
A novel autoencoder approach to feature extraction with linear separability for high-dimensional data
- Published
- Accepted
- Received
- Academic Editor
- Carlos Fernandez-Lozano
- Subject Areas
- Data Mining and Machine Learning, Neural Networks
- Keywords
- Autoencoder, Distance metric, Feature extraction
- Copyright
- © 2022 Zheng et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2022. A novel autoencoder approach to feature extraction with linear separability for high-dimensional data. PeerJ Computer Science 8:e1061 https://doi.org/10.7717/peerj-cs.1061
Abstract
Feature extraction often needs to rely on sufficient information of the input data, however, the distribution of the data upon a high-dimensional space is too sparse to provide sufficient information for feature extraction. Furthermore, high dimensionality of the data also creates trouble for the searching of those features scattered in subspaces. As such, it is a tricky task for feature extraction from the data upon a high-dimensional space. To address this issue, this article proposes a novel autoencoder method using Mahalanobis distance metric of rescaling transformation. The key idea of the method is that by implementing Mahalanobis distance metric of rescaling transformation, the difference between the reconstructed distribution and the original distribution can be reduced, so as to improve the ability of feature extraction to the autoencoder. Results show that the proposed approach wins the state-of-the-art methods in terms of both the accuracy of feature extraction and the linear separabilities of the extracted features. We indicate that distance metric-based methods are more suitable for extracting those features with linear separabilities from high-dimensional data than feature selection-based methods. In a high-dimensional space, evaluating feature similarity is relatively easier than evaluating feature importance, so that distance metric methods by evaluating feature similarity gain advantages over feature selection methods by assessing feature importance for feature extraction, while evaluating feature importance is more computationally efficient than evaluating feature similarity.
Introduction
High-dimensional data usually contains rich features, through extracting the important features, those irrelevant attributes in high-dimensional data can be filtered, thereby achieving data dimensionality reduction (Xue, Zhang & Browne, 2015). Hence, feature extraction is considered to be one of the important methods for data dimension reduction (Bo, Kay & He, 2016).
Feature extraction is a hot topic in recent years, aiming to gain the most valuable features from the input data (Tao, Hou & Nie, 2016; Luo, Nie & Chang, 2018). High dimensionality of data, the so-called the curse of dimensionality, brings negative effects for feature extraction (Gui, Sun & Ji, 2018; Chakraborty & Pal, 2015). Upon a low-dimensional space, those relations between the data are relatively compact but they may become sparse upon a high-dimensional space (Bing, Liao & Zhou, 2021), e.g., the data space with more than 10 dimensionalities (Zhou, Kumar & Hou, 2011). Clearly, sparse relations between data are usually considered to be an unfavorite factor for feature extraction since feature extraction needs to rely on the relations between data (Bo, Wan & Bi, 2021). Beyond that, those latent features scattered in subspaces inside a high-dimensional space not only inspect the ability of methods to extract features (Wang, Wang & Chang, 2016), but also test their extraction efficiency. Hence, it is a challenge for feature extraction from high-dimensional data.
Recently, some opinions have been proposed for feature extraction, for instance, distance metric-based methods, where, the typical representative is the well-known Mahalanobis distance-based methods, which evaluates the similarity between samples using the covariance matrix of data (De Maesschalck, Jouan-Rimbaud & Massart, 2000). Furthermore, Ying, Wen & Shi (2018) proposed the intrinsic semi-supervised metric learning (ISSML) based on a distance metric for feature extraction. Similarly, the methods implemented in (Zadeh, Hosseini & Sra, 2016; Luo, 2017) also applied distance metrics. Certainly, also including, the information-theoretic metric learning is (ITML) (Mei, Liu & Karimi, 2014) employed a distance metric to obtain features. These methods (Ying, Wen & Shi, 2018; Zadeh, Hosseini & Sra, 2016; Luo, 2017; Mei, Liu & Karimi, 2014) address the issues of symmetric positive-definite matrix minimization during feature extraction, but there are several problems in them, (1) since most of them use iterative calculation while performing feature selection, optimization issues have to be addressed iteratively. (2) Most of them need to rely on parameter selection to obtain those desired features. Usually, feature selection-based methods are also considered to be used for feature extraction. Such methods achieve feature extraction through analyzing the information of feature subsets, for example, the cheap feature selection method based on k-means algorithm (Marco, Pérez & Lozano, 2021) selects the m features with the highest relevance measure through obtaining a clustering for each subset of features. Although the method (Marco, Pérez & Lozano, 2021) is a novel measurement for feature relevance, which is beneficial for feature selection, however, calculating per subset of features needs to spend a lot time cost. In order to reduce the correlation between features, some measurements for quickly assessing features are proposed, e.g., the information entropy metric (Pham, Siarry & Oulhadj, 2019), whereas the method (Pham, Siarry & Oulhadj, 2019) has a bias toward features, which may result in appearing selecting deviation during feature extraction. Another kind of feature selection method depends on eigen decomposition, such as, locally linear embedding (LLE) (Hettiarachchi & Peters, 2015; Akpudo & Hur, 2020), multi-manifold discriminant isometric feature mapping (MMD-ISOMAP) (Bo, Xiang & Zhang, 2016), ISOMAP-KL (Neto & Levada, 2020), however, they cannot assess the importance of the features in the background space explicitly.
Neural network-based methods are favored because of excellent feature capture ability (Qu, Zheng & Tang, 2022), e.g., Multilayer Perceptron Neural Network (Sun, Huang & Wong, 2017). For dimension reduction, feature extraction and data compression, autoencoder-based networks provide an interpretable approach for the unknown meaningful insights (Ang, Mirzal & Haron, 2016) by learning non-identity mapping functions (Zheng et al., 2022), for instance, Al-Hmouz, Pedrycz & Balamash (2022) developed interpretable data representation for data dimensionality reduction using logic-oriented and granular logic autoencoders, and such as, autoencoder (Majumdar, 2019) for image compression, and blind denoising autoencoder (Yang, Herranz & Van de Weijer, 2020) for denoising. In addition, sparse autoencoders are used as an unsupervised feature extractor to serve data dimensionality reduction, feature extraction and data mining (Wan, He & Tang, 2018), e.g., Chen, Hu & He (2018) proposed sparse autoencoder (SAE) for feature extraction of ferroresonance overvoltage waveforms in power distribution systems. Yan & Han (2018) used stacked sparse autoencoder (SSAE) to extract effective features. In addition, the autoencoders (Qu et al., 2021; Qu, Zheng & Tang, 2022; Zheng et al., 2022) also successfully capture the low-dimensional features from high-dimensional data, however, these captured low-dimensional features do not show good linear separability. In terms of addressing high-dimensional complex problems, deep methods are the state-of-the-art solution in many disciplines (Abadía-Heredia et al., 2022), e.g., video and language processing, etc.
In this study, our motivation is to extract the features with linear separabilities from the data in a high-dimensional space. Thus, we proposed a novel autoencoder method based on Mahalanobis distance metric of rescaling transformation. The proposed method does not have to address any optimization issue, and also it can focus on the whole data distribution.
We summarize the main contributions of this work as follows:
(i) Distance metric-based methods are more suitable for extracting those features with linear separabilities from high-dimensional data than feature selection-based methods.
(ii) Assessing feature similarity in a high-dimensional space is relatively easier than evaluating feature importance, therefore, distance metric approaches by evaluating feature similarity have more advantages than feature selection approaches by evaluating feature importance in terms of feature extraction.
(iii) The computational time of distance metric-based algorithms is higher than that of feature selection-based algorithms upon a high-dimensional space.
This paper is organized as follows. Section 2 describes the proposed method and implements the proposed model, including training for the model and parameter configuration. Experiment datasets, competing methods, and experiment description are given in Section 3. Section 4 presents experiment results. Section 5 draws conclusions.
Methods
Theory
Given a sample X ={xi — 1 ≤ i ≤ N}, and X⊆ℜd.ℜd is the d-dimensional Euclidean space. P is the probability distribution of X, denoted as original probability distribution. u(X) and Γx are the mean vector and the covariance matrix of X, respectively. Let us assume that Z ={ zj — 1 ≤ j ≤ N} is the reconstructed X, and Z⊆ℜd. Q is the probability distribution of Z, denoted as approximate probability distribution. Similar, u( Z) and Γzare the mean vector and the covariance matrix of Z, respectively. The K–L divergence (Tao et al., 2009) between the two distributions P and Q is given in Eq. (1). (1) where |Γ| = det(Γ). The tr(⋅) is the trace of a matrix. Dxz = (u(X) − u(Z))(u(X) − u(Z))T is a symmetrical matrix. Training a distance metric is equivalent to finding a rescaling of a sample which replaces each xi with MT xi (Feng, Wang & Jin, 2019), so the K-L divergence in Eq. (1) can be converted into Eq. (2), having (2) where M is a metric matrix and satisfies A∗ = MMT, and M ∈ ℜd×d0, d0 ≤ d. The K-L divergence in Eq. (2) is the rescaling transformation for the K-L divergence in Eq. (1) using the distance metric matrix A *. To reduce the difference between the approximate distribution Q and the original distribution P, we consider Mahalanobis distance metric for K-L divergence in Eq. (2), having (3) dA∗(xi, zj) is Mahalanobis distance between xi and zj using A *. The advantage of doing this is that the Mahalanobis distance using A * can appropriately measure similarities between the input sample and the reconstructed input sample because of non-negativity (i.e., dA∗(xi, zj) ≥ 0), distinguishability (i.e., dA∗(xi, zj) = 0⇔xi = zj) and symmetry (i.e., dA∗(xi, zj) = dA∗(zj, xi)) (Feng, Wang & Jin, 2019). Equation (4) gives the calculation of dA∗(xi, zj), where A * can be decomposed as A∗ = MMT. (4)
Model implementation
A classic auto encoder (AE) consists of an input layer, a hidden-layer and an output layer. For AE, the loss error is often measured by using the distance between the original input instance, the predicted instances, and the reconstructed instance (Theis, Shi & Cunningham, 2017). Typically, using divergence metrics or expanding autoencoder structures (e.g., enlarging the number of hidden layers) is more helpful for autoencoders to characterize the data distribution and to learn the desired representations (Lu, Cheng & Xiao, 2017). As such, we designed an autoencoder with multiple-hidden layers, namely m-AE, and m ≥1, as shown in Fig. 1. In addition, the K–L divergence in Eq. (3) was used to increase the ability of m-AE to capture low-dimensional feature representations. The loss error ∇KL(w, b) in m-AE is given as follows: (5) where eX, eZ are the inputting and the reconstructed inputting, respectively. ∇KL(w, b) isupdated through using the backpropagation manner.
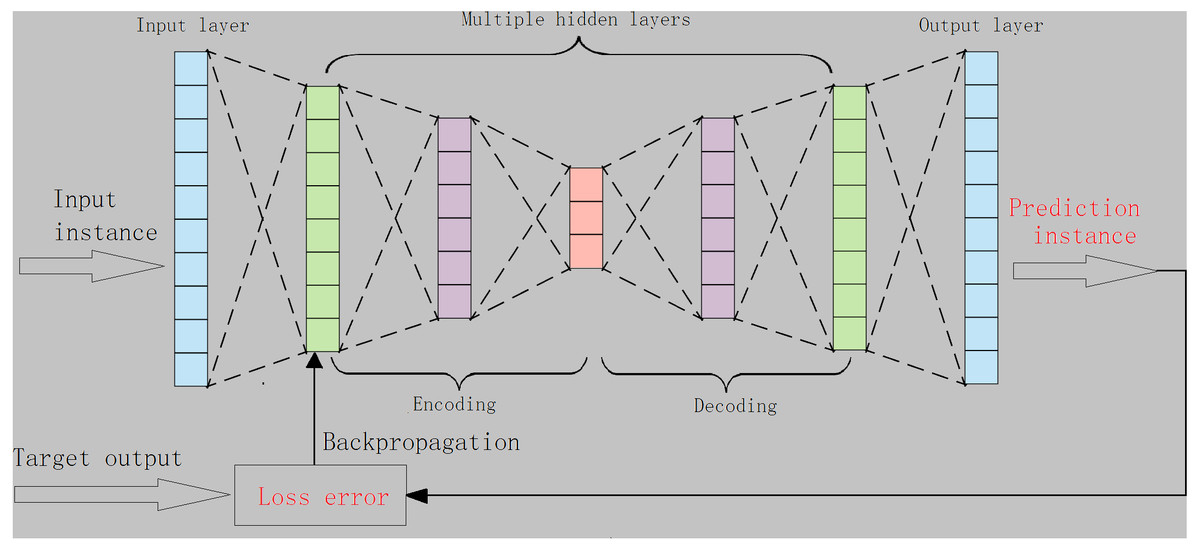
Figure 1: The structure of the proposed m-AE.
{kind=link}
To better train the proposed model, we carefully studied part hyper parameters in the model. For the rest of hyper parameters, their default values were used.
(i) Optimizer. Common optimizers are Adam, RMSprop, SGD, Momentum, Nesterov, etc. However, we selected Adam as the optimizer of m-AE, since Adam has the ability to handle sparse gradients (Kingma & Ba, 2015). Compared with other optimizers, Adam is more suitable for high-dimensional data. Moreover, Adam can provide different adaptive learning rates for different hyper parameters.
(ii) Activation function. Gradient vanishing is easily to be induced during passing gradients backwards for neural networks, in this case, the probability of gradient vanishing caused by activation function Sigmoid is relatively high. Similar to Sigmoid, activation function tanh also suffers from this problem. While for activation function ReLu, the phenomenon of gradient vanishing is partially alleviated, meaning that gradient vanishing does not appear in the positive interval of ReLu. Furthermore, ReLu converges much faster than Sigmoid and Tanh. Therefore, we chose ReLu as the activation function of m-AE.
(iii) Iteration epoch. We dynamically adjust the iteration epoch according to training accuracy. For instance, when training accuracy starts to change from large to small, we reduce iteration epoch in order to prevent over-fitting. When the difference in accuracy between training and testing is minimal, the current iteration epoch can be accepted and training procedure is stopped.
We give the training algorithm for m-AE in Algorithm 1. In the algorithm, the training set Train_set is divided into two datasets TCro_train, TCro_val in step 1. Since m-AE has multiple hidden layers, we set m in the range of Om, in order to determine the m, the dataset TCro_train is used to train m-AE. The data set TCro_val is used for the validation of the network structure of m-AE. To get the optimal m, denoted as mopt, the cross-validation is implemented in step 2 to step 18, where the procedure of step 6 and step 10 describes the calculation process of loss error ∇KL(w, b). After gaining the optimal m, m-AE is trained using the training set Train_set. Using backpropagation manner updates network parameters until m-AE can converge, as shown in step 18 to step 28. The procedure shown in step 29 to step 33 indicates that the maximum training accuracy Train_acc are outputted and the well trained m-AE is saved.
Algorithm 1. Training for m-AE.
Input: Training set Train_set, A∗ = I ∈ ℜd×d is an identity matrix, iteration epoch T, L, parameter Om.
Output: Training accuracy Train_acc.
Begin
1. Train_set is divided into TCro_train, TCro_val;
2. for t =1 to T do:
3. foreach m in Om:
4. Decompose A * as satisfying A∗ = MMT using eigen decomposition.
5. Calculate loss error ∇KL(w, b) using Eq. (5) and the procedure is summarized as following:
6. The procedure:
7. Calculate using Eq. (2).
8. Calculate dA∗(xi, zj) using Eq. (4).
9. Take and dA∗(xi, zj) into Eq. (3) to calculate K − L(dA∗).
10. For any xi, xj, calculate ∇KL(w, b) using Eq. (5).
11. Calculate training accuracy T_acc = m − AE(TCro_train; m; t);
12. Validate m-AE using data set TCro_val;
13. Calculate validation accuracy V_acc = m − AE(TCro_val; m; t)
14. Update weight w←w + ∇w.
15. Update A * as MMT.
16. Until A * and hyper parameters converge.
17. end foreach
18. end for
19. Get the optimal value of m, i.e., mopt = arg max(V_acc);
20. for l =1 to L do:
21. Decompose A * as satisfying A∗ = MMT using eigen decomposition.
22. Train m-AE using training set Train_set and mopt;
23. Update network parameters using the optimizer Adam;
24. Calculate loss error ∇KL(w, b) using Eq. (5);
25. Calculate training accuracy Training_acc(l) = m − AE(Train_set; mopt);
26. Update A * as MMT;
27. Using backpropagation manner updates network parameters;
28. end for
29. Select the l so that lmax =arg max(Training_acc(l));
30. Get the maximum training accuracy Train_acc in the lmax-th iteration;
31. Train_acc =m-AE(Train_set; mopt, lmax);
32. Output Train_acc
33. Save the well trained m-AE(Train_set; mopt, lmax);
End
Experments
Datasets and assessment metrics
To verify the performance of the proposed m-AE, we selected four benchmark datasets with different data dimensions from the UCI machine learning repository (Blake & Merz, 1998). The attributes of the four benchmark datasets are summarized in Table 1.
Receiver operating characteristic curve (ROC) and corresponding area under curve (AUC) are usually used to assess the precision of machine learning methods. Therefore, AUC is taken as the assessment metric of method precision.
Competing and benchmark methods
Since m-AE applies the distance metric of rescaling transformation, the methods based on a distance metric were used for comparisons, including ISSML (Ying, Wen & Shi, 2018) and ITML (Mei, Liu & Karimi, 2014). Certainly, the method based on feature selection was also considered, i.e., MMD-ISOMAP (Bo, Xiang & Zhang, 2016). In addition, autoencoder-based approaches were used as a comparison, e.g., the SAE (Chen, Hu & He, 2018). Furthermore, to further examine the effects of the distance metric of rescaling transformation on the performance of m-AE, a benchmark model was developed with m-AE as a reference. The developed benchmark model used the same structure and parameter configuration of m-AE without using the distance metric of rescaling transformation, namely AE-BK.
| Dataset | Data volume | Data dimensionality | features |
|---|---|---|---|
| Iris | 150 | 4 | 3 |
| Primary | 339 | 17 | 2 |
| Hepatitis | 155 | 19 | 2 |
| Dermatology | 366 | 33 | 6 |
We implemented the corresponding algorithms of the six models using Python on Tensorflow framework. While for those parameters of competing methods, we adopted those values observed in the corresponding literature. Certainly, unless otherwise stated, the five corresponding algorithms all run on the same GPU and apply the same experimental configuration settings.
Experiment description
Experiments were conducted on the four benchmark datasets in order to validate the ability of these six models to extract features and their efficiency.
Experiment I. To test the robustness of m-AE. The proposed m-AE has multiple hidden layers, since the number of hidden layers (i.e., the m) significantly affects the precision of feature extraction, the m needs to be firstly verified, i.e., robustness testing of the model, let m set in the range of {1, 2, 3, 4, 5, 7, 10, 15, 20}.
Experiment II. To test the ability of feature extraction for the six models. The six models were run on the four benchmark datasets, and then the testing results were analyzed.
Experiment III. To compare the efficiency of our method with competing methods. These methods were performed on four benchmark datasets and observed their running time.
Ablation experiments. To verify that using the distance metric of rescaling transformation can be beneficial for extracting linearly separable features, the ablation experiments were also designed.
In addition, to eliminate randomness during the experiment and present an objective result, we used cross-validation to verify the six models. We randomly selected two datasets from the four benchmark datasets as the training set to train the six models. Once the six models were well trained, they were tested on the four benchmark datasets, respectively. The process was repeated five times, independently, then we took the average of five testing results was as a measurement.
Results
Experiments on robustness
Results in Fig. 2 show that the performance of the proposed m-AE and the benchmark model AE-BK improves along with increasing of m, and then the performance remains stable when m reaches a certain size, i.e., m = 3. This means that m-AE and AE-BK are not sensitive to large m on the four benchmark datasets, i.e., their network structures are robust within a reasonable range. Therefore, let m be equal to three in subsequent experiments.
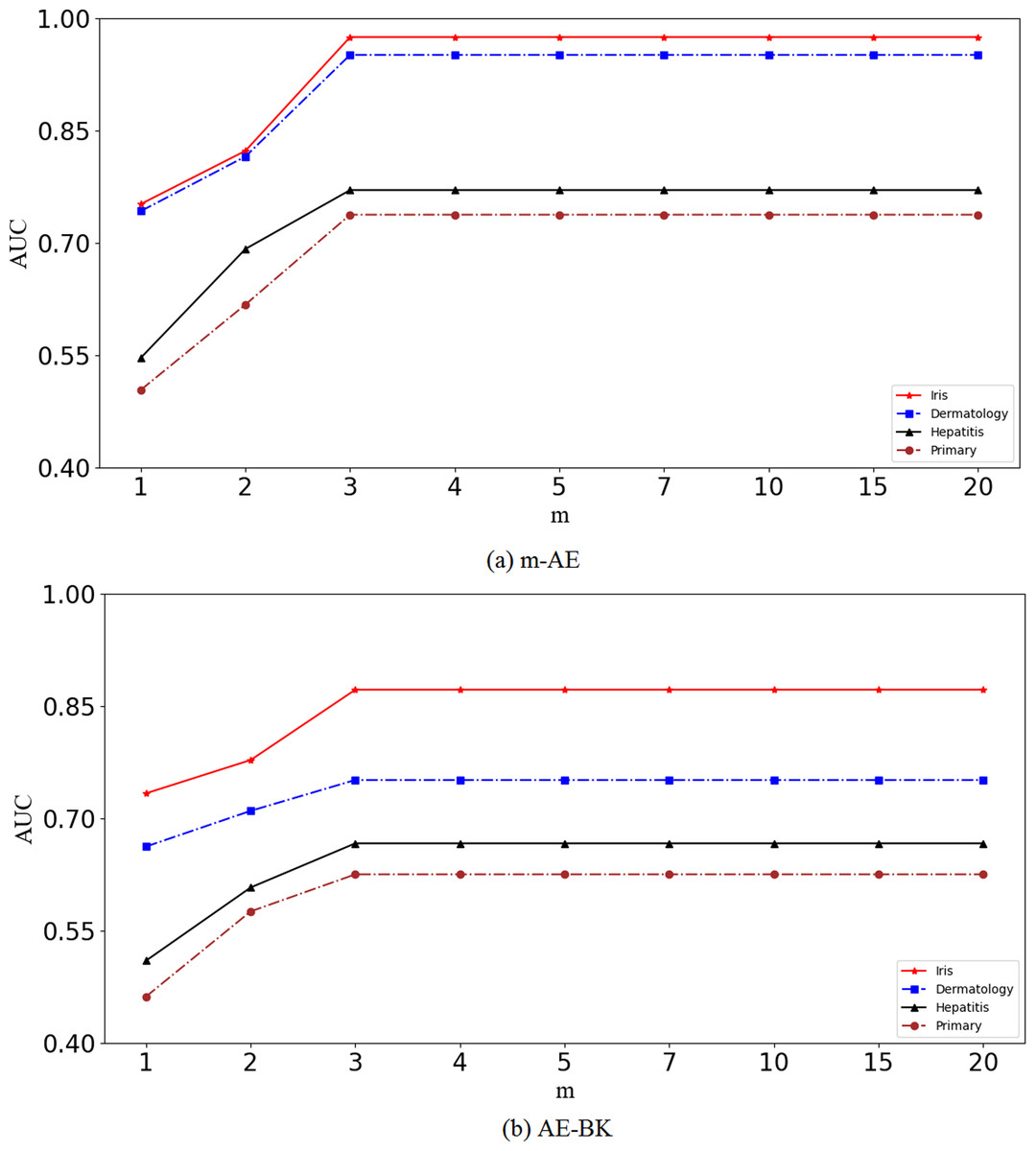
Figure 2: Validation of robustness.
{kind=link}
Comparisons of accuracy extraction
Results in Table 2 show that the proposed m-AE wins the four competing models and the benchmark model in the accuracy of feature extraction on all considered instances. For competitors, ISSML, ITML and SAE outperform MMD-ISOMAP in most benchmark datasets for the extracted accuracy.
Comparisons of linear separability
The results of ablation experiments in Fig. 3A show that compared with the models without using distance metrics, e.g., AE-BK, SAE, the models using distance metrics (including m-AE, ISSML, ITML) perform much better on most datasets in the extracted accuracy of the features with linear separabilities. Similar, the models using distance metrics also win the model using feature selection, as shown in Fig. 3B. To observe the linear separabilities of the extracted features from the four benchmark datasets, we projected these extracted features onto two-dimensional space, and then visualized them. Figure 4 displays the results of visualized distribution on the four benchmark datasets by the six models. The visualized results show that it is optimal for the separation distance between different types of features extracted by m-AE, meaning that compared with competing and benchmark models, m-AE is a winner in terms of the linear separabilities of the extracted features. Together, these results imply that distance metric-based methods have advantages over feature selection-based methods in terms of extracting the features with linear separabilities.
| Iris | Dermatology | Hepatitis | Primary | |
|---|---|---|---|---|
| m-AE (√) | 0.9744± 0.0157 | 0.9506± 0.0137 | 0.7703± 0.0753 | 0.7375± 0.0534 |
| ISSML (√) | 0.9402 ± 0.0154 | 0.8931 ± 0.0284 | 0.7131 ± 0.0642 | 0.6886 ± 0.0865 |
| ITML (√) | 0.9488 ± 0.0120 | 0.9374 ± 0.0246 | 0.7457 ± 0.0622 | 0.6816 ± 0.0745 |
| MMD-ISOMAP (≠) | 0.9247 ± 0.0053 | 0.7680 ± 0.0377 | 0.6897 ± 0.0657 | 0.6664 ± 0.0733 |
| SAE (×) | 0.9571 ± 0.0227 | 0.8707 ± 0.0892 | 0.6773 ± 0.0373 | 0.6700 ± 0.0166 |
| AE-BK (×) | 0.8715 ± 0.1533 | 0.7511 ± 0.0099 | 0.6666 ± 0.0771 | 0.6252 ± 0.1052 |
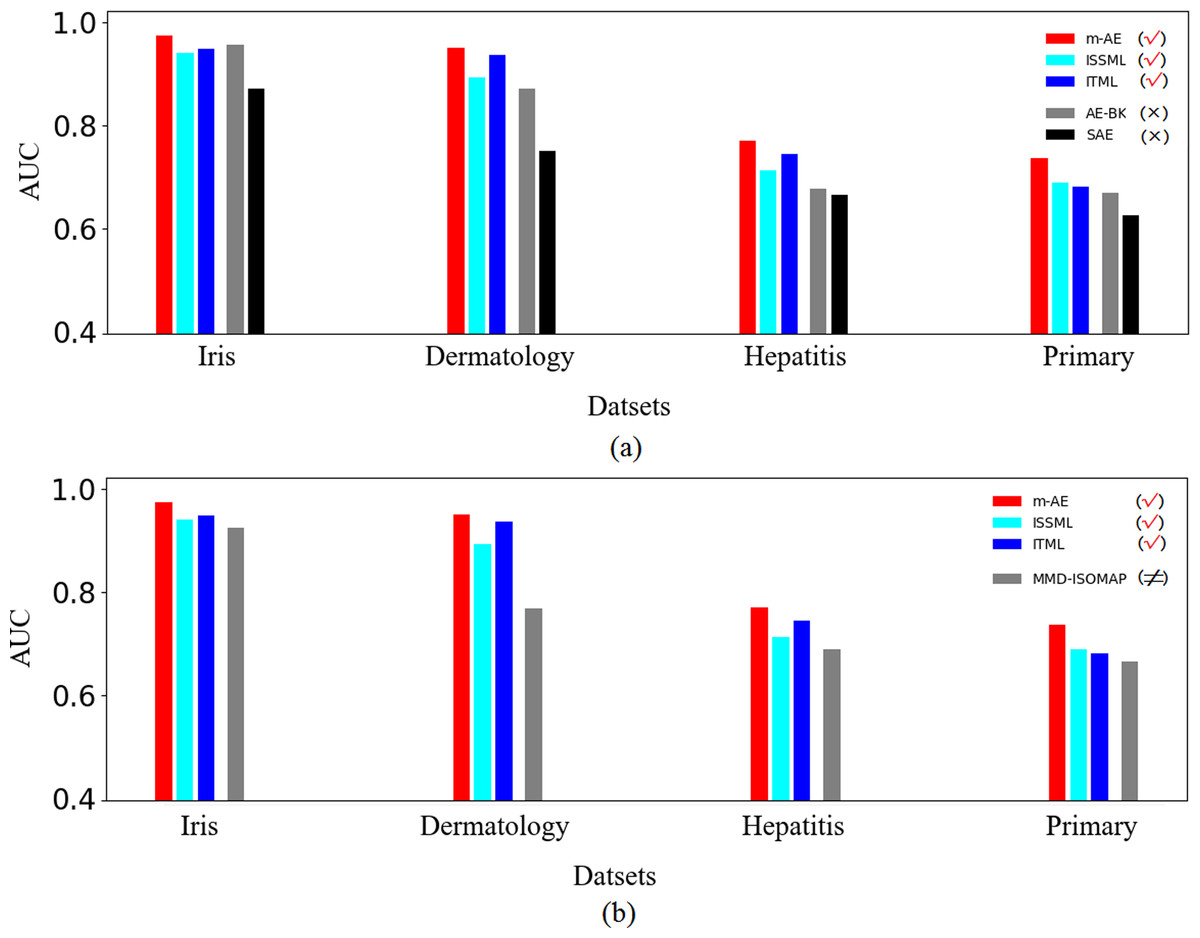
Figure 3: Results of ablation experiments.
(A) Comparisons between using distance metrics and without using distance metrics. These models using distance metrics are marked as the symbol √. The models without both distance metrics and feature selection are marked as the symbol ×. (B) Comparisons between using distance metrics and using feature selection. These models using feature selection are marked as the symbol ≠.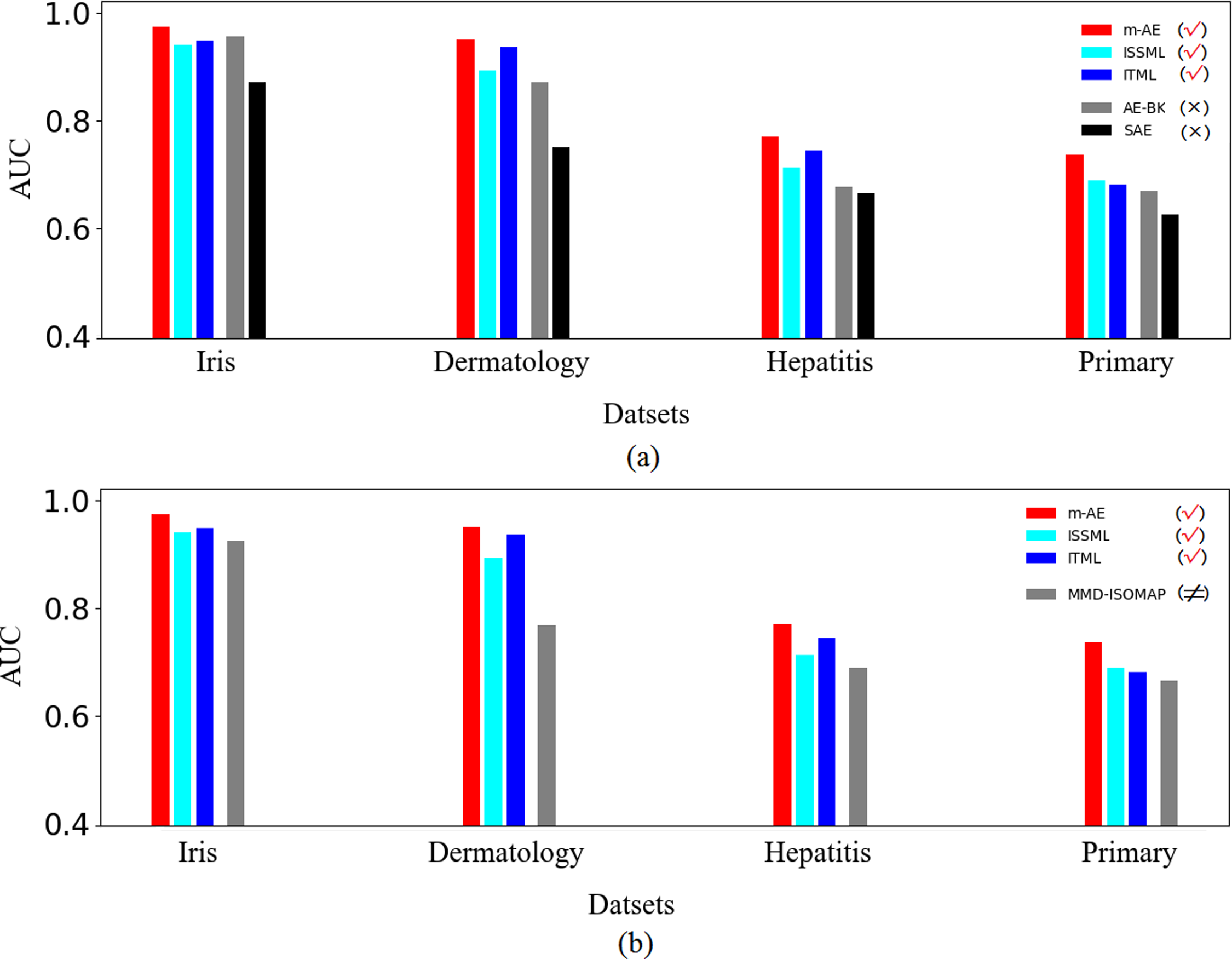{kind=link}

Figure 4: Visualization distributions.
The four datasets are Iris, Dermatology, Hepatitis, Primary from left to right, respectively. The different extracted features are marked with different shapes and colors. The models using distance metrics are marked as the symbol √. The models using feature selection are marked as the symbol ≠. The models without both distance metrics and feature selection are marked as the symbol ×.{kind=link}
Running time
Figure 5 displays the running time of methods. Obviously, the advantage of m-AE in running time is not as significant as that in both the extracted accuracy and the linear separabilities of the extracted features. MMD-ISOMAP spends less in running time on most benchmark datasets than distance metric-based methods, meaning that the execution efficiency of feature selection-based methods is higher than that of distance metric-based methods when running upon a high-dimensional space. Distance metric-based methods take a lot of time to calculate the distance between each point pair upon a high-dimensional space, so as to increase the running time.
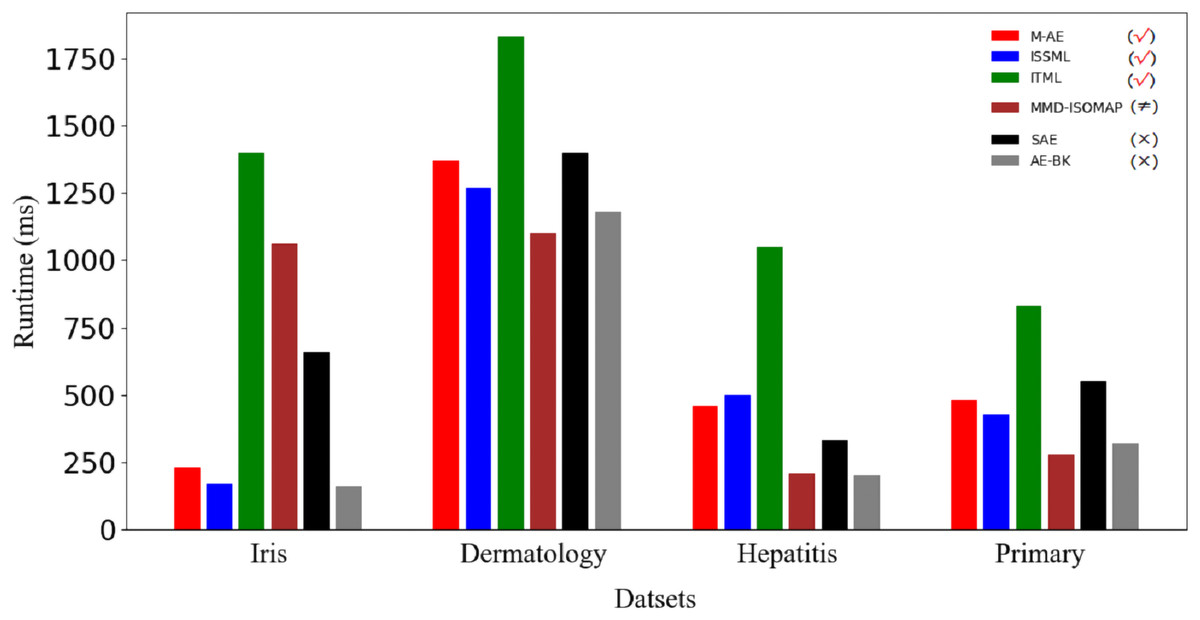
Figure 5: Runtime on benchmark datasets.
The models using distance metrics are marked as the symbol √. The models using feature selection are marked as the symbol ≠. The models without both distance metrics and feature selection are marked as the symbol ×.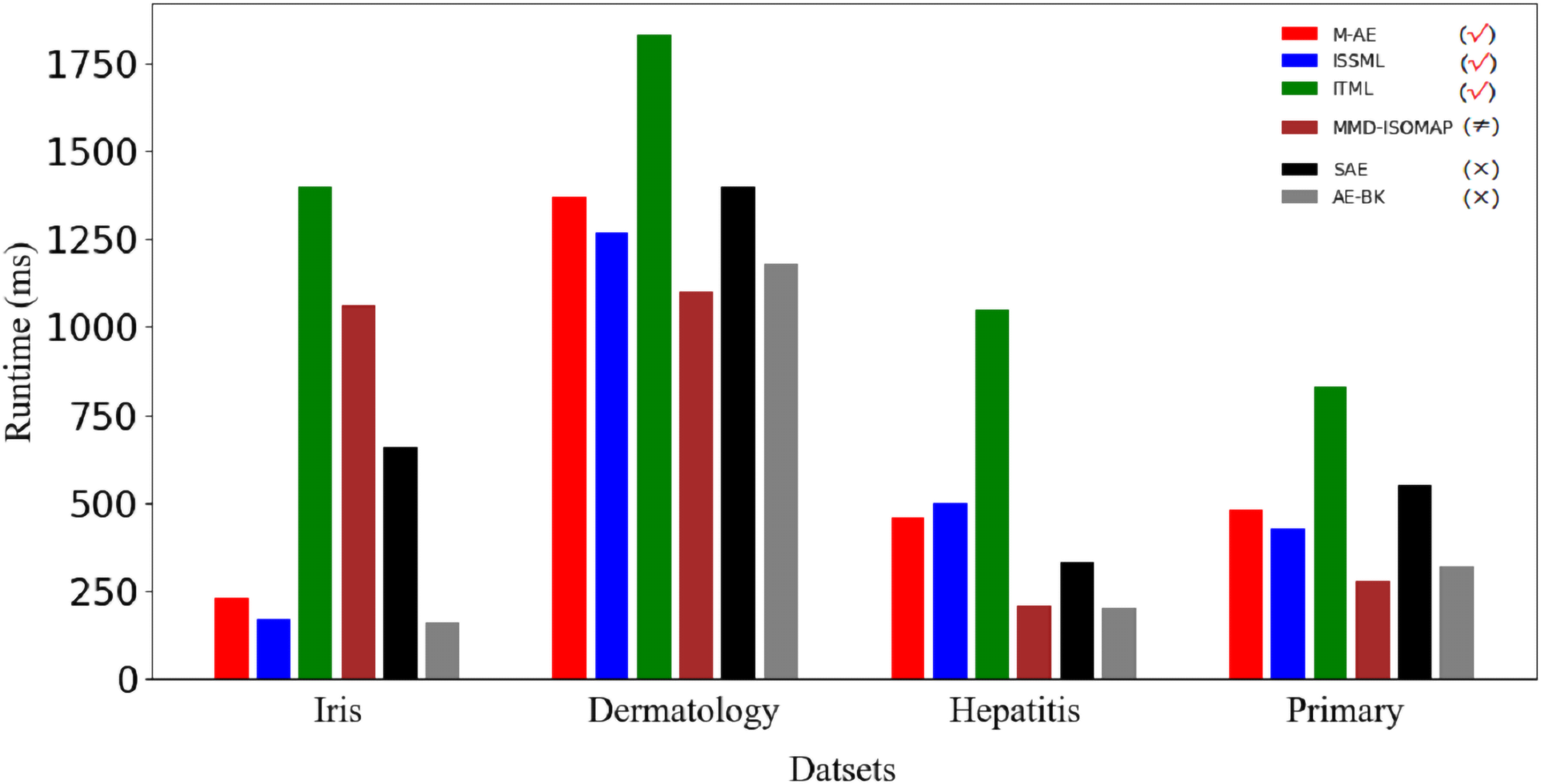{kind=link}
Discussion
Insights gained from investigation
Compared with the competitors, the proposed m-AE has outstanding advantage in term of both the accuracy of feature extraction and the linear separabilities of the extracted features on high-dimensional data. We interpret it as following. On one hand, Mahalanobis distance in Eq. (3) can appropriately measure similarities between the input sample and the reconstructed input sample, so as to minimize the loss error of m-AE in Eq. (5). As such, m-AE gains the desired accuracy of feature extraction. On the other hand, we performed a rescaling on K-L divergence metric in Eq. (2) by using A * in Eq. (4), which effectively allows the extracted features to present linear separabilities, because the rescaling can maximized the classification distance between the extracted different types of features. Hence, the features extracted by m-AE present linear separabilities than competitors. Overall, m-AE outperforms the competitors in extracted accuracy and the linear separabilities of the extracted features.
In a high-dimensional space, distance metric-based methods easily evaluates the feature similarity by calculating the distance between the data, however, feature selection-based methods relatively difficulty assess the feature importance. Therefore, distance metric-based methods, e.g., ISSML (Ying, Wen & Shi, 2018) and ITML (Mei, Liu & Karimi, 2014), are more suitable for extracting those low-dimensional features with the linear separability from high-dimensional data than feature selection-based methods. However, the computational time of feature selection-based methods, e.g., MMD-ISOMAP (Bo, Xiang & Zhang, 2016), is lower than that of distance metric-based methods in a high-dimensional space, since distance metric-based methods spend too much in calculating the distance between each point pair.
Although autoencoders have excellent feature capture capabilities, they may perform poorly in extracting linearly separable features, e.g., SAE (Chen, Hu & He, 2018). Whereas, this deficiency of autoencoders can be remedied by introducing a distance metric. Certainly, there are many methods of distance metrics, e.g., Wasserstein distance metric (Lei, Su & Cui, 2019; Zheng et al., 2022), Bhattacharyya distance metric (Mariucci & Reiß, 2017).
Limitations
The ability of the autoencoder to extract linearly separable features depends on the reconstructed data distribution, while the reconstruction of the data distribution is achieved by the Mahalanobis distance metric of rescaling transformation. Upon a high-dimensional space, the calculation of Mahalanobis distance metric is relatively complicated than that up a low-dimensional space. Moreover, matrix factorization operation needs to be implemented for each computation, therefore, the proposed model is trained using large-scale high-dimensional data until it can converge, which may take longer training epoch.
Conclusions
This article proposed a novel autoencoder method using Mahalanobis distance metric of rescaling transformation to extract linearly separable features from the data in the high-dimensional space. The difference between the reconstructed distribution and the original distribution can be reduced by implementing Mahalanobis distance metric of rescaling transformation, so that the autoencoder can extract the desired features. Finally, results on real high-dimensional datasets show compared with competing methods, the proposed method is a winner in both the accuracy of feature extraction and the linear separabilities of the extracted features. We find that the linear separabilities of those features obtained by the distance metric-based methods are better than that of obtained by the feature selection-based methods. Upon a high-dimensional space, since evaluating feature similarity is relatively easier than evaluating feature importance, distance metric-based methods have more advantages than feature selection-based methods for linearly separable feature extraction, however, feature selection-based methods are better than distance metric-based methods in computational efficiency. In future work, we will look at exploring low-dimensional feature extraction from high-dimensional data under noise disturbance.