
A new extension of Poisson distribution for asymmetric count data: theory, classical and Bayesian estimation with application to lifetime data
- Published
- Accepted
- Received
- Academic Editor
- Kumer Das
- Subject Areas
- Data Science, Optimization Theory and Computation
- Keywords
- Poisson-mixture, Dispersion, Moments, Estimation, Bayesian, Censoring, Data analysis
- Copyright
- © 2023 Alomair and Ahsan-ul-Haq
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. A new extension of Poisson distribution for asymmetric count data: theory, classical and Bayesian estimation with application to lifetime data. PeerJ Computer Science 9:e1748 https://doi.org/10.7717/peerj-cs.1748
Abstract
Several research investigations have stressed the importance of discrete data analysis and its relevance to actual events. The current work focuses on a new discrete distribution with a single parameter that can be derived using the Poisson mixing technique. The new distribution is named the Poisson Entropy-Based Weighted Exponential Distribution. It is useful for discussing asymmetric “right-skewed” data with “heavy” tails. Its failure rate function can be used to explain situations with increasing failure rates. The statistical properties of the new distribution are expressed explicitly. The proposed model is simple to manage for under-, equal-, and over-dispersed datasets. The model parameters are estimated using the maximum likelihood method. We consider the parameter estimation for the new model based on right-censored data with a cure fraction. One more focus of the present study is the Bayesian estimation of the model parameters. In the end, three real-world dataset examples were utilized to show the value of the new distribution. These applications revealed that the new model outperforms other standard discrete models.
Introduction
Numerous studies have emphasized the relevance of count data modeling which has aroused significant interest in a range of fields such as medical research, earth science, physics, economics, and insurance. Various lifetime probability distributions have been utilized and investigated in reliability theory. The Poisson distribution is commonly utilized to analyze the “symmetric” and “asymmetric” count datasets, but it cannot describe over-dispersed datasets. As a result, there has been a lot of interest in the discretization of continuous probability distributions. Several techniques may be used to obtain the discrete analog of a continuous probability distribution. The Poisson mixed approach gets great attention from researchers and is most commonly used for generalization or generation of new probability distributions. The Poisson mixed approach is discussed below.
If the Poisson parameter is a random variable with a parameterized distribution (P), then the resulting model is a discrete Poisson mixed model. The distribution P and its parameter vector Θ are referred to as prior distribution and hyperparameter, respectively. The resulting distribution of random variable X is stated as follows:
(1) where is the Poisson distribution with parameter as
(2)
is a continuous density function and is a random variable of the Poisson parameter .
In the literature, many authors have compounded the standard Poisson parameter using standard lifetime distributions. The negative binomial distribution was derived by Greenwood & Yule (1920) by combining the Poisson and gamma distributions. Johnson, Kemp & Kotz (1992) combined the Poisson and exponential distributions to get the geometric distribution. Similarly, various authors introduced mixed Poisson distributions, some examples include the Poisson Lindley (Sankaran, 1970), Poisson Pseudo Lindley (Zeghdoudi & Nedjar, 2017), Poisson transmuted exponential (Bhati, Kumawat & Gómez-Déniz, 2017), Poisson Xgamma (Altun, Cordeiro & Ristić, 2021), Poisson Ailamujia (Hassan et al., 2020), Poisson Quasi-Lindley (Altun, 2019), Poisson XLindley (Ahsan-ul-Haq et al., 2022), Poisson moment exponential (Ahsan-ul-Haq, 2022), and Poisson Mirra (Maya et al., 2022).
Al-Nasser, Rawashdeh & Talal (2022) introduced a new weighted exponential distribution. The resulting distribution is named entropy-based weighted exponential distribution (EBWED). Let X be a continuous random variable that follows EBWED with a single parameter . The probability density function (pdf) of EBWD will be.
(3)
The cumulative distribution function (cdf) of the EBWED is
(4)
The innovation of this study is the derivation of a new Poisson mixed distribution for under, equal, and over-dispersed count datasets to address the above-mentioned issues. This study has the following goals;
The main objective is to introduce a new flexible Poisson entropy-based weighted exponential distribution. The ensuing distribution is obtained by mixing Poisson with the entropy-based weighted exponential distribution. The moments and associated measures of the new distribution can be calculated analytically when compared to existing discrete distributions, and it has a strong modeling capability. The new model is also incredibly adaptable.
The model parameter is estimated using the maximum likelihood estimation (MLE) method. A comprehensive simulation is performed to assess the behavior ML estimates.
The new distribution is used to model “asymmetric” and “right skewed” data in the presence of complete and right-censored data.
We also take into account censored data with a cure fraction.
The Bayesian estimation approach is also utilized to estimate the model parameter.
The rest of the document is structured as follows: The derivation of the new discrete probability model is presented in “The PEBWE Distribution”. “Moments and Associated Measures” discusses its underlying mathematical characteristics. “Parameter Estimation” discusses the maximum likelihood estimation for the distribution parameter using complete, censored, and censored data with cure fraction. This section also discusses Bayesian estimation using the MCMC approach. Three examples are given in “Application” to illustrate the adaptability of the new distribution. In the end, concluding remarks and some future directions are given in “Conclusion”.
The pebwe distribution
The following proposition introduces a new mixed-Poisson model by combining the Poisson and Entropy-Based Weighted Exponential distributions.
Proposition 1. Suppose that X follows the compound Poisson-EBWE distribution (PEBWED), which has the following stochastic representation:
where and . Then, the pmf of X is given by
(5)
The new model is denoted as , and one can note to apprise that X follows that PEBWED with parameter .
Proof. The pmf of X can be obtained using the common mixing method shown below.
The proof is completed.
Figure 1 depicts the potential pmf plots of the proposed distribution.
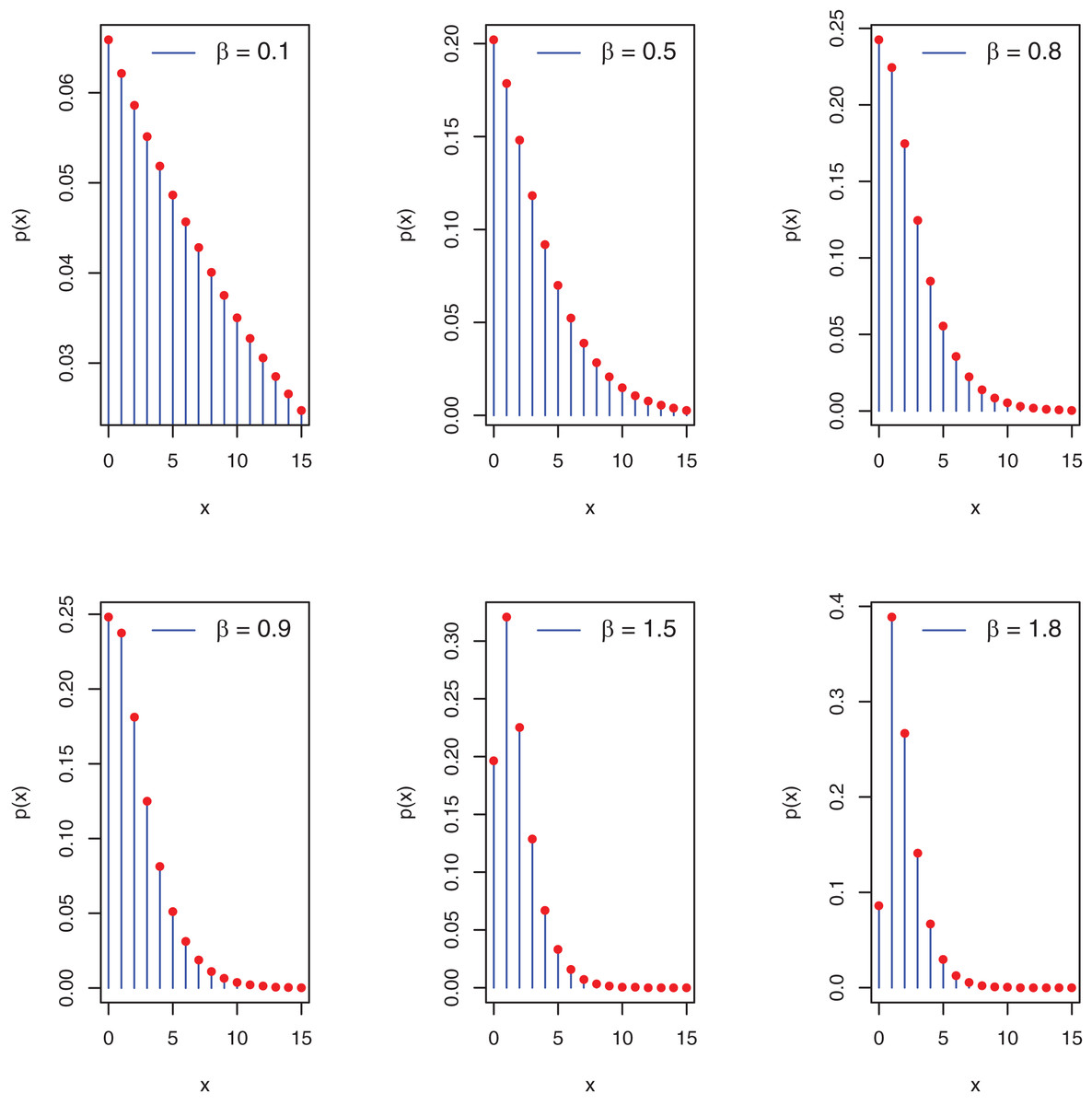
Figure 1: Plots of pmf of the PEBWED.
{kind=link}
Remark: The first derivative of pmf is
gives
(6)
For the is a critical point that maximizes the and the pmf is a decreasing function of x.
and
Therefore, the mode of PEBWED is given by
The cdf and survival function of the PEBWED is given by
(7) and
(8)
The hazard function (hf) of the PEBWED is given by
(9)
Proposition 2: The PEBWED hf increases as x increases.
Proof: Using the idea of Glaser (1980) and from the pmf of PEBWED
It follows that
As , the hf of PEBWED is increasing function.
Furthermore, the graphs in Fig. 2 pertain to the possible shapes of the PEBWED.
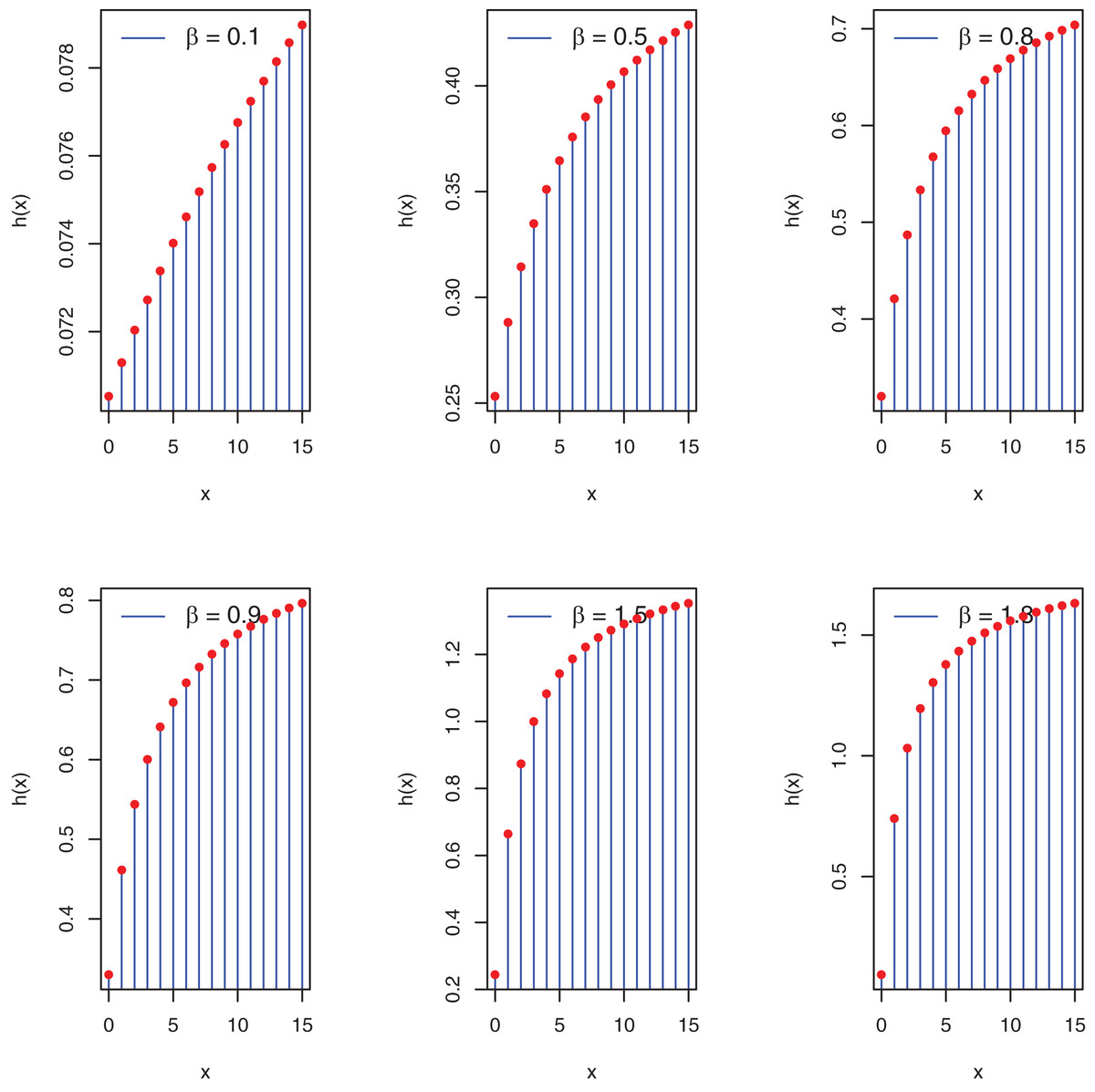
Figure 2: Plots of hf of the PEBWED.
{kind=link}
Moments and associated measures
In this section, moments, probability generating function, moment generating function, and their associated measures, mean, variance, dispersion index, skewness, and kurtosis are derived and discussed.
Proposition 3: The rth factorial moments of PEBWED are given by
(10)
Proof: The factorial moment can be calculated using the compound-Poisson theory as follows:
which complete the proof.
By replacing r = 1, 2, 3, and 4 in Eq. (10), the first four factorial moments of the PEBWED can be derived.
That is,
and
Now, using the general connection between factorial moments and moments about the origin, the first four moments about the origin of the PEBWED are obtained. We get
(11)
Therefore, the variance of PEBWED is obtained as
(12)
The dispersion Index (DI) of the PEBWED is given by
(13)
To obtain explicit formulations for the skewness and kurtosis of the PEBWED, apply the following equations.
and
Proposition 4: The probability generating function (pgf) of PEBWED is given by
(14) for
Proof: The pgf of the PEBWED is derived using the well-known compound-Poisson theory in the manner described below
which completes the proof.
The moment generating function (mgf) and characteristic function (cf) of the PEBWED are obtained from Eq. (14) when s is substituted by and respectively. They are provided, respectively, by
(15) for and
(16) for
The mean, variance, DI, skewness, and kurtosis for the PEBWED are now shown numerically in Table 1 for various parameter choices.
| 0.1 | 13.028 | 164.42 | 1.7974 | 7.6916 | 12.620 | 0.9842 |
| 0.5 | 3.1812 | 10.511 | 1.6455 | 6.8850 | 3.3040 | 1.0191 |
| 0.8 | 2.2720 | 5.3450 | 1.5602 | 6.4932 | 2.3526 | 1.0176 |
| 0.9 | 2.1163 | 4.5742 | 1.5307 | 6.3703 | 2.1614 | 1.0106 |
| 1.2 | 1.8525 | 3.2068 | 1.4354 | 6.0221 | 1.7311 | 0.9667 |
| 1.5 | 1.7880 | 2.4702 | 1.3414 | 5.7724 | 1.3815 | 0.8790 |
| 1.8 | 1.9033 | 1.8930 | 1.3640 | 5.9838 | 0.9946 | 0.7229 |
| 2.0 | 2.1294 | 1.3538 | 2.0214 | 7.3516 | 0.6358 | 0.5464 |
Parameter estimation
In this section, the model parameter is estimated using the maximum likelihood approach based on complete and censored sampling, censored sampling with cure fraction. This section also covers parameter estimation using the Bayesian approach.
ML estimation based on complete data
Let be a random sample obtained from a PEBWE distribution. The log-likelihood function is defined as follows
(17)
For the maximum likelihood (ML) estimator of the parameter, differentiate Eq. (17) for β
(18)
Equating Eq. (18) to zero and solving for yields the ML estimator. The resultant expression has no closed-form solution, implying that numerical methods are required to get the ML estimate of the parameter.
ML estimation based on censored data
Given a random sample of size , the ith individual’s involvement to the likelihood function is given by
where is a censoring indicator variable; it is equal to one for the survival time that was observed and zero for one that was right-censored. The likelihood function for the model parameter is provided by when the data have a PEBWE distribution.
(19)
The corresponding loglikelihood function is
(20)
We have derived the log-likelihood function about β
(21)
When we set Eq. (21) to zero, we have the scoring equation that corresponds, and its numerical solution yields the ML estimator.
ML estimation based on censored data and a cure fraction
Survival analysis reveals that a subset of people seems to be impervious to the occurrence of the important event. In clinical trials, some patients who react to the treatment may experience prolonged symptom relief or perhaps a complete recovery. The conventional mixing model’s survival function is provided by
where is the proportion of immunes or cure fraction, and is a baseline survival function for vulnerable persons. Given a random sample of size , the ith subject’s contribution to the likelihood function is given by
where is the susceptible individuals’ baseline pdf and is a censoring indicator variable. The likelihood and log-likelihood functions for parameter β are given below.
(22) and
(23)
After differentiating the log-likelihood function for parameters and setting the resultant derivatives to zero, the ML estimators are generated by solving the appropriate equations.
Bayesian estimation
The Bayesian approach has become the most extensively utilized technique in a range of domains, including but not limited to numerous applications. It is especially helpful in engineering, reliability, health sciences, epidemiology, and quality studies due to its capacity to incorporate prior information into the study. So, under this approach, a prior distribution must be assigned to each parameter. For the PEBWE distribution, we can consider the gamma distribution as the prior distribution for the parameter and the beta distribution for the cure fraction parameter . The density functions for the gamma and beta distributions are
and
where are the hyperparameters.
The joint posterior expression is gained by multiplying the likelihood function given in Eq. (17) by the prior distribution densities. To simulate the sample from the posterior density, we utilized the Markov chain Monte Carlo (MCMC) procedures as Gibs sampling. We generate 1,006,000 samples for each denomination of parameter. The first 6,000 simulated samples were eliminated as part of a burn-in phase, which is often used to reduce the influence of starting values. The parameter Bayesian estimates were obtained as the mean of samples specified from the joint posterior distribution. Traceplots and the Geweke diagnostic were used to monitor the convergence of the simulated samples. Further, the highest posterior density (HPD) interval of 95% was obtained using the simulated posterior distributions.
Simulation
Here, we conduct a comprehensive simulation analysis to assess the maximum likelihood estimation approach using complete data. Random samples of the PEBWE distribution of sizes (n) 10, 20, 50, 100, and 200 were used considering different values of the parameter (β). All simulation results were based on N = 10,000 replications for the different sample sizes considered for each parameter setting. Table 2 shows the results of the average estimates, absolute bias (AB), mean relative error (MRE), and mean square error (MSE) of all parameter values.
| Parameter | AB | MRE | MSE | |
|---|---|---|---|---|
| 10 | 0.0141 | 0.1410 | 0.0024 | |
| 20 | 0.0064 | 0.0642 | 0.0008 | |
| 50 | 0.0024 | 0.0245 | 0.0003 | |
| 100 | 0.0010 | 0.0102 | 0.0001 | |
| 200 | 0.0007 | 0.0074 | 0.0001 | |
| 10 | 0.1533 | 0.3067 | 0.1955 | |
| 20 | 0.0660 | 0.1320 | 0.0531 | |
| 50 | 0.0180 | 0.0360 | 0.0106 | |
| 100 | 0.0106 | 0.0212 | 0.0046 | |
| 200 | 0.0049 | 0.0097 | 0.0021 | |
| 10 | 0.1794 | 0.2242 | 0.2393 | |
| 20 | 0.1020 | 0.1275 | 0.1153 | |
| 50 | 0.0480 | 0.0600 | 0.0420 | |
| 100 | 0.0219 | 0.0273 | 0.0175 | |
| 200 | 0.0117 | 0.0147 | 0.0078 | |
| 10 | 0.1597 | 0.1774 | 0.2351 | |
| 20 | 0.1032 | 0.1146 | 0.1186 | |
| 50 | 0.0522 | 0.0580 | 0.0502 | |
| 100 | 0.0239 | 0.0266 | 0.0237 | |
| 200 | 0.0112 | 0.0124 | 0.0107 | |
| 10 | 0.0309 | 0.0206 | 0.2654 | |
| 20 | 0.0326 | 0.0218 | 0.1008 | |
| 50 | 0.0280 | 0.0187 | 0.0433 | |
| 100 | 0.0152 | 0.0102 | 0.0223 | |
| 200 | 0.0108 | 0.0072 | 0.0110 | |
| 10 | 0.2553 | 0.1418 | 0.4160 | |
| 20 | 0.1028 | 0.0571 | 0.1776 | |
| 50 | 0.0012 | 0.0007 | 0.0192 | |
| 100 | 0.0035 | 0.0020 | 0.0030 | |
| 200 | 0.0012 | 0.0007 | 0.0014 |
Application
In this section, the new model is applied to three over-dispersed and asymmetric, and right-skewed datasets. We compare the fits of PEBWE distribution with Poisson Ailamujia (PA), discrete Burr Hatke (DBH), discrete inverted Topp-Leone (DITL), discrete moment exponential (DME), and Poisson distributions. Different model selection and goodness-of-fit criteria, log-likelihood (L), Akaike information criteria (AIC), Bayesian information criteria (BIC), and Kolmogorov-Smirnov tests are used to compare the fitted models.
Data I: The first data set is about the number of daily death due to coronavirus in China from 23 January to 28 March 2020. The data set is reported at https://www.worldometers.info/coronavirus/country/china/. The data are: 8, 16, 15, 24, 26, 26, 38, 43, 46, 45, 57, 64, 65, 73, 73, 86, 89, 97, 108, 97, 146, 121, 143, 142, 105, 98, 136, 114, 118, 109, 97, 150, 71, 52, 29, 44, 47, 35, 42, 31, 38, 31, 30, 28, 27, 22, 17, 22, 11, 7, 13, 10, 14, 13, 11, 8, 3, 7, 6, 9, 7, 4, 6, 5, 3 and 5. The MLEs, standard errors, and goodness-of-fit measures are presented in Table 3. PP plots of all considered distributions for the first dataset are given in Fig. 3.
| Statistic | Model | |||||
|---|---|---|---|---|---|---|
| PEBWE | PA | DBH | DITL | DME | Poisson | |
| 0.02446 | 0.02010 | 0.99974 | 0.35393 | 25.121 | 49.742 | |
| SE | 0.00305 | 0.00178 | 0.00185 | 0.04357 | 2.1865 | 0.86814 |
| 324.30 | 329.99 | 461.02 | 366.91 | 330.52 | 1,409.8 | |
| AIC | 650.60 | 661.97 | 924.04 | 735.81 | 663.03 | 2,821.6 |
| BIC | 652.79 | 664.16 | 926.23 | 738.00 | 665.22 | 2,823.8 |
| KS | 0.0876 | 0.1670 | 0.8120 | 0.3290 | 0.1720 | 0.4970 |
| p-value | 0.6900 | 0.0490 | 0.0000 | 0.0000 | 0.0410 | 0.0000 |
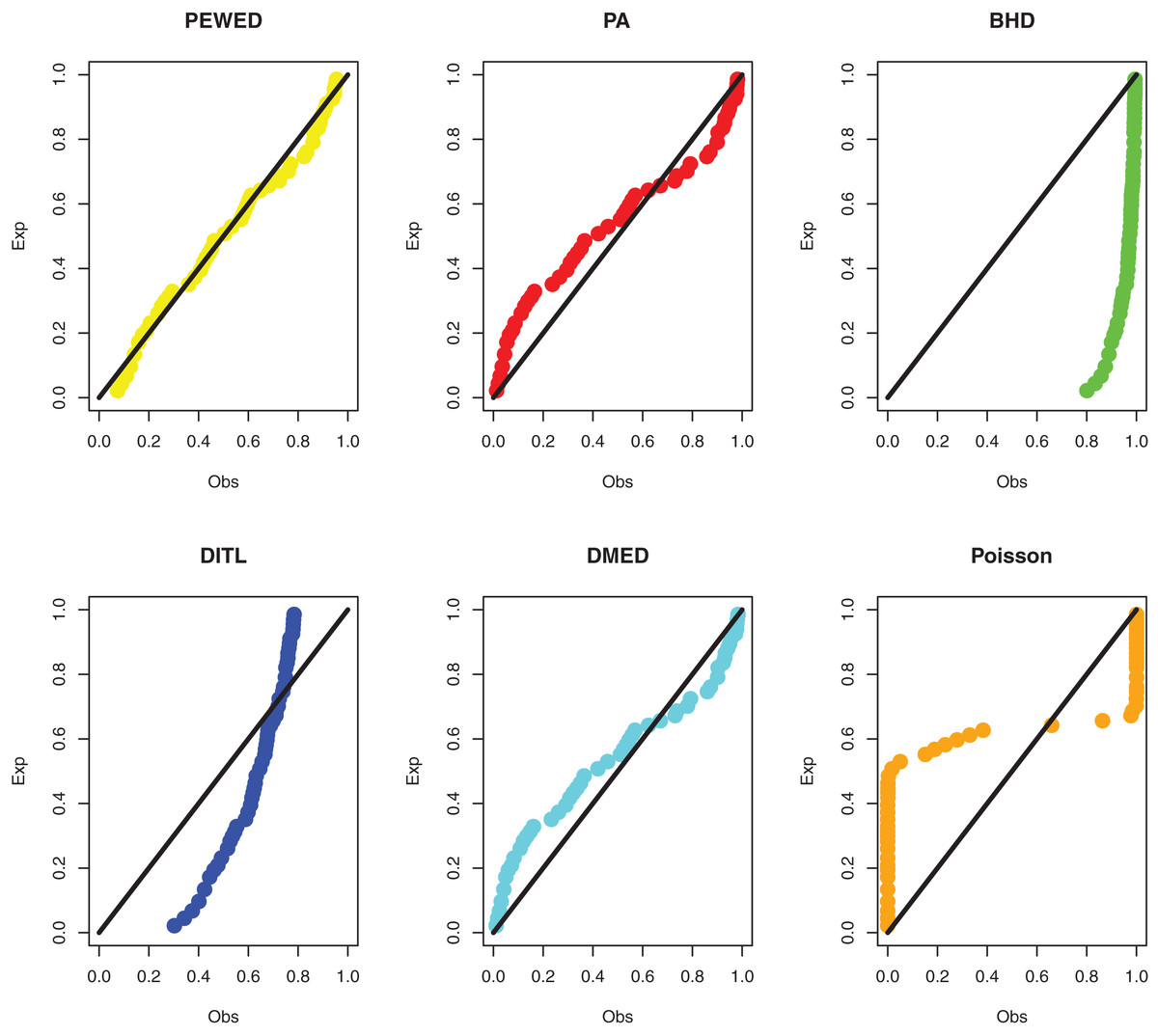
Figure 3: PPP plots of all fitted models for first dataset.
{kind=link}
The next goal of this study was to estimate the model parameter using the Bayesian estimation approach presented in “Bayesian Estimation”. The posterior mean for the parameter is 0.0245, and the 95% HPD is 0.0186 to 0.0304. The posterior samples are presented in Fig. 4. The ACF (autocorrelation function) indicates that the posterior samples are independent, and the traceplot demonstrates the appraisal of MCMC samples over the iterations. The Geweke z-score (0.6071) is also indicative of satisfactory convergence of drawn samples to a stable distribution.
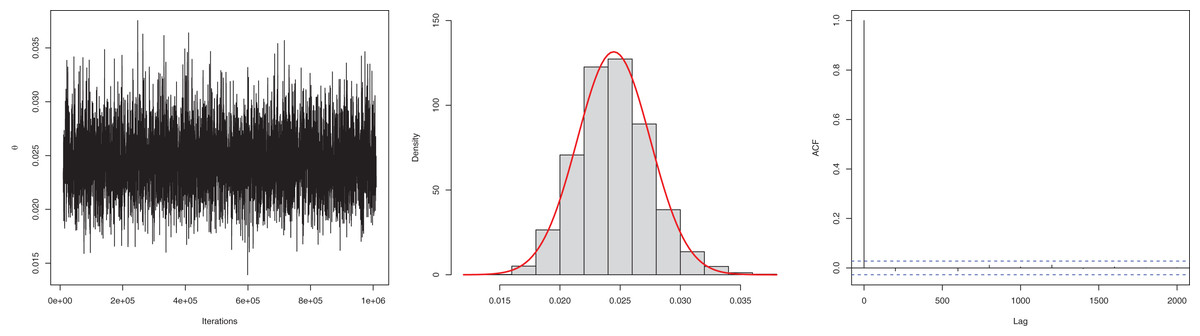
Figure 4: Traceplot, density, and ACF plot for the first data.
{kind=link}
Data II: The second dataset below is remission times (in weeks) for a group of 30 patients with leukemia who received similar treatment (Lawless, 2011). The data observations are; 1, 1, 2, 4, 4, 6, 6, 6, 7, 8, 9, 9, 10, 12, 13, 14, 18, 19, 24, 26, 29, 31+, 42, 45+, 50+, 57, 60, 71+, 85+, 91. The observations with “+” indicate censored times. Using the methodology outlined in “ML estimation based on censored data”, we compute the MLEs. Table 4 shows the ML estimate and goodness of fit metrics. Figure 5 shows a comparison of the PP plots for the model based on the PEBWE distribution and the competitive discrete distributions. The findings presented by models show that the PEBWE distribution efficiently evaluated this data, while the PA distribution is the second-best model. The data was not well fit by models based on the discrete DBH, DITL, and Poisson distributions.
| Statistic | Model | |||||
|---|---|---|---|---|---|---|
| PEBWE | PA | DBH | DITL | DME | Poisson | |
| 0.0402 | 0.0352 | 0.9992 | 0.3829 | 14.420 | 19.118 | |
| SE | 0.0083 | 0.0050 | 0.0035 | 0.0766 | 1.6500 | 0.8940 |
| 111.21 | 117.44 | 147.97 | 115.24 | 118.19 | 290.41 | |
| AIC | 224.41 | 236.88 | 297.94 | 232.48 | 238.38 | 582.81 |
| BIC | 225.81 | 238.29 | 299.34 | 233.88 | 239.78 | 584.21 |
| KS | 0.1630 | 0.2490 | 0.7280 | 0.2650 | 0.2550 | 0.4160 |
| p-value | 0.4000 | 0.0480 | 0.0000 | 0.0300 | 0.0400 | 0.0000 |
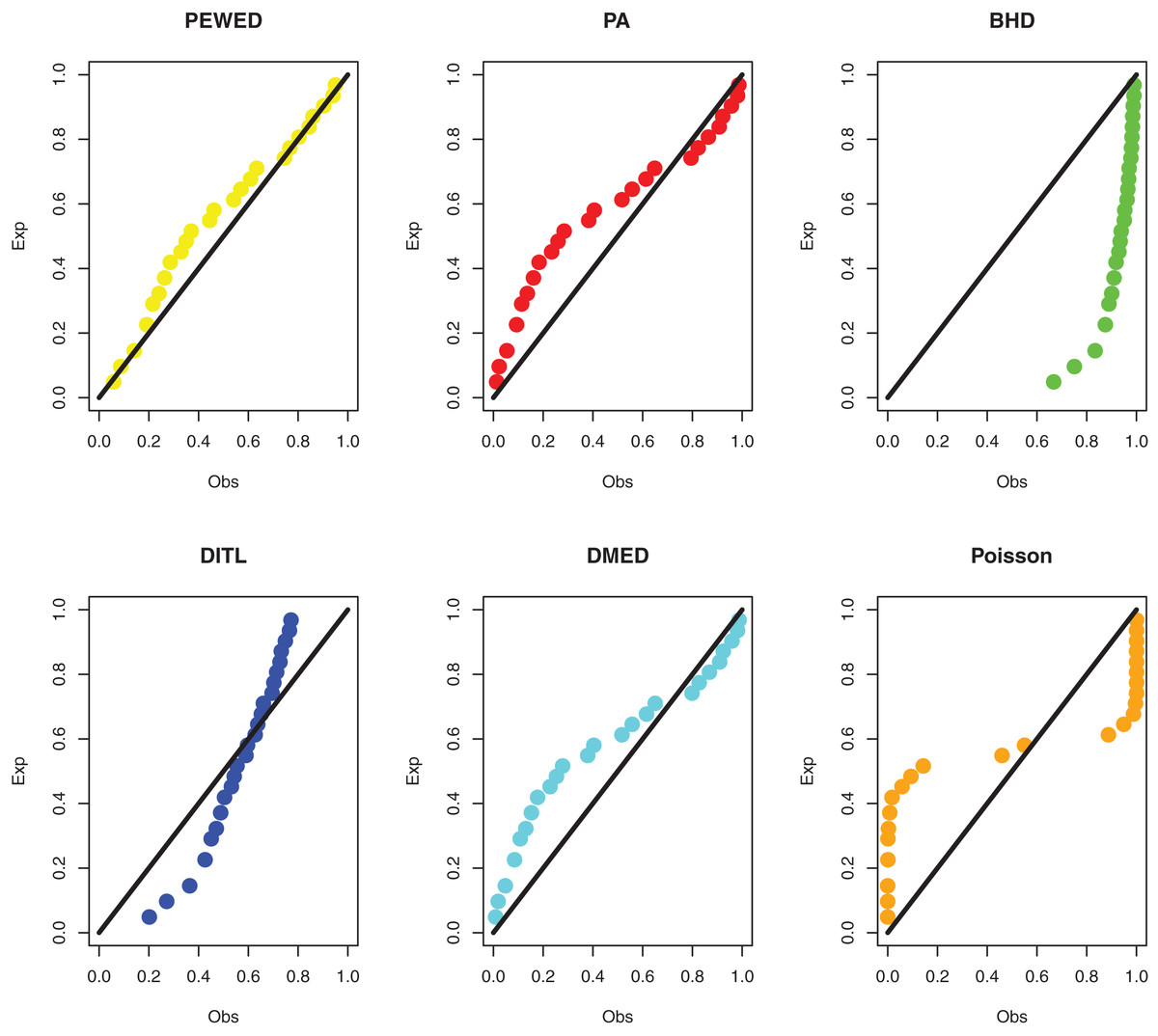
Figure 5: PP plots of all fitted models for the second dataset.
{kind=link}
In the Bayesian estimation, similar to the previous example, we utilized gamma as the prior distribution. The mean is 0.0402, and the 95% HPD is 0.02502 to 0.0565. The posterior samples for the parameter are presented in Fig. 6. The ACF (autocorrelation function) indicates that the posterior samples are independent, and the traceplot demonstrates the appraisal of MCMC samples over the iterations. The Geweke z-score (−0.2249) is also indicative of satisfactory convergence of drawn samples to a stable distribution.
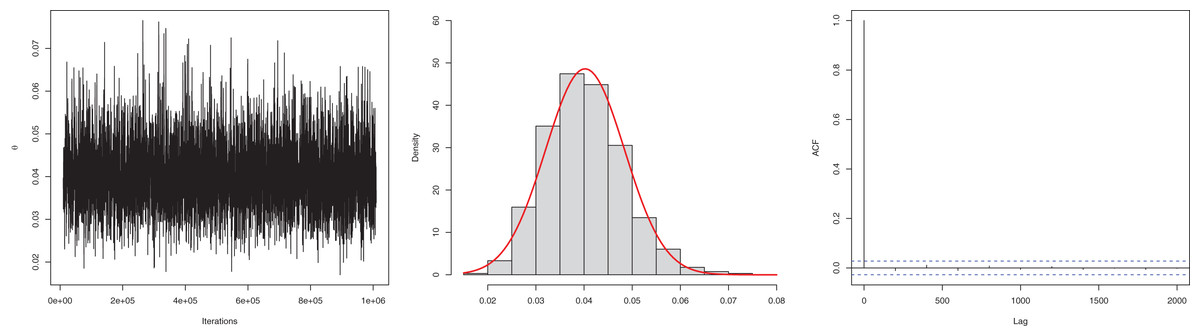
Figure 6: Traceplot, density, and ACF plot for the second data set.
{kind=link}
Data III: The third dataset is about survival data with a cure fraction. Consider the findings of research done between 2003 and 2013 at the Musculoskeletal Oncology Center of Sun Yat-Sen University’s First Affiliated Hospital in China (Wang et al., 2015). This study’s goal was to assess the efficacy of modular hemipelvis endoprosthesis rebuilding after pelvic tumor resection. Recurrence times for pelvic tumors with marginal or intracapsular margins were 3, 7, 11*, 18, 22*, 25, 28, 32*, 34*, 35, 35*, 36*, 40*, 40*, 41, 54*, 66*, 76*, 84*, 88*, and 92* months, with an asterisk (*) denoting a censored observation. We acquire the ML estimations using the approach described in “ML estimation based on censored data and a cure fraction”. Table 5 shows the ML estimate and goodness of fit metrics. The PP plots based on all competitive distributions are given in Fig. 7. We can see that the results from the PEBWE distribution provide the best fit.
| Statistic | Model | |||||
|---|---|---|---|---|---|---|
| PEBWE | PA | DBH | DITL | DME | Poisson | |
| 0.0307 | 0.0350 | 0.9999 | 0.1130 | 14.369 | 21.922 | |
| SE | 0.0264 | 0.0131 | 0.0144 | 0.0883 | 3.9690 | 1.7400 |
| 0.5162 | 0.5799 | 0.6580 | 5.5e-07 | 0.5820 | 0.1290 | |
| SE | 0.2279 | 0.1396 | 0.1056 | 0.6640 | 0.1340 | 0.1270 |
| 40.503 | 41.079 | 54.416 | 42.969 | 41.091 | 50.960 | |
| AIC | 85.006 | 86.158 | 112.83 | 89.938 | 85.182 | 105.92 |
| BIC | 87.095 | 88.247 | 114.92 | 92.028 | 88.271 | 108.01 |
| KS | 0.2350 | 0.3290 | 0.8410 | 0.6470 | 0.3350 | 0.6500 |
| p-value | 0.2000 | 0.0210 | 0.0000 | 0.0000 | 0.0180 | 0.0000 |
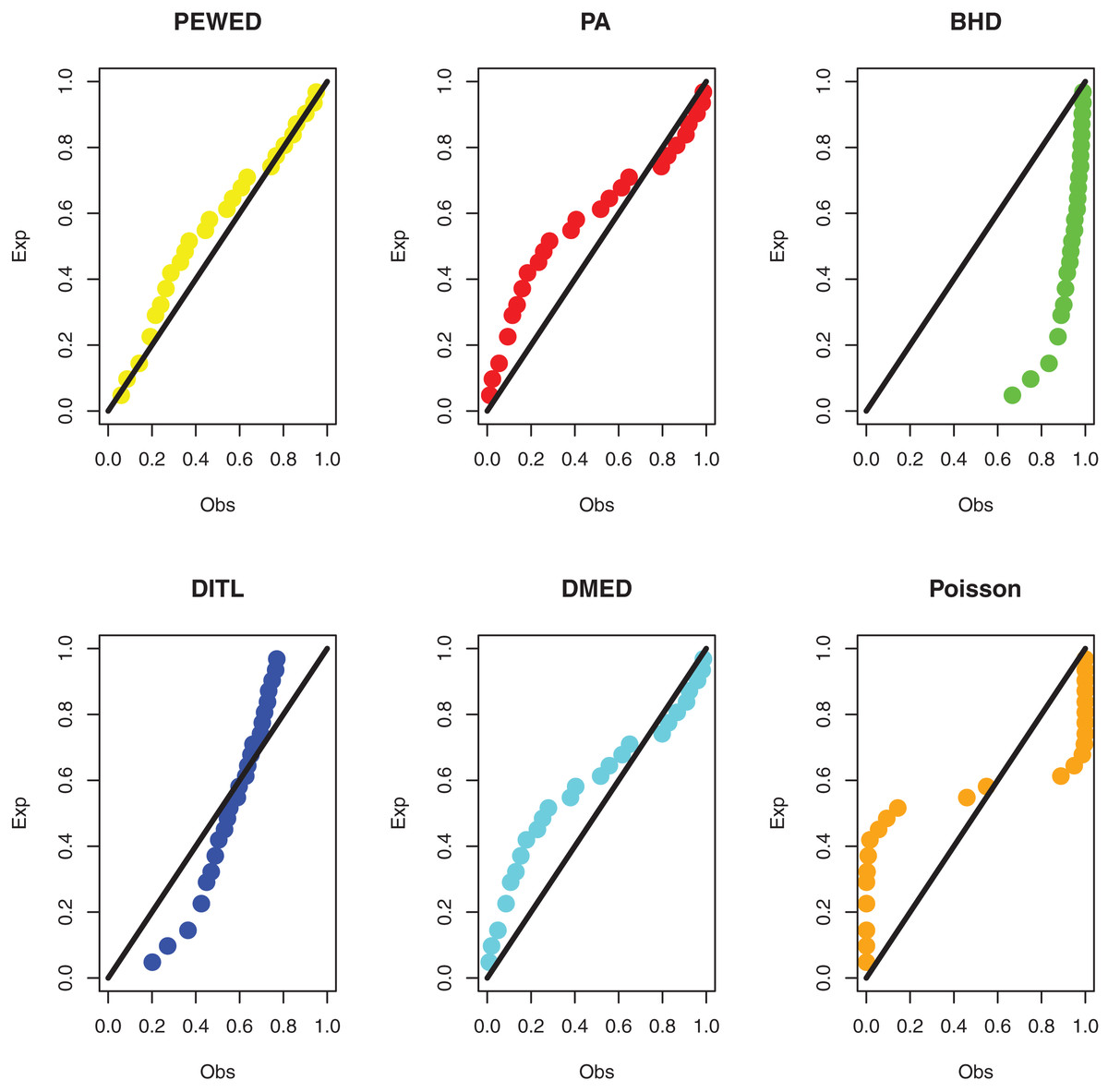
Figure 7: PP plots of all fitted models for third dataset.
{kind=link}
Similar to the previous example, for the Bayesian estimation, we utilized gamma and beta distribution as prior for and parameters. The means of posterior density for the parameters are with a 95% HPD interval (0.0301–0.1401) and with a 95% interval (0.4131–0.8434). The posterior samples for the parameter are presented in Fig. 8. The ACF (autocorrelation function) indicates that the posterior samples are independent, and the traceplot demonstrates the appraisal of MCMC samples over the iterations. The Geweke z-score (0.6607) is also indicative of satisfactory convergence of drawn samples to a stable distribution.
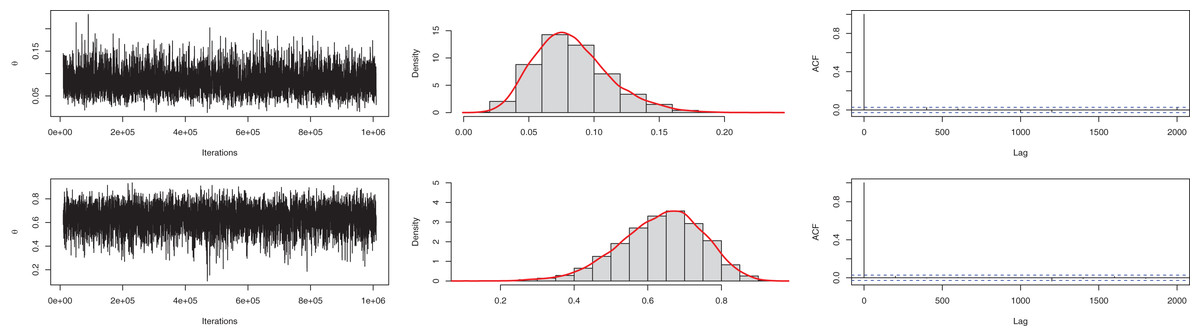
Figure 8: Traceplot, density, and ACF plot for the third data.
{kind=link}
Conclusion
Discrete probability models play an important role in the analysis of count datasets. A new one-parameter discrete distribution is proposed by mixing Poisson and entropy-based weighted exponential distributions. Derived some important mathematical properties of the new model. The model parameter is estimated using the maximum likelihood and Bayesian estimation methods. The Bayesian estimation was performed using the MCMC approach using the Metropolis-Hastings algorithm. More importantly, the new probability model is applied to three datasets one is based on the number of deaths due to COVID-19, second leukemia patients, and third pelvic tumors patients. The proposed distribution provides more efficient results than all considered competitive distributions.