
Detecting periodicities with Gaussian processes
- Published
- Accepted
- Received
- Academic Editor
- Kathryn Laskey
- Subject Areas
- Data Mining and Machine Learning, Optimization Theory and Computation
- Keywords
- RKHS, Harmonic analysis, Circadian rhythm, Gene expression, Matérn kernels
- Copyright
- © 2016 Durrande et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2016. Detecting periodicities with Gaussian processes. PeerJ Computer Science 2:e50 https://doi.org/10.7717/peerj-cs.50
Abstract
We consider the problem of detecting and quantifying the periodic component of a function given noise-corrupted observations of a limited number of input/output tuples. Our approach is based on Gaussian process regression, which provides a flexible non-parametric framework for modelling periodic data. We introduce a novel decomposition of the covariance function as the sum of periodic and aperiodic kernels. This decomposition allows for the creation of sub-models which capture the periodic nature of the signal and its complement. To quantify the periodicity of the signal, we derive a periodicity ratio which reflects the uncertainty in the fitted sub-models. Although the method can be applied to many kernels, we give a special emphasis to the Matérn family, from the expression of the reproducing kernel Hilbert space inner product to the implementation of the associated periodic kernels in a Gaussian process toolkit. The proposed method is illustrated by considering the detection of periodically expressed genes in the arabidopsis genome.
Introduction
The periodic behaviour of natural phenomena arises at many scales, from the small wavelength of electromagnetic radiations to the movements of planets. The mathematical study of natural cycles can be traced back to the nineteenth century with Thompson’s harmonic analysis for predicting tides (Thomson, 1878) and Schuster’s investigations on the periodicity of sunspots (Schuster, 1898). Amongst the methods that have been considered for detecting and extracting the periodic trend, one can cite harmonic analysis (Hartley, 1949), folding methods (Stellingwerf, 1978; Leahy et al., 1983) which are mostly used in astrophysics and periodic autoregressive models (Troutman, 1979; Vecchia, 1985). In this article, we focus on the application of harmonic analysis in reproducing kernel Hilbert spaces (RKHS) and on the consequences for Gaussian process modelling. Our approach provides a flexible framework for inferring both the periodic and aperiodic components of sparsely sampled and noise-corrupted data, providing a principled means for quantifying the degree of periodicity. We demonstrate our proposed method on the problem of identifying periodic genes in gene expression time course data, comparing performance with a popular alternative approach to this problem.
Harmonic analysis is based on the projection of a function onto a basis of periodic functions. For example, a natural method for extracting the 2π-periodic trend of a function f is to decompose it in a Fourier series: (1) where the coefficients ai are given, up to a normalising constant, by the L2 inner product between f and the elements of the basis. However, the phenomenon under study is often observed at a limited number of points, which means that the value of f(x) is not known for all x but only for a small set of inputs {x1, …, xn} called the observation points. With this limited knowledge of f, it is not possible to compute the integrals of the L2 inner product so the coefficients ai cannot be obtained directly. The observations may also be corrupted by noise, further complicating the problem.
A popular approach to overcome the fact that f is partially known is to build a mathematical model m to approximate it. A good model m has to take into account as much information as possible about f. In the case of noise-free observations it interpolates f for the set of observation points m(xi) = f(xi) and its differentiability corresponds to the assumptions one can have about the regularity of f. The main body of literature tackling the issue of interpolating spatial data is scattered over three fields: (geo-)statistics (Matheron, 1963; Stein, 1999), functional analysis (Aronszajn, 1950; Berlinet & Thomas-Agnan, 2004) and machine learning (Rasmussen & Williams, 2006). In the statistics and machine learning framework, the solution of the interpolation problem corresponds to the expectation of a Gaussian process, Z, which is conditioned on the observations. In functional analysis, the problem reduces to finding the interpolator with minimal norm in a RKHS . As many authors pointed out (for example Berlinet & Thomas-Agnan (2004) and Scheuerer, Schaback & Schlather (2011)), the two approaches are closely related. Both Z and are based on a common object which is a positive definite function of two variables k(., .). In statistics, k corresponds to the covariance of Z and for the functional counterpart, k is the reproducing kernel of . From the regularization point of view, the two approaches are equivalent since they lead to the same model m (Wahba, 1990). Although we will focus hereafter on the RKHS framework to design periodic kernels, we will also take advantage of the powerful probabilistic interpretation offered by Gaussian processes.
We propose in this article to build the Fourier series using the RKHS inner product instead of the L2 one. To do so, we extract the sub-RKHS of periodic functions in and model the periodic part of f by its orthogonal projection onto . One major asset of this approach is to give a rigorous definition of non-periodic (or aperiodic) functions as the elements of the sub-RKHS . The decomposition then allows discrimination of the periodic component of the signal from the aperiodic one. Although some expressions of kernels leading to RKHS of periodic functions can be found in the literature (Rasmussen & Williams, 2006), they do not allow to extract the periodic part of the signal. Indeed, usual periodic kernels do not come with the expression of an aperiodic kernel. It is thus not possible to obtain a proper decomposition of the space as the direct sum of periodic and aperiodic subspaces and the periodic sub-model cannot be rigorously obtained.
The last part of this introduction is dedicated to a motivating example. In ‘Kernels of Periodic and Aperiodic Subspaces,’ we focus on the construction of periodic and aperiodic kernels and on the associated model decomposition. ‘Application to Matérn Kernels’ details how to perform the required computations for kernels from the Matérn familly. ‘Quantifying the Periodicity t’ introduces a new criterion for measuring the periodicity of the signal. Finally, the last section illustrates the proposed approach on a biological case study where we detect, amongst the entire genome, the genes showing a cyclic expression.
The examples and the results presented in this article have been generated with the version 0.8 of the python Gaussian process toolbox GPy. This toolbox, in which we have implemented the periodic kernels discussed here, can be downloaded at http://github.com/SheffieldML/GPy. Furthermore, the code generating the Figs. 1–3 is provided in the Supplemental Information 3 as Jupyter notebooks.
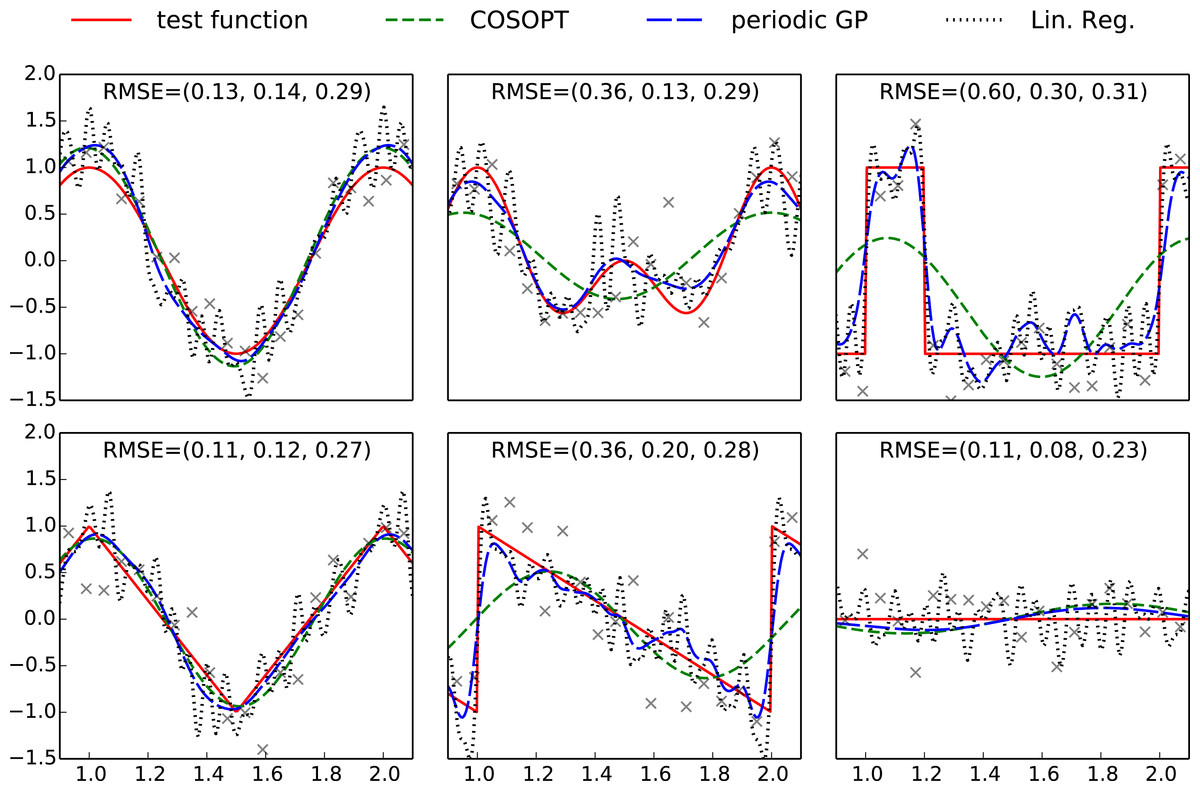
Figure 1: Plots of the benchmark test functions, observation points and fitted models.
For an improved visibility, the plotting region is limited to one period. The RMSE is computed using a grid of 500 evenly spaced points spanning [0, 3], and the values indicated on each subplot correspond respectively to COSOPT, the periodic Gaussian process model and linear regression. The Python code used to generate this figure is provided as Jupyter notebook in Supplemental Information 3.{kind=link}
Motivating example
To illustrate the challenges of determining a periodic function, we first consider a benchmark of six one dimensional periodic test functions (see Fig. 1 and Appendix A). These functions include a broad variety of shapes so that we can understand the effect of shape on methods with different modelling assumptions. A set X = (x1, …, x50) of equally spaced observation points is used as training set and a observation noise is added to each evaluation of the test function: Fi = f(xi) + εi (or F = f(X) + ε with vector notations). We consider three different modelling approaches to compare the facets of different approaches based on harmonic analysis:
-
COSOPT (Straume, 2004), which fits cosine basis functions to the data,
-
Linear regression in the weights of a truncated Fourier expansion,
-
Gaussian process regression with a periodic kernel.

Figure 2: Examples of decompositions of a kernel as a sum of a periodic and aperiodic sub-kernels.
(A) Matérn 3∕2 kernel k(., 5). (B) Periodic sub-kernel kp(., 5). (C) Aperiodic sub-kernel ka(., 5). For these plots, one of the kernels variables is fixed to 5. The three graphs on each plot correspond to a different value of the lengthscale parameter ℓ. The input space is D = [0, 4π] and the cut-off frequency is q = 20. The Python code used to generate this figure is provided as Jupyter notebook in Supplemental Information 3.{kind=link}
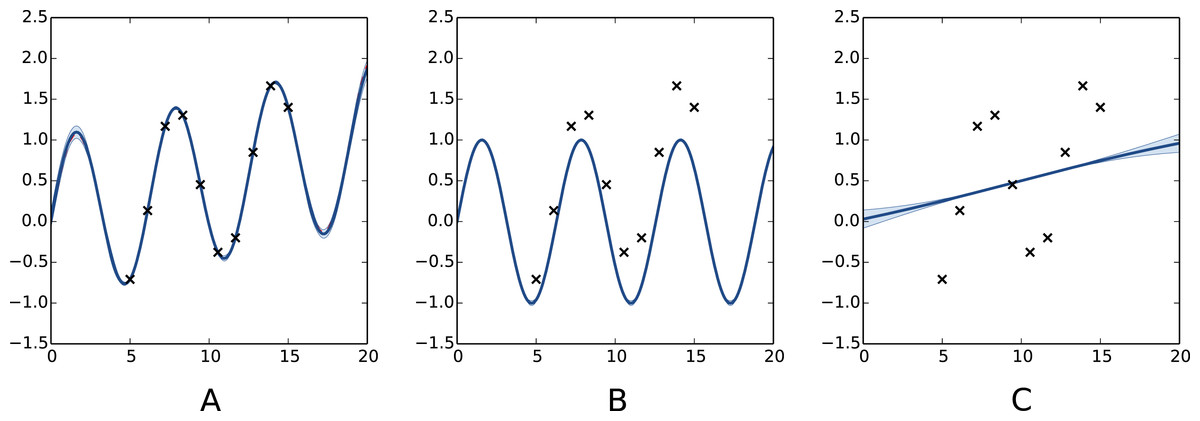
Figure 3: Decomposition of a Gaussian process fit.
(A) full model m; (B) periodic portion mp and (C) aperiodic portion ma. Our decomposition allows for recognition of both periodic and aperiodic parts. In this case maximum likelihood estimation was used to determine the parameters of the kernel, we recovered . The Python code used to generate this figure is provided as Jupyter notebook in Supplemental Information 3.{kind=link}
COSOPT. COSOPT is a method that is commonly used in biostatistics for detecting periodically expressed genes (Hughes et al., 2009; Amaral & Johnston, 2012). It assumes the following model for the signal: (2) where ε corresponds to white noise. The parameters α, β, ω and φ are fitted by minimizing the mean square error.
Linear regression. We fit a more general model with a basis of sines and cosines with periods 1, 1∕2…, 1∕20 to account for periodic signal that does not correspond to a pure sinusoidal signal. (3) Again, model parameters are fitted by minimizing the mean square error which corresponds to linear regression over the basis weights.
Gaussian Process with periodic covariance function. We fit a Gaussian process model with an underlying periodic kernel. We consider a model, (4) where yp is a Gaussian process and where α should be interpreted as a Gaussian random variable with zero mean and variance . The periodicity of the phenomenon is taken into account by choosing a process yp such that the samples are periodic functions. This can be achieved with a kernel such as (5) or with the kernels discussed later in the article. For this example we choose the periodic Matérn 3/2 kernel which is represented in Fig. 2B. For any kernel choice, the Gaussian process regression model can be summarized by the mean and variance of the conditional distribution: (6) where and I is the 50 × 50 identity matrix. In this expression, we introduced matrix notation for k: if A and B are vectors of length n and m, then k(A, B) is a n × m matrix with entries k(A, B)i,j = k(Ai, Bj). The parameters of the model can be obtained by maximum likelihood estimation.
The models fitted with COSOPT, linear regression and the periodic Gaussian process model are compared in Fig. 1. It can be seen that the latter clearly outperforms the other models since it can approximate non sinusoidal patterns (in opposition to COSOPT) while offering a good noise filtering (no high frequencies oscillations corresponding to noise overfitting such as for linear regression).
The Gaussian process model gives an effective non-parametric fit to the different functions. In terms of root mean square error (RMSE) in each case, it is either the best performing method, or it performs nearly as well as the best performing method. Both linear regression and COSOPT can fail catastrophically on one or more of these examples.
Although highly effective for purely periodic data, the use of a periodic Gaussian processes is less appropriate for identifying the periodic component of a pseudo-periodic function such as . An alternative suggestion is to consider a pseudo-periodic Gaussian process y = y1 + yp with a kernel given by the sum of a usual kernel k1 and a periodic one kp (see e.g., Rasmussen & Williams, (2006)). Such a construction allows decomposition of the model into a sum of sub-models where the latter is periodic (see ‘Decomposition in periodic and aperiodic sub-models’ for more details). However, the periodic part of the signal is scattered over the two sub-models so it is not fully represented by the periodic sub-model. It would therefore be desirable to introduce new covariance structures that allow an appropriate decomposition in periodic and non-periodic sub-models in order to tackle periodicity estimation for pseudo-periodic signals.
Kernels of Periodic and Aperiodic Subspaces
The challenge of creating a pair of kernels that stand respectively for the periodic and aperiodic components of the signal can be tackled using the RKHS framework. We detail in this section how decomposing a RKHS into a subspace of periodic functions and its orthogonal complement leads to periodic and aperiodic sub-kernels.
Fourier basis in RKHS
We assume in this section that the space spanned by a truncated Fourier basis (7) is a subspace of the RKHS . Under this hypothesis, it is straightforward to confirm that the reproducing kernel of is (8) where G is the Gram matrix of B in : . Hereafter, we will refer to kp as the periodic kernel. In practice, the computation of kp requires computation of the inner product between sine and cosine functions in . We will see in the next section that these computations can be done analytically for Matérn kernels. For other kernels, a more comprehensive list of RKHS inner products can be found in Berlinet & Thomas-Agnan (2004, Chap. 7).
The orthogonal complement of in can be interpreted as a subspace of aperiodic functions. By construction, its kernel is ka = k − kp (Berlinet & Thomas-Agnan, 2004). An illustration of the decomposition of Matérn 3/2 kernels is given in Fig. 2. The decomposition of the kernel comes with a decomposition of the associated Gaussian process in to two independent processes and the overall decompositions can be summarised as follow: (9)
Many stationary covariance functions depend on two parameters: a variance parameter σ2, which represents the vertical scale of the process and a lengthscale parameter, ℓ, which represents the horizontal scale of the process. The sub-kernels ka and kp inherit these parameters (through the Gram matrix G for the latter). However, the decomposition k = kp + ka allows us to set the values of those parameters separately for each sub-kernel in order to increase the flexibility of the model. The new set of parameters of k is then with an extra parameter λ if the period is not known.
Such reparametrisations of kp and ka induce changes in the norms of and . However, if the values of the parameters are not equal to zero or +∞, these spaces still consist of the same elements so . This implies that the RKHS generated by kp + ka corresponds to where the latter are still orthogonal but endowed with a different norm. Nevertheless, the approach is philosophically different since we build by adding two spaces orthogonally whereas in Eq. (9) we decompose an existing space into orthogonal subspaces.
Decomposition in periodic and aperiodic sub-models
The expression y = yp + ya of Eq. (9) allows to introduce two sub-models corresponding to conditional distributions: a periodic one yp(x)|y(X)=F and an aperiodic one ya(x)|y(X)=F. These two distributions are Gaussian and their mean and variance are given by the usual Gaussian process conditioning formulas (10) (11) The linearity of the expectation ensures that the sum of the sub-models means is equal to the full model mean: (12) so mp and ma can be interpreted as the decomposition of m into it’s periodic and aperiodic components. However, there is no similar decomposition of the variance: v(x) ≠ vp(x) + va(x) since yp and ya are not independent given the observations.
The sub-models can be interpreted as usual Gaussian process models with correlated noise. For example, mp is the best predictor based on kernel kp with an observational noise given by ka. For a detailed discussion on the decomposition of models based on a sum of kernels, see Durrande, Ginsbourger & Roustant (2012).
We now illustrate this model decomposition on the test function f(x) = sin(x) + x∕20 defined over [0, 20]. Figure 3 shows the obtained model after estimating of a decomposed Matérn 5∕2 kernel. In this example, the estimated values of the lengthscales are very different allowing the model to capture efficiently the periodic component of the signal and the low frequency trend.
Application to Matérn Kernels
The Matérn class of kernels provides a flexible class of stationary covariance functions for a Gaussian process model. The family includes the infinitely smooth exponentiated quadratic (i.e., Gaussian or squared exponential or radial basis function) kernel as well as the non-differentiable Ornstein–Uhlenbeck covariance. In this section, we show how the Matérn class of covariance functions can be decomposed into periodic and aperiodic subspaces in the RKHS.
Matérn kernels k are stationary kernels, which means that they only depend on the distance between the points at which they are evaluated: . They are often introduced by the spectral density of (Stein, 1999): (13) Three parameters can be found in this equation: ν which tunes the differentiability of , ℓ which corresponds to a lengthscale parameter and σ2 that is homogeneous to a variance.
The actual expressions of Matérn kernels are simple when the parameter ν is half-integer. For ν = 1∕2, 3∕2, 5∕2 we have (14) Here the parameters ℓ and σ2 respectively correspond to a rescaling of the abscissa and ordinate axis. For ν = 1∕2 one can recognise the expression of the exponential kernel (i.e., the covariance of the Ornstein–Uhlenbeck process) and the limit case ν → ∞ corresponds to the squared exponential covariance function (Rasmussen & Williams, 2006).
As stated in Porcu & Stein (2012 Theorem 9.1) and Wendland (2005), the RKHS generated by kν coincides with the Sobolev space . Since the elements of the Fourier basis are , they belong to the Sobolev space and thus to Matérn RKHS. The hypothesis made in ‘Kernels of Periodic and Aperiodic Subspaces’ is thus fulfilled and all previous results apply.
Furthermore, the connection between Matérn kernels and autoregressive processes allows us to derive the expression of the RKHS inner product. As detailed in Appendix B, we obtain for an input space D = [a, b]:
Matérn 1∕2 (exponential kernel) (15) Matérn 3∕2 (16) Matérn 5∕2 (17) where Although these expressions are direct consequences of Doob (1953) and Hájek (1962), they cannot be found in the literature to the best of our knowledge.
The knowledge of these inner products allow us to compute the Gram matrix G and thus the sub-kernels kp and ka. A result of great practical interest is that inner products between the basis functions have a closed form expression. Indeed, all the elements of the basis can be written in the form cos(ωx + φ) and, using the notation Lx for the linear operators in the inner product integrals (see Eq. (17)), we obtain: (18) The latter can be factorised in a single cosine ρcos(ωx + ϕ) with (19) where
Eventually, the computation of the inner product between functions of the basis boils down to the integration of a product of two cosines, which can be solved by linearisation.
Quantifying the Periodicity
The decomposition of the model into a sum of sub-models is useful for quantifying the periodicity of the pseudo-periodic signals. In this section, we propose a criterion based on the ratio of signal variance explained by the sub-models.
In sensitivity analysis, a common approach for measuring the effect of a set of variables x1, …, xn on the output of a multivariate function f(x1, …, xn) is to introduce a random vector R = (r1, …, rn) with values in the input space of f and to define the variance explained by a subset of variables xI = (xI1, …, xIm) as (Oakley & O’Hagan, 2004). Furthermore, the prediction variance of the Gaussian process model can be taken into account by computing the indices based on random paths of the conditional Gaussian process (Marrel et al., 2009).
We now apply these two principles to define a periodicity ratio based on the sub-models. Let R be a random variable defined over the input space and yp, ya be the periodic and aperiodic components of the conditional process y given the data-points. yp and ya are normally distributed with respective mean and variance (mp, vp), (ma, va) and their covariance is given by . To quantify the periodicity of the signal we introduce the following periodicity ratio: (20) Note that S cannot be interpreted as a the percentage of periodicity of the signal in a rigorous way since . As a consequence, this ratio can be greater than 1.
For the model shown in Fig. 3, the mean and standard deviation of S are respectively 0.86 and 0.01.
Application to Gene Expression Analysis
The 24 h cycle of days can be observed in the oscillations of biological mechanisms at many spatial scales. This phenomenon, called the circadian rhythm, can for example be seen at a microscopic level on gene expression changes within cells and tissues. The cellular mechanism ensuring this periodic behaviour is called the circadian clock. For arabidopsis, which is a widely used organism in plant biology and genetics, the study of the circadian clock at a gene level shows an auto-regulatory system involving several genes (Ding et al., 2007). As argued by Edwards et al. (2006), it is believed that the genes involved in the oscillatory mechanism have a cyclic expression so the detection of periodically expressed genes is of great interest for completing current models.
Within each cell, protein-coding genes are transcribed into messenger RNA molecules which are used for protein synthesis. To quantify the expression of a specific protein-coding gene it is possible to measure the concentration of messenger RNA molecules associated with this gene. Microarray analysis and RNA-sequencing are two examples of methods that take advantage of this principle.
The dataset (see http://millar.bio.ed.ac.uk/data.htm) considered here was originally studied by Edwards et al. (2006). It corresponds to gene expression for nine day old arabidopsis seedlings. After eight days under a 12 h-light/12 h-dark cycle, the seedlings are transferred into constant light. A microarray analysis is performed every four hours, from 26 to 74 h after the last dark-light transition, to monitor the expression of 22,810 genes. Edwards et al. (2006) use COSOPT (Straume, 2004) for detecting periodic genes and identify a subset of 3,504 periodically expressed genes, with an estimated period between 20 and 28 h.
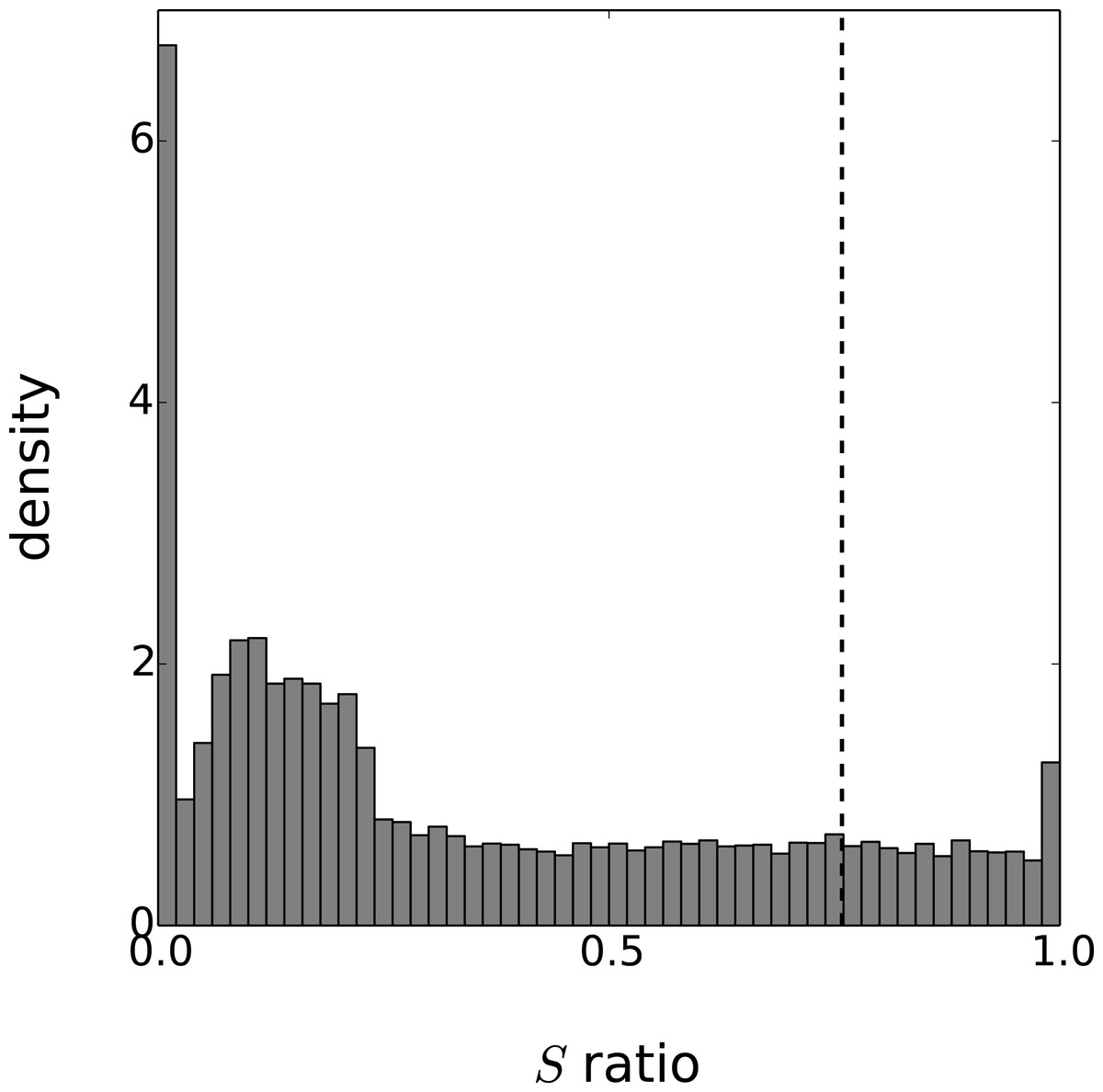
Figure 4: Distribution of the periodicity ratio over all genes according to the Gaussian process models.
The cut-off ratio determining if genes are labelled as periodic or not is represented by a vertical dashed line.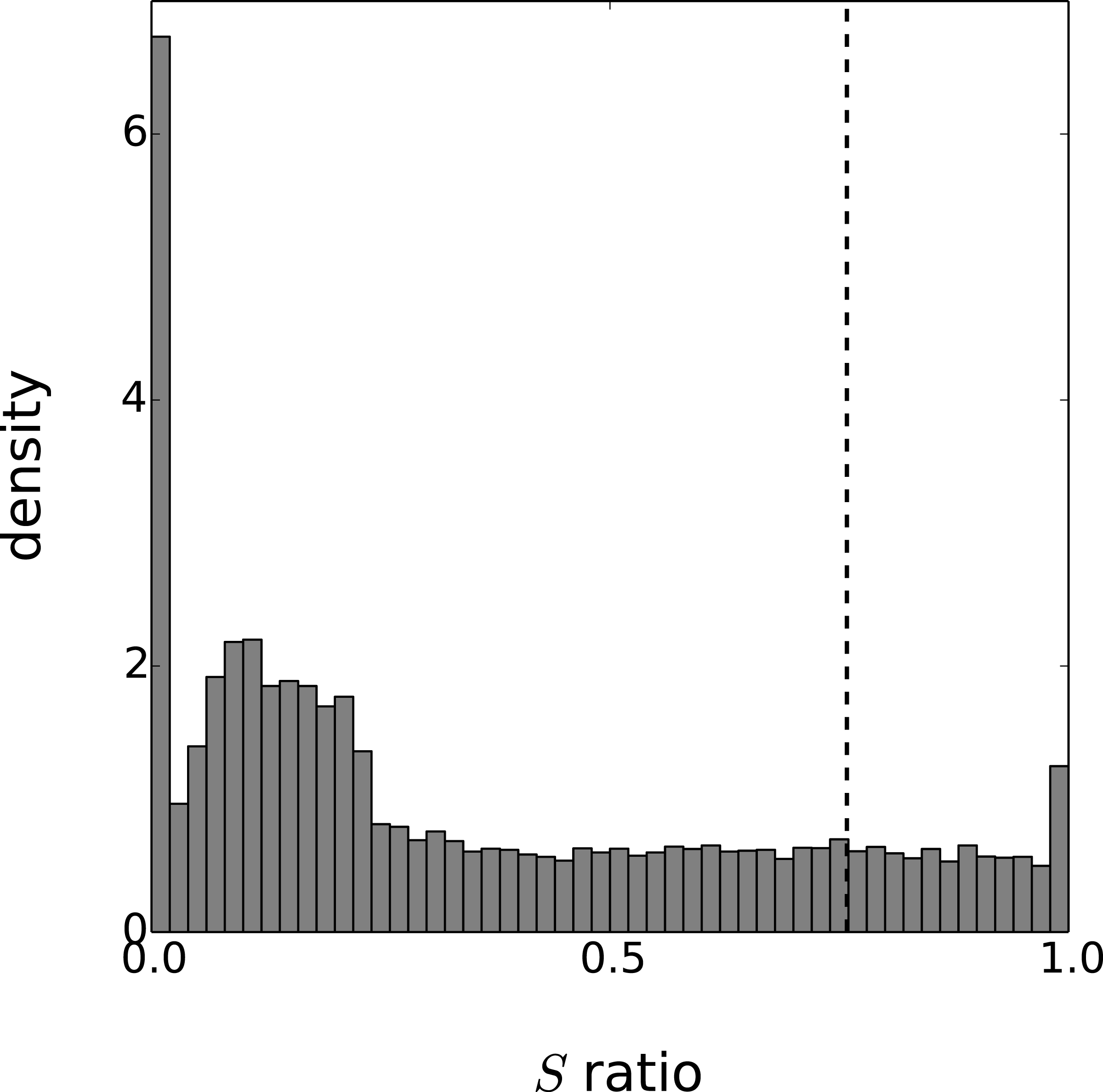{kind=link}
We now apply to this dataset the method described in the previous sections. The kernel we consider is a sum of a periodic and aperiodic Matérn 3/2 kernel plus a delta function to reflect observation noise: (21) Although the cycle of the circadian clock is known to be around 24 h, circadian rhythms often depart from this figure (indeed circa dia is Latin for around a day) so we estimated the parameter λ to determine the actual period. The final parametrisation of k is based on six variables: . For each gene, the values of these parameters are estimated using maximum likelihood. The optimization is based on the standard options of the GPy toolkit with the following boundary limits for the parameters: σp, σa ≥ 0; ℓp, ℓa ∈ [10, 60]; τ2 ∈ [10−5, 0.75] and λ ∈ [20, 28]. Furthermore, 50 random restarts are performed for each optimization to limit the effects of local minima.
Eventually, the periodicity of each model is assessed with the ratio S given by Eq. (20). As this ratio is a random variable, we approximate the expectation of S with the mean value of 1,000 realisations. To obtain results comparable with the original paper on this dataset, we labeled as periodic the set of 3,504 genes with the highest periodicity ratio. The cut-off periodicity ratio associated with this quantile is S = 0.76. As can be seen in Fig. 4, this cut-off value does not appear to be of particular significance according to the distribution of the Gaussian process models. On the other hand, the distribution spike that can be seen at S = 1 corresponds to a gap between models that are fully-periodic and others. We believe this gap is due to the maximum likelihood estimation since the estimate of is zero for all models in the bin S = 1. The other spike at S = 0 can be interpreted similarly and it corresponds to estimated equal to zero.
Let and be the sets of selected periodic genes respectively by Edwards et al. (2006) and the method presented here and let and denote their complements. The overlap between these sets is summarised in Table 1. Although the results cannot be compared to any ground truth, the methods seem coherent since 88% of the genes share the same label. Furthermore, the estimated value of the period λ is consistent for the genes labelled as periodic by the two methods, as seen in Fig. 5.
| # of genes | ||
|---|---|---|
| 2,127 | 1,377 | |
| 1,377 | 17,929 |
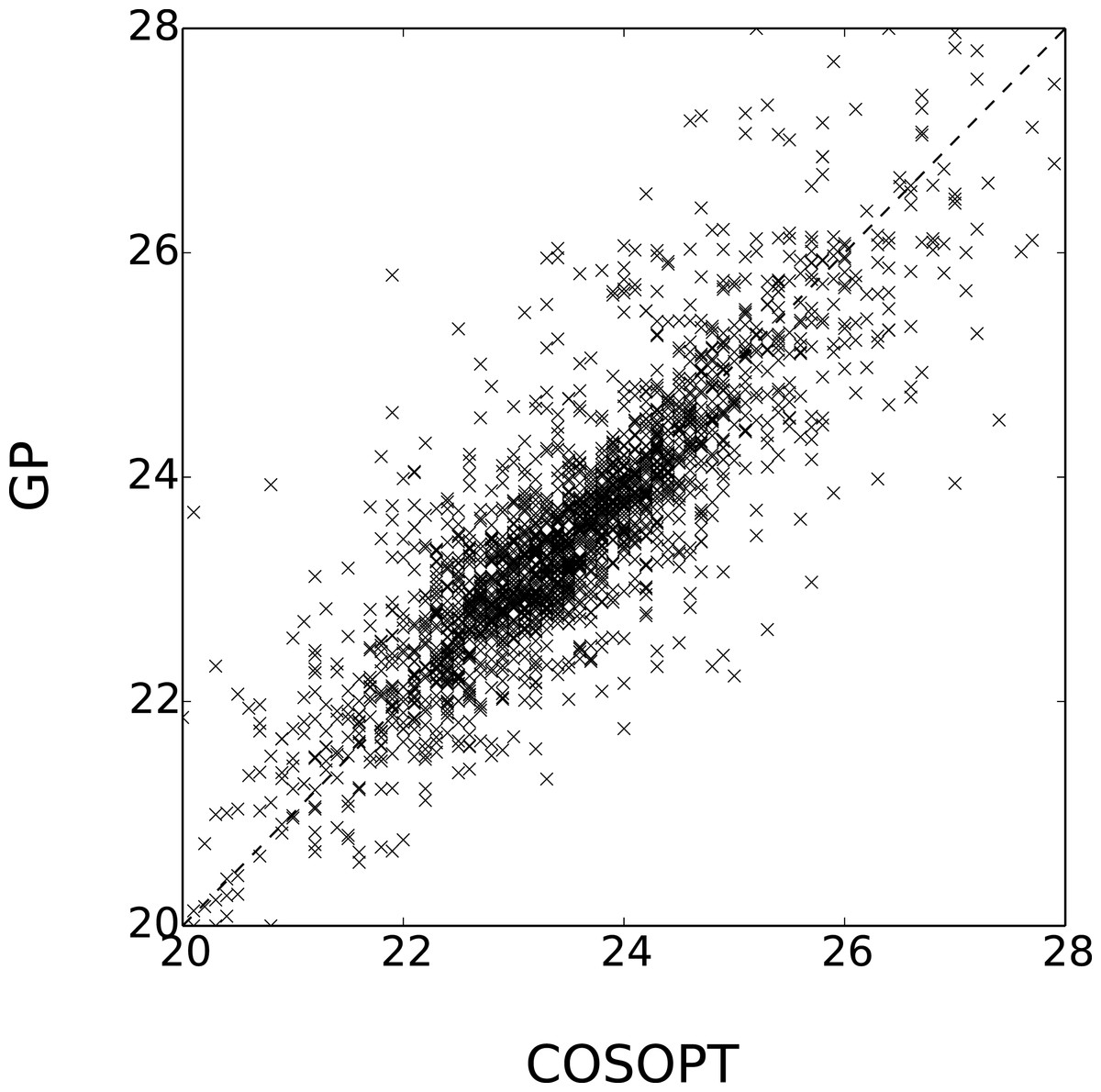
Figure 5: Comparison of Estimated periods for the genes in .
The coefficient of determination of x → x (dashed line) is 0.69.{kind=link}
One interesting comparison between the two methods is to examine the genes that are classified differently. The available data from Edwards et al. (2006) allows focusing on the worst classification mistakes made by one method according to the other. This is illustrated in Fig. 6 which shows the behaviour of the most periodically expressed genes in according to COSOPT and, conversely, the genes in with the highest periodicity ratio S. Although it is undeniable that the genes selected only by COSOPT (Fig. 6A) present some periodic component, they also show a strong non-periodic part, corresponding either to noise or trend. For these genes, the value of the periodicity ratio is: 0.74 (0.10), 0.74 (0.15), 0.63 (0.11), 0.67 (0.05) (means and standard deviations, clockwise from top left) which is close to the classification boundary. On the other hand, the genes selected only by the Gaussian process approach show a strong periodic signal (we have for all genes S = 1.01(0.01)) with sharp spikes. We note from Fig. 6B that there is always at least one observation associated with each spike, which ensures that the behaviour of the Gaussian process models cannot simply be interpreted as overfitting. The reason COSOPT is not able to identify these signals as periodic is that it is based on a single cosine function which makes it inadequate for fitting non sinusoidal periodic functions. This is typically the case for gene expressions with spikes as in Fig. 6B, but it can also be seen on the test functions of Fig. 1.
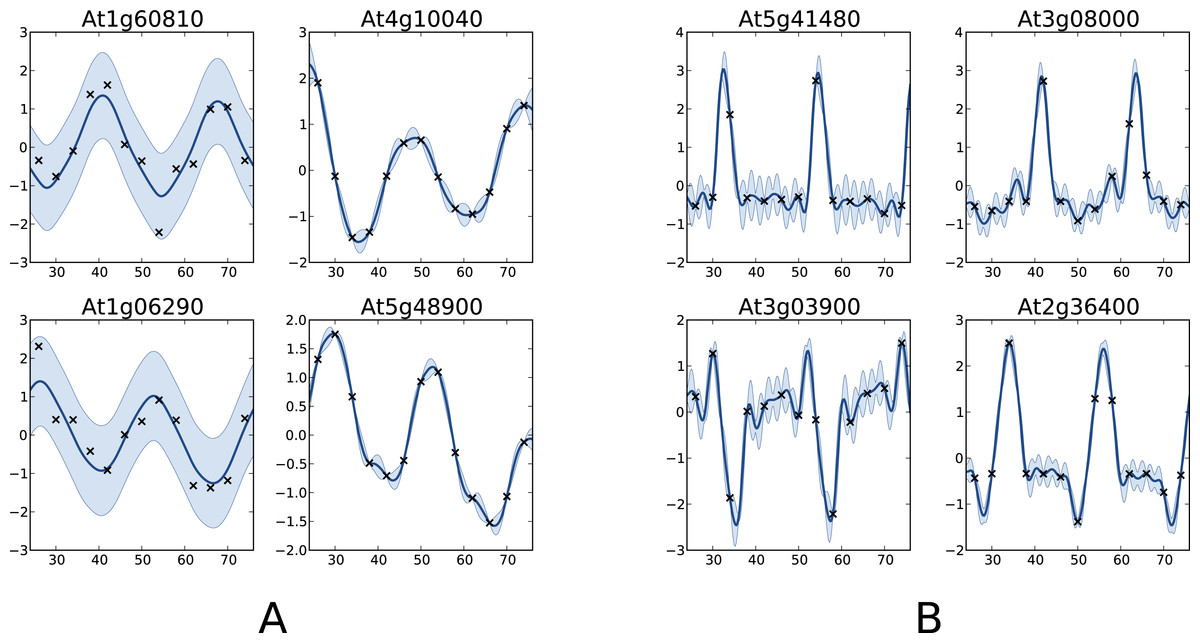
Figure 6: Examples of genes with different labels.
(A) corresponds to genes labelled as periodic by COSOPT but not by the Gaussian process approach, whereas in (B) they are labelled as periodic only by the latter. In (A, B), the four selected genes are those with the highest periodic part according to the method that labels them as periodic. The titles of the graphs correspond to the name of the genes (AGI convention).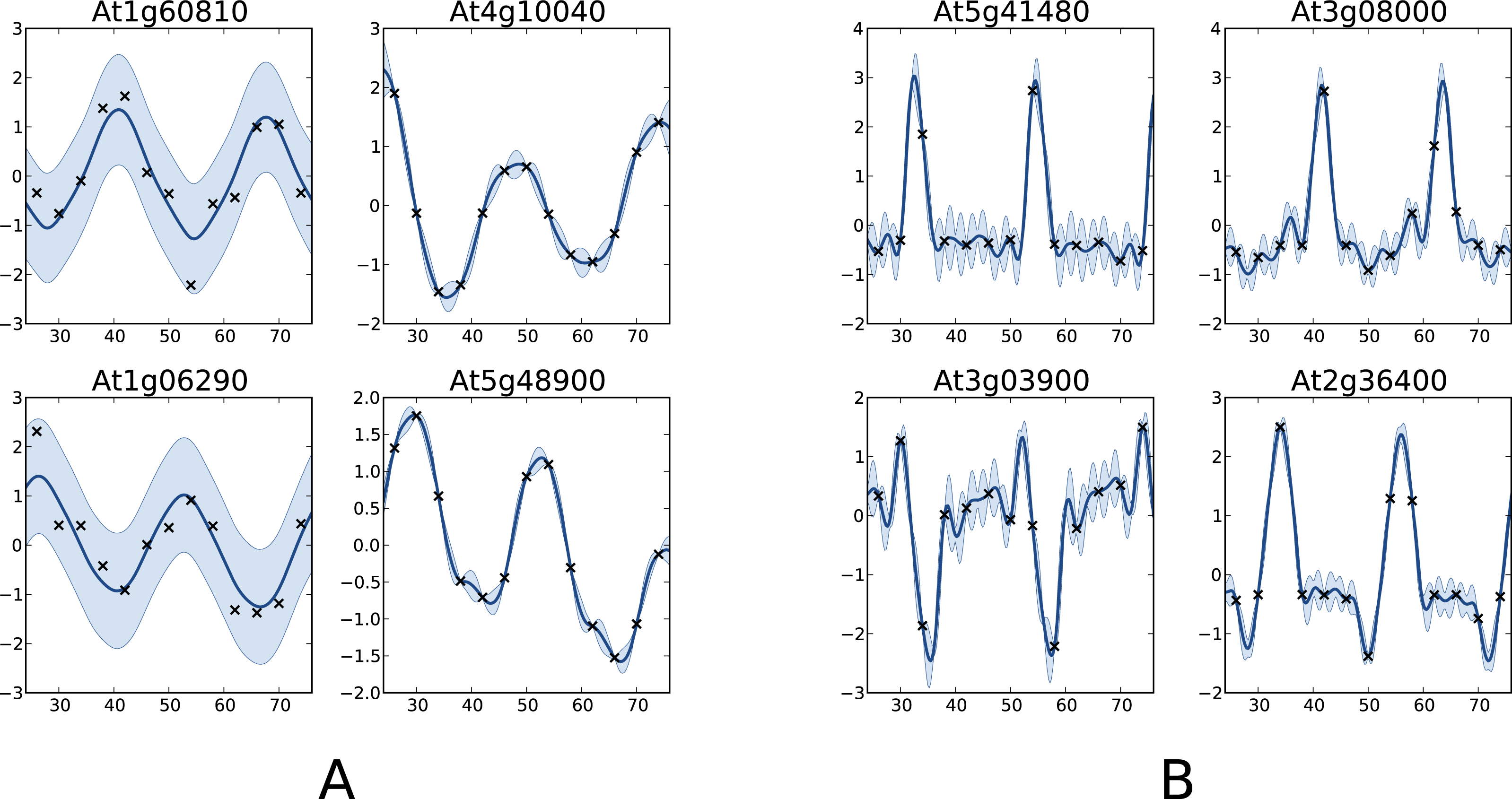{kind=link}
This comparison shows very promising results, both for the capability of the proposed method to handle large datasets and for the quality of the results. Furthermore, we believe that the spike shape of the newly discovered genes may be of particular interest for understanding the mechanism of the circadian clock. The full results, as well as the original dataset, can be found in the Supplemental Information.
Conclusion
The main purpose of this article is to introduce a new approach for estimating, extracting and quantifying the periodic component of a pseudo-periodic function f given some noisy observations yi = f(xi) + ε. The proposed method is typical in that it corresponds to the orthogonal projection onto a basis of periodic functions. The originality here is to perform this projection in some RKHS where the partial knowledge given by the observations can be dealt with elegantly. Previous theoretical results from the mid-1900s allowed us to derive the expressions of the inner product of RKHS based on Matérn kernels. Given these results, it was then possible to define a periodic kernel kp and to decompose k as a sum of sub-kernels k = kp + ka.
We illustrated three fundamental features of the proposed kernels for Gaussian process modelling. First, as we have seen on the benchmark examples, they allowed us to approximate periodic non-sinusoidal patterns while retaining appropriate filtering of the noise. Second, they provided a natural decomposition of the Gaussian process model as a sum of periodic and aperiodic sub-models. Third, they can be reparametrised to define a wider family of kernel which is of particular interest for decoupling the assumptions on the behaviour of the periodic and aperiodic part of the signal.
The probabilistic interpretation of the decomposition in sub-models is of great importance when it comes to define a criterion that quantifies the periodicity of f while taking into account the uncertainty about it. This goal was achieved by applying methods commonly used in Gaussian process based sensitivity analysis to define a periodicity ratio.
Although the proposed method can be applied to any time series data, this work has originally been motivated by the detection of periodically expressed genes. In practice, listing such genes is a key step for a better understanding of the circadian clock mechanism at the gene level. The effectiveness of the method is illustrated on such data in the last section. The results we obtained are consistent with the literature but they also feature some new genes with a strong periodic component. This suggests that the approach described here is not only theoretically elegant but also efficient in practice.
As a final remark, we would like to stress that the proposed method is fully compatible with all the features of Gaussian processes, from the combination of one-dimensional periodic kernels to obtain periodic kernels in higher dimension to the use of sparse methods when the number of observation becomes large. By implementing our new method within the GPy package for Gaussian process inference we have access to these generalisations along with effective methods for parameter estimation. An interesting future direction would be to incorporate the proposed kernel into the ‘Automated Statistician’ project (Lloyd et al., 2014; Duvenaud et al., 2013), which searches over grammars of kernels.
Supplemental Information
Arabidopsis dataset
Original dataset with the gene expressions for each gene at each time point.
Arabidopsis results
File regrouping the available results from Edwards et al. (2006) and the one obtained in the application section. For both methods, the file gives the value of the criterion and the estimated period.