
Symbolic expression generation via variational auto-encoder
- Published
- Accepted
- Received
- Academic Editor
- Muhammad Aleem
- Subject Areas
- Artificial Intelligence, Data Mining and Machine Learning, Data Science, Neural Networks
- Keywords
- Symbolic regression, VAE, LSTM, Constrained optimization, Generation, Machine learning
- Copyright
- © 2023 Popov et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. Symbolic expression generation via variational auto-encoder. PeerJ Computer Science 9:e1241 https://doi.org/10.7717/peerj-cs.1241
Abstract
There are many problems in physics, biology, and other natural sciences in which symbolic regression can provide valuable insights and discover new laws of nature. Widespread deep neural networks do not provide interpretable solutions. Meanwhile, symbolic expressions give us a clear relation between observations and the target variable. However, at the moment, there is no dominant solution for the symbolic regression task, and we aim to reduce this gap with our algorithm. In this work, we propose a novel deep learning framework for symbolic expression generation via variational autoencoder (VAE). We suggest using a VAE to generate mathematical expressions, and our training strategy forces generated formulas to fit a given dataset. Our framework allows encoding apriori knowledge of the formulas into fast-check predicates that speed up the optimization process. We compare our method to modern symbolic regression benchmarks and show that our method outperforms the competitors under noisy conditions. The recovery rate of SEGVAE is 65% on the Ngyuen dataset with a noise level of 10%, which is better than the previously reported SOTA by 20%. We demonstrate that this value depends on the dataset and can be even higher.
Introduction
The discovery of new laws from experimental observations may seem to be an old and long-forgotten topic at first sight. Indeed, in the age of data-driven science, neural networks can easily fit a pretty complicated dependency. However, generalization and interpretation of those networks usually leaves much to be desired. For such phenomena as a biotech reaction, molecular dynamics potentials, or epidemic spread, a learning algorithm representing the dependency between target property and dependent characteristic in a simplistic and human-conceivable, such as usual formulas, is invaluable. There are many tasks where the black-box algorithms cannot be trusted with your eyes closed, i.e., in self-driving cars, medicine, markets analyses, aircraft design and so on. In other words, areas where the cost of error is very high, so it is necessary to understand why algorithm made one decision or another. Such examples are everywhere. Moreover, the Symbolic Regressions techniques are suitable for solving an optimal control task (Sahoo, Lampert & Martius, 2018b). Optimal control task deals with the problem of finding a control law for a given system such that a certain criterion is achieved, solution to this problem is a function of time (Diveev, Konstantinov & Danilova, 2021).
Several methods enhancing the so-called symbolic regression approach have been developed recently (Udrescu & Tegmark, 2020), where the goal was to reconstruct 100 formulas from Feynman’s lectures on physics. In a recent article, the symbolic regression was applied to find thermodynamic description of ionic transport out of experimental data (Flores et al., 2022). The resulting formula reflects physical principles of underpinning ionic transport. Symbolic regression is akin to a simple regression, as it fits experimental data. However, symbolic regression tries to find suitable and functional feature transformations represented by a computational graph over the original feature vector. Such graphs impose additional complications while optimizing those using gradient descent-based approaches.
Another difficulty such methods regularly face is the inherent noisiness of experimental measurements. Hence, each algorithm should ideally provide theoretical or empirical guarantees of the noise level robustness. The example of noisy data can be found in all kind of experimental data and sometimes the noise level could be quite high depending on experiment type (Eling, Morgan & Marioni, 2019; Reinbold et al., 2021). Since the scientific theories or models has to be proven or validated by experiment the ability to reconstruct the symbolic solution of observe effect is critically important. We address this issue by the algorithm presented in this work.
One of our key contributions is the design of a novel process of the symbolic regression training SEGVAE that differs from the current state-of-the-art approaches: higher noise stability, higher data efficiency, and adjustability of the priors for the symbolic expression to the physics intuition of the user. Often scientists do know the frame of the searching formula (e.g., limits and approximations) and laws that data have to follow. We introduce a predicate mechanism for formula search and the ability to implement known conversation laws. These features are essential for processing experimental data.
The structure of this article is the following: “Literature Review” contains an overview of prior symbolic methods, and “Methods” contains a description of our approach. All experiments with comparing performance are presented in “Results”. “Conclusions” concludes the article.
Literature review
The goal of using artificial intelligence to help discover the scientific laws underlying experimental data has been pursued in several works. Some of these works assume prior knowledge of the mystery environments of interest. However, the ones most relevant to our study are the ones that minimize any assumptions.
Since the symbolic regression problem is a discrete optimization task with the search space that exponentially depends on expression length, the majority of traditional approaches generally exploit genetic algorithms Searson, Leahy & Willis (2010) and Koza (1994). In this algorithms the process of optimization is inspired by the natural selection and relies on operators such as mutation, crossover and selection (Michalewicz & Schoenauer, 1996). The new populations are produced by iterative applying of genetic aforementioned operators on individuals from current population. The most successful one of these approaches is the commercial software Eureqa (Schmidt & Lipson, 2009), which was developed more than 10 years ago and still holds one of the leading positions in the field.
There are several recent works dedicated to recovering physical laws in symbolic form. Udrescu & Tegmark (2020) introduce an AI Feynman algorithm and further improved in Udrescu et al. (2020). AI Feynman 2.0 uses (a) physics-inspired deep learning strategies, (b) dimensional analysis like search for symmetries, separability, and alike, (c) brute forces the simplified equation that recovers physical equations from experimental data. While this algorithm does a good job simplifying expressions, it struggles to recover expressions that could not be simplified enough.
PySR (Cranmer et al., 2020) is basically reincarnation of Eureqa used friendly interface which allows to introduce predicates. PySR built on Julia, uses regularized evolution, simulated annealing, and gradient-free optimization and interfaced by Python.
An interesting and intuitively easy approach was demonstrated in Martius & Lampert (2016). Later this method was updated in Sahoo, Lampert & Martius (2018a) and in it’s latest version (Werner et al., 2021). The authors proposed architecture similar to a multilayer perceptron (MLP), where instead of a single activation for all outputs, they used a custom set of activation functions. The authors claim the efficiency of such an approach over MLP neural networks outside of the training set region. Thus good extrapolation capabilities have been demonstrated. Unfortunately, the authors did not present comparison results with other existing methods on common datasets.
Another deep learning approach to symbolic regression is introduced by Petersen et al. (2021). The authors present a gradient-based approach for symbolic regression based on reinforcement learning, which they call deep symbolic regression (DSR). DSR consists of a recurrent neural network that outputs a distribution over mathematical formulas. This network is used to sample equations, which will be evaluated based on the given dataset. Then the evaluation result will be used to further improve the distribution over mathematical formulas making the better expressions more probable. The DSR method has recently been updated by introducing a genetic programming component, significantly enhancing several benchmark tests. The latest algorithm version performs better than others to the best of our knowledge. Thus, we are using it (Mundhenk et al., 2021) as a baseline known as DSO. DSO uses some prebuilt predicates to avoid nested repeating functions e.g., , but a more complex or physics-inspired predicates introduction is challenging.
A recent study was dedicated to mixed approach of computer vision methods and transformers to symbolic regression problem (Li, Yuan & Shen, 2022). The workflow is the following: the input data is represented by image, this image is treated by convolution layers to create the image embedding to feed the transformer. However, proposed approach might be useful only for a datasets, containing a large number of points. In addition, the results of proposed algorithm was not compared with published SOTA aproaches.
SciNet (Iten et al., 2020) approach is inspired by human thinking along a physical modeling process. Just like human physicists do not rely on actual observations but rather on their compressed representation to make some theoretical conclusions, SciNet encodes the experimental data to a latent representation that stores different physical parameters and uses this representation to answer specific questions about the underlying physical system. Undoubtedly SciNet is successful at learning relevant physical concepts. However, its goals are very different from ours: it does not recover the laws in symbolic form but uses a neural network to model them.
In an article on neural-symbolic regression that scales (Biggio et al., 2021) authors propose to use pre-trained transformers (Vaswani et al., 2017) to predict symbolic expression. The network consists of a transformer encoder and transformer decoder trained on generated formulas and BFGS algorithm for constants optimization. They compare transformer results to DSR (previous version of DSO) as a baseline. Despite good evaluation time, results quality is lower than DSR on the Nguyen dataset.
Our method is akin to the work by Bowman et al. (2016). It adapts the variational autoencoder by using LSTM RNNs for both encoder and decoder. Thus, forming a sequence autoencoder with the Gaussian prior acting as a regularizer on the hidden code. The proposed generative model incorporates distributed latent representations of entire sentences. By examining paths through this latent space, it is possible to generate coherent novel sentences that interpolate between known sentences.
Methods
This section introduces the symbolic expression generation via variational auto-encoder (SEGVAE) algorithm (Sergei et al., 2022). In a nutshell, our architecture is a variational auto-encoder (Kingma & Welling, 2013) in which the encoder and decoder are based on recurrent neural networks. The primary motivation behind using VAE for symbolic sequence representation is that VAE conveys a regularized learning method that minimizes the volume of low-energy (noise) representation space, thus preserving the richness of the signal (relevant sequences) representation. We also describe here our implementation of this architecture and the training procedures.
Architecture
SEGVAE sequentially generates formulas. It is possible due to the one-to-one correspondence between sequences of tokens and formulas. Each token can be one of three types: input variables, constants, and operators. In this article our typical library of operators is [‘ ’, ‘ ’, ‘ ’, ‘ ’, ‘ ’, ‘ ’, ‘ ’, ‘ ’]. The number of variables X and constants depends on a task. We discuss the way to deal with constants in the subsection below. We use normal Polish notation to represent formulas as sequences in which operators precede their operands. The main advantage of Polish notation over the conventional one is that Polish representation is unambiguous and does not require brackets.
Variational autoencoder
VAE is a generative encoder-decoder based latent variable model. Given an observation space with a distribution the model’s encoder maps it into a latent space with a distribution , and the model’s decoder maps back into the observation space . Let -dimensionality of the latent space, , -the components of vectors . If and , then the objective takes the following form:
(1)
This approach allows the model to decode plausible equations from every point in the latent space that has a reasonable probability under the prior. As long as we can represent expressions as sequences of tokens, we rely on traditional NLP approaches. Our encoder and decoder are both one-layer LSTMs with 64 hidden units.
Training procedure
Here we summarize the details of our training protocol, which consists of two steps pre-training and the main training cycle.
Pre-training
This step allows the model to memorize the general formula structure and generate valid formulas afterward. Firstly, we randomly sample sequences of tokens from given library . However, uniformly sampling expressions with internal nodes is not a simple task. Naive algorithms tend to favor specific kinds of expressions. Therefore, we follow the data generator technique introduced in Lample & Charton (2020). Secondly, we choose only statements that meet our predicate conditions and thus create a pre-train dataset. Also, we add to the pre-train dataset a set of generalized formulas that commonly appear in natural science. Then the variational autoencoder is trained on these formulas. As a result of training, the vast majority of generated formulas in the next steps of the algorithm are valid formulas, so for the sake of simplicity, we can safely ignore invalid formulas in the following stages. Note that this step does not depend on the target task at all, so we do the pre-training once for each library . The schematic picture of pre-train process and algorythm arhitecture presented in Fig. 1A. Figure 1B shows the formation of the Bank of Best Formulas.

Figure 1: The SEGVAE architecture and training scheme.
(A) Pretraining and training scheme. (B) Sampling scheme, where output formula evaluates and goes to the Bank of Formulas.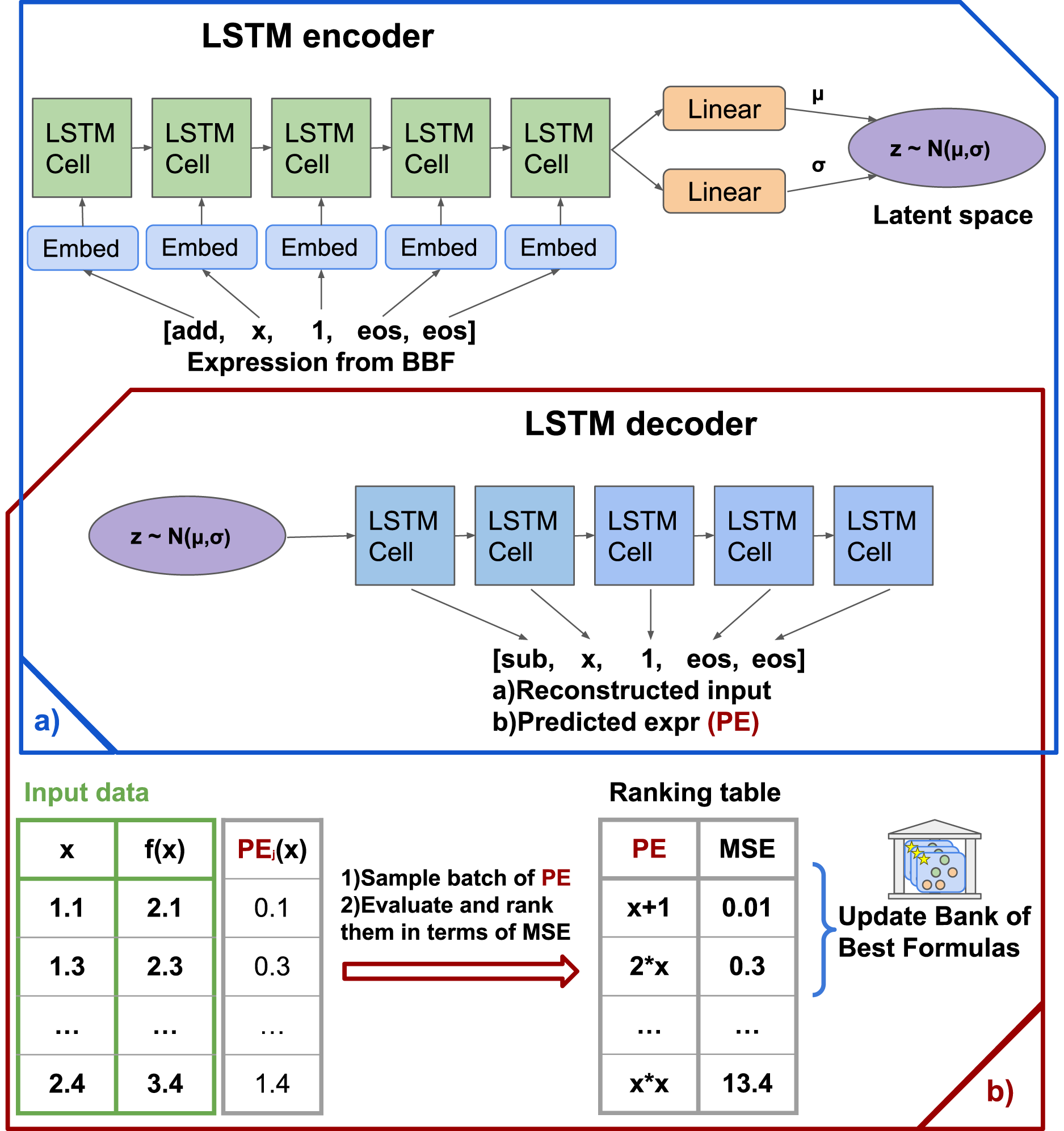{kind=link}
Main training cycle
When the model can generate valid formulas, it is time to teach it to generate valid formulas which describe a given environment or system under exploration. Firstly, a batch of formulas is sampled using the variational autoencoder for each epoch. Then, all the duplicates and invalid formulas are removed. Secondly, each formula is evaluated on the dataset in terms of mean squared error between and :
(2)

| Input: data (X, y), library of operators , Nepochs > 0 |
| Fpre−train = GeneratePretrainFormulas( ) |
| Fpre−train = [f if predicate(f) for f in Fpre−train] |
| vae.train(Fpre−train) |
| for i = 1 to Nepochs do |
| Ftrain = vae.sample(batch_size); |
| Ftrain = [f if predicate(f) for f in Ftrain] |
| if Ftrain (x) = NaN or out of Y discard Ftrain (x) |
| if simplify Ftrain = simplify(Ftrain); |
| bbf = bbf.update(Ftrain, ) |
| vae.train(bbf) |
| end for |
| Result: bbf.pareto_front |
Then the P percent of the formulas with the smallest mean squared error are candidates to be saved to the bank of the best formulas (BBF). First, those candidates needs to be checked on correct of definition and values, by default and defined by the dataset. We evaluate function on points sampled from a uniform distribution on and compute for those points. If gets out of the region or we get a , we discard this formula. This approach does not guarantee that the function is defined on a given domain, e.g., it cannot find discontinuities. However, as we show in our experiments, this approach improves the performance of our model, and it is computationally efficient compared to analytical evaluation. Second, if needed, formulas can be simplified using the library before saving it in BBF. This bank keeps formulas from the last N epochs. Our typical value for both hyperparameters P and N is and . Finally, the VAE is fine-tuned on formulas from the BBF. Details of the network training are specified in the supplemental materials. Training overview presented in Fig. 2.

Figure 2: The SEGVAE algorithm training scheme.
Pre-training stage and main training cycle.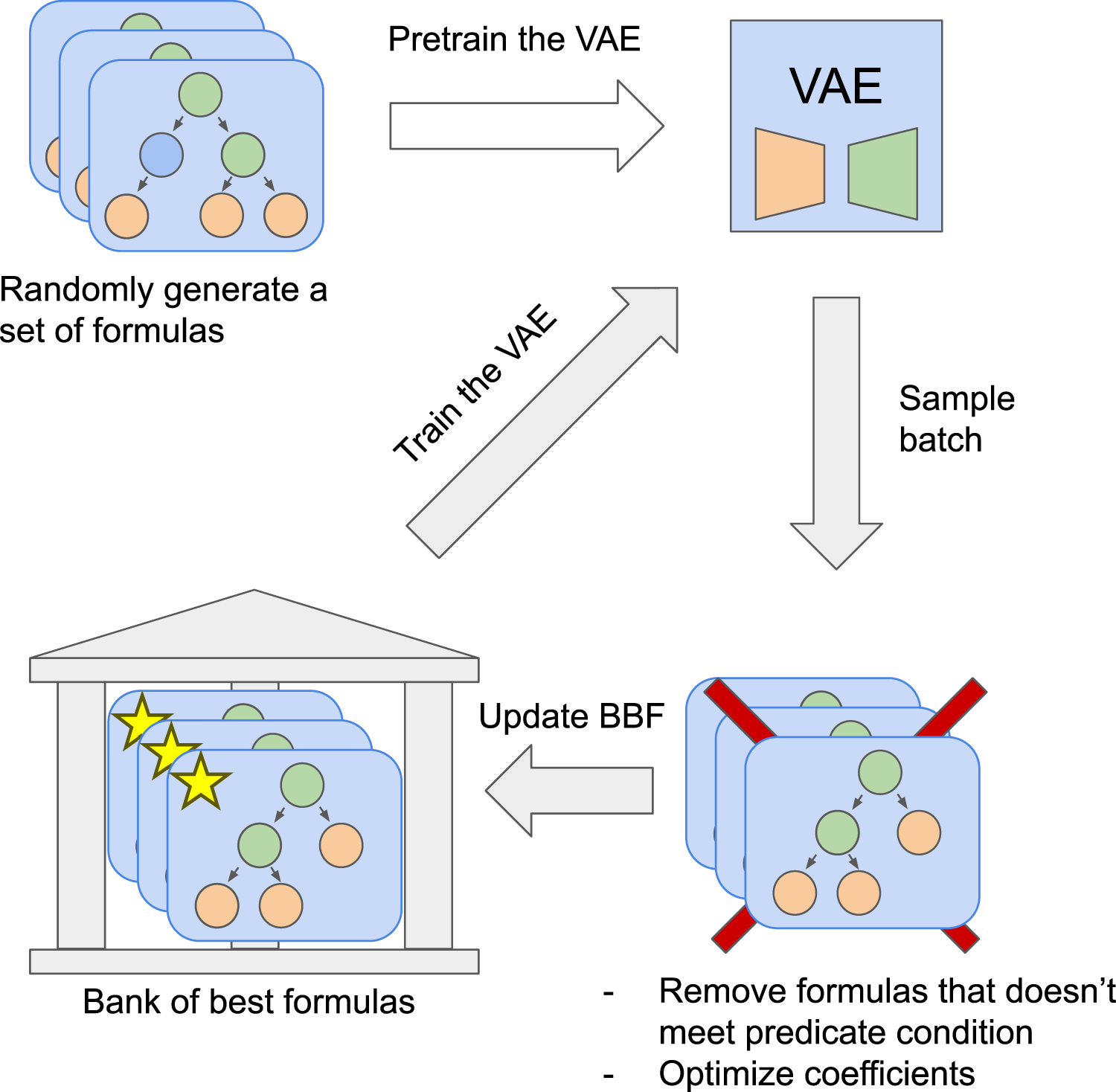{kind=link}
Constants
There are two ways of dealing with constants in the resulting formulae. The first method supposes that all constants are incorporated in a library . In this case, constants are regular tokens, and we do not need any modifications to our algorithm. The main drawback of this approach is the lack of expressiveness. However, it significantly helps the algorithm avoid overfitting to noisy data.
The second method is generating placeholders for future constants by including token ‘ ’ to the library . Then, after the sampling stage, each placeholder is replaced by a parameter which we minimize the mean squared error between and by BFGS optimization algorithm (Fletcher, 1987).
Predicates
It is relatively straightforward to incorporate some prior knowledge about the target formula in the proposed algorithm framework. At the training stage, while we choose the best-sampled formulas by VAE, we ignore formulas that do not meet initial conditions regardless of their metrics. This technique reduces the search space, which helps SEGVAE find correct equations, as demonstrated in the experiment section below.
Imagine we know that the ratio of polynomials describes our physical system dynamics well, and the task is to determine that exact dependency. One way of helping the model is to reduce search space by shrinking the library of operators, e.g., excluding trigonometrical operations. However, one can go further, creating a condition on possible positions for remaining tokens. In our case [‘ ’] operator should be located only in the first place. Eventually model will learn not to generate formulas that violate prior conditions. We will demonstrate algorithm work results on chosen list of formulas and predicates in this article below. The list of formulas and related predicates are listed in Table 3.
Inference
Once the VAE model is trained, one can sample a batch of candidate expressions that are supposed to fit the given dataset. Overwhelmed formulas that describe the dataset best in terms of mean squared error could be overfitted to the noise in the data. Therefore, there is a trade-off between error and complexity. To choose the final expressions, we evaluate the complexity of each equation as:
(3) where is complexity of given token, which is equal to one for all input variables, constants and operators [‘ ’, ‘ ’, ‘ ’], is two for [‘ ’], three for [‘ ’, ‘ ’] and finally four for [‘ ’, ‘ ’]. Then we use this C and error values to identify Pareto-frontier and allow user to pick those formulas that satisfy her needs.
Results
This section reports comparison results between our approach and state-of-the-art symbolic regression packages. We took the bests of our knowledge algorithms, namely deep symbolic optimization (DSO) (Mundhenk et al., 2021), since the DSO superior performance was supplemented by Fig. 3. We used the Nguyen 1–12 formulas (Table 1) and formulas listed in Table 3 to generate datasets. We compared the SEGVAE results with those of the DSO algorithm we took from the GitHub repository.

Figure 3: Recovery rate vs dataset noise and dataset size across all Nguyen benchmarks.
Error bars represent standard error (adopted from Mundhenk et al. (2021)).{kind=link}
| Name | Expression | Dataset | Library |
|---|---|---|---|
| Nguyen-1 | |||
| Nguyen-2 | |||
| Nguyen-3 | |||
| Nguyen-4 | |||
| Nguyen-5 | |||
| Nguyen-6 | |||
| Nguyen-7 | |||
| Nguyen-8 | |||
| Nguyen-9 | |||
| Nguyen-10 | |||
| Nguyen-11 | |||
| Nguyen-12 |
Datasets
Each symbolic regression task corresponds to a table of numbers, those rows are of the form , where . The task is to discover the correct symbolic expression .
-
Nguyen. The Nguyen benchmark is commonly used as a symbolic regression benchmark. The Nguyen dataset consists of 12 formulas. We used the same dataset as in the Petersen et al. (2021) and its updates (see Table 1). To check the method’s robustness, we add Gaussian noise proportional to .
Livermore. New benchmark dataset from the authors of Mundhenk et al. (2021) and Petersen et al. (2021). It consists of 22 formulas. However, we did not use all of them due to their apparent similarity to the Nguyen dataset.
Ablation studies
As was described above, SEGVAE has many parameters such as the number of layers, sampled formulas in pretrained step, number of an epoch, and a maximum length of generated expression. To find the optimal parameters, we performed an ablation study. As a baseline to tune SEGVAE parameters, we used a subset of the Ngyuen dataset, namely Ngyuen-4,5,9,10. First, we concluded that a maximum expression length of 30 is perfectly balanced in terms of model expressibility and model stability. Secondly, we found that hidden dimensionality in the range of 64 to 256 does not affect the recovery rate of 50%. By recovery here, we mean exact symbolic equivalence of the suggested expression to the original formula. For example, we initialize the algorithm 100 times with different random seeds for a given dataset generated by some formula. Out of 100 runs, 80 correctly represented the initial formula. In this case, the recovery rate is . Nevertheless, the recovery rate depends on latent space, as presented in Table 2. We found that latent configuration space of size 128 with 128 hidden units to be optimal for this study. Another critical observation is the SEGVAE’s recovery rate dependence on the library selection. We checked the dependence of the recovery rate on the number of tokens in the library for the DSO and SEGVAE algorithms. Small library size may be why the algorithm cannot find a correct formula. It is simply because not enough tokens are available to describe a formula. On the other hand, an over-inflated library exponentially increases algorithm search space for limited search iteration numbers. Thus, choosing excessive library contents may be a reason for a miserable formula reconstruction. A scientist has some prior knowledge about unknown yet dependency in an actual research process. Thus, we can use both predicates and a task-related library to simulate an actual searching formula situation. In the last series of ablation experiments, we show that our proposed method of discarding formulas that do not satisfy a given domain improves algorithm convergence speed by 50% for the Nguyen dataset. Moreover, our experiments show that it enhances the recovery rate of Livermore-5 and Livermore-7 equations by 100%.
| Latent space dimension | ||||||
| Mean recovery rate |
Noise in data
Noisy data were created by adding Gaussian noise with zero mean and standard deviation proportional to the root-mean-square of the dependent variable . To check the models’ robustness, we present averaged recovery rates as a function of the noise from (noiseless) to the maximum . The main difficulty of regression with noise is the model’s tendency to overfit the data. Sometimes increasing the number of points in a dataset may help.
Experiments
We have evaluated the SEGVAE algorithm on the most commonly used Nguyen benchmark, consisting of 12 formulas. We compared and evaluated our models on two variants of Nguyen datasets. For the first ( I) variant, we sampled only 20 uniformly distributed points, as shown in Table 1. We used the same hyperparameters in SEGVAE for all runs (see details in the supplemental materials). The number of examined expressions was set to 2 million per run, the same as in the DSO article (Mundhenk et al., 2021).
A comparison of DSO and SEGVAE on the Dataset is presented in Fig. 4 as the dependence of averaged recovery rates over noise level. Red and blue colors denote the outputs of DSO and SEGVAE algorithms respectively. Essential to reiterate that by recovery, we mean at least one exact match with the wanted formula in the Pareto frontier.

Figure 4: Average recovery rates of SEGVAE (blue) and DSO (red) algorithms on Ngyuen dataset with error bars.
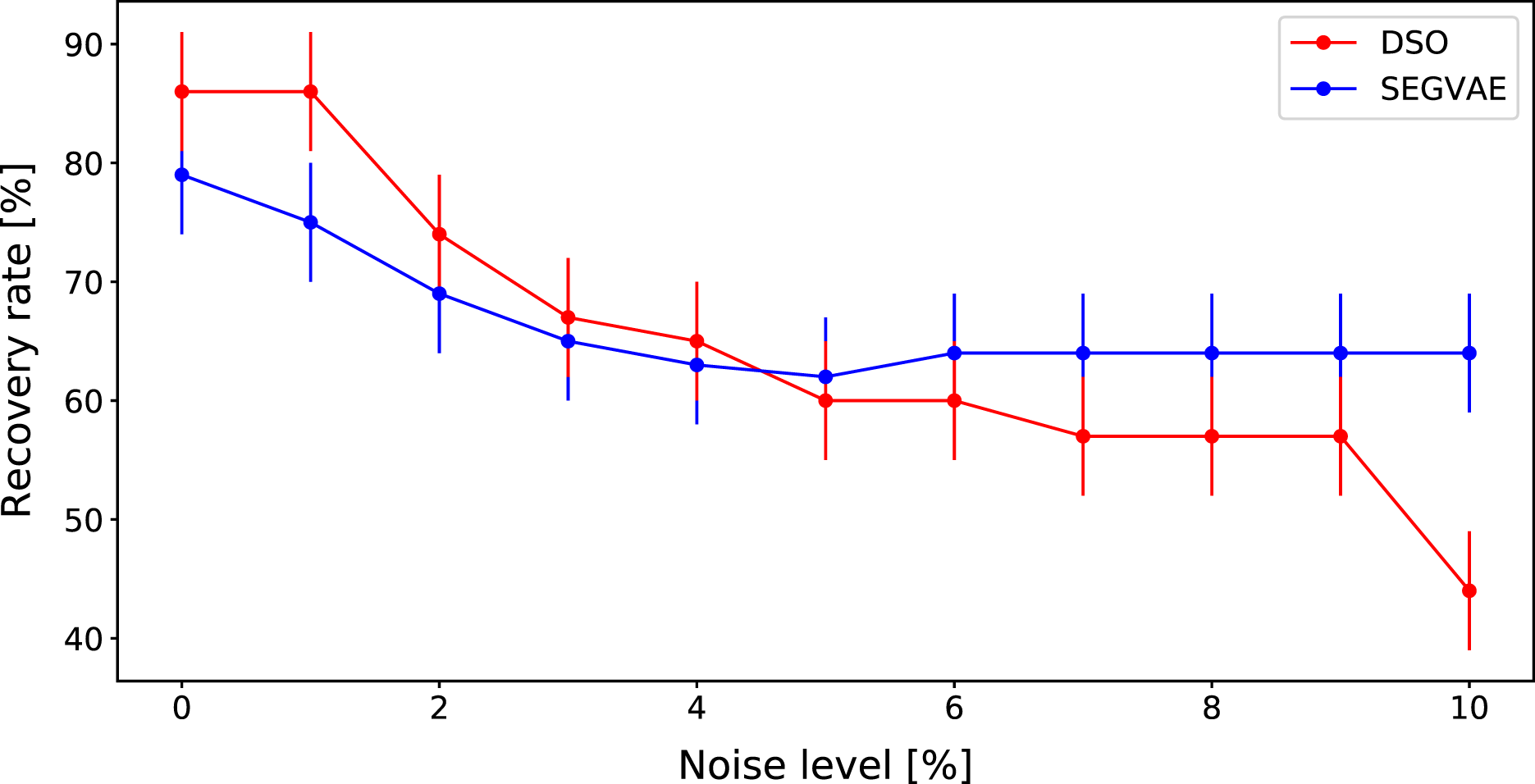{kind=link}
SEGVAE and DSO show similar average recovery rates (ARR) with below moderate noise levels. We averaged the recovery rate overall Nguyen formulas at a given noise level to compute ARR. With increasing noise levels, DSO recovery rates slowly go down. On the other hand, SEGVAE demonstrates good recovery rates stability up to the noise level of 10% with a recovery rate of 70%. The difference becomes visible at high noise levels where SEGVAE slightly outperforms DSO, 70% vs. 45% at maximum noise level. The SEGVAE algorithm demonstrates higher noise stability on this dataset even without prior knowledge.
We compared algorithms and selected formulas from the original DSO article, where the DSO algorithm shows daunting results. These formulas are presented in Table 3. We used specific predicates and token libraries to reveal these formulas and, at the same time to demonstrate the power of our approach. The results of this comparison are summarised in the same way through the ARR in Fig. 5. The detailed results on noiseless data are presented in Table 4.
| Formula name | Formula | Predicate | Dataset | Library |
|---|---|---|---|---|
| Nguyen-12 | ||||
| Neat-8 | ||||
| Neat-9 | ||||
| Livermore-5 | ||||
| Livermore-7 | ||||
| Livermore-8 | ||||
| Livermore-10 | ||||
| Livermore-17 | ||||
| Livermore-22 | ||||
| R-2* |
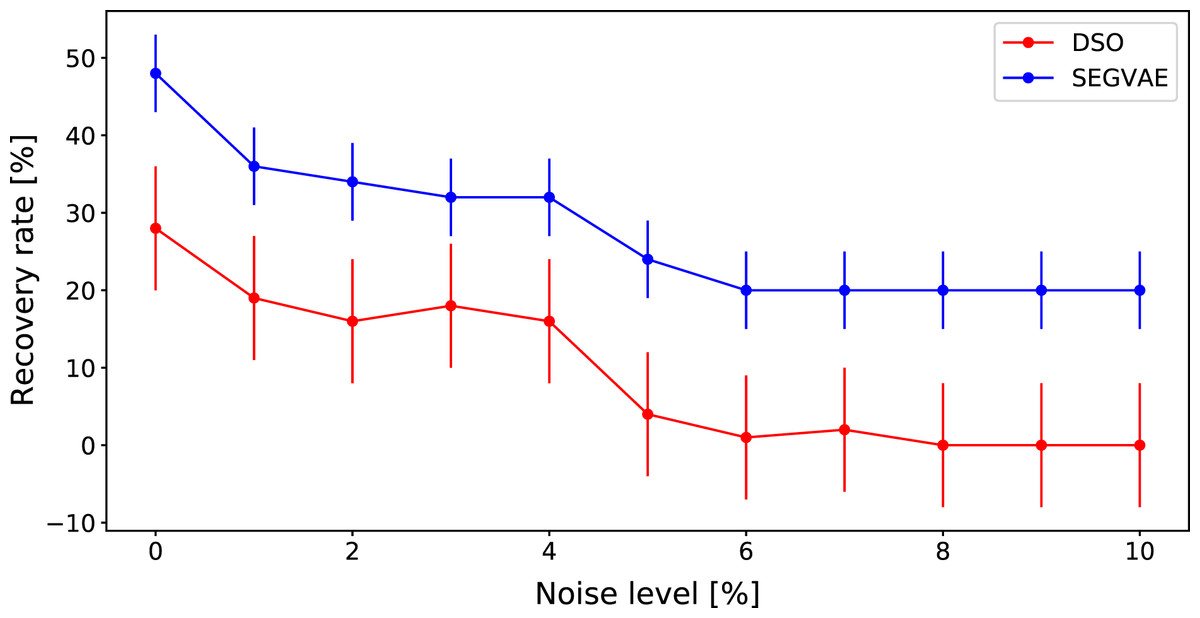
Figure 5: Average recovery rates of SEGVAE (blue) and DSO (red) algorithms based on formulas listed in Table 3 with error bars.
{kind=link}
| SEGVAE | |||||
| DSO | |||||
| SEGVAE | |||||
| DSO |
It often appears that scientists already know the general form of the object of interest. Thus, it would be natural to add predicates to let SEGVAE search formulas in a specific domain. We have seen that our VAE-based algorithm gives a similar result to the recent DSO results on the Nguyen dataset without any prior knowledge. However, there are many equations in which DSO is not accurate enough. To demonstrate the power of predicates in SEGVAE, we took predicates as listed in Table 3 and compared our results to DSO. The comparison results on noiseless data are presented in Table 4. The SEGVAE approach with predicates demonstrates a superior recovery rate than DSO, especially on noiseless data. More detailed results on noiseless are presented in Table 4. The proper predicates and optimal library play a crucial role in this case. In reality, scientists do not know the exact functional form of the studied effect. We can not use the recovery rate as a benchmark in this case. The only benchmark we can trust is MSE and formula shape or predicates that carry common scientific sense.
Conclusions
We introduced a novel algorithm, SEGVAE, for searching for symbolic representation of functional dependence from dependent variables. This approach is based on the VAE generative model that produces mathematical expressions and is constrained by apriori knowledge encoded in the form of fast-check predicates. Those predicates can express, for example, allowed formula patterns, domain, and possible output intervals.
As a benchmark, we used a set of formulas introduced in the DSO article, namely the Nguyen and the Livermore datasets. Our approach has the flexibility of formulating a priory physical knowledge in the form of (a) library of functions, (b) pre-training functions, and (c) selection predicates used for pruning incorrectly generated expressions. Besides the sole accuracy of the method, we focused on the algorithm’s performance in realistic noisy environments. Symbolic regression approaches excel significantly compared to deep learning models where interpretability is paramount. Thus, the demand for such approaches is high in such scientific branches as material sciences, biotechnologies, and astrophysics, to mention a few.
We systematically compared SEGVAE with DSO and shown superior performance of our approach, thus outperforming Eureqa, Wolfram, and alike, which DSO has dominated before. For the scarce-data regime and high-noise regimes, the SEGVAE significantly outperforms the competitors. However, this approach has its limitations: (a) the output formulas quality depends on the dataset and its size, (b) obtaining adequate formula may require the user’s assistance, namely in choosing predicates and the final formula from Pareto-front, and (c) running time may be noticeable, i.e., around tens of minutes on a modern GPU.
We pointed out the importance of the library size and showed that SEGVAE discovered formulas unreachable for DSO thanks to the flexibility of predicates supported by our method. The recovery rate of SEGVAE improves the previously reported SOTA by 20%. Since experimental data usually contains noise and some prior knowledge on the functional dependency is typically available, the SEGVAE benefits can be easily seen from an application point of view. Therefore, our model may be useful in practical cases where interpretable symbolic solutions are needed to understand processes underlying experimental observations.