Navigating the challenges of medical English education: a novel approach using computational linguistics
- Published
- Accepted
- Subject Areas
- Translational Medicine, Science and Medical Education, Computational Science
- Keywords
- computational linguistics, medical English, medical communications, medical humanities, international medical graduations, english for specific purposes, social medicine, text mining, interpersonal communication
- Copyright
- © 2016 Gayle
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ PrePrints) and either DOI or URL of the article must be cited.
- Cite this article
- 2016. Navigating the challenges of medical English education: a novel approach using computational linguistics. PeerJ PrePrints 4:e1711v2 https://doi.org/10.7287/peerj.preprints.1711v2
Abstract
Recent studies have shown that International medical graduates (IMG) comprise a substantial and increasingly larger share of the medical workforce, internationally. IMGs wishing to work in English-speaking countries face many challenges. And overcoming such challenges plays an important role in ensuring a more comfortable transition and improved outcomes for patients. This study addresses one such area of concern: the efficient acquisition of advanced language competence for use in the medical workplace. This research also addresses the needs of medical students and practitioners in other countries, where English is not the primary language. Medical terminology and phrasing is based on a tradition spanning more than 2500 years—a tradition that cuts across typical linguistic and cultural boundaries. Indeed, as is commonly understood, the language required by doctors and other medical professionals varies substantially from the norm. In the present study, this dynamic is exploited to identify and characterize the language and patterns of usage specific to medical English, as it is used in practice and reporting. Overall, constructions comprised of preposition-dependent nouns, verbs and adjectives were found to be most prevalent (38%), followed by prepositional phrases (33%). The former includes constructions such as “present with”, “present to”, and “present in”; while constructions such as “of … patient”, “in … group”, and “with … disease” comprise the latter. Preposition-independent noun and verb-based constructions were far less prevalent overall (18% and 5%, respectively). Up to now, medical language reference and learning material has focused on relatively uncommon, but essential, Greek and Latin terminology. This research challenges this convention, by demonstrating that medical language fluency would be acquired more efficiently by focusing on prepositional phrases or preposition-dependent verbs, nouns, and adjectives in context. This work should be of high interest to anyone interested in improved communication competence within the English-speaking medical workplace and beyond.
What is already known on this subject :
* International medical graduates make up a substantial portion of the medical workforce
* Imperfect medical English creates challenges for international medical graduates
* Subideal language impacts credibility and has been associated with increased risk to patients
What this paper adds :
* Preposition-dependent terms, following Germanic usage patterns, dominate medical English
* Complex terms derived from Greek and Latin are far less prevalent than assumed
* Medical English learning expected to be expedited by focus on preposition-dependent terms
Author Comment
International medical graduates now make up 20-30% of the medical workforce in many developed nations. However, subideal communication skills may impact work performance and career potential for many. Understanding and addressing this often overlooked area of minority disadvantage within medicine has become a subject of ongoing concern. We call this the "medical English problem". This manuscript presents a paradigm-changing approach to addressing a core portion of this issue. This preprint represents a key first step in addressing a much broader issue, and we welcome all comments, advice, and contributions from anyone affected by and/or struggling to address this "medical English problem".
//edit 1: updated formatting and added minor clarifications to the text
Supplemental Information
Fig 2. Grammar relationships, grouped according to POS
Y-axis shows prevalence as a percentage of the aggregate sum (n=9561). X-axis lists the various grammatical relationships included for discussion, grouped according to high-level grammatical part-of-speech.
{kind=link}
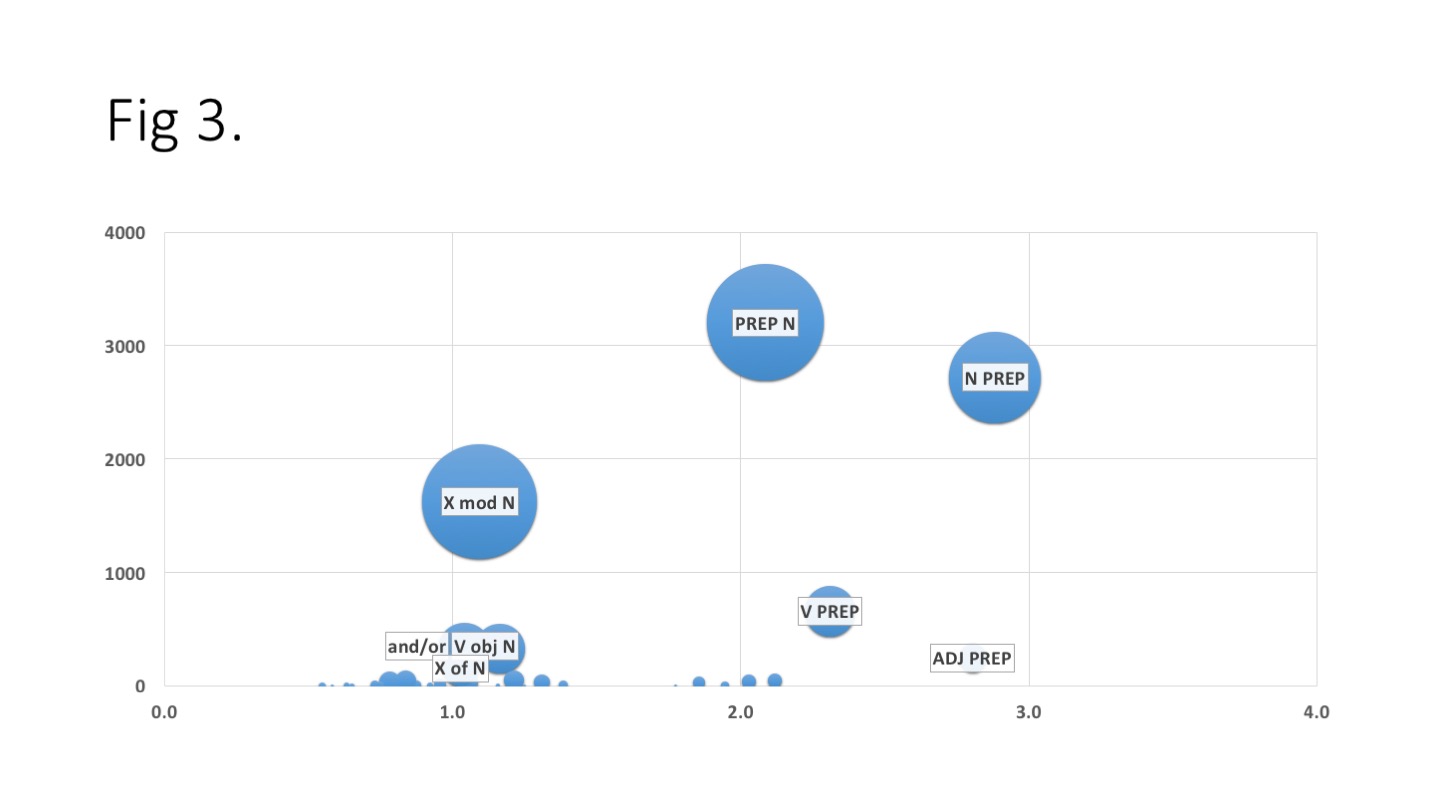
Fig 3. Overview of key grammar relationships
X-axis maps average term frequency per grammar relationship (importance), while Y-axis maps prevalence (term count * frequency). Bubble size represents term count (challenge). Only categories with term count > 100 are labelled.
{kind=link}
Microsoft Word - 20160201_Collocations_MS_3.4 (PeerJ Preprint).docx Microsoft Word - 20160201_Collocations_MS_3.4 (PeerJ Preprint).docx Table 1. Example output
Final output generated as shown here. Each column denotes: a) frequency per million (FREQ); b) term part at the head of a given collocation (LEFT); c) term part at the end of a collocation (RIGHT); d) grammar relationship between LEFT and RIGHT (GR).
Microsoft Word - 20160201_Collocations_MS_3.4 (PeerJ Preprint).docx Table 2. Top grammar relationships within medical English usage
Term Count (Percent) includes terms not shown; n = 5436. Term Frequency reflects term occurrence per million terms. Prevalence (Percent) is based on overall aggregate prevalence (count * frequency), n = 9561.
Table 3. Example usage for “V obj N”
Examples above represent a sample of the data set corresponding to the grammatical relationship, “V obj N”. For this group, passive constructions are shown to demonstrate collocational behavior identical to their active construction counterparts.
Supplemental Table 1
Microsoft Word - 20160201_Collocations_MS_3.4 (PeerJ Preprint).docx Overview of miscellaneous verbs and adverbial phrases.