Fake news detection in Arabic media: comparative analysis of machine learning and deep learning algorithms using the Arabic Fake News Dataset
- Published
- Accepted
- Received
- Academic Editor
- Davide Chicco
- Subject Areas
- Artificial Intelligence, Data Mining and Machine Learning, Natural Language and Speech
- Keywords
- Machine learning algorithms, Social media, Big data, Arabic Fake News Dataset, Deep learning
- Copyright
- © 2025 Alkudah et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Fake news detection in Arabic media: comparative analysis of machine learning and deep learning algorithms using the Arabic Fake News Dataset. PeerJ Computer Science 11:e3272 https://doi.org/10.7717/peerj-cs.3272
Abstract
Staying up-to-date on news through social media has both advantages and disadvantages. Social media platforms are excellent sources of information, but they also contribute significantly to the spread of fake news (incorrect or poor-quality content). The widespread circulation of such information can profoundly impact society by shaping public opinion, influencing policy debates, and affecting decision-making processes. As a result, fake news detection has become a critical area of research, particularly in multilingual and multicultural contexts. Detecting fake news in Arabic presents unique challenges due to the language’s complexity, diverse dialects, and the limited availability of comprehensive annotated datasets. Many existing detection models are vulnerable to misleading or context-heavy information because they rely primarily on basic content features. This study evaluates the effectiveness of various machine learning and deep learning techniques—including random forest (RF), naive Bayes (NB), feedforward neural networks (FNN), long short-term memory (LSTM), Arabic bidirectional encoder representations from Transformers (BERT), and a hybrid AraBERT + bidirectional long short-term memory (BiLSTM) model—in identifying fake news in Arabic media. Experiments were conducted using the Arabic Fake News Dataset (AFND), which contains over 606,000 news items labeled according to credibility. The hybrid AraBERT + Bi-LSTM model outperformed all others, achieving an average F1-score of 98.0%. This model integrates transformer-based contextual embeddings with sequential modeling.
Introduction
Social media platforms have rapidly evolved into dominant news distribution channels, offering instant access to information. However, this speed has made them fertile ground for fake news fabricated content designed to mislead, often indistinguishable from legitimate sources (Kümpel, Karnowski & Keyling, 2015; Allcott & Gentzkow, 2017). Unlike traditional media, where editorial standards and fact-checking practices limit misinformation, social media allows unverified claims to reach massive audiences within minutes (Newman, Dutton & Blank, 2013; Molina et al., 2021; Domenico et al., 2021; Al-Taie, 2025).
Fake news has especially negative effects during times of disaster, like elections or medical crises, when people are truly looking for accurate information. Lies expand more quickly than confirmed facts in these circumstances, increasing public confusion and undermining confidence (Bermes, 2021; Katona, 2024). To combat this, researchers have developed automated fake news detection systems using machine learning and deep learning techniques (Lazer et al., 2018; Jiang & Fang, 2019; D’Ulizia et al., 2021). These systems increasingly rely on features beyond the textual content, incorporating metadata, user interactions, and dissemination patterns (Bondielli & Marcelloni, 2019; Stewart, 2021).
It is more challenging to identify fake news in Arabic due to its rich morphology, dialectal diversity, and lack of benchmark datasets. While earlier approaches employed conventional machine learning algorithms such as random forest (RF) and naïve Bayes (NB) (Alrubaian et al., 2018; Alyoubi, Kalkatawi & Abukhodair, 2023), more recent research has moved towards transformer-based architectures and deep neural networks (Ruchansky, Seo & Liu, 2017; Antoun, Baly & Hajj, 2020; Fouad, Sabbeh & Medhat, 2022; Al-Taie, 2025). Despite these developments, there are still few thorough comparisons between various model types on standardized Arabic datasets (Habeeb et al., 2019).
In this study, we utilize the publicly available Arabic Fake News Dataset (AFND), introduced by Khalil et al. (2022), which comprises over 600,000 labeled news articles collected from 134 Arabic news agencies. The dataset categorizes articles as credible, non-credible, or undecided. This resource has recently become a benchmark for Arabic fake news detection research due to its scale and diversity. We employ AFND to compare the performance of six representative models under a unified experimental setup, ensuring consistent evaluation across classical machine learning, deep learning, and transformer-based architectures.
Contributions of the study
The AFND used in this study was publicly available dataset developed by Khalil et al. (2022) and published on platforms such as GitHub and Kaggle. This study builds upon that dataset to explore and benchmark the performance of various machine learning and deep learning models in Arabic fake news detection.
The key contributions of this article are as follows:
-
A systematic comparative analysis using four-fold cross-validation on the AFND dataset, the study compares six classification models (naive Bayes, random forest, feedforward neural network, long short-term memory (LSTM), fine-tuned Arabic bidirectional encoder representations from Transformers (BERT), and a hybrid AraBERT + bidirectional long short-term memory (BiLSTM) model) in a unified experimental setup.
-
In order to take advantage of both contextual semantic representation and sequential modelling capabilities, this work presents and assesses a novel hybrid deep learning model that combines AraBERT embeddings with a BiLSTM classifier. In terms of accuracy and F1-score, the hybrid model performed better than baseline models.
-
The experimental design provides insights into how traditional and deep learning models behave when applied to large-scale, real-world Arabic news data by taking algorithmic diversity and dataset scale into account.
These contributions aim to bridge existing gaps in Arabic fake news detection research by combining modern embeddings, traditional machine learning, and linguistic insights in a reproducible evaluation framework.
Related works
Arabic fake news detection has changed dramatically in recent years, with researchers investigating both conventional and innovative deep learning techniques. More advanced architectures using contextualized embeddings and hybrid models have taken the place of rules-based and naive machine learning approaches in the field.
Traditional machine learning techniques
Traditional machine learning techniques. Early Arabic fake news detection studies relied heavily on classical machine learning classifiers such as NB, RF, and support vector machines (SVM). For instance, Alrubaian et al. (2018) utilized Term Frequency-Inverse Document Frequency (TD-IDF) features with NB and RF on Arabic tweets and achieved around 87% accuracy. Alyoubi, Kalkatawi & Abukhodair (2023) extracted emotional and syntactic features to classify Hajj-related rumors, attaining 79% accuracy using SVM and NB. These methods are computationally efficient and interpretable but often suffer from limitations in handling semantic and dialectal variation common in Arabic texts.
Deep learning architectures
Deep learning architectures. Deep learning models demonstrated significant performance improvements due to their ability to capture sequential and semantic information (Tian et al., 2018; Shaheen, Lohana & Ramzan, 2025). Fouad, Sabbeh & Medhat (2022) proposed a convolutional neural network (CNN)–BiLSTM model for Arabic rumor detection, achieving ~90% F1-score. Similarly, Wotaifi & Dhannoon (2023) combined convolutional neural network (CNN) and LSTM in an ensemble that reached 97.2% accuracy on a large Arabic news dataset. Veningston, Rao & Ronalda (2023) fine-tuned AraBERT with CNN layers, yielding around 80% accuracy on ANS and COVID-19 misinformation corpora. These architectures mitigate issues related to feature engineering but may still lack contextual sensitivity in complex narratives. Alsukhni (2021) used the multilayer perceptron (MLP) algorithm. She employed an RNN with a long short-term memory (LSTM) model in the post-evaluation phase. When it came to accuracy, the LSTM model outperformed the MLP model. In particular, the accuracy of the MLP model was 80.37%, whereas the accuracy of the LSTM model was 82.03%.
Transformer-based and hybrid models
Transformer-Based and Hybrid Models Transformer-based models like AraBERT, MARBERT, and QARiB have achieved state-of-the-art results in Arabic NLP. Antoun, Baly & Hajj (2020) showed that AraBERT fine-tuned for misinformation detection reached over 95% accuracy. MARBERT and QARiB, trained on dialect-rich datasets, showed improvements in classification tasks involving social media Arabic (Touahri, 2023). Nassif et al. (2022) evaluated the performance of eight recently developed Arabic contextualized embedding models, many of which had not been previously used for Arabic fake news detection: GigaBert-base, RobertaBase, Arabert, Arabic-Bert, ArBert, MARBert, Araelectra, and QaribBert-base. The performance evaluation revealed that RobertaBase had the lowest accuracy across both datasets, while ARBERT and Arabic-Bert performed the best with accuracies of 98.8% and 98%.
Hybrid models combining these transformers with sequential architectures have also been proposed. Çetiner (2024) introduced a BiGRU-enhanced Transformer using Bayesian optimization, achieving 86.4% accuracy. A hybrid of AraBERT and BiLSTM was presented in a more recent study by Al-Taie (2025), which achieved 98.4% accuracy on the AFND and Ara-FakeTweets datasets. By utilizing temporal modelling from recurrent networks and contextual embeddings from transformers, these hybrid systems increase their resilience to informal or dialectal text.
Use of AFND dataset in recent studies
The AFND by Khalil et al. (2022) is among the most comprehensive corpora for Arabic misinformation detection, containing over 600,000 articles from 134 sources, annotated as real or fake. Many researcher like Liu & Wu (2020), Khalil et al. (2022), Al-Taie (2025) are employed AFND in their recent comparative experiments, showing its utility in benchmarking Arabic-specific detection models.
Our study further extends these findings by applying AFND to compare six models: naïve Bayes, random forest, feedforward neural network, LSTM, AraBERT, and AraBERT + BiLSTM. By using the same dataset across all experiments, we ensure a consistent and reproducible evaluation setup.
Summary and motivation
There are still a number of gaps in the literature despite the advancements in Arabic fake news detection:
Many studies have focused exclusively on either classical machine learning models or transformer-based architectures, without leveraging their complementary strengths.
Few works conduct comprehensive evaluations using large-scale, richly annotated datasets such as AFND, limiting insights into model generalizability.
Most existing approaches either focus on raw textual features or semantic embeddings, while neglecting valuable linguistic indicators such as part-of-speech (POS) tags and emotional signals.
Building on a thorough analysis of recent state-of-the-art models and their performance trends, this study selects and compares a range of traditional and deep learning methods, including a novel hybrid model combining AraBERT and BiLSTM. This hybrid model incorporates Arabic-specific preprocessing, contextual embeddings, and sequential learning, aiming to achieve high detection accuracy while addressing the linguistic complexity of Arabic fake news content.
Research objective
Credibility of information has become more challenging in the age of technology due to the growth of fake news, particularly during times when there is political disturbances. Machine learning-powered automated techniques offer a dependable and adaptable alternative to manual detection, which frequently fails due to cognitive biases and information overload. This study aims to explore and compare the effectiveness of multiple machine learning and deep learning techniques in detecting fake news in Arabic text, using a large-scale dataset. The specific research objectives are as follows:
- (1)
To compare the effectiveness of more sophisticated models (like LSTM, AraBERT, and AraBERT + BiLSTM) and more conventional classifiers (like NB and RF) for identifying Arabic fake news.
- (2)
To suggest a hybrid model (AraBERT + BiLSTM) that combines contextualised word embeddings with sequential learning and assess how well it improves classification accuracy.
- (3)
To provide a systematic comparison of different model architectures and their ability to generalize across Arabic text from various topics and sources.
Background
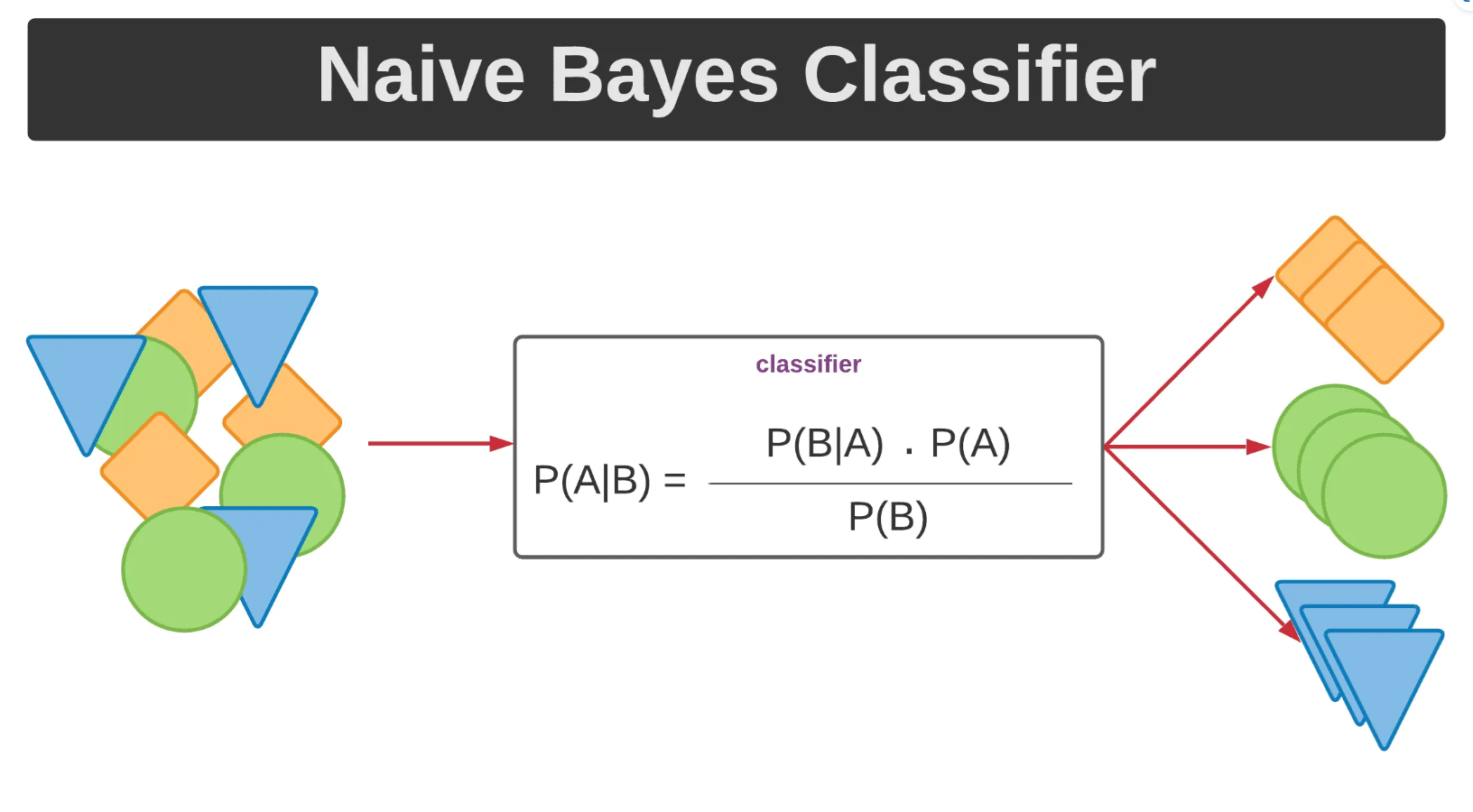
Naive Bayes
Naive Bayes classifiers are a family of simple yet effective probabilistic classifiers widely used in statistics and machine learning. These supervised algorithms rely on Bayes’ Theorem, assuming a strong (naive) independence between features an assumption that rarely holds in practice, yet the models still perform well across various domains (Reddy et al., 2022). Naive Bayes is one of the simplest forms of Bayesian networks, making decisions by selecting the class with the highest posterior probability based on observed features.
The naive Bayes model uses a feature vector x = { , , …, } to classify news articles by estimating the posterior probability of a class . Equation (1) defines this as:
(1) where:
Ck = the class (e.g., Fake or Real)
Xi = the feature (e.g., a word)
n = number of features (words) in the input
= prior probability of class
= likelihood of feature given class
= evidence (can be ignored in argmax).
The classification decision is made using the maximum a posteriori (MAP) estimate as Eq. (2):
(2) Naive Bayes is renowned for its competitive accuracy and high efficiency, especially in text-classification tasks, despite its simplicity. A few modifications, like Gaussian naïve Bayes, estimate probabilities using continuous distributions, such as the Gaussian probability density function (Alghamdi, Luo & Lin, 2024; Sarker, 2021).
Feedforward neural network
One type of artificial neural network in which node-to-node connections do not form cycles is called a feedforward neural network (FNN). Each layer’s output is passed directly to the next layer without any feedback loops. As illustrated in Fig. 1, the model comprises an input layer (in our case: text embeddings such as TF-IDF or BERT), one or more hidden layers, and an output layer (which predicts the class: Fake or Real).
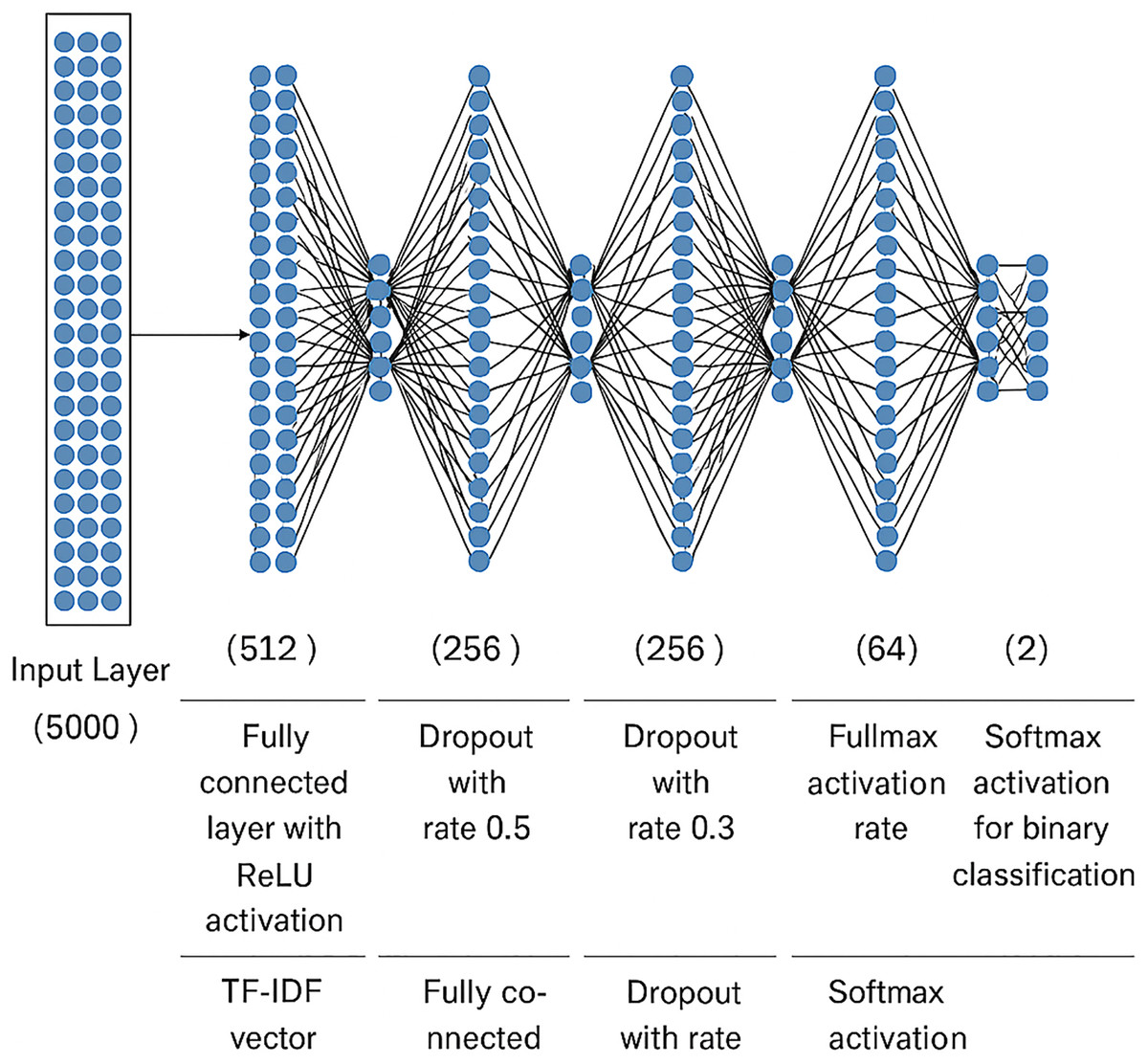
Figure 1: Architecture of the feedforward neural network used in this study for Arabic fake news classification.
{kind=link}
Weighted sums of inputs are calculated and then passed through activation functions to power FNNs. A neuron becomes active and adds to the output of the following layer when its output surpasses an established threshold. This architecture allows the network to learn non-linear relationships between features and output classes. Although simpler than recurrent models like LSTM, FNNs are computationally efficient and perform well in baseline text classification tasks, especially when combined with informative features like pre-trained embeddings (Thakur & Konde, 2021; Khan et al., 2021; Shaheen, Lohana & Ramzan, 2025).
Random forest
The random forest classifier is a powerful ensemble learning method used for classification tasks, building multiple decision trees to improve accuracy and reduce overfitting (Alghamdi, Luo & Lin, 2024; Saeed & Solami, 2023). Unlike standard decision trees that consider all feature splits, random forests use both bagging and feature randomness (or feature bagging) to create diverse, uncorrelated trees, thus enhancing robustness, see Fig. 2. By averaging the results from each tree, random forests produce more accurate and reliable predictions (Khan et al., 2021).
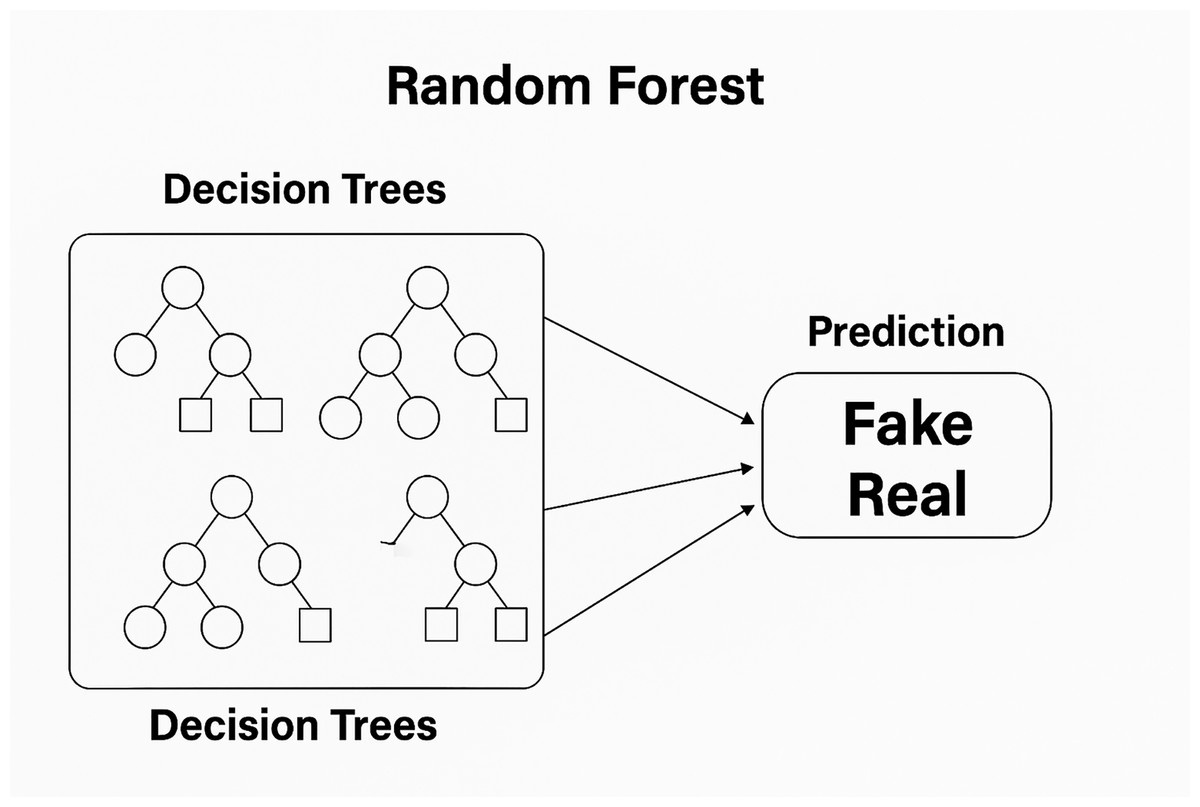
Figure 2: Random forest algorithm.
{kind=link}
Long short-term memory
RNNs is the kind known as LSTM, it has been designed to record dependence on long-term and model data that is sequential. LSTMs are appropriate for text classification tasks like recognizing fake news because, compared to traditional neural networks, they keep internal memory cells and gating mechanisms that enable them to learn context over time (Yang & Wang, 2020; Wotaifi & Dhannoon, 2023). They are especially at recognizing hidden indications of false information because of their capacity to remember important patterns of speech over extended periods of time. LSTM-based models have been widely used in natural language processing (NLP) applications, typically exceeding traditional algorithms in jobs requesting awareness of context. Particularly for languages like Arabic where word order and morphology are crucial, LSTMs give a more complicated representation of textual input than basic feedforward networks. By maintaining semantic meaning across different sentence structures, LSTMs can improve classification accuracy when paired with pre-trained word embeddings (Fouad, Sabbeh & Medhat, 2022).
AraBERT
AraBERT is a pre-trained transformer-based language model designed specifically for Arabic, based on the BERT architecture. AraBERT was created by the American University of Beirut’s Arabic natural language processing team (AUBMindLab) and is well-suited for a variety of Arabic NLP tasks because it has been trained on a sizable corpus of Arabic text, such as news articles, Wikipedia, and the OSCAR corpus (Antoun, Baly & Hajj, 2020). AraBERT uses self-attention mechanisms to comprehend the contextual relationships between words across entire sentences, in contrast to LSTM-based models that process text sequentially and traditional machine learning models that frequently rely on low-level features (Antoun, Baly & Hajj, 2020). This feature is especially in the detection of fake news, where linguistic details and nuance are crucial. AraBERT has done quite well on a lot of Arabic NLP tests, including text classification, identified entity recognition, and sentiment analysis. It does better than generic models on Arabic-language datasets because it has a thorough awareness of context and has been trained in Arabic. In this study, we fine-tuned the ‘aubmindlab/bert-base-arabertv2’ variant on the AFND dataset to assess its effectiveness in distinguishing credible from non-credible news articles.
Hybrid model: AraBERT + BiLSTM
To address the linguistic diversity and dialectal complexity inherent in Arabic social media and online news, we implemented a hybrid model combining AraBERT with a BiLSTM layer. This method is intended to deal with one of the issues in Arabic NLP: finding out exactly how to understand dialects like Levantine, Gulf, and Maghrebi Arabic, which employ different terminology, structures, and ways of speaking than Modern Standard Arabic (MSA). AraBERT uses a large collection of Arabic text to create rich, contextualized embeddings that include both semantic and grammatical information. However, while transformer models excel at global context modeling, they may not fully capture the sequential and temporal dependencies critical in distinguishing nuanced or deceptive text. To complement this, we integrated BiLSTM—a sequential model that processes data in both forward and backward directions—to enhance temporal sensitivity.
The hybrid architecture allows the model to benefit from:
Contextual richness from AraBERT, which is trained on diverse Arabic corpora including dialectal content.
Sequential awareness from BiLSTM, which improves detection of deceptive linguistic patterns and stylistic anomalies often found in fake news narratives.
This design not only improves classification performance but also offers a more dialect-aware mechanism, making it more robust in handling informal Arabic content common on social platforms. The proposed model is particularly effective in scenarios where text contains mixed formal and informal expressions, thereby addressing the reviewer concerns about dialect generalization and lack of architectural novelty.
Dataset
In this article, we utilize the Arabic Fake News Dataset (AFND) by Khalil et al. (2022). It is a large dataset made to help find fake news in Arabic. The AFND is made up of 606,912 news stories from 134 Arabic news websites. The whole dataset is about 442 MB in size. Each item has a label that tells the difference between credible and questionable news sources. This makes for a more complex dataset for training and testing machine learning algorithms. This dataset has metadata that gives more information, like the article’s source, publication date, and categorisation into certain subjects. This lets you look more closely at the linguistic and contextual patterns that are unique to detecting fake news in Arabic.
Table 1 presents the AFND statistics.
| Dataset satistics | Count |
|---|---|
| Total number of articles | 606,912 |
| Credible articles | 207,310 |
| Not credible articles | 167,233 |
| Undecided articles | 232,369 |
| Number of news websites | 134 from 19 different countries |
| Time collected | From 1/2/2021 to 30/6/2021 |
Evaluation
Evaluation metrics
To assess the models, we report training and validation accuracy for each data partition. Accuracy, precision, recall, and F1-score are the main ways this study measured performance. These metrics based on well-known mathematical ideas shown in Eqs. (3)–(6), show how well the model works in every way.
(3)
(4)
(5)
(6)
Methodology
The AFND is a big, specialised dataset for finding false news in Arabic. It has 606,912 items from 134 Arabic news websites in 19 countries. There is information about each article, such when it was published, where it originated from, and what it was about. There is also a notation on each tale that says if it is believable, not credible, or undecided. The dataset, which was gathered over six months, also includes information on language, such the average length of titles and bodies. This makes it a complete resource for teaching machine learning models how to find fake news in Arabic. The following features are found in each article in the dataset:
News title
Full article text
Source credibility label (credible, not credible, or undecided)
Source country
Publication date
Average word count per article
Average word count per title
News topic
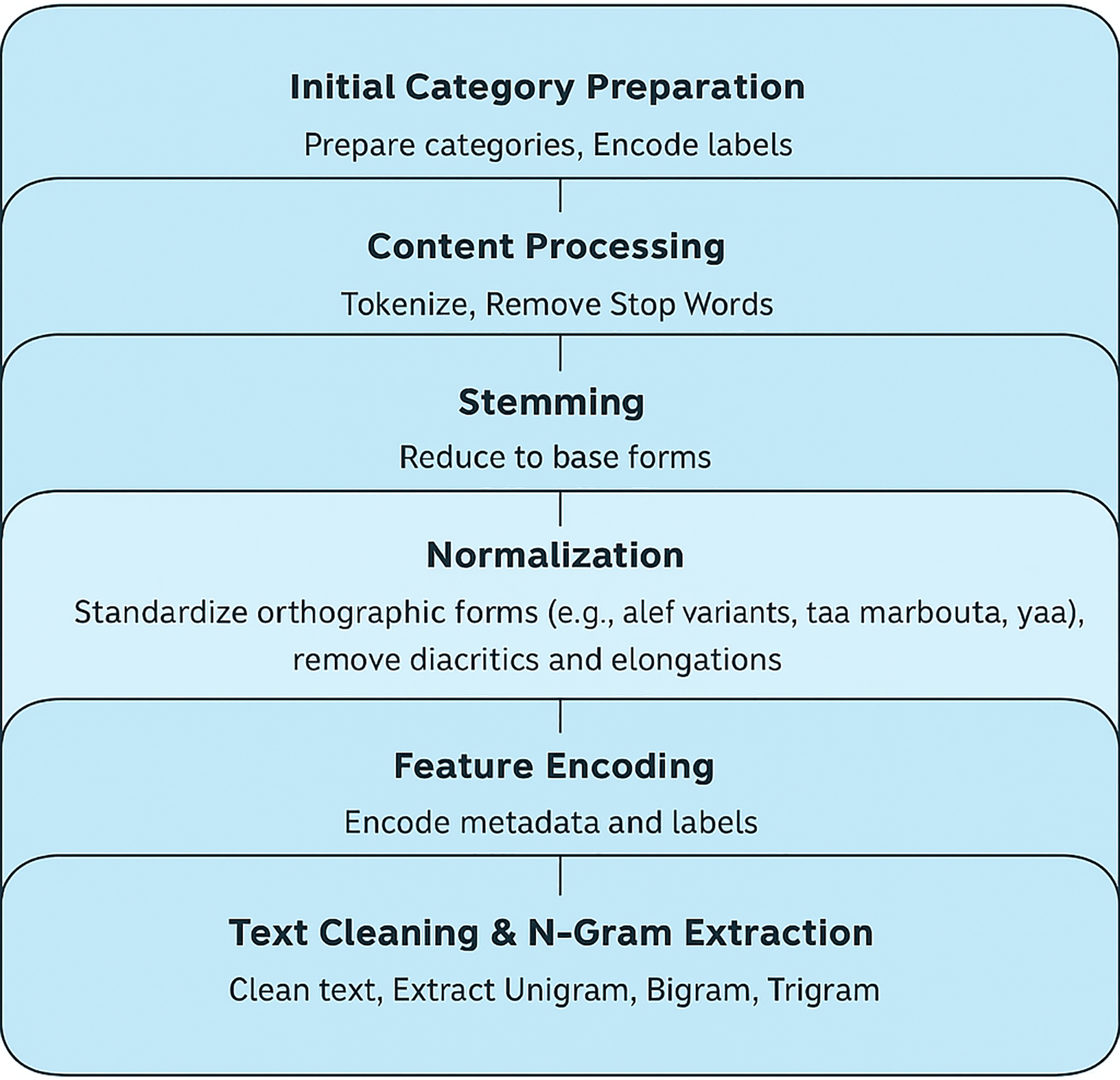
Data preprocessing
For our dataset, we categorized features into numerical and categorical groups to streamline the data preparation process for Arabic fake news detection.
Numerical features: We identified and included any available count-based features within the dataset. For this process, numerical features like frequency counts in text or numerical indicators of credibility could be useful. These features don’t need any pre-processing because they give straight quantitative information about the believability indicators of each news part.
Categorical features: The primary categorical features identified in our dataset included news source credibility labels (credible, not credible, undecided), source country, publication date, and news topic. We used encoding to turn categories into numbers for each characteristic. For example, the credibility label was changed to numbers: 0 for credible, 1 for not credible, and 2 for undecided. The model also got a unique value for each country and topic group to make it easier for it to work.
After preparing the initial categories, we turned our focus to the news content itself:
Tokenization: We segmented each news article’s text into individual words to analyze word usage patterns. This allowed us to work with distinct words separately, which is valuable for identifying specific patterns associated with fake news.
Stop word removal: Common Arabic stop words were removed to enhance classification accuracy, as these words generally contribute little to distinguishing fake from credible news.
Stemming: Using Arabic stemming techniques, we reduced words to their base forms to standardize the vocabulary. While stemming may not be perfect for all words, our primary goal was to convert the content into simplified forms that retain essential meaning.
Normalization: it’s a methods were used to lower the amount of spelling and morphological variance in Arabic text as part of the preprocessing procedure. This included standardizing different forms of alef (e.g., converting “أ“, ”إ”, and “آ” to “ا”), replacing “
 ” with “
” with “ ”, and “
”, and “ ” with “
” with “ ” when contextually appropriate. Additionally, diacritics and elongation characters (tatweel) were removed to minimize noise and ensure uniform tokenization. These normalisation stages are necessary to deal with the natural complexity and richness of Arabic morphology. They make textual input more consistent and make downstream classification models work better.
” when contextually appropriate. Additionally, diacritics and elongation characters (tatweel) were removed to minimize noise and ensure uniform tokenization. These normalisation stages are necessary to deal with the natural complexity and richness of Arabic morphology. They make textual input more consistent and make downstream classification models work better.Encoding unique features: Labels for credibility, country, and topic were encoded into unique numeric values, ensuring each category was properly represented. Additional metadata such as source and publication date were also numerically encoded where applicable.
Text cleaning and N-gram feature extraction: We refined the text data by removing punctuation, hyperlinks, repeated characters, and special symbols from the news content. After this cleaning process, we implemented unigram, bigram, and trigram feature extraction to capture varying levels of word associations. Trigrams, in particular, provided significant insights for distinguishing fake news patterns as shown in Fig. 3.
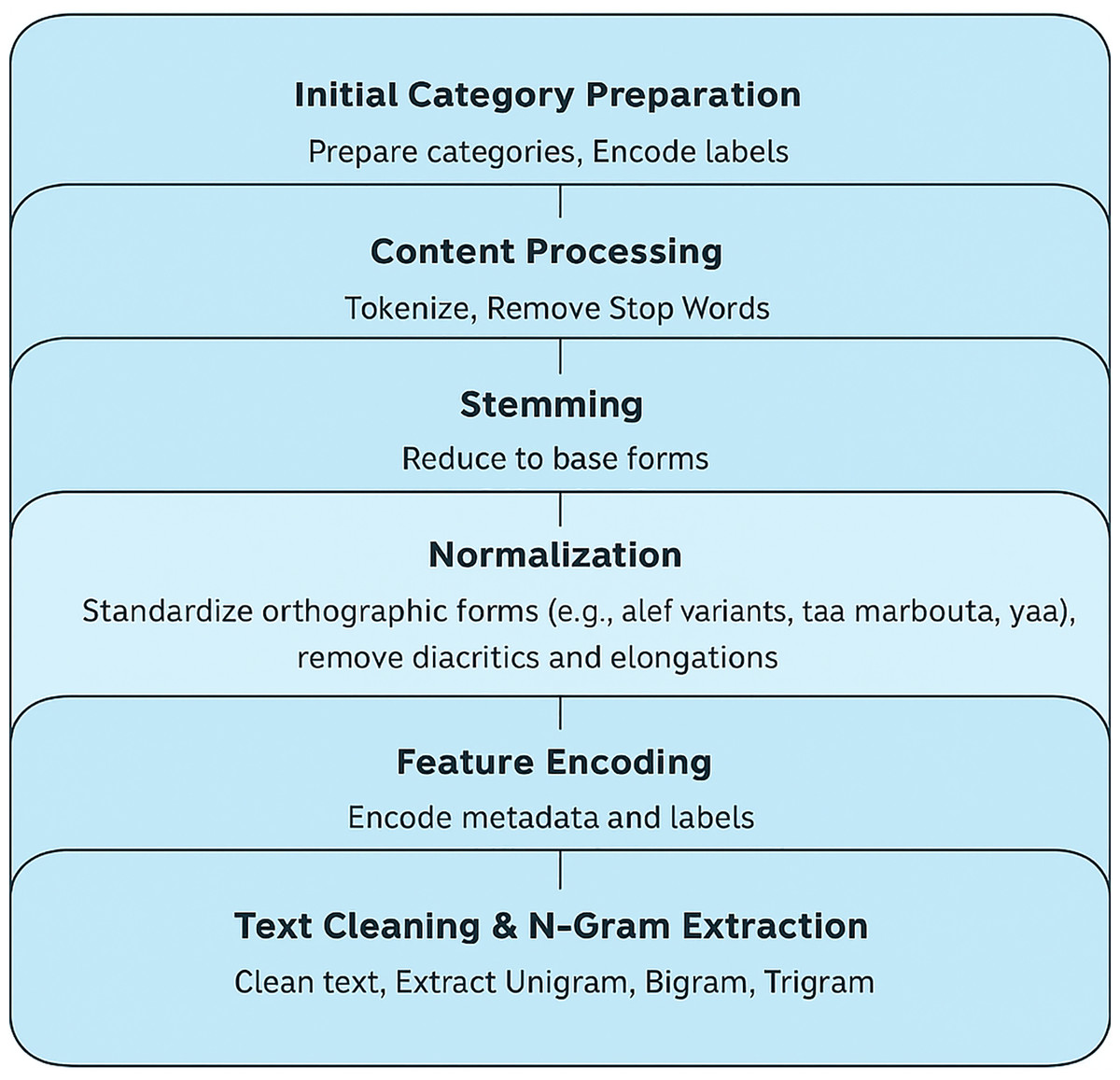
Figure 3: Data preprocessing workflow for Arabic Fake News Detection.
{kind=link}
Data representation strategy
Unlike the general overview provided in the Background section, the following sections (‘Data Representation Strategy’ to ‘Model Selection Justification’) detail exactly how each model was implemented and applied to the AFND dataset for the Arabic fake news detection task. This includes input representation, model configuration, classification layers, and training procedures. We made sure that each model was evaluated fairly and consistently across different architectures by giving them input representations that were specific to their computational paradigm:
Traditional machine learning models (naive Bayes, random forest): We used standard tokenization to preprocess the textual inputs and then turned them into sparse feature vectors using n-gram techniques (unigrams, bigrams, and trigrams). The TF-IDF weighting system was used to make these vectors. This method is popular in text categorisation since it is easy to use and does a good job of showing how important a term is and how often it appears.
Feedforward neural network (FNN): The same TF-IDF-based n-gram vectors were employed, but converted into dense matrix format, allowing the neural network to learn from global term distributions via fully connected layers. This representation is common in prior studies employing shallow networks for text-based tasks.
Sequential models (LSTM): Input texts were tokenized and transformed into fixed-size dense embeddings, and sequences were padded to a uniform length. This approach enabled the LSTM to model temporal dependencies and syntactic flow, following best practices in natural language modeling with RNN-based architectures.
Transformer-based model (AraBERT): Inputs were processed using WordPiece tokenization, generating token IDs, attention masks, and segment IDs. The final hidden state corresponding to the [CLS] token was extracted to represent the entire input text. This is a widely adopted representation strategy in BERT-based classification tasks.
Hybrid model (AraBERT + BiLSTM): AraBERT embeddings were passed to a bidirectional LSTM layer, allowing the model to further capture bidirectional sequential context. This hybridization has been shown in multiple studies to enhance performance by combining contextual richness of Transformers with temporal modeling of LSTM.
This structured representation pipeline ensured that each model operated on feature formats best aligned with its design philosophy, thereby facilitating a balanced and methodologically sound performance comparison.
Feedforward neural network architecture
To implement the FNN model for fake news classification, a multi-layer dense architecture was adopted following common practices in recent fake news detection literature. The model takes in high-dimensional feature vectors like TF-IDF representations and processes them through a series of fully connected layers that use ReLU activations and dropout regularisation. This design helps the network learn hierarchical representations and stops it from overfitting. The last output layer’s Softmax function makes a probability distribution over the two binary classes, which are Fake and Real. Table 2 gives a summary of the model’s detailed design. The number of layers and their respective configurations were inspired by design patterns commonly adopted in related studies on fake news detection and text classification, aiming to balance model complexity and generalization capability.
| Layer type | Output shape | Parameters | Description |
|---|---|---|---|
| Input layer | (5,000) | 0 | TF-IDF vector with 5,000 features |
| Dense | (512) | 2,560,512 | Fully connected layer with ReLU activation |
| Dropout | (512) | 0 | Dropout with rate 0.5 |
| Dense | (256) | 131,328 | Fully connected layer with ReLU activation |
| Dropout | (256) | 0 | Dropout with rate 0.3 |
| Dense | (64) | 16,448 | Fully connected layer with ReLU activation |
| Output layer | (2) | 130 | Softmax activation for binary classification |
Cross validation and overfitting
Overfitting presents a key challenge in fake news detection models, as it leads to excellent performance on training data but poor results on new, unseen data. To avoid this, we used cross-validation, which assesses the model’s capacity to generalise by using data that wasn’t used in training. This method shows how well the model works on examples it hasn’t seen before and points out possible generalisation mistakes. In our experiments with the AFND, we utilized k-fold cross-validation, a widely-used method, to ensure the model does not overfit and can reliably detect patterns across diverse Arabic news articles.
LSTM model architecture
To extend the analysis and address the complexity of fake news detection, we implemented an additional deep learning model using a LSTM architecture. The model consists of the following layers:
Embedding layer using pre-trained word vectors (Word2Vec or global vectors (GloVe) embeddings adapted for Arabic).
A single LSTM layer with 128 units and dropout regularization.
A dense layer with a sigmoid activation for binary classification.
The model was trained using the binary cross-entropy loss function and the Adam optimizer. The same preprocessed AFND dataset was used, with padded sequences to ensure uniform input lengths. The model was trained over 10 epochs with early stopping applied to prevent overfitting.
Hybrid model: AraBERT + BiLSTM
We built a hybrid architecture that combines AraBERT, a pre-trained transformer model for Arabic, with a BiLSTM layer to increase the model’s capacity to find fake information in Arabic by making it more sensitive to context. This combination aims to leverage the strengths of both transformer-based contextual embeddings and recurrent neural networks’ sequence modeling capabilities.
This hybrid design is motivated not only by the pursuit of higher accuracy but also by the need to address dialectal variation across Arabic news sources a limitation highlighted in prior studies. AraBERT was mostly trained on MSA, but it has also read a lot of different types of material, including dialectal and informal content from social media. When you combine AraBERT with BiLSTM, the model gets stronger at picking up on tiny changes in regional expressions and sequential dependencies. This helps it work better across dialects including Levantine, Gulf, and North African Arabic.
The first step is to tokenize and encode the Arabic text using AraBERT (aubmindlab/bert-base-arabertv2), which captures rich semantic and syntactic properties in different situations. We extract the (CLS) token representation from AraBERT’s final hidden layer to serve as a comprehensive sentence-level embedding. These embeddings are then passed to a BiLSTM layer, which processes the information bidirectionally capturing dependencies from both past and future word sequences allowing the model to better detect deceptive language patterns and stylistic inconsistencies often found in fake news content.
The output of the BiLSTM layer is subsequently fed into fully connected dense layers with dropout for regularization, followed by a final softmax layer for binary classification (fake or real). The model is trained using the Adam optimizer, with categorical cross-entropy loss, and employs early stopping and learning rate scheduling to prevent overfitting and optimize convergence. This hybrid approach combines the rich, contextualized embeddings of AraBERT with the temporal sensitivity of BiLSTM, offering a robust solution particularly well-suited to the complexity of Arabic morphology, dialectal variation, and narrative structures found in social media-based news content.
Model selection justification
We chose a wide range of machine learning and deep learning models to make sure that the evaluation was thorough and fair. NB and RF are two conventional, rapid, and easy-to-understand ways to classify text. The FNN and LSTM models reflect foundational deep learning architectures, capable of learning from structured and sequential data, respectively. Furthermore, AraBERT, a transformer-based pre-trained model for Arabic, and the proposed hybrid model AraBERT + BiLSTM represent state-of-the-art approaches that combine contextual embeddings with sequential learning. We chose these methods to reflect a comprehensive spectrum of traditional, deep learning, and Transformer-based approaches, providing a fair comparative baseline.
Experimental result
Training and testing
Training and Testing In this study, we utilized the publicly available Arabic Fake News Dataset (AFND), which contains over 600,000 news articles annotated as credible, non-credible, or undecided. To ensure a reliable evaluation of model performance and minimize overfitting, we used 4-fold cross-validation to evaluate model performance. The data was split into 75% for training and 25% for testing in each iteration. This made sure that the evaluation was fair and uniform across all folds. This was done four times, with each fold using a different quarter of the dataset as the test set. Tables 3 to 6 present the results of each fold respectively. Each table contains the classification performance metrics accuracy, precision, recall, and F1-score obtained during the evaluation of the corresponding fold using the same 75%, 25% train-test division. The average performance across all folds is later summarized to highlight model consistency.
| Evaluation measures | RF | NB | FNN | LSTM | AraBERT | AraBERT + BiLSTM |
|---|---|---|---|---|---|---|
| Accuracy | 0.88 | 0.96 | 0.95 | 0.95 | 0.97 | 0.98 |
| Precision | 0.87 | 0.95 | 0.94 | 0.95 | 0.97 | 0.98 |
| Recall | 0.88 | 0.96 | 0.94 | 0.94 | 0.96 | 0.98 |
| F1-score | 0.87 | 0.96 | 0.94 | 0.94 | 0.97 | 0.97 |
| Evaluation measures | RF | NB | FNN | LSTM | AraBERT | AraBERT + BiLSTM |
|---|---|---|---|---|---|---|
| Accuracy | 0.89 | 0.97 | 0.95 | 0.93 | 0.98 | 0.96 |
| Precision | 0.90 | 0.96 | 0.96 | 0.96 | 0.97 | 0.97 |
| Recall | 0.87 | 0.98 | 0.95 | 0.95 | 0.97 | 0.98 |
| F1-score | 0.88 | 0.97 | 0.94 | 0.96 | 0.98 | 0.99 |
| Evaluation measures | RF | NB | FNN | LSTM | AraBERT | AraBERT + BiLSTM |
|---|---|---|---|---|---|---|
| Accuracy | 0.90 | 0.95 | 0.96 | 0.94 | 0.97 | 0.97 |
| Precision | 0.88 | 0.94 | 0.95 | 0.95 | 0.97 | 0.98 |
| Recall | 0.88 | 0.95 | 0.95 | 0.96 | 0.96 | 0.97 |
| F1-score | 0.89 | 0.95 | 0.94 | 0.94 | 0.97 | 0.98 |
| Evaluation measures | RF | NB | FNN | LSTM | AraBERT | AraBERT + BiLSTM |
|---|---|---|---|---|---|---|
| Accuracy | 0.90 | 0.95 | 0.94 | 0.94 | 0.96 | 0.99 |
| Precision | 0.89 | 0.96 | 0.96 | 0.96 | 0.95 | 0.97 |
| Recall | 0.89 | 0.95 | 0.95 | 0.95 | 0.97 | 0.98 |
| F1-score | 0.88 | 0.95 | 0.95 | 0.93 | 0.96 | 0.98 |
Before training, all data instances were shuffled using a fixed random state (42) to maintain consistency across experiments. We implemented the models using Python, leveraging scikit-learn and Keras libraries. The following six classification models were evaluated in this study:
Naïve Bayes (NB)
Random forest (RF)
Feedforward neural network (FNN)
Long short-term memory (LSTM)
AraBERT (fine-tuned)
Hybrid AraBERT + BiLSTM model
Each model was trained and tuned using the training portion of each fold. Where applicable, a further split of 70/30 was applied on the training data for hyperparameter tuning and validation.
This four-fold arrangement strikes a good compromise between fast calculations and accurate performance estimates, especially since the dataset is so big and has so many dimensions.
Result
To assess the classification performance of each machine learning algorithm, we employed standard evaluation metrics Accuracy, Precision, Recall, and F1-score to ensure a comprehensive evaluation of model effectiveness. The results are visually summarized in Figs. 4 and 5 highlighting the comparative performance across all models.
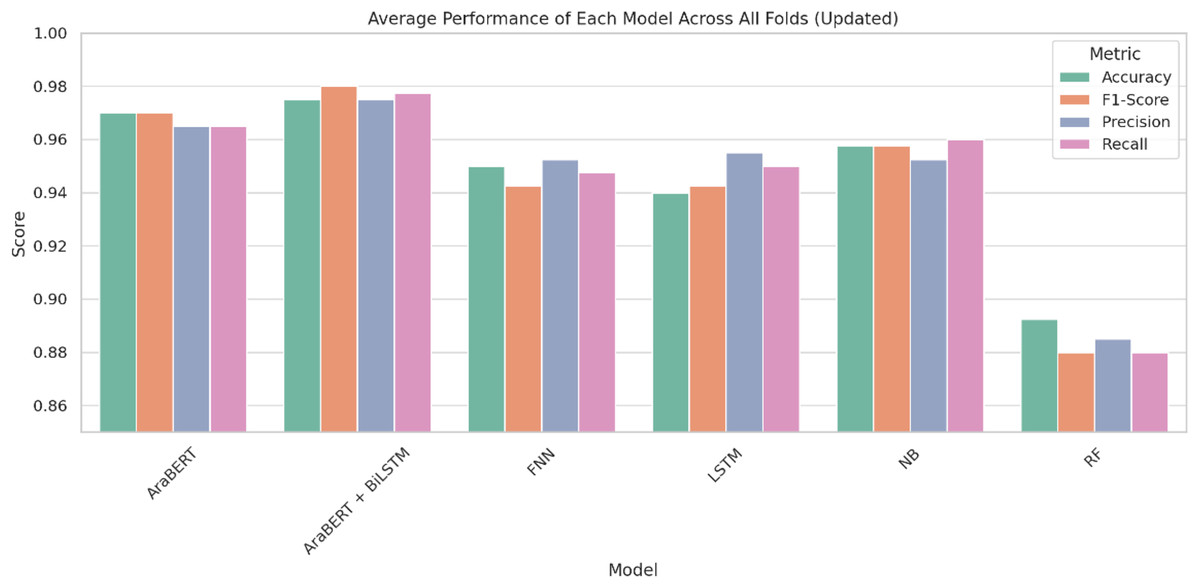
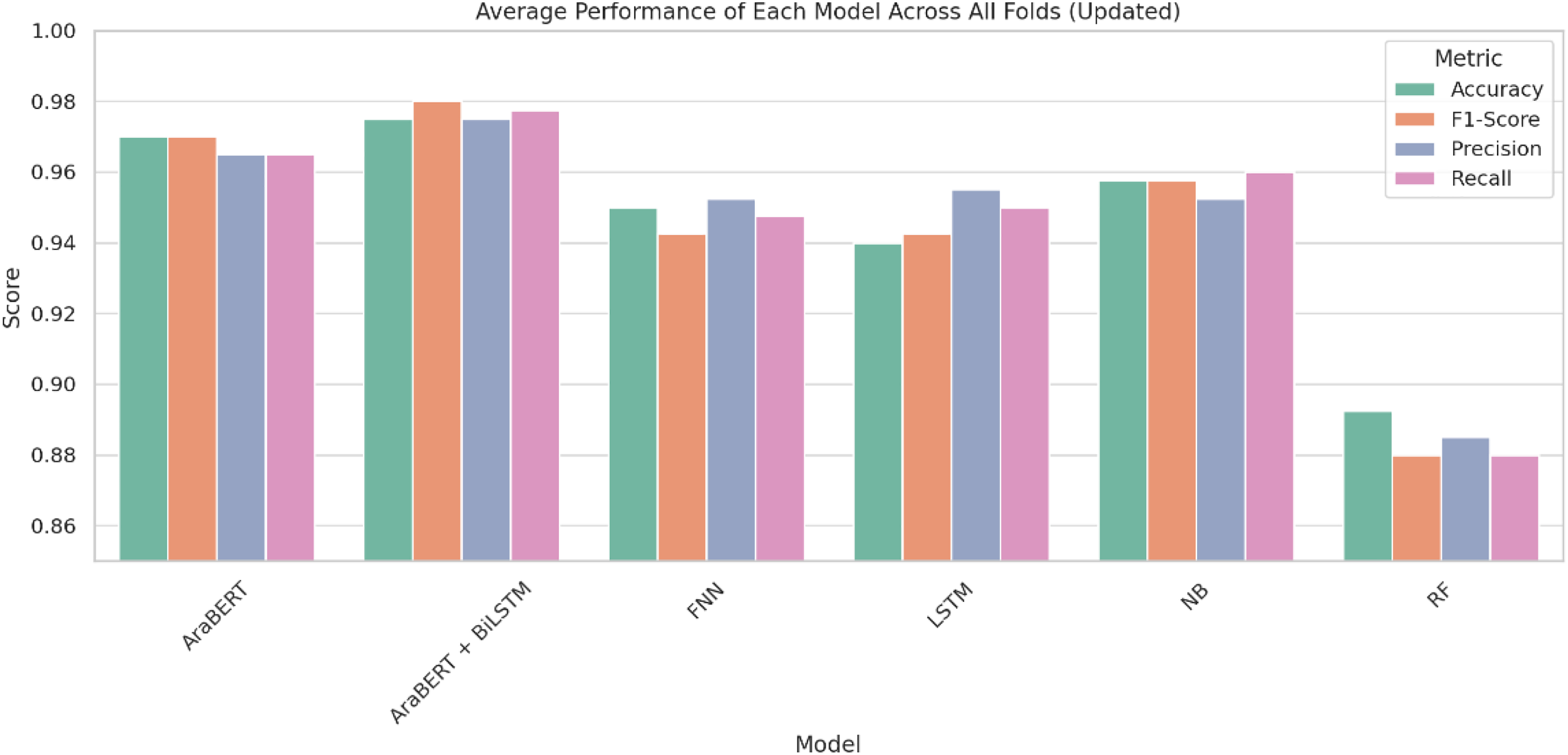
Figure 4: Average performance of each model across all folds.
{kind=link}
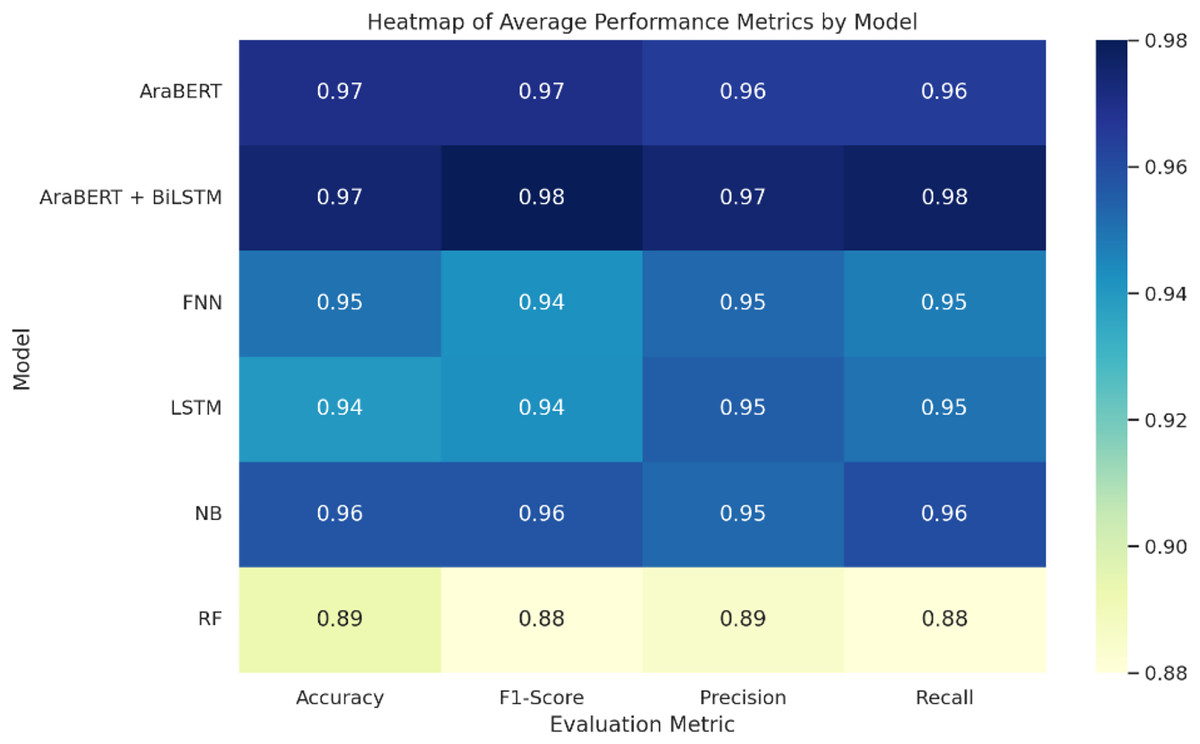
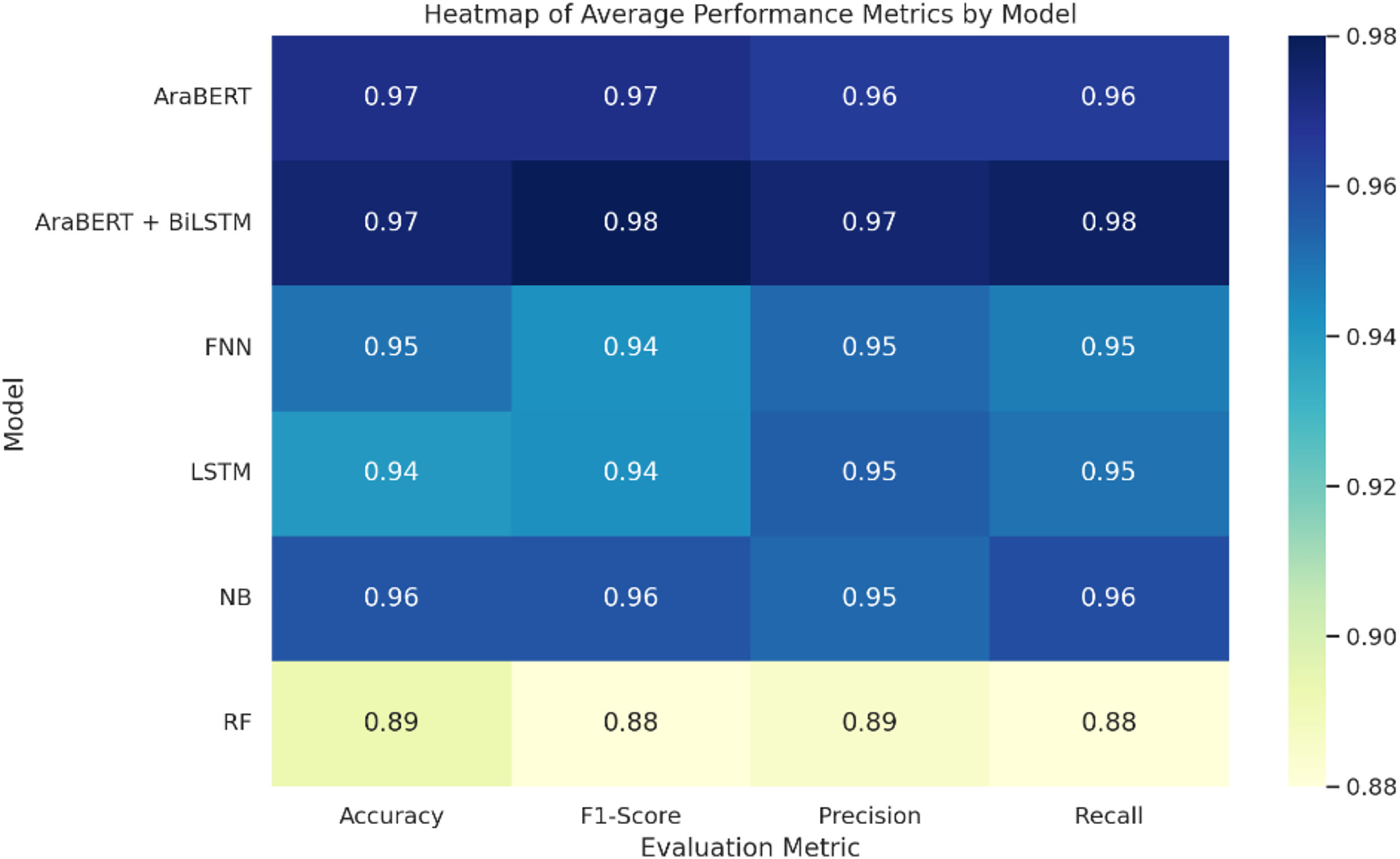
Figure 5: Heatmap of model performance across all folds.
{kind=link}
The AraBERT + BiLSTM hybrid model had the best overall performance, with an average accuracy of 97.5%, precision of 97.5%, recall of 97.8%, and an F1-score of 98.0% across the four folds. This shows that the model can use both deep semantic knowledge and sequential dependencies to find fake news in an effective manner.
The standalone AraBERT model also performed strongly, achieving 97.0% accuracy and a balanced performance across all metrics. Meanwhile, the traditional naive Bayes (NB) classifier showed competitive results with 95.8% accuracy and 95.8% F1-score, outperforming more complex models in some folds.
The FNN and LSTM models both reached 95.0% and 94.0% accuracy, respectively, with similar F1-scores (94.2%), though the LSTM showed slightly better sequential handling. The Random Forest (RF) classifier yielded the lowest results, with an average accuracy of 89.3% and an F1-score of 88.0%, reflecting its limitations with high-dimensional and morphologically rich Arabic text.
All models were evaluated using four-fold cross-validation, and the performance remained consistent across all folds (see Tables 3–6). No significant overfitting was observed, supporting the generalization strength of the models on diverse Arabic-language news content.
Limitations and threats to validity
The results of all the models tested reveal that they are likely to be accurate and consistent, but there are several possible risks to their validity that should be noted. First, the AFND dataset is balanced and has been examined manually, although it may not fully show the range of false news types that can be found in different Arabic dialects and media settings. Second, the lack of user engagement metadata limits the ability of models to leverage behavioral indicators. Finally, although AraBERT + BiLSTM improves dialectal handling, rare dialects remain underrepresented in training data, which may affect the model’s generalizability to unseen regional variations. To make future research more reliable and applicable to other situations, they should use larger, more varied datasets and multimodal signals. and look into adding user interaction features like retweet counts, likes, and source reliability info to improve detection capabilities.
Discussion
We looked at random forest, naive Bayes, FNN, LSTM, AraBERT, and the hybrid model AraBERT + BiLSTM. They all have distinct advantages and disadvantages when it comes to discovering fake news in Arabic using the AFND dataset.
The NB classifier did quite well compared to other traditional models, with an average accuracy of 95.8%, a precision of 95.2%, a recall of 96.0%, and an F1-score of 95.8%. Even though it was simple, NB worked well on a wide range of Arabic news texts. shows that it is a powerful and useful baseline, especially where speed and ease of understanding are important. The model works good because of good preprocessing, text normalisation, and class balancing. The NB model is also good at working in sparse, high-dimensional domains.
On the other hand, the RF classifier only obtained 89.3% of the responses accurate on average and achieved a F1-score of 88.0%. RF is powerful and simple to comprehend, but it wouldn’t have been able to illustrate all the different methods that Arabic text can be place together and used because it wasn’t able indicate patterns.
The FNN achieved a F1-score of 94.2% and an accuracy rate of 95.0%, indicating that it can learn effectively from full TF-IDF data. However, its non-sequential form impeded its usefulness in capturing contextual connected within more extensive or more unclear narratives.
A LSTM model was designed to address these problems. It achieved 94.0% accuracy, matched the forward neural network (FNN) in F1-score (94.2%), and demonstrated improved ability to handle sequential patterns and long-term dependencies, which are common in Arabic news texts.
The AraBERT model, a transformer-based architecture pre-trained on large Arabic corpora, outperformed all baseline models. It achieved an average accuracy of 97.0%, with precision and recall of 96.5%, and an F1-score of 97.0%. Due to AraBERT’s attention mechanism and extensive semantic demonstrating abilities, it was capable to work effectively with both official Modern Standard Arabic (MSA) and unofficial dialectal information.
Finally, the AraBERT + BiLSTM hybrid model exhibited the best overall performance, with an accuracy of 97.5%, a precision of 97.5%, a recall of 97.8%, and an F1-score of 98.0%. This hybrid integration worked because AraBERT could understand context and BiLSTM could recognise sequences of words.
Ethical and legal considerations in Arabic fake news detection
Fake news detection in Arabic online platforms presents dedicated legal and moral problems in addition to the linguistic and technical difficulties. In Arabic-speaking nations, the legal environment that surround fake information is frequently determined by larger laws regarding national security, cybersecurity, and freedom of speech. Although some governments have implemented or created legislation that prohibits the spread of misleading information, these laws frequently lack specific terms or security measures. For instance, ambiguous terms like “rumour” and “fake information” were added to some contriues cybercrime law, which could result in over-enforcement and a lack of those who disagree.
If automated detection systems are used without a clear design or legal responsibility, they may accidentally promote such overreach. When computational models trained on biassed datasets flag authorised material as fake, particularly ideological or religious discourse, the rights of users to free speech and research accessibility may be violated.
Furthermore, the region’s privacy regulations are still being developed and put into effect. Arabic fake news datasets usually do not have clear consent procedures and data managing instructions, making it difficult to assess their ability to comply with ethical data use standards. It is becoming more and more important to automated detection systems follow international standards for data protection, due process, and human rights as they become more sophisticated and widely used. For this reason, any Arabic fake news detection system must be created with stakeholder involvement, ethical review, and legal oversight to reduce the possibility of abuse and guarantee compliance with national and international ethical standards.
Conclusion
Using the comprehensive AFND dataset, this study assessed how well various machine learning and deep learning models detected fake news in Arabic. We study both basic models, such RF and NB, and newer models, like AraBERT, which is a new hybrid model that combines AraBERT with BiLSTM, and deep learning models, including FNN and LSTM. Naive Bayes did better than the standard models, with an average accuracy of 95.8%. This shows that it works well with high-dimensional, well-preprocessed text data. Random forest is easy to understand and works well, but its lower accuracy (89.3%) shows that it has trouble simulating sequential and contextual relationships.
With FNN and LSTM obtaining similar F1-scores of 94.2%, deep learning models demonstrated enhanced performance. LSTM was better at handling sequential patterns in Arabic text, particularly in cases where ambiguity and narrative structures are common. By using deep contextual embeddings, the AraBERT model proved to be very effective in tasks related to Arabic NLP, reaching an accuracy and F1-score of 97.0%. With the greatest average accuracy (97.5%), precision (97.5%), recall (97.8%), and F1-score (98.0%), the hybrid AraBERT + BiLSTM model performed superior to any other approach. This shows how combining sequential models with transformer-based contextual representations can lead to better fake news detection, especially in the complex Arabic language.
More thorough multidimensional detection mechanisms may be made possible for future research by adding contextual metadata like source credibility, publication time, and user engagement indications. Furthermore, the generalisation and adaptability of fake news detection systems across various Arabic languages may be further improved by utilising sophisticated pre-trained Arabic models, like MARBERT, QARiB, and mT5, which have been tuned to handle dialectal and informal Arabic.
Supplemental Information
{kind=link}
Materials And Methods.
Computing infrastructure: operating system, hardware
Code.
Jupyter Notebook containing the complete annotated code for data preprocessing, training, and evaluation.