TGMF-pose: text-guided multi-view 3D pose estimation and fusion network for online sports instruction
- Published
- Accepted
- Received
- Academic Editor
- Ankit Vishnoi
- Subject Areas
- Human-Computer Interaction, Artificial Intelligence, Computer Vision, Data Mining and Machine Learning
- Keywords
- 3D human pose estimation, Online sports instruction, Text-guided modeling, Multi-view fusion, Occlusion handling, Semantic action recognition
- Copyright
- © 2026 Qi and Meng
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. TGMF-pose: text-guided multi-view 3D pose estimation and fusion network for online sports instruction. PeerJ Computer Science 12:e3560 https://doi.org/10.7717/peerj-cs.3560
Abstract
Background
Posture estimation technology has been widely applied in online sports instruction to provide precise motion recognition and real-time correction, which significantly improves teaching quality and learning outcomes. However, existing methods often struggle to capture subtle differences between visually similar but technically distinct actions in multi-motion scenarios, leading to semantic ambiguity. Additionally, in cases of limb occlusion, monocular 2D-to-3D mapping lacks multi-view information fusion and geometric structure constraints, resulting in blurred depth estimation and inaccurate keypoint localization.
Methods
To this end, we present a text-guided multi-view 3D pose estimation and fusion network for online sports instruction, named TGMF-Pose. It consists of three core components that enhance the fine-grained representation of semantic information and the accuracy of depth estimation: (1) The joint feature embedding module models the distances and angles between keypoints in 2D pose estimation. Guided by text-based prompts, it captures subtle geometric differences in limb movements across various sports. (2) The multi-view generator effectively addresses the challenge of limb occlusion by estimating the complete 3D pose of the central frame through querying keypoint features from nearby available frames, guided by textual prompts and geometric constraints. (3) The multi-view fusion module aggregates information from all views to refine features and achieve accurate pose depth estimation.
Results
Extensive experiments conducted on various publicly available pose estimation datasets have shown that TGMF Pose outperforms existing state-of-the-art methods in both recognition accuracy and depth recovery. Moreover, integrated within an AI-based instructional system, TGMF-Pose enables real-time feedback and semantic motion evaluation, offering practical value for intelligent, interactive sportxs education. The code is available at https://github.com/yunduo-vision/TGMF-Pose.git.
Introduction
The diversification and rapid expansion of online education (Pabba, Bhardwaj & Kumar, 2024; Zhao et al., 2024) have initiated a gradual shift in physical education from traditional in-person instruction to virtual environments. This transition, however, presents considerable challenges due to the lack of direct supervision and interactive engagement, which hampers the accurate and timely evaluation and correction of learner movements. Deep learning-based pose estimation technologies (Zheng et al., 2023; Salisu et al., 2025; Lan et al., 2022), leveraging human keypoint detection and three-dimensional pose reconstruction, offer promising solutions by enabling real-time motion monitoring, individualized feedback, and corrective guidance within online physical education settings. These capabilities not only enhance the overall learning experience but also provide critical data support for educational analytics and curriculum development, thereby advancing the intelligent and scalable evolution of physical education.
In recent years, with the successful application of models such as convolutional neural networks, graph neural networks, and Transformers in visual tasks, significant progress has been made in 3D pose reconstruction technology. Most methods (Choi, Shim & Kim, 2023; Tan et al., 2024; Peng, Zhou & Mok, 2024) start from monocular images, improving detection accuracy and efficiency through keypoint detection, stacked regression, and graph-structured reasoning. Although these methods have achieved increasing accuracy in standard scenarios, they largely depend on single-frame or short-term temporal features, which limits their ability to capture dynamic variations in movement and undermines the stability of pose estimation. Temporal modelling approaches (Huang et al., 2025; Cai et al., 2024) attempt to address this limitation by enforcing dynamic consistency constraints across consecutive frames to refine pose estimation. However, these methods typically focus only on temporal feature consistency and lack semantic understanding of action categories and structural constraints based on the human skeleton.
In summary, the potential of incorporating textual prompts and multi-view information to strengthen skeletal modeling and depth structure perception in human motion has been largely underexplored by existing methods. As a result, current pose estimation techniques face two major challenges when applied to the complex setting of online physical education. First, in multi-action recognition tasks, models often exhibit insufficient sensitivity to subtle differences between movements, making it difficult to distinguish between action categories that are semantically similar but differ in technical execution. Second, the information loss caused by occlusion and monocular imaging lead to depth ambiguities and joint localization errors in the mapping from 2D-to-3D space, which affects the accuracy and stability of motion correction. These limitations hinder the practical deployment and fine-grained advancement of pose estimation technologies in online sports instruction.
To this end, this article proposes a text-guided multi-view 3D pose estimation and fusion network (TGMF-Pose) for online sports instruction. First, text prompts are embedded to assist in modeling the distance and angle relationships between key joints, which enhances the ability of the model to recognize human skeleton features in different types of movements. Second, a multi-view generator (MVG) based on temporal data is designed, which uses the self-attention mechanism to capture temporal correlations. Missing information in the central frame is compensated by retrieving keypoint features from adjacent available frames to reconstruct its complete 3D pose. In addition, MVG fuses text prompt embedding and skeletal geometric constraints (joint distance and angle) to generate several candidate pseudo-views, which provide more clues for depth estimation. Finally, a multi-view fusion module is designed to perform feature-level aggregation of outputs from all views, enabling refined depth estimation and correction of localization errors. Experiments conducted on multiple public datasets demonstrate that TGMF-Pose achieves significant improvements over existing state-of-the-art methods in both action classification accuracy and depth recovery precision, which validates its practical value in online physical education. The main contributions of this article are summarized as follows:
A novel text-guided multi-view 3D pose estimation and fusion network for online sports instruction has been proposed, which demonstrates excellent interactivity and usability in actual teaching scenarios.
We propose a text-guided skeleton modeling strategy that innovatively fuse text prompts into joint distance and angle modeling, thereby enhancing the ability of the model to discriminate subtle differences among multi-category movements.
A multi-view fusion module is designed to perform fine-grained integration of cross-view information, significantly reducing depth estimation errors and joint localization deviations.
Related work
Monocular pose estimation
Two-dimensional pose estimation aims to detect the positions of human body joints from a single image and serves as the foundation for three-dimensional reconstruction. In recent years, Transformer-based architectures have achieved remarkable progress in this domain. PoseFormerV2 (Zhao et al., 2023) enhances the efficiency of long-sequence modeling and robustness to noise by incorporating frequency-domain representations, significantly improving estimation accuracy under occlusions and detection errors. Additionally, MHFormer (Li et al., 2022) introduces a multi-hypothesis Transformer structure that models multiple pose hypotheses in parallel, thereby strengthening the model’s ability to represent complex movements.
Although the Transformer-based models effectively capture global temporal dependencies through self-attention mechanisms, thereby enhancing long-range contextual modeling, they lack explicit constraints on the geometric priors of the human skeleton. This often leads to joint position predictions that deviate from anatomically plausible skeletal structures. In contrast, Graph Convolutional Networks (GCNs) (Li et al., 2025) excel at modeling local connectivity between joints by leveraging skeletal topology, reinforcing structural priors through message-passing mechanisms. However, GCNs struggle to model global temporal dynamics and long-range dependencies across distant joints. To harness the strengths of both approaches, hybrid architectures, such as SPGformer (Fang et al., 2024) and MotionAGFormer (Mehraban, Adeli & Taati, 2024) have been proposed, which integrate GCNs in parallel with Transformer encoders. These models retain structural priors from the graph while benefiting from the global feature learning capacity of Transformers. However, in multi-action instruction scenarios, they failed to propose effective methods for aligning graph structure priors with action semantic features, which often resulted in insufficient matching between keypoint structure information and action categories, thereby leading to ambiguity in semantic representation and action recognition.
Recently, diffusion-based approaches have emerged as a new paradigm for monocular 3D pose estimation by treating pose reconstruction as a generative denoising process. Diff3DHPE (Zhou et al., 2023) leverages the noise distillation capabilities of diffusion models and integrates them with graph neural diffusion to robustly refine noisy 2D keypoints into accurate 3D structures. Similarly, FinePOSE (Xu, Guo & Peng, 2024) introduces fine-grained part-aware textual prompts to guide diffusion-based denoising, demonstrating the potential of coupling language priors with probabilistic motion modeling. KTPFormer (Peng, Zhou & Mok, 2024) further combines kinematic and trajectory priors within a Transformer framework, embedding domain knowledge of human motion into the self-attention process to improve both spatial and temporal reasoning. These methods represent an important evolution beyond deterministic regression approaches by incorporating uncertainty modeling and semantic cues. However, they remain limited to single-view or monocular input settings and often depend on pretrained text encoders that do not explicitly fuse geometric constraints, making them less effective in occluded or multi-action scenarios relevant to online physical education. In contrast, our TGMF-Pose jointly leverages text-guided geometry modeling and multi-pseudo-view generation fusion, thereby enhancing both the semantic and spatial consistency of 3D pose reconstruction.
Multi-camera pose estimation
To overcome the inherent depth ambiguity of monocular vision, multi-camera and multi-frame methods have been widely explored for improving the accuracy and robustness of 3D human pose estimation. Traditional multi-view frameworks such as VoxelPose (Tu, Wang & Zeng, 2020; Moliner, Huang & Åström, 2024) and FastPose (Dong et al., 2019) explicitly reason in 3D space by aggregating features across calibrated cameras. While these methods are robust to occlusions, their reliance on voxelized representations and exhaustive cross-view matching results in high computational cost and limited scalability. MvP (Wang et al., 2021) addressed this limitation through projective attention, directly regressing multi-person 3D poses from multiple views without volumetric reconstruction, achieving both efficiency and accuracy. However, these approaches remain sensitive to view calibration errors and perform poorly under partially overlapping or sparse camera setups.
Recent studies have increasingly adopted Transformer-based architectures to implicitly capture geometric consistency across multiple sensors and views. For instance, MVGFormer (Liao et al., 2024) integrates geometry- and appearance-aware Transformer modules to jointly reason about multi-view and temporal cues, enhancing robustness to occlusion and viewpoint variation. Dual Transformer Fusion (DTF) (Ghafoor, Mahmood & Bilal, 2024) further advances this direction by generating two intermediate views and fusing them via a dual-branch Transformer. These approaches collectively demonstrate that multi-view feature fusion through attention-based modeling can effectively alleviate depth ambiguity while maintaining temporal coherence. Although these hybrid design yields strong robustness under complex occlusions, it substantially increases training cost and system complexity. Moreover, the model’s reliance on synchronized multi-sensor input makes deployment infeasible for single-camera or consumer-level environments typical of online sports instruction.
Beyond explicit geometric fusion, new paradigms have emerged. MV-SSM (Chharia, Gou & Dong, 2025) reframes multi-view estimation as a state-space modeling problem, employing a Projective State Space (PSS) block with bidirectional token scanning. This design markedly improves generalization to unseen camera configurations and demonstrates strong robustness under view sparsity. However, the state-space formulation treats joint dynamics as purely spatial–temporal signals, omitting the semantic or instructional context that defines the intent behind an action. Consequently, while MV-SSM achieves cross-dataset robustness, it remains limited in interpretability and fine-grained motion discrimination.
In contrast, TGMF-Pose eliminates the dependency on multi-sensor configurations by introducing a text-guided multi-view generation and fusion strategy within a single-camera framework. Rather than relying on calibrated cameras or synchronized sensors, it synthesizes pseudo-views through temporally conditioned attention guided by textual prompts and geometric priors. This design allows the model to infer missing keypoints and recover depth with comparable accuracy to multi-sensor systems while maintaining the deployability required for real-time online instruction. By jointly leveraging semantic cues and implicit multi-view reasoning, TGMF-Pose bridges the gap between physically constrained multi-sensor fusion and semantically aware single-view pose estimation.
Online athletic instruction technology
Online physical education (He, 2024) imposes higher demands on feedback accuracy and system deploy ability. PoseCoach (Liu et al., 2022) provides visual feedback for running instruction by comparing 3D skeletal animations, yet its reliance on offline processing makes it unsuitable for real-time interaction in large-scale online teaching. Zhao et al. (2022) proposed a 3D pose feedback framework based on graph convolutional networks, capable of detecting user errors during exercise and offering corrective suggestions, thereby significantly enhancing the safety and effectiveness of personalized training. However, this approach primarily targets specific movements and does not adequately address the challenge of recognizing subtle differences across multiple action categories.
Recent advancements are beginning to explore multimodal and privacy-aware instructional setups. For instance, Lupión et al. (2024) employed multi-view thermal vision sensors to preserve privacy while achieving robust 3D estimation in low-light environments. Meanwhile, ChatPose (Feng et al., 2024) demonstrated the integration of large language models (LLMs) for reasoning about human poses from textual or visual inputs, suggesting a new direction for interactive and explainable sports coaching systems. Although these methods improve interpretability or privacy, they often sacrifice temporal coherence or introduce high computational costs that impede real-time deployment.
Building on these insights, there is an urgent need for a semantically aware 3D pose estimation framework that operates reliably with a single standard camera, enabling real-time interaction and fine-grained movement assessment.
Methods
As illustrated in Fig. 1, the overall framework consists of three primary modules: a text-guided joint feature embedding module, a multi-view 3D pose generator, and a multi-view fusion module. The following sections detail the structural design and functional implementation of each component.
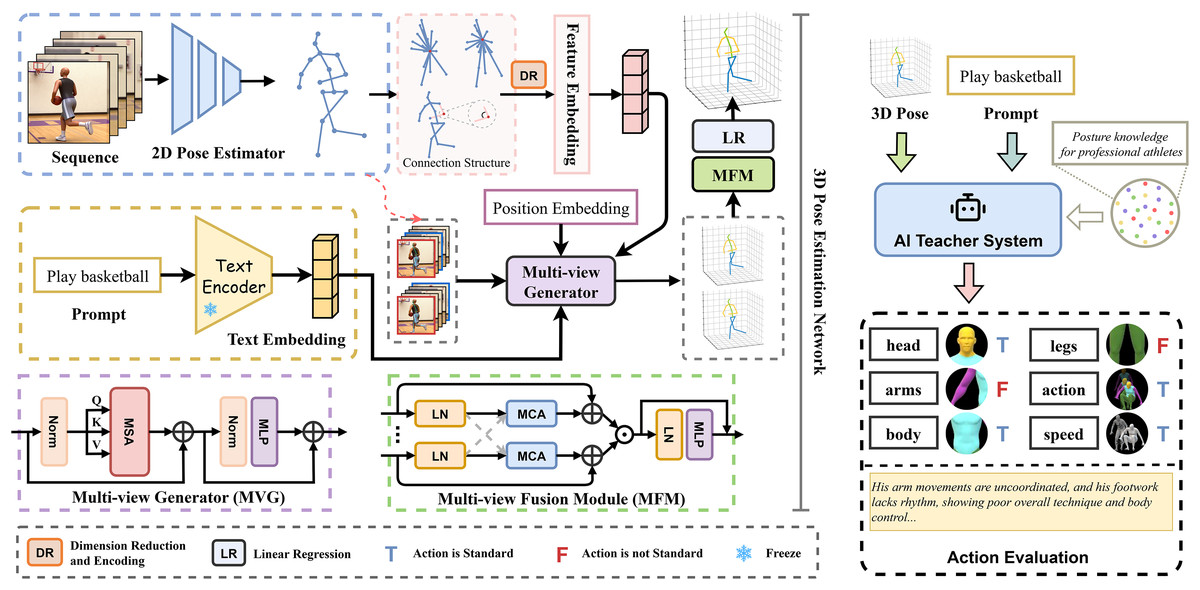
Figure 1: The proposed framework of TGMF-Pose.
{kind=link}
Overall architecture
TGMF-Pose takes a monocular video sequence as input and aims to estimate high-precision 3D human poses for each frame. The overall framework is composed of four key stages: 2D pose extraction, geometric-semantic modeling, 3D candidate generation, and multi-view fusion optimization. Given a sequence of video frames , we first use ViTPose (Xu et al., 2022) as the backbone network for 2D pose estimation to detect keypoints in each frame, yielding a set of skeletal joints and their connectivity, where is the number of joints. Based on this skeletal structure, we construct two geometric measurement branches: the first calculates the Euclidean distances between all pairs of joints to form a spatial distance matrix. The second computes angles between each non-leaf joint and its neighboring joints to capture joint-angle constraints in the pose. These geometric features are encoded through a one-dimensional convolutional network to generate structural embedding representation , which serves as the foundational feature for subsequent geometric modeling.
Second, to introduce motion semantic information, we designed a text feature embedding branch. Users or the system can provide a natural language description of the physical activity being performed in the video. We use the parameter-frozen CLIP model (Radford et al., 2021) to generate semantic vectors. Aligning text prompts with geometric structural features effectively enhances the model’s ability to perceive action-specific geometric characteristics. To address the issue of occlusion commonly encountered in 2D pose estimation, we design a Transformer-based multi-view generation module (MVG). This module utilizes self-attention mechanism to model temporal context dependencies and queries available frames near the central frame. Each combination of the central frame and available adjacent frames is treated as a pseudo-multi-view. By embedding temporal position, text prompt, and geometric structure information, MVG generates sets of 3D pose candidate solutions. All generated candidate 3D poses are subsequently refined through a multi-view fusion module (MVF). This module performs feature-level interaction and consistency optimization across views using the cross-attention mechanism to aggregate complementary information among views. MVF can effectively complete the structure of occluded areas and corrects depth estimation, which made the output are better suited for subsequent tasks such as motion correction and performance feedback in online physical education.
Notably, a potential concern when employing pseudo-view generation is that the model may overfit to the synthetic views instead of learning view-invariant 3D geometry. To avoid this risk, the pseudo-view in our work differ from traditional view fusion methods refers to feature-level pseudo-views produced by cross-frame feature querying and aggregation, not to pixel- or image-level synthesis. Concretely, MVG constructs pseudo-view candidates by attending to and re-weighting latent joint embeddings drawn from nearby temporal frames; no decoder is trained to render new images or to fabricate novel visual appearances. This feature-space design prevents the model from memorizing synthetic image artifacts and keeps the learned representations grounded in real observed evidence, improving robustness and avoiding distributional shift associated with pixel-level view generation.
Text-guided geometric embedding module
This module is designed to leverage the spatial structural features between joints and incorporate semantic guidance from text to enable sensitive modeling of inter-class differences in actions. From 2D poses, we extract two types of structural features: the Euclidean distance matrix and the angle feature matrix. For any two joints and , the normalized Euclidean distance matrix is defined as:
(1)
Among them, represents the indices of the two joints with the furthest spatial distance. For non-leaf joints, the angle between the adjacent joints and is defined as:
(2)
These normalized geometric descriptors are encoded into feature vectors through convolutional layers . Then passed through a multi-layer perceptron (MLP) composed of two fully connected layers with Gaussian Error Linear Unit activations and residual normalization. This MLP projects the geometric features into a latent vector space, ensuring each joint is represented by a compact embedding that preserves relative spatial structure.
(3)
(4)
Given an action semantic text prompt (e.g., “playing basketball”), we encode it using a pre-trained CLIP text encoder to obtain its embedding , then expand this embedding into multi-head prompt vectors that match keypoint dimension. To align the two modalities, a cross-modal attention block is introduced, where text features act as queries and geometric embeddings serve as keys and values. This operation generates a text-guided geometric feature, emphasizing spatial regions relevant to the described action.
(5)
denotes the multi-head attention module, represents the semantic perception embedding of joints under text prompts and serving as the input to the subsequent 3D pose generation module.
Multi-view generator
The multi-view generator is designed to infer missing or occluded body parts and to simulate multiple complementary pseudo-views of the same motion from a single input sequence. Its role is to enhance depth perception and occlusion robustness by reconstructing consistent 3D representations from limited 2D evidences. Let the central frame be at timestamp , and a total of adjacent frames before and after it form a temporal window:
(6)
Here, represents the geometric feature embedding of the frame after the text prompt is fused. The corresponding text prompt embedding is , and the temporal position encoding is used to indicate the relative position of frames. We utilize the self-attention mechanism to model cross-frame contextual dependencies, search for nearby available frames, and concatenate them with the above feature embeddings as input to the MVG to generate pseudo 3D views .
(7)
(8)
The architecture of MVG is illustrated in Fig. 1. The input is first normalized and then passed through a Multi-Head Self-Attention (MSA) module. This is followed by another normalization layer and a Multi-Layer Perceptron (MLP) for further feature transformation. Residual connections are employed throughout the process to facilitate gradient flow and improve information propagation. This process essentially leverages the temporal differences in frame perspectives to simulate spatial perspective differences and generate pseudo views.
Multi-view fusion module
This module is designed to perform feature-level fusion of 3D pose estimations obtained from multiple different viewpoints, with the goal of refining predictions and enhancing the accuracy of both depth estimation and keypoint localization.
Taking the fusion of two pseudo-views as an example, let them be denoted as and respectively. A pose encoder is introduced to project them into a shared latent space . Using as the query and as the context, a Multi-Head Cross-Attention (MCA) mechanism is employed to fuse structural information from the two viewpoints. The MCA module is composed of multiple parallel attention heads that jointly capture and quantify the inter-view correlations.
(9)
This process enables structural alignment and contextual information sharing, which refines the 3D pose representation. The fused features are then fed into a 3D pose reconstructor , which regresses the final 3D pose estimation for the central frame, denoted as .
To optimize the proposed TGMF-Pose network, a multi-objective loss function is employed to jointly supervise joint consistency and semantic-text alignment. The total loss is computed as follows:
(10) where is the loss-term balancing hyperparameter. measures the mean squared error between the predicted (P) and ground-truth (T) 3D joint positions. It is defined as follows:
(11)
minimizes the cosine distance between the predicted pose and the text embedding in the shared latent space. It is defined as follows:
(12) where denotes the CLIP-based text encoder, and is a shallow MLP implemented as three feed-forward layers equipped with GELU activations and layer normalization. This module projects the fused 3D pose features into the shared semantic embedding space of the text encoder, thereby facilitating cosine-similarity-based alignment between the visual pose representations and their corresponding textual descriptions.
Action evaluation
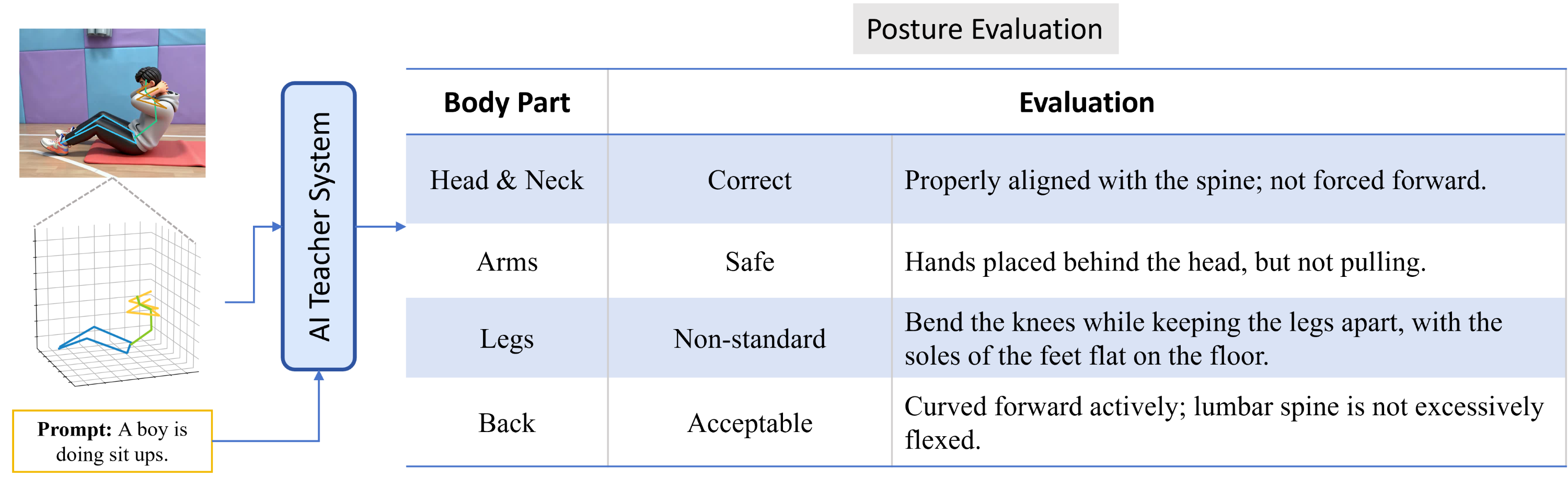
The Artificial Intelligence (AI) Teacher System is an intelligent, interactive instructional engine built upon the existing large language model (LLM) architecture, enhanced through Low-Rank Adaptation (LoRA) (Hu et al., 2022), which enables efficient fine-tuning on domain-specific datasets without compromising general linguistic capability. By performing instruction tuning on standardized 3D pose data collected from professional athletes, the system acquires both structural understanding and semantic expressiveness of athletic movements. In practical applications, the system takes as input a sequence of joint coordinates generated by a 3D pose estimation network for each frame, along with user-provided natural language prompts such as the name of the movement. This enables the system to perform a comprehensive analysis that integrates temporal motion trajectories with semantic expectations. The system evaluates the execution quality of key parts (e.g., head, arms, body, legs, action and speed) on an individual basis, producing structured scores and personalized textual feedback. This facilitates fine-grained, interpretable automatic error correction and instructional support.
Notably, Through LoRA-based fine-tuning, the system achieves efficient parameter adaptation while preserving the general language understanding capability of the base LLM, thereby enhancing robustness to real-world textual inputs. It can handle natural language instructions containing typos, informal expressions, or non-technical vocabulary, and maps diverse phrases to standardized motion categories through contextual semantic alignment. The low-rank adaptation also maintains the model’s disambiguation ability, allowing the system to infer ambiguous actions by integrating linguistic semantics with 3D pose data. Furthermore, the attention-based confidence mechanism enables adaptive weighting or clarification when textual uncertainty is high, ensuring stable motion evaluation performance across diverse natural language environments.
Results
To evaluate the practicality and accuracy of the proposed Text-Guided Multi-View 3D Pose Estimation and Fusion Network (TGMF-Pose) in the context of online physical education, we conducted comprehensive experiments on multiple public datasets and further validated its effectiveness through instructional feedback within an AI-assisted teaching system.
Datasets and evaluation metrics
Human3.6M (Ionescu et al., 2013) is one of the most widely used large-scale datasets for 3D human pose estimation. Captured in a controlled laboratory setting, it features 11 subjects performing 15 everyday activities such as walking, sitting, phoning, and eating. Each sequence is recorded from four synchronized camera views and annotated with high-precision 3D motion capture data. The dataset contains approximately 3.6 million image frames, providing per-frame 3D joint coordinates for 17 body joints, along with corresponding 2D projections and RGB images. In our experiments, we follow Protocol #1, where subjects S1, S5, S6, S7, and S8 are used for training, and S9 and S11 are reserved for testing. Owing to its accurate annotations and structured setup, Human3.6M serves as a strong benchmark for evaluating the 3D reconstruction accuracy of pose estimation models under controlled conditions.
MPI-INF-3DHP (Mehta et al., 2017) presents a more challenging benchmark designed to assess the generalization ability of pose estimation algorithms, particularly under unconstrained scenarios such as outdoor environments, occlusions, and viewpoint transitions. The dataset includes 17 activity classes performed by eight actors across diverse indoor (e.g., green screen) and outdoor (e.g., street, grassland) scenes. Several sequences involve varying clothing, props, and partial occlusions. Compared to Human3.6M, MPI-INF-3DHP offers greater variability in background complexity, lighting conditions, and camera angles, as well as a broader range of body poses. It is therefore well-suited for testing the robustness of TGMF-Pose to diverse viewpoints, motion amplitudes, and environmental conditions.
To comprehensively evaluate the performance of our model, we employ three standard metrics: Mean Per Joint Position Error (MPJPE), Percentage of Correct Keypoints (PCK), and Area Under the Curve (AUC). Specifically, MPJPE measures the average Euclidean distance between the predicted and ground-truth 3D joint positions, with lower values indicating higher accuracy in pose estimation. PCK quantifies the proportion of correctly predicted keypoints within a specified error threshold, serving as an indicator of overall pose correctness. AUC represents the area under the PCK curve across varying thresholds and provides a holistic assessment of the model’s keypoint prediction stability and robustness.
Implementation details
All experiments were conducted under a unified hardware and software environment to ensure reproducibility and fair comparison. We used an NVIDIA A100 GPU (40 GB) and ran our code in Python 3.9 with PyTorch 2.0. Each input frame was resized to 256 × 192 pixels and normalized to the [−1, 1] range. A pretrained ViTPose backbone then extracted 17 joint coordinates and their confidence scores. Confidence values were applied as attention masks in downstream modules to enhance robustness against low-quality detections. Action prompts, each limited to 20 Chinese characters to avoid redundancy, were authored by professional sports instructors. We encoded these prompts using a frozen CLIP text encoder (ViT-B/32), producing 512-dimensional embeddings. Each embedding was then expanded into multi-head prompt vectors matching the number of joints for cross-modal attention. Both the Multi-View Generator (MVG) and the Multi-View Fusion Module (MVF) employ a 4-layer Transformer, with 8 attention heads per layer and a hidden dimension of 256. Joint features are encoded via two stacked 1D convolutional layers (kernel = 3, stride = 1). Cross-modal fusion is implemented through multi-head cross-attention, integrating textual and geometric features.
For each centre frame , we sample five preceding and five succeeding frames to form a 10-frame temporal window. At video boundaries, missing frames are duplicated. All 2D joint coordinates are normalized to [−1, 1], and their confidence scores serve as optional attention masks. We optimized all models using Adam with an initial learning rate of . A linear warm-up was applied for the first 20 epochs, followed by cosine-annealing decay over a total of 80 epochs. In the live sports-teaching system, TGMF-Pose splits uploaded video clips into frames, extracts 2D skeletons, and generates fused 3D poses. These 3D poses are then fed into an AI instructor module, which produces natural-language feedback and localized action scores for interactive, interpretable teaching.
Comparison with state-of-the-art methods
To assess the effectiveness of our proposed TGMF-Pose model in online sports instruction scenarios, we conducted a comprehensive comparison using standard benchmarks and compared it with a series of state-of-the-art 3D human pose estimation methods, including Anatomy3D (Chen et al., 2021), PoseFormer (Zheng et al., 2021), MHFormer (Li et al., 2025), P-STMO (Shan et al., 2022), MixSTE (Zhang et al., 2022), and PATA (Xue et al., 2022).
1) Results on Human3.6M Dataset:
All compared methods are evaluated under Protocol #1, which computes the Mean Per Joint Position Error (MPJPE) between the predicted and ground-truth 3D joint coordinates without any alignment. Table 1 presents action-wise MPJPE results for each method across eight commonly benchmarked activities. Our method, TGMF-Pose, achieves the lowest average MPJPE of 56.81 mm, demonstrating a notable margin of improvement over all other methods. In particular, TGMF-Pose outperforms Anatomy3D by 19.85 mm, and reduces error by over 18.88 mm compared to PoseFormer, confirming the efficacy of our multi-view guided estimation and prompt-based skeletal modeling. Compared with Anatomy3D and MHFormer, both of which depend on single-frame or short-range temporal information, our method exhibits stronger resilience in capturing long-term dependencies and handling self-occlusion. For actions involving intricate hand or upper-body interactions (e.g., “Greet” and “Phone”), where keypoints are frequently occluded or spatially entangled, TGMF-Pose achieves superior accuracy by effectively leveraging surrounding frames to reconstruct the occluded joints. While MixSTE also utilizes a spatio-temporal encoder, its simplified token mixing mechanism lacks the fine-grained semantic modeling and cross-view fusion capabilities found in our architecture. Consequently, although MixSTE performs well on relatively structured actions such as “Eating” and “Directions”, it suffers from depth ambiguity in actions like “Photo” and “Pose”, where our approach consistently produces more reliable 3D reconstructions. A key factor contributing to the superior performance of TGMF-Pose is the incorporation of textual prompts into the geometric reasoning process. Unlike PATA, which introduces prompt attention in a relatively shallow fashion, our method integrates text-guided joint relationships into both the view generation and refinement stages. This design allows the model to adaptively emphasize discriminative spatial patterns that differentiate actions with subtle inter-joint variations.
| Methods | Dir. | Disc. | Eat. | Greet | Phone | Photo | Pose | Sit | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Anatomy3D | 73.45 | 80.90 | 75.11 | 83.26 | 74.02 | 93.63 | 66.96 | 65.93 | 76.66 |
| PoseFormer | 75.60 | 73.87 | 72.27 | 81.00 | 78.31 | 87.43 | 66.22 | 70.80 | 75.69 |
| MHFormer | 71.62 | 73.38 | 71.98 | 79.56 | 71.06 | 85.79 | 64.90 | 80.76 | 74.88 |
| P-STMO | 70.79 | 73.92 | 73.15 | 79.14 | 86.50 | 64.28 | 66.48 | 64.96 | 72.40 |
| MixSTE | 58.02 | 55.81 | 51.98 | 59.11 | 53.76 | 71.27 | 55.99 | 62.65 | 58.57 |
| PATA | 62.72 | 74.57 | 74.68 | 82.32 | 71.59 | 73.89 | 66.71 | 64.46 | 71.37 |
| TGMF-Pose | 55.41 | 54.98 | 50.20 | 57.29 | 53.65 | 67.88 | 53.22 | 61.85 | 56.81 |
Additionally, the multi-view generator in TGMF-Pose synthesizes diverse pose hypotheses from temporally adjacent frames, capturing alternate perspectives and mitigating the impact of missing or noisy joints. The subsequent fusion module then aggregates these candidate views into a unified representation, significantly enhancing depth estimation robustness. Notably, our method exhibits stable performance across a broad range of action categories. For example, in “Discussion” and “Photo”—scenarios prone to partial occlusion or limited body movement—TGMF-Pose maintains competitive accuracy, thanks to its temporal reconstruction capabilities. In contrast, prior methods often misinterpret such inputs due to over-reliance on frame-local information or limited structural priors.
Figure 2 illustrates one representative case involving a male subject seated with legs crossed and facing away from the camera, where severe occlusion of the lower limbs poses significant challenges to accurate 3D pose recovery. In this example, all baseline methods fail to correctly localize the joints of the occluded leg. Their predictions exhibit noticeable artifacts such as misaligned knee positions, inverted lower limbs, or unrealistic joint angles, which deviate significantly from the ground truth. These errors highlight the limitations of existing models in handling occluded or self-overlapping joint regions, particularly when lacking multi-view context or fine-grained geometric priors. In contrast, our TGMF-Pose model reconstructs the full 3D pose with remarkable accuracy, even in the absence of visible leg joints in the current frame. The predicted keypoints for the occluded knee and ankle align closely with the ground-truth annotations, demonstrating our model’s ability to infer plausible joint configurations based on temporal cues and structural reasoning.
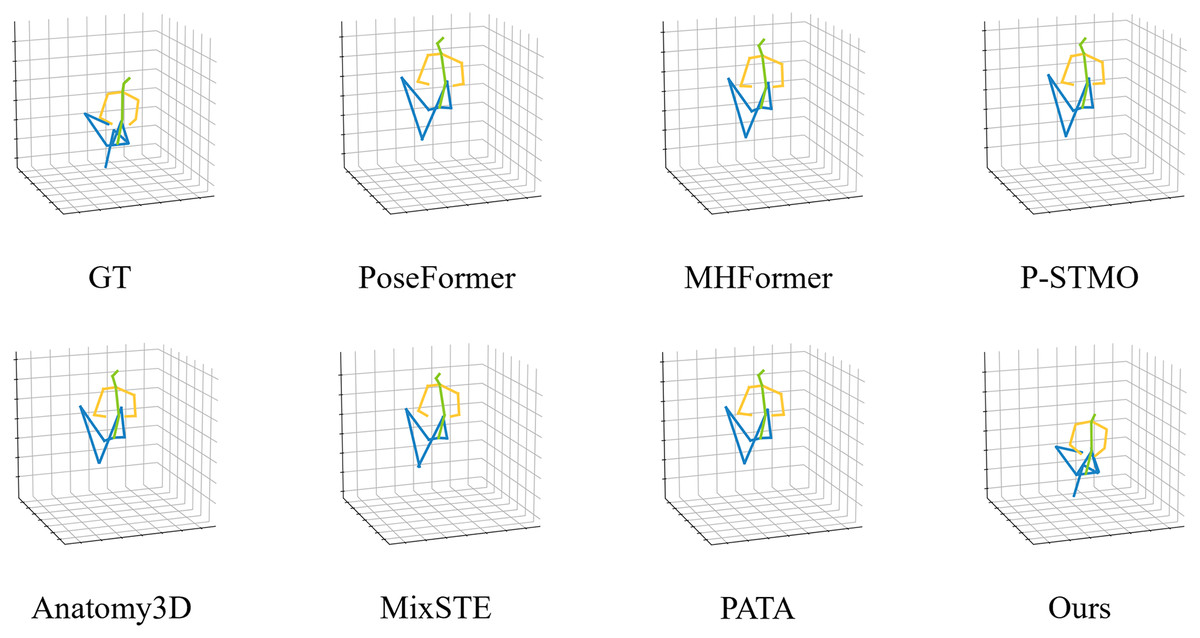
Figure 2: Qualitative comparison with state-of-the-art methods on Human3.6M.
{kind=link}
2) Results on MPI-INF-3DHP Dataset:
Table 2 shows that TGMF-Pose achieves the best performance across all evaluation criteria, with a PCK of 98.6%, AUC of 83.3, and MPJPE of only 25.7 mm. These results represent significant improvements over the closest competitor, P-STMO, which achieves a PCK of 97.9% and an MPJPE of 32.2 mm. MHFormer, though effective in clean sequences, suffers performance degradation with an MPJPE of 58.0 mm and lower AUC (63.3), reflecting limited robustness to occlusion and appearance confusion. MixSTE, which employs mixed spatio-temporal encoding, shows better resistance to pose jitter but lacks sufficient semantic modeling, leading to higher MPJPE (54.9 mm). Anatomy3D and PoseFormer perform reasonably but are evidently less capable of handling visual ambiguities, as indicated by their lower PCK and higher MPJPE values.
| Methods | PCK↑ | AUC↑ | MPJPE↓ |
|---|---|---|---|
| Anatomy3D | 87.9 | 54.0 | 78.8 |
| PoseFormer | 88.6 | 56.4 | 77.1 |
| MHFormer | 93.8 | 63.3 | 58.0 |
| P-STMO | 97.9 | 75.8 | 32.2 |
| MixSTE | 94.4 | 66.5 | 54.9 |
| PATA | 90.3 | 57.8 | 69.4 |
| TGMF-Pose (Ours) | 98.6 | 83.3 | 25.7 |
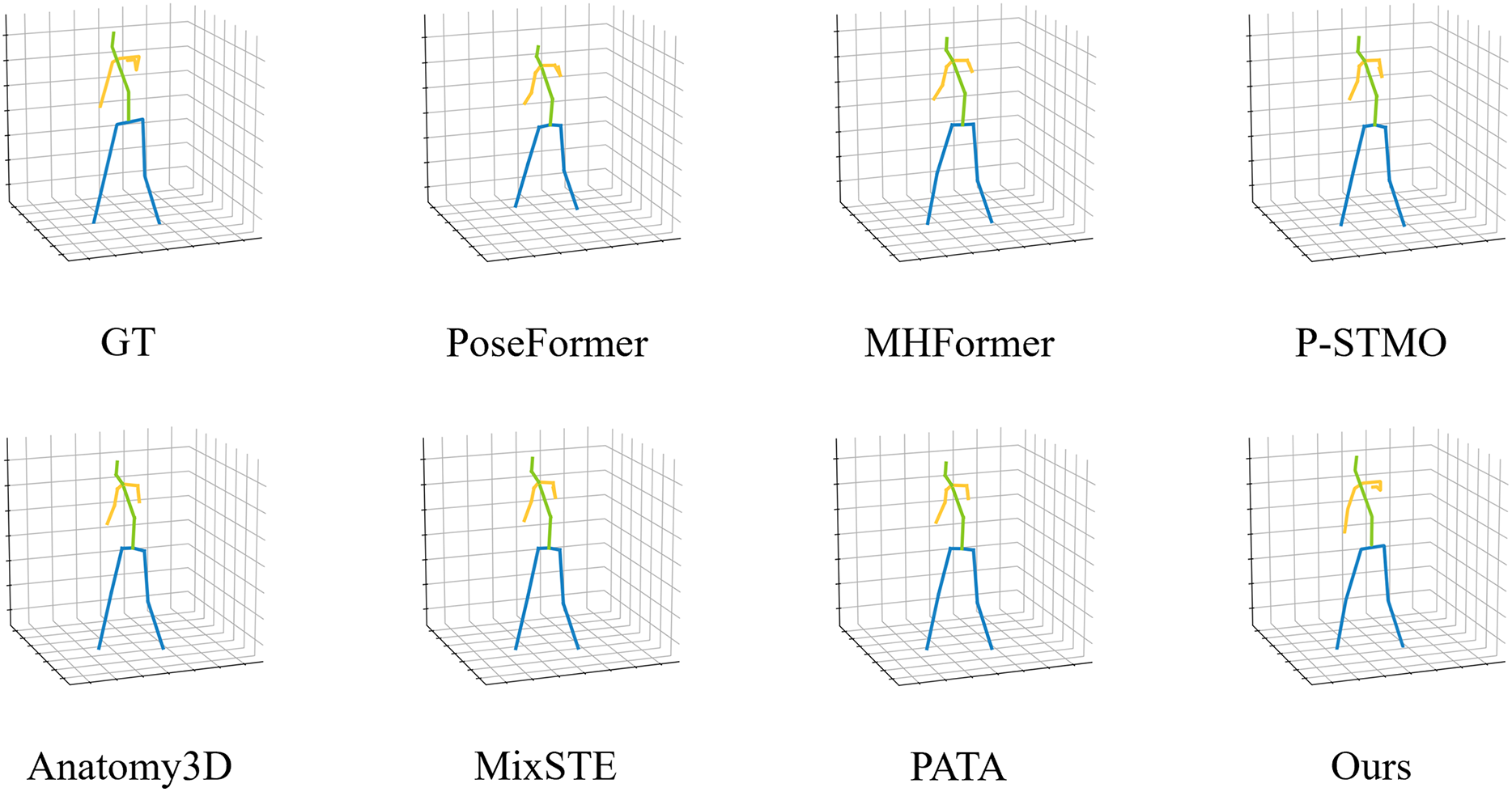
To complement the numerical findings, Fig. 3 showcases a challenging outdoor scenario captured from the MPI-INF-3DHP dataset. The subject is a woman walking across a grassy field, partially occluded by her own scarf, which drapes over her right arm and introduces a confusing visual cue. In this scene, Baseline models such as MHFormer, PoseFormer, and P-STMO consistently misidentify the scarf as part of the right arm, resulting in visible misalignment in elbow and wrist localization. These methods erroneously extend the arm’s trajectory along the scarf contour. In contrast, TGMF-Pose accurately distinguishes between clothing and actual limb structure, producing a 3D pose that closely aligns with the ground-truth. The wrist and elbow are correctly inferred despite the absence of direct visual evidence, thanks to temporal cue propagation and structural constraints learned through prompt-guided modeling. This qualitative example highlights a critical advantage of TGMF-Pose: semantic-awareness and structural integrity. By embedding text-based priors and enforcing multi-view consistency, our model avoids common confusions induced by background objects or accessories.
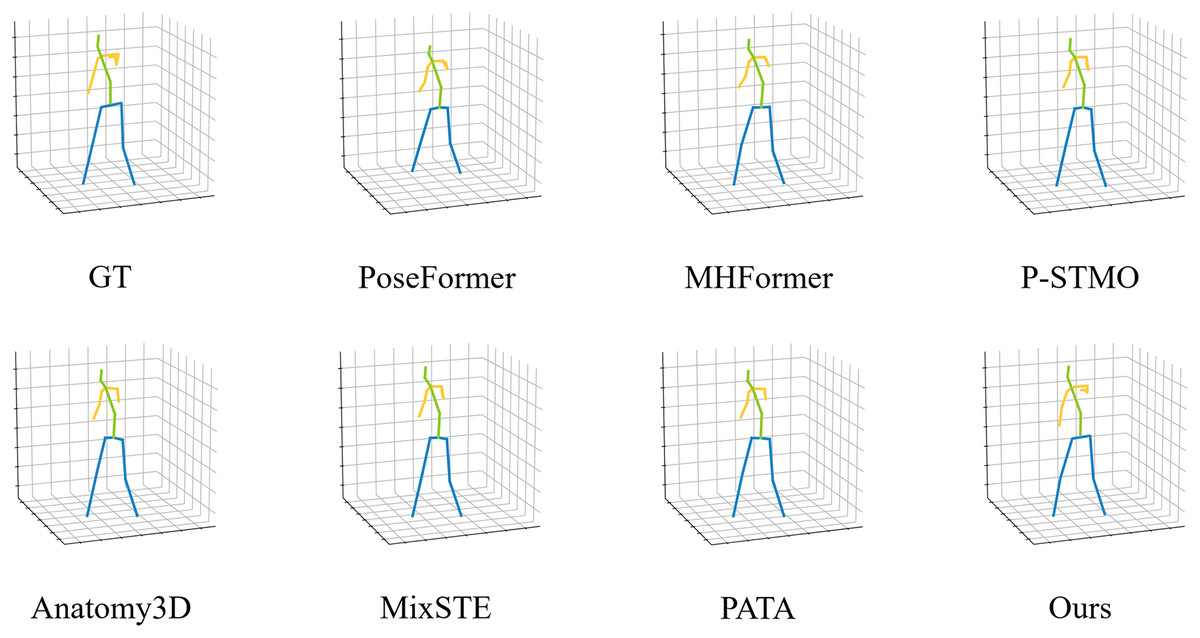
Figure 3: Qualitative comparison with state-of-the-art methods on MPIINF-3DHP.
{kind=link}
In addition, to further assess the generalization capacity and practical utility of the proposed TGMF-Pose framework beyond conventional benchmarks, we conducted an additional evaluation using sports imagery sourced directly from the internet, as illustrate in Figs. S1, S2, and Supplemental Material 1.
Ablation
To thoroughly evaluate the contribution of each core component within the proposed TGMF-Pose framework, we conducted a series of ablation experiments on the MPI-INF-3DHP dataset. All experiments adopt ground-truth 2D keypoints as input to exclude the interference of detection errors and focus purely on the impact of each architectural component.
1) Effectiveness of Text-Guided Prompt Embedding:
We first remove the TGPE module, which is responsible for modeling semantic differences in joint relationships based on textual prompts. As shown in Table 3, this modification causes a performance drop across all evaluation metrics. These results indicate that the introduction of text-based guidance significantly enhances the model’s sensitivity to fine-grained variations in human motion, especially for semantically similar but technically distinct actions. The lack of TGPE weakens the model’s ability to incorporate human-level prior knowledge in joint distance and angle modeling, leading to increased ambiguity in pose interpretation.
| Method | PCK↑ | AUC↑ | MPJPE↓ |
|---|---|---|---|
| TGMF-pose (Full model) | 98.6 | 83.3 | 25.7 |
| w/o Text-Guided Prompt Embedding | 96.9 | 78.2 | 30.8 |
| w/o Multi-View Generator | 95.7 | 75.6 | 34.1 |
| w/o Multi-View Fusion Module | 96.3 | 77.4 | 31.9 |
To further validate the contribution of TGPE in capturing technical nuances across similar motions within the same sport category, we conducted an additional comparative study across four exercise pairs that are commonly confused in instructional settings due to their visual similarity but require different technical execution: sit-up vs. crunch, squat vs. lunge, push-up vs. plank, and jump vs. high-knee running. As summarized in Table 4, the full model consistently exhibited improved pose accuracy in these ambiguous cases. Notably, in the sit-up vs. crunch pair, the MPJPE decreased from 31.5 to 25.8 mm when TGPE was included, primarily due to better estimation of upper-body joint trajectories where trunk flexion angles are critical. Similar improvements were observed in the squat vs. lunge comparison (from 32.3 to 27.0 mm), where TGPE helped differentiate foot placement and knee alignment that are otherwise visually similar in monocular input.
| Action pair | MPJPE (w/o TGPE) ↓ | MPJPE (w/TGPE) ↓ |
|---|---|---|
| Sit-up vs. Crunch | 31.5 | 25.8 |
| Squat vs. Lunge | 32.3 | 27.0 |
| Push-up vs. Plank | 30.9 | 25.9 |
| Jump vs. High-Knees | 29.6 | 23.9 |
These results support the hypothesis that TGPE enhances the model’s fine-grained perception by integrating motion-specific semantic priors into geometric reasoning. By embedding text-derived intent into the joint embedding space, TGPE enables the network to interpret not only how a pose appears, but also what it is intended to represent. This effectively bridges the gap between kinematic similarity and task-level meaning. Such capability is particularly beneficial in online sports instruction environments, where subtle misalignments in joint behavior, such as premature trunk elevation during a crunch or insufficient hip descent in a lunge, can result in incorrect form or even injury. TGPE provides a semantic scaffold that allows the model to resolve motion ambiguity that cannot be reliably addressed through spatial features alone.
2) Effectiveness of Multi-View Generator:
To evaluate the impact of the Multi-View Generator, we disable the generation of pseudo-views from adjacent frames, forcing the model to rely solely on the central frame’s features. As reflected in Table 3, the model performance declines significantly. This suggests that MVG plays a crucial role in addressing occlusion and depth ambiguity by reconstructing occluded joints using temporal context. The removal of MVG deprives the network of critical auxiliary views, reducing its capacity to infer accurate spatial structures under motion continuity.
3) Effectiveness of Multi-View Fusion Module:
Lastly, we analyse the role of MVF by replacing it with a simple averaging operation across pseudo-view outputs. This simplification results in a measurable decline in performance, demonstrating that the proposed fusion strategy is not merely a redundant integration step but a key component that adaptively refines pose hypotheses by resolving inconsistencies across views. The MVF enhances the robustness of final predictions by aggregating cross-view evidence in a context-aware manner. The above results clearly demonstrate that all three components, TGPE, MVG, and MVFM, contribute synergistically to the performance of TGMF-Pose. TGPE enhances semantic understanding and structural awareness, MVG provides temporal redundancy and occlusion recovery, and MVF ensures robust view-wise information aggregation. Disabling any of these modules leads to a consistent and non-trivial degradation in pose estimation accuracy, underscoring their necessity for effective application in multi-action online sports instruction scenarios.
In Supplemental Materials 2–6, we present a more comprehensive ablation study covering hyperparameter sensitivity, temporal performance, computational complexity, robustness to textual inputs, and the effect of text-guided prompts on action differentiation. Overall, these findings demonstrate that TGPE enhances the AI teacher’s ability to provide context-aware, task-specific feedback. While feedback without TGPE tends to be generalized, the inclusion of text-based prompts allows the system to offer actionable, expert-like guidance. This makes TGPE a valuable tool in online instruction, where visual cues alone may not be sufficient to address subtle technical issues.
Discussion
From an application perspective, 3D pose estimation has great potential to enhance online sports education, especially under AI-driven personalized learning paradigms. It can underpin AI coaching assistants that provide personalized form corrections, complementing traditional instructors. By automating form analysis, such systems could help mitigate the shortage of expert coaches in remote settings. When combined with VR/AR and wearables, immersive interactive training becomes possible: VR experiences (Mallek et al., 2024) have been shown to boost engagement through personalized immersion.
In this application background, despite its advantages, the proposed TGMF-Pose framework also presents several limitations and boundary conditions that warrant further exploration. First, although the text-guided multi-view generator effectively reconstructs occluded joints, its accuracy remains dependent on the reliability of the 2D keypoint detections. When faced with extremely long motion sequence inputs, fixed text embeddings may gradually lose its modulation strength over extended temporal horizons. Second, while the pseudo-view generation strategy mitigates the need for physical multi-camera setups, it may still struggle with extreme self-occlusions or rapid non-periodic motions where temporal cues are insufficient to infer missing spatial information. Third, because the model integrates a transformer backbone with language-conditioned attention, its inference latency, though acceptable for online applications, additional optimization or lightweight distillation strategies may be necessary for large-scale deployment on mobile or embedded platforms. Furthermore, multi-person interactions and group dynamics remain open challenges, particularly for sports contexts involving close physical contact or overlapping movements.
Future research should therefore aim to enhance both the robustness and scalability of text-guided multi-view modeling through three complementary directions. First, adaptive prompt generation and self-supervised text–pose alignment could reduce dependency on manually curated textual inputs, enabling the model to automatically refine semantic cues during training or deployment. Second, developing an end-to-end text-guided 3D pose estimation framework that directly infers joint representations from raw visual inputs—without requiring precomputed 2D detections—would further improve spatial coherence and reduce cumulative error propagation across stages. Such an integrated design would enable more consistent alignment between geometric and semantic features while simplifying the deployment pipeline. Third, expanding the model to handle multi-person interactions and cooperative motion analysis would extend its applicability to team-based or competitive sports instruction.
Conclusion
This article presents TGMF-Pose, a text-guided multi-view 3D pose estimation and fusion network tailored for online physical education scenarios. The proposed approach addresses key limitations of existing pose estimation methods, particularly their difficulties in fine-grained recognition of multi-category actions and inaccurate keypoint localization under occlusion. To overcome these challenges, TGMF-Pose integrates semantic prompt modeling, temporal multi-view reconstruction, and cross-view fusion, effectively enhancing performance in complex action recognition and 3D reconstruction tasks. Specifically, TGMF-Pose consists of three novel components: A text-guided joint feature embedding module, which models angular and distance relationships between joints to capture fine-grained structural differences in movements under semantic guidance. A multi-view generation module, which leverages adjacent frames and textual prompts to recover occluded limbs, ensuring temporal consistency and spatial completeness. A multi-view fusion module, which aggregates pose information from different viewpoints to refine depth estimation and improve keypoint localization accuracy. Extensive experiments conducted on Human3.6M, MPI-INF-3DHP, and a self-constructed sports instruction dataset demonstrate that TGMF-Pose significantly outperforms state-of-the-art methods in terms of keypoint localization accuracy, occlusion recovery, and multi-action recognition. Importantly, the proposed model not only serves the pose reconstruction task but also functions as a core component of the AI Teacher System, forming an intelligent and interactive human-computer teaching framework. In future work, we aim to enhance the AI Teacher System’s interactivity by enabling natural dialogue-based instruction and task-driven motion training.
{kind=link}
{kind=link}
{kind=link}