in the Supplemental File. We found multi-SNE to have the highest accuracy (and a close NMI to the approach by Liu et al. (2013)) as seen in Fig. 12. Qualitatively, the projections by t-SNE on scRNA-seq and multi-SNE are similar, but multi-SNE separates the clusters better (especially between CD4 and CD8 cell types (Figs. 12, and S1 in Section 3 of the Supplemental File). While it is known that ATAC-seq data is noisier and has less information by itself, we see that integration of the data-views results in better overall separation of the different cell types in this data set. These results indicate the promise of multi-SNE as a unified multi-view and clustering approach for multi-omics single-cell data.
Discussion
In this manuscript, we propose extensions of the well-known manifold learning approaches t-SNE, LLE, and ISOMAP for the visualisation of multi-view data sets. These three approaches are widely used for the visualisation of high-dimensional and complex data sets on performing non-linear dimensionality reduction. The increasing number of multiple data sets produced for the same samples in different fields, emphasises the need for approaches that produce expressive presentations of the data. We have illustrated that visualising each data set separately from the rest is not ideal as it does not reveal the underlying patterns within the samples. In contrast, the proposed multi-view approaches can produce a single visualisation of the samples by integrating all available information from the multiple data-views. Python and R (only for multi-SNE) code of the proposed solutions can be found in the links provided in Section 5 of the Supplemental File.
Multi-view visualisation has been explored in the literature with a number of approaches proposed in recent years. In this work, we propose multi-view visualisation approaches that extend the well-known manifold approaches: t-SNE, LLE, and ISOMAP. Through a comparative study of real and synthetic data, we have illustrated that the proposed approach, multi-SNE, provides a better and more robust solution compared to the other tested approaches proposed in the manuscript (multi-LLE and multi-ISOMAP) and the approaches proposed in the literature including m-LLE, m-SNE, MV-tSNE2, j-SNE, j-UMAP (additional results in Figs. S2 and S3 of Sections 4.1 and 4.2, respectively, in the Supplemental File). Although multi-SNE was computationally the most expensive multi-view manifold learning algorithm (Table S4 in Section 4.6 of the Supplemental File), it was found to be the solution with superior performance, both qualitatively and quantitatively. All t-SNE results presented in this manuscript were based on the original R implementation (https://cran.r-project.org/web/packages/tsne/) and verified by the original Python implementation (https://lvdmaaten.github.io/tsne/); multi-SNE was based on the original t-SNE implementation and not on any other variation of the algorithm. A future direction is the exploration of other variations of the t-SNE algorithm for the implementation of multi-SNE.
It was widely known that t-SNE can not deal with high-dimensional data and we have therefore implemented the suggestion of van der Maaten & Hinton (2008) and applied firstly PCA to obtain a smaller dataset that t-SNE is subsequently applied to. A similar procedure was implemented for multi-SNE. As part of our exploration of multi-SNE we proposed the use of multi-CCA for obtaining the lower dimensional datasets. The use of the multi-CCA step provided mixed results, that suggest the need for further exploration of an appropriate dimensionality reduction approach, whether it is a multi-view one vs. a single-view one, or whether is a non-linear one vs. a linear one.
We have utilised the low-dimensional embeddings of the proposed algorithms as features in the K-means clustering algorithm, which we have used (1) to quantify the visualisations produced, and (2) to select the optimal tuning parameters for the manifold learning approaches. By investigating synthetic and real multi-view data sets, each with different data characteristics, we concluded that multi-SNE provides a more accurate and robust solution than any other single-view and multi-view manifold learning algorithms we have considered. Specifically, multi-SNE was able to produce the best data visualisations of all data sets analysed in this article. Multi-LLE provides the second-best solution, while multi-view ISOMAP algorithms have not produced competitive visualisations. By exploring several data sets, we concluded that multi-view manifold learning approaches can be effectively applied to heterogeneous and high-dimensional data (i.e. ).
Through the conducted experiments, we have illustrated the effect of the parameters on the performance of the methods. We have shown that SNE-based methods perform the best when perplexity is in the range , LLE-based algorithms should take a small number of nearest neighbours, in the range , while the parameter of ISOMAP-based should be in the range , where N is the number of samples.
We believe that the best approach to selecting the tuning parameters of the methods is to explore a wide range of different parameter values and assess the performance of the methods both qualitatively and quantitatively. If the produced visualisations vary a lot between a range of parameter values, then the data might be too noisy, and the projections misleading. In this case, it might be beneficial to look at the weights obtained for each data-view and explore removing the noisiest data-views (depending on the number of data-views used and/or existing knowledge of noise in the data). Otherwise (if the produced visualisations vary slightly between various parameter values), the parameter value with the best qualitative and quantitative performance can be selected. Since t-SNE (and its extensions) are robust to perplexity (van der Maaten & Hinton, 2008), a strict optimal parameter value would not be necessary to produce meaningful visualisations and clusterings, i.e. identical performance qualitatively and quantitatively can be observed for a range of values.
Cao & Wang (2017) proposed an automatic approach for selecting the perplexity parameter of t-SNE. According to the authors the trade between the final KL divergence and perplexity value can lead to good embeddings, and they proposed the following criterion:
(10)
This solution can be extended to automatically select the multi-SNE perplexity, by modifying the criterion to:
(11)
Our conclusions about the superiority of multi-SNE have been further supported by implementing the Silhouette score as an alternative approach for evaluating the clustering and tuning the parameters of the methods. In contrast to the measures used throughout the article, the Silhouette score does not take into account the number of clusters that exist in the data set, illustrating the applicability of multi-SNE approach in unsupervised learning problems where the underlying clusters of the samples are not known (Fig. S8 in Section 4.7 of the Supplemental File). Similarly, we have illustrated that alternative clustering algorithms can be implemented for clustering the samples. By inputting the produced multi-SNE embeddings in the DBSCAN algorithm we further illustrated how the clusters of the samples can be identified (Figs. S9 and S10 in Section 4.8 of the Supplemental File).
As part of our work, we explored the application of multi-SNE for the visualisation and clustering of multi-OMICS single-cell data. We illustrated that the integration of the data-views results to better overall separation of the different cell types in the analysed dataset. Pursuing further this area of research it would be interesting to compare the proposed multi-SNE approach with deep generative models proposed for the analysis of single-cell data including the approaches proposed by Ashuach et al. (2023) and Li et al. (2022).
Multi-view clustering is a topic that has gathered a lot of interest in recent years with a number of approaches published in the literature. Such approaches include the ones proposed by Kumar, Rai & Hal (2011), Liu et al. (2013), Sun et al. (2015), Ou et al. (2016) and Ou et al. (2018). The handwritten data set presented in the manuscript has been analysed by the aforementioned studies for multi-view clustering. Table 5 shows the NMI and accuracy values of the clusterings performed by the multi-view clustering algorithms (these values are as given in the corresponding articles). In addition, the NMI and accuracy values of the K-means clustering applied on the multi-SNE low-dimensional embeddings (from 2 to 10 dimensions) are presented in the table. On handwritten digits, the multi-SNE variation with multi-CCA as pre-training and weight adjustments had the best performance (Table 4). This variation of multi-SNE with K-means was compared against the multi-view clustering algorithms and it was found to be the most accurate, while pre-training with PCA produced the highest NMI (Table 5). By applying K-means to the low-dimensional embeddings of multi-SNE can successfully cluster the observations of the data (Fig. S7 in Section 4.6 of the Supplemental File for a three-dimensional visualisation via multi-SNE).
| Multi-view clustering on handwritten digits data set | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Kumar, Rai & Hal (2011) | Liu et al. (2013) | Sun et al. (2015) | Ou et al. (2016) | Ou et al. (2018) | Multi-SNE with PCA/multi-CCA | ||||
| 2D | 3D | 5D | 10D | ||||||
| NMI | 0.768 | 0.804 | 0.876 | 0.785 | 0.804 | 0.863/0.838 | 0.894/0.841 | 0.897/0.848 | 0.899/0.850 |
| ACC | – | 0.881 | – | 0.876 | 0.880 | 0.822/0.914 | 0.848/0.915 | 0.854/0.922 | 0.849/0.924 |
The increasing number of multi-view, high-dimensional and heterogeneous data requires novel visualisation techniques that integrate this data into expressive and revealing representations. In this manuscript, new multi-view manifold learning approaches are presented and their performance across real and synthetic data sets with different characteristics was explored. The multi-SNE approach is proposed to provide a unified solution for robust visualisation and subsequent clustering of multi-view data.