
Modified generalized method of moments for a robust estimation of polytomous logistic model
- Published
- Accepted
- Received
- Academic Editor
- Frank Emmert-Streib
- Subject Areas
- Epidemiology, Statistics
- Keywords
- Robust statistics, Generalized method of weighted moments, Polytomous logistic model
- Copyright
- © 2014 Wang
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
- Cite this article
- 2014. Modified generalized method of moments for a robust estimation of polytomous logistic model. PeerJ 2:e467 https://doi.org/10.7717/peerj.467
Abstract
The maximum likelihood estimation (MLE) method, typically used for polytomous logistic regression, is prone to bias due to both misclassification in outcome and contamination in the design matrix. Hence, robust estimators are needed. In this study, we propose such a method for nominal response data with continuous covariates. A generalized method of weighted moments (GMWM) approach is developed for dealing with contaminated polytomous response data. In this approach, distances are calculated based on individual sample moments. And Huber weights are applied to those observations with large distances. Mellow-type weights are also used to downplay leverage points. We describe theoretical properties of the proposed approach. Simulations suggest that the GMWM performs very well in correcting contamination-caused biases. An empirical application of the GMWM estimator on data from a survey demonstrates its usefulness.
Introduction
Polytomous logistic regression models for multinomial data are a powerful technique for relating dependent categorical responses to both categorical and continuous explanatory covariates (McCullagh & Nelder, 1989; Liu & Agresti, 2005). In practice, however, the model building process can be highly influenced by peculiarities in the data. The maximum likelihood estimation (MLE) method, typically used for the polytomous logistic regression model (PLRM), is prone to bias due to both misclassification in outcome and contamination in the design matrix (Pregibon, 1982; Copas, 1988). Hence, robust estimators are needed.
For categorical covariates, we may apply MGP estimator (Victoria-Feser & Ronchetti, 1997), -divergence estimator (Gupta et al., 2006), and robust quadratic distance estimator (Flores, 2001). The least quartile dfference estimator can deal with overdispersion problem (Mebane & Sekhon, 2004). But all these methods are difficult to adapt for continuous covariates.
A generalized method of moments (GMM) estimation can be formed as a substitute of MLE. The GMM is particularly useful when the moment conditions are relatively easy to obtain. GMM has been extensively studied in econometrics (Hansen, 1982; Newey & West, 1987; Pakes & Pollard, 1989; Hansen, Heaton & Yaron, 1996; Newey & McFadden, 1994). Under some regularity conditions, the GMM estimator is consistent (Hansen, 1982). With an appropriately chosen weight matrix, GMM achieves the same efficiency as the MLE (Hayashi, 2000). Furthermore, under certain circumstances, GMM provides more flexibility, such as dealing with endogeneity through instrumental variables (Baum, Schaffer & Stillman, 2002).
Like MLE, GMM estimation can be easily corrupted by aberrant observations (Ronchetti & Trojani, 2001). Such observations can bring up disastrous bias on standard parameter estimates if they are not properly accounted for, see Huber (1981), Hampel et al. (2005), and Rousseeuw & Leroy (2003). So we propose a modified estimation method based on an outlier robust variant of GMM. The method is different from the kernel-weighted GMM developed for linear time-series data by Kuersteiner (2012) in that this is a data-driven method for defining weights. The new approach is evaluated using asymptotic theory, simulations, and an empirical example.
The robust GMM estimator is motivated by the data from a 2006 study on hypertension in a sample of the Chinese population. 520 people completed the survey. Observed variables included demographics, social-economic status, weight, height, blood pressure, and food consumption. Sodium intakes were calculated based on overall food consumption. Among those covariates, age, body mass index (BMI), and sodium intakes are all continuous. Based on blood pressure measurements, subjects were classified into 4 categories: Normal, Pre-hypertension, Stage 1 and Stage 2 hypertension. Table 1 lists the summary statistics of the sample. One of the research objectives is to examine the association between hypertension and risk factors in the population. Since the proportional odds assumption is violated (Score test for the proportional odds assumption gives with a degree of freedom of 8, ), we apply the polytomous logistic model, using the normal category as the reference level. In the case of category, the polytomous logit model have comparisons. Each comparison have a set of parameters for all covariates in the model. Therefore, the generalized logit model is not parsimonious when comparing with the proportional odds model. But the simultaneous estimation of all parameters is more efficient than separate models for each comparison. It is another option for ordinal response data, especially when a proportional odds model does not fit the data well. Table 2 lists the output from the model estimated by MLE. It is obvious that, if MLE is used, the estimates is inconsistent for sodium intakes, particularly the negative coefficient of sodium intake for the odds between the Stage 2 hypertension and the Normal categories. The inconsistency is more obvious when we plot the odds with respect to the sodium intake, the downward trend of the odds in Fig. 2A. This result contradicts the previous finding that there is a strong relationship between sodium intake and hypertension, see for example National Research Council (2005), He & MacGregor (2004) and references therein. Besides, Fig. 2A also shows another strange situation: the higher starting points for the odds between the Pre-hypertension and the Normal categories. The scatter plot (Fig. 1) between distances and leverages suggests some observations are possible outliers: Observations 21, 33, 85, 92, 194, 274, 336, 414, 459, 483, and 489 have large distances, which are blue-colored, and Observations 37, 83, 263, 459, 483, 485, and 490 have large leverages, which are red-colored.
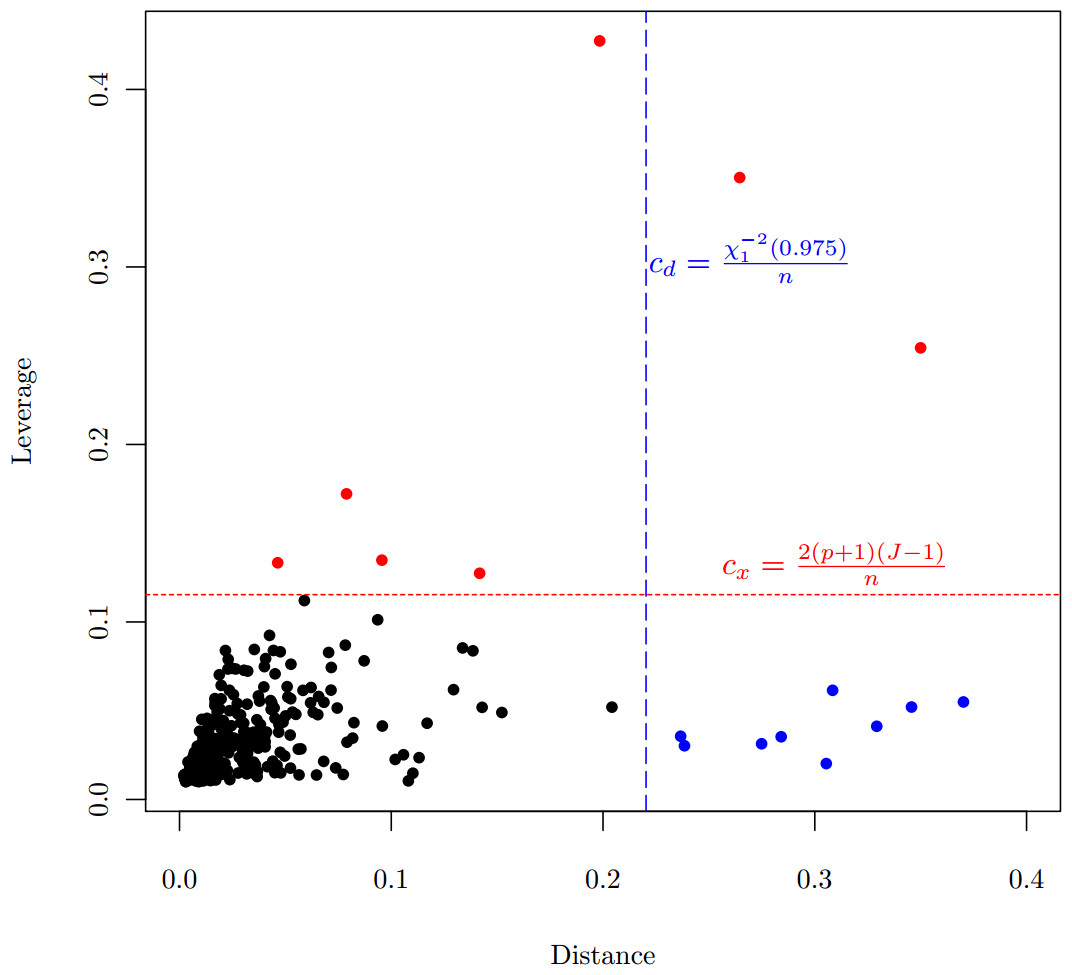
Figure 1: Scatter plot of distance vs. leverage, which are based on MLE.
Criteria for the distance and for the leverage are demonstrated.{kind=link}
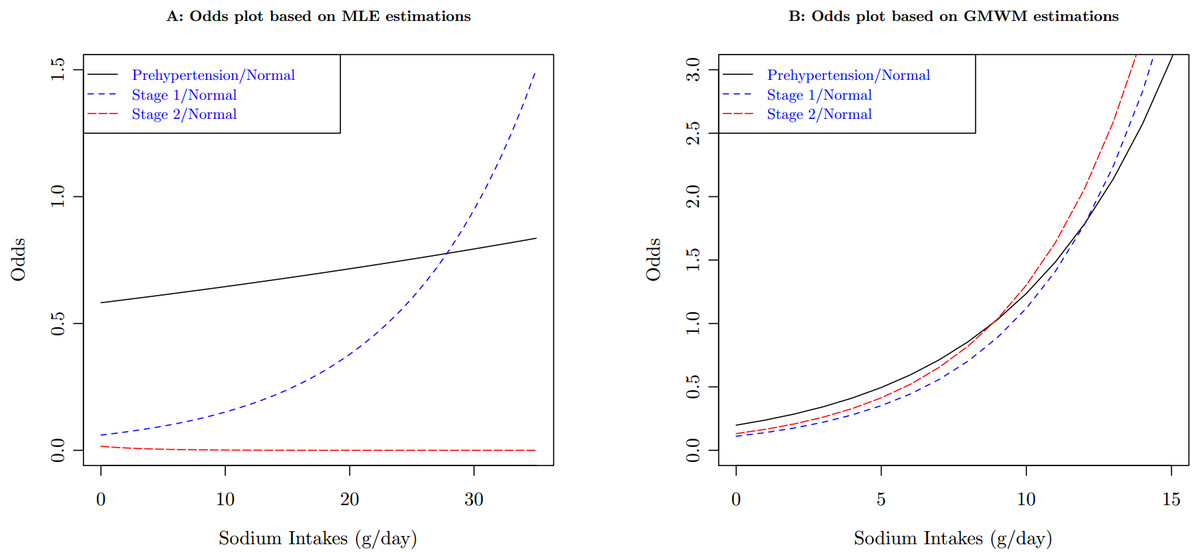
Figure 2: Compare odds plots of sodium intakes between MLE estimates and GMWM estimates on the population of female, age 40, and BMI 23.
{kind=link}
| Covariate | Hypertension categories | ||||
|---|---|---|---|---|---|
| Normal | Pre-hypertension | Stage 1 | Stage 2 | ||
| Gender | Male | 138 | 104 | 29 | 8 |
| Female | 87 | 114 | 31 | 9 | |
| Age | Mean | 43.2 | 48.8 | 54.3 | 60.3 |
| Std. Dev. | 13.7 | 13.8 | 12.2 | 13.4 | |
| BMI | Mean | 43.2 | 48.8 | 54.3 | 60.3 |
| Std. Dev. | 13.7 | 13.8 | 12.2 | 13.4 | |
| Sodium intake | Mean | 3.7 | 3.7 | 4.6 | 2.7 |
| Std. Dev. | 3.0 | 2.4 | 5.0 | 2.1 | |
| Variable | Coefficients | MLE | GMWM | ||||
|---|---|---|---|---|---|---|---|
| Estimates | Std. Err | value | Estimates | Std. Err | value | ||
| Sex | 0.7062 | 0.2022 | 0.0002 | 1.3339 | 0.2269 | <0.0001 | |
| 0.9789 | 0.3235 | 0.0012 | 1.0368 | 0.3013 | 0.0003 | ||
| 1.4193 | 0.5746 | 0.0068 | 0.6753 | 0.2195 | 0.0010 | ||
| Age | 0.0350 | 0.0075 | <0.0001 | 0.0671 | 0.0086 | <0.0001 | |
| 0.0715 | 0.0121 | <0.0001 | 0.1139 | 0.0133 | <0.0001 | ||
| 0.1096 | 0.0216 | <0.0001 | 0.0753 | 0.0103 | <0.0001 | ||
| BMI | 0.1147 | 0.0316 | 0.0001 | 0.1681 | 0.0360 | <0.0001 | |
| 0.2422 | 0.0474 | <0.0001 | 0.4382 | 0.0538 | <0.0001 | ||
| 0.4351 | 0.0884 | <0.0001 | 0.2279 | 0.0388 | <0.0001 | ||
| Sodium | 0.0104 | 0.0349 | 0.3829 | 0.1831 | 0.0355 | <0.0001 | |
| 0.0919 | 0.0426 | 0.0155 | 0.2315 | 0.0486 | <0.0001 | ||
| −0.2699 | 0.1580 | 0.9562 | 0.2294 | 0.0353 | <0.0001 | ||
Notes:
Std. Err, standard error.
The paper is set up as follows. In the next section we presents the basic notations, model, and standard GMM. “A robust GMM” introduces the outlier robust GMM estimator, and gives a detailed exposition of its implementation. In “Results”, we compares the performance of the standard MLE with the new estimator using a Monte-Carlo experiment. And we apply both estimators to real epidemiological data, and illustrate the usefulness of the robust estimator for application oriented researchers. We conclude with a discussion of advantages and limitations of the approach. The supporting document gathers the proofs of the asymptotic property.
Materials and Methods
The baseline-category logit model
Assume a random sample of size from a large population. Each element in the population may be classified into one of categories, denoted by the multinomial trial for subject , where when the response is in category and otherwise, , . Thus, . Suppose explanatory covariates, with at least one of them being continuous, are observed. Define , and . We assume that are independently and identically distributed (). Let , denote the probability that the observation of belongs to category , given covariates , we assume the relationship between the probability and can be modeled as: (1) where . Here we set the first category as reference class. This model is called a baseline-category logit model (Agresti, 2012) or generalized logit model (Stokes, Davis & Koch, 2009). MLE is usually used for obtaining parameter estimation of this model. Here we present an alternative estimation method formed with the GMM.
Estimation using GMM
The baseline-category logit model can be viewed as a multivariate model. Define , since is redundant. Let is a matrix, with , a matrix, defined as: (2) In the GMM framework, we define (3) where . And is the vector of unknown parameters. The population moment condition is with the corresponding sample moment condition (4) The GMM estimation of can be obtained by minimizing the following quadratic objective function where can be the empirical variance–covariance matrix given by Or, for the best efficiency of the GMM estimation, we can take the information matrix of the polytomous logit model (PLRM), that is, (5) where
In general, can be computed via an iterative procedure (Hansen, Heaton & Yaron, 1996). Under standard regularity conditions, the GMM estimator exists and converges in probability to the true parameter (Hansen, 1982). A proof of asymptotic normality of GMM can be found on p. 2148 of Newey & McFadden (1994).
A robust GMM
In this section we introduce the outlier robust GMM estimator. In the following subsection, we specify moment conditions used for robust estimation. And the details on the implementation of the estimator follows.
The generalized method of weighted moments
The main principle used in the robust GMM estimator is that we replace moment conditions by a set of observation weighted moment conditions. Instead of Eq. (3), we define (6) where . Then the estimation can be based on the moment conditions Consequently, the generalized method of weighted moments (GMWM) estimates can be defined by (7) where (8) with (9) Here we take the summation as the sample moment condition. The advantage of using the summation is that it can lead us to a direct estimation of covariance matrix.
It is clear to see that this definition is analogous to the standard GMM. If we choose and for all observations, the moment conditions in (6) are reduced to the standard moment conditions. Therefore, the standard GMM is a special case of the GMWM.
In order to specify the weights for the robust GMM estimator, we need the following definition of a distance, which is based on individual moment conditions: (10) The weight is assigned based on , that is, . There are several alternative specifications of weight functions available in the literature (Huber, 1981; Hampel et al., 2005). In this study, the Huber’s weights are applied: (11) The above specification of weight function requires a value of the tuning constant . Both the outlier sensitivity and the efficiency of the estimator are determined by the constant. On the one hand, the estimator should be reasonably efficient if the sample contains no outlier. On the other hand, the estimator should be insensitive to outliers. To determine , understanding the distribution of is critical. Clearly, is a column vector, and is a scalar quadratic distance, so we set , where is the quantile of the distribution with degrees of freedom.
If we take the information matrix (5) of the PLRM as , we can compute leverage for each observation: (12) where is the component of . Then, a Mallows-type weight can be defined based on ; that is, , to downplay the observations with high leverages. Lesaffre & Albert (1989) suggest that the practical rule for isolating leverage points might set . In this study, we give observations with large leverages 0 weights, (13) An approach often used to combine the two weights is (Heritier et al., 2009).
The consistency correction vector is defined as where with , is the weight for .
Implementation of the estimator
The continuous updating estimation method is applied in this study for estimating the regression coefficients and corresponding variance. The procedure is detailed as follows:
-
Apply an initial value for computing .
-
Compute using Eq. (10) and using Eq. (12); assign weights correspondingly based on (11) and (13).
-
With the combined weights, calculate and in Eq. (9).
-
Obtain the estimator by minimizing of Eq. (8).
-
Go back to Step 1, replace with the estimator in computing , and move to the next iteration.
-
Continue this procedure until convergence criteria are met.
For the starting value , a reasonable choice is the MLE estimation based on the original data.
In the appendix, we proved that, under some regularity assumptions, we can have that is consistent for . And by studying the behavior of the weighted moment equations in a neighborhood of , we showed that the asymptotic linearity ensures the applicability of the central limit theorem for the asymptotic normality of GMWM.
Results
Monte Carlo simulations
In this section we investigate the properties of the GMWM estimator using a Monte-Carlo study. We generate data with three response categories and two covariates which are from multivariate normal distribution with 0 mean and identity covariance. The true coefficient matrix is Based on the specified coefficient values and using the probability based on the model (1), we compute the category-specific probabilities for each subject. Then, using the computed probabilities, we determine the most likely category to which each subject belongs. This decision is made through random generation from the multinomial distribution with the probability vector as a parameter. For instance, multinomial categories in R-Language are generated using function, where is the probability vector, is the number of random vectors to draw, and is the total number of objects that are put into -categories. In our case, for all subjects and .
Two sample sizes, 100 and 1000, are examined. For each sample size, we run the simulation 1000 times. Average biases and MSEs are calculated and tabulated. Table 3 shows the results from randomly generated data with no outliers added. When the sample size is small, GMWM will give greater biases on and compared to the MLE method. For the sample size 1000, biases on these two parameters increase too, but not so obviously. Variances will also be inflated due to the weights we applied.
| Parameter | True | MLE | GMWM | |||||
|---|---|---|---|---|---|---|---|---|
| Bias | MSE | Coverage | Bias | MSE | Coverage | |||
| 100 | 1.0 | 0.0666 | 0.1030 | 0.945 | 0.0488 | 0.1986 | 0.949 | |
| −0.3 | −0.0059 | 0.1206 | 0.957 | −0.1440 | 0.5578 | 0.952 | ||
| −0.8 | −0.0654 | 0.1190 | 0.938 | −0.0513 | 0.2550 | 0.961 | ||
| 0.7 | 0.0566 | 0.1892 | 0.963 | 0.2318 | 0.5468 | 0.923 | ||
| −1.0 | −0.0853 | 0.1764 | 0.969 | −0.0691 | 0.2380 | 0.950 | ||
| −0.5 | −0.0624 | 0.1453 | 0.945 | 0.0203 | 0.3195 | 0.964 | ||
| 1000 | 1.0 | 0.0050 | 0.0087 | 0.956 | 0.0043 | 0.0181 | 0.962 | |
| −0.3 | −0.0055 | 0.0105 | 0.984 | −0.0106 | 0.0333 | 0.950 | ||
| −0.8 | −0.0039 | 0.0099 | 0.943 | −0.0013 | 0.0251 | 0.956 | ||
| 0.7 | 0.0081 | 0.0160 | 0.968 | 0.0162 | 0.0401 | 0.954 | ||
| −1.0 | −0.0071 | 0.0145 | 0.987 | −0.0025 | 0.0258 | 0.948 | ||
| −0.5 | −0.0047 | 0.0122 | 0.948 | 0.0041 | 0.0361 | 0.947 | ||
Outliers are generated from a multivariate normal distribution with the mean vector and identity covariance . For these outliers, their responses are intentionally misclassified, that is, they are placed within a different category from those predicted categories based on the true parameters.
Table 4 lists simulation results with outliers added. For estimations from datasets with 5% outliers, bias correction from the GMWM is excellent. However, when the datasets have 10% outliers, biases on estimations of some parameters ( and in this simulation) are decreased, but not completely corrected.
| Size | Parameter | 5% contamination | 10% contamination | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GMWM | MLE | GMWM | MLE | ||||||||||
| Bias | MSE | Coverage | Bias | MSE | Coverage | Bias | MSE | Coverage | Bias | MSE | Coverage | ||
| 100 | 0.0568 | 0.1102 | 0.956 | 0.0860 | 0.0884 | 0.957 | 0.0489 | 0.0999 | 0.971 | 0.0868 | 0.0819 | 0.970 | |
| −0.0038 | 0.1427 | 0.954 | −0.0055 | 0.1528 | 0.949 | −0.0057 | 0.1510 | 0.945 | −0.0431 | 0.1461 | 0.814 | ||
| −0.0392 | 0.1464 | 0.949 | 0.2377 | 0.1360 | 0.785 | 0.0319 | 0.1227 | 0.946 | 0.3607 | 0.1933 | 0.579 | ||
| 0.0175 | 0.2020 | 0.944 | −0.1072 | 0.1270 | 0.921 | −0.0235 | 0.1770 | 0.943 | −0.1631 | 0.1283 | 0.949 | ||
| 0.0374 | 0.1207 | 0.949 | 0.3848 | 0.2115 | 0.578 | 0.0207 | 0.0968 | 0.945 | 0.6088 | 0.4151 | 0.526 | ||
| −0.0548 | 0.1572 | 0.956 | −0.0964 | 0.0904 | 0.964 | −0.0817 | 0.1349 | 0.977 | −0.1069 | 0.0803 | 0.967 | ||
| 1000 | 0.0172 | 0.0189 | 0.939 | 0.0490 | 0.0102 | 0.932 | 0.0451 | 0.0202 | 0.944 | 0.0657 | 0.0120 | 0.900 | |
| 0.0012 | 0.0340 | 0.945 | 0.0124 | 0.0075 | 0.952 | −0.0071 | 0.0336 | 0.952 | −0.0111 | 0.0063 | 0.822 | ||
| 0.0260 | 0.0242 | 0.937 | 0.2874 | 0.0885 | 0.101 | 0.0164 | 0.0207 | 0.936 | 0.3876 | 0.1545 | 0.002 | ||
| −0.0058 | 0.0356 | 0.950 | −0.1423 | 0.0345 | 0.697 | −0.0497 | 0.0346 | 0.917 | −0.2269 | 0.0658 | 0.521 | ||
| 0.0366 | 0.0237 | 0.936 | 0.4390 | 0.2032 | 0.000 | 0.0238 | 0.0182 | 0.938 | 0.6500 | 0.4322 | 0.000 | ||
| −0.0106 | 0.0292 | 0.951 | −0.0538 | 0.0103 | 0.940 | −0.0434 | 0.0250 | 0.953 | −0.0629 | 0.0106 | 0.902 | ||
Application
For the hypertension data, the criterion for identifying observations with large distances is , and the criterion for identifying leverage points is . Applying the GMWM estimator, those blue-colored points in Fig. 1 are automatically downweighted, and red-colored points have 0 weight. The GMWM method indeed eliminates those inconsistencies: the coefficient of sodium intake for the odds model between the Stage 2 hypertension and the Normal categories is no longer negative, see the right side of Table 2.
As the results indicate, age, gender, and BMI all had significant impact on hypertension status. For example, one unit increase in BMI resulted in an increase of 1.26 (95% confidence interval [1.16–1.35]) times in likelihood to have Stage 2 hypertension when compared with the normal status. And with one year age increase, a subject was 1.07 (95% CI [1.06–1.10]) times more likely to have Stage 2 hypertension than to stay at the normal healthy status. Contrary to the MLE results for sodium intakes, which were difficult to make a conclusion due to inconsistent estimate, we now find that sodium intakes were statistically significant. When a daily intake of sodium increased one gram, a subject were 1.26 (95% CI [1.15–1.37]) times more likely to have Stage 1 hypertension, and 1.25 (95% CI [1.17–1.35]) times more likely to have Stage 2 hypertension. These results are consistent with the findings from previous studies (National Research Council, 2005; He & MacGregor, 2004).
Discussion
A reasonable choice to fit ordinal response data is the proportional odds model if the proportional odds assumption is not violated. Proportional odds models can take the ordinal information into modeling. And it reduces the number of parameters which is needed by the generalized logit model. Unfortunately, our data does not met the fundamental assumption of proportional odds models, which makes us choose to treat the outcome as a nominal response.
A datum with a nominal response and some continuous covariates is commonly seen in many scientific areas, such as sociology, economy, and biomedical studies. In order to be able to deal with outliers, we modified the GMM estimator to replace the standard moment conditions with weighted moment conditions, so that aberrant observations automatically receive less weight. We proved that the proposed method has good asymptotic behavior. When outliers are present, the GMWM estimator give much smaller biases than the estimations derived from the traditional MLE method. This method can be adapted to check whether results obtained with the traditional MLE approach are driven only by a few outlying observations. The weights produced from the robust procedure can be used to diagnose the cause of the differences and to indicate routes for model re-specification.