Approximate spectral clustering using both reference vectors and topology of the network generated by growing neural gas
- Published
- Accepted
- Received
- Academic Editor
- Nicolas Rougier
- Subject Areas
- Algorithms and Analysis of Algorithms, Artificial Intelligence, Data Mining and Machine Learning, Software Engineering
- Keywords
- Spectral clustering, Growing neural gas, Self-organizing map, Large-scale data
- Copyright
- © 2021 Fujita
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2021. Approximate spectral clustering using both reference vectors and topology of the network generated by growing neural gas. PeerJ Computer Science 7:e679 https://doi.org/10.7717/peerj-cs.679
Abstract
Spectral clustering (SC) is one of the most popular clustering methods and often outperforms traditional clustering methods. SC uses the eigenvectors of a Laplacian matrix calculated from a similarity matrix of a dataset. SC has serious drawbacks: the significant increases in the time complexity derived from the computation of eigenvectors and the memory space complexity to store the similarity matrix. To address the issues, I develop a new approximate spectral clustering using the network generated by growing neural gas (GNG), called ASC with GNG in this study. ASC with GNG uses not only reference vectors for vector quantization but also the topology of the network for extraction of the topological relationship between data points in a dataset. ASC with GNG calculates the similarity matrix from both the reference vectors and the topology of the network generated by GNG. Using the network generated from a dataset by GNG, ASC with GNG achieves to reduce the computational and space complexities and improve clustering quality. In this study, I demonstrate that ASC with GNG effectively reduces the computational time. Moreover, this study shows that ASC with GNG provides equal to or better clustering performance than SC.
Introduction
A clustering method is a workhorse and becomes more important for data analysis, data mining, image segmentation, and pattern recognition. The most famous clustering method is k-means, but it cannot accurately partition a nonlinearly separable dataset. Spectral clustering (SC) is one of the efficient clustering methods for a nonlinearly separable dataset (Filippone et al., 2008) and can extract even complex structures such as half-moons data (Bojchevski, Matkovic & Günnemann, 2017). SC often outperforms traditional popular clustering methods such as k-means (von Luxburg, 2007). However, SC has significant drawbacks: the considerable increases in computational complexity and space complexity with the number of data points. These drawbacks make it difficult to use SC for a large dataset. Nowadays, the drawbacks are becoming more crucial as datasets become more massive, more varied, and more multidimensional.
SC treats a dataset as a graph (network) consisting of nodes and weighted edges. The nodes and the edges respectively represent the data points in the dataset and the connections between the data points. The weights of the edges are the similarities between data points. In SC, eigenvectors are calculated from the Laplacian matrix derived from the similarity matrix of the network. The rows of the matrix that consist of the eigenvectors are clustered using a traditional clustering method such as k-means. The drawbacks of SC for a large dataset are the time complexity to compute the eigenvectors and the space complexity to store the similarity matrix.
Researchers have tackled the high computational cost of SC. There are four approaches to improve the computational cost. The first approach is parallel computing to reduce computational time (Song et al., 2008; Chen et al., 2011; Jin et al., 2013). The second approach is data size reduction by random sampling. For example, Sakai & Imiya (2009) make a similarity matrix small by random sampling its columns to reduce the computational cost of eigendecomposition. The third approach is to use a low-rank matrix that approximates the similarity matrix of the original dataset to avoid calculating the whole similarity matrix (Fowlkes et al., 2004; Li et al., 2011). The last approach is to reduce a data size using a vector quantization method such as k-means (Yan, Huang & Jordan, 2009), self-organizing map (SOM) (Duan, Guan & Liu, 2012) and neural gas (NG) (Moazzen & Taşdemir, 2016). This method is called approximate spectral clustering or two-level approach. In approximate spectral clustering (ASC), data points are replaced with fewer reference vectors. We can decrease the computational cost of SC by reducing data size using a quantization method.
This study focuses on ASC using SOM and its alternatives such as NG and growing neural gas (GNG). SOM and its alternatives are brain-inspired artificial neural networks that represent data points in the network parameters. The network consists of units that have weights regarded as reference vectors and edges connecting pairs of the units. ASC uses fewer reference vectors instead of data points to reduce the size of the input to SC. Furthermore, the reference vectors are regarded as local averages of data points, thus, less sensitive to noise than the original data (Vesanto & Alhoniemi, 2000). This may improve the clustering performance of SC. The performance of SC highly depends on the quality of the constructed similarity matrix from input data points (Chang & Yeung, 2008; Li et al., 2018; Park & Zhao, 2018; Zhang & You, 2011). In other words, to construct a more robust similarity matrix is to improve the clustering performance of SC (Lu, Yan & Lin, 2016). Because of the dependence on the quality of the similarity matrix, SC is highly sensitive to noisy input data (Bojchevski, Matkovic & Günnemann, 2017). Thus, the lower sensitivity of reference vectors to noise may improve the clustering quality of SC. In many studies, reference vectors of a network generated by SOM are used to reduce input size, but the topology of the network is not exploited.
In this study, I develop a new ASC using a similarity matrix calculated from both the reference vectors and the topology of the network generated by GNG, called ASC with GNG. The key point is to regard the network generated by GNG as a similarity graph and calculate the similarity matrix from not only the reference vectors but also the topology of the network that reflects the topology of input. I employ GNG to generate a network because the network generated by GNG can represent important topological relationships in a given dataset (Fritzke, 1994) and the better similarity matrix will lead to better clustering performance in the ASC. The quantization by GNG reduces the computational complexity and the space complexity of SC. Furthermore, the effective extraction of the topology by GNG may improve clustering performance. This paper investigates the computation time and the clustering performance of ASC with GNG. Moreover, I compare ASC with GNG with ASC using a similarity matrix calculated from quantization results generated by neural gas, Kohonen’s SOM, and k-means instead of GNG.
Related works
The most well-known clustering method is k-means (MacQueen, 1967), which is one of the top 10 most common algorithms used in data mining (Wu et al., 2007). k-means is highly popular because it is simple to implement and yet effective in performance (Haykin, 2009). It groups data points so that the sum of Euclidean distances between the data points and their centroids is small. It can accurately partition only linearly separable data.
Expectation–maximization algorithm (EM algorithm) is a popular tool for simplifying difficult maximum likelihood problems (Hastie, Tibshirani & Friedman, 2009). EM algorithm can estimate the parameters of a statistical model and is also used for clustering. When we use EM algorithm for clustering, we often assume that data points are generated from a mixture of Gaussian distributions. However, EM algorithm cannot precisely partition data points not generated from the assumed model. k-means is described by slightly extending the mathematics of the EM algorithm to this hard threshold case (Bottou & Bengio, 1994) and assumes a mixture of isotropic Gaussian distributions with the same variances.
A major drawback to k-means is that it cannot partition nonlinearly separable clusters in input space (Dhillon, Guan & Kulis, 2004). There are two approaches for achieving nonlinear separations using k-means. One is kernel k-means (Girolami, 2002) that partitions the data points in a higher-dimensional feature space after the data points are mapped to the feature space using the nonlinear function (Dhillon, Guan & Kulis, 2004). All the computation of kernel k-means can be done by the kernel function using the kernel trick (Ning & Hongyi, 2016). However, kernel k-means cannot accurately partition data points if the kernel function is not suitable for the data points. The other is k-means using other distances such as spherical k-means (sk-means) (Dhillon & Modha, 2001; Banerjee et al., 2003, 2005) and cylindrical k-means (cyk-means) (Fujita, 2017). Sk-means uses cosine distance because of assuming the data points generated from a mixture of von Mises–Fisher distributions. Cyk-means uses the distance that combines cosine distance and Euclidean distance because of assuming the data points generated from a mixture of joint distributions of von Mises distribution and Gaussian distribution. However, k-means using other distances cannot accurately partition data points if the distance is not suitable for the data points.
Affinity propagation (Frey & Dueck, 2007) is a clustering method using a similarity matrix as in SC and is derived as an instance of the max-sum algorithm. Affinity propagation simultaneously considers all data points as potential exemplars and recursively transmits real-value messages along edges of the network until a good set of exemplars is generated (Frey & Dueck, 2007). Its advantage is that there is no need to pre-specify the number of clusters and no assumption of a mixture of distributions. Its time complexity is O(N2T) (Fujiwara, Irie & Kitahara, 2011; Khan, Amjad & Kleinsteuber, 2018), where N and T are the number of data points and the number of iterations, respectively. Space complexity is O(N2) because it stores a similarity matrix. For a large dataset, these complexities are not ignored.
Spectral clustering (SC) is a popular modern clustering method based on eigendecomposition of a Laplacian matrix calculated from a similarity matrix of a dataset (Taşdemir, Yalçin & Yildirim, 2015). SC does not assume a statistical distribution and partitions a dataset using only a similarity matrix. SC displays high performance for clustering nonlinear separable data (Chin, Mirzal & Haron, 2015) and has been applied to various fields such as image segmentation (Eichel et al., 2013), co-segmentation of 3D shapes (Luo et al., 2013), video summarization (Cirne & Pedrini, 2013), identification of cancer types (Chin, Mirzal & Haron, 2015; Shi & Xu, 2017), document retrieval (Szymański & Dziubich, 2017). In SC, a dataset is converted to a Laplacian matrix calculated from the similarity matrix of the dataset. We obtain a clustering result by grouping the rows of the matrix that consists of the eigenvectors of the Laplacian matrix. SC often outperforms a traditional clustering method, but it requires enormous computational cost and large memory space for a large dataset. Especially, its use is limited since it is often infeasible due to the computational complexity of O(N3) (Izquierdo-Verdiguier et al., 2015; Taşdemir, 2012; Taşdemir, Yalçin & Yildirim, 2015; Wang et al., 2013), where N is the number of data points. The huge computational complexity of SC is mainly derived from the eigendecomposition and constitutes the real bottleneck of SC for a large dataset (Izquierdo-Verdiguier et al., 2015). The required memory space increases with O(N2) (Mall, Langone & Suykens, 2013) because the similarity matrix is an N × N matrix.
Clustering a large dataset often becomes more challenging due to increasing computational cost with the size of a dataset. One approach to reducing the computational cost of clustering is two-level approach that partitions the quantization result of a dataset (Vesanto & Alhoniemi, 2000). In two-level approach, first, data points are converted to fewer reference vectors by a quantization method such as SOM and k-means (abstraction level 1). Then the reference vectors are combined to form the actual clusters (abstraction level 2). Each data point belongs to the same cluster as its nearest reference vector. The two-level approach has the advantage of dealing with fewer reference vectors instead of the data points as a whole, therefore reducing the computational cost (Brito da Silva & Ferreira Costa, 2014). This approach does not limit a quantization method in abstraction level 1 and a clustering method in abstraction level 2. There are many pairs of quantization methods and clustering methods, for example, SOM and hierarchical clustering (Vesanto & Alhoniemi, 2000; Taşdemir, Milenov & Tapsall, 2011), GNG and hierarchical clustering (Mitsyn & Ososkov, 2011), and SOM and normalized cut (Yu et al., 2012). Especially, the approach using SC in abstraction level 2 is called Approximate Spectral Clustering (ASC) (Taşdemir, Yalçin & Yildirim, 2015).
In two-level approach, there is the concern of underperformance of clustering by the quantization because it uses fewer reference vectors instead of all the data points in a dataset. However, a quantized dataset would be sufficient in many cases (Bartkowiak et al., 2005). Furthermore, two-level approach using SOM also has the benefit of noise reduction (Vesanto & Alhoniemi, 2000).
Approximate spectral clustering with growing neural gas
This paper proposes approximate spectral clustering with growing neural gas (ASC with GNG). ASC with GNG partitions a dataset using a similarity matrix calculated from both reference vectors and the topology of the network generated by GNG. ASC with GNG consists of the two processes, which are abstraction level 1 and abstraction level 2, based on two-level approach (Taşdemir, Yalçin & Yildirim, 2015; Vesanto & Alhoniemi, 2000). In abstraction level 1, a dataset is converted into the network by GNG. The similarity matrix is calculated from the network, considering the reference vectors and the topology of the network. In abstraction level 2, the reference vectors are merged by SC using the similarity matrix. The data points in the dataset are assigned to the clusters to which the reference vectors nearest to the data points belong.
ASC with GNG can partition a nonlinearly separable dataset. After abstraction level 2, the data points are assigned to the nearest reference vectors based on Euclidean distance. Thus, ASC with GNG divides the space into regions consisting of Voronoi polygons around reference vectors. In ASC with GNG, SC merges the reference vectors to k clusters. Simultaneously, the Voronoi polygons corresponding to the reference vectors are also merged to k regions. ASC with GNG provides the complex decision regions consisting of Voronoi polygons and achieves nonlinear separation.
At first, ASC with GNG appears to be the same as other ASCs because many ASCs using a quantization method such as k-means, SOM and its alternatives already exist. For example, Duan, Guan & Liu (2012) have proposed ASC using SOM. In their method, data points are quantized by SOM, and SC partitions the reference vectors. The similarity measure of their method is defined by the Euclidean distance divided by local variance reflecting the distribution of data points around a reference vector. The interesting point of their method is using a local variance. Moazzen & Taşdemir (2016) have proposed ASC using NG. Similarly, in their method, the similarity matrix used by SC is calculated from reference vectors. It is interesting that their method uses integrated similarity criteria to improve accuracy. In ASC with GNG as well as the other ASCs, reference vectors are partitioned by SC. However, ASC with GNG uses both reference vectors and topology of the network generated by GNG, but the other ASCs use only reference vectors. Using the topology will play an important role in improving clustering performance because SC can be regarded as a type of partition problem for a network (Diao, Zhang & Wang, 2015) and partitions the units of the network into disjoint subsets.
Algorithm
ASC with GNG consists of generating a network by GNG, partitioning reference vectors by SC, and assigning data points into clusters. The algorithm for ASC with GNG is given in Algorithm 1.
| Input: Data points X ∈ Rd, the number of clusters k |
| Output: A partition of given data points into k clusters C1,…,Ck |
| 1: {Abstraction Level1} |
| 2: Generate the network from the dataset X using GNG. |
| 3: Calculate the similarity matrix A ∈ RM × M from the reference vectors and the topology of the network. |
| 4: {Abstraction Level 2} |
| 5: Calculate the normalized Laplacian matrix Lsym by Eq. (2). |
| 6: Calculate the k first eigenvectors u1,…,uk of Lsym. |
| 7: Let U ∈ RM× k be the matrix containing the vectors u1,…,uk as columns. |
| 8: For i = 1,…, M, let yi ∈ Rk be the vector corresponding to the i-th row of U. |
| 9: Assign (yi)i = 1,…,M to clusters C1,…,Ck by k-means. |
| 10: {Assign data points to the clusters.} |
| 11: Find the nearest unit to each data point. |
| 12: Each data point is assigned to the cluster to which the nearest unit is assigned. |
Let us consider a set of N data points, X = { x1, x2,…,xn,…,xN}, where xn ∈ Rd (Fig. 1A). The data point n is denoted by xn. In this study, each data point is previously normalized by , where xmax is the data point that has the maximum norm. For an actual application, such normalization will not be required because we can use specific parameters for the application.
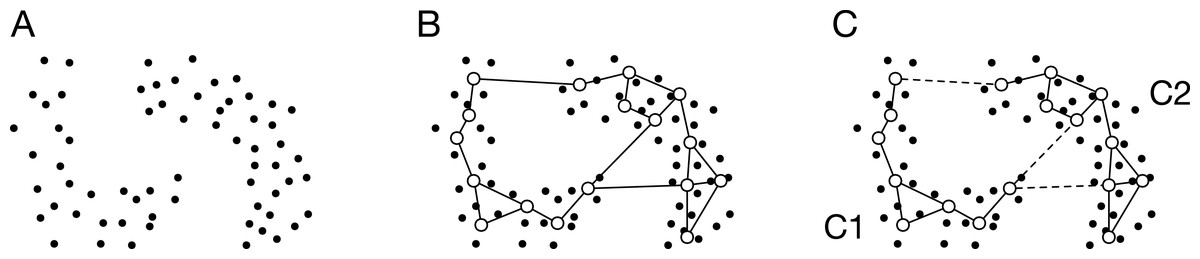
Figure 1: Schematic image of ASC with GNG.
(A) Data distribution. The dots denote the data points. (B) Generated network. The open circles and the solid lines denote the units and the edges, respectively. (C) Partition of the units using SC. The broken line denotes the connection cut by SC. SC merges the units into two clusters: C1 and C2. In other words, SC removes the edges connecting the units that belong to different clusters.{kind=link}
GNG generates a network from data points (Fig. 1B). The generated network is not a complete graph, and its topology reflects input space. The unit i in the network has the reference vector wi ∈ Rd. The algorithm of GNG is denoted in Appendix.
The similarity matrix A ∈ RM × M is calculated from the reference vectors and the topology of the generated network. M is the number of units in the network. If the unit i connects to the unit j, the element aij of A is defined as follows:
(1)
where wi and wj are the reference vectors of i and j, respectively. Otherwise, aij = 0. Equation (1) is the Gaussian similarity function that is most widely used to obtain a similarity matrix. The proposed method’s new point is to make a similarity matrix from both the reference vectors and the network topology. The similarity matrix is sparse because of using the network topology. However, the similarity matrix has information about significant connections representing input space.
The reference vectors are merged to k clusters by SC as shown in Fig. 1C. The normalized Laplacian matrix Lsym ∈ RM × M is calculated from A. Here, we define the diagonal matrix D ∈ RM × M to calculate the Laplacian matrix. The element of the diagonal matrix is . The Laplacian matrix is L = D − A. We derive the normalized Laplacian matrix from the following equation:
(2)
Here, we calculate the k first eigenvectors u1,…,uk of Lsym. Let U ∈ RM× k be the matrix containing the vector u1,…,uk as columns. For i = 1,…,M, let yi ∈ Rk be the vector corresponding to the i-th row of U. k-means assigns (yi)i = 1,…,M to clusters C1,…,Ck. Each row vector corresponds with each reference vector one-to-one.
Each data point is assigned to the cluster to which the nearest reference vector belongs. Finally, the data points are assigned to the clusters.
ASC with SOM and its alternatives
In this study, ASC with GNG is compared with ASCs with NG, SOM, k-means, and GNG using no topology to investigate the difference in clustering performances depending on the methods used to generate the network. ASCs with NG and SOM use NG and Kohonen’s SOM to generate networks instead of GNG, respectively. The weights of the network generated by NG and SOM are calculated using the Gaussian similarity function. ASC with k-means uses centroids generated by k-means as units in the network. The network is fully connected, and its weights are calculated using the Gaussian similarity function. ASC with GNG using no topology uses only the reference vectors generated by GNG. In ASC with GNG using no topology, the network is fully connected, and its weights are calculated using the Gaussian similarity function. In this study, ASC with GNG is also compared with SC. SC uses a fully-connected network, the Gaussian similarity function, a normalized Laplacian matrix Lsym = D − 1/2LD − 1/2, and k-means.
Complexity
The time complexity of SC is O(N3) (Izquierdo-Verdiguier et al., 2015; Taşdemir, Yalçin & Yildirim, 2015; Wang et al., 2013), where N is the number of data points. The complexity relies on the eigendecomposition of a Laplacian matrix. The eigendecomposition takes O(N3) time.
The time complexity of ASCs with GNG is O(MT + M3 + NM), where M and T are respectively the number of units and the number of iterations. O(MT) is the time complexity of GNG because O(M) is required to find the best match unit of a presented data point at every iteration. To decide the best match unit, we need to compute the distance between every reference vector and a presented data point and find the minimum distance. Thus, we calculate and compare M distances at every iteration. O(M3) is the time complexity of SC to partition the units. O(MN) is the time complexity to assign data points to clusters. To assign data points to clusters, we determine the nearest reference vector of every data point. Thus, we calculate M distances for each data point. For , O(MN) dominates the computational time of ASCs with GNG.
If we use a sort algorithm, such as quicksort, to simultaneously find the best match unit and the second-best match unit every iteration, the time complexity of ASC with GNG is O(T M log M + M3 + NM). In this case, GNG sorts the distances between all the reference vectors and a presented data point to finds the best match and the second-best match units at every iteration. The sort algorithm takes O(M log M).
The time complexity of ASC with NG is O(TM log M + M3 + NM). The complexity of NG is O(TM log M). In NG, the distances between all the reference vectors and a presented data point are calculated at every iteration. The calculation of the distances takes O(M). NG sorts the distances to obtain the neighborhood ranking of the reference vectors at every iteration. The sort of M distances takes O(M log M) when we use quicksort. NG updates the weights of all the reference vectors at every iteration. NG takes O(M) to update the weighs. Thus, the time complexity of NG is O(T(M + M log M + M)) = O(TM log M). For , O(MN) dominates the computational time of ASC with NG.
The time complexity of ASC with SOM is O(MT + M3 + NM). O(MT) is the time complexities of SOM because it requires finding the best match unit of a presented data point and updating all the reference vectors at every iteration. For , O(MN) dominates the computational time of ASCs with SOM.
The time complexities of ASC with k-means is O(MNTkmeans + M3 + NM), where Tkmeans is the number of iterations in k-means. O(MNTkmeans) is the time complexities of k-means because the distances between M centroids and N data points are calculated at every iteration. It is difficult to estimate Tkmeans, but the convergence of k-means is fast (Bottou & Bengio, 1994) and Tkmeans will be enough smaller than N. For , O(MNTkmeans + NM) dominates the computational time of ASCs with k-means. In this case, the computational time approximately linearly increases with N because Tkmeans will be enough smaller than N.
The space complexity of SC is O(N2) (Mall, Langone & Suykens, 2013) because the memory space is required to store the N × N similarity matrix. The space complexity of ASCs with GNG, NG, SOM, and k-means is O(N + M2). O(N) is the memory space to store the data points. O(M2) is the memory space to store the similarity matrix of reference vectors. For , the space complexity of the ASCs is O(N). Thus, the space complexities of the ASCs are much smaller than that of SC.
The time complexities and the space complexities of ASCs and SC are summarized in Table 1.
| Method | Time complexity | Space complexity |
|---|---|---|
| ASC with GNG | O(MT + M3 + NM) | O(N + M2) |
| ASC with NG | O(TM log M + M3 + NM) | O(N + M2) |
| ASC | O(MT + M3 + NM) | O(N + M2) |
| ASC with k-means | O(MNTkmeans + M3 + NM) | O(N + M2) |
| SC | O(N3) | O(N2) |
Parameters
All the parameters of the methods, except for T, Mmax, M, and l, are found using grid search to maximize the mean of the purity scores for the datasets used in “Clustering Quality”. The parameters of ASC with GNG are T = 105, λ = 250, ɛ1 = 0.1, ɛn = 0.01, amax = 75, α = 0.25, β = 0.99, σ = 0.25. The parameters of ASC with NG are T = 105, λi = 1.0, λf = 0.01, ɛi = 0.5, ɛf = 0.005, amaxi = 100, amaxf = 300, and σ = 0.25. The Parameters of ASC with SOM are T = 105, γ0 = 0.05, σ0 = 1.0, and σ = 0.5. The Parameter of ASC with k-means is σ = 0.1. The parameters of ASC with GNG no edge are T = 105, λ = 350, ɛ1 = 0.05, ɛn = 0.01, amax = 100, α = 0.5, β = 0.999, σ = 0.5. The Parameter of ASC with k-means and SC is σ = 0.1. The meanings of the parameters are shown in “Algorithm” and Appendix.
Results
This section describes computational time and clustering performances of ASCs with GNG.
The programs used in the experiments were implemented using Python and its libraries. The libraries are numpy for linear algebra computation, networkx for dealing a network, and scikit-learn for loading datasets and using k-means.
Computational time
This subsection describes the computational time of ASCs with GNG, NG, SOM, and k-means and SC. For the measurement of the computational time, the dataset has five clusters and consists of 3-dimensional data points. This dataset is generated by datasets.make_blobs, which is the function of scikit-learn. The dataset is called Blobs in this study. In this experiment, I use the computer with two Xeon E5-2687W v4 CPUs and 64 GB of RAM and cluster the dataset using only one thread to not process in parallel.
Figure 2A shows the relationship between the computational time and the number of data points for 102 units. The computational time of ASC with k-means is shortest under about 5 × 105 data points. The computational time of ASC with k-means linearly increases from about 104 data points. ASCs with GNG, NG, and SOM show better computational performance than ASC with k-means beyond about 106 data points. The computational time of ASCs with GNG, NG, and SOM does not significantly change under about 105 data points. However, the computational time of ASCs with GNG, NG, and SOM linearly increases with the number of data points from about 106 data points. Under 105 data points, the computational time of ASCs with GNG, NG, and SOM will mainly depend on the computational cost to generate a network because O(MT) and O(TM log M) are more than O(M3) and O(MN). On the other hand, the linear increase of the computational time of ASCs with GNG, NG, and SOM will be dominantly derived from the computational cost to assign data points to units. The computational time of ASC with SOM is shorter than that of ASCs with GNG and NG under about 106 data points because SOM does not have the process to change the network topology. From about 107 data points, the computational time of ASC with SOM is not different from ASCs with GNG and NG because the computational cost to assign data points to units is dominant. Under 106 data points, the computational time of ASC with GNG is shorter than ASC with NG. This difference occurs because the mean of growing M of ASC with GNG during learning is less than M of ASC with NG. The computational time of SC is not shown for more than 104 data points because the computational time of spectral clustering is too long compared to the other methods. These results show that the ASCs outperform SC in terms of computational time for a large dataset. However, the results also show that ASC using topology is not effective for a small dataset.

Figure 2: Computational time of ASCs for clustering the synthetic dataset.
(A) Relationship between computational time and the number of data points. The number of units of all ASCs is 102. (B) Relationship between computational time and the number of units. The number of the data points in the dataset is 106. GNG, NG, SOM, k-means, and SC in these figures represent the computational time of ASCs with GNG, NG, SOM, and k-means and SC, respectively. The computational time is the mean of 10 runs with random initial values.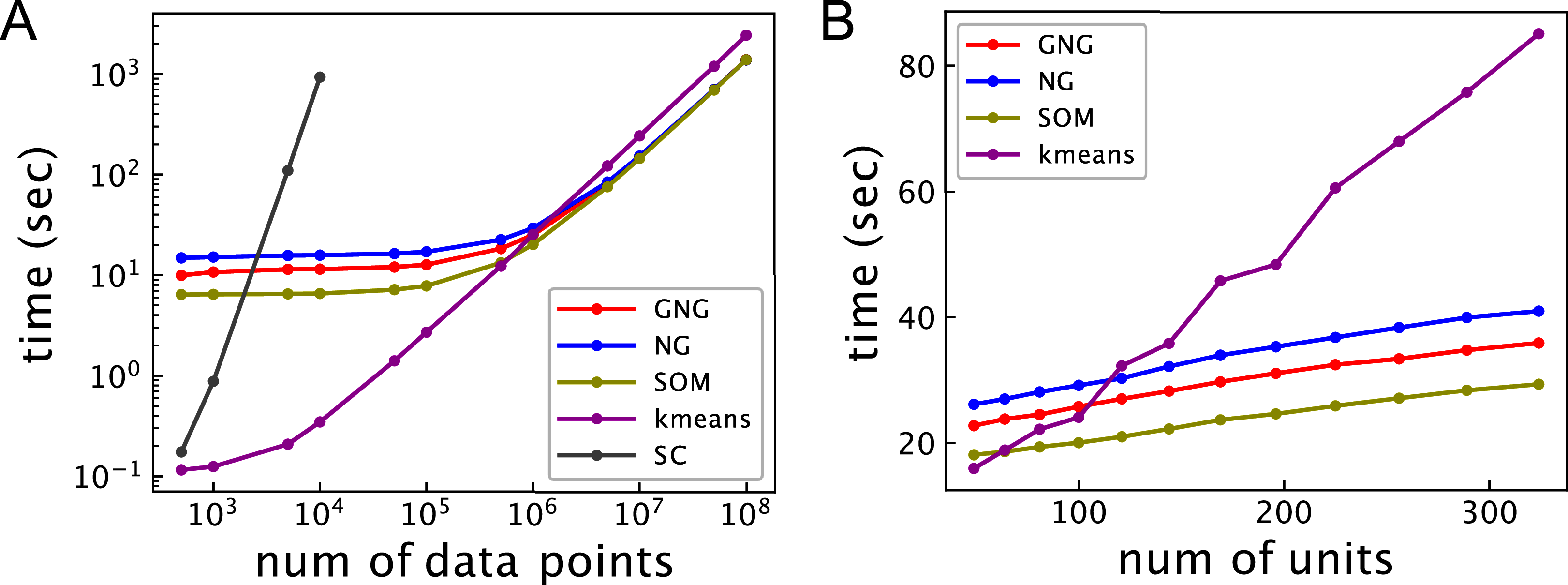{kind=link}
Figure 2B shows the relationship between the computational time and the number of units for 106 data points. In ASC with GNG, the number of units means the maximum of the number Mmax. The computational time of all ASCs linearly increases with the number of units. The computational time of the ASCs with GNG, NG, and SOM increases more slowly than k-means because the complexity of k-means depends on not only the number of units but also the number of data points.
Clustering quality
To investigate the clustering performances of the ASC with GNG, NG, and SOM, three synthetic datasets and six real-world datasets are used. The synthetic datasets are Blobs, Circles, and Moons generated by datasets.make_blobs, datasets.make_circles, and datasets.make_moons that are functions of scikit-learn, respectively. Blobs are generated from three isotropic Gaussian distributions. The standard deviation and the means of each Gaussian are default values of the generating function. Blobs can be partition by a linear separation method such as k-means. Circles consists of two concentric circles. The noise and the scale parameters of the function generating Circles are set at 0.05 and 0.5, respectively. Moons includes two-moons shape distributed data points. The noise parameter of the function generating Moons is 0.05. Circles and Moons are typical synthetic datasets that can not be partitioned by a linear separation method. The real-world data are Iris, Wine, Spam, CNAE-9, Digits, and MNIST (Lecun et al., 1998). Iris, Wine, Spam, CNAE-9, and Digits are datasets found in the UCI Machine Learning Repository. In this study, Iris, Wine, Digits, and MNIST are obtained using scikit-learn. Iris and Wine are datasets frequently used to evaluate the performance of a clustering method. Spam and CNAE-9 are word datasets. In this study, three attributions of Spam: capital_run_length_average, capital_run_length_longest, and capital_run_length_total, are not used. Digits and MNIST are handwritten digits datasets. Table 2 shows the numbers of classes, data points, and attributions of the datasets.
| Dataset | k | n | d |
|---|---|---|---|
| Blobs | 3 | 1,000 | 2 |
| Circles | 2 | 1,000 | 2 |
| Moons | 2 | 1,000 | 2 |
| Iris | 3 | 150 | 4 |
| Wine | 3 | 178 | 13 |
| Spam | 2 | 4,601 | 54 |
| CNAE-9 | 9 | 1,080 | 856 |
| Digits | 10 | 1,797 | 8 × 8 |
| MNIST | 10 | 70,000 | 28 × 28 |
Note:
k, n, and d indicate the number of classes, data points and attributions, respectively.
To evaluate the clustering methods, we use the purity score. Purity is given by , where N is the number of data points in a dataset, k is the number of clusters, and nji is the number of data points that belong to the class j in the cluster i. When the purity score is 1, all data points belong to true clusters.
Table 3 shows the purities of ASCs with GNG, NG, SOM, k-means, and GNG using no topology and SC. ASC with GNG shows the best accurate clustering results for five datasets: Circles, Moons, Spam, CNAE-9, and Digits. For Blobs, ASC with GNG displays the second-best performance, but the difference of purity between ASC with GNG, NG, and GNG using no topology and SC is small. For MNIST, ASC with GNG shows the second-best performance. ASC with NG also shows relatively high purities for Blobs, Circles, Moons, and Digits. However, for Iris and Wine dataset, the clustering performances of ASCs with GNG and NG are worse than the others. The lower performance of ASCs with GNG and NG may be caused by too many units for the number of data points. Perhaps, there will be the optimal number of units to make a better similarity matrix. The performance of ASC with SOM is worse than the other methods for the datasets apart from Spam. The bad performance of ASC with SOM may be caused by the feature of SOM that is the tendency to have null units often. This feature of SOM is unsuitable for ASC using topology. ASC with k-means shows relatively high performance for Blobs, Circles, Moons, Iris, Wine, and MNIST. For MNIST, the performance of ASC with k-means is best. ASC with GNG using no topology shows the best performance for Blobs, Circles, and Wine. For Moons and Spam, ASC with GNG using no topology displays the second-best performance. For Blobs, Circles, Moons, Wine, Spam, CNAE-9, and Digits, the performance of ASC with GNG using no topology is better than that of ASC with k-means. This result suggests that GNG can quantize dataset better than k-means in many cases. For MNIST, SC cannot perform clustering because overflow occurs. These results suggest that the network topology effectively improves the performance of the clustering, and GNG will generate the same or better quantization result than k-means.
| Dataset | GNG | NG | SOM | k-means | GNG using no topology | SC |
|---|---|---|---|---|---|---|
| Blobs | 0.9744 | 0.9632 | 0.4110 | 0.9690 | 0.9813 | 0.9671 |
| Circles | 1.0000 | 1.0000 | 0.5403 | 0.9997 | 1.0000 | 1.0000 |
| Moons | 0.9992 | 0.9884 | 0.5810 | 0.9328 | 0.9985 | 0.9933 |
| Iris | 0.5840 | 0.5648 | 0.5020 | 0.8473 | 0.8427 | 0.8533 |
| Wine | 0.4650 | 0.4649 | 0.4379 | 0.6656 | 0.6827 | 0.6742 |
| Spam | 0.7676 | 0.6063 | 0.6082 | 0.6095 | 0.7464 | 0.6070 |
| CNAE-9 | 0.6711 | 0.5920 | 0.2913 | 0.4887 | 0.5706 | 0.1871 |
| Digits | 0.8572 | 0.8129 | 0.3356 | 0.7641 | 0.8025 | 0.6023 |
| MNIST | 0.6100 | 0.5801 | 0.2784 | 0.6754 | 0.5888 | nan |
Note:
GNG, NG, SOM, k-means, GNG using no topology, and SC mean ACSs with GNG, NG, SOM, k-means, and GNG using no topology, and spectral clustering, respectively. The purities are the mean of 100 runs with random initial values. The best purities are bold.
Figure 3 shows the relationship between purity and the number of units for Circles, Iris, and MNIST to investigate the dependence of clustering performance on the number of units. For Circles, the clustering performances of ASCs with GNG and NG vary in convex upward. This result suggests that the performances become worse for the larger or smaller number of units than the optimal number of units and become better for the around optimal number of units. For Iris, the performances of ASCs with GNG and NG are high under about 50 and 36 units, respectively. From about 50 and 36 units, these performances go down with the number of units. This result suggests that the number of units used in Table 3 is too large to obtain the optimal performances for Iris and Wine. For MNIST, the performances of ASCs with GNG and NG improve with the number of units. For all cases, the performances of ASCs with k-means and GNG using no topology more weakly depend on the number of units. This result suggests that ASC not using network topology displays peak performance less than ASCs using network topology in many cases but its performance does not strongly depend on the number of units.
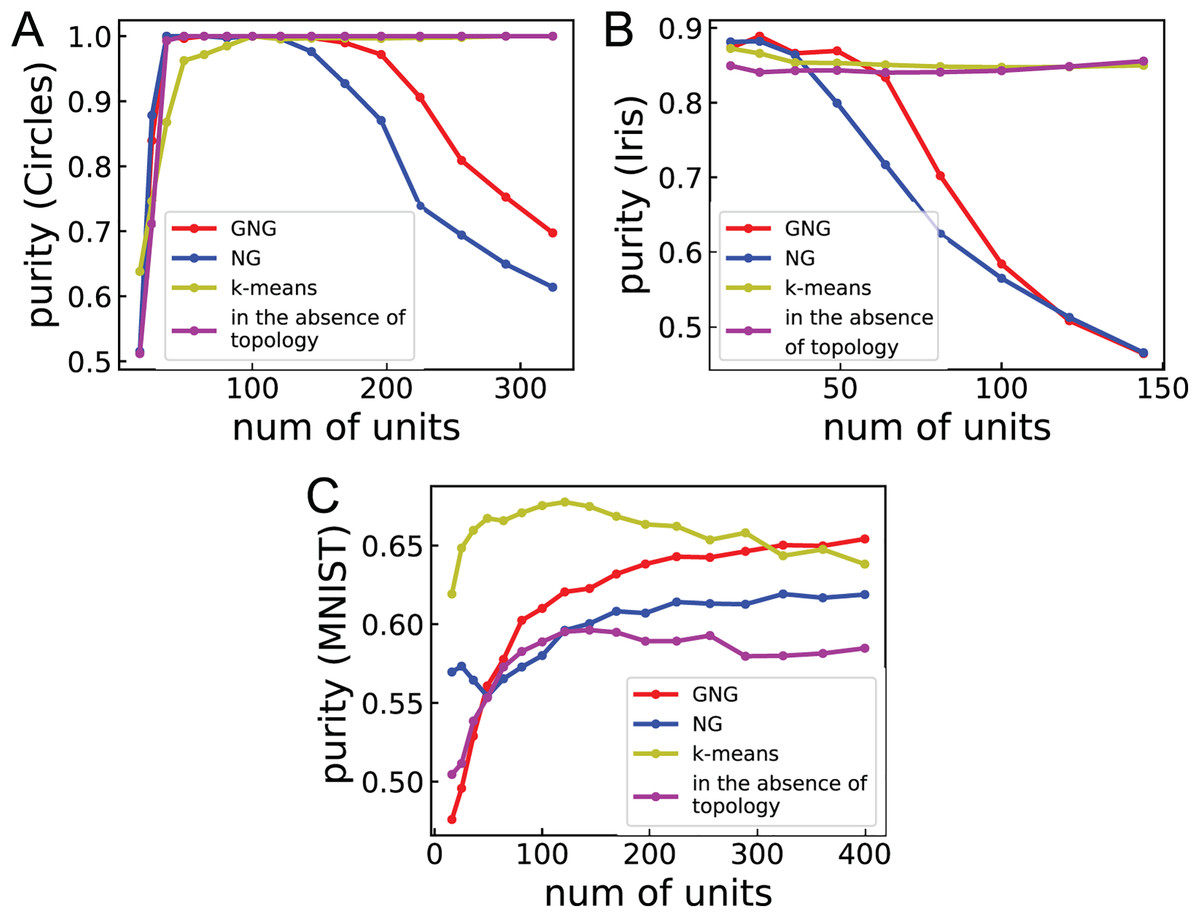
Figure 3: The relationship between purity and the number of units.
(A)–(C) Show the performance of clustering Circles, Iris, and MNIST, respectively. Purities are the mean of 100 runs with random initial values. The line labeled “in the absence of topology” denotes the clustering performance of ASC with GNG using no topology.{kind=link}
Conclusion
This study proposes approximate spectral clustering using the network generated by growing neural gas, called ASC with GNG. ASC with GNG partitions a dataset using a Laplacian matrix calculated from not only the reference vectors but also the topology of the network generated by GNG. ASC with GNG displays better computational performance than SC for a large dataset. Furthermore, the clustering quality of ASC with GNG is equal or better than SC in many cases. The results of this study suggest that ASC with GNG improves not only computational but also clustering performances. Therefore, ASC with GNG can be a successful method for a large dataset.
Why does ASC with GNG display better clustering performance? The clustering results of SC depend on the quality of the constructed network from which a Laplacian matrix is calculated (Li et al., 2018). Namely, we need to improve the way to construct a similarity matrix to obtain better clustering performance for SC (Lu, Yan & Lin, 2016; Park & Zhao, 2018). The network generated by GNG represents the important topological relationships in a given dataset (Fritzke, 1994). Furthermore, in ASC with GNG, a similarity matrix calculated using the network topology is sparse because the elements of a similarity matrix between not connected units are zero. The sparse similarity matrix may contribute to the improvement of clustering performance. Therefore, the ability of GNG to extract the topology of a dataset will lead to improving clustering performance.
However, when the number of units is not optimal, ASC with GNG will produce more unsatisfactory results than ASC with GNG using no topology, and SC. This problem occurs when the number of units is close to or too smaller than the number of data points. This problem will not frequently occur in the actual application dealing with a large dataset.
ASC using no topology, such as ASCs with k-means and GNG using no topology, also displays high performance, but its peak performance is less than ASC with GNG in many cases. If we are concerned about the dependence of performance on the number of units, then ASC using no topology may also be a good option.
Why can ASC partition a nonlinearly separable dataset? The ability for nonlinear clustering is provided by SC used in abstraction level 2. Simply put, abstraction level 1 reduces the size of a dataset. The assignment after abstraction level 2 does not provide nonlinear separation, as only it creates only Voronoi regions around the reference vectors. SC makes the complex decision region merging the Voronoi regions and achieves nonlinear clustering. Thus, the ability for nonlinear clustering is not derived from the way of abstraction level 1. However, the clustering performance of ASC also depends on the way of abstraction level 1, as mentioned in the results section.
ASC with GNG can be more accelerated by parallel computing. García-Rodríguez et al. (2011) have achieved to accelerate GNG using graphics processing unit (GPU). Vojácek & Dvorský (2013) have parallelized GNG algorithm using high-performance computing. Thus, the process of making the network using GNG can be accelerated by GPU or high-performance computing. Furthermore, finding the nearest reference vectors of data points can easily be parallelized because each calculation of distance is independent. If the nearest reference vectors are found using parallel computing with p threads, the computational time of the finding is reduced to 1/p.
SC and ASC have a limitation as well as other clustering methods such as k-means. SC and ASCs can make nonlinear boundaries but can only group neighboring data points based on similarity or distance. In other words, they cannot group some not-neighboring subclusters that represent the same category. For instance, in MNIST, the subclusters representing the same digit are scattered, as shown in Fig. 10 of Khacef et al. (2019). To accurately cluster such a dataset, the scattered subclusters must be merged into one cluster. Khacef et al. (2019) and Khacef, Rodriguez & Miramond (2020) have accurately clustered MNIST using only six hundred labeled data points. Their proposed method projects input data onto a 2-dimensional feature map using SOM and then labels reference vectors using post-labeled unsupervised learning. Post-labeled unsupervised learning using SOM is efficient if we have some labeled data points in a dataset and require a more accurate clustering result.
Appendix
A self-organizing map and its alternatives
Self-organizing map (SOM) and its alternatives, such as NG and GNG, are artificial neural networks using unsupervised learning. They convert data points to fewer weights (representative vectors) of units in a neural network and preserve the input topology as the topology of the neural network. Kohonen’s SOM (Kohonen, 1990) is a basic and typical SOM algorithm. Kohonen’s SOM has the features that the network topology is fixed into a lattice (Sun, Liu & Harada, 2017) and the number of units is constant. NG has been proposed by Martinetz & Schulten (1991) and can flexibly change the topology of its network. However, in NG, we have to preset the number of units in the network. GNG (Fritzke, 1994) achieves to flexibly change both the network topology and the number of units in the network according to an input dataset. GNG can find the topology of an input distribution (Garca-RodrGuez et al., 2012). GNG has been widely applied to clustering or topology learning such as extraction of two-dimensional outline of an image (Angelopoulou, Psarrou & García-Rodríguez, 2011; Angelopoulou et al., 2018), reconstruction of 3D models (Holdstein & Fischer, 2008), landmark extraction (Fatemizadeh, Lucas & Soltanian-Zadeh, 2003), object tracking (Frezza-Buet, 2008), and anomaly detection (Sun, Liu & Harada, 2017).
Kohonen’s self-organizing map
Kohonen’s SOM is one of the neural network algorithms and a competitive learning and unsupervised learning algorithm. Kohonen’s SOM can project high-dimensional to a low-dimensional feature map. The function of the projection is used for cluster analysis, visualization, and dimension reduction of a dataset.
The topology of the network of Kohonen’s SOM is a two-dimensional l × l lattice in this study, where l × l = M. The unit i in the network has the reference vector wi ∈ Rd. The unit i is at pi ∈ R2 on lattice, where pi = ((mod(i − 1, l) + 1)/l, ⌈i/l⌉/l), i = {1, 2,…,M}. mod(a, b) is the remainder of the division of a by b. A general description of SOM algorithm is as follows:
1. Initialize the reference vectors of the units. All elements of the reference vectors are randomly initialized in the range of [0, 1].
2. Randomly select a data point xn and find the best match unit c, that is
(3)
3. Update the reference vectors of all units. The new reference vector of the unit i is defined by
(4)
where t is the number of iterations, hci(t) is the neighborhood function. hci(t) is described by the following equation:
(5)
where α(z, t) is a monotonically decreasing scalar function of t, and sqdist(i, c) is the square of the geometric distance between the unit i and the best match unit c on the lattice. α(z, t) is defined by
(6)
sqdist(i, c) is defined by
(7)
4. If t = T, terminate. Otherwise, go to Step 2.
Neural gas (NG)
NG also generates a network from input data points. NG flexibly changes the topology of the network according to input data points, but the number of the units is static. The network consists of M units and edges connecting pairs of units. The unit i has the reference vector wi. The edges are not weighted and not directed. An edge has a variable called age to decide whether the edge is deleted. Let us consider the set of N data points, X = { x1, x2,…,xn,…,xN}, where xn ∈ Rd. The algorithm of the neural gas is shown below:
1. Assign initial values to the weight wi ∈ Rd and set all Cij to zero. Cij describes the connection between the unit i and the unit j.
2. Select a data point xn from the dataset at random.
3. Determine the neighborhood-ranking of i, ki, according to distance between wi and xn by the sequence of ranking (i0, i1,…,ik,…,iM − 1) of units with
(8)
4. Perform as adaptation step for the weights according to
(9)
5. Determine the nearest neighbor unit i0 and the second nearest neighbor unit i1. If , set and . If , set . describes the age of the edge between the unit i0 and the unit i1.
6. Increase the age of all connections of i0 by setting for all j with .
7. Remove all connections of i0 that have their age exceeding the lifetime by setting for all j with and .
8. If the number of iterations is not T, go to step 2.
ɛ, λ, and amax decay with the number of iterations t. This time dependence has the same form for these parameters and is determined by g(t) = gi (gf/gi)t/T.
Growing neural gas
Growing neural gas (GNG) can generate a network from a given set of input data points. The network represents important topological relations in the data points using Hebb-like learning rule (Fritzke, 1994). A network generated by GNG consists of units and edges that are connections between units. In GNG, not only the number of the units but also the topology of the network can flexibly change according to input data points. The unit i has the reference vector wi ∈ Rd and summed error Ei. The edges are not weighted and not directed. An edge has a variable called age to decide whether the edge is deleted.
Let us consider the set of N data points, X = { x1, x2,…,xn,…,xN}, where xn ∈ Rd. The algorithm of the GNG to make a network from X is given by the following:
1. Start the network with only two units that are connected to each other. The reference vectors of the units set two data points randomly selected from X.
2. Select a data point xn from the dataset at random.
3. Find the winning unit s1 of xn by
(10)
Simultaneously, find the second nearest unit s2.
4. Add the squared distance between xn and to the summed error :
(11)
5. Move toward xn by fraction of the total distance:
(12)
Also move the reference vectors of the all direct neighbor units sn of s1 toward xn by the fraction of the total distance:
(13)
6. If s1 and s2 are connected by an edge, set the age of this edge to zero. If s1 and s2 are not connected, create the edge connecting between these units.
7. Add one to the ages of all the edges emanating from s1.
8. Remove the edges with their age larger than amax. If this results in nodes having no emanating edges, remove them as well.
9. Every certain number λ of the input data point generated, insert a new unit as follows:
Determine the unit q with the maximum summed error Eq.
Find the node f with the largest error among the neighbors of q.
Insert a new unit r halfway between q and f as follows:
(14)
The number of units has the limit Ms.
Insert edges between r and q, and r and f. Remove the edge between q and f.
Decrease the summed errors of q and f by multiplying them with a constant α. Initialize the summed error of r with the new summed error of q.
10. Decrease all summed errors by multiplying them with a constant β
11. If the number of iterations is not T, go to step 2.