
An explicit solution for calculating optimum spawning stock size from Ricker’s stock recruitment model
- Published
- Accepted
- Received
- Academic Editor
- Jack Stanford
- Subject Areas
- Ecology, Mathematical Biology
- Keywords
- Ricker model, Maximum sustainable yield, MSY, Stock-recruit, Spawner, Harvest
- Copyright
- © 2016 Scheuerell
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2016. An explicit solution for calculating optimum spawning stock size from Ricker’s stock recruitment model. PeerJ 4:e1623 https://doi.org/10.7717/peerj.1623
Abstract
Stock-recruitment models have been used for decades in fisheries management as a means of formalizing the expected number of offspring that recruit to a fishery based on the number of parents. In particular, Ricker’s stock recruitment model is widely used due to its flexibility and ease with which the parameters can be estimated. After model fitting, the spawning stock size that produces the maximum sustainable yield (SMSY) to a fishery, and the harvest corresponding to it (UMSY), are two of the most common biological reference points of interest to fisheries managers. However, to date there has been no explicit solution for either reference point because of the transcendental nature of the equation needed to solve for them. Therefore, numerical or statistical approximations have been used for more than 30 years. Here I provide explicit formulae for calculating both SMSY and UMSY in terms of the productivity and density-dependent parameters of Ricker’s model.
Introduction
One of the most difficult problems in the assessment of fish stocks is establishing the relationship between the spawning stock and subsequent recruitment (Hilborn & Walters, 1992). Stock-recruitment models have been used for decades in fisheries management as a means of formalizing this relationship (Beverton & Holt, 1957; Ricker, 1954). Over time, a variety of functional forms have emerged to capture varying assumptions about depensatory and compensatory mortality (Hilborn & Walters, 1992). In a classroom setting, deterministic versions of the models provide useful constructs for teaching about management reference points such as maximum sustained yield (MSY).
In particular, Ricker’s stock recruitment model (Ricker, 1954; Ricker, 1975) is one of the most widely used models to describe the population dynamics of fishes, such that (1) R is the number of recruits produced, S is the number of spawners, α is the dimensionless number of recruits per spawner produced at very low spawner density, and b is the strength of density dependence (units: spawner−1). It is common to substitute α = ea into Eq. (1) and rewrite it as (2) To make the model reflect a stochastic process, Eq. (2) is typically multiplied by a log-normal error term, so that (3) and ε is a normally distributed error term with a mean of −1∕2 σ and variance σ. This non-zero mean ensures that a is interpreted as the mean recruits per spawner rather than the median (Hilborn, 1985). Part of the model’s popularity is due to the relative ease with which its parameters are estimated. After log transformation, Eq. (3) is typically rewritten as (4) and the parameters are estimated via simple linear regression. I note here that estimation of the parameters via a simple observation-error model like (4) can lead to substantial biases in a and b if the sample size is low (n ≤ 10) due to autocorrelation in the residuals ε (Walters, 1985).
Once the model has been fit to data and any necessary bias corrections made, the parameters can be used to derive various biological reference points of interest to fisheries managers. Some of these metrics are rather trivial to compute. For example, the spawning stock size leading to maximum recruit production (SMSR) is simply 1/b. However, other reference points are much less straightforward to calculate. In particular, the spawning stock expected to produce the maximum sustainable yield (SMSY) under deterministic dynamics is of common interest.
To find SMSY, I express the yield (Y) as (5) and then take the derivative of Y with respect to S: (6) SMSY is then determined by setting Eq. (6) to zero and solving for S. Upon initial inspection, however, there does not appear to be an explicit solution to this equation in terms of S, and therefore SMSY is typically solved “by trial” (Ricker, 1975) with some form of gradient method (e.g., Newton’s as in Hilborn, 1985).
To simplify this issue for common applications, Hilborn (1985) developed a simple model whereby the ratio of spawning stock size at MSY to that at the unfished equilibrium (SMSY∕Sr) is a linear function of the parameter a. Specifically, for 0 < a ≤ 3 he estimated that (7a) (7b) Although this approximation is very useful due to its simplicity, there is no underlying fundamental support for the statistical form of the relationship.
Methods
Here I make use of the Lambert W function, W(z), to demonstrate an explicit solution to Eq. (4) that precludes the need to estimate SMSY via numerical methods or Hilborn’s (1985) linear approximation. This function has been used for explicit solutions to Roger’s random predator equation in ecology (McCoy & Bolker, 2008) and susceptible-infected-removed (SIR) models in epidemiology (Reluga, 2004; Wang, 2010). Specifically, W(z) is defined as the function that satisfies (8) for any complex number z (Lambert 1758 and Euler 1783 as cited in Corless et al., 1996). Here we are interested only in real values, however, so I replace z with x and note that W(x) is only defined for x ≥ − 1∕e (Corless et al., 1996). Furthermore, this function is not injective and has two values for −1∕e ≤ x ≤ 0, but as I show below, we are concerned only with the region where x > 0 and W(x) is a singular, non-negative value.
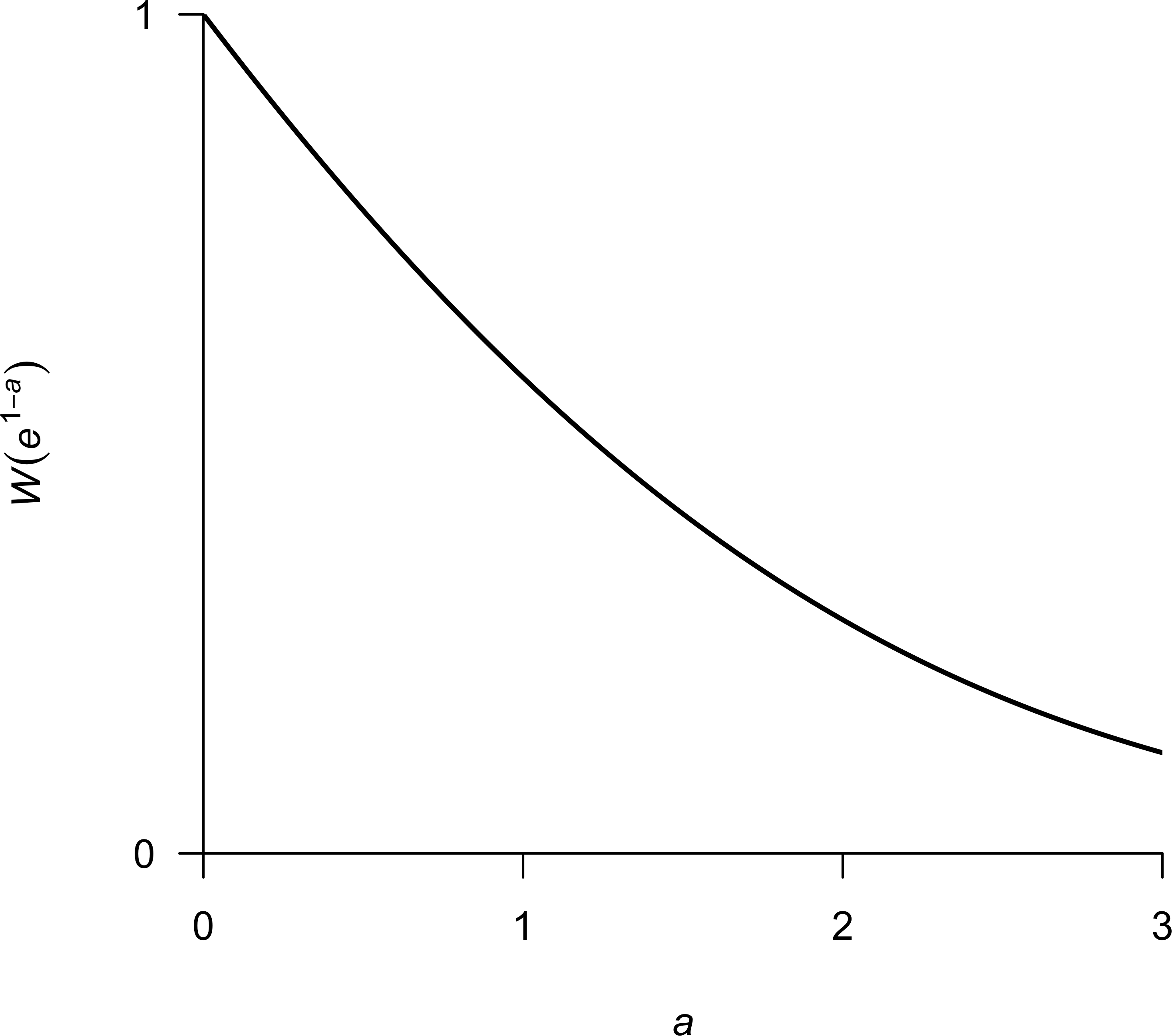
I begin my explicit solution of SMSY by setting Eq. (6) to zero, such that (9) After rearranging terms and multiplying both sides by e, we arrive at (10) At this point I note the relationship between Eqs. (10) and (8), with 1 − bSMSY = W(z) and e1−a = z. Therefore, we can write (11) (12) We now have an explicit solution for SMSY that depends only on the parameters a and b from Eq. (2). As mentioned above, W(x) is only defined for x ≥ − 1∕e, which does not pose any problems here because x = e1−a > 0∀a ∈ ℝ. For visualization purposes, I show a plot of W(e1−a) versus a in Fig. 1.
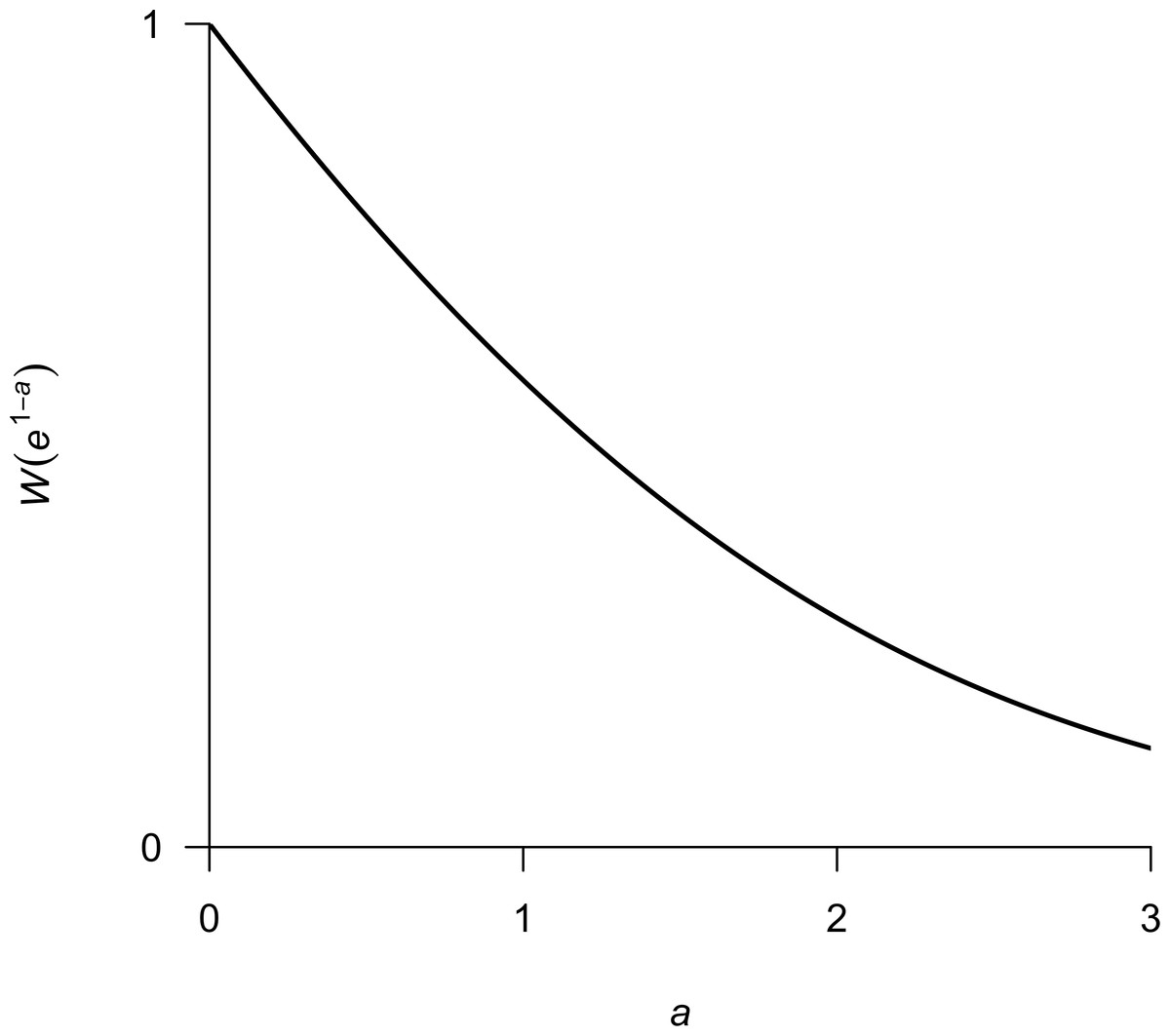
Figure 1: Plot of W(e1−a) over a range in values of a typically encountered in fisheries.
{kind=link}
We can also derive an explicit formula for calculating the fraction of the return harvested at SMSY, which I call UMSY. As Ricker (1975) shows, (13) and therefore substituting (12) into (13) gives (14)
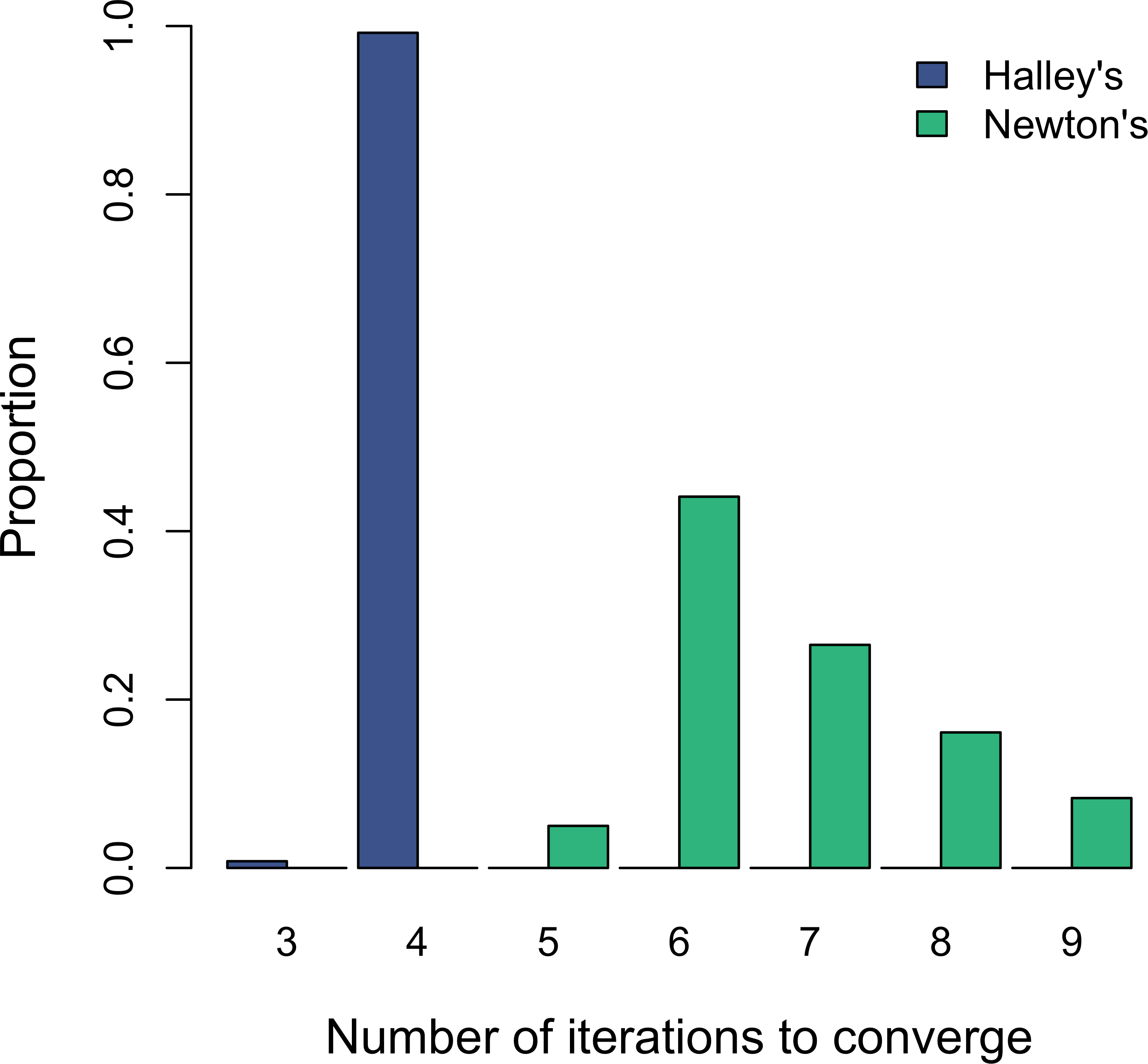
In practice W(x) may be approximated numerically using some form of gradient method. Corless et al. (1996) recommend Halley’s method, with the update equation given by (15) I used an initial guess of w0 = 3∕4ln(x + 1) based on the shape of W(x) over the range of a typically considered in fisheries research (i.e., 0 < a < 3 as in Hilborn, 1985). If, however, one must estimate W(x) numerically, then one should ask whether doing so is, in fact, computationally faster. Therefore, as a test I randomly selected 1,000 values each for 0 < a ≤ 3 and 10−5 ≤ b ≤ 10−3, and then solved for SMSY using both Newton’s method as suggested by Ricker (1975), and Halley’s method as in Eq. (15).
Results and Discussion
Recent analyses have relied on estimating SMSY via Hilborn’s (1985) linear approximation when calculating optimal yield profiles (Fleischman et al., 2013) or the effects of observation error on biases in parameter estimates (Su & Peterman, 2012). On the other hand, solving for SMSY using W(x) and Halley’s method is not only convenient; it also offers an appreciable computational advantage over the standard Newton method. Although both methods converged in less than 10 iterations during my test, Halley’s method was always faster and less variable overall (Fig. 2). Therefore, estimating SMSY via Halley’s method might save significant time in applications such as management strategy evaluations that are much more computationally intensive than a simple one-case solution.
Although implementing Eq. (15) may seem a bit daunting to individuals less familiar with numerical methods, a variety of contemporary software packages (e.g., MATLAB, R) include built-in functions to calculate W(x) directly. This means that anyone using a personal computer to estimate the parameters in a Ricker model can easily estimate SMSY from Eq. (12) as I demonstrate in Table 1; I show the results from my R implementation for a range of a and b in Fig. 3. For those preferring to use Microsoft Excel, there is no built-in function to calculate W(x), but I have implemented Eq. (15) as the VBA function ‘LAMBERTW’ in the Microsoft Excel add-in file ‘LambertWfunc.xlam’ (see Fig. S1 for download and install instructions).
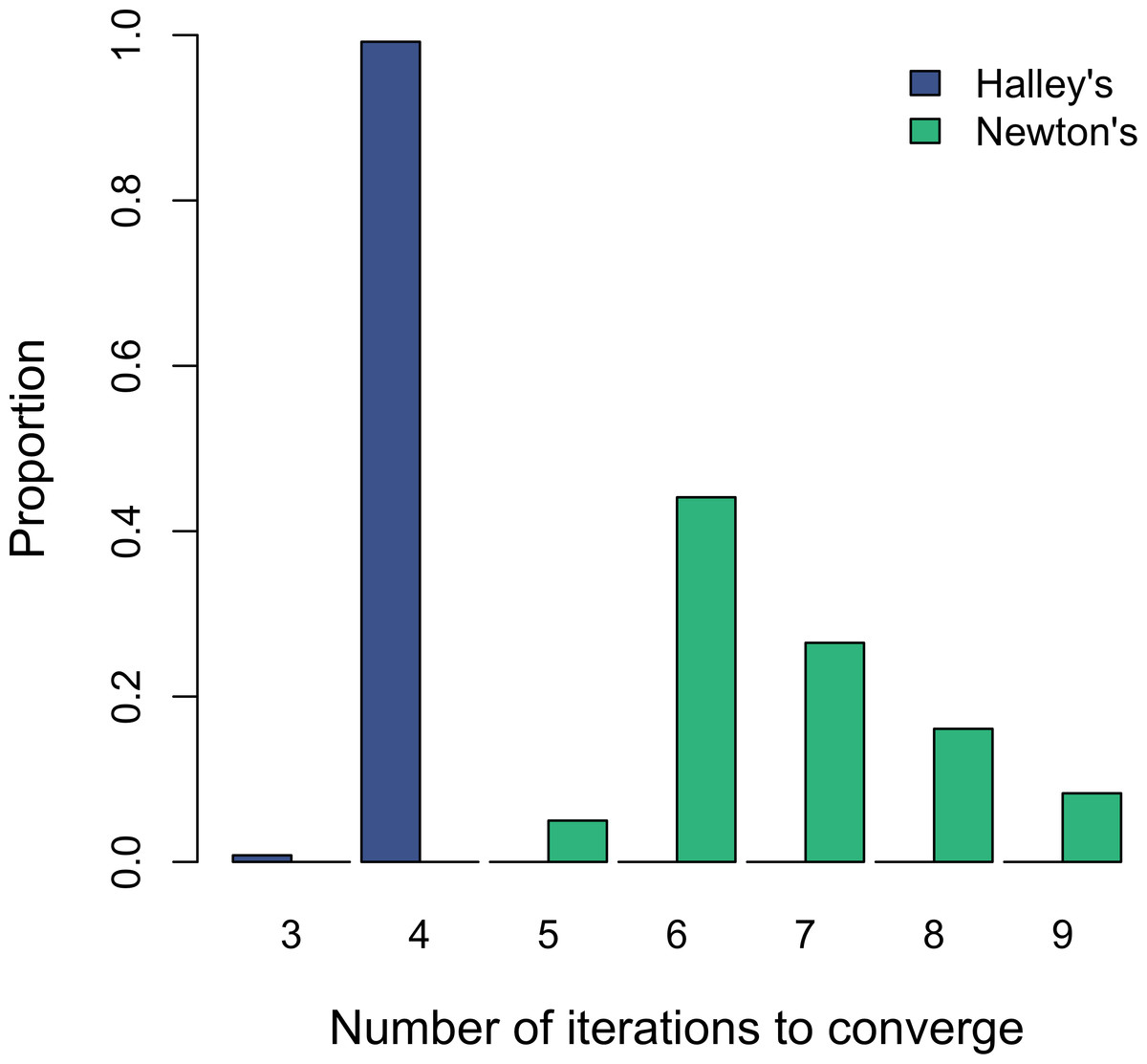
Figure 2: Histograms showing the distribution of the number of iterations that each of the two numerical methods takes to converge to SMSY using a threshold of 10−6.
{kind=link}
| Software | Code example | ||
|---|---|---|---|
| R |
|
||
| MATLAB |
|
||
| Excel | A | B | |
| 1 | a | 1 | |
| 2 | b | 5e-4 | |
| 3 | Smsy | =(1 - LAMBERTW(EXP(1 - B1))) / B2 | |
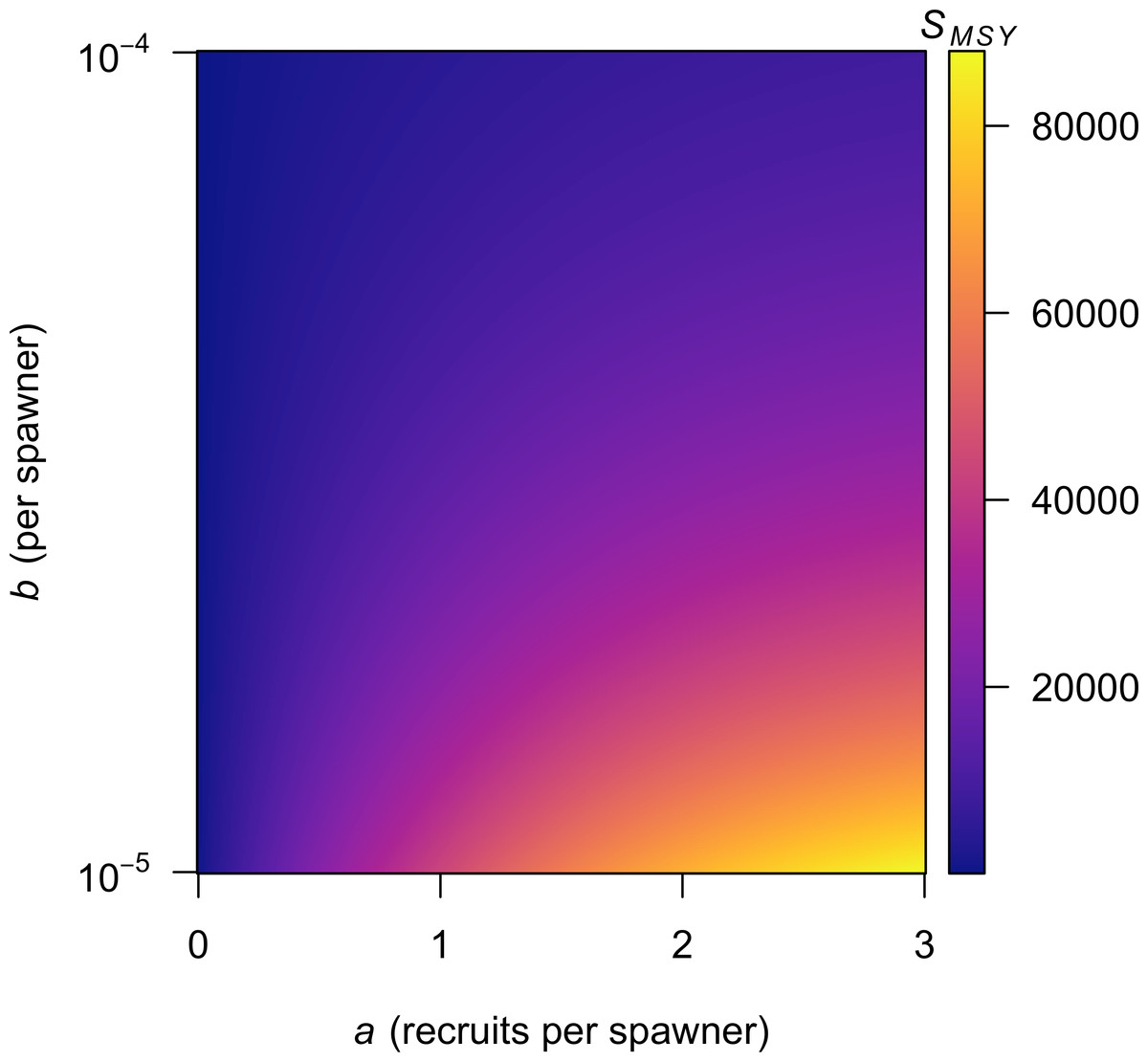
Figure 3: Contour plot showing values of SMSY for combinations of the a and b parameters in Eq. (2).
{kind=link}
Here I have outlined a new method to easily calculate SMSY from the productivity (a) and density-dependent (b) parameters in a Ricker model using readily available functions in several software packages. This method is much more straightforward than trying to solve for SMSY using numerical methods and should be useful in many classroom settings. Although there could be some utility in actually going through the exercise of numerically deriving the answer, it is rare nowadays, for example, for anyone to code a random number generator because of their ubiquitous implementation in standard software. In addition, the explicit analytical solution is closed-form with respect to the special functions, and therefore precludes the need to estimate SMSY via Hilborn’s (1985) approximation. Thus, due to the speed and ease with which these new equations are calculated, I recommend that practitioners use them for the estimation of SMSY and UMSY in lieu of those listed in Appendix III of Ricker (1975) and Table 7.2 of Hilborn & Walters (1992).
Supplemental Information
Instructions for downloading and installing the LAMBERTW function in Microsoft Excel
See Table 1 in main text for an example of the function call.