
Persistent homology classification algorithm
- Published
- Accepted
- Received
- Academic Editor
- Sebastian Ventura
- Subject Areas
- Algorithms and Analysis of Algorithms, Data Mining and Machine Learning, Data Science, Theory and Formal Methods
- Keywords
- Persistent homology, Supervised learning, Classification algorithm, Topological data analysis
- Copyright
- © 2023 De Lara
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. Persistent homology classification algorithm. PeerJ Computer Science 9:e1195 https://doi.org/10.7717/peerj-cs.1195
Abstract
Data classification is an important aspect of machine learning, as it is utilized to solve issues in a wide variety of contexts. There are numerous classifiers, but there is no single best-performing classifier for all types of data, as the no free lunch theorem implies. Topological data analysis is an emerging topic concerned with the shape of data. One of the key tools in this field for analyzing the shape or topological properties of a dataset is persistent homology, an algebraic topology-based method for estimating the topological features of a space of points that persists across several resolutions. This study proposes a supervised learning classification algorithm that makes use of persistent homology between training data classes in the form of persistence diagrams to predict the output category of new observations. Validation of the developed algorithm was performed on real-world and synthetic datasets. The performance of the proposed classification algorithm on these datasets was compared to that of the most widely used classifiers. Validation runs demonstrated that the proposed persistent homology classification algorithm performed at par if not better than the majority of classifiers considered.
Introduction
Machine learning is an important branch of artificial intelligence that deals with the study of computer systems and algorithms that can learn and develop on their own without being explicitly programmed to do so. It is focused on the development of computer programs capable of performing data processing and predictive analysis. The three major categories of machine learning techniques are supervised, unsupervised, and reinforcement learning. Supervised learning is a process in which a system learns from a readily available training dataset of accurately classified observations. One of the major tasks addressed by supervised learning is classification.
Classification algorithms
Classification is the process of identifying, recognizing, grouping, and understanding new observations into categories or classes (Alpaydin, 2014). A training dataset is composed of ( )-dimensional data points which are split into an -dimensional input vector often called attributes and into a one-dimensional output category or class. A dataset can be univariate, bivariate, or multivariate in nature, whereas the attributes are quantifiable properties that can be categorical, ordinal, integer-valued, or real-valued. A classification algorithm or classifier is a procedure that performs classification tasks. The term classifier may also refer to the mathematical function that maps input attributes to an output category.
Classification algorithms have found a wide range of applications in domains such as computer vision, speech recognition, biometric identification, biological classification, pattern recognition, document classification, and credit scoring (Abiodun et al., 2018). Classification problems can be categorized as binary or multi-class. Binary classification entails allocating an observation to one of two distinct categories, whereas multi-class classification involves assigning an observation to one of more than two distinct classes.
Numerous classification algorithms have been developed since the rise of artificial intelligence. While several of these classifiers are specifically developed to solve binary classification problems, some algorithms can be used to solve binary and multi-class classification problems. Many of these multi-class classifiers are extensions or combinations of one or more binary classifiers.
The no-free lunch theorem proved by David Wolpert and William Macready implies that no learning or optimization algorithm works best on all given problems (Wolpert, 1996; Wolpert & Macready, 1997). A classifier can be chosen depending on the type of data at hand. Since then, many state-of-the-art classifiers have been developed. Some of the most commonly used classifiers are logistic regression, Naive Bayes classifier, linear discriminant analysis, support vector machines, k-nearest neighbor, decision trees, and neural networks.
A classification algorithm is a linear classifier if it uses a linear function or linear predictor that assigns a score to each category based on the dot product of a weight vector and a feature vector. The linear predictor is given by the score function, , where is the feature vector for the observation , and is the weight vector corresponding to category . Observation is mapped by the linear predictor to the category with the highest score function . Examples of linear classifiers include logistic regression, support vector machines, and linear discriminant analysis (Yuan, Ho & Lin, 2012).
Topological data analysis (TDA)
Data scientists employ techniques and theories drawn from various fields of mathematics, particularly algebraic topology, statistics, information science, and computer science. In mathematics, there is a growing field called topological data analysis, which is an approach that uses tools and techniques from topology to analyze datasets (Chazal & Michel, 2021). In the past two decades, TDA has been applied in various areas of science, engineering, medicine, astronomy, image processing, and biophysics.
Analyzing the shape of data is one of the motivations for using TDA. One of the key tools used in TDA is persistent homology (PH), a method based on algebraic topology that can be used for determining invariant features or topological properties of a space of points that persist across multiple resolutions (Edelsbrunner & Harer, 2008; Carlsson, 2009; Edelsbrunner & Harer, 2010). These derived invariant features are sensitive to small changes in the input parameters which make PH attractive to researchers studying qualitative features of data. PH involves representing a point cloud by a filtered sequence of nested complexes, which are turned into novel representations like barcodes and then interpreted statistically and qualitatively based on persistent topological features obtained (Otter et al., 2017). The following section gives a brief description of how to compute PH and a more detailed discussion of pertinent information about the homology of simplicial complexes and the complete process of computing PH of a point cloud can be found in the Appendix.
Computing persistent homology
Given a finite metric space S, such as a point cloud or a collection of experimental data, it is assumed that S represents a sample from an underlying topological space, such as space T. Describing the topology of T based only on a finite sample S is not a straightforward task. However, PH can be utilized to determine the general shape and topological properties of T while maintaining the robustness of the data.
A point cloud can undergo a filtration process that turns it into a sequence of nested simplicial complexes. This is accomplished by considering a finite number of increasing parameters and recording the sublevel sets that track changes in the topological features of the complexes. More specifically, gradually thickening the points give birth to new topological features, like simplices and -dimensional holes (Zomorodian & Carlsson, 2005). Figure 1 shows an illustration of the filtration process. A more formal and extensive discussion of how to compute the persistent homology of a point cloud is presented in the Appendix.
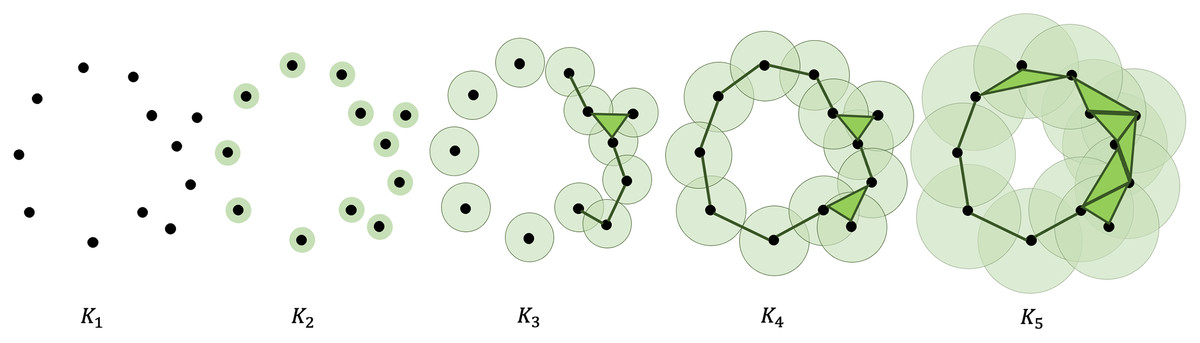
Figure 1: Filtration of a point cloud into a nested sequence of simplicial complexes, with .
{kind=link}
The appearance (birth) and disappearance (death) of intrinsic topological features, like homology groups and Betti numbers, can be recorded and visualized in many ways. The most frequently used are persistence barcodes or persistence diagrams. The duration or life span of the persisting topological features is essential in analyzing the qualitative and topological properties of a dataset.
Definition 1. Let K be a finite simplicial complex and be a finite sequence of nested subcomplexes of K. K is called a filtered simplicial complex and the sequence is called a filtration of K.
The homology of each of the subcomplexes can be computed. For each , the inclusion maps induce -linear maps for all with . It follows from functoriality that for all .
Definition 2. Let be a subcomplex in the filtration of the simplicial complex K, or be the filtered complex at time , and and be the -th cycle group and boundary group of , respectively. The -th homology group of is .
Definition 3. For , the -persistent -th homology group of K given a subcomplex is
The -th persistent -th Betti number of is the rank of .
Persistent vector spaces and persistence diagrams
Definition 4. A persistent vector space Carlsson (2014) is defined to be a family of vector spaces with linear maps between them, denoted by , such that
(1) for each ,
(2) there exist , such that all maps are linear isomorphisms for and for , and
(3) there are only finitely many values of such that
(4) for any , we have .
Note that there are only finitely many values of for which the linear maps are not isomorphisms. This implies that the indexing set can be reduced to , and we may equivalently define a persistent vector space to be an -induced family such that
(1) for each and
(2) there exists such that all the are isomorphisms for .
A persistent vector space can be obtained from a filtered simplicial complex and for each persistent vector space, one may associate a multiset of intervals called a persistence barcode or persistence diagram. A barcode represents each persistent generator with a horizontal line beginning at the first filtration level where it appears and ending at the filtration level where it disappears. Short bars correspond to noise or artifacts in the data, while lengthy bars correspond to relevant topological features. The standard treatment of persistence barcodes and diagrams appears in Edelsbrunner, Letscher & Zomorodian (2002) and Zomorodian & Carlsson (2005).
Presented here is a modern presentation of the definition of persistence diagrams and persistence barcodes (Chowdhury & Mémoli, 2018; Edelsbrunner, Jablonski & Mrozek, 2015).
Let be a persistent vector space. Compatible bases for each , can be chosen such that is injective for each , and , for each (Edelsbrunner, Jablonski & Mrozek, 2015). Note that denotes the restriction of to the set . Fix such a collection of bases. Then, define
For each , the integer is interpreted as the birth index of the basis element or the first index at which a certain algebraic signal appears in the persistent vector space. Now, define a map as follows
For each , the integer is called the death index or the index at which the signal disappears from the persistent vector space.
Definition 5. The persistence barcode of is defined to be the following multisets of intervals:
where the bracket notation denotes taking the multiset and the multiplicity of is the number of elements such that
The elements of are called persistence intervals. They can be represented as a set of line segments over a single axis. Equivalently, can be visualized as a multiset of points lying on or above the diagonal in counted with multiplicity, where denotes .
Definition 6. The persistence diagram of is given by
where multiplicity of is given by the multiplicity of .
Discussion of the robustness and stability of the persistence diagram requires the notion of distance. Given two persistence diagrams, say X and Y, the definition of distance between X and Y is given as follows.
Definition 7. Let . The -th Wasserstein distance between X and Y is defined as
for and as
for , where is a metric on and ranges over all bijections from X to Y.
Normally, is taken to be where and the most commonly used distance function is the Bottleneck distance . Equivalently, the bottle distance between persistence diagrams can be defined as follows.
Definition 8. The bottleneck distance between persistent diagrams and more generally, between multisets C, D of points in is given by
where for each , , p', and , and is the multiset consisting of each point on the diagonal, taken with infinite multiplicity.
Basis for the classification algorithm
Let I be an index set with K elements, where . Suppose each corresponds to a class of points in . Let be the set of -dimensional points in the Euclidean space belonging to class . Now, suppose there is an -dimensional point . The problem of determining which of the K classes of points belongs to is a classification problem. Note that the collection of points belonging to the same class has its own topological properties. It is a natural intuition that the inclusion of an additional point in a point cloud where it belongs should result in a very small change in its topological properties. What follows is a way to analyze a point cloud and its properties.
Given a point cloud, we can compute its corresponding topological properties in the form of a persistence barcode or a persistence diagram. To do this, we follow the succeeding construction. From here on, this is referred to as the long construction.
For each point cloud , , applying the long construction is the same as defining the following;
(i) the Vietoris Rips complex filtration given by corresponding to the with fixed , , and the parameter values ’s with and , for each ,
(ii) an -indexed persistent vector space such that
(1) for each and
(2) there exists such that all the are isomorphisms for .
(iii) chosen compatible bases for each respective class or , such that denote the restriction of to the set and ,
(iv) the set given by ,
(v) the map defined by ,
(vi) the persistence barcode given by , where the bracket notation denotes taking the multiset and the multiplicity of is the number of elements such that , and
(vii) the persistence diagram given by , where multiplicity of is given by the multiplicity of .
Now, we consider the scenario of adding the -dimensional point to the point clouds. Define for each . Apply the long construction for each of these point clouds, that is define the following;
(i) the Vietoris Rips complex filtration given by corresponding to the with fixed , , and the parameter values ’s where and for each ,
(ii) the -indexed persistent vector space similar to that of ,
(iii) compatible bases similar to that of ,
(iv) the set similar to that of ,
(v) the map similar to that of
(vi) the persistence barcode or multiset given by , and
(vii) the persistence diagram given by .
Finally, classification is done by choosing the class for which the change in the topological properties between and is minimum. This is inspired by the following observations.
Theorem 1. Let I be a finite index set. Suppose that for each , is the set of points in belonging to class , and that for each . Assuming is a point identical to one of the points in , for an element . Then, for each ,
where , and are the -indexed persistent vector spaces corresponding and , respectively, for each .
Proof. Let be an -dimensional point where . Choose any element such that . Then, . Apply the long construction for , , , and . From the long constructions leading to the computation of persistence diagrams, we can define the following
(i) the Vietoris Rips complex filtrations associated to , , and , with respect to some , , and the parameter values ’s with and for each ,
(ii) the -indexed persistent vector spaces , , , and ,
(iii) respective compatible bases , , , and ,
(iv) the sets , , , and ,
(v) the maps , , , and ,
(vi) the persistence barcodes or multisets given by , , , and , and
(vii) the persistence diagrams given by , , , and .
Since , then , , and has one more element than . Also, and . Note that there is at least one with at least the first index 1. Then , by the definition of . That is, the death index corresponding must be greater than 1.
This implies that will have one more element than . This means that has one unmatched point with respect to the pairing with . Then, the computation of boils down to the optimal distance between the matched points or the distance between the unmatched point to the diagonal. In either case, this is greater than zero.
Now, since , then .
Hence, for each ,
Theorem 2. Let I be a finite index set. Suppose that for each , is the set of points in belonging to class , and that for each . Assume is the new data point and for each . Let be a point in , where , such that is the closest point to among all points in . If the long construction is applied to and , and to and , for each , , and the sets , , , and are limited to elements with birth index of 1, then for each ,
where and are the -indexed persistent vector spaces corresponding to and , respectively, for each .
Proof. Let I be a finite index set. Suppose that for each , is the set of points in belonging to class , and that for each . Assume is the new point and for each . For each , let be the element in which is closest to . Suppose that is the closest element to among any , where .
Without loss of generality, choose any element such that . Then, . Apply the long construction for , , and . From the long constructions leading to the computation of persistence diagrams, we define the following;
(i) the Vietoris Rips complex filtrations associated to , , and , with respect to some , , and the parameter values ’s with and , for each ,
(ii) the -indexed persistent vector spaces , , , and ,
(iii) respective compatible bases , , , and ,
(iv) the sets , , , and whose elements are restricted to those with birth index of 1,
(v) the maps , , , and ,
(vi) the persistence barcodes or multisets given by , , , and , and
(vii) the persistence diagrams given by , , , and .
For each , define to be the point in which is closest to . Note that limiting the basis elements to those with birth index of 1 means that only the 0-dimensional topological properties or the connectedness of the simplices are considered. Also, for each , and differ only by a single point, the point . By these, the 0-dimensional hole corresponding to in the filtration of disappears faster if is closer to . Moreover the computation of is reduced to the computation of for each . Since is closest to among all the ’s, then this implies that , for any , where and . This completes the proof.
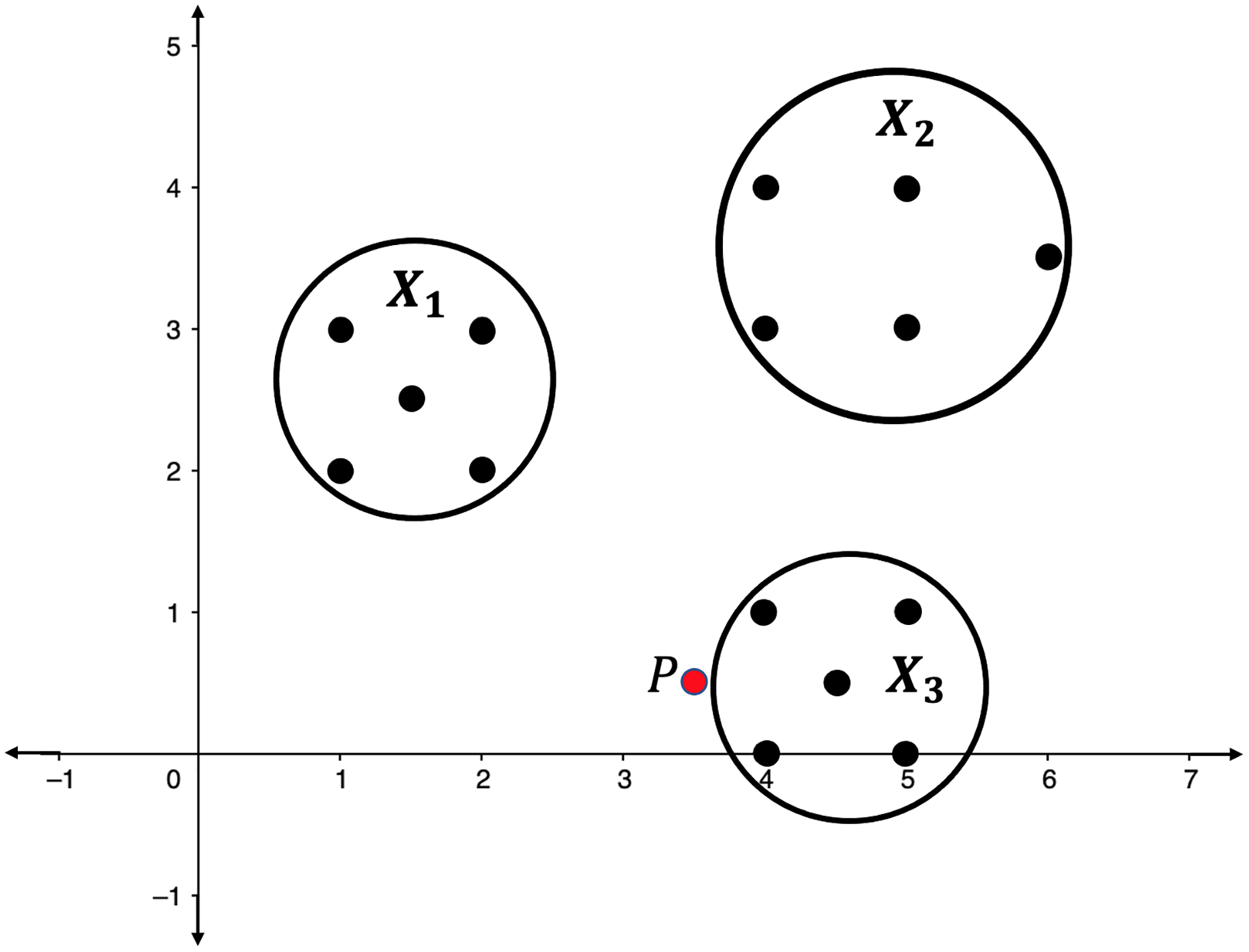
Illustration 1. Consider the point clouds labelled as , , and , and the point P in the 2-dimensional space as presented in Fig. 2. Suppose that the point P has to be categorized into one of the point clouds.
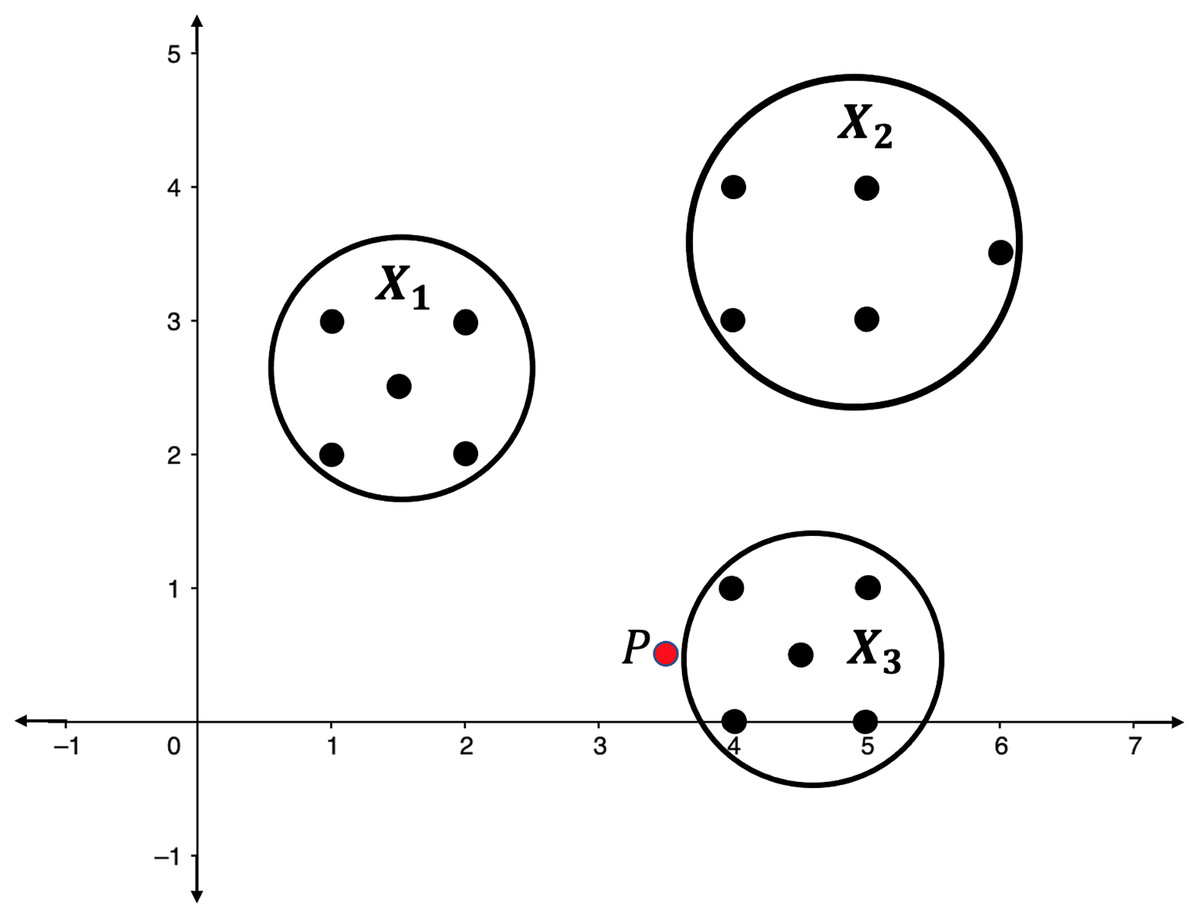
Figure 2: Point clouds , , and , and point P.
{kind=link}
For each , define and compute the persistent homologies of and . Presented in Fig. 3 are the respective persistence barcodes corresponding to the 0-dimensional holes in the filtration of the ’s and ’s. Note that each pair of and differ only by a single point, the point P. Since only the 0-dimensional holes are considered here, then the persistence barcode for has one more bar than the persistence barcode for , for each . These differences, represented by the green bars in Fig. 3, are indicative of the shortest distance of P from the point clouds. The life span of the 0-dimensional hole corresponding to point P in the filtration of is the shortest when is the closest point cloud to P. For each ,
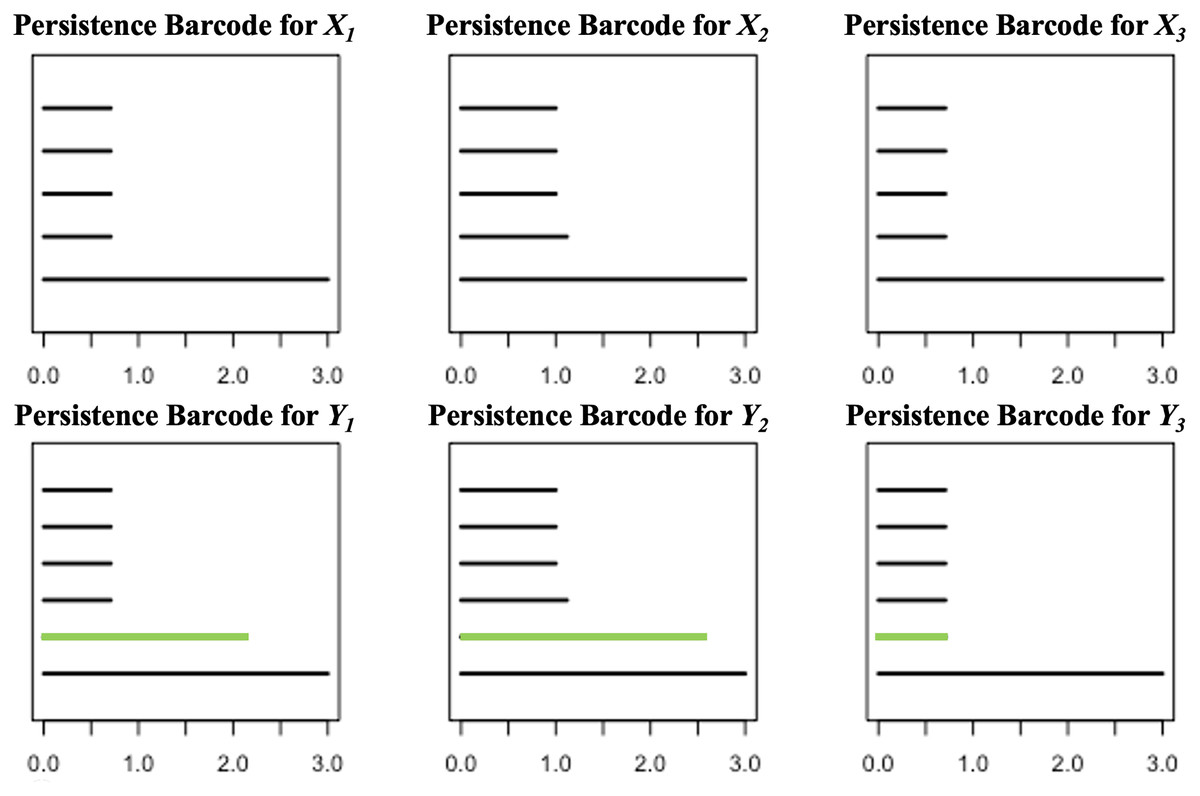
Figure 3: Persistence barcodes corresponding to the 0-dimensional holes in the filtration of the ’s and ’s.
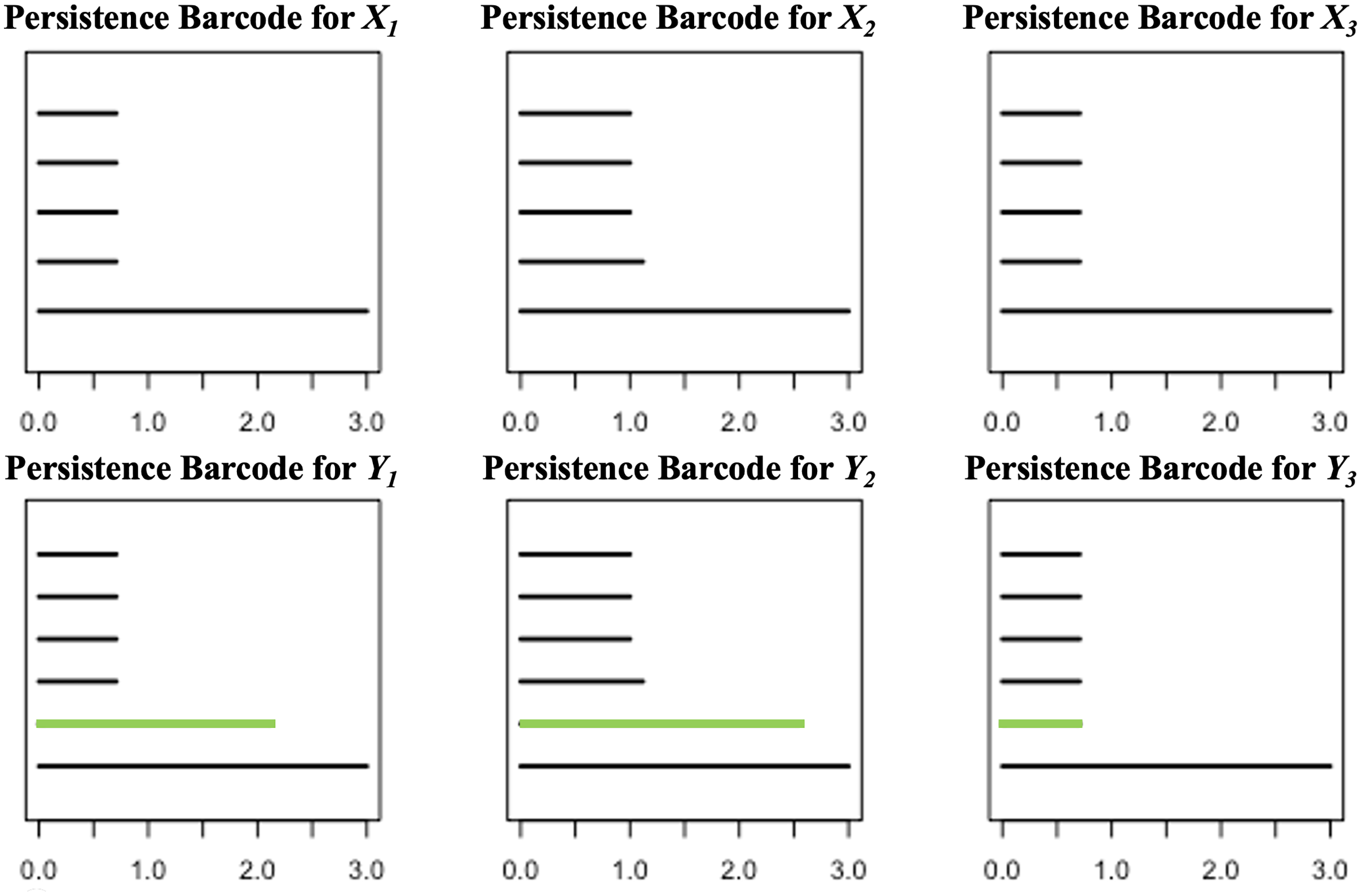{kind=link}
where is the point in that is closest to P.
Advances in the fusion of persistent homology and machine learning
Computation of persistent homology (PH) has been applied to a variety of fields, including image analysis, pattern comparison and recognition, network analysis, computer vision, computational biology, oncology, and chemical structures. Some examples can be found in the works of Charytanowicz et al. (2010), Goldenberg et al. (2010), Nicolau, Levine & Carlsson (2011), Xia & Wei (2014), Giansiracusa, Giansiracusa & Moon (2019), and Ignacio & Darcy (2019). Furthermore, advances in the different aspects of computing PH have been increasing at a very rapid rate. Various software have also been developed for computing persistent homology. These software packages include JavaPlex, Perseus, Dipha, Dionysus, jHoles, GUDHI (Geometry Understanding in Higher Dimensions), Rivet, Ripser, PHAT (Persistent Homology Algorithm Toolkit), and R-TDA (R package for Topological Data Analysis) (Otter et al., 2017; Pun, Lee & Xia, 2022). On the other hand, machine learning has been in development as early as 1950s, but it was not until the 1990s that a shift from a knowledge-driven approach to a data-driven approach in studying machine learning took place. It was also during this time when support vector machines and neural networks became very popular. Persistent homology, which has only been around for a decade, has also received attention in recent years.
A direct exposition of the use of machine learning and persistence barcodes was used by Giansiracusa, Giansiracusa & Moon (2019) in solving a fingerprint classification problem. They also showed that better accuracy rates can be achieved when applying topological data analysis to 3-dimensional point clouds of oriented minutiae points. Chung, Cruse & Lawson (2020) used persistence curves, rather than barcodes or diagrams, to analyze time series classification problems. Ismail et al. (2020) used PH-based machine learning algorithms to predict next day direction of stock price movement. Hofer et al. (2017) incorporated topological signatures to deep neural networks and performed classification experiments on 2D object shapes and social network graphs. Gonzalez-Diaz, Gutiérrez-Naranjo & Paluzo-Hidalgo (2020) used PH to define neural networks by incorporating the concept of representative datasets. In their study, they used persistence diagrams in choosing points that would be included in the representative dataset. Chen et al. (2019) leveraged topological information to regularize the topological complexity of kernel classifiers by incorporating a topological penalty, while Pokorny, Hawasly & Ramamoorthy (2014) used topological approaches to improve trajectory classification in robotics. Edwards et al. (2021) introduced TDAExplore, a machine learning image analysis pipeline based on topological data analysis. TDAExplore can be used to classify high-resolution images and characterize which image regions contribute to classification. PH has also been found useful in unsupervised learning and clustering tasks. Islambekov & Gel (2019) presented an unsupervised PH-based clustering algorithm for space-time data. They evaluated the performance of their proposed algorithm on synthetic data and compared it to other well-known clustering algorithms such as K-means, hierarchical clustering, and DBSCAN (Density-based spatial clustering of applications with noise).
Pun, Lee & Xia (2022) published a survey of PH-based machine learning algorithms and their applications. They presented ways how to use persistent homologies to improve machine learning algorithms such as support vector machines, tree-based methods, and artificial neural networks. The strategies require extracting topological features from individual data points and adding them as new attributes to the data points. The classification algorithms are then modified in such a way that they can utilize the additional attributes to classify the data points more accurately. These strategies of modifying learning algorithms by incorporating topological signatures as additional features to the data points are very effective when the data under scrutiny contains high-dimensional points and when points belonging to the same class share common topological properties. This means that the improved algorithm can be used to group together data points with similar shapes or topological properties. On the other hand, these strategies may not work when the dataset under consideration contains data points in a Euclidean space, when each of the points in the dataset has very low dimensions, or if data points from the same class do not share the same topological properties.
On the contrary, the objective of this study was to develop a supervised classification algorithm for dealing with classification problems involving points in a Euclidean space, datasets that can be separated into classes using hyperplanes, or when points from the same class have a certain level of proximity with each other. The proposed classifier in this study takes substantial use of persistent homologies and topological signatures associated with the different classes of points in the dataset instead of the individual data points’ persistent homologies and topological features.
Persistent homology classification algorithm (phca)
A supervised classification algorithm or classifier is a technique that assigns a new object or observation to a class based on the training set and the new observation’s attribute values. The classifier proposed in this work, termed persistent homology classification algorithm (PHCA), is largely reliant on the topological properties of each class of points in the available training set. The topological features derived from the persistence diagrams, generated by computing the persistent homology of each class in the training set, will be used to construct a linear classifier or a score function for classifying new observations. The section titled Computing Persistent Homology contains a discussion of the basis of this algorithm, while this section shows the outline of the proposed algorithm’s implementation.
Interpretation of a point cloud’s persistent homology
Let Z be a point cloud. Computing the persistent homology of Z means letting Z undergo filtration and recording the topological properties of Z that persist across multiple resolutions. The result of computing the persistent homology of Z or the summary of the topological properties of the space underlying Z can be visualized using persistence barcodes and persistence diagrams as shown in Definitions 5 and 6. See the Appendix for an illustration. Moreover, it can also be represented by an matrix and it will be denoted by in this section. The number of rows of , , is the number of topological features or -dimensional holes detected in the filtration of Z. The 0-dimensional holes are the connected components, 1-dimensional holes refer to loops, 2-dimensional holes represent voids, and so on. One can limit the maximum dimension that can be detected in the filtration of Z. The first column entry of the -th row of indicates the dimension of -th topological feature in the filtration of Z. The second and third column entries in the -th row of give the birth and death time of the -th topological feature, respectively. The birth and death times refer to the filtration steps when the topological feature appears and disappears, respectively.
Let be the persistent homology of a point cloud Z. Although it can be visualized as a persistence diagram, it denotes an matrix, where is the number of holes, of various dimensions, which are detected in the complex filtration.
Setting of maximum parameter value
The maximum scales, denoted by maxsc, must be fixed. The scale here refers to the size of the parameter values that will be used in the filtration and the computation of the persistent homology of a point cloud. The suitable value for maxsc depends on the data at hand and it can be chosen to be equal to half of the maximum distance between any two points in the point cloud.
Training and classification
Assume that X is a training dataset consisting of ( )-dimensional data points categorized into classes. Each data point’s initial entries contain its attributes, while the ( )-th entry gives its label or classification. Suppose that , where ,…, are the classes of data points, and is the number of elements in . Each training point cloud can be viewed as an ( ) ( ) matrix with each row representing a point belonging in .
Suppose that a new -dimensional point, denoted by , needs to be classified. To begin, analyze the different classes in the training set or describe the topological properties of each class in X by computing for each . Then, measure the effect of including in each class in X. Define and compute for each . Record the changes in the persistent homology between and for each . Specifically, record the change from to for each . Lastly, identify the class that is least impacted by the inclusion of . This procedure follows the long construction defined in the basis for the classification algorithm.
Score function for PHCA
The use of persistent homology in the development of the score function that will act as the linear predictor for PHCA is described here. Consider a training set categorized into two classes, A and B. Suppose is a point that needs to be classified and that belongs to either A or B only, as shown in Fig. 4. The proposed PHCA works by computing the persistent homology of A, B, , and . Afterward, measure the changes in the topological features from A to and from B to . Suppose that point is closer to point cloud A than point cloud B, then the change in the persistent homology of A to will be lower than the change in the persistent homology from B to . This is because the closer a point to a point cloud, say Z, the birth, and death of some topological features of , particularly the 0-dimensional holes, will come earlier. That is, the early appearance or disappearance of topological features translates to a shorter life span of topological features in the filtration of the complexes. This procedure which is based on Theorems 2 and 3 works particularly well when the point clouds for different classes are disjoint from one another or when a point under consideration is close to a particular point cloud. In light of these, the score function used for PHCA is computed in the following manner.
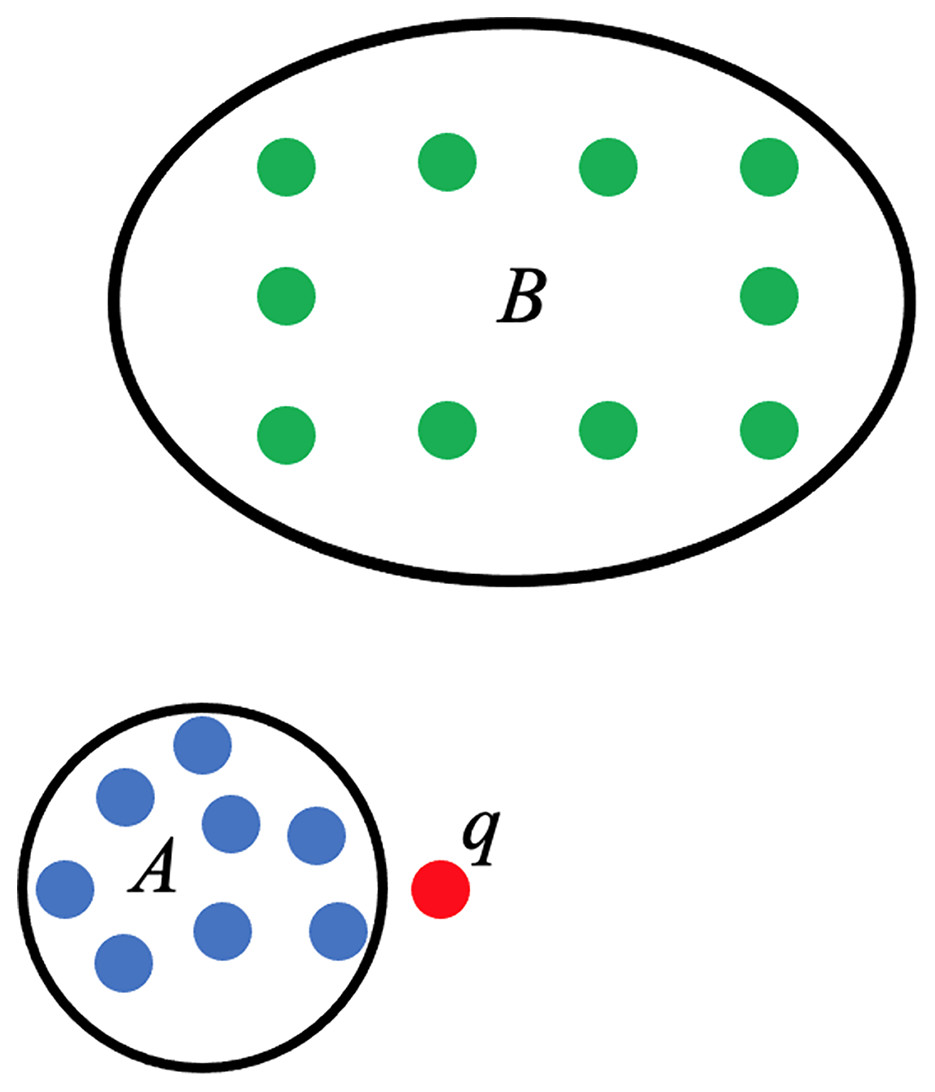
Figure 4: Training set of points categorized into class A (blue points) and class B (green points), and a new point .
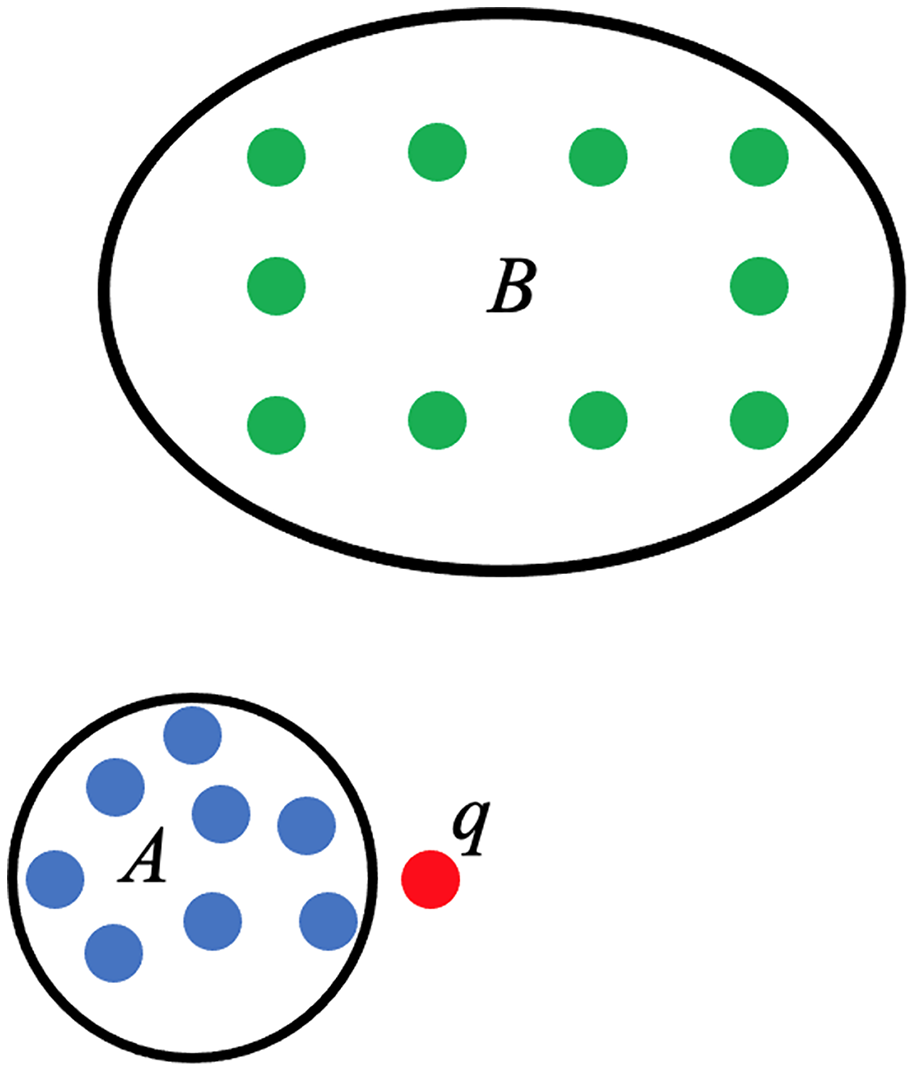{kind=link}
Recall that we have defined for each , and that is the persistent homology of for each . The score function is computed as the difference between the sum total of the lifespan of all the topological features in and the sum total of the lifespan of all the topological features in . This is equivalent to the difference between the sum of the entries of the third column of and the sum of the entries of the third column of . More explicitly, the score function value is computed as
(1) where is the map that sends a basis element with birth index of 1 to its death index.
Finally, the new data point is classified under class if for all . Algorithm 1 gives the pseudocode for the persistent homology classification algorithm (PHCA).
| Require: |
| Ensure: |
| Procedure |
| for do |
| matrix, a result of computing PH of Xi |
| Compute Score (Xi) |
| end for |
| end procedure |
Otter et al. (2017) established that computing the persistent homology of a point cloud using the standard algorithm has cubic complexity in terms of the number of simplices in the worst-case scenario. This, combined with the fact that PHCA is a linear classifier, means that the proposed classifier can be used to perform classification tasks in polynomial time.
Evaluvation methodolgy
The validity of PHCA was determined by solving four classification tasks using three well-studied datasets and a synthetic dataset made of points from three separate geometric figures. The number of classes per dataset ranges from 2 to 10, while the number of attributes per dataset ranges from 2 to 2025. The performance of the proposed PHCA was quantified and then compared to the performance of five main classification algorithms on four validation datasets. Linear discriminant analysis (LDA), Classification and Regression Trees (CART), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and Random Forest (RF) were the five classifiers used as benchmarks in this study.
All validation runs implemented in this study employed five-fold cross-validation. That is, the validation process involved dividing each class of the datasets into five sections. Each validation run requires a training set and a testing set. At any particular run, the testing set is composed of a partition from each class and the training set is composed of all the remaining data points. This guarantees that each class will have a representation in the testing. This scheme also assured that every single data point served as a testing point in one of the validation runs. To evaluate the methods, the confusion matrix was generated to determine the following metrics: precision, recall (sensitivity), specificity, accuracy, and F1 score. The confusion matrix gives the number of data points per class that is correctly predicted or incorrectly predicted.
For instance, consider a particular class, say , among classes. Then, we can define the following for each .
TPi is the number of true positives in class , or the number of instances in which are predicted to belong in .
TNi is the number of true negatives in class , or the number of instances outside which are predicted to not belong in .
FPi is the number of false positives in class , or the number of instances outside which are predicted to belong in .
FNi is the number of false negatives in class , or the number of instances in which are predicted to not belong in .
The five metrics per class are computed as follows
(2)
(3)
(4)
(5)
(6)
A high sensitivity prediction in Class implies that the reliability of predicting that an instance does not belong to is high. However, predicting that an instance belong to with high sensitivity is inconclusive. On the other hand, the high specificity of prediction in Class implies that the reliability of predicting that an instance belongs to is high. And, predicting that an instance does not belong to with high specificity is inconclusive. Moreover, precision for Class gives the proportion of data points predicted to really belong in . Recall gives the proportion of data points in Class which are correctly classified. Lastly, F1 score for Class is a performance measure that combines recall and precision. F1 score is computed as the harmonic mean of precision and recall. This is a particular instance of the F score which allows for more weight towards one of precision or recall over the other, needed for particular problems. An F-score may have a maximum value of 1.0, indicating perfect precision and recall, or a minimum value of 0, indicating that either precision or recall is zero.
The performance of PHCA and the five benchmark classification algorithms were compared using the Nemenyi post-hoc test. Pairwise comparisons of the methods were measured using mean rank differences. A was computed for each pair of methods using the formula
where and are mean ranks of two methods, is the number of methods and is the number of performance metric means per method. A of less than implies that the two methods are significantly different.
The validation of PHCA and the benchmark classifiers were done in R using the TDA, Caret, and DescTools packages. R-TDA package, containing the Dionysius library, was used for the computation of the persistent homology of the point clouds. The Caret package was used for the implementation of the benchmark classifiers, with the same caret parameters, which are metric and control. While DescTools was used for the implementation of the Nemenyi Test.
Results and discussion
The performances of the proposed PHCA and the five benchmark classification algorithms (i.e., LDA, CART, KNN, SVM, and RF) for the four classification problems are presented here. Validation results for each classification task are also discussed in the following sections. Program codes, written in R, to implement the classification algorithms can be found on https://github.com/mlddelara/PHCA. Recall that PHCA works in a way that a data point in the testing set will be classified under a class if the inclusion of the point in the particular class’ training set results in the least change in the persistence diagram of the training set with the additional data point and least change in the engineered features corresponding the data point to be classified.
Iris plant dataset
The iris plant dataset composed of 150 observations created by Fisher (1936) was obtained from the UCI Machine Learning Repository (Dua & Graff, 2017). This is one of the commonly used datasets in pattern recognition. The dataset is divided into three categories: iris setosa, iris versicolour, and iris virginica. Each category is comprised of 50 data points, with four attributes namely sepal length, sepal width, petal length, and petal width (expressed in centimeters).
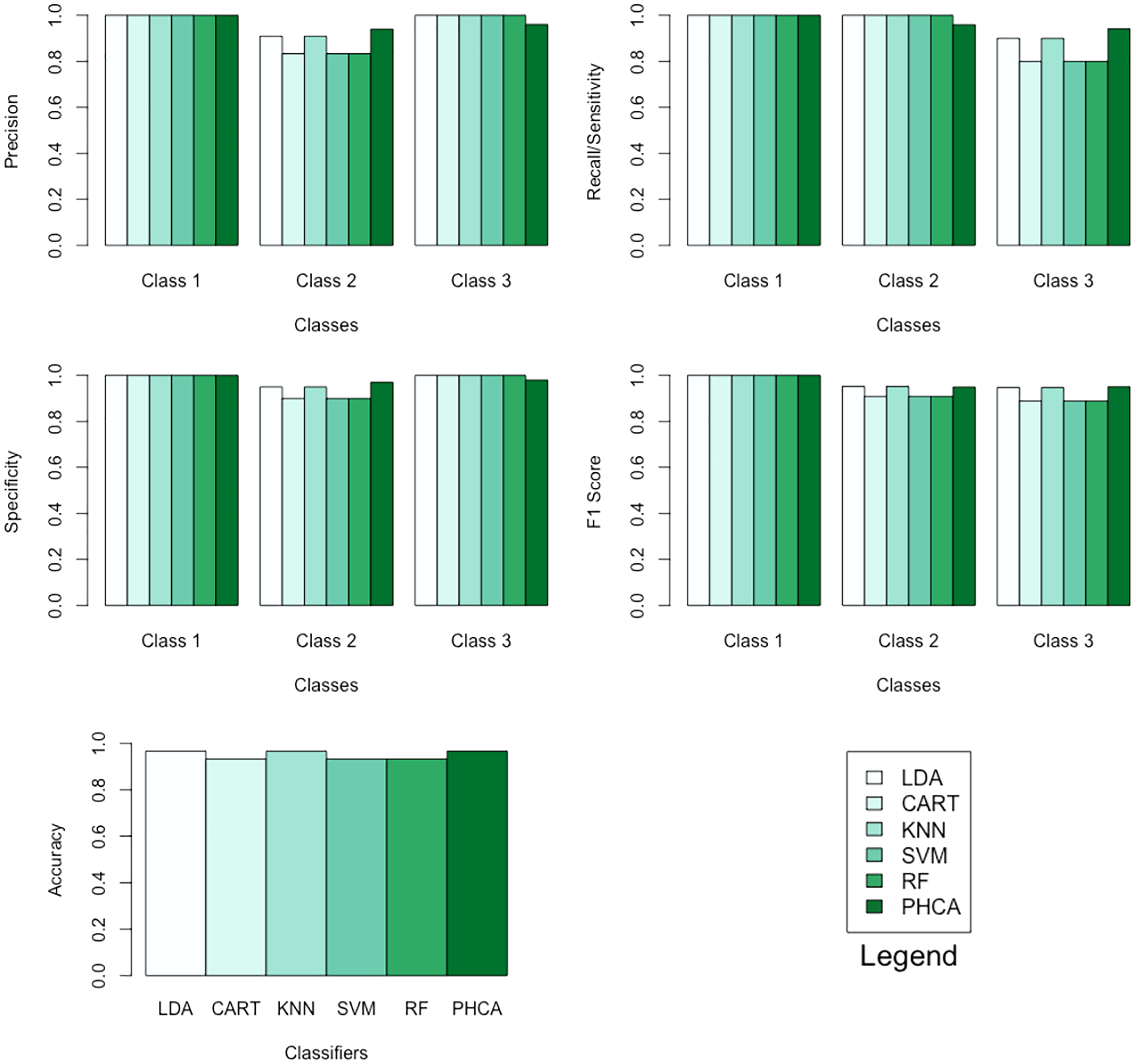
Table 1 shows the performance of PHCA and the five major classification algorithms in terms of precision and recall per class. Moreover, Table 2 shows the mean performance of the six methods in terms of accuracy, specificity per class, and F1 score per class. Barplots of these results are presented in Fig. 5. LDA, KNN, and PHCA got an accuracy of , while CART, SVM and RF obtained an accuracy of . Table 3 shows a summary of the Nemenyi test results and the implies that there is no significant difference in the performance of PHCA and the other methods in terms of the mean performance metrics.
| Classifier | Precision (%) | Recall (%) | ||||
|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 1 | Class 2 | Class 3 | |
| LDA | 100.00 | 90.91 | 100.00 | 100.00 | 100.00 | 90.00 |
| CART | 100.00 | 83.33 | 100.00 | 100.00 | 100.00 | 80.00 |
| KNN | 100.00 | 90.91 | 100.00 | 100.00 | 100.00 | 90.00 |
| SVM | 100.00 | 83.33 | 100.00 | 100.00 | 100.00 | 80.00 |
| RF | 100.00 | 83.33 | 100.00 | 100.00 | 100.00 | 80.00 |
| PHCA | 100.00 | 94.00 | 96.00 | 100.00 | 95.92 | 94.11 |
| Classifier | Accuracy (%) | Specificity (%) | F1 score (%) | ||||
|---|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 1 | Class 2 | Class 3 | ||
| LDA | 96.67 | 100.00 | 95.00 | 100.00 | 100.00 | 95.24 | 94.74 |
| CART | 93.33 | 100.00 | 90.00 | 100.00 | 100.00 | 90.91 | 88.89 |
| KNN | 96.67 | 100.00 | 95.00 | 100.00 | 100.00 | 95.24 | 94.74 |
| SVM | 93.33 | 100.00 | 90.00 | 100.00 | 100.00 | 90.91 | 88.89 |
| RF | 93.33 | 100.00 | 90.00 | 100.00 | 100.00 | 90.91 | 88.89 |
| PHCA | 96.67 | 100.00 | 97.03 | 97.98 | 100.00 | 94.95 | 95.05 |
| Number of data points: | 150 | Number of classes: | 3 | ||||
| Training set size: | 120 | Number of attributes: | 4 | ||||
| Testing set size: | 30 | ||||||
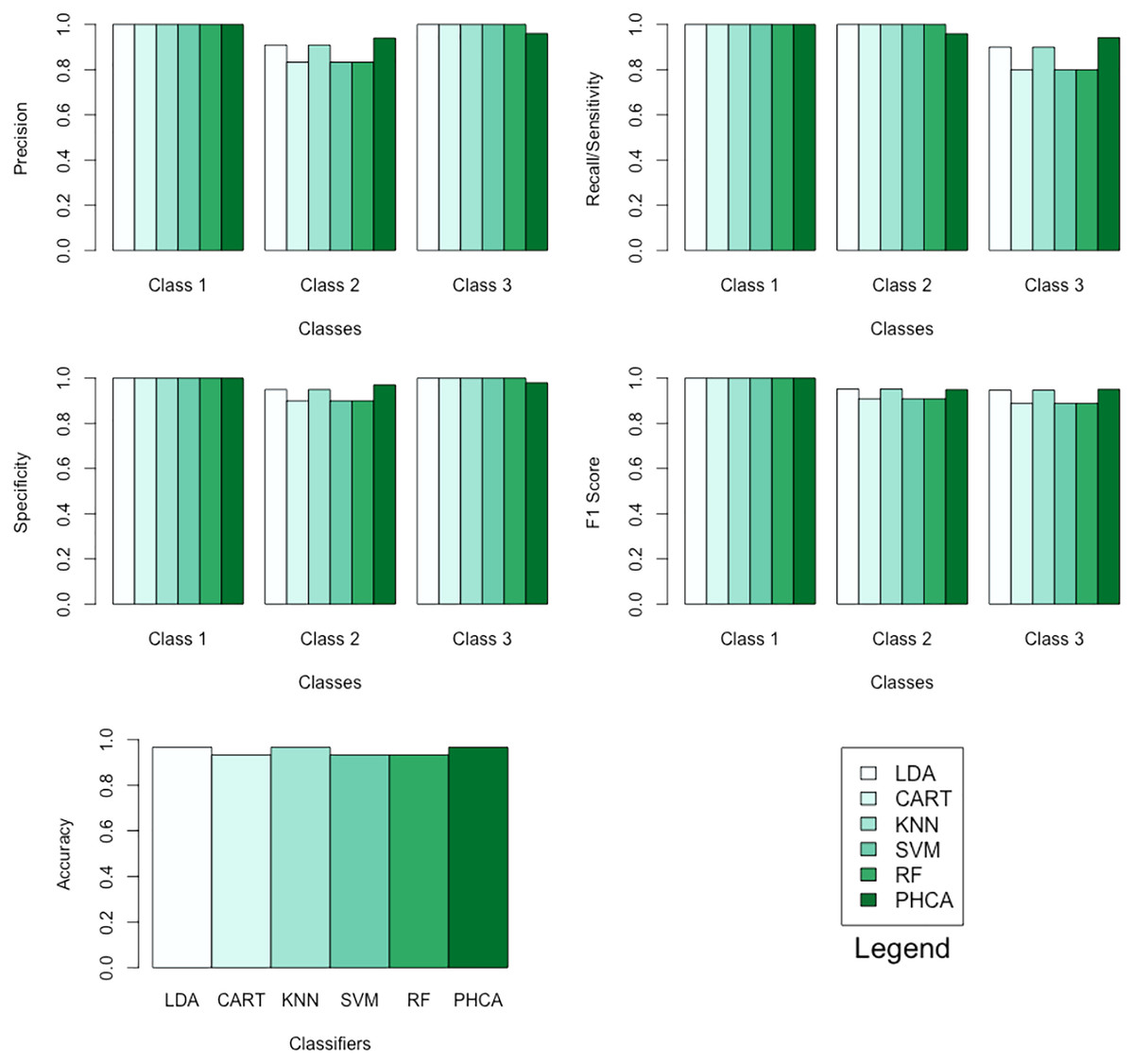
Figure 5: Barplots of performance metrics of PHCA and the five other classifiers for the iris dataset.
{kind=link}
| Mean rank difference | p-value | |
|---|---|---|
| CART-LDA | −6.576923 | 0.9770 |
| KNN-LDA | 0.000000 | 1.0000 |
| SVM-LDA | −6.576923 | 0.9770 |
| RF-LDA | −6.576923 | 0.9770 |
| PHCA-LDA | −3.346154 | 0.9990 |
| KNN-CART | 6.576923 | 0.9770 |
| SVM-CART | 0.000000 | 1.0000 |
| RF-CART | 0.000000 | 1.0000 |
| PHCA-CART | 3.230769 | 0.9992 |
| SVM-KNN | −6.576923 | 0.9770 |
| RF-KNN | −6.576923 | 0.9770 |
| PHCA-KNN | −3.346154 | 0.9990 |
| RF-SVM | 0.000000 | 1.0000 |
| PHCA-SVM | 3.230769 | 0.9992 |
| PHCA-RF | 3.230769 | 0.9992 |
Wheat seeds dataset
The wheat seeds dataset was created by Charytanowicz et al. (2010) at the Institute of Agrophysics of the Polish Academy of Sciences in Lublin. It is available at the UCI Machine Learning Repository (Dua & Graff, 2017). The dataset is composed of 210 observations, which is divided equally into three categories: kama, rosa, and canadian wheat variety. Each observation is characterized by seven attributes, namely, area, perimeter, compactness, length of kernel, width of kernel, asymmetry coefficient, and length of kernel groove. All of these attributes are real-valued and continuous.
The performance of PHCA and the five major classification algorithms in terms of precision and recall per class is shown in Table 4. Furthermore, Table 5 compares the six methods in terms of accuracy, specificity per class, and F1 score per class. Barplots of these results are presented in Fig. 6. For the wheat seeds dataset, PHCA got the third highest accuracy, which is at . Notice that PHCA got the least performance in some metrics per class, but these were offset when PHCA got the highest performance in terms of precision for class 3, recall for class 1, specificity for class 3, and F1 score for class 3. Moreover, the results of the Nemenyi test, which can be found in Table 6, show that there is no significant difference between the performance of the six methods in terms of the mean performance metrics.
| Classifier | Precision (%) | Recall (%) | ||||
|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 1 | Class 2 | Class 3 | |
| LDA | 100.00 | 100.00 | 82.35 | 78.57 | 100.00 | 100.00 |
| CART | 100.00 | 100.00 | 77.78 | 71.43 | 100.00 | 100.00 |
| KNN | 100.00 | 93.33 | 73.68 | 57.14 | 100.00 | 100.00 |
| SVM | 100.00 | 100.00 | 82.35 | 78.57 | 100.00 | 100.00 |
| RF | 100.00 | 100.00 | 77.78 | 71.43 | 100.00 | 100.00 |
| PHCA | 85.71 | 92.86 | 94.28 | 86.96 | 94.21 | 91.67 |
| Classifier | Accuracy (%) | Specificity (%) | F1 score (%) | ||||
|---|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 1 | Class 2 | Class 3 | ||
| LDA | 92.85 | 100.00 | 100.00 | 89.3 | 88.00 | 100.00 | 90.30 |
| CART | 90.48 | 100.00 | 100.00 | 85.70 | 83.30 | 100.00 | 87.50 |
| KNN | 85.71 | 100.00 | 96.40 | 82.10 | 72.70 | 96.60 | 84.90 |
| SVM | 92.86 | 100.00 | 100.00 | 89.30 | 88.00 | 100.00 | 90.30 |
| RF | 90.48 | 100.00 | 100.00 | 85.70 | 83.30 | 100.00 | 87.50 |
| PHCA | 90.95 | 92.90 | 96.50 | 97.10 | 86.30 | 93.50 | 93.00 |
| Number of data points: | 210 | Number of classes: | 3 | ||||
| Training set size: | 168 | Number of attributes: | 7 | ||||
| Testing set size: | 42 | ||||||
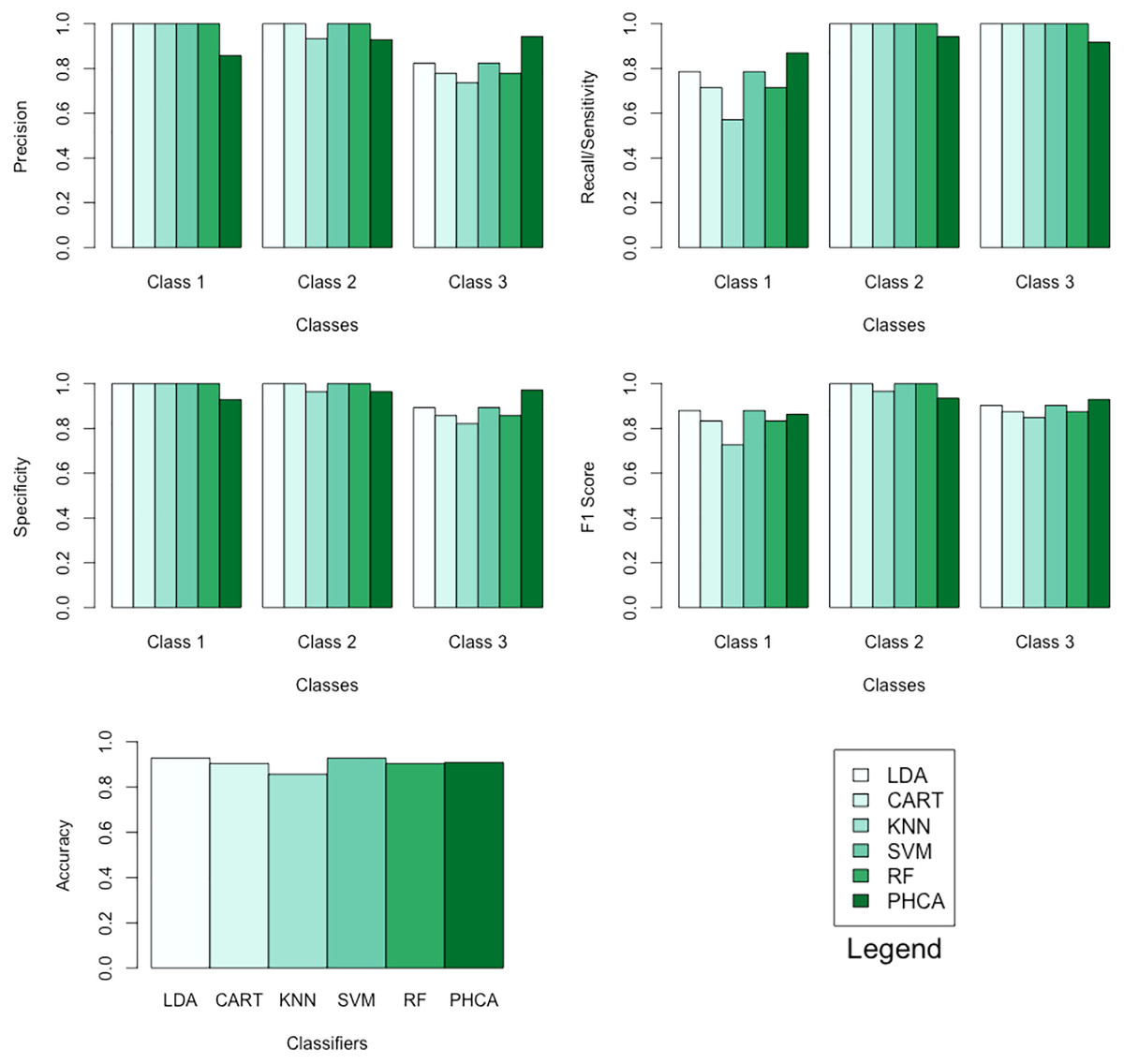
Figure 6: Barplots of performance metrics of PHCA and the five other classifiers for the wheat seeds dataset.
{kind=link}
| Mean rank difference | p-value | |
|---|---|---|
| CART-LDA | −3.192308 | 0.9992 |
| KNN-LDA | −10.961538 | 0.8206 |
| SVM-LDA | 0.000000 | 1.0000 |
| RF-LDA | −3.192308 | 0.9992 |
| PHCA-LDA | −9.653846 | 0.8871 |
| KNN-CART | −7.769231 | 0.9527 |
| SVM-CART | 3.192308 | 0.9992 |
| RF-CART | 0.000000 | 1.0000 |
| PHCA-CART | −6.461538 | 0.9787 |
| SVM-KNN | 10.961538 | 0.8206 |
| RF-KNN | 7.769231 | 0.9527 |
| PHCA-KNN | 1.307692 | 1.0000 |
| RF-SVM | −3.192308 | 0.9992 |
| PHCA-SVM | −9.653846 | 0.8871 |
| PHCA-RF | −6.461538 | 0.9787 |
Social network ads dataset
The social network ads dataset was created by Raushan (2017) and was retrieved from the Kaggle repository. The dataset is composed of 400 data points and is comprised of uneven number of observations per class. There are 143 data points for Class 1 and 257 data points for Class 2. Each data point has two attributes, age and estimated salary, and a class label, whether a customer purchased a product or not.
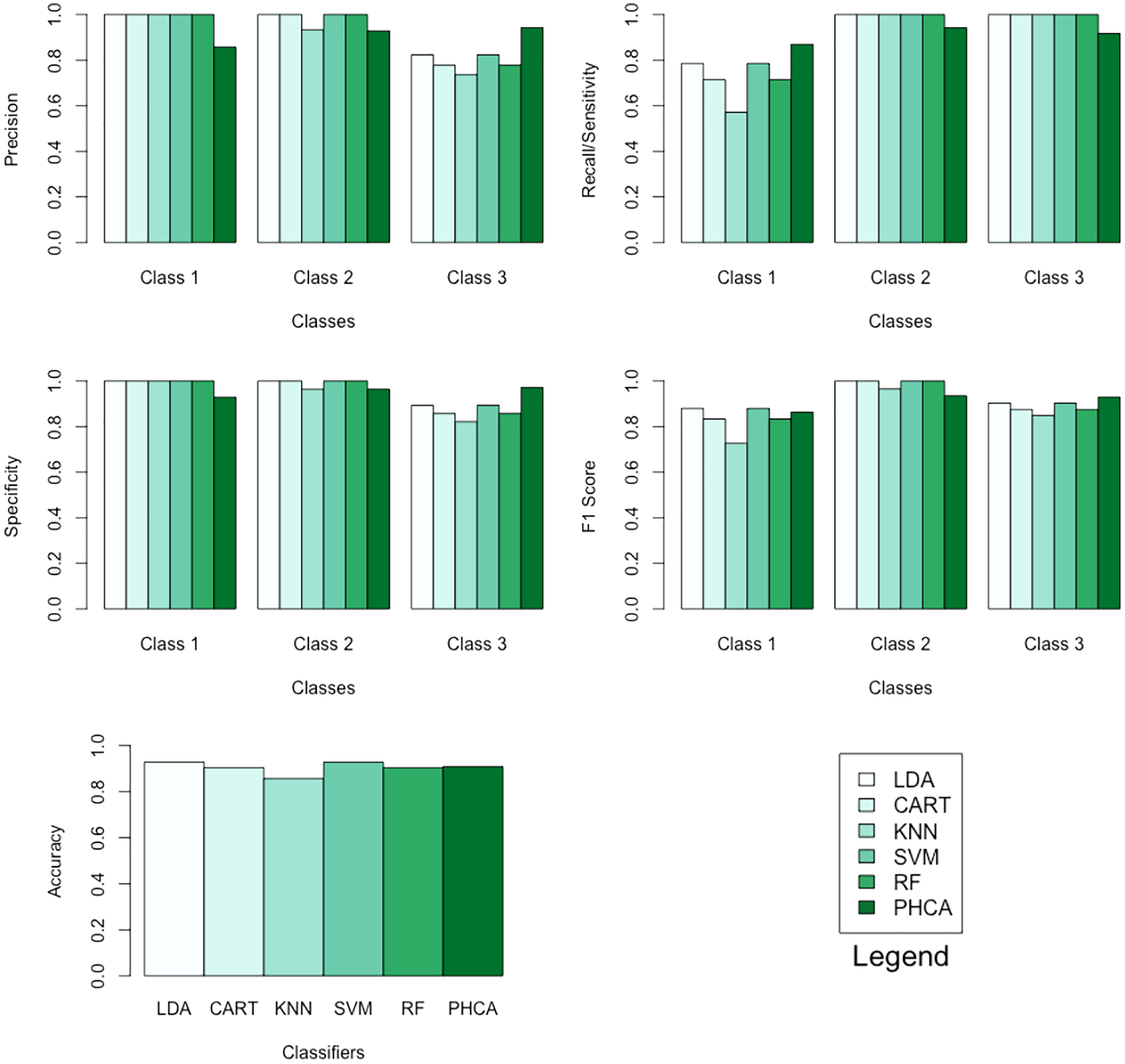
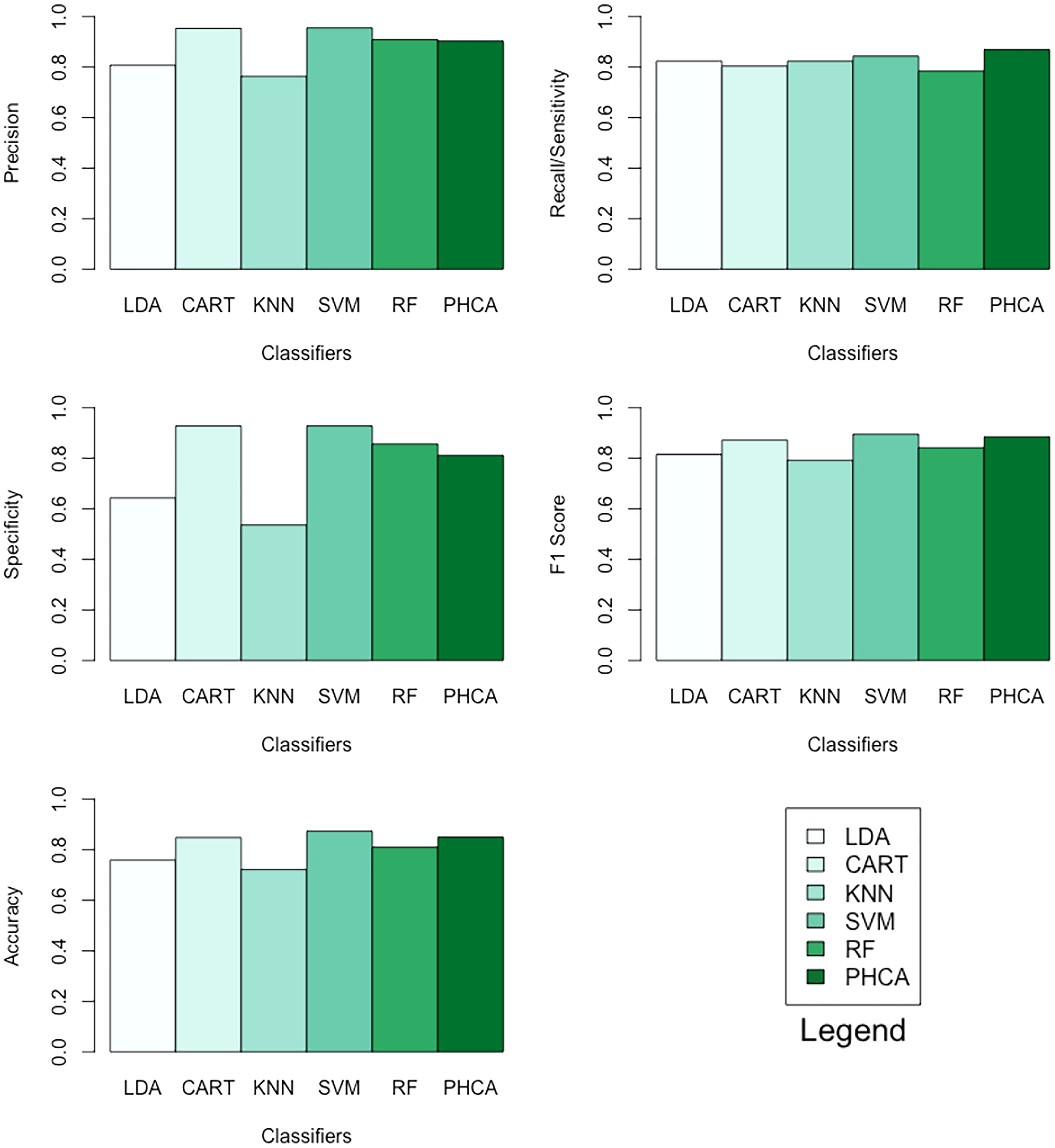
Table 7 shows the performance of PHCA and the five major classification algorithms in terms of precision, recall, specificity, F1 score, and accuracy. Barplots of these results are presented in Fig. 7. For this binary classification problem, PHCA got the highest recall at . PHCA also got the second-highest F1 score and accuracy, which are at and , respectively. The results of the Nemenyi test, which is summarized in Table 8, show that there is no significant difference between the performance of PHCA and the other classification algorithms in terms of the mean performance metrics. Moreover, the mean rank difference of 18 and the of 0.0155 between KNN and SVM shows that SVM performed significantly better than KNN.
| Classifier | Precision | Recall | Specificity | F1 Score | Accuracy |
|---|---|---|---|---|---|
| LDA | 80.77 | 82.35 | 64.28 | 81.55 | 75.95 |
| CART | 95.35 | 80.39 | 92.85 | 87.23 | 84.81 |
| KNN | 76.36 | 82.35 | 53.57 | 79.24 | 72.15 |
| SVM | 95.56 | 84.31 | 92.85 | 89.58 | 87.34 |
| RF | 90.91 | 84.31 | 85.71 | 84.21 | 81.01 |
| PHCA | 90.27 | 86.89 | 81.20 | 88.55 | 85.00 |
| Number of data points: | 400 | Number of classes: | 2 | ||
| Training set size: | 181 | Number of attributes: | 2 | ||
| Testing set size: | 119 | ||||
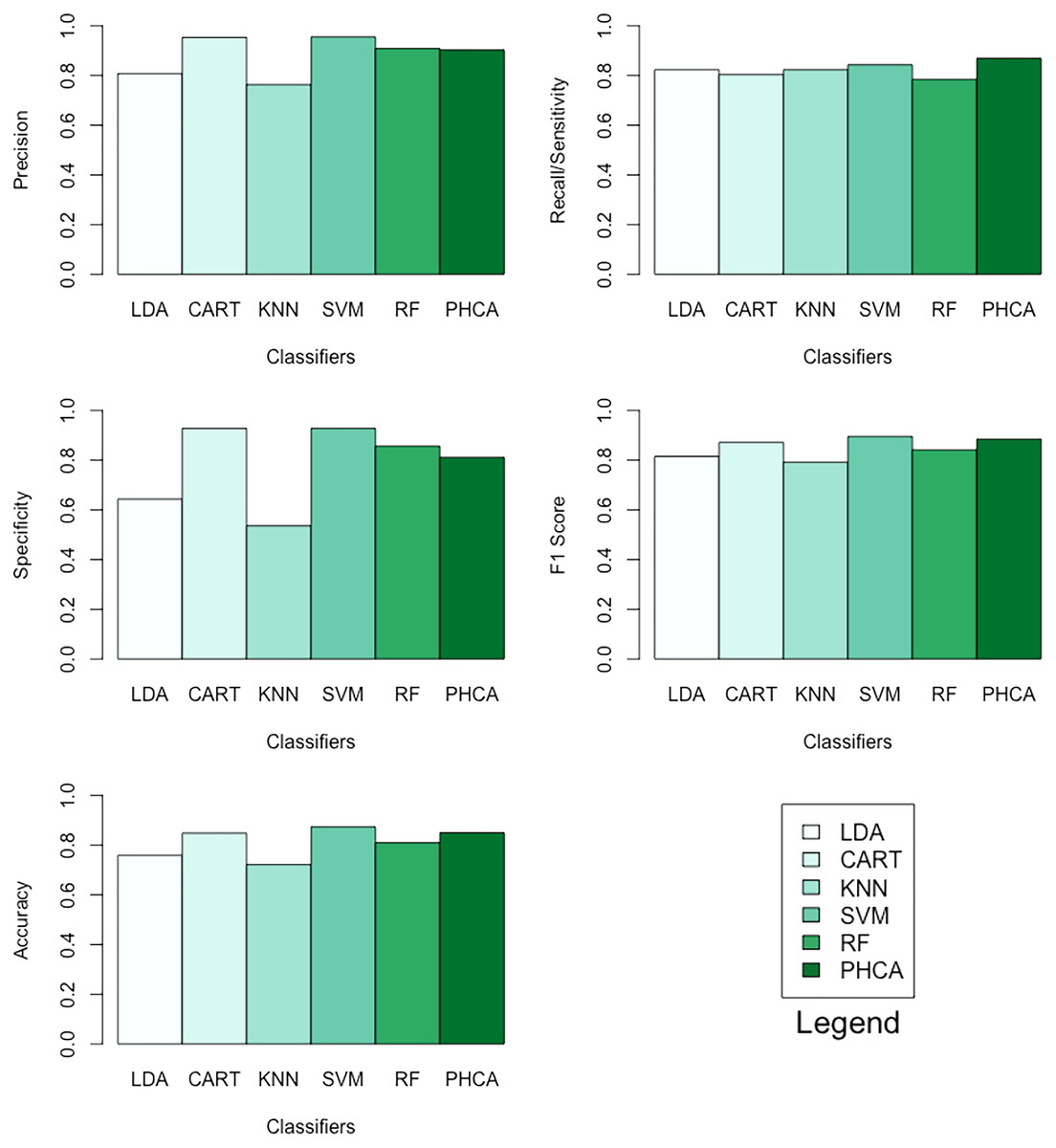
Figure 7: Barplots of performance metrics of PHCA and the five other classifiers for the social network ads dataset.
{kind=link}
| Mean rank difference | p-value | |
|---|---|---|
| CART-LDA | 12.4 | 0.2252 |
| KNN-LDA | −2.2 | 0.9988 |
| SVM-LDA | 15.8 | 0.0517 |
| RF-LDA | 7.1 | 0.7987 |
| PHCA-LDA | 11.3 | 0.3254 |
| KNN-CART | −14.6 | 0.0919 |
| SVM-CART | 3.4 | 0.9903 |
| RF-CART | −5.3 | 0.9328 |
| PHCA-CART | −1.1 | 1.0000 |
| SVM-KNN | 18.0 | 0.0155 |
| RF-KNN | 9.3 | 0.5515 |
| PHCA-KNN | 13.5 | 0.1477 |
| RF-SVM | −8.7 | 0.6234 |
| PHCA-SVM | −4.5 | 0.9661 |
| PHCA-RF | 4.2 | 0.9749 |
PHCA ranked 4th on all metrics with precision of , recall of , specificity of , F1 score of , and accuracy of . PHCA bested LDA and KNN in terms of precision, specificity, F1 score, and accuracy, and it bested CART and RF in terms of recall, F1 score, and accuracy.
Synthetic dataset
This dataset was created by uniformly sampling 200 points from each of the following figures, the circle defined by , the sphere defined by , and the torus defined by . The x, y, and coordinates of the 600 points served as the attributes, and the category was assigned according to which figure the points belong to.
Table 9 shows the performance of PHCA and the five major classification algorithms in terms of precision and recall per class. Moreover, Table 10 shows the performance of the six methods in terms of accuracy, specificity per class, and F1 score per class. Barplots of these results are presented in Fig. 8. For this synthetic dataset, PHCA and all benchmark classifiers, except LDA, got for all performance metrics considered in this study. This is consistent with the results of the Nemenyi test which are summarized in Table 11. The show that the performance of LDA is significantly different than the performance of the other algorithms, including PHCA.
| Classifier | Precision (%) | Recall (%) | ||||
|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 1 | Class 2 | Class 3 | |
| LDA | 76.92 | 96.55 | 100.00 | 100.00 | 70.00 | 97.5 |
| CART | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| KNN | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| SVM | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| RF | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| PHCA | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Classifier | Accuracy (%) | Specificity (%) | F1 score (%) | ||||
|---|---|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 1 | Class 2 | Class 3 | ||
| LDA | 89.16 | 85.00 | 98.75 | 100.00 | 86.95 | 81.15 | 98.73 |
| CART | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| KNN | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| SVM | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| RF | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| PHCA | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Number of data points: | 600 | Number of classes: | 3 | ||||
| Training set size: | 480 | Number of attributes: | 3 | ||||
| Testing set size: | 120 | ||||||
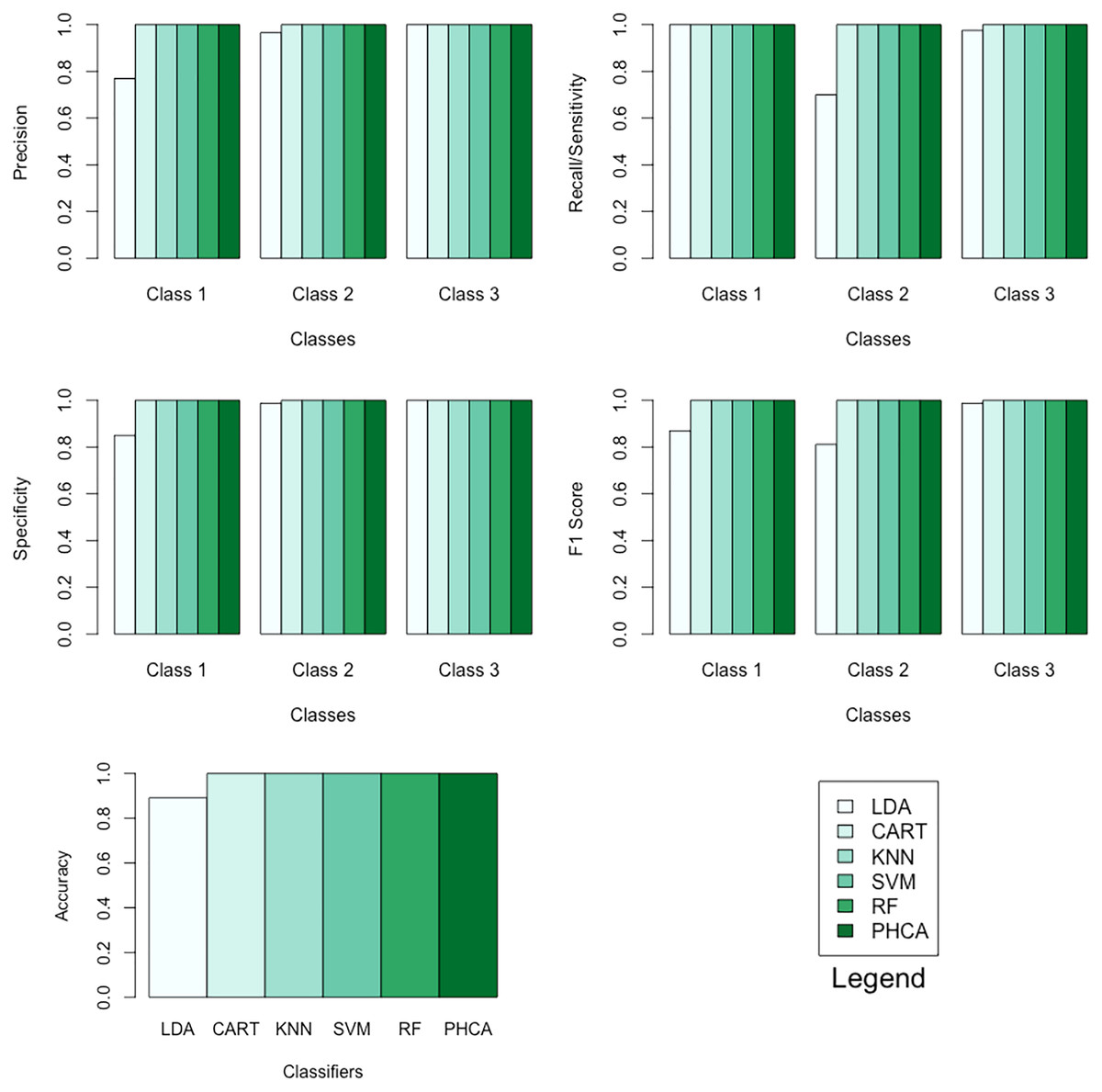
Figure 8: Barplots of performance metrics of PHCA and the five other classifiers for the synthetic dataset.
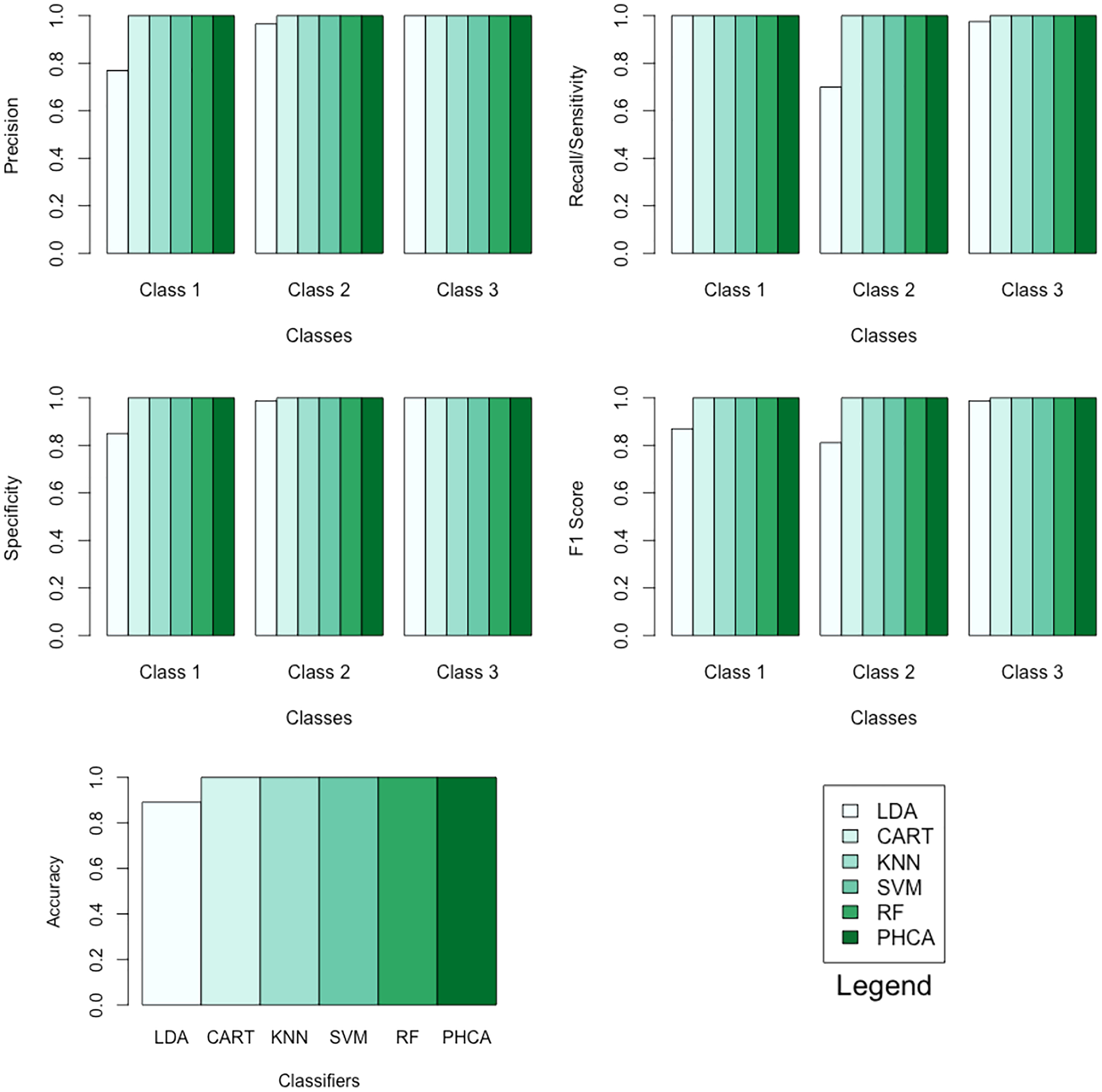{kind=link}
| Mean rank difference | p-value | |
|---|---|---|
| CART-LDA | 30 | 0.0096 |
| KNN-LDA | 30 | 0.0096 |
| SVM-LDA | 30 | 0.0096 |
| RF-LDA | 30 | 0.0096 |
| PHCA-LDA | 30 | 0.0096 |
| KNN-CART | 0 | 1.0000 |
| SVM-CART | 0 | 1.0000 |
| RF-CART | 0 | 1.0000 |
| PHCA-CART | 0 | 1.0000 |
| SVM-KNN | 0 | 1.0000 |
| RF-KNN | 0 | 1.0000 |
| PHCA-KNN | 0 | 1.0000 |
| RF-SVM | 0 | 1.0000 |
| PHCA-SVM | 0 | 1.0000 |
| PHCA-RF | 0 | 1.0000 |
MNIST database of handwritten digits
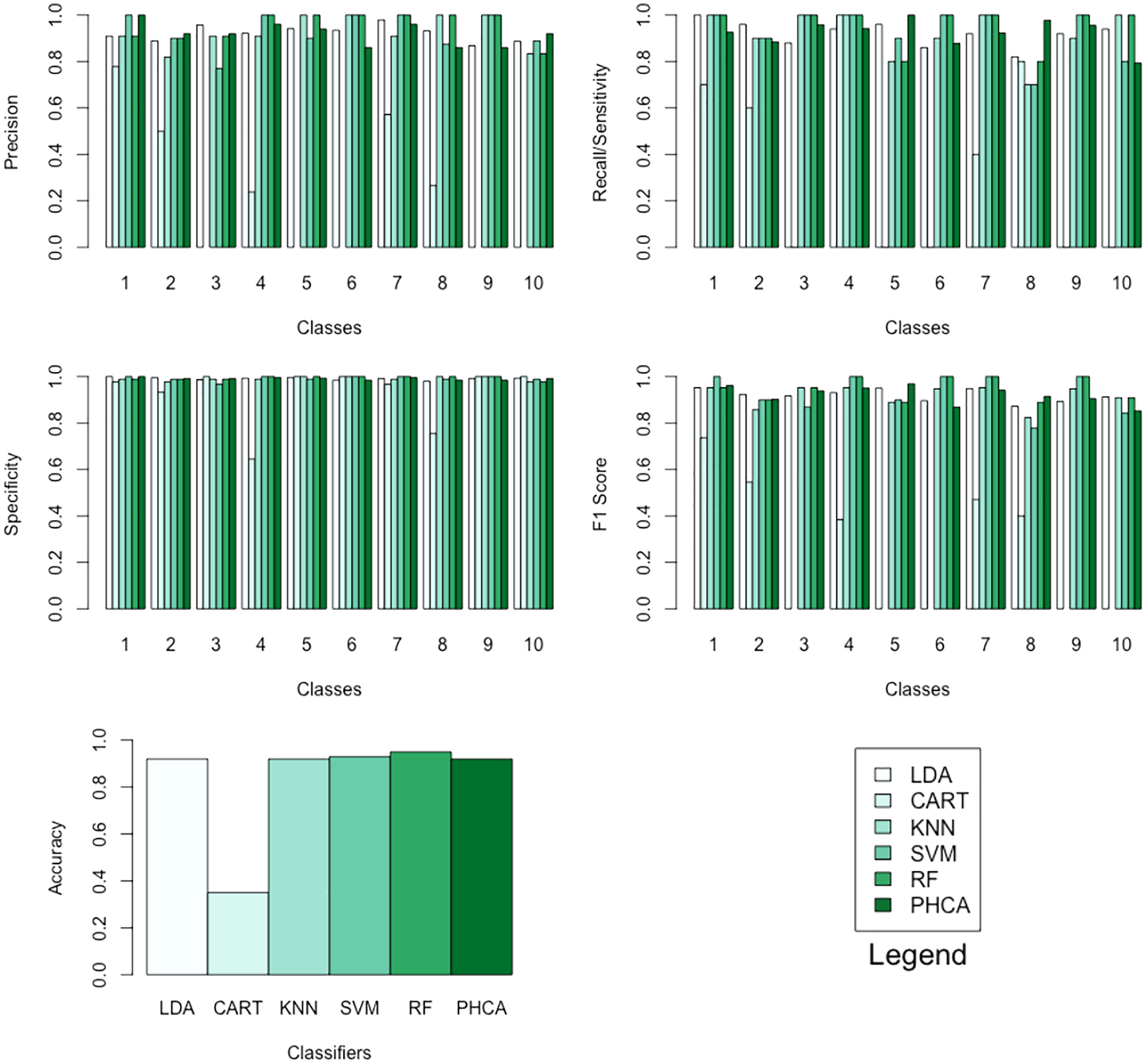
The MNIST database (Modified National Institute of Standards and Technology database (Lecun et al., 1998)) is a massive library of handwritten digits that is often used for training and testing image processing techniques. It was made by “re-mixing” samples from the original datasets from NIST. The MNIST database of handwritten digits contains 60,000 training examples and 10,000 test instances. It is a subset of a bigger set accessible from the National Institute of Standards and Technology (NIST). The digits have been centered and size-normalized in a fixed-size picture. The original NIST black and white photos were resized to fit within a 20 × 20 pixel frame while maintaining their aspect ratio. The generated photos feature grey levels as a result of the normalization algorithm’s anti-aliasing method. The images were centered in a 28 × 28 image by computing the pixel’s center of mass and translating the image to place this point in the 28 × 28 field’s center (Lecun et al., 1998). From the large MNIST database, 500 samples were chosen randomly. At each of the five-fold cross-validation runs, 400 data points served as training points, and 100 data points served as testing points. Note that for this dataset, each data point which is represented by a matrix was transformed into a vector using histogram of oriented gradients, a feature descriptor used in computer vision and image processing.
Tables 12–15 show the performance of PHCA and the five major classification algorithms in terms of precision, recall, specificity, and F1-score per class, and accuracy. Barplots of these results are presented in Fig. 9. PHCA obtained an accuracy of . It was outperformed by RF and SVM with accuracy of 95 and 93, respectively. Moreover, Table 16, which is a summary of the Nemenyi post-hoc test results, show that the performance of PHCA is not significantly different from the performance of the other classification algorithms, except from the performance of CART. The mean rank difference of 51.469709 between CART and PHCA, and the of 0.01919 show that PHCA outperformed CART significantly for the sampled MNIST data points, in terms of the mean performance metrics.
| Classifier | Precision per class (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| LDA | 90.9 | 88.9 | 95.7 | 92.2 | 94.1 | 93.5 | 97.9 | 93.2 | 86.8 | 88.7 |
| CART | 77.8 | 50.0 | NA | 23.8 | NA | NA | 57.1 | 26.7 | NA | NA |
| KNN | 90.9 | 81.8 | 90.9 | 90.9 | 100.0 | 100.0 | 90.9 | 100.0 | 100.0 | 83.3 |
| SVM | 100.0 | 90.0 | 76.9 | 100.0 | 90.0 | 100.0 | 100.0 | 87.5 | 100.0 | 88.9 |
| RF | 90.9 | 90.0 | 90.9 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 83.3 |
| PHCA | 100.0 | 92.0 | 92.0 | 96.0 | 94.0 | 86.0 | 96.0 | 86.0 | 86.0 | 92.0 |
| Classifier | Recall per class (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| LDA | 100.0 | 96.0 | 88.0 | 94.0 | 96.0 | 86.0 | 92.0 | 82.0 | 92.0 | 94.0 |
| CART | 70.0 | 60.0 | 0.0 | 100.0 | 0.0 | 0.0 | 40.0 | 80.0 | 0.0 | 0.0 |
| KNN | 100.0 | 90.0 | 100.0 | 100.0 | 80.0 | 90.0 | 100.0 | 70.0 | 90.0 | 100.0 |
| SVM | 100.0 | 90.0 | 100.0 | 100.0 | 90.0 | 100.0 | 100.0 | 70.0 | 100.0 | 80.0 |
| RF | 100.0 | 90.0 | 100.0 | 100.0 | 80.0 | 100.0 | 100.0 | 80.0 | 100.0 | 100.0 |
| PHCA | 92.6 | 88.5 | 95.8 | 84.1 | 100.0 | 87.8 | 92.3 | 97.7 | 95.6 | 79.3 |
| Classifier | Specificity per class (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| LDA | 100.0 | 99.6 | 98.7 | 99.3 | 99.6 | 98.5 | 99.1 | 98.0 | 99.1 | 99.3 |
| CART | 97.8 | 93.3 | 100.0 | 64.4 | 100.0 | 100.0 | 96.7 | 75.6 | 100.0 | 100.0 |
| KNN | 98.9 | 97.8 | 98.9 | 98.9 | 100.0 | 100.0 | 98.9 | 100.0 | 100.0 | 97.8 |
| SVM | 100.0 | 98.9 | 96.7 | 100.0 | 98.9 | 100.0 | 100.0 | 98.9 | 100.0 | 98.9 |
| RF | 98.9 | 98.9 | 98.9 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 97.8 |
| PHCA | 100.0 | 99.1 | 99.1 | 99.6 | 99.3 | 98.5 | 99.6 | 98.5 | 98.5 | 99.1 |
| Classifier | Acc (%) | F1 score per class (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| LDA | 92.0 | 95.2 | 92.3 | 91.7 | 93.1 | 95.0 | 89.6 | 94.8 | 87.2 | 89.3 | 91.2 |
| CART | 35.0 | 73.7 | 54.5 | NA | 38.5 | NA | NA | 47.1 | 40.0 | NA | NA |
| KNN | 92.0 | 95.2 | 85.7 | 95.2 | 95.2 | 88.9 | 94.7 | 95.2 | 82.4 | 94.7 | 90.9 |
| SVM | 93.0 | 100.0 | 90.0 | 87.0 | 100.0 | 90.0 | 100.0 | 100.0 | 77.8 | 100.0 | 84.2 |
| RF | 95.0 | 95.2 | 90.0 | 95.2 | 100.0 | 88.9 | 100.0 | 100.0 | 88.9 | 100.0 | 90.9 |
| PHCA | 92.0 | 96.2 | 90.2 | 93.9 | 95.0 | 96.9 | 86.9 | 94.1 | 91.5 | 90.5 | 85.2 |
| Number of data points: | 500 | Number of classes: | 10 | ||||||||
| Training set size: | 400 | Number of attributes: | 2,025 | ||||||||
| Testing set size: | 100 | ||||||||||
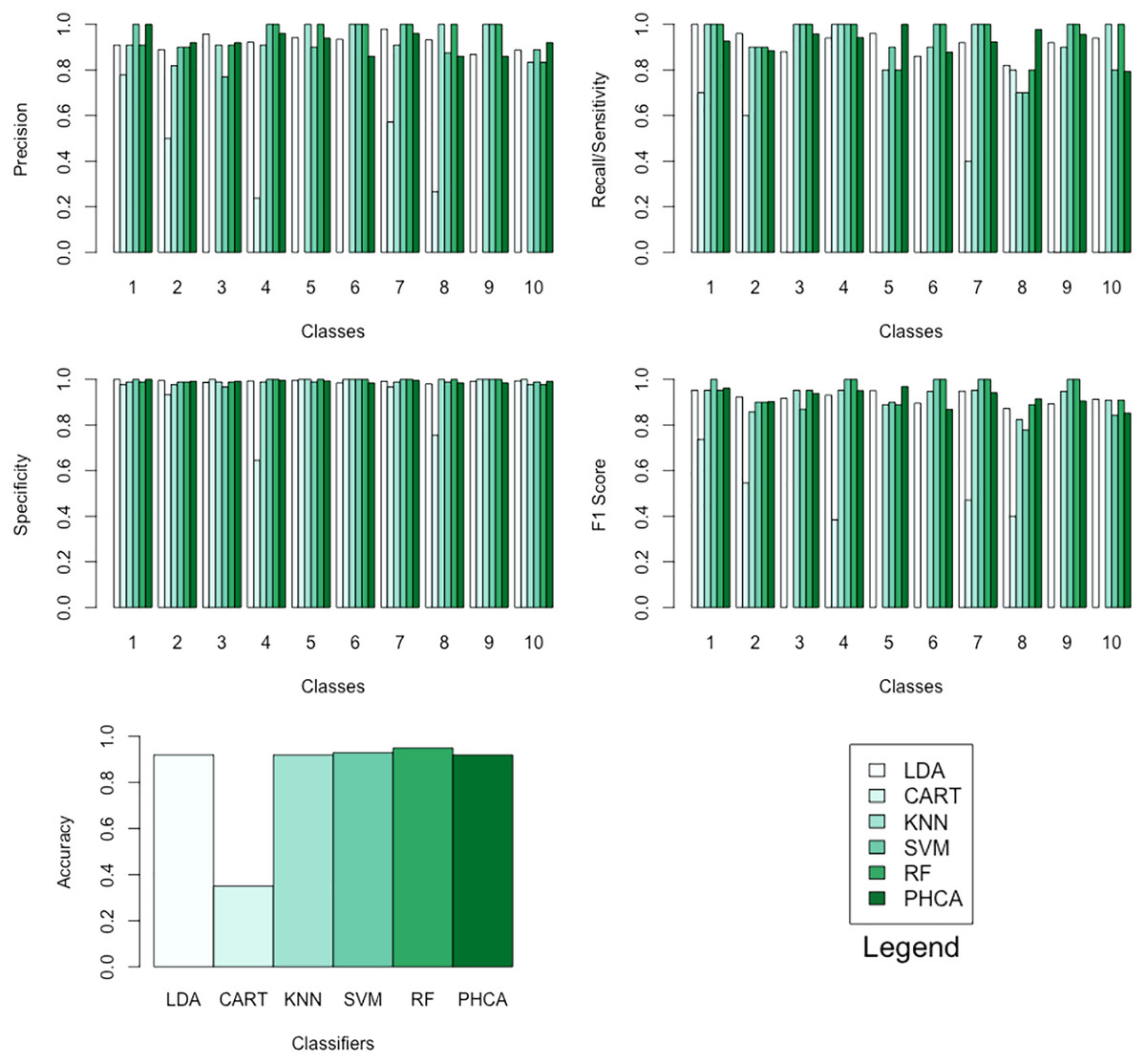
Figure 9: Barplots of performance metrics of PHCA and the five other classifiers for the MNIST dataset.
{kind=link}
| Mean rank difference | p-value | |
|---|---|---|
| CART-LDA | −48.59166 | 0.03322 |
| KNN-LDA | 16.54878 | 0.88258 |
| SVM-LDA | 32.07317 | 0.27317 |
| RF-LDA | 43.57317 | 0.04462 |
| PHCA-LDA | 2.87805 | 0.99997 |
| KNN-CART | 65.14044 | 0.00086 |
| SVM-CART | 80.66483 | 1.0e−05 |
| RF-CART | 92.16483 | 2.1e−07 |
| PHCA-CART | 51.46971 | 0.01919 |
| SVM-KNN | 15.52439 | 0.90814 |
| RF-KNN | 27.02439 | 0.47074 |
| PHCA-KNN | −13.67073 | 0.94496 |
| RF-SVM | 11.50000 | 0.97367 |
| PHCA-SVM | −29.19512 | 0.37988 |
| PHCA-RF | −40.69512 | 0.07541 |
The five validation experiments exhibit that the proposed classifier, PHCA, can be used to solve binary or multi-class classification problems, classification problems involving points from the -dimensional euclidean space or image data, classical or synthetic datasets, and datasets whose number of features ranges from two to the thousands. Moreover, the performance of PHCA has no significant difference form the performance of the benchmark classifiers, except for a few instances where a benchmark classification algorithm performed significantly poorer than the performance of PHCA.
These validation results do not imply that PHCA is better than any of the other major classification algorithms. However, these results illustrate the no-free lunch theorem, which implies that no learning algorithm works best on all given problems. Moreover, these results suggest that PHCA can be at par or even better than some classifiers in solving some particular classification problems.
What sets PHCA apart from the well-known machine learning classifiers is that it is non-parametric, but at the same time a linear classifier. It is a non-parametric algorithm in the sense that it does not restrict the data to follow a particular distribution, nor fix the number of datasets’ parameters for the algorithm to work.
Conclusions
The main contribution of this study was the development of PHCA, a non-parametric but linear classifier which utilizes persistent homology, a major and very powerful TDA tool. PHCA was applied in solving four different classification problems with varying sizes, number of classes, and number of attributes. For the four classification problems, the performance of PHCA was measured and compared to the performance of LDA, CART, KNN, SVM, and RF, in terms of precision, recall, specificity, accuracy, and F1 score. A five-fold cross-validation was used in all validation runs. PHCA performed impressively in each of the four classification problems. PHCA ranked either second or third in the first three datasets in almost all metrics; although it ranked 5th in the synthetic dataset, it obtained an accuracy of 99.16%. Additionally, all the classifiers, except for PHCA, ranked last in terms of accuracy and F1 scores in at least one of the four classification problems. In conclusion, the validation results show that PHCA can perform well, or even better, than some of the widely used machine learning classifiers in solving classification problems. Moreover, this study does not imply that PHCA works better than other machine learning algorithms, but this shows that PHCA can work in solving some classification problems.
The validation of PHCA in this study was limited to relatively small problems which are restricted by the computers used in this study. PHCA can be further validated by considering larger problems and by using more powerful computers which can solve problems involving datasets with higher dimensions. Furthermore, some improvements that can be imposed on the proposed classification algorithm in this study is by considering other topological signatures or by considering PH representations other than persistence diagrams, such as persistence landscapes. Recent advancements and modifications on the computation of persistent homology may also be implemented to possibly improve the performance of PHCA. Validation of the proposed algorithm were implemented in R using TDA package and GUDHI library in solving persistent homology of data. It should be noted that there are other platforms and solvers which can be used, like JavaPlex, Perseus, Dipha, Dionysus, jHoles, Rivet, Ripser, and PHAT, which offer some variations in the way PH can be computed. Indeed, this study has opened many of research opportunities which can be explored by mathematicians, data scientists, and computer programmers.