

Hybrid computational and real data-based positioning of small cells in 5G networks
- Published
- Accepted
- Received
- Academic Editor
- Ayaz Ahmad
- Subject Areas
- Computer Networks and Communications, Emerging Technologies
- Keywords
- 5G networks, Clustering, Bioinspired optimization, Small cells positioning, Smart cities
- Copyright
- © 2023 Ferreira et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. Hybrid computational and real data-based positioning of small cells in 5G networks. PeerJ Computer Science 9:e1412 https://doi.org/10.7717/peerj-cs.1412
Abstract
One of the key technologies in smart cities is the use of next generation networks such as 5G networks. Mainly because this new mobile technology offers massive connections in densely populated areas in smart cities, thus playing a crucial role for numerous subscribers anytime and anywhere. Indeed, all the most important infrastructure to promote a connected world is being related to next generation networks. Specifically, the small cells transmitters is one of the 5G technologies more relevant to provide more connections and to attend the high demand in smart cities. In this article, a smart small cell positioning is proposed in the context of a smart city. The work proposal aims to do this through the development of a hybrid clustering algorithm with meta-heuristic optimizations to serve users, with real data, of a region satisfying coverage criteria. Furthermore, the problem to be solved will be the best location of the small cells, with the minimization of attenuation between the base stations and its users. The possibilities of using multi-objective optimization algorithms based on bioinspired computing, such as Flower Pollination and Cuckoo Search, will be verified. It will also be analyzed by simulation which power values would allow the continuity of the service with emphasis on three 5G spectrums used around the world: 700 MHz, 2.3 GHz and 3.5 GHz.
Introduction
The emerging concept of Smart cities is being promoted with the deployment of 5G technologies. Considering the increasing amount of industrialization with urbanization, the huge demand for resources and their ubiquitous use are catalyzing the emergence deployment of smart city technologies and applications. All urbanization enablers like transportation and mobility, health care, natural resources, electricity and energy, homes and buildings, commerce and retail, society and workplace, industry, agriculture and the environment, are hugely dependent of a suitable communication and safe capabilities to support these smart cities application domains.
Meanwhile, the fifth generation of wireless communications, the 5G system, is currently being integrated, with an extensive range of applications and frequency channels for its operation. According to Dahlman et al. (2014), 5G operation aims at a 1,000 times greater traffic capacity and a pulled bandwidth capacity capable of working with a latency response of 1 ms with data rates in the order of 1 to 10 Gbps. The development of 5G systems is divided into indoor and outdoor spreads. Generally, the sub-6 GHz band is applied outdoors because it is easier to transmit and propagate, and communication companies are already testing and applying 5G systems in this band for commercial purposes, in different parts of the world, as reports from Viavi (2022) have shown. In Brazil, it is no different—all major operators already have 5G systems in operation for several capitals in the country. AgênciaBrasil (2021) and Reuters (2021) inform that the main frequencies to operate 5G in the country, according to the government body Anatel, are 700 MHz, 2.3 GHz and 3.5 GHz for outdoor systems, and 26 GHz for indoor deployments.
GSMA (2021) states the band allocation of auctioned 5G spectrums in Brazil. The sub-6 GHz bandwidths are 20 MHz for 700 MHz (10 MHz per operator), 90 MHz for 2.3 GHz (40 or 50 MHz per operator), and 400 MHz for 3.5 GHz (80 to 100 MHz per operator). The 3.5 GHz spectrum is, currently, the most used for 5G applications around the world, and it is the range that possesses the greater number of proposed devices in the literature. Examples can be found in Li et al. (2021) and Kapoor, Mishra & Kumar (2021).
Along the difficulties tied to the deployment of 5G heterogeneous networks (5G HetNet), are the challenges to optimize their user coverage and user capacity, allowing for an increased number of services provided whilst keeping network costs low. And, as Rappaport et al. (2013) has stated, 5G coverage should be available everywhere, to anyone. That is, user coverage needs to be as closer to a hundred percent as ever.
A number of studies and surveys have dealt with the necessity of coverage optimization. Agiwal et al. (2021), for instance, dedicates a whole survey on the applications of 4G–5G inter-operations, and how those can be better achieved. This is because implementation of 5G networks till this day are much costing, and changes cannot be applied overnight. Meanwhile, 4G-LTE cells can provide service coverage while 5G is still expanding. Another survey that is worth noticing, written by Shayea et al. (2020), focuses on user mobility management and how user equipments (UEs) are prone to disconnect if there are no satisfactory solutions to coverage, capacity and handoff problems and challenges.
The study herein proposed aims to provide a solution to the coverage problem for future 5G network applications, focusing especially in the range of small cells. The positioning of small cells is a key concept of densification offering a potential solution for the ultra-dense traffic in Smart cities. Otherwise, to add to the traditional cell planning in this work two types of computational intelligence techniques will be tested, i.e., metaheuristic optimization through the utilization of a bioinspired computing algorithm (BIC) and a clustering technique. It is possible to group a set of users into an intelligent network coverage system, that aims to not only optimize the number of small cells but also deal with energy efficiency measures (such as controlling the transmitted power used in the cells).
Bioinspired computational methods are mainly based on natural selection. They are set to mimic the natural behavior of nature, in which the best and most surviving individuals prevail. With that in mind, these bioinspired algorithms serve as good optimization methods for mathematical and engineering problems, especially those where metaheuristic techniques (trial and error) can be applied to achieve one or more concrete goals. They have been applied to a multitude of areas where non-linear, multimodal optimization is required. E.g., Li et al. (2022) cite some areas of robotics where they might be useful, Nguyen et al. (2020) exposes some challenges in smart energy management that can be overcome with bioinspired solutions, and Gill & Buyya (2019) shows that some of them are even used on big data analysis and as aid to digitization of important documents into digital libraries.
The clustering method chosen for this application is K-means, which is extensively utilized in the literature for its simplicity and efficiency Ahmed, Seraj & Islam (2020). As for the bioinspired methods, two are to be tested in conjunction with K-means: the Cuckoo Search (CS) and the Flower Pollination Algorithm (FPA). As the aim of the work is to both maximize user coverage and minimize transmitted power, it is needed to use their multi-objective counterparts (that is, MOCS and MOFPA).
By using real data from open and free database OpenCellid, see Khan, García-Armada & Escudero-Garzás (2020), it is possible to pre-select cells with the greatest amount of user traffic in 4G-LTE in order to plan out how future 5G small cells shall behave in order to provide good coverage of service to users. More details about this are to be explained in the Methodology section.
The proposed hybridization of clustering and bioinspired algorithms is to be tested in simulations to determine an optimal user coverage for the three aforementioned frequencies that have been auctioned to operate in Brazil: 700 MHz, 2.3 GHz and 3.5 GHz. In total, two hybrid algorithms have been produced: MOCS + K-means (MOCS-KM) and MOFPA + K-means (MOFPA-KM).
The main contributions of this study are the provision of a metaheuristic method to achieve optimal network coverage with low-power small cells, and to provide data that can be adapted to an densely urban but with a rainforest climate such as the city of Belém, Brazil—which is where our OpenCellid data is from. A considerable area of the city has been selected to test the intelligent UE clustering simulations for 5G small cell implementation.
The article is organized into the following sections: Related Works discourses about some of the state-of-the-art solutions for coverage and capacity optimization for 5G as well as bioinspired/clustering algorithm hybrids; Methodology explains how the study was conducted, the theory behind the algorithms utilized and gives information on the propagation model chosen for path loss and user coverage modeling; the Results demonstrate the simulation of the algorithms for the different frequency ranges; and Conclusions expose our final considerations of the study.
Methodology
In this section, details about the objectives, the methods and optimization techniques used in this study are elucidated.
In general terms, the aim of the study presented herein is to acquire real-life LTE user data from OpenCellid to aid in the deployment of 5G cells in a four-neighborhood area from the city of Belém, Brazil. The involved neighborhoods are Sacramenta, Barreiro, Miramar and Pedreira, and the area is represented in Fig. 1.

Figure 1: Area of interest inside Belém, Brazil.
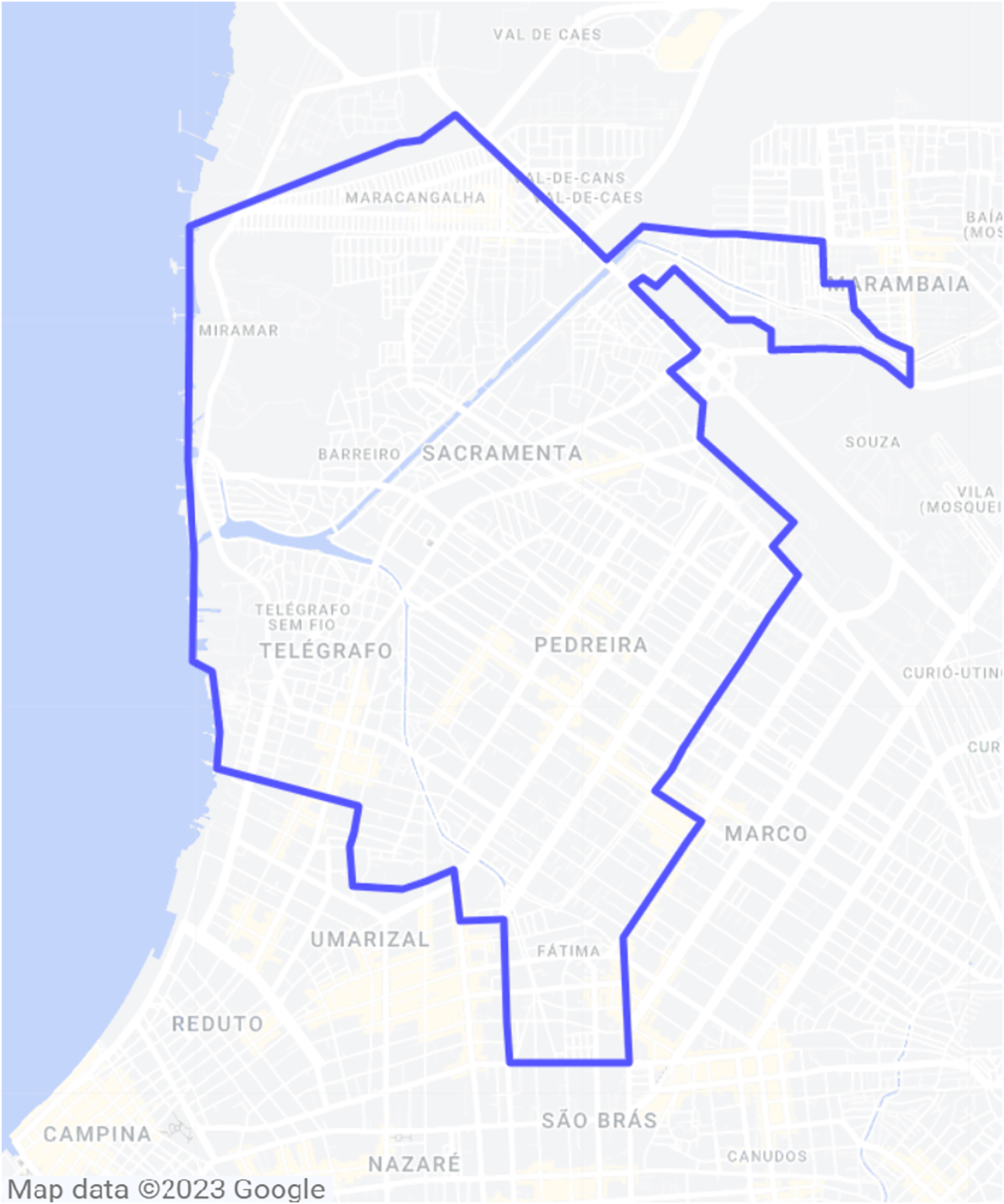{kind=link}
For that matter, by selecting the LTE cells with the greater traffic according to OpenCellid data, and inspired by the data mining process of Khan et al. (2022), a total of 19 LTE cells were selected to provide the highest data traffic areas and aid our deployment proposal. Therefore, by taking learning data from these cells, we have made a hybrid clustering/bioinspired technique that aims to solve the coverage problem in 5G frequency bands of 700 MHz, 2.3 GHz and 3.5 GHz.
Two problems to be optimized show up when thinking of providing coverage for a medium-to-high density urban area so large such as this: the number of cells (or clusters of users) that is required to achieve a good user coverage percentage, and also, for matters of energy efficiency, how much power should be applied to these cells in order to reach the best coverage by spending less energy. Given that our approach aims to minimize both these variables, network costs should also be minimized throughout the process. So, a simulation with an N number of users normally distributed in the aforementioned area is drawn to test how much coverage the proposed metaheuristic setup will achieve.
The Methodology from here is separated in various subsections. Firstly, the bioinspired algorithms shall be revised, then an explanation on the K-means clustering algorithm is given. Lastly, the hybridization process is explained, as well as the path loss propagation model for producing the objective functions.
Also, Table 1 denotes all variables, constants and parameters that are present in equations and results throughout the article with brief explanations and, when present, their units.
| Symbols | Descriptions |
|---|---|
| Base median path loss (ECC model) | |
| Free-space attenuation (ECC model) | |
| Receiving antenna gain factor (ECC model) | |
| Transmitting antenna gain factor (ECC model) | |
| Receiving antenna gain | |
| Transmitting antenna gain | |
| L | Pollination strength for global pollination (MOFPA) |
| Lower bounds of the search space (MOCS and MOFPA) | |
| Number of users connected to the network | |
| Maximum number of iterations (MOCS and MOFPA) | |
| Number of users disconnected from the network | |
| Number of total users in the optimization search space | |
| Path loss given by the ECC model (in dB) | |
| Nest discard probability (MOCS) | |
| Differential between optimized transmitted power and its minimum value (in dBm) | |
| , or | Received power (in dBm) |
| , or | Transmitted power (in dBm) |
| Upper bounds of the search space (MOCS and MOFPA) | |
| Position of an individual in the search space, for iteration t (MOCS and MOFPA) | |
| Position for next iteration t+1 of an individual in the search space (MOCS and MOFPA) | |
| Set of centroid positions (K-means) | |
| Haversine distance between a base-station and a user (in meters) | |
| Average fitness of the best generation produced by the optimization | |
| Best fitness produced by the optimization, overall | |
| Central frequency (in MHz or GHz, as specified) | |
| Single objective , in a multi-objective function | |
| Maximum fitness found within the best generation of the optimization | |
| Best current solution (MOFPA) | |
| Base-station antenna height (in meters) | |
| User antenna height (in meters) | |
| Number of clusters given by the optimization (MOCS and MOFPA) | |
| Cuckoo population (MOCS) | |
| Pollen population (MOFPA) | |
| Switch probability between local and global pollination (MOFPA) | |
| Step size of Lévy flight (MOFPA) | |
| Current iteration of the optimization algorithm (MOCS and MOFPA) | |
| Lévy distribution approximation, for the MOCS algorithm | |
| Weight of single objective , in a multi-objective function | |
| Data points to clusterize (K-means) | |
| Cluster membership variable (K-means) | |
| Step size of Lévy flight (MOCS) | |
| Random step length (MOCS) | |
| Parameter for local pollination strength (MOFPA) | |
| Parameter for global pollination strength (MOFPA) |
In order to the utilize multi-objective functions, the simplest way is to involve all objectives into a single mathematical sentence, as shown in Eq. (1):
(1) in which are the weights given to each objective, and are the single objectives and the sum of all weights must be equal to 1.
Multi-objective cuckoo search
One of the most utilized bioinspired algorithms, the Cuckoo Search algorithm has been created by Yang & Deb (2009). It has been used to optimize multiple applications ever since, mainly in the areas of mathematics and engineering, according to Shehab, Khader & Al-Betar (2017) and Ferreira et al. (2021). The main bioinspired idea behind this method is the computational modeling of the parasitic behavior of cuckoo-type birds, that often lay their eggs inside the nests of other types of birds. This is a natural occurrence in nature, as the host species often does not perceive the cuckoo’s “alien” egg inside the nest, or either choose to ignore it completely or abandon the nest altogether, choosing another place to lay its eggs on. However, if the egg is ignored and left to grow inside the host bird’s nest, the cuckoo hatchling is born, and reaches maturity much faster than the other eggs, pushing the host bird’s eggs outward. Thus, the cuckoo baby bird expels the other eggs from the nest, resulting in a higher food share for it, and becoming well-fed.
Thus, the whole process is based upon three major rules:
Each cuckoo lays one egg at a time, and deposits it in a random nest. Each egg is considered a potential solution—metaheuristic
The best nests carry the best eggs (solutions), and these will survive the next generations due the parasitic nature of the cuckoo hatchlings—elitism.
The number of available nests is constant, and defined by the code developer. The probability of a cuckoo egg being discovered by the host bird is defined as . After this, the bird may choose to discard this egg or abandon its nest—discarding the worst solutions.
The latter rule can also be described by indicating that a probability fraction Pa from the various n nests of host birds are replaced by new nests, presenting randomized solutions.
The movement of cuckoos within the search space is dictated by a stochastic method called Lévy flights, which provides each cuckoo (from a number of i cuckoos) in the code iteration a path to find possible solutions (nests). Equations (2) and (3) represent, mathematically, a Lévy flight and its Lévy distribution, respectively:
(2)
(3) where i and t are, respectively, the maximum number of cuckoos and the current code iteration. is a parametric value denoting the step size for the cuckoo flight, that must generally be greater than zero. In this study the value is set to , as Yang & Deb (2009) claim that an unitary alpha is sufficient for most optimization cases.
In Eq. (2), the Lévy distribution is associated to the Lévy flight with the product , which means “entrywise multiplication”—a kind of product between two matrices of the same size. In the PSO algorithm, a similar product can be found, however, for the Lévy flight method, the search space can be much better harnessed.
As for Eq. (3), this is about the Lévy distribution. It possesses infinite variance and average values. The variable is the random step length, needed for providing a variable magnitude to the random walk performed by the Lévy flight.
Given that the Lévy distribution presents infinite variance, the search space is virtually limitless, meaning that the length of the flight taken could be very short or incredibly long. However, generally, the new solutions are generated through the Lévy method around the best obtained solution on a given instant, accelerating the process and concentrating the computational effort in a part of the search space. Oftentimes, however, solutions are generated randomly across the space—this is good to prevent the algorithm from getting stuck in local optima, which are not the globally best possible solution.
An illustration showing a Lévy flight with around a hundred steps can be found in Fig. 2.
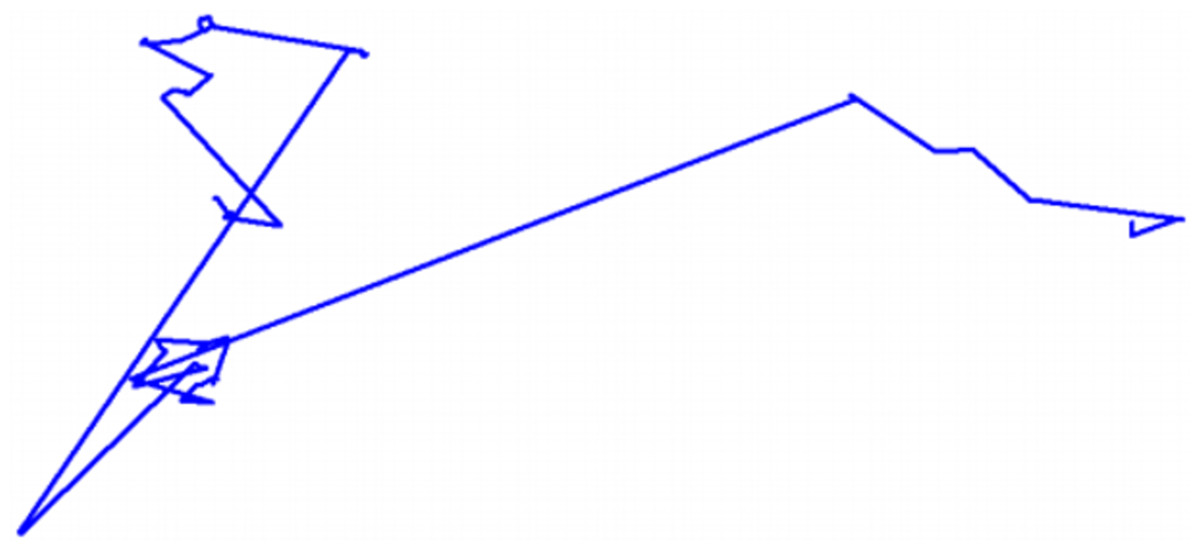
Figure 2: Representation of a 100-step Lévy flight in its search space.
{kind=link}
A pseudocode of the CS algorithm, as well as its multi-objective counterpart, can be found in the article in which it was proposed by Yang & Deb (2009). Below, in Algorithm 1, a transcription of this code is presented.
| Define the objective functions as |
| Generate the initial population of n host nests |
| while ( number of iterations) or (stop criterion) do |
| Select a cuckoo randomly via Lévy flight (Eq. (2)) |
| Evaluate the cuckoo’s fitness (represented by F) |
| Draft a random nest (say, j) out of the n available |
| if then |
| Replace randomly drafted j by the new solution xi |
| end if |
| Discard a fraction Pa of worse nests and build new ones |
| Keep the best/better quality solutions |
| Rank the best nest set and find the current best |
| end while |
| Post-process and visualize results |
Multi-objective flower pollination
A solution based on the behavior of natural flower pollinators has been proposed by Yang (2012), the same author of the cuckoo search, which also utilizes the Lévy flight method of optimal space search. Its efficiency, in many single and multi-objective applications is proven to be greater than particle swarm and genetic optimization algorithms. Its multi-objective counterpart has been proposed in 2013, also by Yang, Karamanoglu & He (2013).
As for the stages of the algorithm, four rules are defined thusly:
Biotic and cross-pollination is considered as global pollination process with pollen-carrying pollinators performing Lévy flights.
Abiotic and self-pollination are considered as local pollination.
Flower constancy can be considered as the reproduction probability and is proportional to the similarity of two flowers involved.
Local pollination and global pollination is controlled by a switch probability p [0, 1]. Due to the physical proximity and other factors such as wind, local pollination can have a significant fraction p in the overall pollination activities.
Two kinds of pollination are considered and simulated: global and local pollination. This assures that the code does not only fall for local solutions, healthily seeking to encounter a global solution to the objectives. For simplicity manners, the algorithm is based on the idea that every plant possesses only one flower and can pollinate also just one other flower at a time, when in true biological terms they can hold a few flowers and millions of pollinating gametes. This is so that a plant/flower/pollinating gamete are all considered to be part of one solution altogether.
Hence, the first rule (global pollination) and third rule (flower constancy) of FPA are mathematically represented as shown in Eq. (4):
(4) where is the pollen i or solution vector at iteration t, and g is the current best solution among all solutions at the current iteration.
Pollination strength L is dealt via Lévy flight, in which it is a measure of each flight’s step size, as denoted in Eq. (5). Here, the flights symbolize the path of insects and pollinator animals in a given area—in the algorithm, this area is the optimization’s global search space. However, the equation used in this algorithm differs from the one found in cuckoo flights, as it is based on producing Lévy flights via the Mantegna algorithm. This is basically a technique to generate pseudo-random step sizes via normal distributions in order to provide an optimal performance whilst still maintaining the demands of the Lévy distribution.
(5) in which is the standard, classic gamma function found in Lévy flights, and other probabilistic and complex number applications.
The Mantegna step size algorithm can be explained as the Eq. (6).
(6) with being the step size, U being drawn from a Gaussian distribution of variance and V also being drawn from a Gaussian distribution but with unitary variance, as can be verified in Yang, Karamanoglu & He (2014). Generally, the lambda is treated as a parametric value and it is safe to assume that it is a constant with a possible value of around . When , the variance also equals 1, and results are in such case easier to predict.
For the purpose of Rule 2 (local pollination), the flower constancy is mimicked for a limited neighborhood near to the reproductive flower’s position. It is represented as
(7) where and are pollens from different flowers of the same plant species.
The fourth rule is a probabilistic switch between global and local pollination, and the probability p can be parametrically and singularly adjusted to improve optimization performance, depending on the need of the objective function.
All stages of the algorithm are represented in pseudocode form by the recommendations in Yang (2012), which are transcribed in Algorithm 2. Some details previously discussed can be noticed, such as an if/else switch for global and local pollination, which are done by Lévy flights and random selection, respectively.
| Define the objective functions as |
| Generate an initial population of flowers/pollens as random solutions |
| Find, within this population, the best solution |
| Define the switch probability |
| while ( number of iterations) or (stop criterion) do |
| for all n flowers in the population do |
| if then |
| Generate a step vector L which obeys a Lévy distribution |
| Execute global pollination as in Eq. (4) |
| else |
| Pick a uniformly distributed number from |
| Randomly choose individuals j and k from all solutions |
| Do local pollination according to Eq. (7) |
| end if |
| Evaluate new solutions |
| Update solutions that are better into the population |
| end for |
| Find the best current solution, represented by |
| end while |
| Post-process and visualize results |
The K-means algorithm
An unsupervised learning method of computational intelligence, the K-means clustering algorithm has the goal of grouping similar data points. Each of those amount of clusters, then, possesses a centroid, which is the mean value M of all positions of the data points. Due to being fast and easy to reproduce, it is one of the most popular clustering algorithms. Sinaga & Yang (2020) defines the objective function of K-means according to the following equation (Eq. (8)):
(8) in which is a data point i belonging to a dataset spread over an Euclidean space of d-dimensions, is the centroid of the k-th cluster and is a binary variable (either 0 or 1) that signals if the user i belongs to cluster k. Given that the objective function needs to be minimized, the algorithm then proceeds to alter the centroids by also minimizing the Euclidean distance between them and the data points that belong to them, according to Eq. (9):
(9) where is the Euclidean distance.
The ECC-33 propagation model
A channel path loss model is required to evaluate which users are connected to the network. This propagation model should both belong to a frequency range where the 5G-NR channels are going to be propagated, as well as adapt to the environment in which it shall be applied. Some examples in the literature by Samad, Choi & Choi (2022) and Oladimeji, Kumar & Elmezughi (2022) address models such as the Close-In (CI), Floating Intercept (FI) and Alpha-Beta-Gamma (ABG), along with measurement campaigns to verify their usage in 5G channel modelling characteristics.
However, in this study, an ECC-33 model was chosen, which is adapted to the urban but forested environments of the city of Belém, as proposed by de Carvalho et al. (2021).
ECC-33 is derived from the famous Okumura-Hata model, but taking into consideration the behavior of higher frequencies, thus extending the frequency range. In Mollel & Michael (2014), experimental results have been drawn by comparing different path loss models conducted in Dar es Salaam, Tanzania. The COST-231 and ECC-33 models had the lesser Root Mean Square Error (RMSE), meaning that—for urban, suburban and rural settings—they had the most approximate results to measured signal data.
Therefore, the model used in this work is defined thusly:
(10) in which is the free-space attenuation, is the base median path loss and and are the transmitting antenna gain factor and received antenna gain factor, respectively. The values used for the model correspond to the large city scenario, as all acquired data correspond to an urban region of medium-to-high density. The following Eqs. (11)–(14) further detail the variables of the model:
(11)
(12)
(13)
(14) in which , and are the central frequency, the base-station antenna height and the user device’s antenna height, respectively. While is the distance between a user and a base-station, that in this study is calculated by the haversine distance formula, as it appears on Gade (2010) and Chopde & Nichat (2013):
(15) where are the latitudinal positions, are the longitudinal positions, and R is the approximate radius of the Earth ( m). Furthermore, the received power for an user is represented in Eq. (16):
(16) in which are the transmitting (Tx) antenna gain and receiving (Rx) antenna gain.
The hybridization process
In real-life scenarios, not often is the number of clusters to achieve optimal results is known beforehand. For that, there are some heuristic methods that can be utilized to get approximations of how many clusters one might need to satisfy an application. For instance, Khan et al. (2022) have chosen the Elbow heuristic. However, given that one might need a more complex and sophisticated way of deciding how to cluster, and how much to cluster, like in a scenario of network dimensioning and coverage area optimization, these heuristics may not provide optimal solutions. This is why a metaheuristic method, like a bioinspired algorithm, is more suited for this task. The hybridization of a clustering algorithm like K-means and a metaheurisitc BIC means that both of those methods benefit from each other. The K-means provides the base-station coordinates on a given area, and the BIC provides the values of the ideal number of clusters, taking into consideration multiple inputs that will decide how much clustering there must be. Figure 3 demonstrates the whole process of the study. Please notice how the K-means processes a geographical position for cluster centers and the BIC returns it a number of clusters to attempt and see if an optimal result is reached. This process has the goal, in our study, to provide an optimal value of k clusters, as well as a satisfactory transmitted power value.
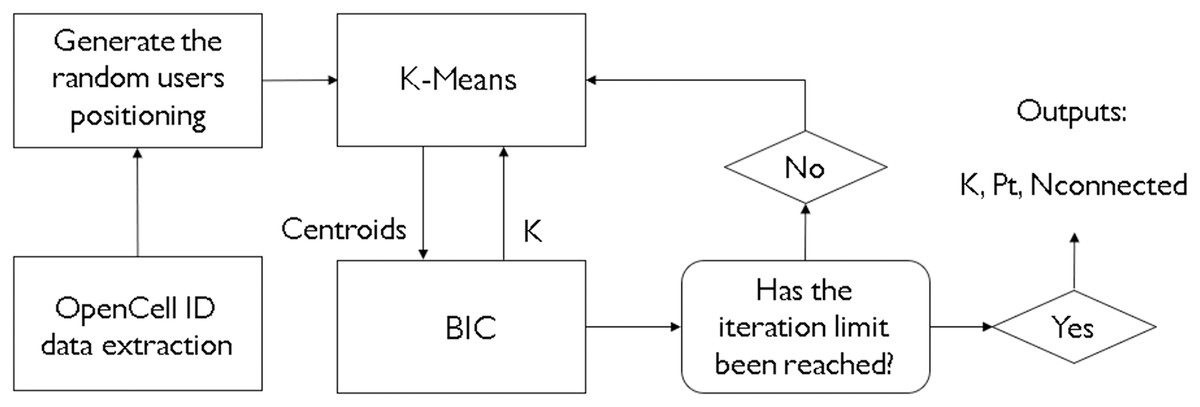
Figure 3: Flowchart of the processes involved in this study.
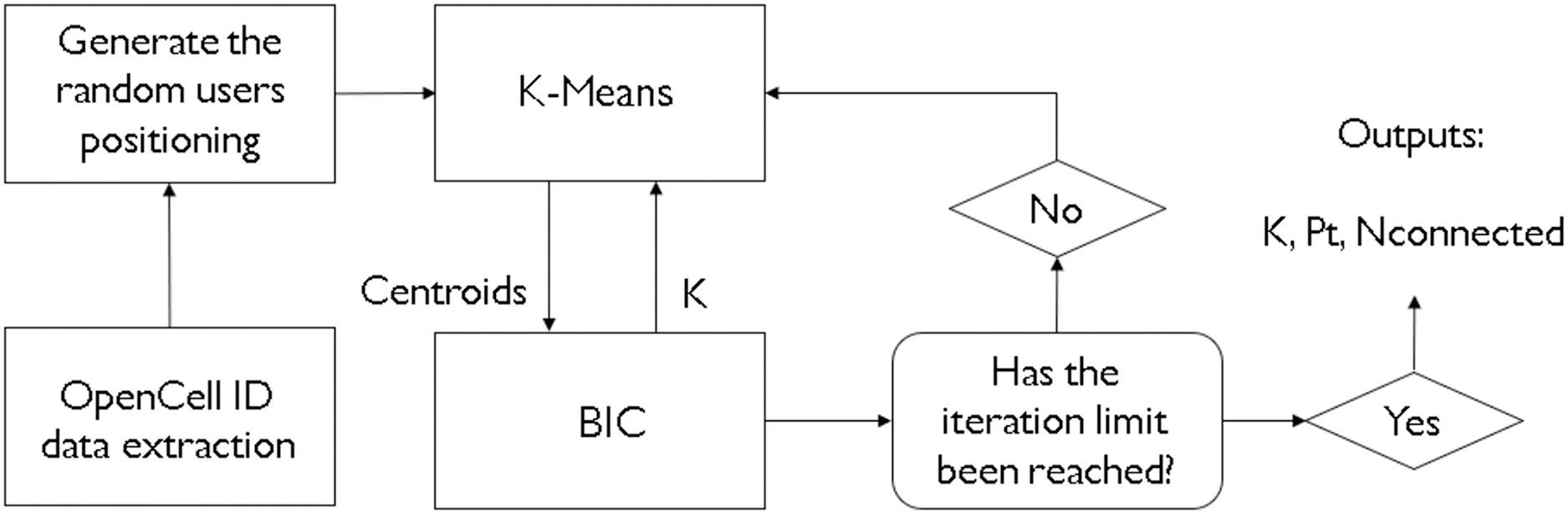{kind=link}
A pseudocode displaying the structure of the hybridization can be found in Fig. 3. For each iteration of the BIC, the K-means will run alongside it, providing cluster center (or centroid) values that the BIC shall take and calculate the received power for each and every user, one cluster at a time. If the user has a received power of −90 dBm or greater, it will be considered as connected to the network and, thus, covered.
| Define the constant values of , fc and antenna gains |
| Initialize one of the bioinspired optimization techniques (MOCS or MOFPA) |
| Generate an initial population with random solutions for k clusters and PBSt transmitted power |
| while (Iterations ≤ Max Iterations) do |
| Initialize the K-means for each k given by the BIC |
| for (all the clusters k in the K-means) do |
| for (all the users associated to cluster k) do |
| Calculate the distance between the user and its clusters’ centroid via (15) |
| Calculate the ECC path loss, present in (10) |
| Calculate the received power Pr as in (16), with Pt given by the BIC |
| if ( dBm) then |
| Count the user as within the coverage area |
| end if |
| end for |
| end for |
| Calculate the percentage of connected users in relation to the total number of users |
| Evaluate, with the BIC, the outputs in a single objective function |
| Update the best solutions into the population |
| end while |
| Post-process and visualize results |
Results
A total of 1,900 users have been randomly generated within the simulated area where the small cells shall actuate. This is to ensure that there are users in every corner of the area, and to assure that the clusters can manage to provide coverage for them.
It is worth to denote that the received power threshold to consider a user as connected to its respective cluster is dBm. This value has been chosen as a reasonable target for 5G mobile, heterogeneous networks to main good signal strength and capacity. Furthermore, as per stated in Ayad et al. (2022), values of between dBm are acceptable for this kind of application.
The objective function for the simulations can be defined as:
(17) in which is the difference of transmitted power to the ideal minimum value of 30 dBm, is the total number of users to be attended by the network, are the number of users connected to the small cells and is the percentage of users which are experiencing outage (i.e., disconnected from any cell). Therefore, the main objectives are to minimize the number of users that are excluded from the network whist maintaining the lowest transmitted power possible, that is, and .
The search space bounds on the number of clusters and transmitting power are: and . These power values for are the limits generally found in small cells, as stated by Khan, García-Armada & Escudero-Garzás (2020). So, the objective for is to approach its minimum value, that is, . It also can be noticed that, since the main goal of the study is to achieve better coverage for users in 5G networks, there is a 0.7–0.3 weight towards coverage over transmitted power optimization in the objective function (Eq. (17)).
Table 2 refers to the constant and variable values that have been coded into the algorithms and the propagation model:
| Parameters | Values |
|---|---|
| Tx antenna height ( ) | 40 m |
| Rx antenna height ( ) | 1.6 m |
| Tx antenna gain | 3 dBi |
| Rx antenna gain | 0 dBi |
| Central frequencies ( ) | [700 MHz, 2.3 GHz, 3.5 GHz] |
| Number of clusters (k) bounds | 1 to 100 clusters |
| Transmitted power ( ) bounds | 30 to 40 dBm |
| Discard probability, for MOCS ( ) | 0.25 |
| Switch probability, for MOFPA ( ) | 0.5 |
The simulation and its algorithms have been coded in MATLAB, and are run on a personal computer with these characteristics: AMD Ryzen 5 CPU with 4.2 GHz clock and 16 GB DDR4 RAM.
Results for 700 MHz
Firstly, Figs. 4 and 5 display the results achieved for the 700 MHz frequency band for, respectively, the MOCS-KM and MOFPA-KM. This is a band that possesses a fairly low data rate and bandwidth, but since it is one of the auctioned bands for 5G operation in Brazil, it is included here as means of comparison and to test the BIC + K-means hybrids.
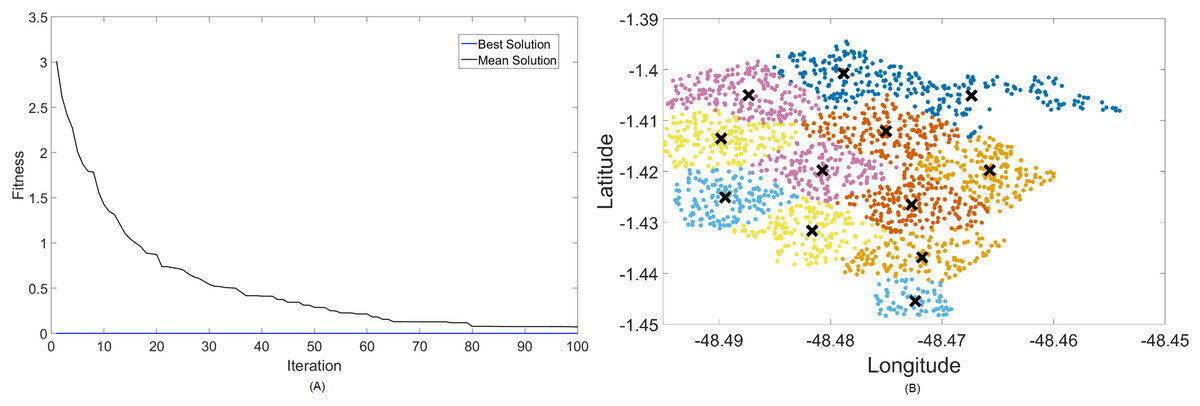
Figure 4: Results for 700 MHz: (A) fitness plot of MOCS-KM and (B) cluster formation given by the technique.
{kind=link}
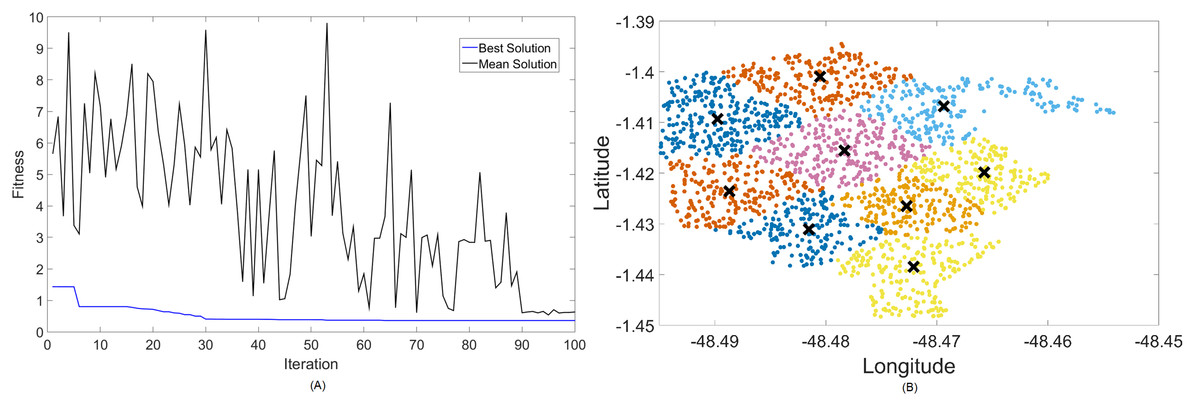
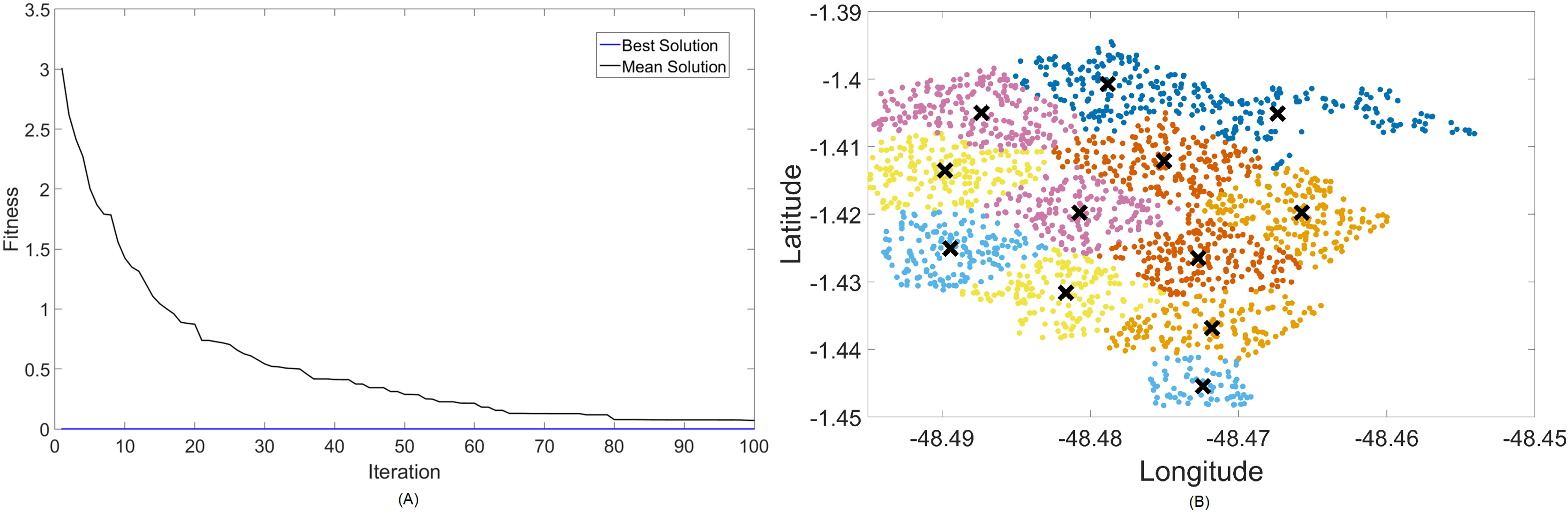
Figure 5: Results for 700 MHz: (A) fitness plot of MOFPA-KM and (B) cluster formation given by the technique.
{kind=link}
The X symbols in the figures displaying the clusters are referent to the position of centroids, and the colored dots correspond to the users.
Here, the algorithm had no problems whatsoever in optimizing for zero fitness, needing only a few iterations to converge. This is because path loss is less intense for lower frequencies, and so a small group of small cells can already provide perfect coverage.
The best solver in this case is MOCS-KM, with a solution of 12 clusters and power of 30 dBm. However, MOFPA-KM comes very close to a zero fitness value as well, with an inferior number of clusters of only 9 and 30 dBm power.
Results for 2.3 GHz
The band that promises to function both in LTE and in 5G is shown next. Figures 6 and 7 are the results for the 2.3 GHz frequency band. It is expected to operate in smaller cities as a means of digital inclusion, providing more bandwidth to 4G-LTE demands, or in urban centers as a complementary traffic alternative to the main band of 5G, which is 3.5 GHz.
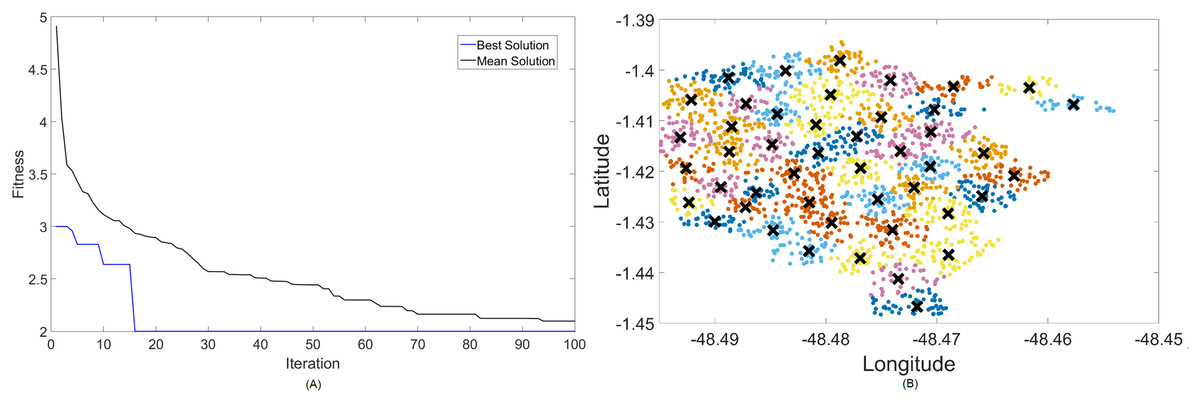
Figure 6: Results for 2.3 GHz: (A) fitness plot of MOCS-KM and (B) cluster formation given by the technique.
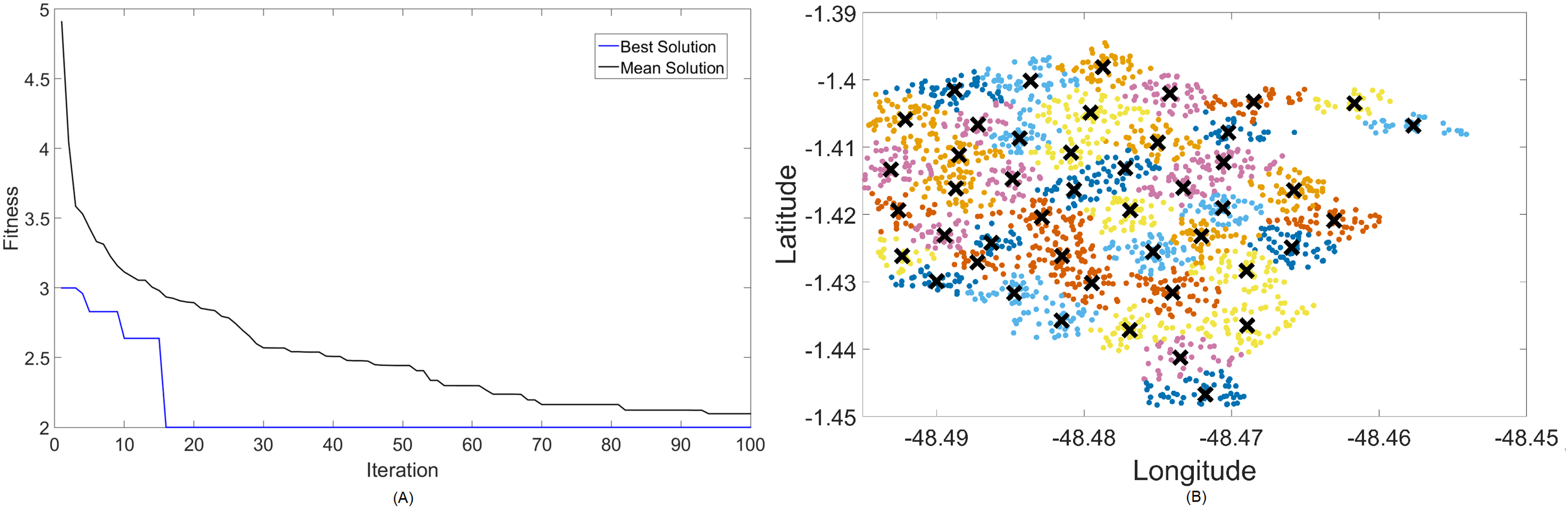{kind=link}
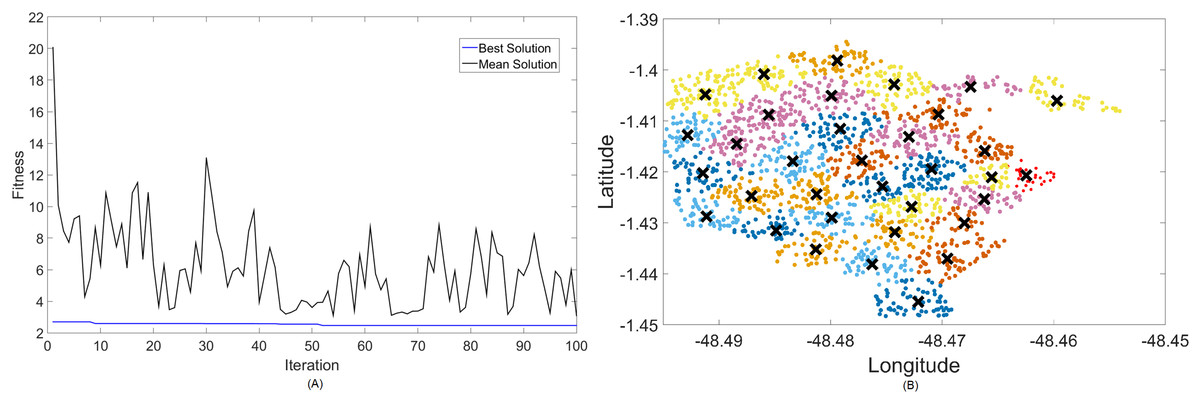
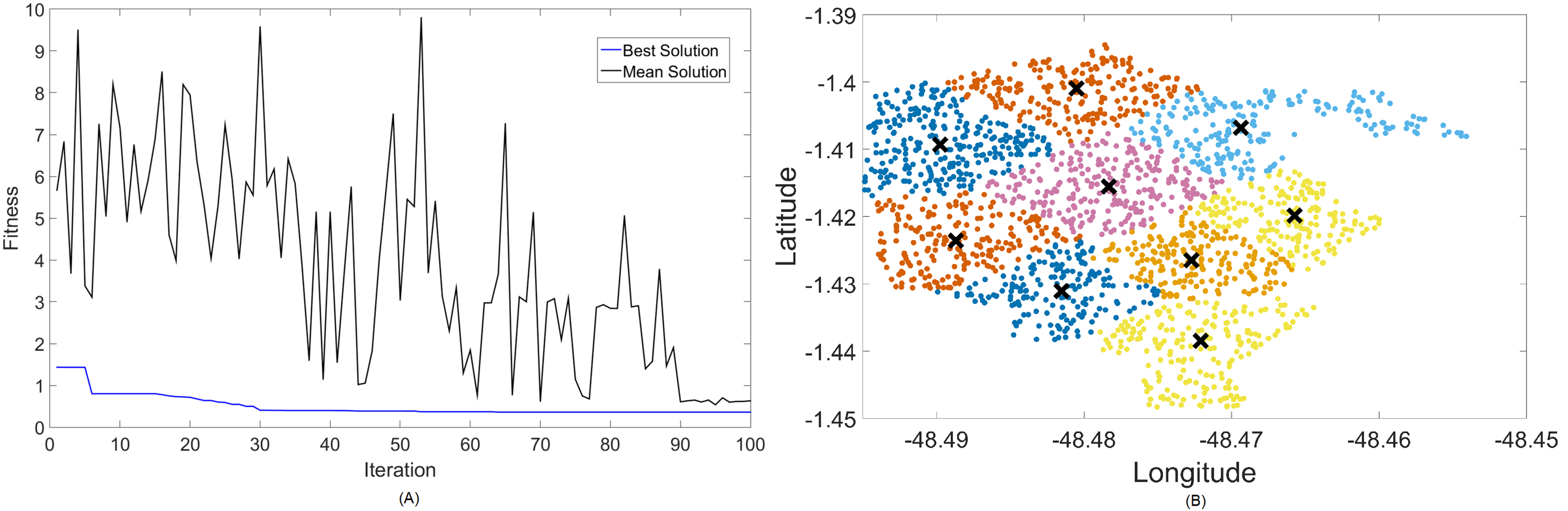
Figure 7: Results for 2.3 GHz: (A) fitness plot of MOFPA-KM and (B) cluster formation given by the technique.
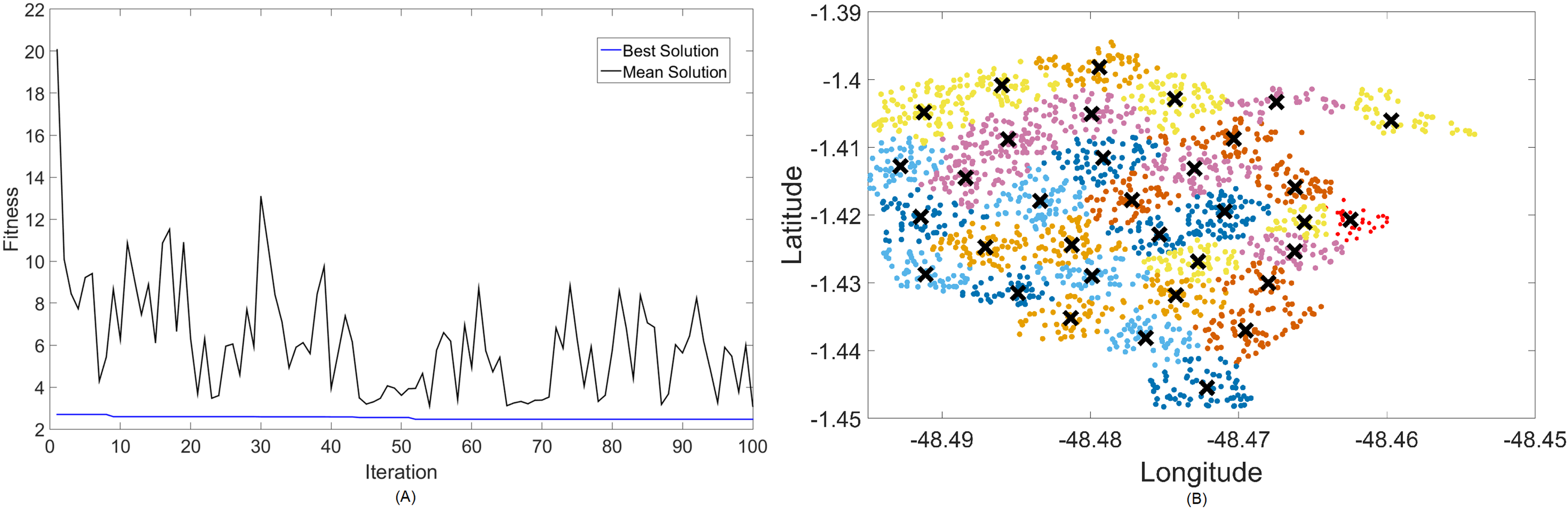{kind=link}
Results for this band are already harder to solve than 700 MHz, with the best fitness results coming from MOCS-KM once again. It has achieved , with 46 clusters and a satisfactory transmitted power of 31 dBm. MOFPA-KM has proposed a higher value with less clusters, resulting in , , and dBm.
Results for 3.5 GHz
Finally, the main and most used frequency band of 5G. The 3.5 GHz spectrum possesses up to 80 MHz of band per operator in Brazil, and is set to expand in highly-urbanized areas, as it can handle greater traffic and provide faster data rates than the other two. Figures 8 and 9 demonstrate the results of the simulation for this frequency.
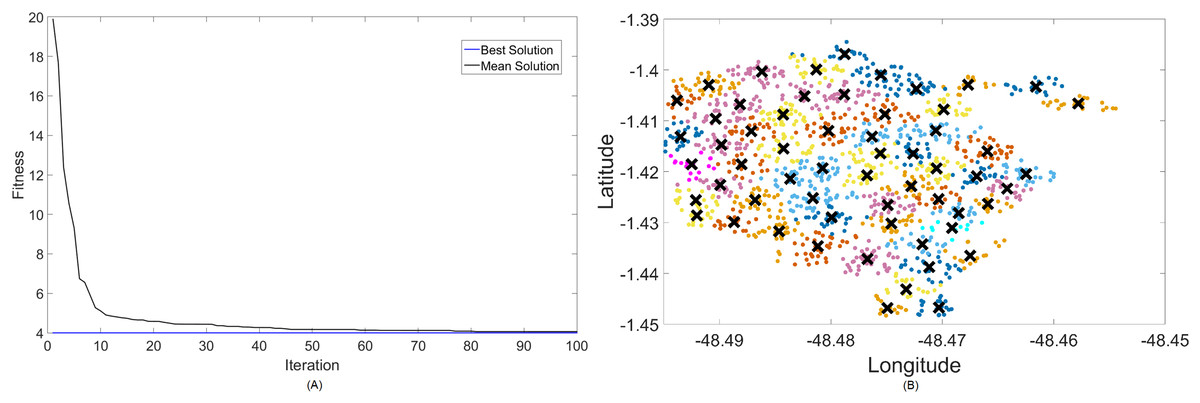
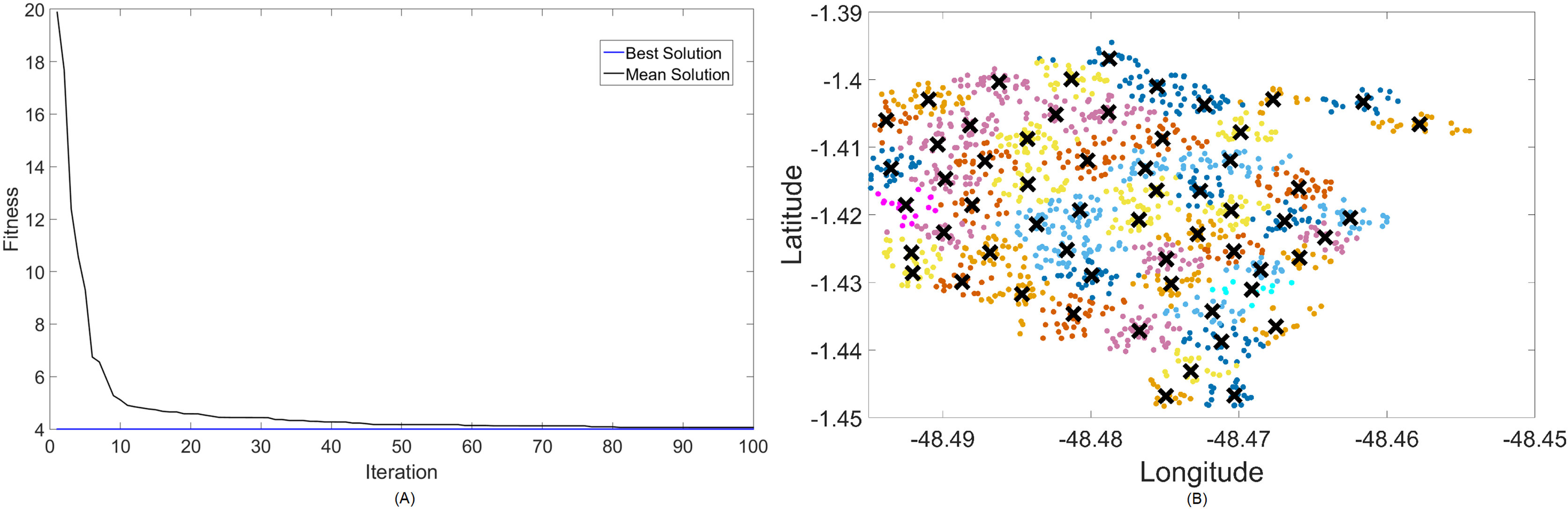
Figure 8: Results for 3.5 GHz: (A) fitness plot of MOCS-KM and (B) cluster formation given by the technique.
{kind=link}
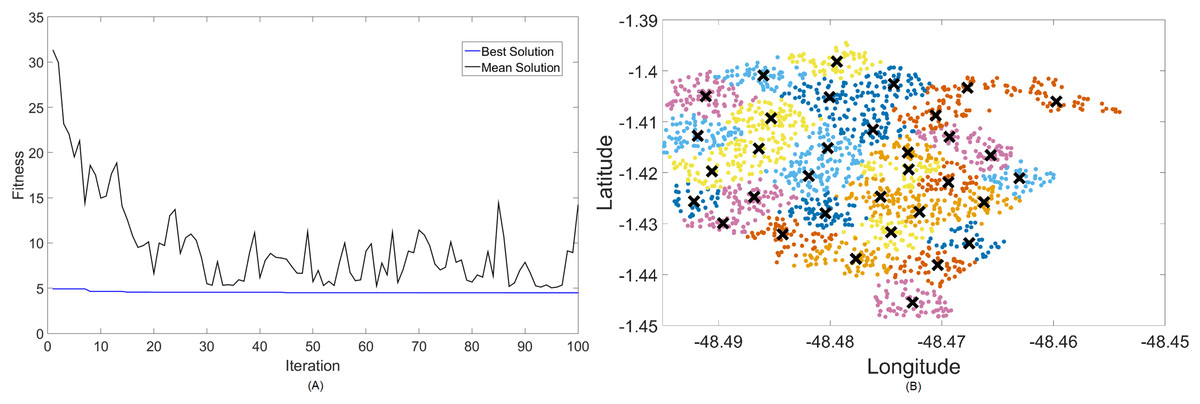
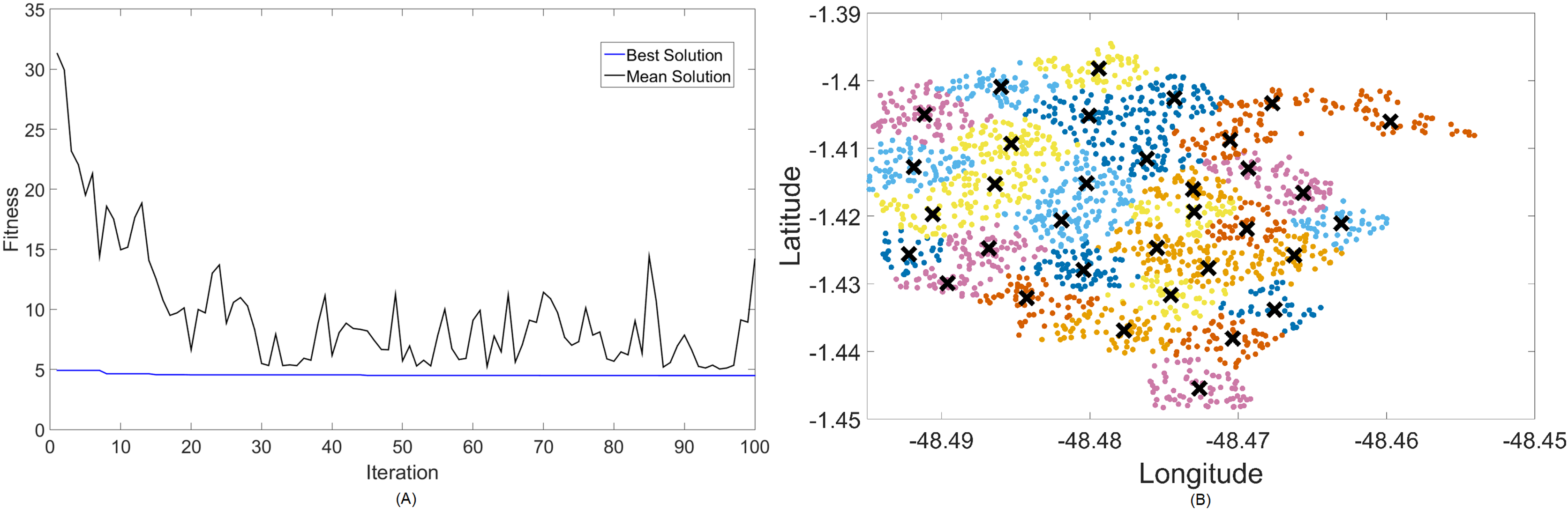
Figure 9: Results for 3.5 GHz: (A) fitness plot of MOFPA-KM and (B) cluster formation given by the technique.
{kind=link}
For this case, the results are basically the same in terms of coverage, but fitness values turn greater because of the choice in both algorithms to utilize more transmitted power instead of increasing the number of clusters too much. In terms of fitness, MOCS-KM marginally wins again, with . That being said, MOFPA-KM has converged to a solution with 34 clusters again—the same number from the 2.3 GHz simulation. It has, however, increased the transmitted power to its maximum value of 40 dBm in order to achieve that.
Table of results
In Table 3, results for the optimization processes of MOCS-KM and MOFPA-KM hybrids are shown. For the best generated population (the one which produced ), it records the maximum, medium and best fitness values, as well as the outputs and the running time of the respective simulations.
| Simulation | Time (s) | |||||||
|---|---|---|---|---|---|---|---|---|
| 700 MHz (MOCS-KM) | 12 | 30 | 0 | 0 | 0.7892 | 0.1327 | 0 | 552 |
| 700 MHz (MOFPA-KM) | 9 | 30 | 0.5133 | 0 | 1.9397 | 0.6075 | 0.3593 | 594 |
| 2.3 GHz (MOCS-KM) | 46 | 31 | 2.4285 | 1 | 10.9882 | 2.1649 | 2 | 848 |
| 2.3 GHz (MOFPA-KM) | 34 | 33.3352 | 2.0373 | 3.3352 | 4.7515 | 2.7564 | 2.4267 | 843 |
| 3.5 GHz (MOCS-KM) | 59 | 38 | 2.2857 | 8 | 5.5686 | 4.1163 | 4.006 | 993 |
| 3.5 GHz (MOFPA-KM) | 34 | 40 | 2.0421 | 10 | 6.3954 | 4.7312 | 4.4295 | 905 |
The parameters and variables displayed in Table 3 are: the optimal number of clusters (k); optimal transmitted power per cluster ( , in dBm); the percentage of users suffering outage ( , in %); the differential between optimal and the lower bound value of dBm ( , in dBm); maximum objective function fitness value found within the best generation ( ); average fitness value of all individuals in the best generation ( ); the fitness value of the best individual, in the best generation ( ); and the total running time of the optimizations (Time, in seconds).
Computational analysis
In order to elucidate the performance of both algorithms, a numerical analysis of their computational complexity has been conducted.
Theoretically, the study of algorithmic complexity of bioinspired computing and clustering hybrids has already been conducted. Kaur, Pal & Singh (2020) denotes that the complexity of both CS-KM and FPA-KM hybrids are set to linear variables in the Big-O formula—see Bae & Bae (2019). These are still valid for multi-objective counterparts of the same techniques. Thus, the equations for algorithmic time complexity, adapted from Kaur, Pal & Singh (2020), are as follows:
(18)
(19) in which , , , and are the number of iterations in the code, the number of clusters, the cuckoo population (for MOCS), the pollen population (for MOFPA), and the number of users to be covered by the network, respectively. The area of coverage, as considered in the original formula, can be replaced into the number of users to be covered by the network. In general terms, the more users a network needs to cover, the greater the area of coverage should be.
Numerical simulations have been performed taking into account the running time of the algorithms. Therefore, a set of 32 data points, 16 per technique, were obtained via simulations in order to measure the linearity of computational complexity. That is because, for each simulation, one of four parameters (iterations, clusters, population and users) is chosen to vary between four values, while all others are kept to fixed values.
Cardoso et al. (2020) is an example of an article that provides a numerical analysis of results. Although it utilized another network planning method (cellular automata, or CA), its methodology, along with Kaur, Pal & Singh (2020), have served as basis for the computational analysis made in this work.
Table 4 shows the variations chosen for each parameter, denoting in italic letters which ones are kept constant—for both MOCS-KM and MOFPA-KM. Lastly, Figures 10 and 11 display the numerical analysis results for MOCS-KM and MOFPA-KM parameters, respectively. These are curve fittings (blue line) taking into account the simulated data points (circles) in MATLAB.
| Parameters | Values |
|---|---|
| Iterations ( ) | [50, 100, 150, 200] |
| Clusters (k) | [1 to 50, 1 to 100, 1 to 150, 1 to 200] |
| Cuckoo population ( ) | [15, 20, 25, 30] |
| Pollen population ( ) | [15, 20, 25, 30] |
| Users ( ) | [400, 900, 1,400, 1,900] |
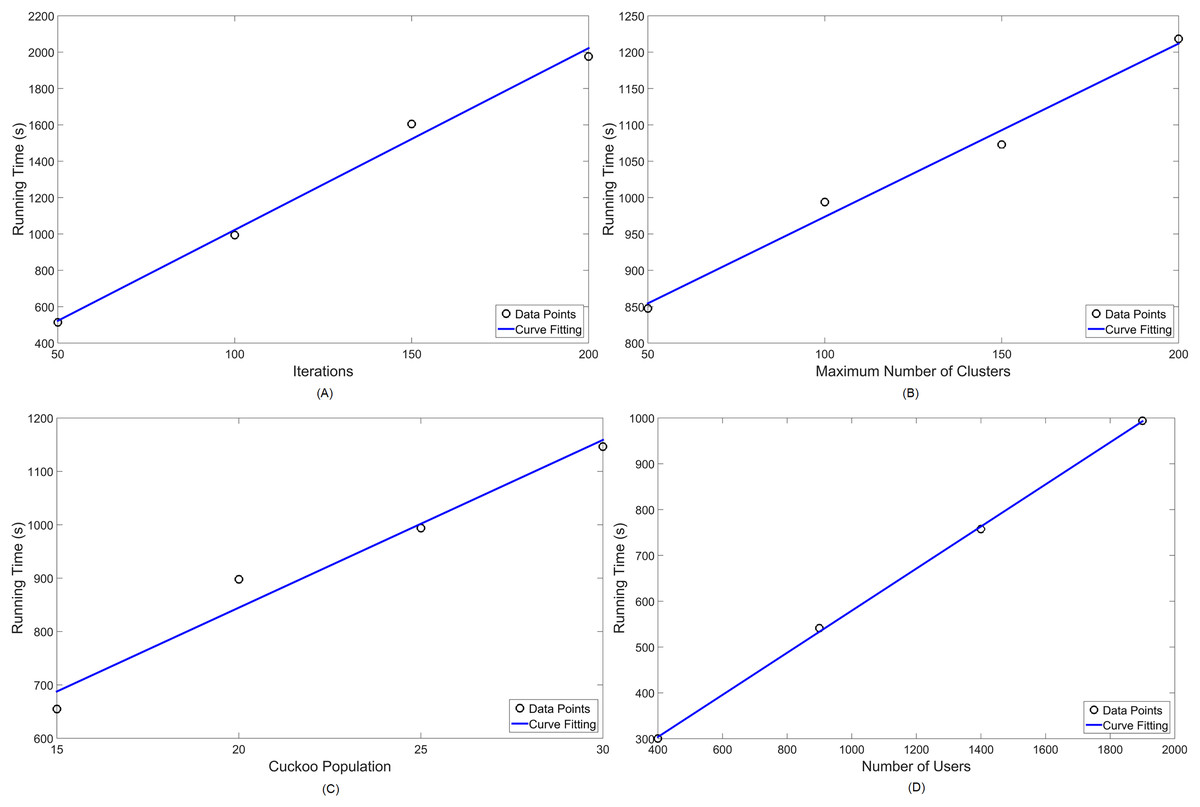
Figure 10: Numerical analysis over running time for MOCS-KM: (A) number of iterations ( ); (B) number of clusters (k); (C) Cuckoo population ( ) and (D) number of users ( ) in the simulation.
{kind=link}
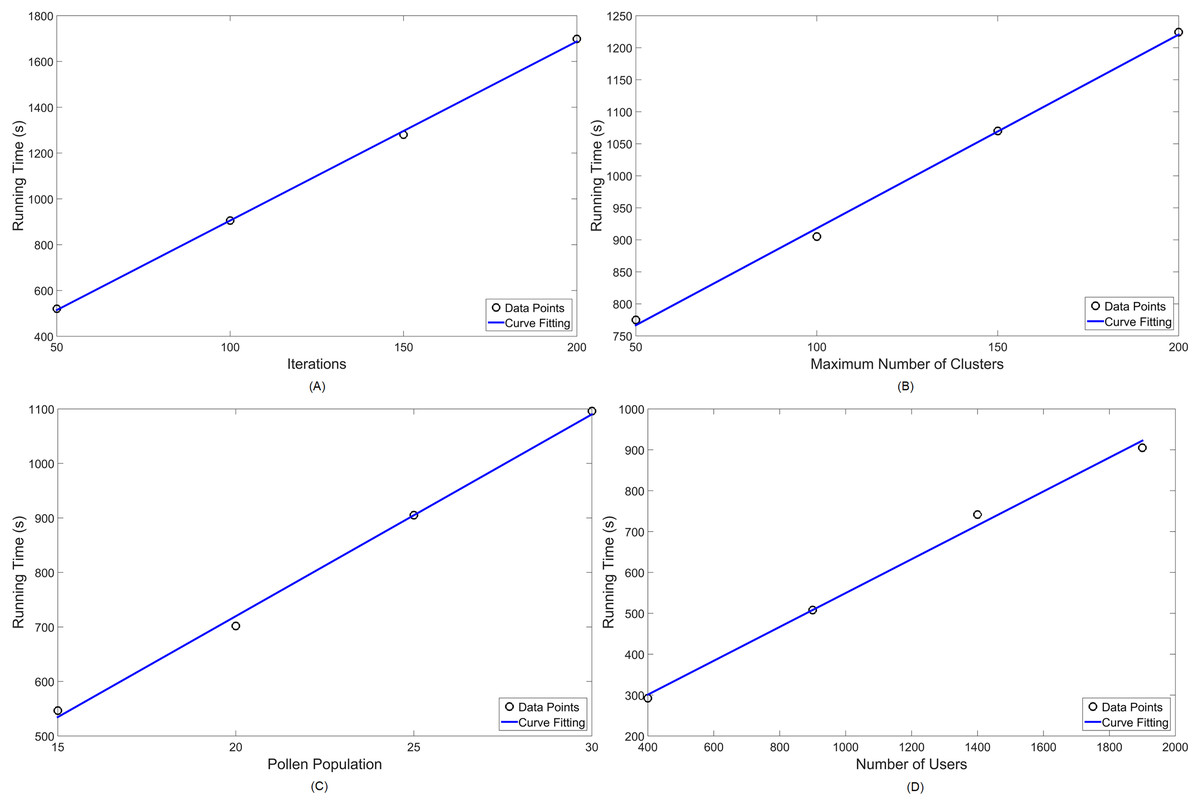
Figure 11: Numerical analysis over running time for MOFPA-KM: (A) number of iterations ( ); (B) number of clusters (k); (C) pollen population ( ) and (D) number of users ( ) in the simulation.
{kind=link}
Given that simulational results have shown in Table 3 to operate, in standard parameter values, in around 10 to 15 min, these are satisfactory approximations for the NP-hard problem of cell planning. Furthermore, their performance are linearly scalable, thus easy to predict for a set of parameter values, as seen in Figs. 10 and 11.
Table 5 denotes the running times and coverage capacity (by number of users covered) of data points for MOCS-KM, whilst Table 6 does so for MOFPA-KM, both for the frequency of 3.5 GHz. These two variables are measured in the analysis of Cardoso et al. (2020), thus it is useful to detail them further here as well. The coverage ratio, which is the amount of users connected to the clusters, can be calculated as taken from objective function (Eq. (17)).
| Running time (s) | Coverage ratio (%) | ||||
|---|---|---|---|---|---|
| 50 | [1..100] | 25 | 1,900 | 513.517 | 96.1 |
| 100 | [1..100] | 25 | 1,900 | 993.888 | 97.4 |
| 150 | [1..100] | 25 | 1,900 | 1,604.884 | 97.4 |
| 200 | [1..100] | 25 | 1,900 | 1,976.066 | 97.4 |
| 100 | [1..50] | 25 | 1,900 | 847.608 | 97.4 |
| 100 | [1..100] | 25 | 1,900 | 990.723 | 97.4 |
| 100 | [1..150] | 25 | 1,900 | 1,072.863 | 97.4 |
| 100 | [1..200] | 25 | 1,900 | 1,218.268 | 97.4 |
| 100 | [1..100] | 15 | 1,900 | 654.813 | 97.4 |
| 100 | [1..100] | 20 | 1,900 | 897.975 | 97.4 |
| 100 | [1..100] | 25 | 1,900 | 991.452 | 97.4 |
| 100 | [1..100] | 30 | 1,900 | 1,146.521 | 97.4 |
| 100 | [1..100] | 25 | 400 | 654.813 | 95 |
| 100 | [1..100] | 25 | 900 | 897.975 | 96 |
| 100 | [1..100] | 25 | 1,400 | 991.452 | 96.6 |
| 100 | [1..100] | 25 | 1,900 | 1,146.521 | 97.4 |
| Running time (s) | Coverage ratio (%) | ||||
|---|---|---|---|---|---|
| 50 | [1..100] | 25 | 1,900 | 520.203 | 97.2 |
| 100 | [1..100] | 25 | 1,900 | 905.090 | 98 |
| 150 | [1..100] | 25 | 1,900 | 1,279.922 | 98 |
| 200 | [1..100] | 25 | 1,900 | 1,976.066 | 98 |
| 100 | [1..50] | 25 | 1,900 | 774.981 | 95.4 |
| 100 | [1..100] | 25 | 1,900 | 903.691 | 98 |
| 100 | [1..150] | 25 | 1,900 | 1,070.089 | 98 |
| 100 | [1..200] | 25 | 1,900 | 1,224.242 | 98 |
| 100 | [1..100] | 15 | 1,900 | 546.529 | 98 |
| 100 | [1..100] | 20 | 1,900 | 701.901 | 98 |
| 100 | [1..100] | 25 | 1,900 | 908.275 | 98 |
| 100 | [1..100] | 30 | 1,900 | 1,095.929 | 98 |
| 100 | [1..100] | 25 | 400 | 292.472 | 93.8 |
| 100 | [1..100] | 25 | 900 | 508.127 | 96.8 |
| 100 | [1..100] | 25 | 1,400 | 741.414 | 97.5 |
| 100 | [1..100] | 25 | 1,900 | 902.978 | 98 |
In Table 5, it is noticeable that the maximum coverage achieved by MOCS-KM, considering all users at 3.5 GHz, is capped at 97,4%. A likewise behavior is seen for MOFPA-KM, in Table 6, where maximum capacity is capped at 98%. When reducing the number of users, they may become more scattered in the search space, thus resulting in slightly lower coverage in some cases.
Conclusions
Smart cities will bring forth many future challenges, and this work proposed a novel small cell positioning system using a hybrid approach to provide better user coverage and to save more energy. The presented scheme deals with a method of clustering and optimizing for the implementation of 5G small cells according to user traffic, using the city of Belém, Brazil as a simulational example. Optimization was provided by the two hybrid methods, MOCS-KM and MOFPA-KM.
In general the simulations were satisfactory, as user outage is never greater than 2.5% for all cases, making the amount of connected users over 97%. Transmitted power levels have been kept within small cell ranges, providing good implementation opportunities. That being said, the techniques have a sort of preference that differentiate themselves. Also, it can be denoted that MOCS-KM prefers to increase the amount of clusters to reduce the transmitted power, whilst MOFPA-KM is the opposite.
Therefore, the usage of said hybridizations should be a matter of preference for the network planner professional that intends to use them. For coverage optimization both present similar and adequate results, but MOFPA-KM keeps cluster numbers to a bare minimum and optimizes for greater power usage; and MOCS-KM is a bit more precise and uses less power per cluster but produces a higher amount of clustering. So, these variables are bound to limitations and cost of implementation issues that are up to which of those are less costly to produce.
Additionally, an analysis of the performance of both hybrid techniques has been tested in the results. Even though these are complex problems that cannot be solved in real-time, there is a predictable and linear behavior of running time and fitness of results for one-variable variations. It is also attested that the number of iterations in the code has the greatest influence in computational cost. Oftentimes, processing times are lower for MOFPA-KM and so is the coverage ratio.
Further challenges to enrich the study would be to implement more 5G capacity variables into the simulation. The focus of this article has been mostly on coverage problems, but there is much to add in concern to capacity dimensioning. Further opportunities for research involve minimization and measurement of network cost and maximization of throughput of data per area.
Supplemental Information
Matlab code program for optimization based on cuckoo search.
Matlab code function to calculate the distance between two points.
Matlab code program for optimization based on flower pollination.
Matlab code program to load data form the studied region and implementation of K-means.
plot_numerical.m.
Plot numerical tests done to calculate complexity analysis