
Assessment of a Takagi–Sugeno-Kang fuzzy model assembly for examination of polyphasic loglinear allometry
- Published
- Accepted
- Received
- Academic Editor
- Tjeerd Boonstra
- Subject Areas
- Ecology, Mathematical Biology, Plant Science, Statistics, Computational Science
- Keywords
- Polyphasic log linear allometry, Takagi-sugeno-kang fuzzy model
- Copyright
- © 2020 Echavarria-Heras et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2020. Assessment of a Takagi–Sugeno-Kang fuzzy model assembly for examination of polyphasic loglinear allometry. PeerJ 8:e8173 https://doi.org/10.7717/peerj.8173
Abstract
Background
The traditional allometric analysis relies on log- transformation to contemplate linear regression in geometrical space then retransforming to get Huxley’s model of simple allometry. Views assert this induces bias endorsing multi-parameter complex allometry forms and nonlinear regression in arithmetical scales. Defenders of traditional approach deem it necessary since generally organismal growth is essentially multiplicative. Then keeping allometry as originally envisioned by Huxley requires a paradigm of polyphasic loglinear allometry. A Takagi-Sugeno-Kang fuzzy model assembles a mixture of weighted sub models. This allows direct identification of break points for transition between phases. Then, this paradigm is seamlessly appropriate for efficient allometric examination of polyphasic loglinear allometry patterns. Here, we explore its suitability.
Methods
Present fuzzy model embraces firing strength weights from Gaussian membership functions and linear consequents. Weights are identified by subtractive clustering and consequents through recursive least squares or maximum likelihood. Intersection of firing strength factors set criterion to estimate breakpoints. A multi-parameter complex allometry model follows by adapting firing strengths by composite membership functions and linear consequents in arithmetical space.
Results
Takagi-Sugeno-Kang surrogates adapted complexity depending on analyzed data set. Retransformation results conveyed reproducibility strength of similar proxies identified in arithmetical space. Breakpoints were straightforwardly identified. Retransformed form implies complex allometry as a generalization of Huxley’s power model involving covariate depending parameters. Huxley reported a breakpoint in the log–log plot of chela mass vs. body mass of fiddler crabs (Uca pugnax), attributed to a sudden change in relative growth of the chela approximately when crabs reach sexual maturity. G.C. Packard implied this breakpoint as putative. However, according to present fuzzy methods existence of a break point in Huxley’s data could be validated.
Conclusions
Offered scheme bears reliable analysis of zero intercept allometries based on geometrical space protocols. Endorsed affine structure accommodates either polyphasic or simple allometry if whatever turns required. Interpretation of break points characterizing heterogeneity is intuitive. Analysis can be achieved in an interactive way. This could not have been obtained by relying on customary approaches. Besides, identification of break points in arithmetical scale is straightforward. Present Takagi-Sugeno-Kang arrangement offers a way to overcome the controversy between a school considering a log-transformation necessary and their critics claiming that consistent results can be only obtained through complex allometry models fitted by direct nonlinear regression in the original scales.
Introduction
Julian Huxley introduced the theory of constant relative growth between a trait y and overall body size x (Huxley, 1924; Huxley, 1932; Strauss & Huxley, 1993). This paradigm is commonly refereed as Huxley’s model of simple allometry and is essentially formulated through the power law y = βxα with α identified as the allometric exponent and β as the normalization constant. In biology allometric relationships are to within species, as well as, between species (evolutionary allometry) (Houle et al., 2011; Marquet et al., 2005; West & Brown, 2005; Pélabon et al., 2014). Power function models are also extensively used in other research fields, e.g., physics (Newman, 2007), ecology (Harris, Duarte & Nixon, 2006; Hood, 2007) earth and atmospheric sciences (Hills, 2013), and economics (Li et al., 2015). This has encouraged many research endeavors addressing interpretation of involved parameters, as well as, suitability of analysis method for getting estimates. Indeed, concomitant to Huxley’s theory of relative growth is the Traditional Analysis Method of Allometry (TAMA hereafter). This is, a widespread device to acquire estimates of the parameters α and β. It contemplates a logarithmic transformation of the original bivariate data in arithmetical scale in order to consider a linear regression model in geometrical space, and then retransforming to acquire Huxley’s model of simple allometry in the original scale. This approach implicitly embraces a notion that variability of the response conforms to a pattern of multiplicative growth. On Huxley’s elucidation (Huxley, 1932) the intercept lnβ of TAMA’s line was of no specific biological importance, but the slope b was significant enough as to mean allometry itself. This interpretation has permeated contemporary research to such an extent that many practitioners still consider it to be the valid theoretical perspective for static and ontogenetic allometry (Eberhard, 2009; Houle et al., 2011; Pélabon et al., 2018). However, views assert that a TAMA approach produces inconsistent results, thereby recommending allometric examination by relying instead on nonlinear regression in the direct scales of data (Packard, 2017a; Packard, 2013; Packard, 2009; Packard & Birchard, 2008). This is, debatable for defenders of the traditional approach that claim that, as it is conceived in the original theoretical context of allometry, a logarithmic transformation deems necessary in the analysis (Lai et al., 2013; Klingenberg, 1998; Nevill, Bate & Holder, 2005; Kerkhoff & Enquist, 2009; Xiao et al., 2011; White et al., 2012; Ballantyne, 2013; Glazier, 2013; Niklas & Hammond, 2014; Lemaître et al., 2015; Pélabon et al., 2018). Yet steering further away from Huxley’s perspective on covariation among different traits, other views conceive allometry centered on the covariation between size and shape (Mosimann, 1970; Klingenberg, 2016). From this standpoint, analysis must rely in Multiple Parameter Complex Allometry (MPCA after this) formalizations through all varieties of nonlinear or discontinuous relationships (e.g., Frankino, Emlen & Shingleton, 2010; MacLeod, 2014; Bervian, Fontoura & Haimovici, 2006; Lovett & Felder, 1989; Packard, 2013). However, adoption of MPCA approaches nourishes one of the most fundamental discrepancies among schools of allometric examination. Indeed, for advocates of the traditional approach, examination based on MPCA models fitted in arithmetical scale sacrifices appreciation of biological theory in order to privilege statistical correctness (Houle et al., 2011; Lemaître et al., 2015; Pélabon et al., 2018). A way to keep the analysis in geometrical space while amending unreliability of a linearity assumption is conceiving the notion of non-log linear allometry (Packard, 2012b; Strauss & Huxley, 1993; Echavarría-Heras et al., 2019a). As every analytic function can be expanded as a power series, curvature in geometrical space has been addressed through polynomial regression schemes (Kolokotrones et al., 2010; Lemaître et al., 2014; MacLeod, 2010; Glazier, Powell & Deptola, 2013; Tidière et al., 2017; Echavarría-Heras et al., 2019a). But besides difficulties related to biological interpretation of a polynomial mean response, this approach maintains a single functional form of the response over the whole covariate range. This could not account for inherent heterogeneity in the logtransformmed response as contemplated in Huxley’s theoretical perspective. Certainly, Huxley reported a breakpoint in the log–log plot of chela mass vs. body mass of fiddler crabs (Uca pugnax). It was attributed to a sudden change in relative growth of the chela approximately when crabs reach sexual maturity (Huxley, 1924; Huxley, 1927; Huxley, 1932). This suggests a slant aimed at adding complexity in geometrical space while keeping the theoretical essence of traditional allometry in the analytical set up. Is this conception that hosts polyphasic loglinear allometry approaches (PLA afterwards) (Packard, 2016; Gerber, Eble & Neige, 2008; Strauss & Huxley, 1993; Hartnoll, 1978). PLA characterizes heterogeneity of the logtransformmed response by composing covariate range into sectors separated by break points. Each subdivision associates to a linear sub model. Broken- line regression (Beckman & Cook, 1979; Ertel & Fowlkes, 1976; Tsuboi et al., 2018; Ramírez-Ramírez et al., 2019; Muggeo, 2003; Echavarria-Heras et al., 2019b). Forbes & López (1989) furnish an empirical approach to identification of PLA patterns. Nevertheless, by relying in nonlinear regression this technique requires starting values for the break-point estimation. Therefore, complications set by local maxima, as well as, inferences on estimates could make implementation difficult (Julious, 2001; Muggeo, 2003).
The quest for new tools that increase reliability of analytical methods has been always a motivation in research. This drive explains the introduction of hybrid models that merge different techniques with the aim of efficiently addressing complexity (Kimmins, Mailly & Seely, 1999; Alur et al., 1995; Ajili & Wallace, 2004; Pozna et al., 2010; Hamilton, Lloyd & Flores, 2017). In particular, soft computing techniques entail modelling procedures, which are supplemental to customary statistics and probability approaches and that bear tolerance to imprecision, uncertainty, partial truth and approximation (Baldwin, Martin & Azvine, 1998). For instance, identification and control of nonlinear systems exemplifies a subject that has greatly benefited by adoption of related hybrid modeling schemes (Bonissone et al., 1999; Kawaji, 2002; Vrkalovic, Lunca & Borlea, 2018; Chen, 2001; Echavarria-Heras et al., 2019b). Implementation of soft computing protocols include techniques of fuzzy set theory, neural networks, probabilistic reasoning, rough sets, machine learning, and evolutionary computing (Zadeh, 1993; Oduguwa, Tiwari & Roy, 2005; Bello & Verdegay, 2012; Ibrahim, 2016; Al-Kaysi et al., 2017; Herrera-Viedma & López-Herrera, 2010). In this upsurge of nonconventional analytical tools, we can place adaptation of fuzzy logic procedures aimed to lessen parametric uncertainty effects in allometry (Schreer, 1997; Schwetter & Bertone, 2018; Bitar, Campos & Freitas, 2016; Echavarría-Heras et al., 2018a; Näther & Wälder, 2006; Dechnik-Vázquez et al., 2019).
An operating regime based modeling approach offers a structure supporting model adaptation amid an empirical and mechanistic standpoint. Local models valid over restricted domains are combined by smooth interpolation into an overall general output (Johansen & Foss, 1997). Therefore, this structure naturally hosts heterogeneity as conceived by PLA (Echavarria-Heras et al., 2019b). One example of a hybrid-operating regime based modeling is the Takagi-Sugeno-Kang fuzzy model (Sugeno & Kang, 1988; Takagi & Sugeno, 1985) (TSK in what follows). This construct composes a fuzzy logic step intended to characterize smoothing weight factors. Then, conventional statistical methods are used to acquire estimates of parameters characterizing sub models. It turns out that the general output of a first order TSK fuzzy model can uniformly approximate any continuous function to arbitrarily high precision (Ying, 1998; Zeng, Nai-Yao & Wen-Li, 2000). As we show in this examination, an advantage of TSK over conventional PLA, is that it can offer convenient non-statistical proxies of break points for transition among phases. Moreover, consideration of sub models of a TSK scheme as TAMA’s linear functions in geometrical space not only offers a congruent PLA model, but it could also entail a highly biologically meaningful model of allometry, because it can model the breakpoints while keeping the meanings of allometric exponents as in Huxley’s original formulation. A comprehensive exploration of suitability of the TSK scheme to examine PLA patterns has not been undertaken so here we attempted to fill this gap. In what follows a formulation of PLA by means of a the TSK fuzzy model will be referred as TSK-PLA for short.
The outstanding approximation capabilities of a TSK fuzzy model entail reliable identification of whatever MPCA functional form renders necessary in arithmetical space (Echavarría-Heras et al., 2018a; Echavarria-Heras et al., 2019b). Adaptation of the TSK fuzzy model for that aim will be forward designated by means of the TSK-MPCA abbreviation. As a criterion to evaluate the performance of the TSK-PLA proxy we verified the dependability of linked retransformation results, including break point placement and reproducibility strength of mean response function against corresponding estimations produced via TSK-MPCA. It turns out that proposed TSK-PLA analysis method endorsed reliable identification of heterogeneity of examined allometries. Furthermore, the affine structure of the present fuzzy protocol can accommodate either complex or simple allometry as required to analyzing the data. Thus, the presented TSK-PLA model can be considered as a general tool for examination of zero intercept allometries. Moreover, from a theoretical standpoint a TSK-PLA representation implies an allometric model in arithmetical space that seemingly fits MPCA. This expresses the response as a generalized power function including scaling parameters expressed as functions of the covariate (Bervian, Fontoura & Haimovici, 2006; Echavarría-Heras et al., 2019a; Echavarria-Heras et al., 2019b). But, above all, present fuzzy approach contributes by offering a way of overcoming the controversy between a school considering analysis in geometrical space as a must in allometry, and critics claiming that consistent results can only come along by using a MPCA formulation followed by nonlinear regression protocol in the original scale of data. Interestingly, present TSK-PLA arrangement also contributed on qualitative grounds. Certainly, Huxley reported a breakpoint in the log–log plot of chela mass vs. body mass of fiddler crabs (Uca pugnax). Packard (2012a) inferred this point was only putative. In his own interpretation, perhaps due to combined effects of a log transformation itself and the format of graphical display of Huxley’s data. However, application of present Takagi-Sugeno-Kang protocol supports existence of a break point in Huxley’s Uca pugnax log–log plot.
This article is organized as follows: In the Materials and Methods section, we formally explain the steps backing the identification of the offered TSK-PLA scheme. There, we explain why this construct can be considered as a generalized protocol for allometric analysis in geometrical space. We also clarify why the offered TSK model implies a MPCA scheme in arithmetical space. The presentation includes an elucidation of sufficient conditions under what the asymptotic mode of the acquired TSK proxy behaves as the power function in Huxley’s model of simple allometry. There, we also suggest a correction factor (CF here after) for bias of retransformation of the regression error that grants highest reproducibility for derived mean response function in arithmetical space. The Results section highlights on the advantages of the present approach over conventional counterparts. A Discussion section elaborates on the contribution that our approach bears for the general subject of suitability of analysis method in bivariate allometry. An Appendix includes a detailed explanation of the steps involved in the construction and identification of the general form of the addressed TSK models.
Materials & Methods
Data
Allometric examination here mainly relied on a primary data set exhibiting curvature in geometrical space. This composes 10,412 measurements of Zostera marina (Eelgrass) leaf biomasses y and corresponding leaf areas x as reported in Echavarría-Heras et al. (2019a) and Echavarría-Heras et al. (2018b). For comparison, we also considered data reported in Mascaro et al. (2011) comprising 30 Biomass-Diameter at Breast Height measurements on Metrosideros polymorpha. Analisis also extended to data reported in De Robertis & Williams (2008) including 29,363 Length–Weight measurements on Gadus chalcogrammu. This last data set allowed illustration of the performance of the TSK paradigm in a circumstance where the TAMA protocol is consistent. Finally, we analysed the fitness of the TSK in detecting break points in the log–log plot of chela mass vs. body mass of fiddler crabs (Uca pugnax) (Huxley, 1924; Huxley, 1932).
Models
General formula of allometry
The methods engaged here aim to identification of the suitable form of the allometric function representing the variation of a trait y depending on a descriptor x. For that purpose, we firstly introduce the formal framework and the notation convention used through. We assume that a response y and its covariate x belong to domains Y and X of positive real numbers one to one and with y having a zero limit when x approaches zero. We also consider that there exist a function where p = (p1, …, pn) is a parameter set, and a concomitant approximation error function that combine to model whatever form, the linkage between x and y acquires. Moreover, we take on, that such a relationship can be expressed through an additive error description (1) or else through the multiplicative error alternate (2)
In order to get , we can consider the error term as a random variable ϵ. Then, specifications above offer two commonly addressed analysis protocols in allometry. A regression model with additive error in arithmetical scale (3) with ϵ taken as ψ −distributed with zero mean and variance generally expressed as a function of covariate, that is, . Fitting Eq. (3) generally requires direct nonlinear regression protocols. This returns a mean response function For the sake of facilitating comparison aims in further developments, this a subscript will be maintained to typify a mean response function gotten by means of identification protocols applied in arithmetical space.
A second procedure circumscribes to the multiplicative error model of Eq. (2) and relies in a logtransformation procedure in order to consider a parallel regression model in geometrical space. Formally, we contemplate a mapping (y, x) → (v, u) such that u = lnx and v = lny. This sets variation domains U and V for u and v to one. We concomitantly have the regression model with additive error in geometrical space (4) where formally (5) and ϵ is random variable as specified above. It follows that back-transforming Eq. (4) to arithmetical space yields, (6) Then, concomitant mean response function is symbolized through Egw(y|x) and becomes (7) where . Notice that in Egw(y|x) we have used the notation convention of a subscript g referring to identification of w(x, p) based on the regression model of Eqs. (4) and (5).
The CF, δ above provides the necessary adjustment for bias of retransformation of the regression error ϵ (Mascaro et al., 2011; Baskerville, 1972; Newman, 1993). Assuming sets eϵ to be lognormally distributed. Then, CF becomes (8)
But, Newman (1993) asserts that whenever ϵis not normally distributed, δis given by the smearing estimate of bias of Duan (1983). Nevertheless, in some settings this nonparametric form can produce bias overcompensation (Manning, 1998; Smith, 1993; Koch & Smillie, 1986). Zeng & Tang (2011a) propose an alternate nonparametric form of δ namely (9) Actually, δ given this way corresponds to a three terms partial sum approximation of the power series expression of E(eϵ) assuming . By the same token, Echavarría-Heras et al. (2019a) suggest a representation for δ given by a n-terms partial sum of series representation of , that is, (10) Maximization of Lin’s Concordance Correlation Coefficient (CCC) (Lin, 1989) between observed values and mean response Eg(y|x) resulting using this form of δ sets criterion to choose n.
Huxley’s formula of Simple Allometry
A characterization of as a power function βxα has been traditionally referred as Huxley’s formula of simple allometry (Strauss & Huxley, 1993). This model will be ahead epitomized by a subscript s as a mnemonic device for “simple”. Equation (3) becomes (11) with and ϵ assumed to be normally distributed with zero mean and variance σ2, that is, . According to our notation convention Eq. (11) yields the mean response function .
Similarly, the logtransformation method produces the TAMA’s regression model, that is, (12) with (13) and ϵ as specified above. Equations (12) and (13) determine . Accordingly, back transformation of Eq. (12) to arithmetical space brings up a mean response given by (14) where δ stands for necessary CF.
It often occurs that even after contemplation of proper form for δ this TAMA’s derived proxy for produces biased projections of observed values of the response y. This means, that complexity of Huxley’s formula of simple allometry becomes inappropriate to identify the true form (Gould, 1966; Huxley, 1932; Bervian, Fontoura & Haimovici, 2006; MacLeod, 2014; Echavarría-Heras et al., 2019a). From the settings of Eq. (1) it is reasonable assuming that adapting complexity as it is needed to identify could depend on MPCA forms. Corresponding logtransformmed expression is inferred to be a nonlinear function of covariate u. This rears PLA as a likely device to acquire complexity for identification of MPCA through geometrical space methods. We adopt the affine structure of a first order TSK fuzzy model as a device for identification both MPCA or PLA alternates.
The TSK account of
The general output of a first order TSK fuzzy model bears a fuzzy alternate to a statistical mixture regression model (Cohn, Ghahramani & Jordan, 1997). It is then reasonable to assume that such an structure could efficiently address the problem of identifying expressed as a MPCA model in arithmetical scale or its assumed PLA forms in geometrical space. The symbol will stand for the TSK-MPCA surrogate for . Accordingly, adaptation of Eq. (3) becomes (15) with ϵTSKa ψ −distributed residual random variable with zero mean and variance expressed as a function of x, that is, .
Denoting through the symbol the mean response function determined by Eq. (15), we have (16)
Since, the general output of a first order TSK fuzzy model can uniformly approximate any continuous function to arbitrarily high precision (Ying, 1998; Zeng, Nai-Yao & Wen-Li, 2000) then whatever MPCA form embraces, this can be accurately projected through a consistent identification of .
In turn, according to Eq. (4) the TSK-PLA regression protocol becomes, (17) where according to Eq. (5), and ϵTSK as specified in Eq. (15).
In turn, equation Eq. (17) yields Additionally, a back-transformation ev of Eq. (17) sets (18)
Then, corresponding mean response function in arithmetical space turns out to be (19)
By assumption, we take in the form given by Eq. (A14), that is, (20) with and a one to one the firing strengths and consequent functions for i = 1, 2, …, q. Since, the domain U of covariate is R, we can assume membership functions to have a Gaussian form i.e., (21) being θk and λk for k = 1, 2, …, q, parameters. We also consider that consequent local models have a description, that is, (22) being αi and lnβi parameters. Readily, Eqs. (20) through (22) entail a TSK-PLA arrangement. As it will be clarified ahead a similar adaptation of Eq. (A14) stablishes the TSK-MPCA form wTSK(x, p) in Eq. (15).
Identification of as given by Eqs. (20) through (22) is performed by means of the Matlab function: main_fun_tsk_pla_model_fit.m. available from the Supplementary Information section. Heterogeneity and reproducibility strength features of can be interactively explored through different characterizations of the clustering radius-training parameter ra as specified by Eqs. (B7) through (B9).
As described in Appendix A, acquiring requires on first stage a fuzzy partition Lu of the input domain U (cf. Eq. (A3)). Achieving this relies on a Subtractive Clustering (SC after this) technique to establish the value of the parameter q (Castro et al., 2016; Chiu, 1994). A brief description of the SC method is provided in Appendix B. This stage also sets the number of inference rules Ri specified by Eq. (A10) and concomitant number local models in . The SC step also produces estimates for the parameters θk and λk in characterizing the membership functions . Then, the normalized firing strength functions, follows from (Eqs. A11) and (A12). A second step targets at characterization of the linear consequents as given by Eq. (22). This is achieved by replacing the identified factors and the assumed form of the consequents into Eq. (20) to characterize the regression model of Eq. (17). Then, the parameters in the consequents are estimated by implementing a Recursive Least Squares (RLS) routine (Jang, Sun & Mizutani, 1997; Wang & Mendel, 1992). This identification step could be also performed through a maximum likelihood approach (Kalbfleisch, 1985). The whole identification algorithm is explained in Appendix B. Codes are included in the Supplementary Information section.
Assessment of reproducibility strength of models
Following Echavarria-Heras et al. (2019b) reproducibility will be primarily estimated by comparing values of Lin’s concordance correlation coefficient, symbolized by means of ρC (Lin, 1989). Agreement will be defined as poor whenever ρC < 0.90, moderate for 0.90 ≤ ρC < 0.95, good for 0.95 ≤ ρC < 0.99, or excellent for ρC ≥ 0.99 (McBride, 2005). Assessment of reproducibility will also rely on model performance metrics, such as the Coefficient of Determination (CD), Standard Error of Estimate (SEE), Mean Prediction Error (MPE), and Mean Percent Standard Error (MPSE) (Gupta, Sorooshian & Yapo, 1998; Hauduc et al., 2011; Zeng et al., 2017; Zeng & Tang, 2011b; Parresol, 1999; Meyer, 1938; Schlaegen, 1982). Related statistics are included in Appendix C. Matlab and R codes are provided in the supplemental files section.
Results
Data
Plots in Fig. 1 display the spread response–covariate in geometrical space for data sets included in this examination. Figure 1A relates to the Echavarría-Heras et al. (2019a) data. Figure 1B is for Mascaro et al. (2014) data. Figure 1C shows Huxley’s plot of chela mass vs. body mass of fiddler crabs (Uca pugnax) in log–log scale (Huxley, 1924; Huxley, 1932). Figure 1D displays spread for the De Robertis & Williams (2008) data. Assessment of curvature will be performed for all data sets by analyzing fitting results of the TSK-PLA and TSK-MPCA models. For easy of presentation detailed results on a TAMA-TSK model comparison will only circumscribe to the Echavarría-Heras et al. (2019a) data.
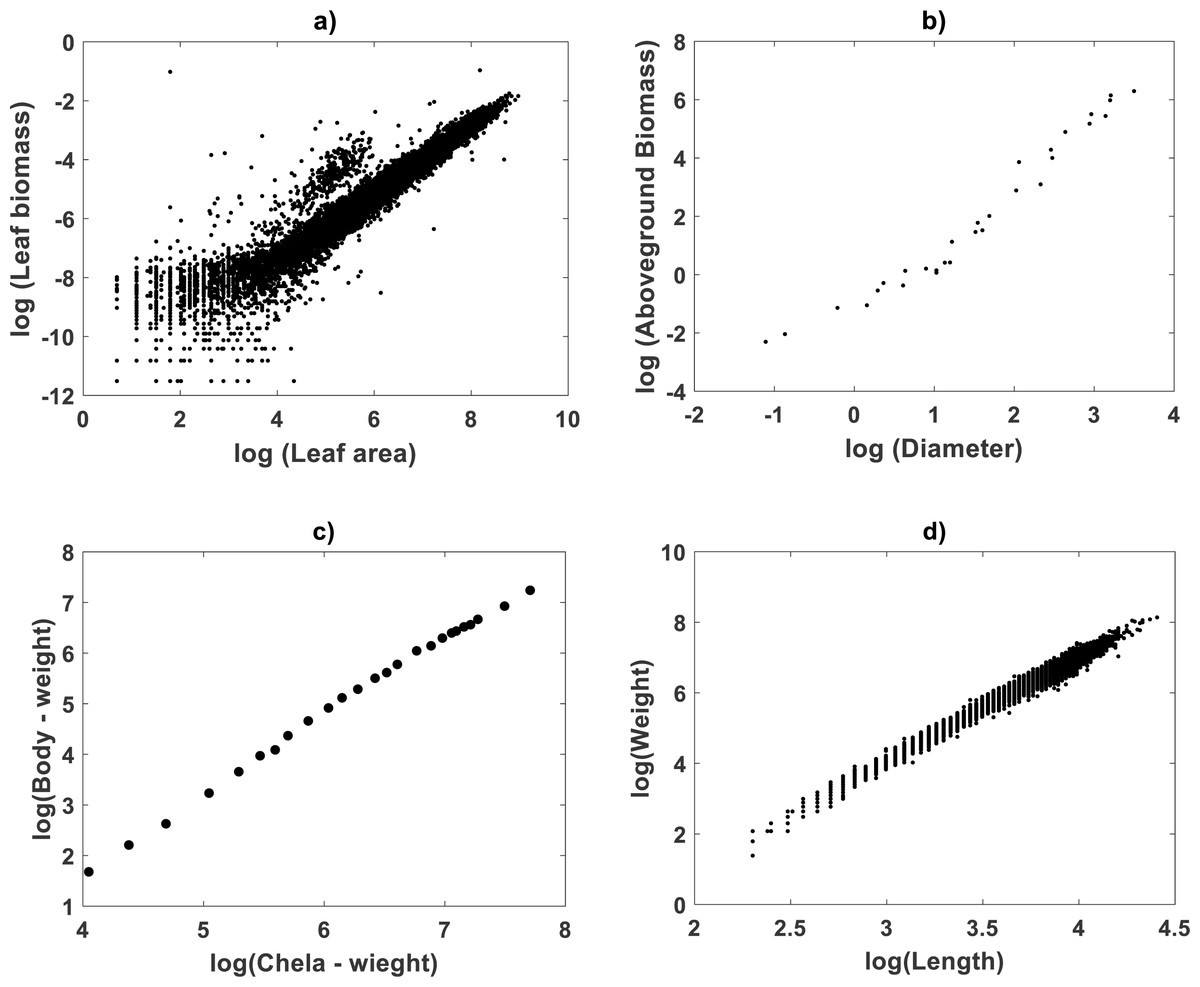
Figure 1: Spreads of allometric response and covariate in geometrical space.
This plot shows the spread response–covariate in geometrical space for the included data sets. (A) depicts dispersion for Echavarría-Heras et al. (2019a), (B) presents that associating to Mascaro et al. (2014) (C) shows that for Huxley (1932) and (D) is for the De Robertis & Williams (2008) data sets.{kind=link}
Representation of the back-transformed TSK-PLA proxy as a MPCA formula
This section explains that assuming TSK-PLA implies a multiple parameter complex allometry form in direct arithmetical scales. Indeed following Bervian, Fontoura & Haimovici (2006), Echavarría-Heras et al. (2019a) proposed an extension of Huxley’s formula of simple allometry that includes scaling parameters α and β depending in the covariate, that is, (23) where and α(x) are continuous functions and with assumed to be positive. This sets (24) Thus, formally whenever the scaling functions and α(x) are not simultaneously constant as given by Eq. (24) entails MPCA (Echavarría-Heras et al., 2019a; Echavarria-Heras et al., 2019b).
We now demonstrate that the mean response function EgTSK(y|x) in arithmetical space derived from a TSK-PLA arrangement implies MPCA in the form set by Eq. (24). For that drive, we notice that replacing Eq. (22) into Eq. (20) and then rearranging leads to (25) where (26) and (27) Thus, Eq. (17) takes on the equivalent representation, (28)
The functions and above, suggest u − dependent forms of the parameters lnβ and α involved in the regression model of the TAMA approach. Then, under the assumption of Eq. (22) a TSK–PLA arrangement interprets as generalization of the TAMA scheme (Echavarría-Heras et al., 2019a). Applying the back-transformation ev of Eq. (28) and recalling Eq. (19) yields (29)
This sets But, from Eq. (5) we have then as identified by retransformation of admits the form specified by Eq. (24).
Fitting results of the TAMA protocol: Zostera marina
For comparison aims, we present fitting results of the TAMA on the Echavarría-Heras et al. (2019a) data. Estimates for the allometric parameters α and β derive from linear regression on log-transformed data (v, u) (cf. Eq. (12)). Table 1 summarizes the results of the analysis. Corresponding, mean response in geometrical scale is shown in Fig. 2A. Log-transformation is a mechanism aimed to reduce variability of data (Feng et al., 2014). Nevertheless, Fig. 2A still displays a significant dispersion of v values about . Spread may lead on first sight to the impression that the distribution of v around the mean response line for small values of u is fair. Agreeing with (Packard, 2017b), on the importance of graphs in allometry, led to a careful revision of the spread which suggested curvature. Moreover, the assessment of dispersion of residuals ϵ of Eq. (12) suggested lack of normality, as well as, heteroscedasticity (Fig. 2B). Further, QQ plot shows heavier tails than expected for a normal distribution (Fig. 2C). Indeed, an Anderson & Darling (1952) test to ascertain normality of ϵ residuals produced a test statistics value of A = 310.848 and a :p-value < 2.2e–16. In turn a Lilliefors (Kolmogorov-Smirnov-type) test, delivered D = 0.1305, as well as, a relatively small p-value < 2.2e–16. Therefore, the hypothesis of normally distributed errors in the analysis should be rejected since obtained p-values are extremely small (<2.2e–16). What is more, a lack of normality of ϵerrors in the linear regression analysis of Eq. (12) can be also ascertained from the normal QQ plot shown in Fig. 2C. It can be perceived that the distribution of ϵ residuals exhibits heavier tails than those expected for a normal distribution.
| Residual statistics | |||||
|---|---|---|---|---|---|
| Minimum | 1Q | Median | 3Q | Maximum | |
| −4.7535 | −0.2642 | 0.0042 | 0.2151 | 8.3509 | |
| Coefficient values | |||||
| Parameters | Estimate | Std. Error | t value | Pr(>—t—) | Confidence Interval (95%) |
| α | 1.022775 | 0.003662 | 279.3 | <2e−16 | (1.015597, 1.029953) |
| lnβ | −11.202199 | 0.021515 | −520.7 | <2e−16 | (−11.24437, −11.16003) |
| Fitting test. | |||||
| Test | Value | ||||
| Residual standard error | 0.5723 on 10410 degrees of freedom | ||||
| Multiple R-squared | 0.8823 | ||||
| Adjusted R-squared | 0.8823 | ||||
| F-statistic | 7.802e+04 on 1 and 10410 DF | ||||
| p-value | <2.2e−16 | ||||
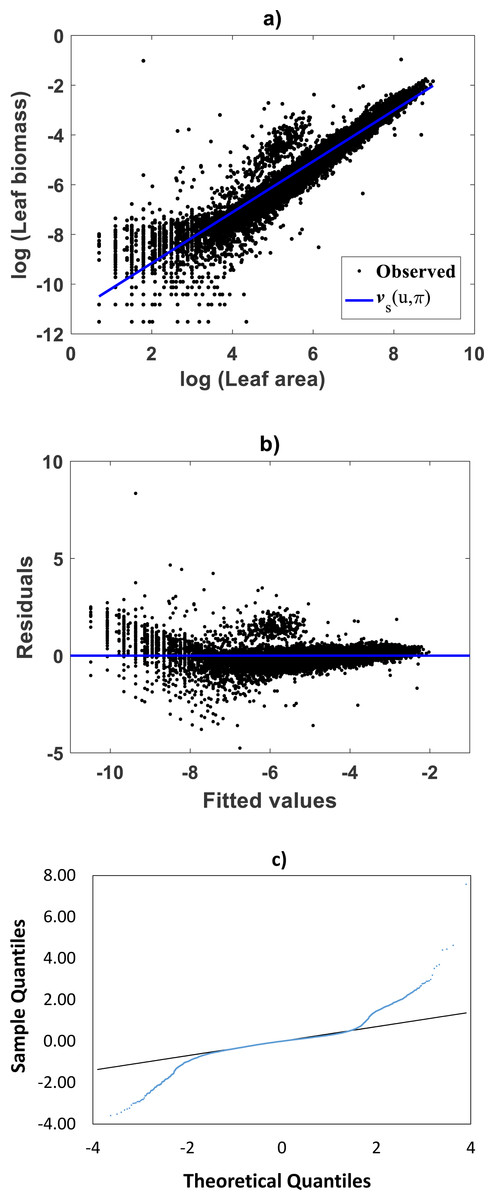
Figure 2: Dispersion plots for the TAMA fit on the Echavarría-Heras et al. (2019a) data set.
(A) shows dispersion of log transformed eelgrass leaf biomasses v around the estimated form of mean response line of Eq. (13). Residuals for the regression model of Eq. (12) show irregular spreading about the zero line (B). Besides, the QQ plot in (C) displays heavier tails than expected for a normal distribution.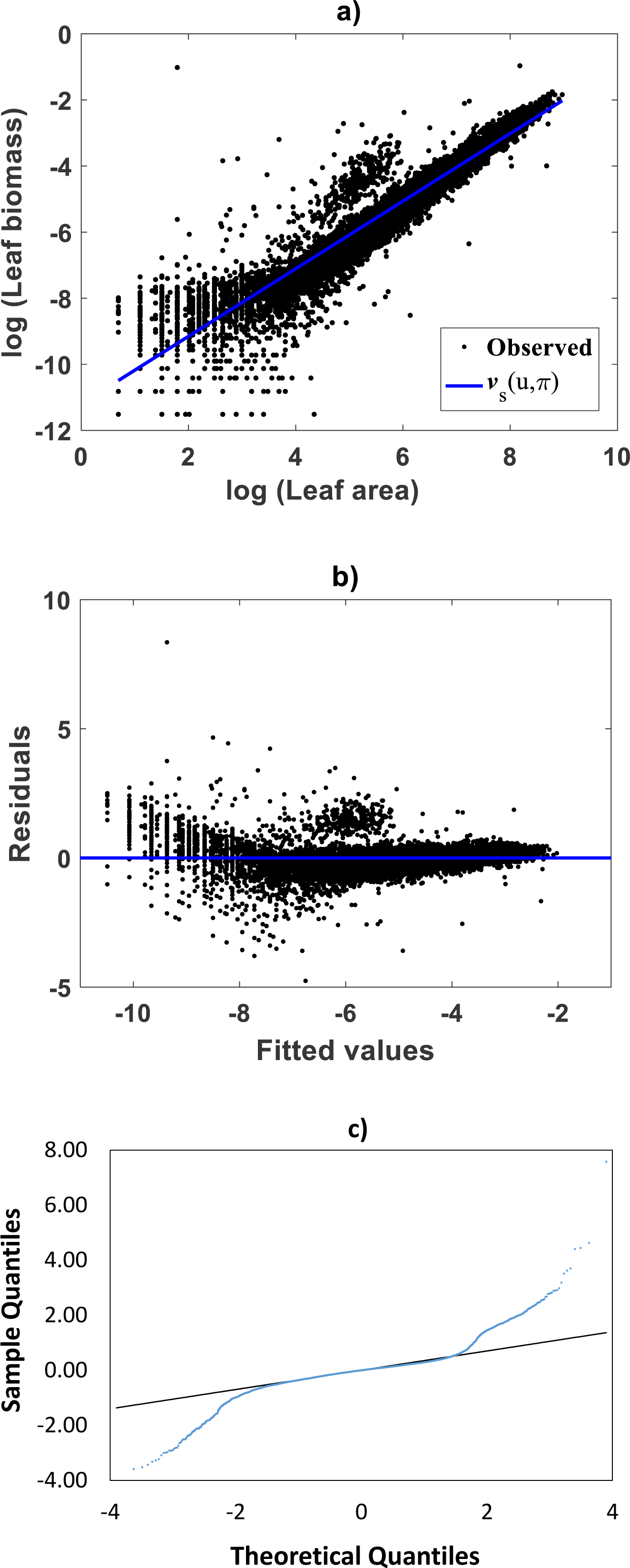{kind=link}
Besides, a Breush-Pagan statistic (Breusch & Pagan, 1979), provided a way to assess heteroscedasticity of the ϵ residuals. In order to perform this test, the squared errors in the linear model of Eq. (12) were assumed to depend linearly on the independent variable i.e., (30) where b and d are parameters and ζthe error term. The null hypothesis is that the parameter d in Eq. (30) vanishes. Rejection of the null hypothesis not only corroborates heteroscedasticity but also provides information on variability. The test statistics turned out to be BP = 808.8119 with one degree of freedom with a p − value (<2.2e–16), that is sufficiently small as to provide strong evidence against homoscedasticity, while undoubtedly favoring heteroscedasticity. Thus, the presently fitted straight line does not comply the essential assumptions of normality and homoscedasticity of the analysis. Therefore, the TAMA protocol turned out unsuited for analyzing the allometric relationship in the Echavarría-Heras et al. (2019a) data. Consequently, characterization of the general function w(x, p) entailed by Huxley’s model of simple allometry (cf. Eq. (11)) does not fit required complexity. Thus data spread shown in Fig. 2A, submits curvature in geometrical space. We now turn to explore the capabilities of the TSK-PLA construct to identify this pattern.
Fitting results of the TSK-PLA assembly: Zostera marina
Identification of firing strength factors
In order to identify the required firing strength factors for i = 1, 2, …, q. We executed the main_fun_tsk_pla_model_fit.m code on log-transformed values (v, u) from the Echavarría-Heras et al. (2019a) data set. This try assumed membership functions having a form given by Eq. (21) for k = 1, 2, …, q. Setting ra = 0.47 returned a value of q = 2. Then, we have to consider two membership functions characterizing the fuzzy partition of imput space U. Moreover, in compliance with Eq. (A12) normalized firing strength factors and turn out to be (31) (32)
Plots of the estimated membership functions μΦ1(u) and μΦ2(u) and normalized firing strength factors and appear in Fig. 3A and Fig. 3B respectively. We observe that agreeing curves intersect at a point ub = 3.998.
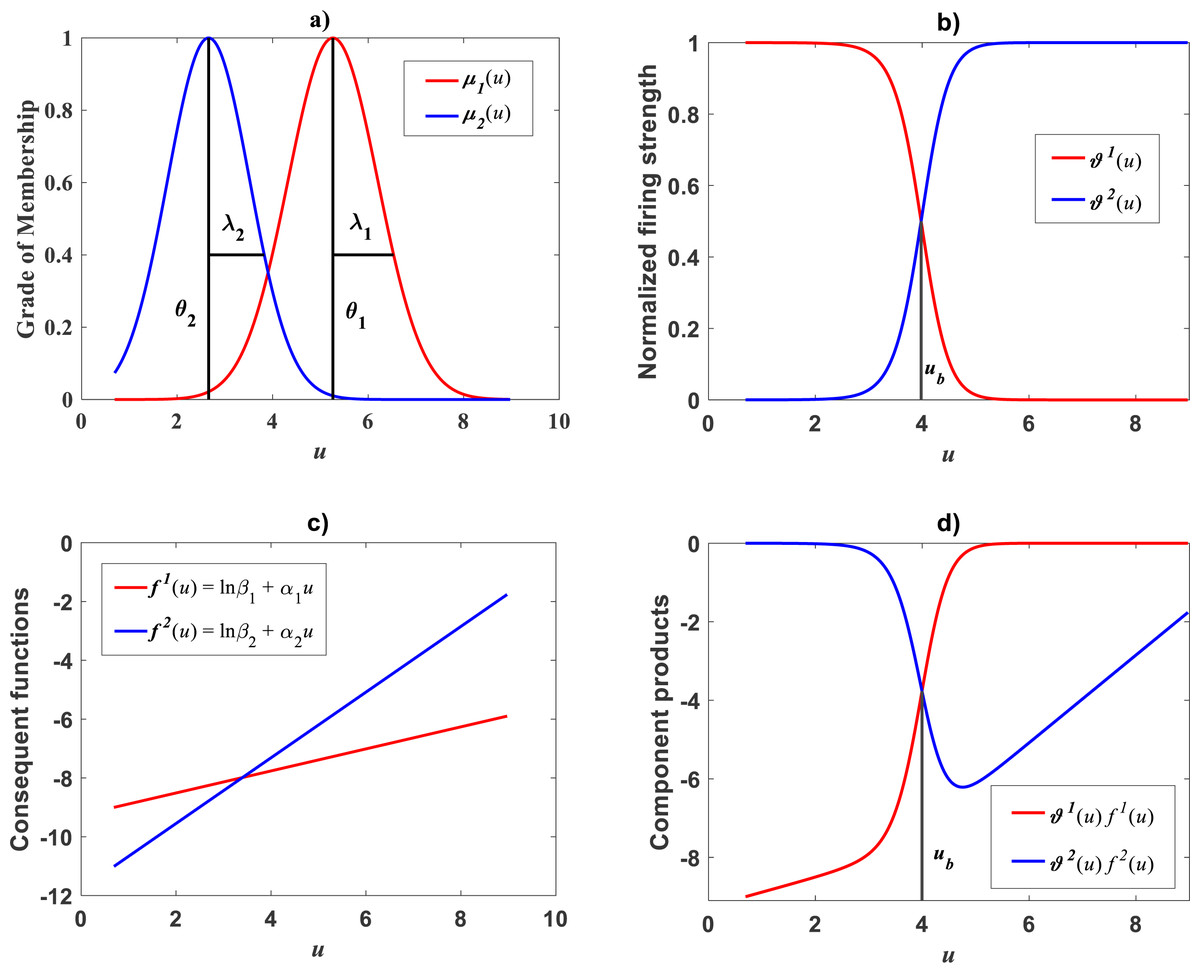
Figure 3: Elements of the TSK-PLA fuzzy model identified on the Echavarría-Heras et al. (2019a) data set.
Shown results associate to a value ra = 0.47 for the clustering radius that corresponded to a q = 2, heterogeneity index. (A) displays plots of membership functions both given in the Gaussian form of Eq. (21). (B) presents plots of normalized firing strength factors given by Eqs. (31) and (32) one to one. A break point at ub = 3.98 is shown. (C) displays consequent linear functions as given by Eqs. (33) and (34). (D) portraits component products.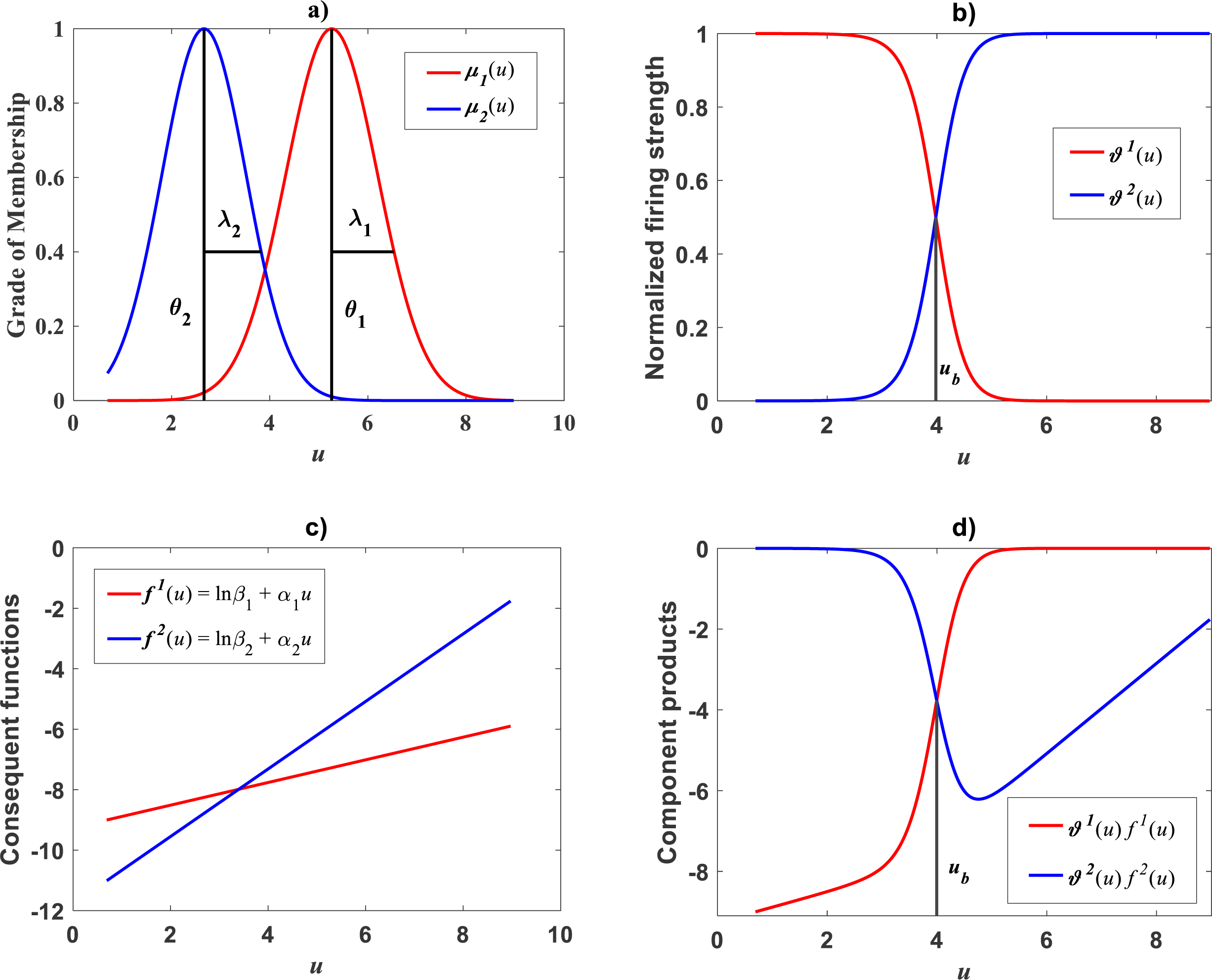{kind=link}
Identification of consequent functions
A second step in the procedure to get vTSK(u, π) concerns acquiring the consequent functions in Eq. (22). Since, for this data, we obtained q = 2, the code ought to establish consequent functions and each one assumed to be linear, that is, (33) and (34)
With the aim of assessing heteroscedasticity, we replaced the forms of and identified by SC technique in regression Eq. (17). In turn the involved consequent functions and were assumed to have both the form given by Eqs. (33) and (34) correspondingly. Then, we assumed the involved ϵTSK residuals to be normally distributed with zero mean, but with a standard deviation set as a function σTSK(u) of the covariate u, Namely (35) where σ and k are parameters to be estimated and such that σ + ku > 1. Table 2 presents maximum-likelihood parameter estimates and associated uncertainties for the related fit. We can ascertain a highly significant fit, since, in all cases the standard error is extremely small, this mainly explained by the large amount of data in the analysis. To judge heteroscedasticity of residuals we study the confidence interval of parameter k. This parameter determines the change in residual variability per unit change in u. It turns out that figures in Table 2 show that confidence interval of parameter k does not include a zero value. Therefore, we may conclude that with high probability the variability of the residuals changes as u changes.
| Residual statistics | ||||
|---|---|---|---|---|
| Minimum | 1Q | Median | 3Q | Maximum |
| −4.4478 | −0.2273 | −5.99 ×10−5 | 0.1936 | 7.5718 |
| Fitting results | |||||
|---|---|---|---|---|---|
| Parameters | Estimate | Std. Error | t value | Pr(>—t—) | Confidence Interval (95%) |
| lnβ1 | −11.7672 | 0.0259 | −454.09 | <2.2 × 10−16 | (−11.8180613 −11.7164792) |
| α1 | 1.1148 | 0.0036 | 302.84 | <4.0 × 10−16 | (1.1076198 1.1220501) |
| lnβ2 | −9.2326 | 0.0803 | −114.93 | <2.2 × 10−16 | (−9.3901440 −9.0752428) |
| α2 | 0.3629 | 0.0278 | 13.02 | <4.2 × 10−39 | (0.3083460 0.4175571) |
| σ | 2.5063 | 0.0169 | 147.93 | <2.2 × 10−16 | (2.4731764 2.5395905) |
| k | −0.1580 | 0.0021 | −73.21 | <2.2 × 10−16 | (−0.1623302 −0.1538654) |
Meanwhile, setting k = 0 in Eq. (35) allowed consideration of a parallel maximum likelihood fit of homoscedastic case of the TSK regression model of Eq. (17). Table 3 provides fitting results. Model performance metrics allow assessment of the fits of the heteroscedastic and homoscedastic versions of the TSK–PLA protocol. Accordingly, we can assert that the heteroscedastic model stands a better fit than its homoscedastic counterpart. Particularly, in the heteroscedastic case we have a negative log-likelihood value of −logL = 6304.60, which turns out to be notably smaller than −logL = 8111.49 obtained for the homoscedastic model. These figures bear a notable difference that backs the selection of the heteroscedastic model. This difference in fit quality favoring the heteroscedastic model is mainly due to the fact that the latter models the pattern of variation of the errors in a more reliable way. Plots of identified consequents appear in Fig. 3C, component products ϑ1(u)f1(u) and ϑ2(u)f2(u) appear in Fig. 3D. As it occurs for the membership functions and firing strength factors for this data the component products also intersect at value of ub = 3.98. This estimate of ub is consistent with value previously reported by Echavarría-Heras et al. (2019a) for this data and deriving from conventional maximum likelihood biphasic regression. Figure 4A displays dispersion about resulting mean response function vTSK(u, π). Figure 4B shows residual scattering about the zero line. Region bounded by red lines determine (95%) confidence intervals. Figure 4C shows corresponding QQ plot.
| Residual statistics | ||||
|---|---|---|---|---|
| Minimum | 1Q | Median | 3Q | Maximum |
| −4.4569 | −0.2264 | 0.0017 | 0.1943 | 7.5545 |
| Fitting results | |||||
|---|---|---|---|---|---|
| Parameter | Estimate | Std. Error | t value | Pr(>—t—) | Confidence Interval (95%) |
| lnβ1 | −11.7029 | 0.0369 | −316.34 | <2.2 × 10−16 | (−11.7754563, −11.6304399) |
| α1 | 1.1047 | 0.0058 | 189.14 | <2.2 × 10−16 | (1.0932778, 1.1161734) |
| lnβ2 | −9.1869 | 0.0562 | −163.27 | <2.2 × 10−16 | (−9.2972775, −9.0767044) |
| α2 | 0.3437 | 0.0205 | 16.69 | <7.1 × 10−63 | (0.3033585, 0.3840624) |
| σ | 0.5273 | 0.0036 | 144.30 | <2.2 × 10−16 | (0.5201765, 0.5345015) |
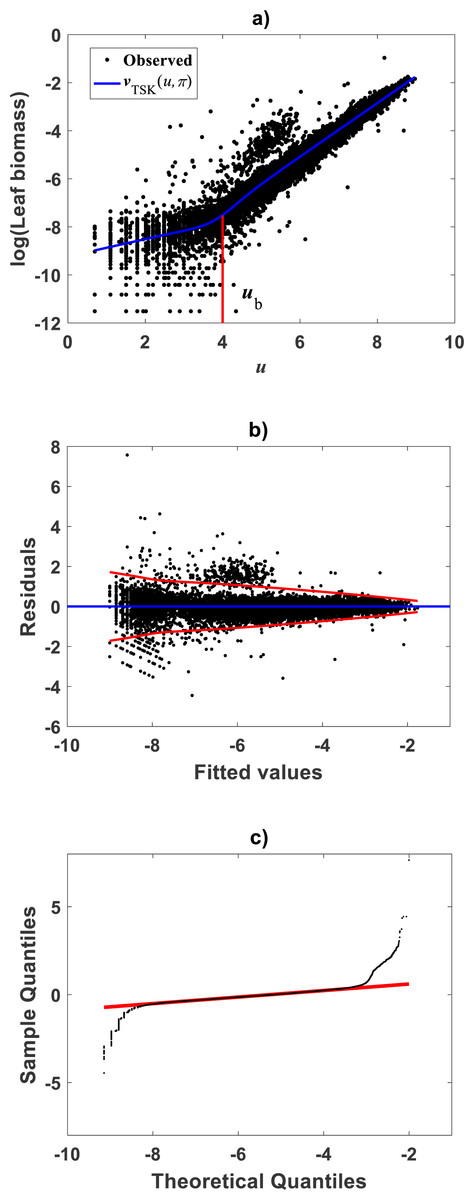
Figure 4: Fitting results of the TSK -PLA model for the Echavarría-Heras et al. (2019a) and Echavarría-Heras et al. (2018b) data set.
(A) shows the dispersion about the mean response curve identified through the regression model of Eq. (17) assuming heteroscedasticity in the form set by Eq. (35). (B) displays residual spread about the zero line. Region bounded by red lines determine (95%) confidence intervals. (C) presents corresponding QQ plot. Opposing a biased spreading about the mean response in Fig. 2A, distribution around the TSK-PLA mean response is fair all over the domain of the log transformed response. It is shown that the breaking point separates two phases conforming the identified non-log linear allometry.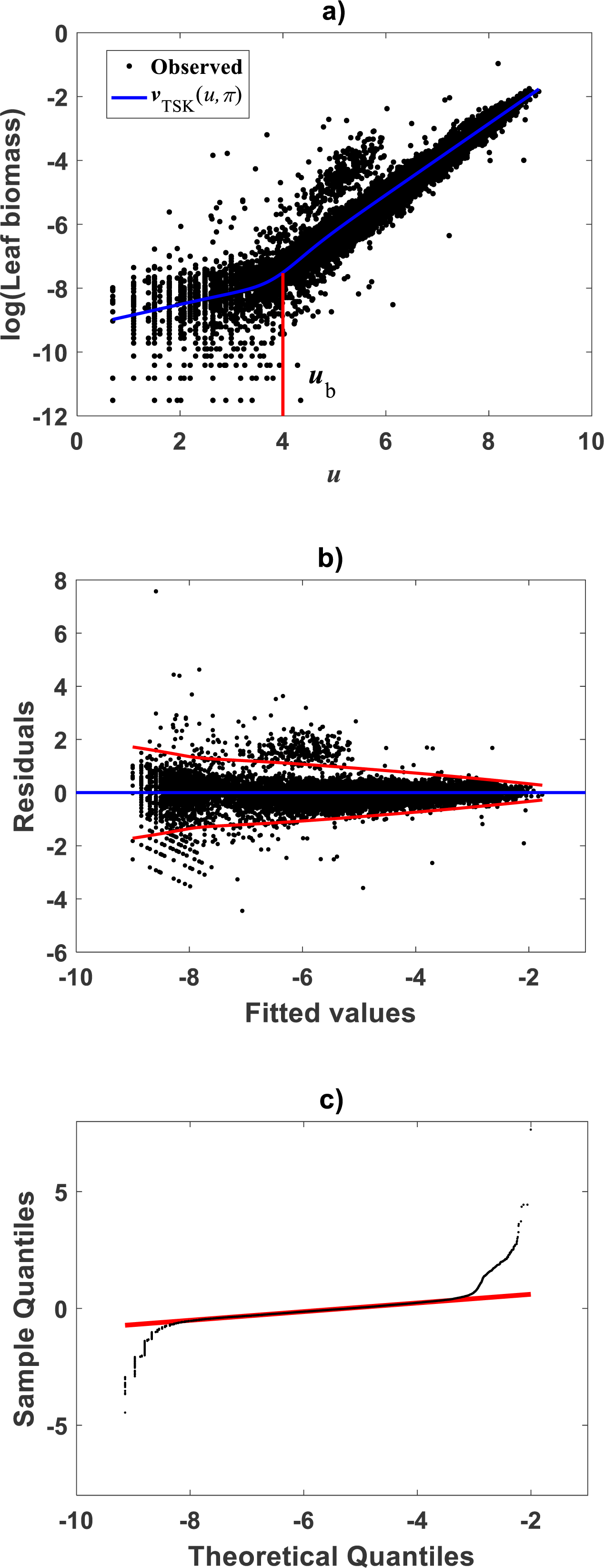{kind=link}
Comparison TAMA vs. TSK–PLA
Compared with corresponding fitting results for the TAMA protocol (Fig. 2A) we can verify that plots in Fig. 4 show fairer residual spread patterns. Nevertheless, the QQ plot in Fig. 4C, still suggest deviation of ϵTSK residuals from a normal distribution pattern. Table 4 allows further comparison of performances of the TAMA and TSK proxies. This undoubtedly favor selection of the TSK scheme. Therefore, opposed to the linear model , the affine characterization of variability granted by vTSK(u, π) can better refer to inherent non-log linear allometry for the Echavarría-Heras et al. (2019a) data set. Certainly, the point ub = 3.98 shown in Fig. 3B can be interpreted as a point separating two phases describing the variation pattern of the log transformed response v. One for small leaves valid over the region u < uc and another for large leaves over u ≥ ub. The form of the component products ϑi(u)fi(u) shows that while u drifts away from ub taking smaller and smaller values the closer the TSK output vTSK(u, π) will be to the component product ϑ1(u)f1(u). Conversely, the larger the distance between u and ubfor leaves in the large phase u ≥ ub the closer vTSK(u, π) will be to ϑ2(u)f2(u). Relating to Es(v|u) shown in Fig. 2A, we can assess from Table 4 and Fig. 4A that the reproducibility strength of ETSK(v|u) is higher. Besides compared with Fig. 2B, the plot in Fig. 4B shows that distribution of residuals about the zero line for the TSK fit improved. Also compared to Fig. 2C, normal QQ plot in Fig. 4C shows a larger plateau where ϵTSK residuals track a normal distribution pattern. Nevertheless, application of an Anderson & Darling (1952) test to the residuals of regression Eq. (17) resulted in AD = 370.17. This associates a p-value <2.2 × 10−16, that provides evidence against a normality assumption for the ϵTSK residuals. This is, in agreement with the observation that he normal Q–Q plot shown in Fig. 4C showing heavier tails than those expected for a normal distribution. It is worth pointing out that the break point ub identified by the fuzzy proxy vTSK(u, π) coincides with corresponding value obtained by Echavarría-Heras et al. (2019a) using conventional biphasic regression methods.
| Method | ra | q | AIC | ρc | R2 | SEE | MPE | MPSE |
|---|---|---|---|---|---|---|---|---|
| – | – | 17928.42 | 0.9375 | 0.8823 | 0.5723 | −0.2077 | 6.4777 | |
| 0.47 | 2 | 16240.77 | 0.9475 | 0.9000 | 0.5276 | −0.1915 | 5.7908 | |
| 0.47 | 2 | 16237.40 | 0.9474 | 0.9000 | 0.5275 | −0.1915 | 5.8064 |
Correspondingly, Fig. 5A displays the plot of the estimated form of the mean response function EgTSK(x|y) of Eq. (19). Since, residuals ϵTSK are not normally distributed, Eq. (10) provided CF form. Figure 5B allows a visual assessment of the extent of biased projections in arithmetical scale tied to the TAMA surrogate Egs(x|y) calculated with Duan’s form of δ. Compared with spread deriving from the TSK model, TAMA’s bias is significant. Besides, Table 4 allows assessment of differences in associated predictive strengths. All indices favor the TSK–PLA scheme. As suggested by perceptible bias shown in Fig. 5B, CCC value for TAMA’s projections point to poor reproducibility of observed values. Besides, relevance of accounting for curvature, this assessment highlights on the importance of choosing a proper form of δ for assuring consistency or retransformation results.

Figure 5: Comparison of TAMA and TSK-PLA mean responses in arithmetical scales fitted on the Echavarría-Heras et al. (2019a) data set.
(A) shows the distribution of observed eelgrass leaf biomass values y about the mean response EgTSK(y|x) (cf. Eq. (19)). Equation (10) provided the form of the correction factor. (B) shows the extent of bias tied to proxies Egs(y|x) calculated through the TAMA scheme and a Duan’s form of the correction factor. (C) exhibits a remarkable correspondence between Eas(y|x) derived from a fit of Huxley’s formula of simple allometry and the asymptotic mean response derived from the TSK-PLA model (cf. Eq. (47)).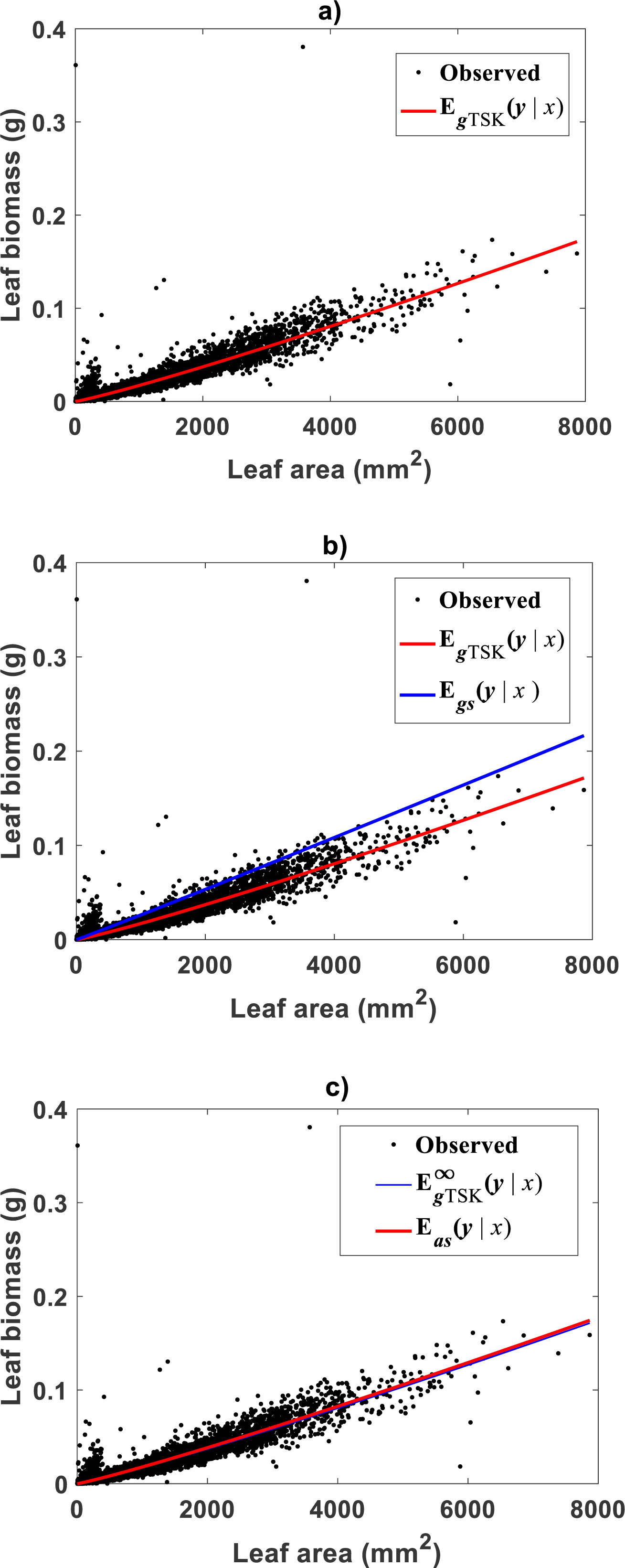{kind=link}
Asymptotic analysis of TSK-PLA assembly
In this section we explain that adoption of a TSK-PLA approach allows exploration of asymptotic behavior of the allometric mean response function in arithmetical space. After replacing and as given by Eqs. (33) and (34) in Eq. (20) direct algebraic manipulation yields (36)
Similarly, it can be directly verified that firing strengths and as given by Eqs. (31) and (32) can be also expressed in the form (37) and (38) where (39) (40) (41) (42) with θ, λ standing for parameter vectors and (λ1, λ2) one to one. We can then ascertain that remains positive for all values of u. Also, the term ,does not depend on u. Consequently, whenever the factor in Eq. (40) is positive, will approach infinity as u approaches infinity. Then, Eq. (37) implies asymptotically vanishing as u approaches infinity. Reversely, whenever is negative, the firing strength factor will asymptotically approach one as u approaches infinity. For the Echavarría-Heras et al. (2019a) data set we obtained , then we must have (43) and since Eq. (A13) implies , we also have (44)
Agreeing with Eqs. (19) and (20) back-transformation ev produces (45)
We denote by means of the symbol, the limit of as x approaches infinity, that is, (46) Then, Eqs. (31), (32) and (44) through (46) imply (47)
Then, the asymptotic mode identified for the Echavarría-Heras et al. (2019a) data set, is attains a form like Huxley’s formula of simple allometry . Estimated parameters are α2 = 1.1126 and β2 = 7.8398 × 10−6. Figure 5C displays observed leaf biomass values y and their projections through the proxy. We can learn of a remarkable correspondence between the power function of Eq. (11) fitted by direct nonlinear regression methods and the asymptotic mean response Besides as established by Eq. (45) we can directly asses from Fig. 5C that for sufficiently large values of x in the Echavarría-Heras et al. (2019a) data set, the mean response EgTSK(y|x) behaves as the power function . Moreover, the order relationship u ≥ ub holds for about 86% of analyzed data. This explains why corresponding phase of the TSK output can be considered dominant. This by the way elucidates the apparent benefit of fitting Huxley’s formula of simple allometry by means of nonlinear regression model directly in arithmetical scale for the considered data. Indeed, such a fitting could deliver reasonable model adequacy results. But, as the present results show direct nonlinear examination based on Huxley’s formula of simple allometry will fail to detect the different allometrical phases conforming the real variation pattern in the data. Then, as we have elaborated a log transformation step followed by nonlinear model identification in geometrical space could overcome the reproducibility deficiency of the TAMA approach.
Fitting results of the TSK-PLA assembly: Metrosideros polymorpha
For trying the main_fun_tsk_pla_model_fit.m function on the Mascaro et al. (2011) data we set ra = 0.80. This returned q = 2, heterogeneity. Figure 6 displays the plots of membership functions μΦi(u), firing strength factors , consequent linear segments and component products identified by the fit of the TSK fuzzy model to the Mascaro et al. (2011) data set. Membership functions are shown in Fig. 6A. Fit suggests heterogeneity determined by a break point ub = 1.575 as shown in Fig. 6B displaying firing strength factors. This estimate of ub is consistent with value previously reported by Echavarría-Heras et al. (2019a) for this data and deriving from conventional maximum likelihood biphasic regression. Break point suggest a growth phase 0 < u ≤ ub and a complementary u > ub. We can interpreted these regions as dominance realms for the component product functions and one to one (Figs. 6C and 6D). Correspondingly, Fig. 7A shows spread about mean response function regions in geometrical space matching identified phases. Moreover, residual plot in Fig. 7B displays a fair distribution about the zero line. And, normal QQ-plot in Fig. 7C shows a large plateau where residuals track a normal distribution pattern. We can also ascertain from goodness of fit statistics in Table 5, that compared to the linear regression scheme of the TAMA protocol, the affine modeling approach composing the TSK-PLA scheme entails consistent identification of curvature in geometrical space.

Figure 6: Elements of the TSK-PLA fuzzy model identified on the Mascaro et al. (2011) data set.
Shown results associated to a value ra = 0.80 for the clustering radius and corresponding to a q = 2, heterogeneity index. (A) plots of membership functions both given in the Gaussian form of Eq. (21). (B) presents plots of normalized firing strength factors given by Eqs. (31) and (32) one to one. A break point at ub = 1.575 is shown. (C) displays consequent linear functions as given by Eqs. (33) and (34). (D) portraits component products.{kind=link}
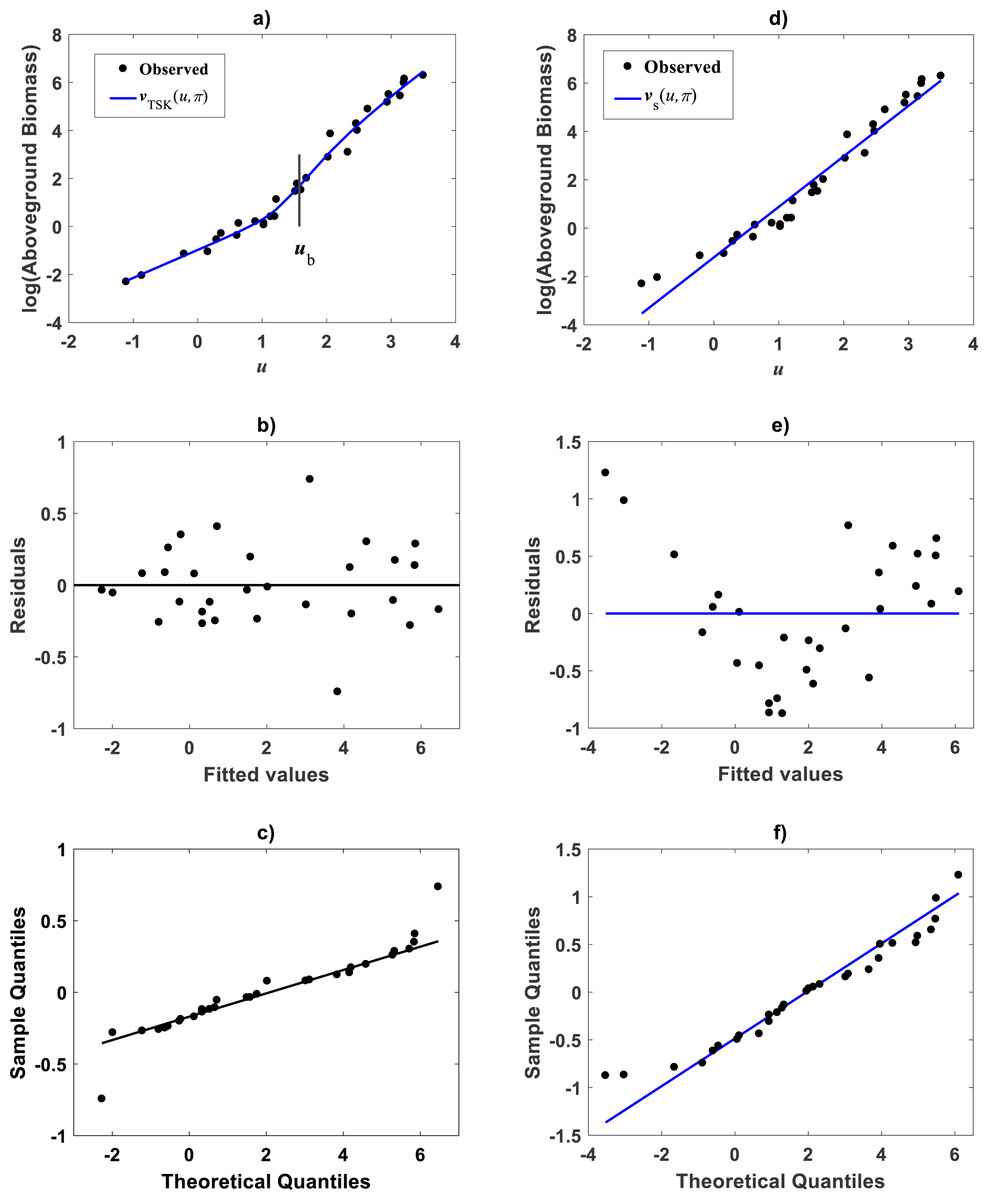
Figure 7: Spread plots for the TSK-PLA model fitted on the Mascaro et al. (2011) data set.
The spread about the TSK-PLA mean response displays remarkable reproducibility and consistency of biphasic allometry (A). The residual plot displays a fair spread about the zero line (B). The Normal-QQ plot shows a large plateau where residuals track a normal distribution pattern (C). (D–F) show the spread about mean response, residual and QQ-plot of TAMA’s fit to this data one to one.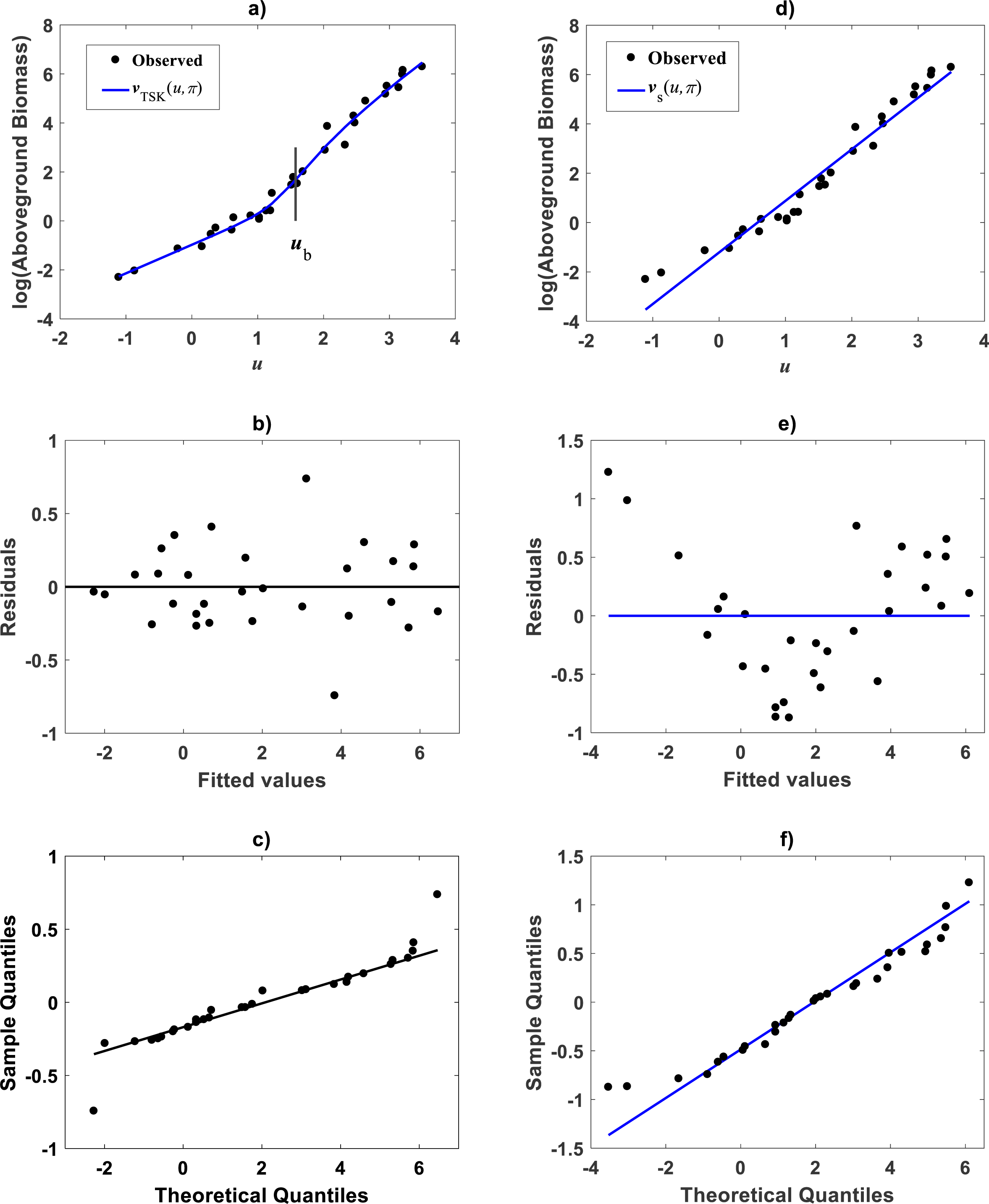{kind=link}
Identification of the TSK-PLA proxy: Uca pugnax
Huxley conceived a breakpoint in the log–log plot of chela mass vs. body mass of fiddler crabs (Uca pugnax) (Huxley, 1924; Huxley, 1932). Huxley situated this point between the 15th and 16th observations and assumed it meant a to a sudden change in relative growth of the chela approximately when crabs reach sexual maturity. Examination of Huxley’s data by Packard (2012a) implied such a break point to be only putative and in Packard’s own interpretation, perhaps explained by the fact that Huxley could have been misled by the effects of the log transformation itself, along with the format of graphical display that might have exaggerated the slopes of segments before and after the change point. In order to test the performance of the TSK-PLA protocol in analyzing Huxley’s Uca pugnax data, we took averages of both body mass and chela mass form Table 1 in Huxley’s report (Huxley, 1932). Concurrent log transformed values appear in Fig. 1C. For easy of presentation a break point as conceived by Huxley’s will be denoted here through the symbol ubH. One substantial advantage of the fuzzy logic approach over conventional probabilistic slants is that the former facilitates knowledge based modeling. In order to incorporate previous knowledge, we we abided by Huxley’s assertion of biphasic allometry in Uca pugnax. Then, we examined heterogeneity patterns predicted by the TSK-PLA system for different values of clustering radius ra. Particularly, setting ra = 0.8 returned q = 2, arranging biphasic allometry. Acquired firing strengths appear in Fig. 8A, exhibiting a break point at ub = 5.831. Figure 8B display consequent linear functions with estimated slopes α1 = 1.2676 and α2 = 1.4708 one to one respectively. In the settings of performed TSK-PLA analysis these correspond to exponents characterizing allometric phases as conceived in Huxley’s original theoretical standpoint. Correspondingly, Fig. 8C portrays consequent component products and . Similarly, Fig. 8D shows spread about mean response vTSK(u, π) including placement of ub in a display in compliance with that in Fig. 3 in Huxley (1932). We can be aware that location of ub is shifted back relative to ubH. Figure 8E displays placement of ub and spread about vTSK(u, π) in the original scale of data (cf. Fig. 1C). But instead, we may integrate previous knowledge by considering for that the break point ubH actually exists. Then, we can search among different values of ra, the one for what the TSK-PLA arrangement compromises a break point ub placed as ubH and also a maximum reproducibility strength of interpolation by . Accordingly, setting ra = 0.2 brought about q = 7 sub models, inducing a maximum reproducibility strength of interpolation function and where ubI, one of six detected break points is placing as ubH. (Fig. 8E and Table 6). Interestingly, visual examination of plot showing suggests a pattern accommodating two linear segments that alternate about ubI. Moreover, using the interpolation points we fit two linear segments of slopes α1I = 1.626 and α2I = 1.274 before and after ubI one to one (Fig. 8F). Since ubI. can be taken as a proxy for ubH the TSK-PLA interpolation mode could suggest Huxley’s reasoning of biphasic allometry in in Uca pugnax as consistent. In the meantime acquired q = 7, interpolation confirms the outstanding capabilities of the TSK-PLA device to approximate the dynamics of the logtransformmed allometric response. This can be better ascertained from Fig. 9A through Fig. 9C presenting spread about the high order interpolation function , as well as, concomitant residual and QQ plots in conforming order. Moreover, Fig. 9D through Fig. 9F allow visual comparison of parallel results by a TAMA’s fit. Additionally, Table 6 compares model performance metrics for the TSK-PLA interpolation and TAMA’s output fits. We can ascertain that the TSK-PLA interpolation stands a better fit. In any event, the non-probabilistic interpretation of uncertainty backing the TSK–PLA approach seems to advocate biphasic heterogeneity in geometrical space for Huxley’s Uca pugnax data.
| Method | ra | q | AIC | ρc | R2 | SEE | MPE | MPSE |
|---|---|---|---|---|---|---|---|---|
| —- | — | 53.4608 | 0.9767 | 0.9544 | 0.5712 | 10.5825 | 47.7494 | |
| 0.80 | 2 | 23.4700 | 0.9943 | 0.9888 | 0.3200 | 5.9292 | 24.4923 |
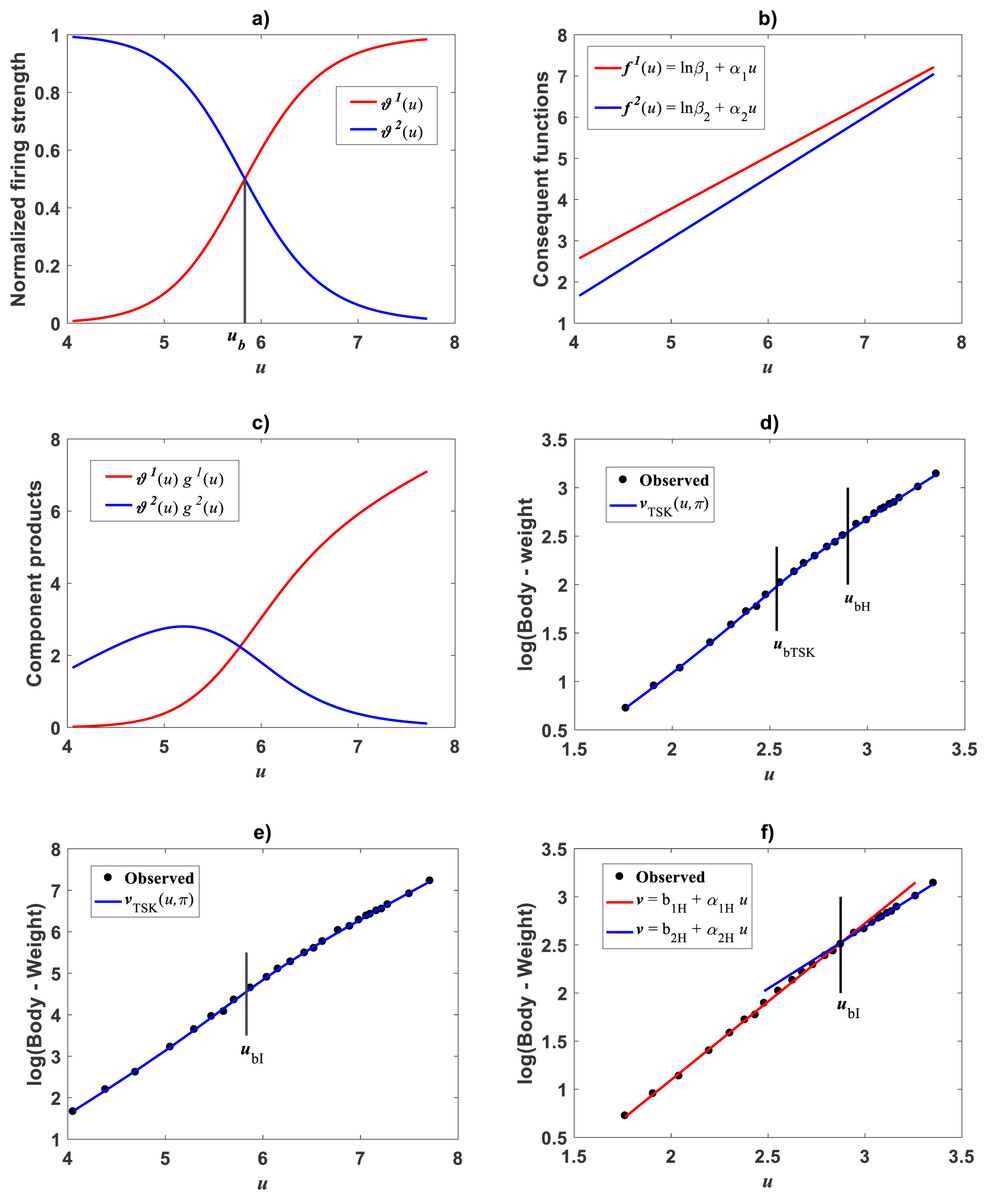
Figure 8: TSK-PLA model identified on Huxley (1932)Uca pugnax data.
For ra = 0.8 the fuzzy inference system returned q = 2 heterogeneity. (A) exhibits firing strengths intersecting at a break point ub = 5.813 in original log scales. (B) acquired linear consequents. (C) component products. (D) shows position of ub relative to Huxley’s break point ubH in a display conforming that in Fig. 3 of Huxley (1932). (E) spread about TSK-PLA interpolation function produced by ra = 0.2 and q = 2 in original log scales. This plot shows ubI = 6.78 one of detected breakpoints. This can be considered as a proxy for Huxley’s designated break point ubH. Interpolation results in (E) suggest the biphasic arrangement of linear segments about ubI shown in (F).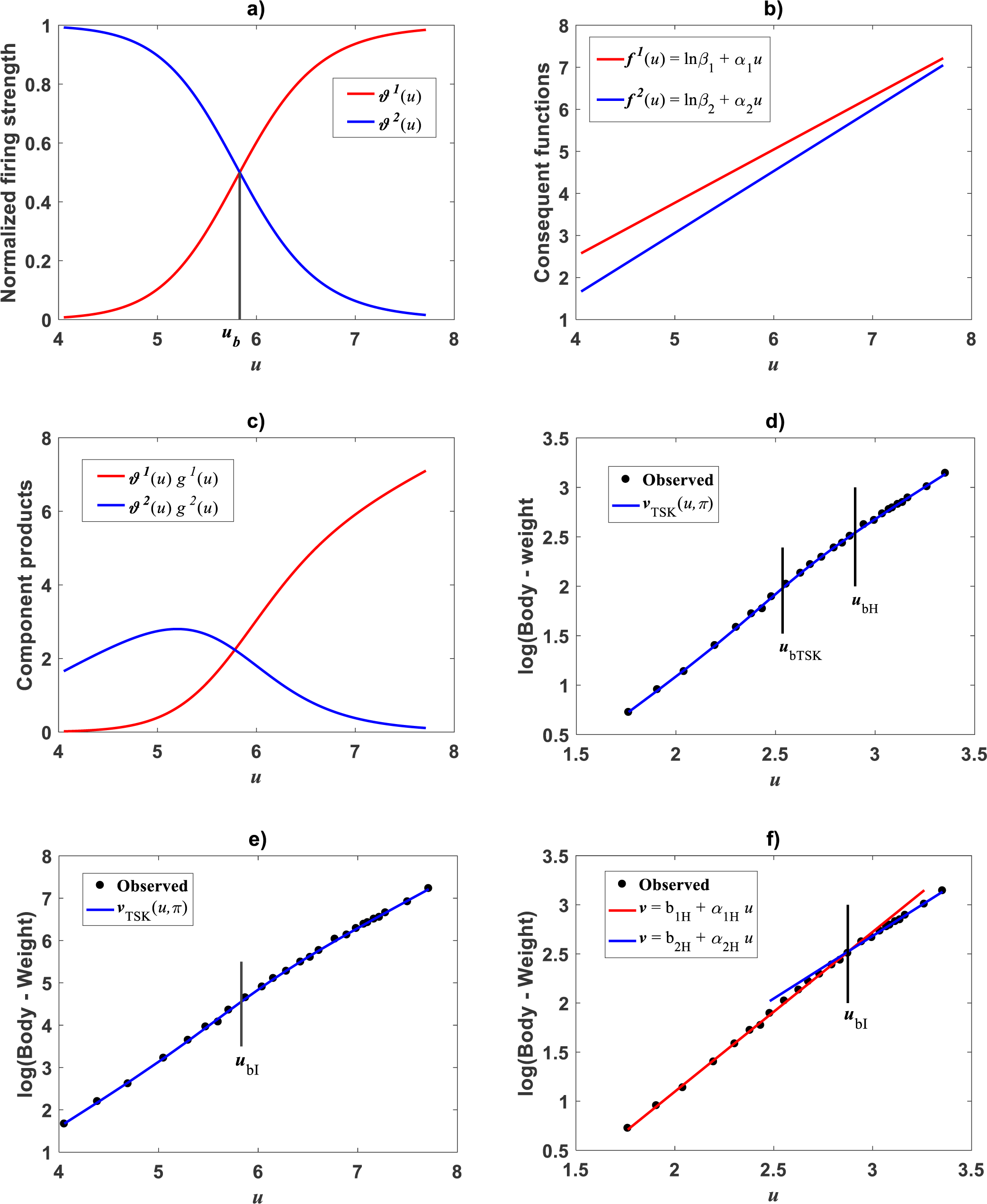{kind=link}
| Method | ra | q | AIC | ρc | R2 | SEE | MPE | MPSE |
|---|---|---|---|---|---|---|---|---|
| – | – | −51.4477 | 0.9986 | 0.9972 | 0.0832 | 0.6519 | 1.5399 | |
| 0.8 | 2 | −97.8184 | 0.9999 | 0.9997 | 0.0301 | 0.2359 | 0.4239 | |
| 0.2 | 7 | −127.57 | 0.9999 | 0.9999 | 0.0166 | 0.1301 | 0.2058 |
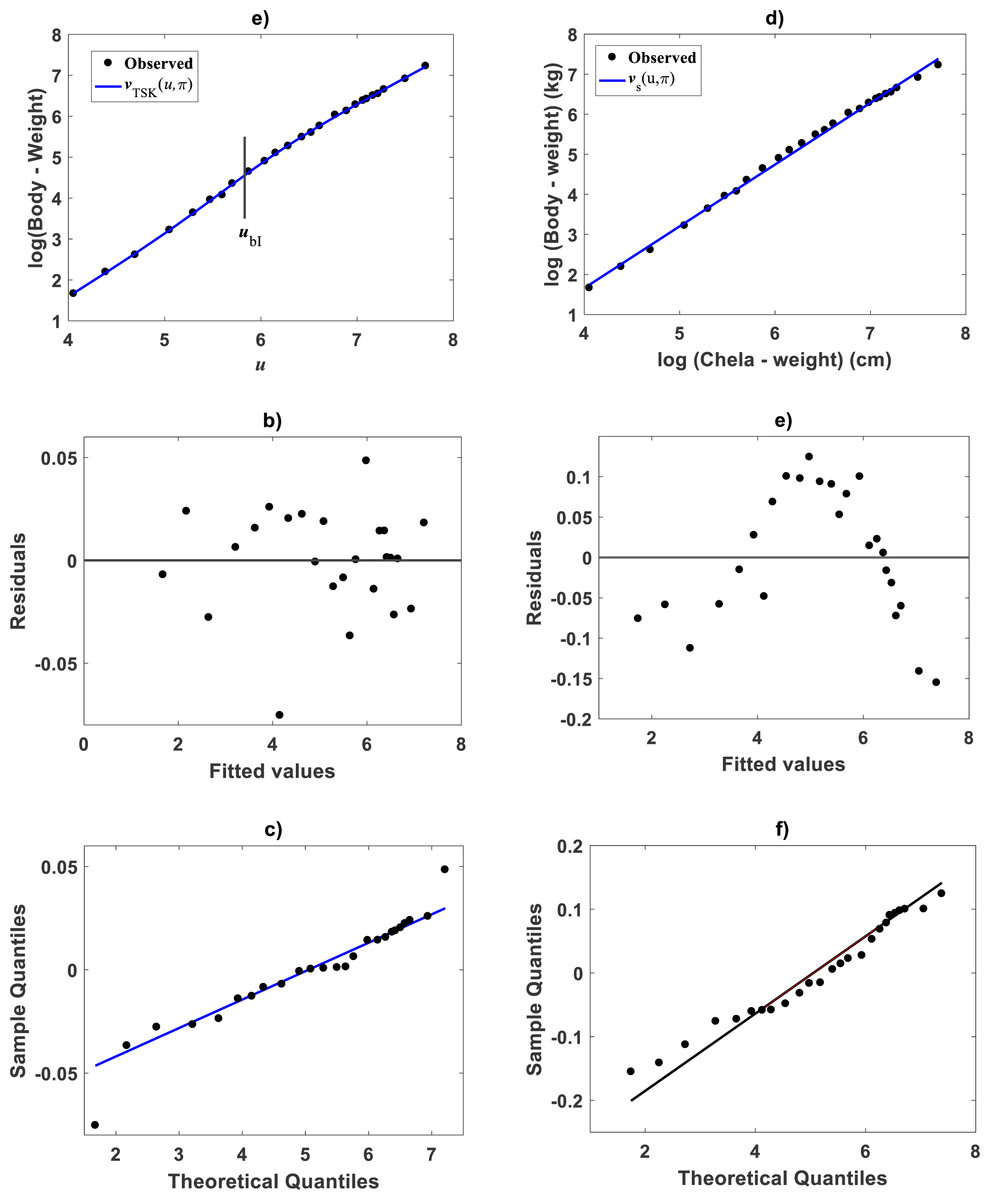
Figure 9: Comparison TAMA vs. TSK-PLA fuzzy model fitted on Huxley (1932)Uca pugnax data.
(A) exhibits spread about TSK-PLA mean response as determined by a ra = 0.8 and q = 2 fit on Huxley’s Uca pugnax data. Associating residual and QQ-plots are shown in (B) and (C) one to one. (D) trough (F) display corresponding spreads produced by TAMA’s fit to referred data.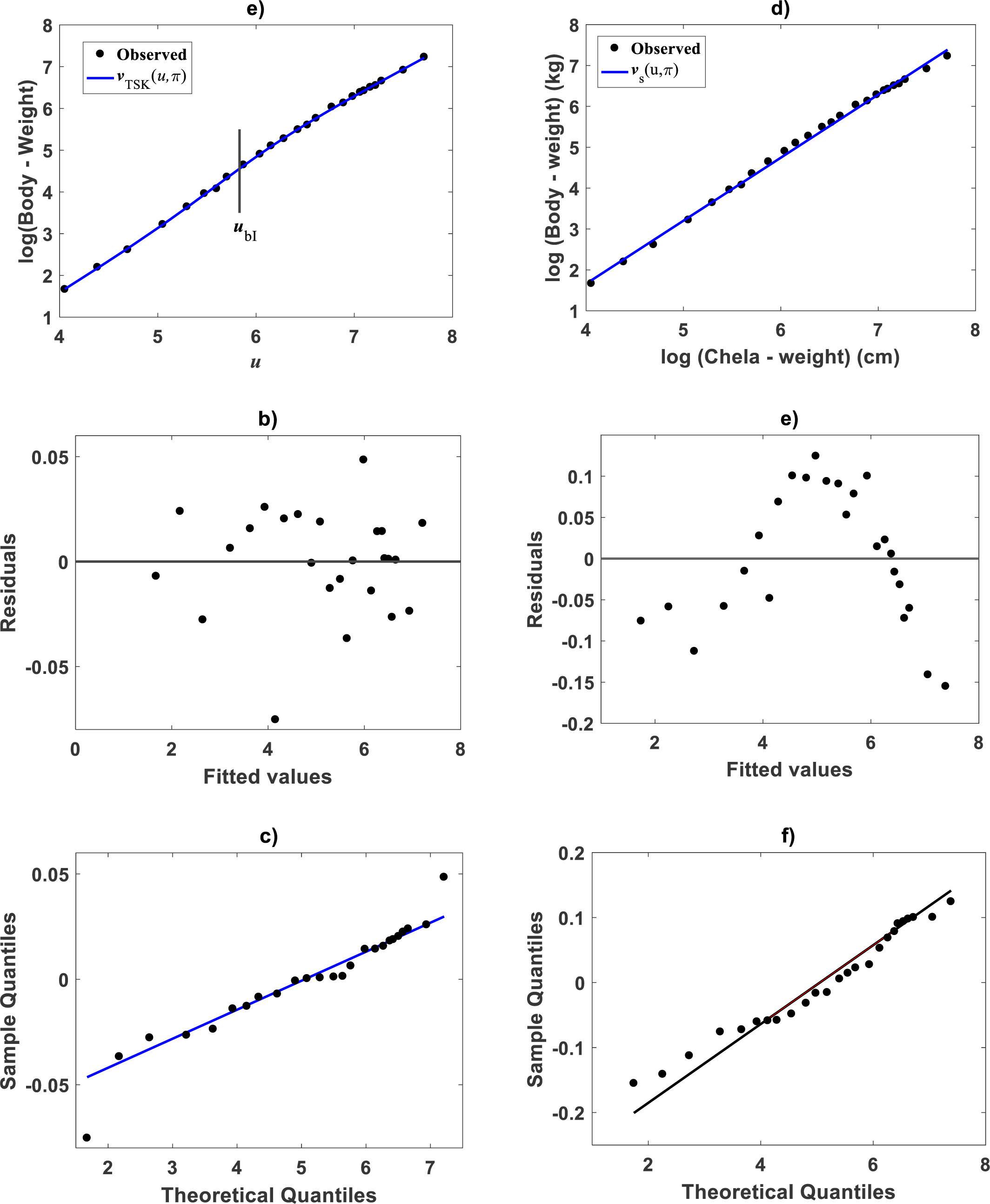{kind=link}
Fitting results of the TSK- PLA assembly: Gadus chalcogrammu
A fit of the TSK-PLA protocol to Gadus chalcogrammu data reported in De Robertis & Williams (2008), can exhibit reliability of this paradigm in further way. Visual examination of spread in geometrical space may suggest curvature. But, setting ra = 0.5 led to highest reproducibility of vTSK(u, π) characterized in a linear form. Indeed, plots in Fig. 10 show that identification of the TSK-PLA model for this data, produced only one membership function μΦ1(u) (Fig. 10A). This corresponds to a firing strength set to one (Fig. 10B), and a conforming single TAMA’s form linear consequent (Fig. 10C). This matched the single linear component product function shown in Fig. 10D. As a result, no heterogeneity as determined by breaking points ub was detected for this data. Consequently, the TSK arrangement suggests a fit equivalent to the TAMA approach. Moreover, spread abut mean response, residual and Normal QQ-plots for a TAMA fit performed in this data (Fig. 11A through Fig. 11C respectively) seem to faithfully agree to corresponding plots (Fig. 11D, through Fig. 11F) associating to the TSK-PLA fit. In turn model performance metrics in Table 7 corroborate these alternate fits as equivalent. Therefore, the TSK-PLA assembly seemingly adapts required complexity. This supports judgement on this paradigm being considered as a generalized tool for allometric examination in geometrical space.
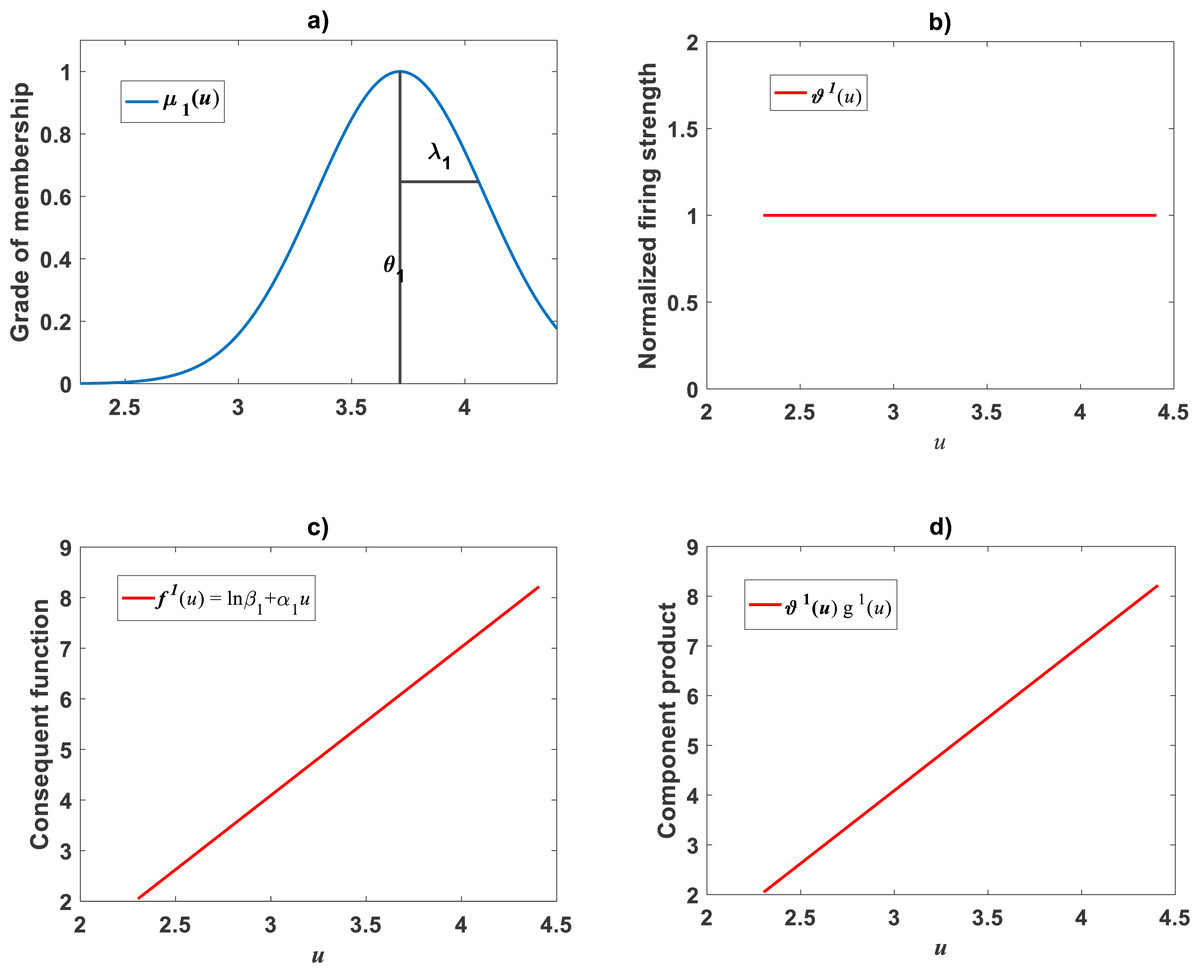
Figure 10: Elements of the TSK-PLA model identified on the De Robertis & Williams (2008) data.
A single membership function in the Gaussian form given by Eq. (21) is shown in (A). Corresponding firing strength is displayed in (B). Consequent function appears in (C). Component product appears in (D). These components rule out nonlinearity in geometrical space, suggesting consistency of a TAMA approach.{kind=link}
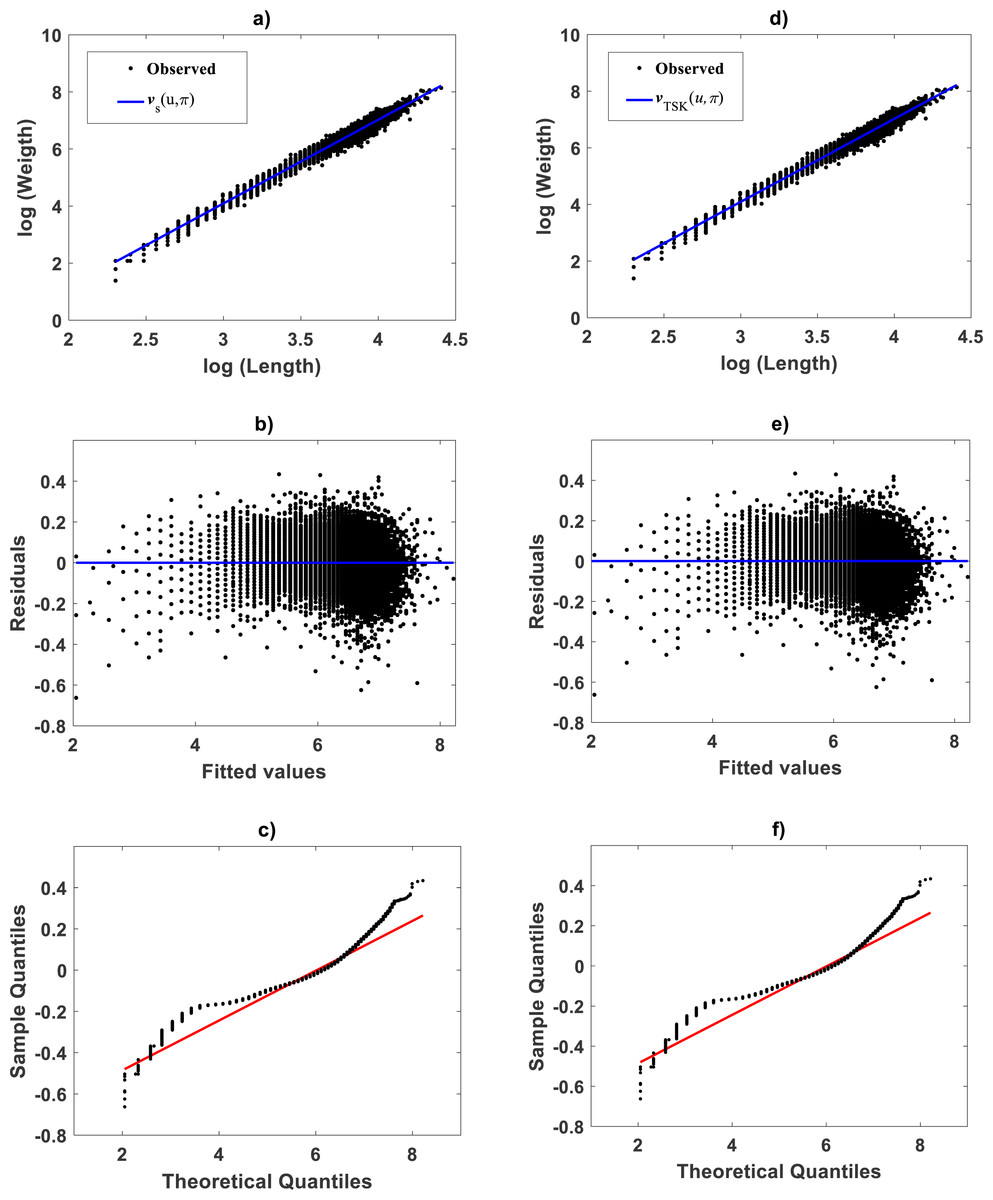
Figure 11: Comparison of TAMA and TSK-PLA fuzzy model fitted on the De Robertis & Williams (2008) data set.
(A–C) display spread about mean response, residual plot and QQ-Normal plot for the fit of the TAMA protocol one to one. (D–F) present corresponding plots for the fit of the TSK fuzzy model.{kind=link}
Assembly of the TSK- MPCA proxy
We assume that as intended for MPCA can be modeled by as expressed by means of Eq. (A14), in arithmetical space, namely (48) with firing strengths given by (49) being μΦi(x) for i = 1, 2……..q the involved membership functions. We also undertake that both and x remain positive, and that (50)
| Method | ra | q | AIC | ρc | R2 | SEE | MPE | MPSE |
|---|---|---|---|---|---|---|---|---|
| – | – | −55181 | 0.9940 | 0.9881 | 0.0945 | 0.0185 | 1.274 | |
| 0.5 | 1 | -55169 | 0.9941 | 0.9882 | 0.0946 | 0.0186 | 1.274 |
This sets the imput space X to be R+. We then contemplate that membership functions can be expressed through a composite log normal form that satisfies the constrain by Eq. (50), namely (51) where c = (1 − e)−1 and (52) with θi and λi for i = 1, 2, …., q parameters. Correspondingly we consider the consequents to be linear functions, that is, (53)
It is worth recalling that Eq. (15) provides the form of linked regression protocol.
Identification of as given by Eq. (48) through Eq. (53) from data pairs (y, x) in direct scale is performed by means of the Matlab function main_fun_tsk_mpca_model_fit.m supplied in the supplemental files section. Heterogeneity and reproducibility strength features of can be explored in an interactive way through different characterizations of the clustering radius parameter ra as specified by Eq. (B7) through Eq. (B9).
Identification of the TSK–MPCA proxy: Zostera marina
For the Echavarría-Heras et al. (2019a) data a try of the main_fun_tsk_mpca_model_fit.m code setting ra = 0.5416 returned q = 2 for a biphasic mode and a maximum reproducibility of Figure 12A displays acquired firing strength functions. The estimated break point was xb = 49.632 consistent with the retransformed value of ub = 3.9 for this data set. This means that variability of the response y indeed conforms to a MPCA pattern in the direct scale of data. Corresponding spread about fitted mean response function appear in Fig. 12B. This plot allows comparison to its counterpart produced by retransformation of mean function vTSK(u, π) to arithmetical space. We can be aware of remarkable correspondence through x values. This validates adequacy of a TSK-PLA analysis for this data. Figures 12C and 12D show residual spread and QQ-plot for the TSK-MPCA fit. Figures 12E and 12F show corresponding plots for retransformed TSK-PLA fit. Besides Table 8 allows assessment of addressed proxies through model performance metrics. This could endure a judgement that concurrent MPCA pattern in arithmetical space can be consistently characterized by retransformation of PLA results.
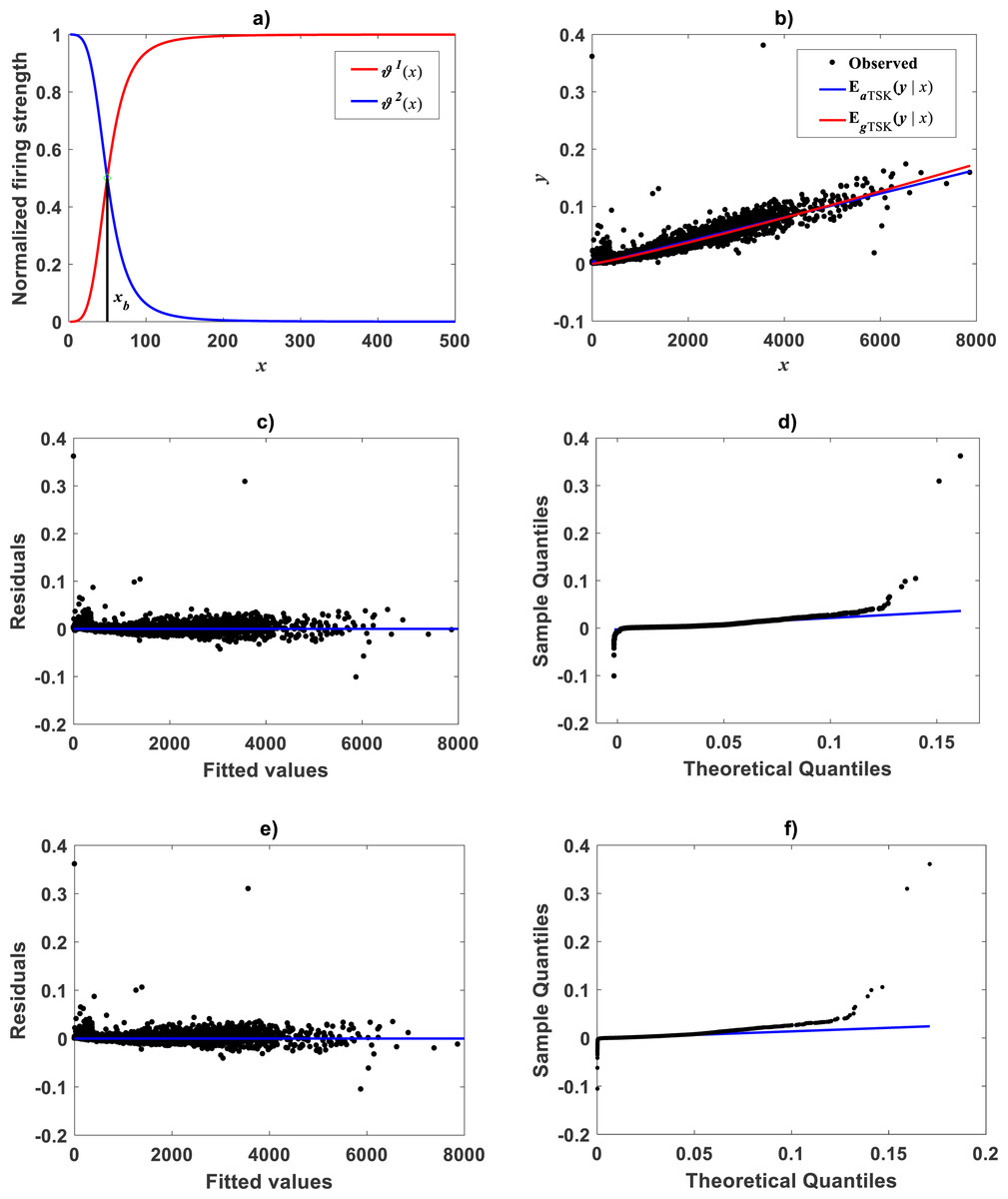
Figure 12: TSK-MPCA fitted on the Echavarría-Heras et al. (2019a).
Setting ra = 0.5416 returned q = 2 for present eelgrass data analyzed by means of the TSK-MPCA fuzzy model of Eq. (48) through Eq. (53). (A) firing strength factors detecting a break point placed at xb = 49.632. (B) spread about fitted mean response function EaTSK(y|x) compared to EgTSK(y|x) derived from retransformation of the TSK-PLA output. We can be aware that reproducibility strengths are equivalent. This can be stressed by performance metrics in Table 8. (C) through (D) presenting residual and QQ-plots confirm equivalence of EaTSK(y|x) and EgTSK(y|x).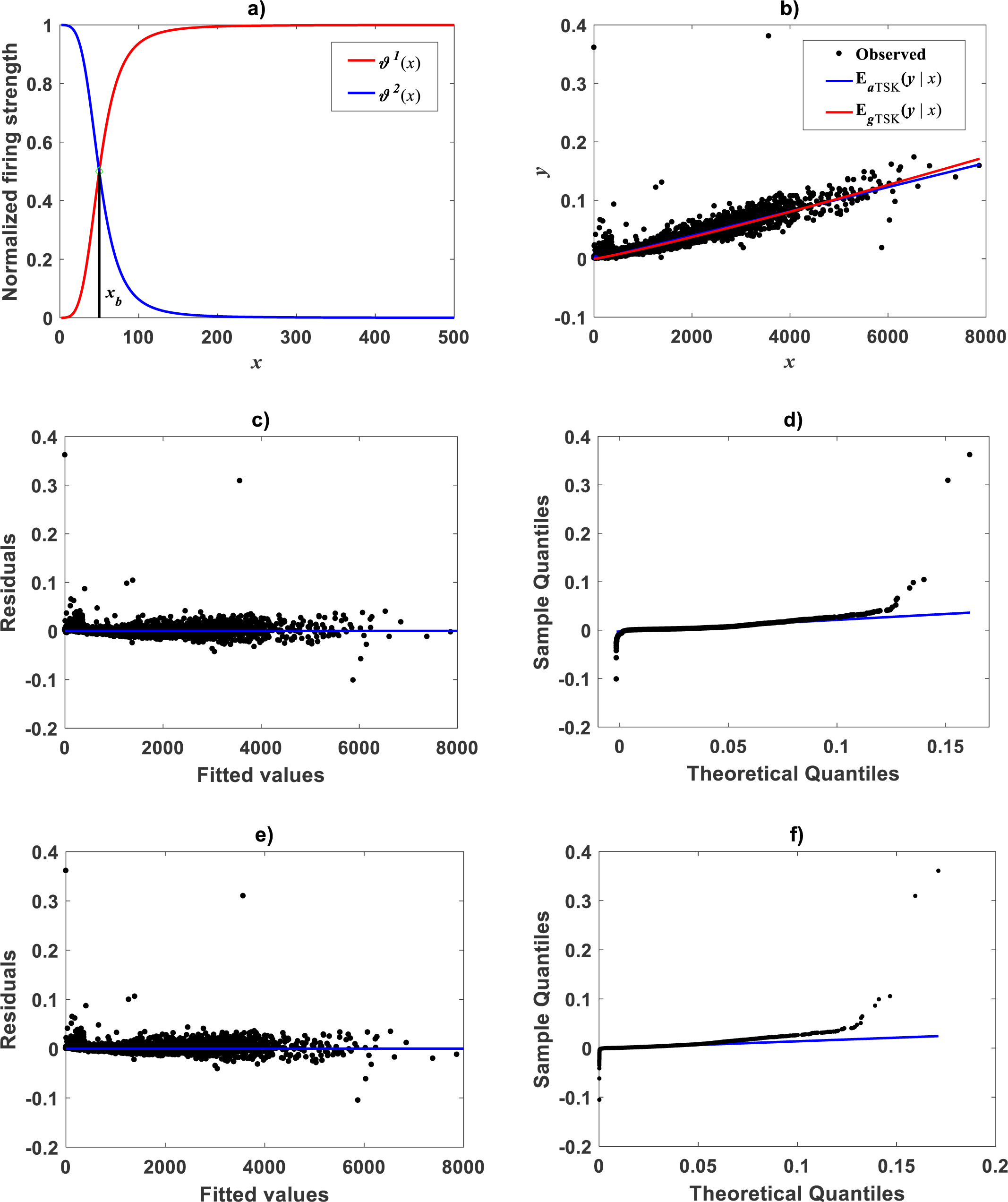{kind=link}
Identification of the TSK-MPCA proxy: Metrosideros polymorpha
Correspondingly, taking as previous knowledge a manifestation of biphasic allometry as detected by the TSK-PLA scheme, for the Mascaro et al. (2011), we examined the possibility of the TSK-MPCA arrangement identifying a similar pattern in direct scales. Indeed, by setting ra = 0.855 the main_fun_tsk_mpca_model_fit.m function returned q = 2 for a biphasic mode and a of reliable reproducibility. Identified firing strengths, display in Fig. 13A. Again analysis in direct scale detected by the TSK-MPCA approach corroborates the consistency of break point allometry assumption for this data. We can learn of a break point estimated at ab = 8.8662. This estimate is consistent with resulting from a two linear segment mixture regression model performed by present authors. Spreads about fitted mean functions shown in Fig. 13B reveal remarkable correspondence of projections by EaTSK(y|x) and EgTSK(y|x). This can be stressed by performance metrics in Table 9. In turn this demonstrates adequacy of a TSK-PLA approach for the analysis of this data. Figures 13C and 13D display residual and QQ plots for TSK-MPCA fit to Metrosideros polymorpha. Equivalent plots associating to the retransformed TSK- PLA are displayed in Figs. 13E and 13F, correspondingly. Exploring interpolation capabilities of the TSK-MPCA for this data led to considering an alternate clustering radius set at a value ra = 0.52. Resulting heterogeneity index was q = 3 that resulted in good model assessment metrics (Table 9) and a break point placed at xb = 4.832. This is in agreement with retransformed TSK-PLA estimation for this data. Nevertheless, forcing an interpolation mode of the TSK-MPCA to achieve a break point placed in agreement with previous estimation brings about complexity that renders biological interpretation difficult.
| Method | ra | q | AIC | ρc | R2 | SEE | MPE | MPSE |
|---|---|---|---|---|---|---|---|---|
| 0.5416 | 2 | −73038.16 | 0.9294 | 0.8678 | 0.007 | 1.0993 | 59.31 | |
| 0.47 | 2 | −73107.75 | 0.9282 | 0.8688 | 0.007 | 1.0956 | 63.00 |
Identification of the TSK-MPCA proxy: Uca pugnax
Firing strengths, of a ra = 0.668, q = 2, TSK-MPCA fit to Huxley’s Uca pugnax data set are displayed in Fig. 14A. We can be aware of heterogeneity as corresponds to dominance of sub models before and after the break point placed at xb = 340.7, matching exp(ub) with ub = 5.83 the break point determined by a TSK-PLA fit to this data. Figure 14B show spread about resulting mean function EaTSK(y|x) and compares to EgTSK(y|x) gotten by retransformation of fitted TSK-PLA. Plot suggest equivalent reproducibility strengths. Nevertheless as it can be made certain by model performance metrics in Table 10 the EgTSK(y|x) proxy entails relatively higher reliability. Figures 14C and 14D one to one show residual and QQ plots corresponding to the TSK-MPCA fit. Similarly, residual and QQ plots for the back-transformed TSK-PLA fit appear in Figs. 14E and 14F. Table 10 also includes performance metrics for EgTSK(y|x) gotten by retransforming the output of the ra = 0.2 and q = 7, fit of the TSK-PLA. We can assert that resulting interpolation EgTSK(y|x) yields a relatively better fit. Therefore, results of the retransformed form of a TSK-PLA approach entails consistent results in direct scales. In other words, logtransformation based procedures do not lead to biased results for this data. But above all, results of a TSK-MPCA fit could provide a clue clearing an apparent misinterpretation of Huxley about existence of a break point in his analysis of Uca pugnax data. Indeed, as stated above we have . This implies ub being the image of ab under logtransformation. Then, claiming existence of ub attributable to distortion set by a logtransformation itself is inappropriate. Agreeing with Packard (2012a), we have no doubt that conventional statistical methods do not put up with existence of ub as detected by the present fuzzy inference system. But, this fact cannot be exhibited to question fuzzy methods. These relying in non-probabilistic approaches have provided reliable interpretation of uncertainty as it can be inferred by fuzzy approach solutions to many problems of identification and control of nonlinear systems.
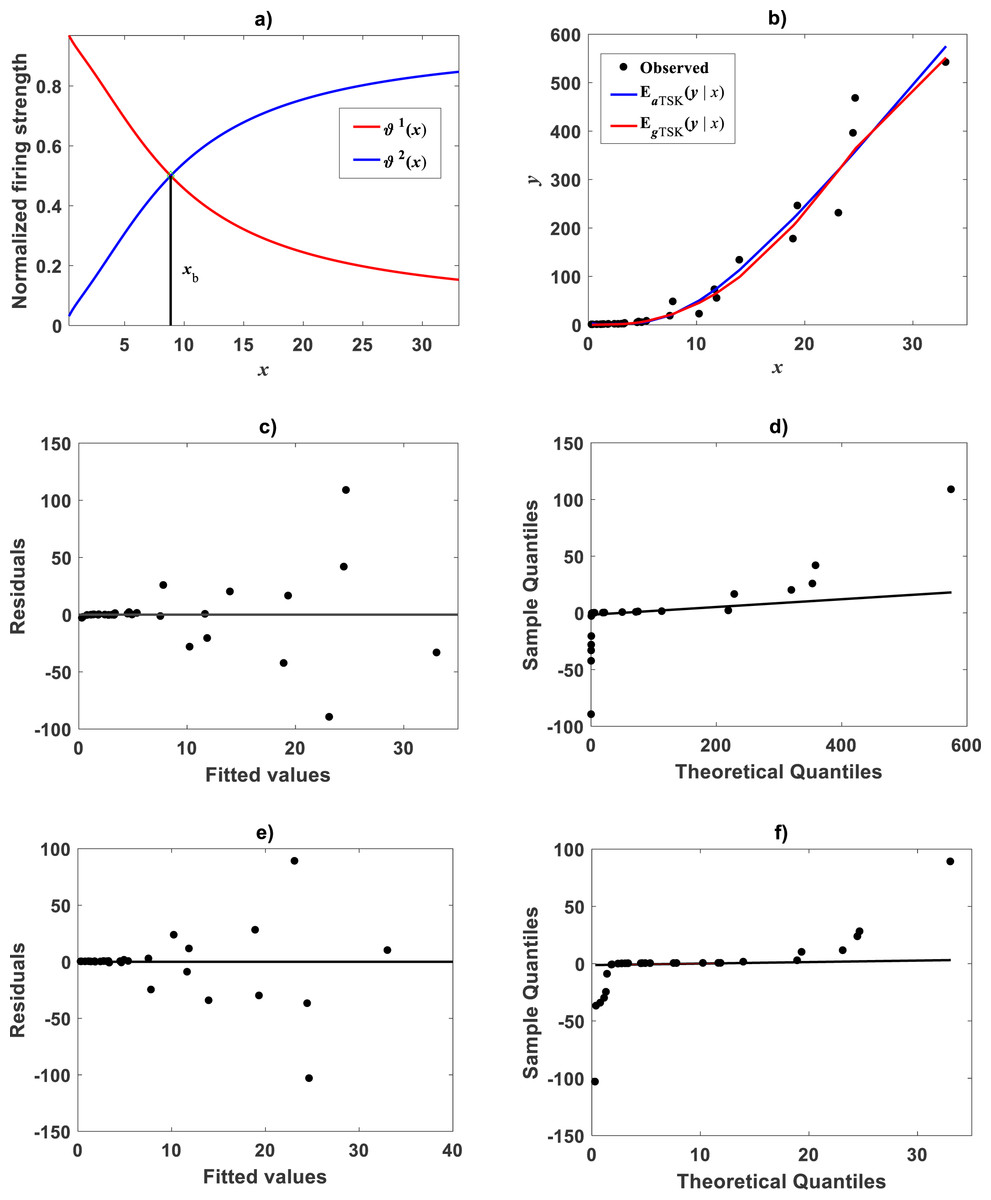
Figure 13: TSK-MPCA fitted on Mascaro et al. (2011) data set.
(A) displays the q = 2 firing strength factors deriving from a ra = 0.855 of the TSK-MPCA fit. We can learn of a break point estimated at xb = 8.8662. Spreads about fitted mean functions shown in Fig. 13B reveal remarkable correspondence of projections by EaTSK(y|x) and EgTSK(y|x). This can be stressed by performance metrics in Table 9. (C) and (D) residual and QQ plots for TSK-MPCA fit one to one. Equivalent plots for retransformed results of TSK- PLA fitted on this data are displayed in (E) and (F).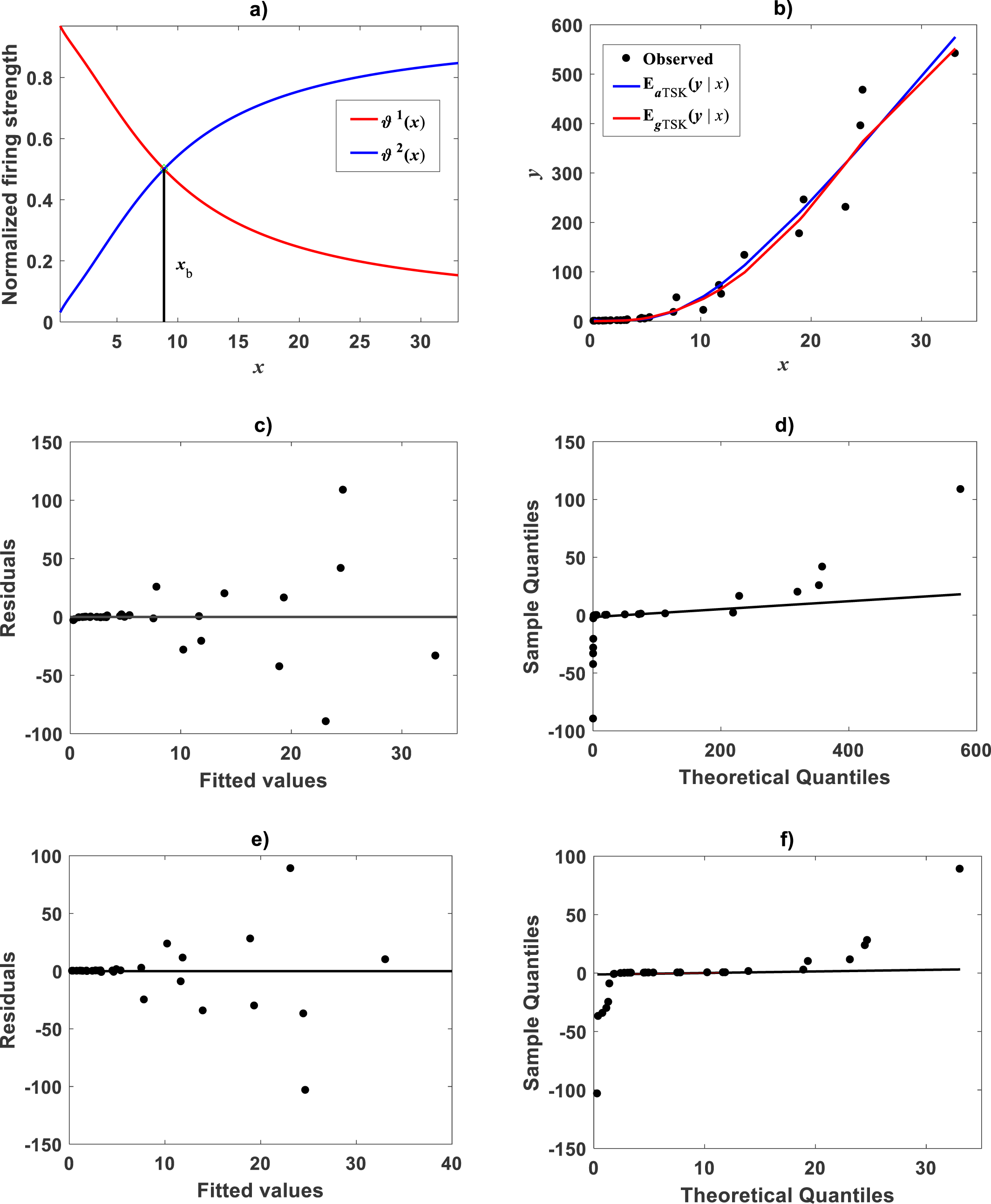{kind=link}
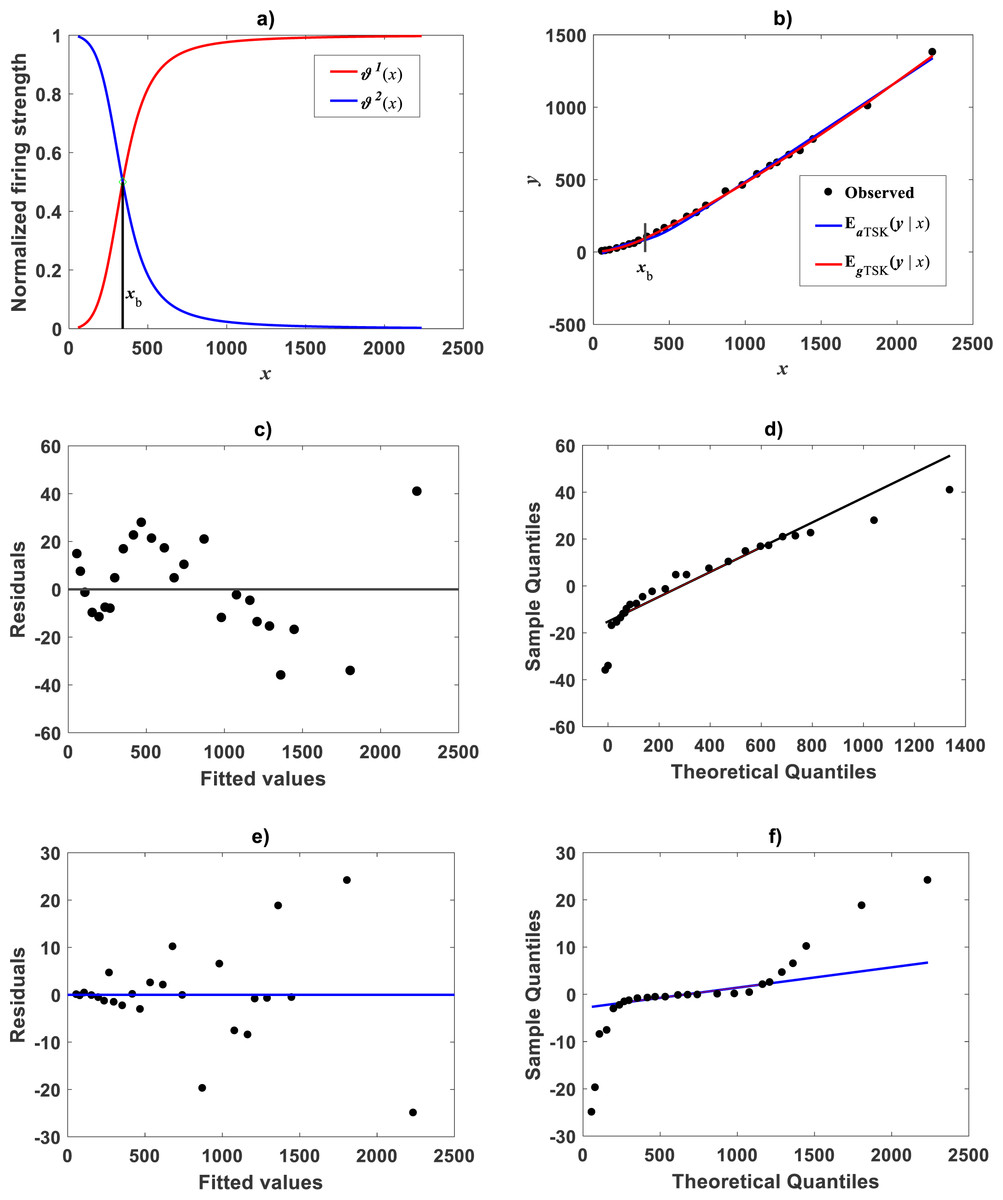
Figure 14: TSK-MPCA fitted on Huxley (1932)Uca pugnax data.
(A) displays the q = 2 firing strength factors deriving from an ra = 0.668 fit of the TSK-MPCA. A break point places at xb = 340.7. (B) shows spread about resulting mean function EaTSK(y|x) and compares to EgTSK(y|x) gotten by retransformation of fitted TSK-PLA. Plot suggest corresponding reproducibility strengths. Nevertheless, as it can be made certain by model performance metrics in Table 10, the EgTSK(y|x) proxy entails relatively higher reliability. (C) and (D) display residual and QQ plots one to one for EaTSK(y|x). (E) and (F) show corresponding plots for EgTSK(y|x). We may be aware that log-transformation based procedures do not lead to biased results for this data.{kind=link}
Identification of the TSK-MPCA proxy: Gadus chalcogrammu
When we assessed the performance of the TSK-MPCA device on the De Robertis & Williams (2008) data we found results consistent to the TSK-PLA fit reported above. Indeed, a TSK-MPCA analysis based on ra = 0.50 for this data returned q = 1, for a single membership function. This consequently associates to a single firing strength . As a result, we have to contemplate a single component product of a linear form in Eq. (48). No break point composed heterogeneity in direct scales can be verified for this data. Moreover, implied linear form of Eq. (48) does not fit required complexity in direct scales. Nevertheless, previous knowledge on consistency of corresponding TSK-PLA fit suggest using the interpolation features of TSK-MPCA to grant adequacy. For this empirical aim, for instance taking the clustering parameter ra = 0.22 in Eq. (B7) we can manage to obtain an heterogeneity index of q = 3. This entails three sub models composing Eq. (48). Figures 15A through 15C display spread about resulting form of interpolation mean response function EaTSK(y|x), as well as, residual and normal QQ plots in that order. Figure 15A also allows visual appraisal of a better reproducibility by EgTSK(y|x). Figure 15D presents spread about Eas(y|x) and compares to EgTSK(y|x). We can observe that both proxies entitle similar reproducibilities. Figures 15E and 15F present residual spread and QQ plot accompanying Eas(y|x). Table 11 compares reproducibility metrics for the EaTSK(y|x), EgTSK(y|x) and Eas(y|x) proxies for this data. Again confrontation of model performance metrics shows that retransformation of the TSK- PLA output stands reliable results in direct scales.
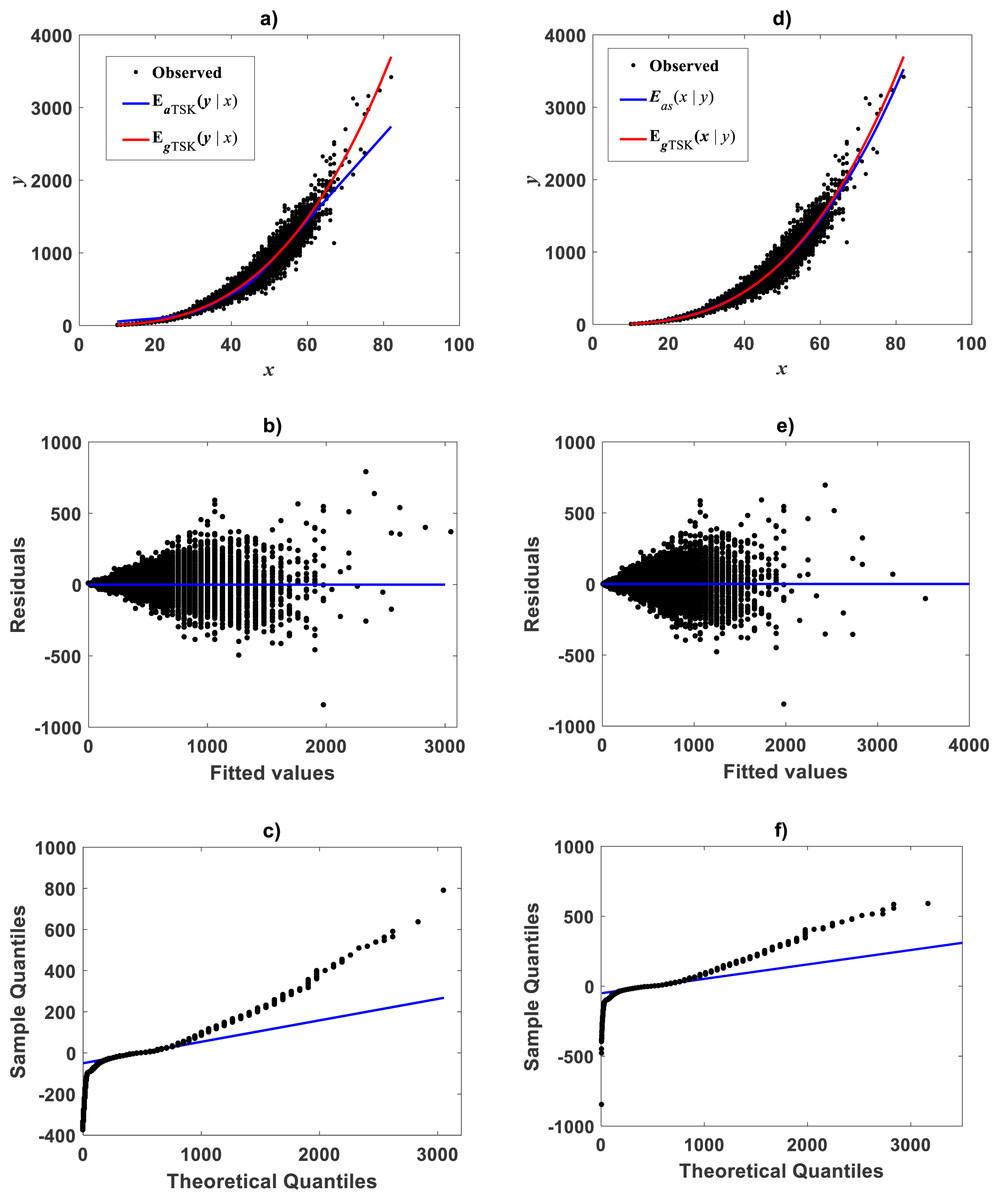
Figure 15: TSK-MPCA model identified on the De Robertis & Williams (2008) data.
(A) shows spread about the interpolation mean response EaTSK(y|x) produced by a ra = 0.22 and q = 3 fit of the TSK-MPCA fuzzy model. Plot exhibits a greater adequacy of EgTSK(y|x) obtained by retransformation of output of TSK-PLA fitted to this data. (B) and (C) residual spread and QQ plots for EaTSK(y|x) one to one. (D) presents spread about the mean response Eas(y|x) produced by a fit of Huxley’s formula of simple allometry compared to EgTSK(y|x). We can be aware that EgTSK(y|x) grants similar reproducibility features. (E) and (F) residual spread and QQ plots accompanying Eas(y|x).{kind=link}
| Method | ra | q | AIC | ρc | R2 | SEE | MPE | MPSE |
|---|---|---|---|---|---|---|---|---|
| 0.855 | 2 | 305.32 | 0.9785 | 0.9579 | 35.09 | 15.7416 | 33.14 | |
| 0.52 | 3 | 308.62 | 0.9749 | 0.9530 | 37.0804 | 16.6307 | 111.49 | |
| 0.80 | 2 | 314.21 | 0.9720 | 0.9434 | 40.7013 | 18.2547 | 22.31 |
Discussion
A logarithmic transformation in allometry is often vindicated as a natural way to lodge a variation pattern resulting from multiplicative growth in plants and animals. Indeed, Gingerich (2000) and Kerkhoff & Enquist (2009) state that a number of biological processes, (i.e., growth, reproduction, metabolism and perception), are essentially multiplicative and are therefore prone to fit in better to a geometric error model. Beyond biological arguments supporting the traditional approach, Kerkhoff & Enquist (2009) underline that fitting models to log-transformed data is seamlessly adequate, since taking into account proportional rather than absolute variation is more significant. Therefore, from this standpoint, the fact that log-transformation places numbers into a geometric domain could bestow advantages beyond a purely statistical convenience. Nevertheless, there are remarks that a logtransformation approach procedure produces biased results, and that direct nonlinear regression methods in arithmetical scale, should be preferred in parameter identification tasks (e.g., Packard, 2013; Packard, 2009; Packard & Birchard, 2008; Packard & Boardman, 2008). But, these views are debatable for a school of defenders of the traditional protocol. For instance, Mascaro et al. (2014), stress on an important drawback in findings in Packard (2013) that refuted the traditional analysis method of allometry. This concerns the apparent significant bias linked to small values of the explanatory variable, that result from a use of nonlinear regression with the assumption of homoscedastic errors. Besides, Mascaro et al. (2014), underline that a lack of a CF misled Packard (2013), thereby explaining his assertion of biased results attributed to the logarithmic transformation protocol. Other practitioners have also placed a vigorous defense of this procedure, (e.g., Ballantyne, 2013; Glazier, 2013; Lai et al., 2013; White et al., 2012; Xiao et al., 2011). This is reasonably understood since inferences of many allometric studies could be invalidated by a substantiated rebuttal of this analysis method. But, Packard (2017a) asserts for instance, that adherence to a TAMA approach has been maintained even in situations when the resulting bivariate distribution is curvilinear in geometrical scale. Consequent pattern is generally referred as non-log linear allometry (Packard, 2012b; Strauss & Huxley, 1993; Echavarría-Heras et al., 2019a). Moreover, G.C. Packard has considered deviations from linearity in log-log plots of allometry as mainly attributable to a logtransformation itself (Packard & Boardman, 2008; Packard, 2012a; Packard, 2012b; Packard, 2013). From this perspective, overcoming the bias due to curvature in log scale requires extending complexity of Huxley’s model of simple allometry in direct scales, which bears a paradigm of multiple parameter complex allometry (Gould, 1966; Lovett & Felder, 1989; MacLeod, 2014; Bervian, Fontoura & Haimovici, 2006; Packard, 2012a). Again, for promoters of the traditional approach this viewpoint sacrifices appreciation of biological theory in order to privilege statistical correctness (Houle et al., 2011; Lemaître et al., 2015; Pélabon et al., 2018). The approach underwent here demonstrates that a merging of points above can be achieved by evoking Huxley’s report on the existence of a breakpoint in the log–log plot of chela mass vs. body mass of fiddler crabs (Uca pugnax) (Huxley, 1924; Huxley, 1927; Huxley, 1932). A generalization of this perspective explains adoption of a polyphasic loglinear allometry paradigm (Packard, 2016; Gerber, Eble & Neige, 2008; Strauss & Huxley, 1993; Hartnoll, 1978). This notion bestows curvature in geometrical space as determined by breakpoints interpreted as thresholds for transition among successive growth phases. Formally, this conception adds complexity for improving statistical consistency while keeping the meanings of allometric exponents as Huxley’s original formulation.
| Method | ra | q | AIC | ρc | R2 | SEE | MPE | MPSE |
|---|---|---|---|---|---|---|---|---|
| 0.668 | 2 | 232.81 | 0.9986 | 0.9972 | 22.42 | 2.52 | 32.35 | |
| 0.8 | 2 | 199.72 | 0.9996 | 0.9993 | 11.56 | 1.30 | 1.8548 | |
| 0.2 | 7 | 160.43 | 0.9999 | 0.9998 | 5.27 | 0.59 | 0.9577 |
Conventional approaches have handled curvature in geometrical space by means of polynomial regression (Kolokotrones et al., 2010; Lemaître et al., 2014; MacLeod, 2010; Glazier, Powell & Deptola, 2013; Tidière et al., 2017; Echavarría-Heras et al., 2019a). Nevertheless, complexity underneath precludes accounting for heterogeneity as determined by break-point allometry. Conventional identification procedures also offer refined broken-line regression protocols (Beckman & Cook, 1979; Ertel & Fowlkes, 1976; Muggeo, 2003; Tsuboi et al., 2018; Ramírez-Ramírez et al., 2019; Echavarría-Heras et al., 2019a). Nevertheless, this slant relies on nonlinear regression that requires starting values for break-point estimation. Besides, crucial profile log likelihood could be log-concave so local maxima problems may exist. Surpassing this inconvenience may depend on using smoothed scatter plots to get candidate break points and consider several additional trials for estimation sensitivity to different starting points. Also necessary inferences on estimates could make implementation difficult (Julious, 2001; Muggeo, 2003).
| Method | ra | q | AIC | ρc | R2 | SEE | MPE | MPSE |
|---|---|---|---|---|---|---|---|---|
| —– | — | 324,010 | 0.9812 | 0.9630 | 60.2367 | 0.1401 | 7.3767 | |
| 0.22 | 3 | 330,531 | 0.9762 | 0.9539 | 67.3087 | 0.1565 | 11.6985 | |
| 0.50 | 1 | 324,613 | 0.9812 | 0.9622 | 60.0856 | 0.1415 | 7.2992 |
The approaches in Bitar, Campos & Freitas (2016), Echavarría-Heras et al. (2018a) and in Echavarria-Heras et al. (2019b) typify fuzzy logic based hybrid paradigms aimed to allometric examination. Present TSK constructs can be placed in this framework. Moreover, as our results demonstrate offered fuzzy paradigm can naturally host complexity as intended in a break point assimilation of allometry. Moreover, conceived TSK arrangements offer direct-intuitive and starting value free identification of breakpoints. Certainly, beak points as conceived here correspond to points of intersection of TSK-firing strength factors. Besides, intervals in between break points can be interpreted as dominance realms of corresponding sub models. The TSK break point identification in geometrical space for the Echavarría-Heras et al. (2019a) and the Mascaro et al. (2011) was paralleled by conventional broken-line regression. This confirms consistent capabilities by the fuzzy paradigm to identify heterogeneity in of the logtransformmed response. Thus, the offered TSK fuzzy model can be considered a tool entailing efficient automatic detection of weighted polyphasic log linear allometry patterns. And, the fact that the TSK model identified linearity in geometrical space for the De Robertis & Williams (2008) data demonstrates this approach can adapt complexity as necessary in an efficient way. But, we must emphasize that consistency of results in arithmetical space hinges on suitability of CF form. We suggest contemplating the optimal reproducibility criterion around Eq. (10) for this matter.
Motivation for the present research mainly stirred from the idea that identification based on a logarithmic transformation is suited for allometric examination. Visual inspection of TSK proxies fitted in geometrical space, as well as, included model performance metrics provides partial validation of our assertion. But, from the perspective of MPCA proponents, validation of detected heterogeneity should be made on the original arithmetic scales. Moreover, the addressed TSK-MPCA proxy corresponds to an expression of the general output of the TSK fuzzy model involving linear consequents in arithmetical scales. This arrangement is consistent with a MPCA approach as conceived in Lovett & Felder (1989). Furthermore, identification of a TSK-MPCA arrangement allows examination of break point allometry in arithmetical scales. Existence of break points in direct scales of data, confirms that a corresponding structure detected in geometrical space was not induced by effects of a logtransformation itself. And, using the Weierstrass approximation theorem, it can be demonstrated that the general output of a TSK fuzzy model can uniformly approximate any continuous function to arbitrarily high precision (Ying, 1998; Zeng, Nai-Yao & Wen-Li, 2000). Therefore, the high order interpolation capabilities of the TSK-MPCA scheme sets criterion to evaluate performance of retransformed TSK-PLA output . Certainly, as our results demonstrate this can be achieved by comparing the reproducibility strength of against that of for a given data set. And in the present settings the offered TSK-PLA or TSK-MPCA approaches were equally suited. This demonstrates that it is possible to maintain a logtransformation as part of a consistent allometric examination arrangement. This is a controversial subject whose clarification seems to be overcome by adopting presently offered analytical arrangement.
Packard (2012a) applied conventional statistical methods to conclude that a break point in Huxley’s Uca pugnax data (Huxley, 1932) was inexistent. Nevertheless, application of present fuzzy methods detected a break point shifted back from the locus Huxley conceived. Corroboration of existence of this point seems to endure a biologically meaningful interpretation by Huxley of existence of a threshold for a sudden change in relative growth of the chela at about the time crabs reach sexual maturity. Likewise, detected break point in Zostera marina could be interpreted as a threshold beyond which plant assigns to leaves a relatively greater amount of tissue to resist damage and separation from shoots induced by drag forces. This implies different scaling parameters among small and large leaves (Echavarría-Heras et al., 2019a; Echavarría-Heras et al., 2018b; Echavarria-Heras et al., 2019b). Similarly, a detected break point in Metrosideros polymorpha may suggest different allometric scaling depending on tree size. Certainly, resource allocation to different tree traits like diameter or height could vary through growth in response to different environmental-biotic settings, and also to changes in resource availability. In this perspective, a risk of suppression by competitors may drive small trees to assign more resources to increase height (Echavarria-Heras et al., 2019b). Then, past a threshold height at which suppression risk is at a minimum resource may be apportioned to horizontal growth parameters such as diameter, crown and root cover (Weiner, 2004; Ramírez-Ramírez et al., 2019; Echavarria-Heras et al., 2019b). Therefore since the aim of allometric examination is understanding the biological processes that bring about covariance among traits, analytical approaches entailing break point identification must be preferred over conventional complex multi-parameter approaches (Echavarria-Heras et al., 2019b). Indeed, on spite of any gains in statistical fit attributable to the latter, characterization of inherent heterogeneity by the former could enhance biological insight. Particularly, a TSK-PLA slant could be a highly biologically significant model of allometry, because it can model the breakpoints while keeping the meanings of allometric exponents as Huxley’s original formulation (Echavarria-Heras et al., 2019b).
As it is demonstrated by the steps in the derivation of Eq. (29), an imbedding of the TSK-PLA in the original theoretical perspective of allometry makes MPCA in arithmetical scale its logical consequence. By the same token the TSK-PLA approach grants direct–intuitive and starting values-free estimation of break points for transition among growth phases. We can also refer to benefits derived from the outstanding high order interpolation capabilities by this device. This functional mode of the TSK paradigm can be achieved by adjusting the value of the clustering parameter ra in Eq. (B7) (radii in supplied code) as to let the identification algorithm increase the number q of interpolation sub models in Eq. (20) or Eq. (48). And, if we can manage to include a suitable CF form, we can assure a remarkable reproducibility strength of projections of values of the response in arithmetical scales. Nevertheless, unsuitable forms of membership functions could lead to inconveniences in the present TSK approach. Moreover, fitting results of the TSK-MPCA on the Mascaro et al. (2014) data exhibit the extent on what a combination of membership functions form and ra value can influence both break point detection and reproducibility strength (Table 9). We can be aware for instance that for membership functions in the form set by Eq. (51) consistent break point transference among geometrical and arithmetical scales is only achieved when ra = 0.52 which implies heterogeneity set by q = 3. Nevertheless, this by the way leads to a penalization in reproducibility strength relative to a fit by ra = 0.855. Setting a compromise between both fits depends on integration of previous knowledge into the analysis. This could help for instance by suggesting ad hoc forms of membership function with the aim of achieving high reproducibility and consistent break point placement relative to that previously estimated on geometrical space. In any event present digression on integration of subjective knowledge in the analysis of Huxley’s data illustrates the extent on which a fuzzy logic approach can elucidate issues in allometric examination.
Conclusions
The offered TSK-PLA as formalized by the paradigm can be interpreted as a generalized tool for the analysis of log transformed allometric data, that allows to contemplate: (1) the regression arrangement of the TAMA way (the case q = 1 and ), (2) a generalized nonlinear model for identification of weighted polyphasic nonlinear allometry (the case q > 1). (3) A direct–intuitive identification of concomitant break points for transition among successive growth phases.
On spite of a seemingly complicated formal set up of the scheme, this can be conveniently identified by loading logtransformmed data into the provided code. Analysis of model performance metrics show that the mean response function deriving from retransformation of to arithmetical space produces similar reproducibility strength as its counterpart following from identification of its arithmetical space TSK-MPCA counterpart . Available conventional like broken line or weighted linear segment mixture regression approaches could offer reasonable analytical paradigms. Nevertheless, the offered TSK approach bears a flexible computational assembly for previous knowledge integration in an intuitive-interactive way. The present digression on Huxley’s break point illustrates this advantage in a more proper way.
Present results confirm the pertinence of the quotation of Kerkhoff & Enquist (2009), on the uselessness of a distinction between logarithmic transformations and nonlinearity in many instances of allometric examination. Moreover, in our view, whenever we can manage to exhibit a suitable CF form proposed Takagi Sugeno Kang generalization can elucidate a glowing controversy. Surely, this paradigm allows the coexistence of the log transformation step claimed by practitioners as a must in allometry, and the unbiasedness of parameter estimates attributed to alternate direct nonlinear regression approaches in the original scale defended by many others.
However, the fact that TSK-PLA modeling provided meaningful interpretation in present settings does not rear this paradigm as a general tool of allometric examination. In the elucidating around Eq. (1) we established a condition on the response being positive and having a zero limit as covariate approaches zero. Therefore, the TSK-PLA slant essentially aims to analyse zero intercept allometries. And, there are instances where the initial timing of development of the trait itself and overall size are different. This situation will lead to consideration of a negative intercept in direct scales, ruling out transference of the examination into geometrical space. Then, modeling should be necessarily kept in direct scales and relying in MPCA turns out to be biologically reasonable. There are also situations where the error structure can be additive while the biological process underlying allometry is multiplicative. Again, this requests keeping the analyses on the arithmetic scales or modeling heteroscedastic errors in geometrical space. Certainly, we briefly addressed this approach while analyzing the eelgrass data. However, offering a heteroscedastic TSK-PLA protocol suited for the general settings requires further exploration.
Supplemental Information
Raw data
We provide the Echavarria Heras et al 2018, (Mascaro et al., 2011) AND hUXLEY 1932 data sets. For (De Robertis & Williams, 2008) data please contact Alex De Robertis: [email protected]