
A game-theoretic model for the classification of selected oil companies’ price changes
- Published
- Accepted
- Received
- Academic Editor
- Ghufran Ahmad
- Subject Areas
- Data Mining and Machine Learning, Optimization Theory and Computation
- Keywords
- Binary classification, Nash equilibrium, Oil data
- Copyright
- © 2023 Lung and Duma
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. A game-theoretic model for the classification of selected oil companies’ price changes. PeerJ Computer Science 9:e1215 https://doi.org/10.7717/peerj-cs.1215
Abstract
One of the essential properties of a machine learning model is to be able to capture nuanced connections within data. This ability can be enhanced by considering alternative solution concepts, such as those offered by game theory. In this article, the Nash equilibrium is used as a solution concept to estimate probit parameters for the binary classification problem. A non-cooperative game is proposed in which data variables are players that attempt to maximize their marginal contribution to the log-likelihood function. A differential evolution algorithm is adapted to solve the proposed game. The new method is used to study the price changes of the Romanian oil company, OMV Petrom SA Romania, relative to the price of oil (crude and Brent) and the evolution of two other major oil companies with influence in the region. Results show that the proposed method outperforms the baseline probit and classical classification approaches in predicting price changes.
Introduction
Machine learning methods (Zaki & Meira, 2020) should benefit from the use of game-theoretic solution concepts (Maschler, Solan & Zamir, 2013) due to their intrinsic trade-off properties. Game solutions, called equilibria, are optimal in some sense for each player and can also offer a global compromise. Different types of equilibria are defined for different game settings, for example, cooperative or non-cooperative, with perfect or imperfect information, etc. (Maschler, Solan & Zamir, 2013). They are used in many fields to model and predict the strategic behavior of agents in conflicting situations (Tuljak-Suban, 2018). They can also be used as alternative solutions to optimization problems in which a trade-off among several objectives is needed (Lung, Chira & Andreica, 2014). However, they have seldom been used as direct solutions for classification problems. Most game theoretic applications to classification are found in adversarial settings (Dritsoula, Loiseau & Musacchio, 2017), and some theoretical results for support vector machine models (Couellan, 2017). Nevertheless, if we model a classification problem as a game and find model parameters representing an equilibrium solution, we may gain new insight into the data and offer the decision-maker a novel approach.
The use of solution concepts from game theory in real-world applications is limited by several factors, among which intractability is one of the most important. This setback can be overcome by using computational intelligence tools such as evolutionary algorithms (Eiben & Smith, 2015) that can be adapted to search and approximate various types of solutions. While they may not provide exact solutions to the problem, their adaptability and scalability offer the means to find solutions that can be used in practical applications.
In this article, we propose a new game-theoretic formulation of the binary classification problem that uses the probit classification model as baseline (Bliss, 1934). The game assumes that variables in data are game players that search for the best probit parameters for classification. A differential evolution algorithm is adapted to compute the equilibria of this game. The approach’s main goal is to estimate parameters for the probit model as the equilibrium of a game instead of as the maximum of the log-likelihood function.
As a practical application of real-world data, the proposed model is used to classify the variation of stock prices for three oil companies based on oil prices. The three oil companies are OMV Petrom SA Romania (SNP), OMV Aktiengesellschaft Austria (OMV), and Exxon Mobil USA (XOM). We used the closing price for the Brent oil and the Crude West Texas Intermediate (WTI) for almost two decades and the same period for the stocks of the three oil companies. The results provided by the proposed method are compared with probit, as well as with those provided by other classification methods.
The next section of the article presents an overview of related work. The proposed Probit variable game is described in the following section, together with the proposed method of approximating its equilibrium, probit equilibrium differential evolution. The numerical experiments section presents a brief analysis of the method’s parameters and results reported on the real-world data. The article ends with conclusions and further work.
Related Work
In the field of machine learning, the binary classification problem is a central one used to build up models and explain many types of phenomena (Srinivas, Sucharitha & Matta, 2021; Zaki & Meira, 2020). Most classical binary classification approaches ultimately provide a rule for assigning label probabilities to data instances based on the information provided by some training data. In some models, such as logit or probit, probabilities are computed based on a function (Sugiyama, 2016), while other models, such as decision trees (Fürnkranz, 2010) or k-nearest neighbors (Sam, 2010), provide such probabilities based on the proportion of instances with a certain label in a particular region of the data space.
Game theory aims to model inherent strategic and conflicting situations and offers trade-off solutions. These solutions are called equilibria because they usually present some stability qualities, e.g., against unilateral or collective deviations (Maschler, Solan & Zamir, 2013). There is a vast amount of literature related to the direct application of game theoretic models in very different sectors, such as medicine (Chang et al., 2020; Razi et al., 2014; Diamant et al., 2021), computer science (Faugère & Tayi, 2007; Dasgupta & Collins, 2019), management (Leng & Parlar, 2005), economy (Pinasco, Rodríguez Cartabia & Saintier, 2018; Chistiakov, Andersen & Vishnevskii, 2015), education (Stull, 2006), agriculture (Gupta, Bhatt & Bhatt, 2020), environment (Dutta & Radner, 2006; Nagase & Silva, 2007) etc.
Also, there is a lot of work around machine learning and game theory, mostly focused on modeling and explaining agents’ behavior (Hazra & Anjaria, 2022; Kiekintveld et al., 2021; Strumbelj & Kononenko, 2010). However, particularly for binary classification, there are very few attempts to use equilibrium concepts as solutions for the classification problem directly. The most straightforward one is in Couellan (2017), where a game based on SVMs is designed. Attempts to model the problem as a game among instances of data are made in Suciu & Lung (2020). Most other applications use game-theoretic solutions to interpret or select results of other approaches and are mostly concentrated on problems that model obviously conflicting situations, such as adversarial classification (Dritsoula, Loiseau & Musacchio, 2017).
Regarding the energy sector, classical approaches are related to the applications of game-theoretic models to electricity markets (Su & Huang, 2014; Paudel et al., 2019; Tushar et al., 2018; Lise et al., 2006) or for natural gas (Csercsik et al., 2019; Chang et al., 2021), but not related to oil companies stocks. Interesting correlations between the oil price and the stock returns can be found in Diaz, Molero & Perez de Gracia (2016), where a vector autoregressive model with several variables is estimated for the G7 economies, as well as in Cunado & Perez de Gracia (2014) for 15 selected European economies. Also, the effects of the oil market on the US stock market are evaluated in Arampatzidis et al. (2021) by estimating a structural vector autoregression model. Several other articles are studying the relationship between oil and the stock market, e.g., using VAR, SVAR, or other statistical models. Other machine learning approaches to related to oil prices from different perspectives can be found in Chen et al. (2021), Guan et al. (2022). We could not identify articles using a game-theoretic model for this specific relation.
The Binary Classification Game
The binary classification problem consists in finding a rule of assigning a label, out of possible two, to some data instances, based on the information that we have about their distribution. Thus, we are given a data set d, with N instances d, and attributes/variables . Also, we have their corresponding labels/classes set , such that label corresponds to instance , and we want to provide a model that predicts labels Y from X as good as possible (Hastie, Tibshiran & Friedman, 2016).
The probit classification model estimates parameters that can be used to predict classification probabilities by using the normal cumulative distribution function. Parameters are usually estimated by maximizing the log-likelihood function. In this article, a new approach for estimating these parameters is proposed. The optimization problem is converted into a multi-player game among data attributes that choose a parameter that maximizes their marginal contribution to the log-likelihood function, subject to constraints. The aim is to find probit parameters that present some equilibrium properties and a good classification. Our endeavor can be empirically validated if classification results reported by using the game are better than those reported by the standard probit approach from which the approach is derived. The probit variable game and the method used to approximate its equilibrium are described in what follows.
Probit classification The probit classification model assumes that the probability that a label is equal to 1 can be expressed as:
(1) where represents the cumulative distribution function for the standard normal distribution, and d is the model parameter, estimated by maximizing the log-likelihood function. The corresponding probability that a label is 0 is (Hsiao, 1996). The log-likelihood function can be written as:
(2)
The goal is to find and use it for predicting the label of an instance in the following manner:
(3)
It is assumed that provides the best classification solution for the probit model. However, for a given problem there may be more solutions that can be used in Eq. (3) in a satisfactory manner. In this article, we explore the use of an alternative method of estimating the parameter for the probit model, which is based on the Nash equilibrium concept, in an attempt to offer a different and maybe more interesting solution to the classification problem.
The probit variable game
The current approach assumes that among values useful for classification (Eq. (3)), we can find some that better optimize individual , providing a better trade-off in the maximization of their sum in . A normal form game is designed, in which players are the variable/attributes in X that choose their parameters to maximize their marginal contribution to the log-likelihood function, subject to satisfying conditions in Eq. (5).
Formally is defined as:
the set of players : a player represents an attribute in X;
the set of strategy profiles d, an element is , where is the strategy of player ;
the payoff function , with :
(4) where represents X with attribute removed, and represents without and . Function is
(5) where denotes the cardinality of a set.
The payoff function is designed to maximize the marginal contribution of attribute to the log-likelihood function if the parameter evaluated improves upon the probit estimated parameter (restriction Eq. (5)), and if not, is taken as the log-likelihood function in order to be maximized. The marginal contribution is computed as the difference between , the value of the log-likelihood function, and , the log-likelihood function computed without taking into account attribute (and consequently ) in the data. By maximizing their payoffs, either the log-likelihood will be maximized, or if a better solution can be found, it will be computed based on the marginal contribution to the log-likelihood function.
Restrictions If we consider conditions in Eq. (3), these are equivalent with having whenever and correspondingly whenever . This condition can be re-written as
(6)
If, for a , this condition holds, then also Eq. (3) holds, and, even if does not maximize the log-likelihood function, it provides a good classification of the data. But condition (6) may not hold for all even for , therefore searching for a value such that (6) holds may be useless. However, there might exist values such that the number of instances for which the condition Eq. (6) holds is greater than or equal to the corresponding number computed for . Among these values, we may find better classification models that are based on probit. Because we are only interested in such values, for all other situations, all players seek to maximize the log-likelihood function in Eq. (4).
Nash equilibrium (NE) The Nash equilibrium of a game (Maschler, Solan & Zamir, 2013) is a strategy profile such that no player has an incentive for unilateral deviation. This means that while all other players maintain their strategies unchanged, none of the players can improve their payoff by only changing their strategies. For game , the Nash equilibrium represents a value such that each variable cannot contribute more to the log-likelihood function if all other variables maintain their choices. Finding a NE for game is not trivial. In this approach, we use a differential evolution algorithm (Bilal et al., 2020), adapted to approximate the Nash equilibria for game in the following manner.
Probit equilibrium differential evolution (PrEDE)
Differential evolution (DE) is a stochastic search and optimization method that evolves a population of potential solutions to the problem (Storn & Price, 1997). It can be adapted to compute the Nash equilibria of a game by using the Nash ascendancy relation (Lung & Dumitrescu, 2008) during the selection phase of the search. We further adapt the DE to approximate the NE of game , and we call this DE version Probit Equilibrium Differential Evolution (PrEDE). The outline of PrEDE is presented in Algorithm 3.
Population and initialization PrEDE population consists of individuals d that are possible parameters for the probit model and strategy profiles for game . Because we are searching in a neighborhood of the probit parameters, the initial population is generated starting from by adding deviations following a normal distribution with standard deviation . Parameter controls how much the initial population is spread in the search space around . A very small value would lead to premature convergence to , while a higher value would slow the search as the initial solutions may need a lot of improvement before satisfying restrictions in the payoff functions.
Variation operators A DE/rand/1/exp scheme, presented in Algorithm 1, is used to create offspring (Thomsen, 2004). With probability CR, some of the components of the offspring are modified based on the values of three distinct parents from the current population by adding the difference of two of them multiplied by a scaling factor F to the third. This is a standard DE scheme that has been proven efficient in optimization problems.
| 1: ; |
| 2: randomly select parents , , , where ; |
| 3: ; |
| 4: for ; ; do |
| 5: ; |
| 6: ; |
| 7: end for |
| is a discrete uniform value between 0 and d. |
| 1: ; |
| 2: if and then |
| 3: for ; j < p; do |
| 4: if then |
| 5: ; |
| 6: ; |
| 7: if then |
| 8: ; |
| 9: end if |
| 10: if then |
| 11: ; |
| 12: end if |
| 13: end if |
| 14: end for |
| 15: else |
| 16: if and then |
| 17: ; |
| 18: else |
| 19: if and then |
| 20: ; |
| 21: else |
| 22: , ; |
| 23: ; |
| 24: end if |
| 25: end if |
| 26: end if |
| 27: if then |
| 28: return o Nash ascends β is TRUE (1); |
| 29: else |
| 30: if then |
| 31: return o Nash ascends β is FALSE (−1); |
| 32: else |
| 33: return o is INDIFFERENT to β (0); |
| 34: end if |
| 35: end if |
| 1: Generate initial population of strategies following a normal distribution with mean probit parameter and σ; |
| 2: Evaluate population//fitness = AUC; |
| 3: nrgen = 0; |
| 4: while (nrgen¡MaxGen) or (better ) do |
| 5: for each do |
| 6: create offspring oi from parent using the DE/rand/1/exp scheme (Alg. 1); |
| 7: if (oi Nash ascends (Alg. 2) parent ) or (oi indifferent to and fitness ( fitness ( ) then |
| 8: oi replaces parent ; |
| 9: end if |
| 10: end for |
| 11: if fitness of best individual better than fitness of then |
| 12: better ++ |
| 13: else |
| 14: better = 0 |
| 15: end if |
| 16: end while |
Nash ascendancy In order to guide the search towards the equilibrium of game the Nash ascendancy relation is used (Lung & Dumitrescu, 2008). Two strategy profiles of the game—here represented by the offspring and parent —are compared by counting how many players can improve their payoffs by unilaterally changing their strategy from one to the other. The strategy profile having less number of such players is considered to be better with respect to NE than the other. If the number of players that can unilaterally improve their payoffs is the same, they are considered indifferent (Algorithm 2). In the context of game an extra step is added to take into account conditions in the payoff functions (Eqs. (4) and (6)). Thus, the Nash ascendancy relation is tested only if both individuals fulfill conditions in Eq. (5), otherwise, if only one of them fulfills them, it will be considered better, and if none of them fulfills them, the one having a better probit likelihood value (Eq. 2) is considered better.
Fitness function While the Nash ascendancy relation is used for evolution purposes, in order to identify the best individual in the population, a specific classification-based fitness is used: the Area under the Curve (AUC) indicator (Fawcett, 2006) computed based on the prediction made using the cumulative normal distribution function for individuals in the population-based on training data. The AUC metric indicates the probability that a classifier will rank a positive instance higher than a negative instance. A maximum value of 1 indicates a correct classification of the tested data. A higher value indicates a better classification from the positive label point of view.
Termination condition PrEDE repeats iterations until a maximum number MaxGen of iterations is reached, or if the best AUC in the population computed on the training data supersedes the AUC of the probit estimator for a successive number of iterations. The motivation behind stopping the search is double-fold: to reduce the computational complexity of a run and to avoid overfitting, as better AUC values on the training data may indicate both a better classification and the danger of overfitting. If a better solution is identified, and it is held for iterations, then it might represent a genuine improvement to probit, and it should be enough; continuing the search may indeed improve the AUC value but only for the training data, and even the probit log-likelihood function, but may not lead to an actual improvement in results.
PrEDE parameters PrEDE uses three types of parameters:
parameters that are specific to any evolutionary algorithm: population size ( ), and the maximum number of iterations ( );
two parameters that are specific to the differential evolution algorithm: the scaling factor F, and crossover probability CR;
two parameters specific to the classification problem: number of iterations the AUC fitness of the best individual exceeds the AUC of the probit estimator before the search is stopped , and the standard deviation used to generate the initial population around probit parameters, .
Numerical Experiments
The numerical experiments section is composed of two main parts. First, results reported by PrEDE on a set o synthetic data sets are used just to illustrate the behavior of the proposed method and the effect of varying different parameters on results. In the second part, a real-world application that studies changes in the price of oil of the Romanian national oil company based on oil prices and two mainstream companies with direct or indirect influence on the region.
Synthetic data and parameter testing
A set of synthetically generated data is used to preliminary assess the performance of PrEDE in various settings and provide an overview of the effect of parameter settings on results. The datasets are generated by using the make_classification function in the scikit-learn Python (https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html, last accessed Feb. 2022). To simulate an environment that is similar to the one created by the oil price data, we generated datasets with 100 and 200 instances, with three and six attributes, and with different degrees of separation between classes by setting the class separator parameter to 0.1, 0.5 and 1. A higher value creates instances with better-separated classes. As a performance indicator, the AUC (Fawcett, 2006) is used. AUC takes values between 0 and 1, 1 indicates a correct classification, and it can be used to compare results. A total of 10-folds cross-validation is used and the average of the 10 AUC values reported on the tested folds are presented (Hastie, Tibshiran & Friedman, 2016; Stone, 1974). Figure 1 presents the tested values and corresponding AUC values.
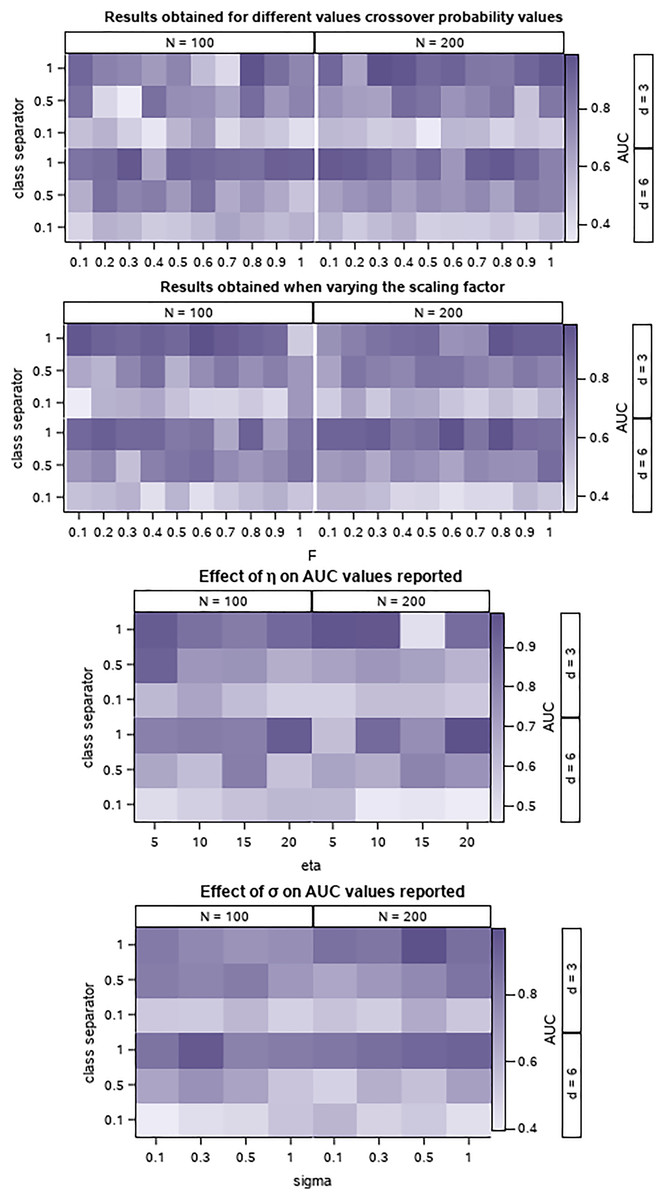
Figure 1: Effect of parameter variation on PrEDE results for the synthetic data sets.
Colors represent average AUC values, with 1, the best, and darkest.{kind=link}
The differential evolution parameters, F, and CR are set to take values from 0.1 to 1 with a step of 0.1, Fig. 1. We find, as expected, that there is no ‘gold’ setting for these parameters. However, smaller CR and F values seem to provide a good trade-off on datasets with smaller class separator values which are more difficult to solve.
The parameter is used to stop the search if for a successive number of iterations the fitness of the best individual in the population is better than the fitness of the probit parameter. This ensures that the solution provided by PrEDE is indeed better than that provided by probit while avoiding overfitting (Fig. 1). The value of least influences results (Fig. 1), indicating that the choice of initial population setting does not influence the search.
Application: oil data
Data used in the study consists of the closing price for the crude oil WTI and the Brent oil collected by the authors from the Bloomberg database for almost two decades, starting from 2000 until 2019. From the same database and for the same period, the closing prices for three stocks: Exxon Mobil (XOM, Irving, TX, USA) from the US, OMV AG Austria (OMV, Vienna, Austria), and OMV Petrom SA Romania (SNP, Bucharest, Romania) were also collected. To better compare and avoid any distortions, all the data were converted into US dollars. We selected these three oil companies because they are from different geographical areas, and they are also different in size, but they have similar activities. Yet, what is more important, these companies have some close connections: OMV AG owns 51 percent of Petrom, while Petrom and Exxon have made together a joint company to prospect and exploit natural gas from the Black Sea. Other reasons for this selection were the fact that, on the one hand, the oil companies from the area of Central and Eastern Europe (in our case, OMV Petrom, Bucharest, Romania) were not researched enough yet and, on the other hand, Exxon Mobil, besides its links with OMV Petrom, is probably the most representative oil company in the world. Figure 2 illustrates the collected data used for the analysis.
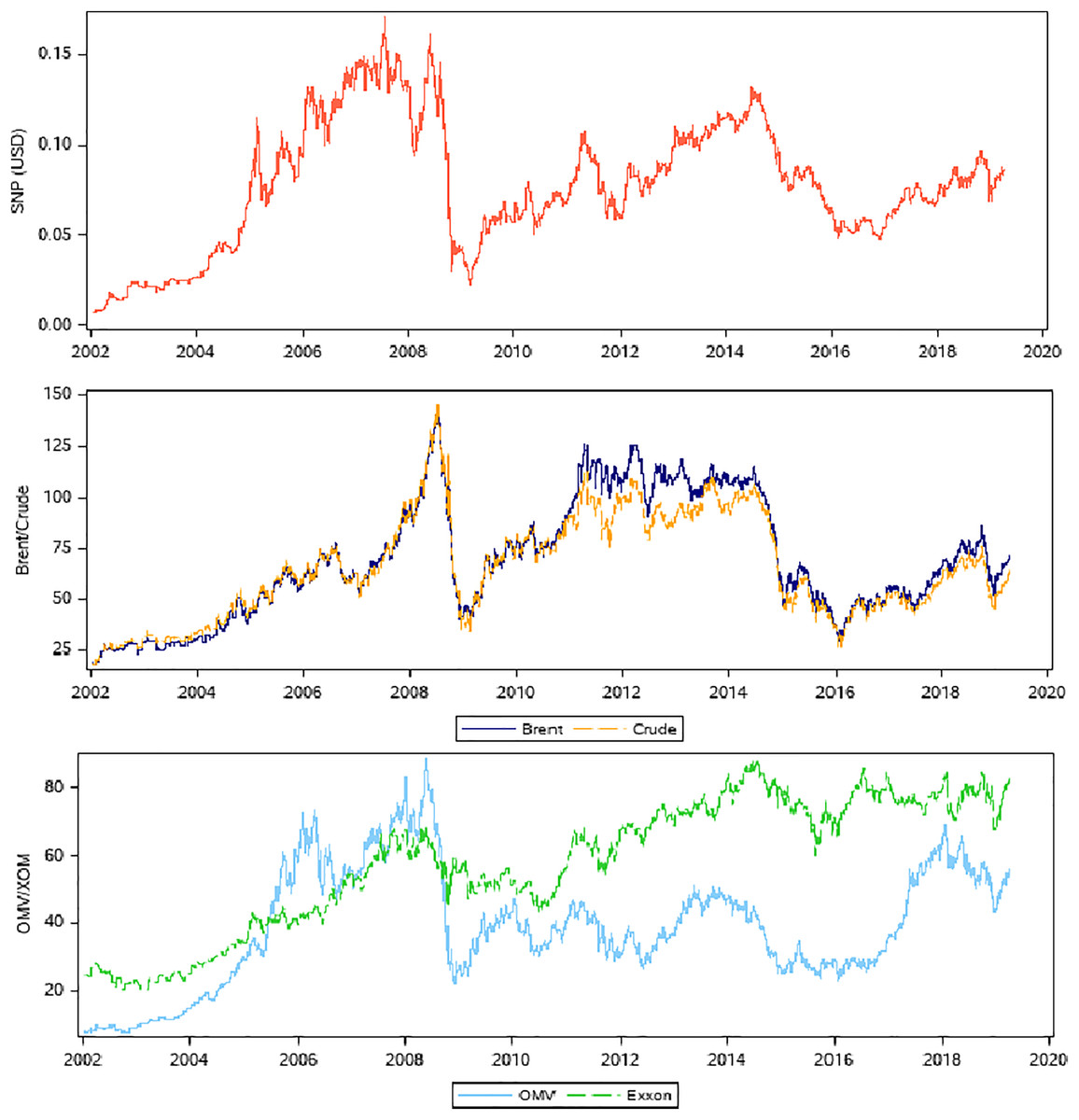
Figure 2: Data used in the study.
Variations in SNP prices (A) are studied in relation to various combinations of oil prices Brent and crude (B) and two oil companies OMV and XOM (C).{kind=link}
One of the issues of interest when looking at oil price data is to predict if an increase/decrease in price is expected for these three stocks. In this approach, we test the following model: a binary variable taking values of 0 and 1 is created for the stock prices of each oil company, with value 1 representing an increase in the stock price from the previous day and 0 a price decrease. Figure 3 presents the overlapping degree of the two obtained classes for all pairs of considered data. Probit models changes in the oil price and PrEDE, and results are compared and discussed.
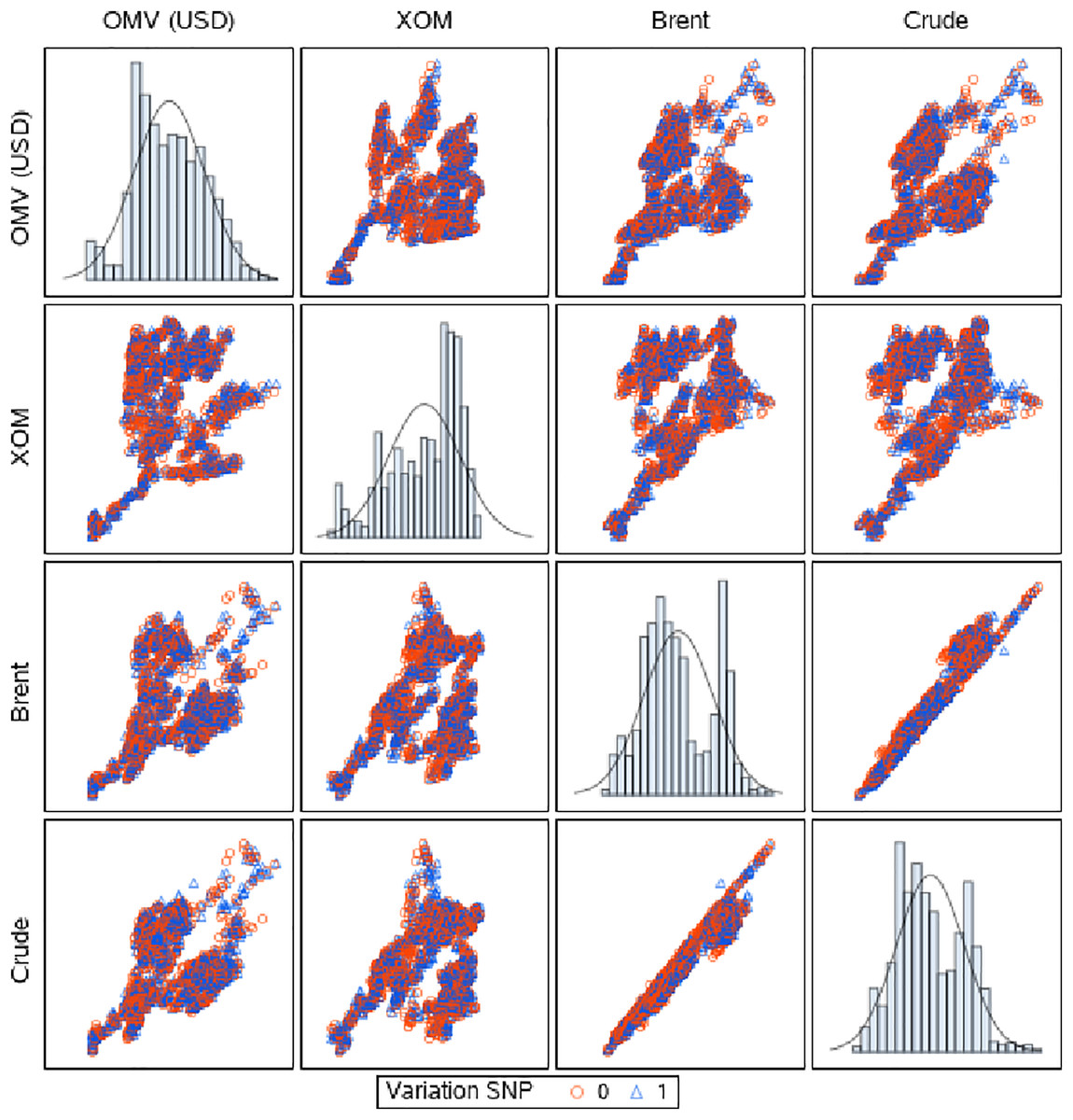
Figure 3: Scatter matrix of data grouped by the SNP variation labels.
The two groups overlap significantly, creating a challenging classification problem.{kind=link}
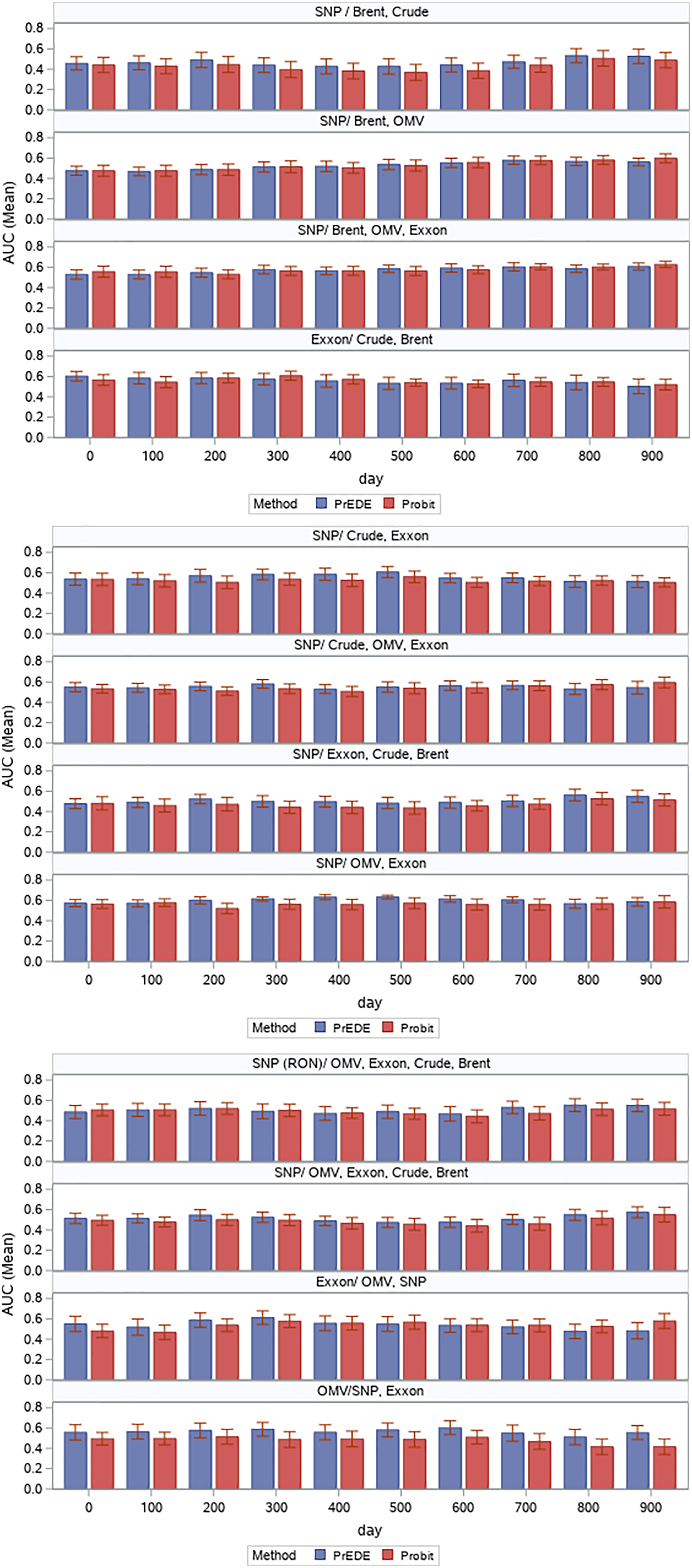
Ten intervals of 50 days were selected for training, and the subsequent 10 days were used in the testing phase. This is a reasonable setting as it is common to look for the trends of the last 50 days to make predictions related to the near future. AUC values were reported for each time slot. Various combinations of data were tested in this manner. Our focus was mainly on the Romanian oil company OMV Petrom (SNP, Bucharest, Romania); thus, we tested the changes in eight different combinations with Brent and Crude oil and with the other two oil companies, combinations that we considered that are the most useful ones, as we can see from in Fig. 4. We were primarily interested in SNP because it is the least researched of the three companies and has been less studied. In order to do this analysis, we tested SNP in combination with the oil prices and the other oil companies in pairs of two, three, or four data sets (Fig. 4). Firstly, we tested SNP stock price variation based on Brent oil, because this is the European benchmark, and together with OMV, because it is the majority shareholder of SNP, and then based on two more combinations with Brent. Secondly, we continued by testing SNP stock price variation with the crude oil, which is the US benchmark, in four ways, including Exxon, because it is a US company, then adding OMV, and then Brent. Thirdly, we tested SNP stock price variation based on the stock prices of the other two oil companies, OMV and XOM. In the end, mainly for confirmation purposes, we tested XOM and OMV stock price variation, in relation with each-others, with the two oil benchmarks, and with SNP.
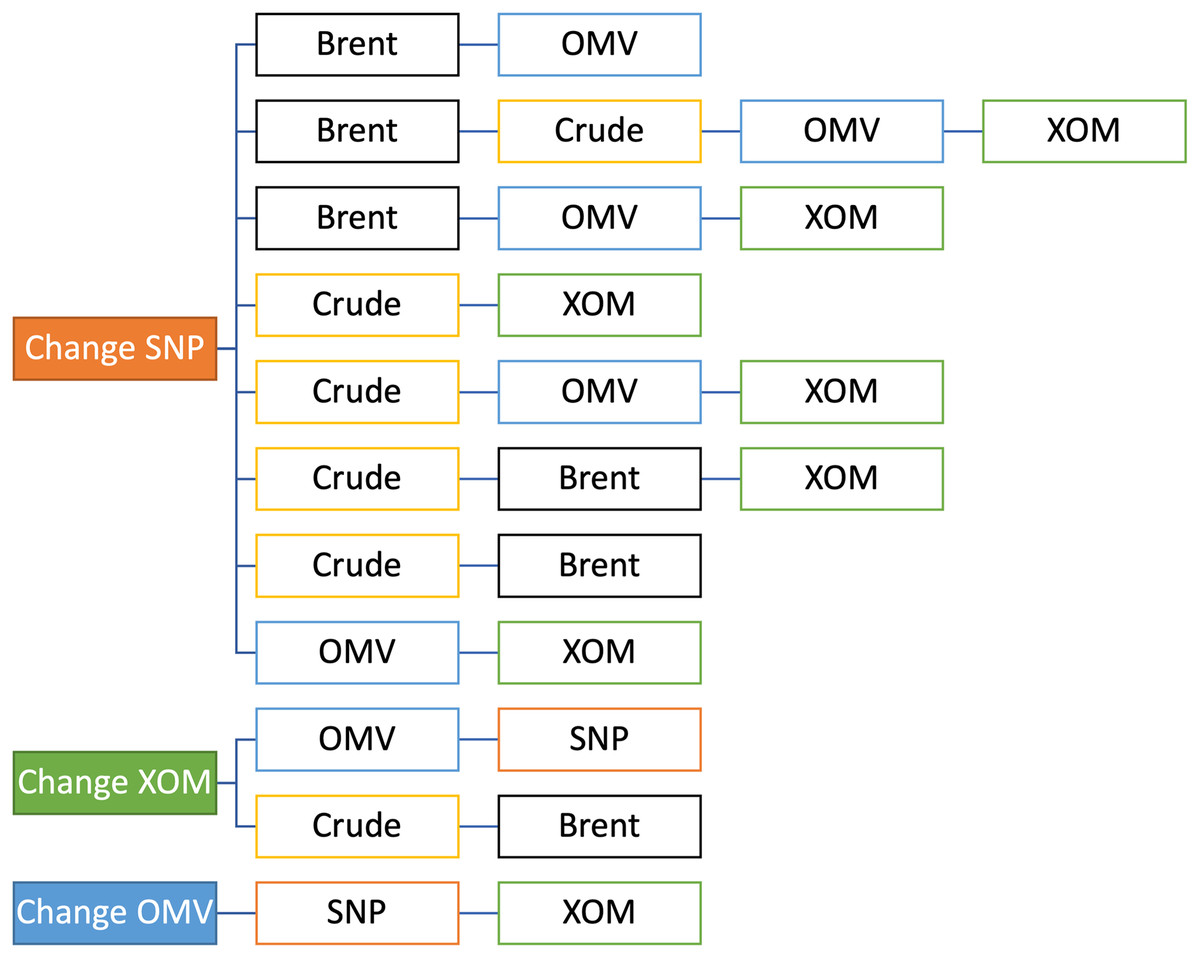
Figure 4: Selected combinations tested.
{kind=link}
Results are presented as error bars of AUC values in Fig. 5 and corresponding numerical values in Table 1. While values are comparable, we find the PrEDE reports better average AUC values than probit in eight out of the 12 scenarios tested. Figure 5 illustrate AUC values for each set of days tested. A paired t-test performed overall AUC values for each data set, and each starting date shows a significant difference between AUC values reported by PrEDE and probit ( , and ). For seven out of the 12 combinations tested, the differences between results are significant, while there is no situation in which probit results can be considered better. A detailed representation of differences is illustrated in Fig. 5. Considering the high overlapping degree of the data (Fig. 3), it is to be expected that average AUC values are around 0.5; however, the fact that PrEDE has been able to improve results reported by probit indicates the potential of exploring such an approach. Results reported by other standard classification methods are presented in Table 2. Logit (Seabold & Perktold, 2010), k-nearest neighbor (kNN), and a random forest (RF) (Pedregosa et al., 2011) were used on the same data, and the mean and standard deviation of AUC values are reported. Only in one instance (SNP Brent, Crude) kNN and RF results were significantly better than those reported by PrEDE.
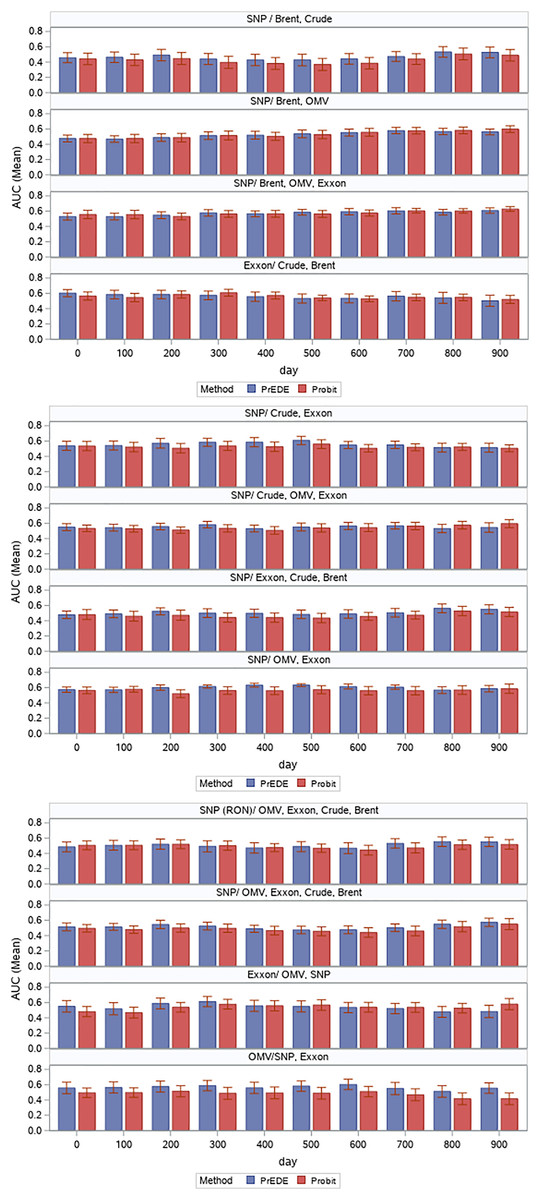
Figure 5: Average AUC values (with error bars) reported by the two methods for each time frame.
{kind=link}
| Selection | Method | Mean | Std Dev | Lower 95% | Upper 95% |
|---|---|---|---|---|---|
| SNP Brent, Crude | PrEDE | 0.47 (*) | 0.22 | 0.42 | 0.51 |
| Probit | 0.43 | 0.23 | 0.38 | 0.47 | |
| SNP Brent, OMV | PrEDE | 0.53 | 0.14 | 0.50 | 0.55 |
| Probit | 0.53 | 0.16 | 0.50 | 0.56 | |
| SNP Brent, OMV, XOM | PrEDE | 0.57 | 0.13 | 0.55 | 0.60 |
| Probit | 0.57 | 0.13 | 0.55 | 0.60 | |
| XOM Crude, Brent | PrEDE | 0.56 | 0.19 | 0.52 | 0.59 |
| Probit | 0.56 | 0.14 | 0.53 | 0.58 | |
| SNP Crude, XOM | PrEDE | 0.56 (*) | 0.17 | 0.52 | 0.59 |
| Probit | 0.52 | 0.17 | 0.49 | 0.56 | |
| SNP Crude, OMV, XOM | PrEDE | 0.55 | 0.15 | 0.52 | 0.58 |
| Probit | 0.54 | 0.15 | 0.51 | 0.57 | |
| SNP XOM, Crude, Brent | PrEDE | 0.51 (*) | 0.17 | 0.47 | 0.54 |
| Probit | 0.47 | 0.19 | 0.43 | 0.51 | |
| SNP OMV, XOM | PrEDE | 0.60 (*) | 0.10 | 0.58 | 0.62 |
| Probit | 0.56 | 0.16 | 0.53 | 0.59 | |
| SNP (RON) OMV, XOM, | PrEDE | 0.51 (*) | 0.20 | 0.47 | 0.55 |
| Crude, Brent | Probit | 0.49 | 0.18 | 0.46 | 0.53 |
| SNP OMV, XOM, | PrEDE | 0.52 (*) | 0.16 | 0.49 | 0.55 |
| Crude, Brent | Probit | 0.49 | 0.18 | 0.45 | 0.52 |
| XOM OMV, SNP | PrEDE | 0.54 | 0.22 | 0.49 | 0.58 |
| Probit | 0.54 | 0.21 | 0.50 | 0.58 | |
| OMV SNP, XOM | PrEDE | 0.56 (*) | 0.22 | 0.52 | 0.61 |
| Probit | 0.48 | 0.22 | 0.43 | 0.52 |
| Selection | Logit | kNN | RF |
|---|---|---|---|
| SNP Brent, Crude | 0.43 0.23 | 0.53 0.16 | 0.50 0.11 |
| SNP Brent, OMV | 0.53 0.16 | 0.51 0.13 | 0.47 0.19 |
| SNP Brent, OMV, XOM | 0.57 0.13 | 0.51 0.12 | 0.49 0.19 |
| XOM Crude, Brent | 0.55 0.14 | 0.57 0.17 | 0.51 0.15 |
| SNP Crude, XOM | 0.53 0.17 | 0.46 0.13 | 0.42 0.17 |
| SNP Crude, OMV, XOM | 0.55 0.15 | 0.53 0.11 | 0.48 0.19 |
| SNP XOM, Crude, Brent | 0.47 0.19 | 0.51 0.17 | 0.50 0.12 |
| SNP OMV, XOM | 0.56 0.16 | 0.55 0.15 | 0.45 0.19 |
| SNP (RON) OMV, XOM, Crude, Brent | 0.49 0.19 | 0.52 0.13 | 0.50 0.17 |
| SNP OMV, XOM, Crude, Brent | 0.49 0.18 | 0.50 0.17 | 0.52 0.14 |
| XOM OMV, SNP | 0.54 0.21 | 0.53 0.19 | 0.50 0.19 |
| OMV SNP, XOM | 0.48 0.22 | 0.48 0.17 | 0.48 0.23 |
Conclusions
Game theory and machine learning are naturally considered interconnected, with many data models attempting to use game theory concepts to explain results or agents’ behavior. However, there are various other ways in which game theory can be involved in machine learning. The direct use of equilibria as solution concepts when estimating model parameters has not yet been explored, despite the advantages provided by their intrinsic trade-off capabilities.
An example of such use of equilibrium is presented in this article. A non-cooperative game is designed in such a manner that the game strategies, and hence its equilibrium, are probit parameters. Players of the game aim to improve upon probit parameters by maximizing a payoff based on their attribute’s marginal contribution to the log-likelihood function. The solution of the game is represented by parameters such that none of the players can unilaterally improve its marginal contribution to the log-likelihood function. An equilibrium of this game is approximated by a stochastic search method based on a differential evolution algorithm adapted to solve this game.
Thus, the goal of our endeavor is to show that there are other solution concepts that can be explored within a classical classification framework. While we assume that maximum likelihood methods may provide the best possible classification of data based on a particular model, such as probit, there may be some other parameters, endowed with different trade-off properties, that, under the same model, offer a better classification for some data.
The limitation of such an approach is, for the moment, at a theoretical level, as an in-depth analysis of such alternatives to probit is required to generalize results. However, the flexibility provided by a search heuristic such as the differential evolution, which has been adapted in the context of the probit variable game, consists in its flexibility: it can be adapted to other game settings and other data to provide a different—equilibrated—insight into its structure.
The new approach is tested on a set of real oil data collected between 2002 and 2020 to study the influence of the oil price and the prices of two major companies on the price changes of the Romanian national oil company. We find data to be highly overlapping and consider it a challenge from a classification point of view. Nevertheless, PrEDE improves upon probit on these data, indicating that the game-theoretic approach has the potential to uncover better relationships within it. A future research direction could be to extend the use of this new method to investigate the price changes of the Romanian OMV Petrom SA shares relative also to its peers from Central and Eastern Europe like PKN Orlen from Poland, MOL from Hungary, Unipetrol from Czech Republic and to some other regional companies from the same field. Other similar analyses may also be envisaged.