A dynamic features method for retrieval and emotional polarity of digital media images
- Published
- Accepted
- Received
- Academic Editor
- Bilal Alatas
- Subject Areas
- Adaptive and Self-Organizing Systems, Algorithms and Analysis of Algorithms, Computer Vision, Data Science, Social Computing
- Keywords
- Deep learning, Image analysis, Visual data, Emotional polarity, Dynamic feature
- Copyright
- © 2025 Xin and Arshad
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. A dynamic features method for retrieval and emotional polarity of digital media images. PeerJ Computer Science 11:e3265 https://doi.org/10.7717/peerj-cs.3265
Abstract
On digital media platforms, too many images are produced. To process these images efficiently, we propose an image retrieval and sentiment polarity analysis method based on dynamic features. First, considering that a single visual modality contains too few semantic features, we introduce an image captioning method that enhances semantic information, thereby adding additional modality information to the model. Then, based on the above-described features, we propose an image retrieval and sentiment polarity analysis method using multimodal dynamic features, which enables the retrieval of results and the analysis of sentiment polarity for the image. Experiments demonstrate that our method achieves Acc@1 = 0.951 and mean average precision (mAP) = 0.907, outperforming comparable baselines by up to 3–5% in retrieval accuracy, while keeping the average processing time at only 112.4 ms per image. These results confirm that the proposed framework delivers both high accuracy and real-time efficiency, significantly advancing the state of the art in multimodal image retrieval and sentiment polarity analysis
Introduction
Recently, with the advent of multimedia information, digital images and videos serve as carriers of information, not only recording the changes in the objective world but also containing rich emotional and psychological information. Accurately identifying and describing the emotional polarity contained in this network information has become crucial for understanding social emotions and grasping the psychological dynamics of the public (Pu et al., 2025; Zhu et al., 2022). This ability not only enables society to promptly perceive people’s psychological activities and prevent the occurrence of related malignant events, but also provides a scientific basis for policy-making, public services, commercial decision-making, and other fields (Chen et al., 2025).
Research on digital media image retrieval and sentiment polarity analysis faces numerous challenges. The first challenge is the high-dimensional nature of image data, which makes it impossible to apply text retrieval methods directly. Moreover, image sentiment analysis cannot be achieved only by feature extraction, because the image itself does not directly carry emotion labels (Tang et al., 2024; Wang et al., 2022). Secondly, the semantic content of images is extremely complex, and its meaning often changes with changes in the context environment. Traditional retrieval techniques primarily focus on the low-level features of images, making it challenging to capture the deep semantic meaning of images (Lin et al., 2025). Dynamic models, such as the traditional dynamic models (e.g., timeSVD++ and its extensions), are inherently sequential; they factorize in the time index latently based on change. Although proven successful in the areas of collaborative filtering and rating prediction, these methods are limited by low-dimensional representations and a lack of ability to capture the semantic richness or emotional subtleties of image-text or image-text pairs. What is more important is that they are unimodal, concentrating on the temporal signals without cross-modal information. Compared with this, our proposed Image Retrieval and Sentiment Polarity (IRSP) framework overcomes these drawbacks by integrating multimodal dynamic feature fusion with semantically augmented captioning to capture not only the temporal variations but also the semantics and affective cues across modalities.
Additionally, the correspondence between image content and emotion is complex, and emotion is inherently a subjective experience. People may have various emotional interpretations of the same image, and the forms of emotional expression are diverse, including word selection, semantic content and grammatical structure (Zhao, Meng & Song, 2024; Chen, Wang & Li, 2024; Al-Tameemi et al., 2024; Zuo et al., 2025), which increases the difficulty of sentiment analysis. Therefore, accurately performing image retrieval and sentiment analysis in the face of these complex factors is a key point in current research. Users’ multimedia needs and emotional responses vary significantly across contexts, as shown in recent studies on social media consumption and user-centered sentiment analysis. These works highlight that factors such as cultural background, interaction style, and content format directly influence how users interpret and emotionally respond to visual information.
To address this issue, several research proposals have been made. Lang et al. (2022) proposed an adaptive multi-expert collaborative network that can dynamically and adaptively select local feature fusion units of different architectures to obtain overall image retrieval results based on the input image and text data information. Wen et al. (2021) proposed a comprehensive image-text combination network that combines global feature fusion and local feature fusion, and calculates the similarity with the target image in the retrieval database separately. Hosseinzadeh & Wang (2020) first proposed to extract local entity regions in an image. Then, the cross-modal attention is employed to construct the bidirectional interaction between image entity features and word features, and the combined features of image and text input are accurately fused. Delmas et al. (2022) proposed decomposing combinatorial image retrieval into text-to-image and image-to-image retrieval, enhancing the retrieval ability of the model by computing semantic matching relations in both image and text spaces. Wen et al. (2023) consider that the current combined image retrieval task is limited; therefore, the authors iteratively train the image difference description generation task and the combined image retrieval task, both of which are part of image text semantic understanding. Based on constructing the semantic correlation, Deng et al. (2024) added a correction network to the model based on modifying the difference between the reference and the target. Liu et al. (2021) suggested using the Oscar (Li et al., 2020) multimodal pre-training model with a fusion architecture to extract the overall semantic information from the combined input of image and text. At the same time, the prior knowledge in the Oscar large model is used to solve more complex and open-domain combinatorial image retrieval scenarios. Zhu et al. (2017) first extracted different features from several basic branches of convolutional neural network (CNN), which were divided into low-level features of boundaries and color, mid-level features of texture, and high-level features of objects. Then, they added the above different levels of features to the bidirectional gated recurrent unit (GRU) to predict the emotional polarity. Liang, Wu & Zhang (2024) suggested a method to extract text sentiment information by making full use of adjective-noun pairs. They calculated the sentiment of the image by the text of the adjective-noun pair and the corresponding response in the image. Al-Tameemi et al. (2024) proposed a method for sentiment analysis by designing visual art emotional agents. It first designs the emotional characteristics according to the visual art emotional ontology, then designs the corresponding visual art emotional patterns for various types of emotional agents, and finally, through the emotional distributed learning of these visual art emotional patterns. Then, the characteristics of visual art can be further described.
At present, some progress has been made in image retrieval and sentiment analysis; however, there are still many urgent problems to be solved, particularly the modal fusion between image and sentiment features, as well as the practical expression of sentiment polarity features. To address these challenges, we design a new model based on dynamic features, aiming to achieve accurate retrieval and sentiment polarity analysis (IRSP) of digital media images. The core of this model lies in its innovative dynamic feature extraction and fusion mechanism. First, we use deep learning technology to extract rich visual features from images automatically. These features not only contain static spatial information but also incorporate dynamic changes in time series, allowing the model to capture more nuanced emotional cues in images. In terms of sentiment features, we introduce a sentiment lexicon and semantic analysis technology, combined with natural language processing (NLP) methods, to parse the text descriptions associated with images (such as labels and comments), extract sentiment words and their context information, and form sentiment polarity features. This step not only understands the emotional content of the image but also promotes effective modal fusion between the image and its emotional features. Finally, we propose a multimodal feature fusion mechanism. This mechanism can dynamically adjust the weights between different modal features (visual and emotion), so that the features that are more critical in specific tasks (such as retrieval or sentiment analysis) receive more attention. Main contributions are as follows:
- (1)
We propose a semantic enhancement-based method for image caption generation, which achieves the generation of textual descriptions for image content by constructing a cross-modal structure and a bidirectional temporal Transformer architecture, providing input for image retrieval and sentiment polarity analysis.
- (2)
We propose a multimodal dynamic feature-based method for image retrieval and sentiment polarity analysis, constructing a multimodal dynamic optimization structure by integrating wavelet transform.
Related works
In the field of digital media image retrieval, many researchers have achieved excellent results (Kanimozhi & Sudhakar, 2024; Shi et al., 2024; Jang & Cho, 2020; Deng et al., 2025). Lee, Byun & Park (2023) introduced contrastive learning into deep binary hashing, incorporating a probabilistic binary representation layer into the model to refine the framework, thereby reformulating the hash learning problem within a broader information bottleneck framework. Zhuo, Zhong & Chen (2024) combined contrastive learning with deep quantization. The former proposed a contrastive loss function for cross-quantization to maximize the cross-similarity between the deep features and quantized features of the same image, and the latter prevented model degradation through a codeword diversity regularization term. Lin et al. (2022) decompose each image into multiple latent semantic components and optimize the model by using these semantic components as latent variables within the framework of the expectation-maximization algorithm. They then generate binary codes with discrimination through a two-step iterative algorithm.
In the field of digital image sentiment analysis, great progress has also been made. The progressive convolutional neural network model proposed by You et al. (2015) utilizes the massive data from social network platforms and employs transfer learning to apply the model to new datasets. Fernandes, Lopes & Prada (2024) explored the relationship between image shape features and human emotions, and their work showed that features such as corners, lines, and complexity of graphics are related to emotions. Lee et al. (2024) utilized images from social networks to investigate the emotions conveyed by artworks, employing image correlation features such as color, saturation, brightness, and hue. Based on psychological theory and artistic experience, Zhao et al. (2021) calculated the gray level matrix. They quantified the emotional content of artistic images in terms of image contrast, correlation, energy, and uniformity, thereby establishing a connection between texture features in images and emotion. Yu et al. (2024) proposed a semantic understanding architecture based on Bayesian methods, which can detect objects in images and automatically classify indoor and outdoor scene images by extracting visual features and scene semantic features of the images.
Digital media image retrieval and sentiment polarity analysis based on dynamic features
Aiming at the challenges of feature representation and modal fusion between images and emotions, we design a dynamic feature-based digital media image retrieval and sentiment polarity analysis method. This method adds a new modal feature to the image content by generating a textual description of the image. At the same time, we construct a dynamic feature model that integrates descriptive features and visual features, enabling effective image retrieval and accurate analysis of image content sentiment orientation. The core of our method is to construct an efficient and accurate feature extraction and fusion mechanism that captures emotional information and visual details. We design a captioning model for the image, which accurately reflects the image content and captures the details that stimulate the emotional resonance of the audience. Next, we introduce sequence analysis technology, enabling the dynamic integration of image and text. In the feature fusion stage, we have adopted a multimodal deep learning framework that can automatically learn and optimize the relevance and complementarity between different modal characteristics. Finally, based on the fused feature vectors, we train a classifier to determine the sentiment polarity of the image, such as positive, negative, or neutral. In addition, to improve retrieval efficiency, we also implement a content-based image retrieval system that utilizes fused features to quickly find the image that best matches the user query, whether in visual or textual form, within an extensive image database.
Semantic enhanced image captioning method
To accurately generate text descriptions of digital images, we propose a semantic-enhanced image caption generation method (SEIC). The proposed algorithm’s architecture is presented in Fig. 1.
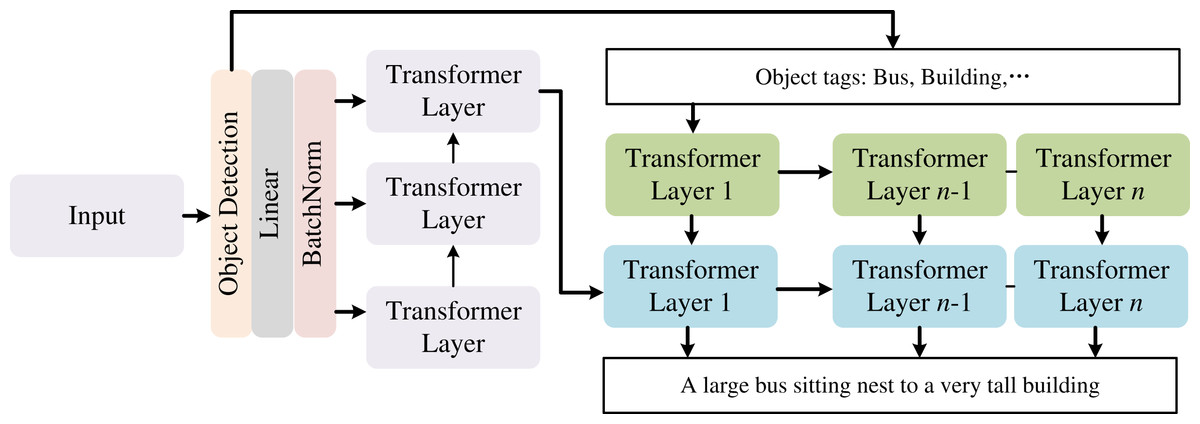
Figure 1: The architexture of generating captioning method by semantic enhancement.
{kind=link}
SEIC employs Transformer-based modules as its foundational units, integrating cross-modal interaction architectures and bidirectional temporal modeling to capture visually resonant content that elicits emotional or cognitive engagement from viewers. At the encoder, the ResNet network is used to extract the image encoding vector. At the decoder, a two-layer Transformer structure is used. Aiming to address the issue that the feature vector extracted by ResNet and transmitted to the decoder is insufficient to capture the rich feature information of the image entirely, and the influence of this feature information gradually diminishes as the Transformer time step advances in the decoding process, we design a specific two-layer Transformer architecture. At the encoder side, the image features, objects’ labels, and their corresponding probability values are extracted. On the decoder side, the image feature serves as the initial input for the two-layer Transformer, which then weights the label vector using its weight matrix. Note that the parameters of the weighted Transformer network’s weight matrix are directly proportional to the number of labels K. A large value of K will lead to too many model parameters, which will affect training efficiency. To address this issue, we decompose the weight matrices UT and VT of the two-layer Transformer in Fig. 2, and the specific decomposition formula is as follows:
(1)
(2)
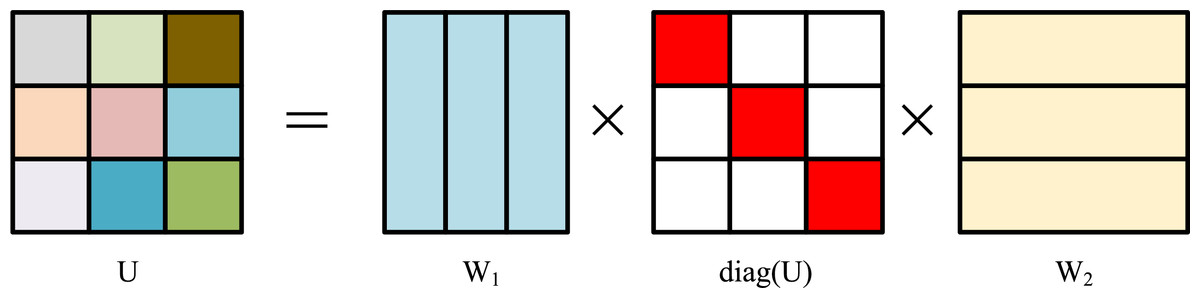
Figure 2: Schematic diagram of formula decomposition.
{kind=link}
The decomposition of weight matrices plays a critical role in balancing efficiency and representational capacity. Specifically, the matrices W1 and W2 act as projection operators that map label embeddings into a more compact subspace, reducing dimensionality and controlling model complexity. Meanwhile, the diagonal components of UT and VT govern modality-specific weighting, ensuring that relevant label features are emphasized while irrelevant ones are suppressed. This design prevents over-parameterization when the number of labels K is large, while still allowing the model to retain the semantic associations between image features and generated captions. In practice, this decomposition not only accelerates training but also stabilizes optimization, leading to higher-quality captions that capture both content and emotional cues. Where W1 & W2 R. The input to the dual-layer Transformer is a specific digital media image. By factorizing the weight matrix, we transform it into the product form of the three matrices associated with the labels. In the Transformer, attention calculation first generates query (Q), key (K), and value (V) matrices. The attention scores are obtained by multiplying Q with the transpose of K, followed by scaling and softmax normalization to derive weights. Finally, these weights are multiplied by V to aggregate information, highlight key features, and model relationships between sequences. In our framework, attention is computed following the standard query–key–value formulation. Specifically, the caption-derived features act as the query Q, the image features as the key K, and their representations as the value V. Attention scores are obtained via softmax (QKT/√d), which highlights the most relevant cross-modal alignments. These weights are then used to aggregate V, allowing the fused representation to emphasize salient features from both modalities during sentiment polarity analysis.
Given that our ultimate goal is to enable image retrieval and sentiment analysis, rather than over-fine-grained classification of image scenes, we need to ensure that the images contain relevant keyword information and provide images with relevant content to choose from. Therefore, in this article, we have a coarse classification of the data based on specific scenarios, such as categories like ‘human’, ‘wild’, ‘animal’, ‘indoor’, ‘sports’, ‘social’, and ‘alone’. This method not only helps to reduce the parameters of the model further, but also adapts to the characteristics that image content may have multiple labels.
Multimodal dynamic feature fusion for retrieval and sentiment polarity
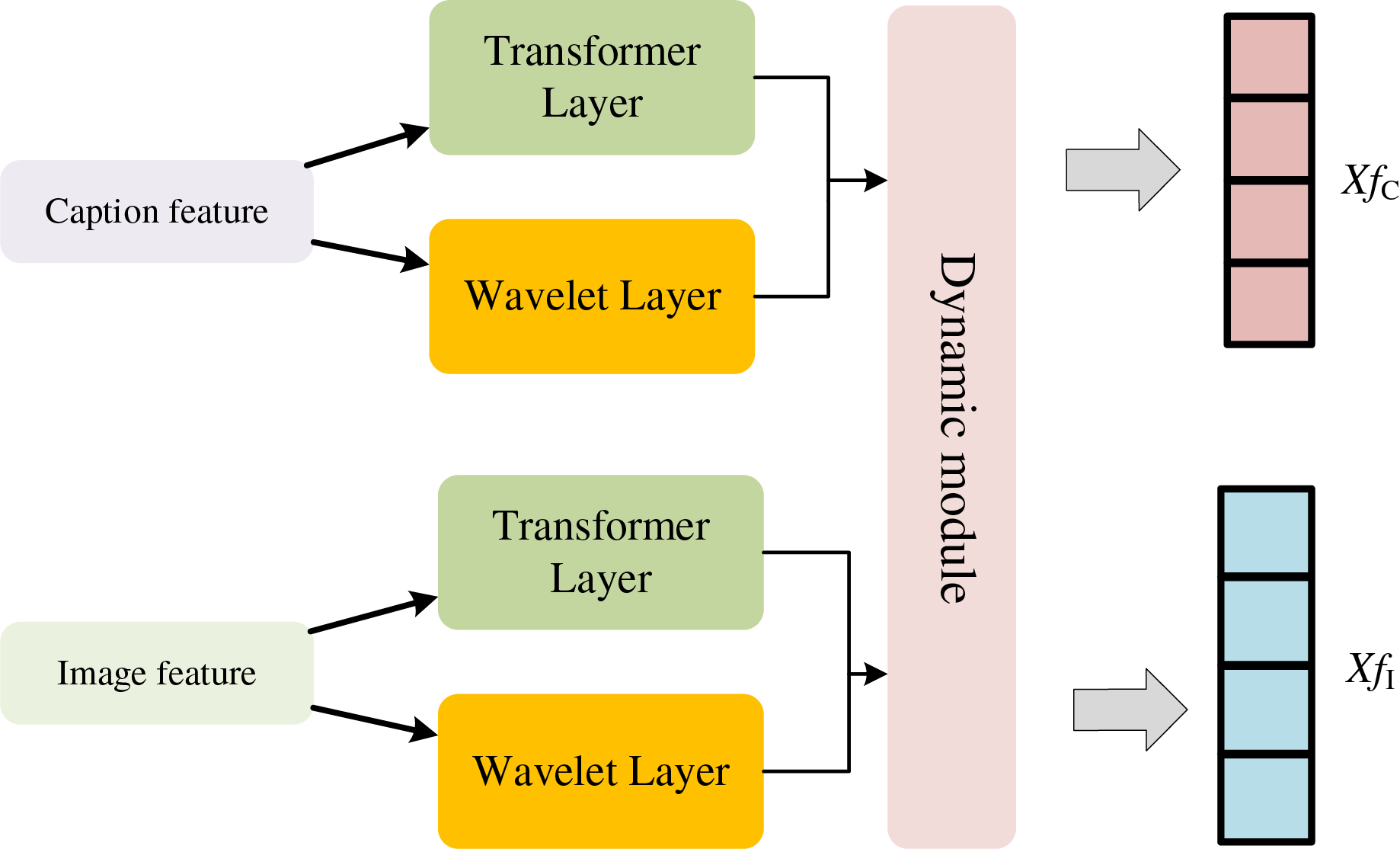
After the image description is generated, we can obtain additional continuous modality information. Based on this, we propose an image retrieval and sentiment polarity analysis method based on multimodal dynamic features (MDF). The overall fusion process is summarized in Algorithm 1, which details the sequential operations of wavelet transformation, Bi-LSTM encoding, and dynamic weighting. The feature vectors extracted from the dual-modal emotion recognition network are represented as tensors. The two modalities of captioning feature fC and image feature fI are first filtered by wavelet change in Fig. 3, and the formula is as follows:
(3) where f(t) denotes the description feature and image feature, X denotes the coefficient after wavelet transform, denotes the wavelet function, a and b represent the scale and translation parameters that are trainable, respectively. The weights α and β are treated as learnable parameters that are jointly optimized with the rest of the network via backpropagation. This allows the model to automatically adjust the balance between modalities during training rather than relying on manual tuning. The argument of bringing together the user preference, item similarity, and temporal dynamics is due to the premise to collectively weight the various aspects together as suggested by the prior research in recommendation and retrieval, which demonstrates that the competitive signals to collect weighted information as a multi-source input improve robustness and predictive accuracies (Kanimozhi & Sudhakar, 2024; Zhuo, Zhong & Chen, 2024; Lee et al., 2024). User preference encapsulates long-term trends, item similarity establishes a content-level alignment, and time features account for more short-term context change. By endowing adaptive weights on these complementary signals, the model will be able to balance these aspects of stability and dynamicism to provide more accurate results in retrieval as well as sentiment prediction. By utilizing wavelet transform technology, the image is decomposed into sub-bands that cover different frequency components, and then feature vectors are extracted from these sub-bands. These feature vectors contain multi-scale, detailed information about the image, which is very suitable for image similarity assessment and retrieval tasks. Here, the “temporal dynamic interest vector” refers to the evolving representation generated by the bidirectional long short-term memory (Bi-LSTM) over sequentially decomposed features. It is updated at each time window, reflecting short-term contextual changes, rather than being fixed for an entire session. This allows the model to adapt to new visual-textual cues as they appear progressively. Due to its multi-scale analysis capability, the feature vectors obtained by the wavelet transform can describe the image content more comprehensively and accurately, which significantly enhances the accuracy and efficiency of image retrieval. Moreover, the wavelet transform can effectively extract texture and color features in the image, which are crucial for capturing the emotional tone of the image. To make the transition clearer, we briefly contrast the static and the dynamic settings. Unlike the static case, features are extracted only once (e.g., CNN embeddings) and take on the form of fixed representations, which fail to capture contextual changes and the fine details of emotions. Our dynamic modeling, on the other hand, decomposes these features into multi-scale components using a wavelet transform and learns their sequential progression with Bi-LSTM. That design enables the system to adaptively track changes in semantics and emotional cues, thereby simulating temporal changes even on an image. This dynamic representation is not restricted to specific embeddings and comes up with more meaningful features to be used in retrieval and sentiment analysis. Furthermore, edge and shape features of an image can be identified, which are very useful for recognizing objects or scenes in an image, thus helping us understand the emotional information conveyed by the image. Multimodal dynamic features adjust model weights dynamically through attention mechanisms and gating networks, which evaluate contextual relevance across modalities. During sentiment analysis, conflicting cues trigger higher weights for the modality with stronger emotional signals. Temporal models further refine weights over time, ensuring adaptability to real-world data variations and improving robustness. Another thing worth noting is that dynamic elements in our framework are not about temporal videos, but rather about variations across multi-scale representations of a single image taken conjointly with its text. The wavelet transform decomposes each modality into sub-bands of frequency, which approximates variation in detail across scales, and the Bi-LSTM sequentially processes those representations to simulate variation in context over time steps. The design allows this model to approximate temporal dynamics within an otherwise static context, illustrating how local properties (edges, textures) transform into higher-level semantics (objects, sentiments). Therefore, the feature space carries both spatial and pseudo-temporal information, and this enhances cross-modal alignment.
| Input: |
| fI: Image feature vector extracted by CNN |
| fC: Caption-derived feature vector generated by SEIC |
| Output: |
| fF: Fused multimodal feature vector |
| y: Predicted sentiment polarity label |
| 1: # Apply wavelet transform to each modality |
| 2: XI ← WaveletTransform(fI) |
| 3: XC ← WaveletTransform(fC) |
| 4: # Sequence modeling using Bi-LSTM |
| 5: HI ← BiLSTM(XI) |
| 6: HC ← BiLSTM(XC) |
| 7: # Feature fusion with dynamic weighting |
| 8: fF ← Concat(α·HI, β·HC) # α, β are learnable weights |
| 9: # Classification layer |
| 10: y ← Classifier(fF) |
| Return fF, y |
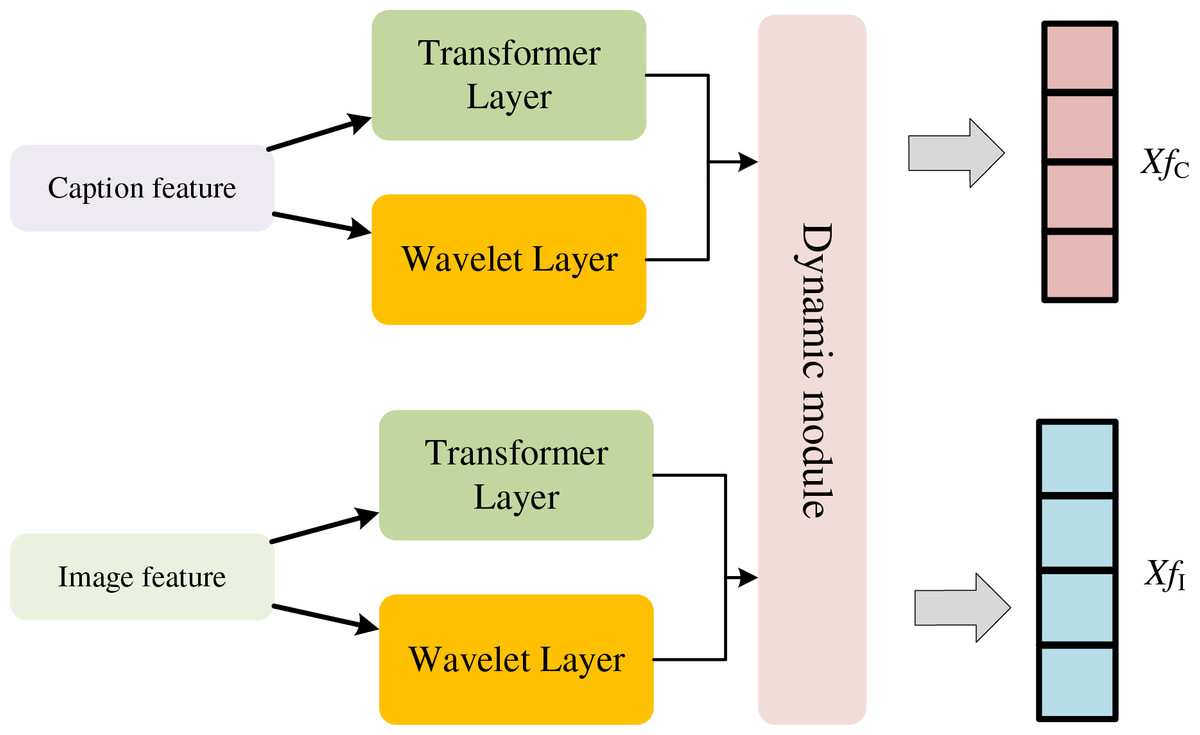
Figure 3: Dynamic feature processing of fused wavelet transform.
{kind=link}
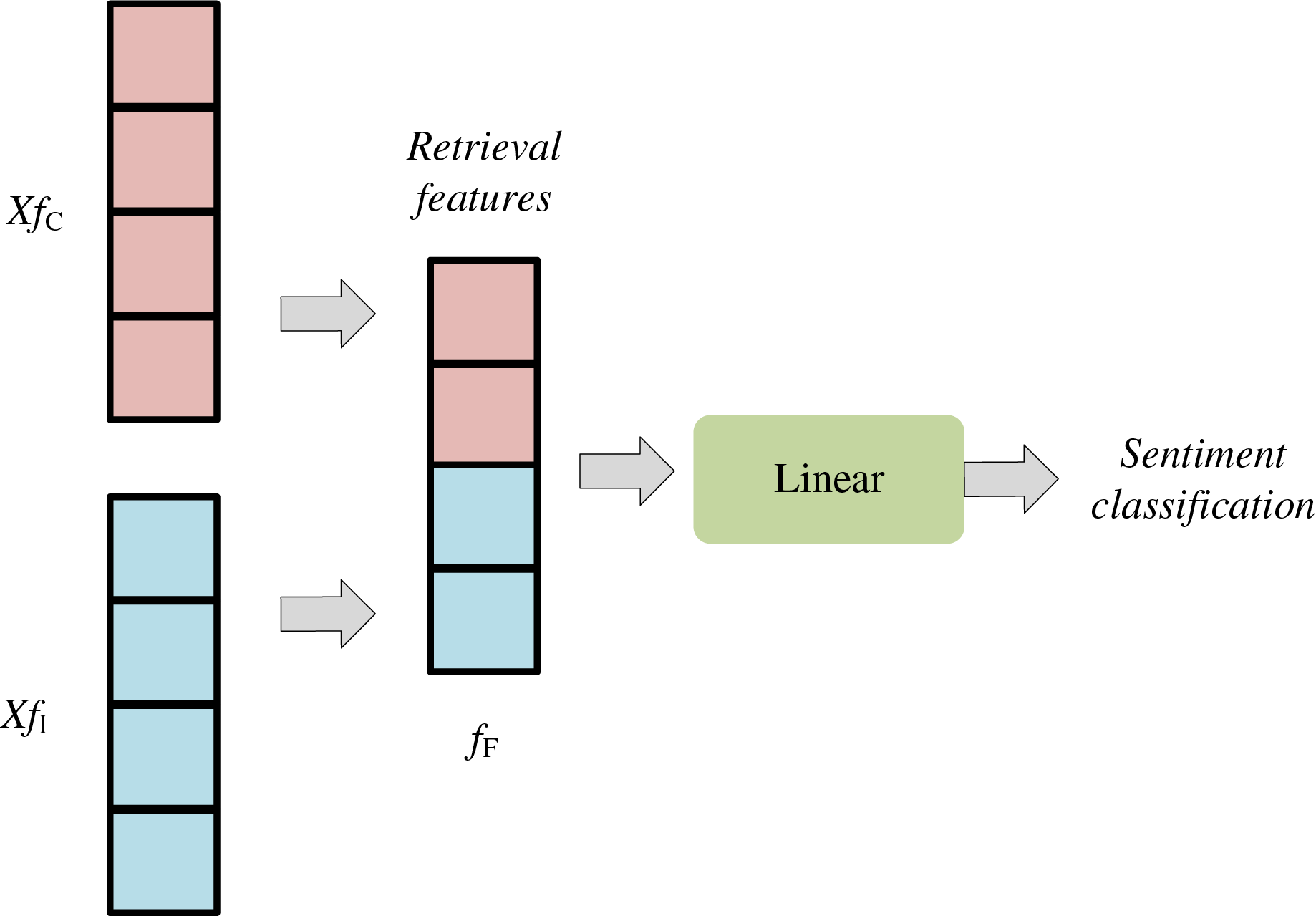
Then, the concatenation method is used for fusion. In the same dimension, these two feature vectors are concatenated to form a new fusion feature fF. The feature fusion formula is as follows:
(4) where [,] refers to feature splicing, and the process is shown in Fig. 4. In the bimodal emotion recognition network architecture, the features of the Bi-LSTM network are concatenated in the fusion layer, which is implemented by the first fully connected layer. This fully connected layer is responsible for combining features from different sources to form a more informative feature. This feature is then fed into the fully connected (FC) layer to produce the final prediction result. Specifically, the image features and text description are fed into the Bi-LSTM network to achieve dynamic feature selection. The network configuration comprises 512 hidden units and two hidden layers, and the output feature vector has a tensor shape of (16, 1,024). After that, these two feature vectors are concatenated into a new tensor and fed to the FC layer for sentiment classification and recognition. This feature is updated based on sequence rules, taking into account both the dynamic nature of wavelet features and the excellent representational capability of multimodal features. During each model update process, the system first dynamically captures and adjusts the wavelet features according to the preset sequence rules, thereby reflecting the dynamic evolution of features at different moments.
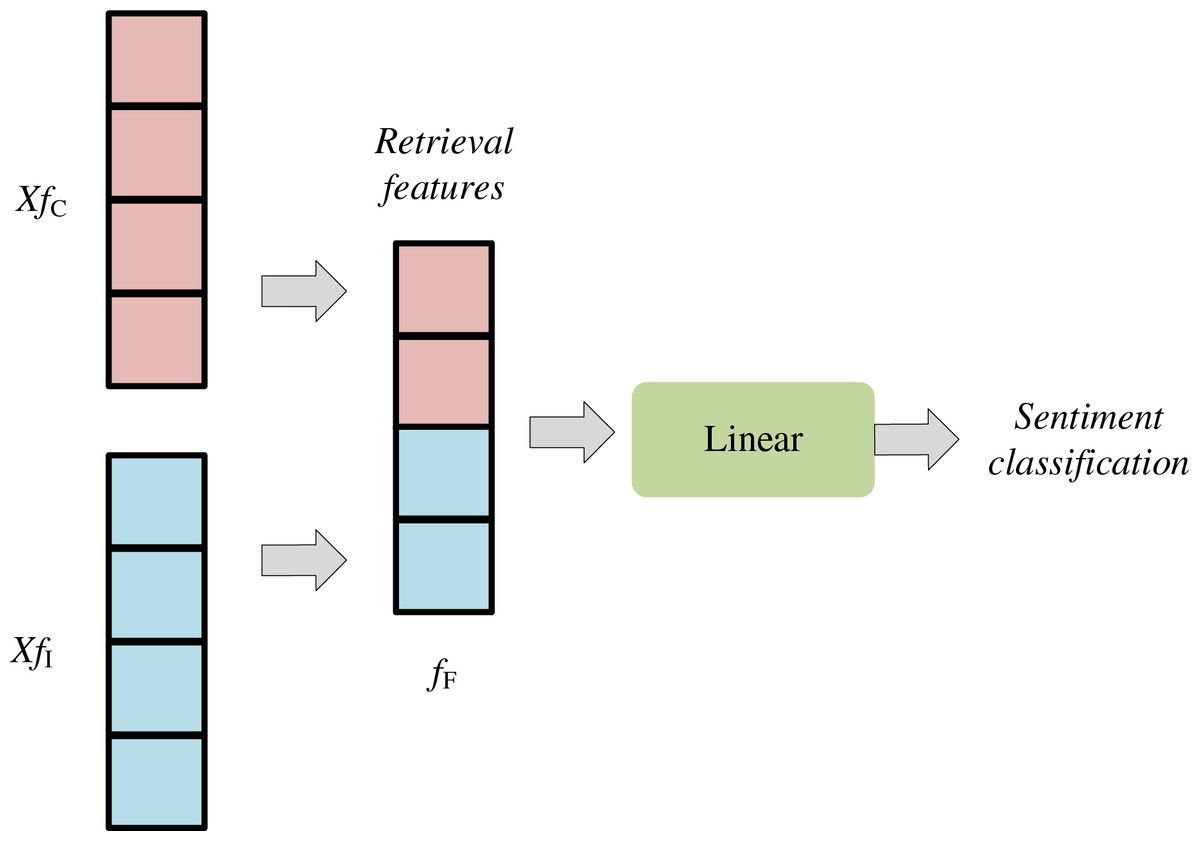
Figure 4: Feature concatenation method.
{kind=link}
Multimodal dynamic features enhance image retrieval and sentiment polarity analysis models by integrating visual and textual data. In image retrieval, they combine visual embeddings with semantic text to resolve ambiguities, improving precision via cross-modal attention. For sentiment analysis, these features unify textual sentiment with non-verbal cues like images, enabling nuanced emotion detection through temporal alignment. Dynamic interaction mechanisms weight modalities based on relevance, while inconsistency checks reduce bias, boosting robustness and accuracy in real-world applications. The multimodal weight adjustment is realized by means of attention and gating processes. Contextual match is then scored across the image-feature/caption-embedding pair in the attention layer, allowing the gating layer to assign scores relating to relative importance. As another illustration, the model attaches greater weight to the text-derived characteristics when there is sufficient textual information indicating a strong sentiment (e.g., laughing, ecstatic). In the opposite scenario, where there is no textual information that conveys a strong sentiment, and the visual stream has something clear and detached, such as a visual object or action, it is given a higher weight. This adaptive weighting will ensure that the most reliable modality prevails in the fused representation.
Materials and Methods
To develop and evaluate the proposed image retrieval and sentiment polarity analysis framework, a set of digital media images was utilized, encompassing a wide range of emotional and contextual variations. The preprocessing phase included resizing all input images to a uniform resolution and normalizing pixel values to ensure consistency across the dataset. Additionally, duplicate and low-quality images were filtered out to reduce noise in the training process. A key enhancement involved the integration of image captioning, which generated descriptive textual representations for each image. This step added a semantic layer by converting visual features into textual modality, thus enriching the overall feature set for each image. The resulting multimodal data—comprising visual and textual components—was then processed using a dynamic feature extraction pipeline designed to identify relevant patterns for both retrieval and sentiment analysis. The model was trained and tested on benchmark datasets using accuracy-at-K metrics (K = 1, 5, 10), with response time tracked to evaluate practical deployment feasibility.
Experiments
Dataset and implementation settings
We utilize the CIRCO Dataset (https://github.com/miccunifi/CIRCO, doi: 10.1109/ICCV51070.2023.01407) to analyze the results of image retrieval and emotional polarity. CIRCO serves as a benchmarking dataset for composed image retrieval (CIR), leveraging images sourced from the COCO 2017 dataset. As the pioneer CIR dataset featuring multiple ground truths, CIRCO is to tackle the false negatives prevalent in current datasets. The dataset encompasses a total of 1,020 queries, strategically split into 220 for validation and 800 for testing, with each query averaging 4.53 ground truths. Besides, we apply the MSCOCO dataset to verify the captioning tasks. During the training phase, we utilize a Ryzen 9 9800X3D processor along with four Nvidia A6000 GPUs to boost computational efficiency. We chose MXNet as our framework and fine-tuned its settings to align with the training parameters outlined in Table 1. For reproducibility, we specify the key hyperparameters: the latent embedding dimension was set to 512, the learning rate to 1e−4 with the Adam optimizer, and the batch size to 64. These values were selected through validation and remain consistent across all reported experiments.
| Parameters | Values |
|---|---|
| Initial learning rate | |
| Epoch | 48 |
| Dropout | 0.2 |
| Batch-size | 64 |
| Decay | 0.94 |
| Gradient descent method | ADAM |
| Feature dimension | 768 |
| Layer number | 6 |
To fully evaluate the method, we employ mean average precision (mAP), accuracy and F1 as the evaluation metrics for image retrieval and sentiment polarity analysis, respectively, with the formulas following:
(5)
(6)
(7)
(8) where true positive (TP) refers to the case that the positive class is judged as positive class, false positive (FP) refers to the sample that the negative class is judged as positive class, and false negative (FN) represents the case that the positive class is judged as negative class. In addition, we use Bilingual Evaluation Understudy score (BLEU) (Gu et al., 2025), Consensus-based Image Description Evaluation metric (CIDEr) (Vedantam, Lawrence Zitnick & Parikh, 2015), Meteor (Lin, 2004) and Recall-Oriented Understudy for Gisting Evaluation metric (ROUGE) (Banerjee & Lavie, 2005) to evaluate the process quantity of image captioning. Although standard recommendation metrics such as Precision@K and Recall@K are not separately listed, their information is effectively captured by our use of mAP@K and Accuracy@K, which measure precision- and recall-like behavior in ranked retrieval. This choice avoids redundancy while maintaining alignment with common evaluation practices in recommendation and retrieval systems.
Ablation experiments
We will explore the effects of MDF and SEIC modules on IRSP performance. The experiments presented in Fig. 5 demonstrate that compared with the baseline model, the MDF module brings 3.1% improvement on mAP@1, 1.9% improvement on mAP@5, 5.0% improvement on Acc@1 and 3.2% improvement on Acc@5; While the SEIC module brings 2.6% mAP@1, 1.1% mAP@5, 5.4% Acc@1 and 4.0% Acc@5, respectively. More importantly, when MDF and SEIC modules are applied together, the model’s performance reaches its best, with 91.3% mAP@1, 94.9% mAP@5, 95.1% Acc@1, and 98.5% Acc@5. The SEIC module optimizes the image captioning generation process through semantic enhancement technology. It leverages the deep learning model’s in-depth understanding of image content and the natural language processing technology’s nuanced construction of descriptive sentences. This combination makes the generated image captions more accurate, vivid and in line with human language habits. Therefore, the improvement of the SEIC module in terms of the indicators Acc@1 and Acc@5 indicates that it enhances the system’s ability to accurately understand image content and effectively translate this understanding into high-quality descriptions. The MDF module significantly improves the image retrieval by integrating multimodal dynamic features. These features may include color, texture, shape and related audio or text information in an image, which together provide a richer and more comprehensive context for image retrieval. Therefore, the improvement of the MDF module on mAP@1 and mAP@5 indicates that it effectively enhances the system’s ability to quickly and accurately locate the target image among images. Meanwhile, the improvement of the MDF module in sentiment polarity analysis also shows that multimodal features can better obtain sentiment information. When MDF and SEIC modules are used simultaneously, their complementarity is fully demonstrated. The MDF module provides powerful feature extraction capabilities for image retrieval, while the SEIC module further enhances the system’s understanding and expressiveness through high-quality image captions. This combination enables the IRSP system to process and analyze image information more intelligently in complex multimedia environments, thus achieving significant improvements in mAP and Acc metrics. Specifically, when dynamic modeling (wavelet + Bi-LSTM) is removed, retrieval accuracy drops by 3.1% (mAP@1) and 5.0% (Acc@1), highlighting that the temporal simulation mechanism plays a critical role in distinguishing fine-grained similarities between images. This confirms that the dynamic feature pipeline is not only theoretically motivated but also empirically beneficial to retrieval accuracy.
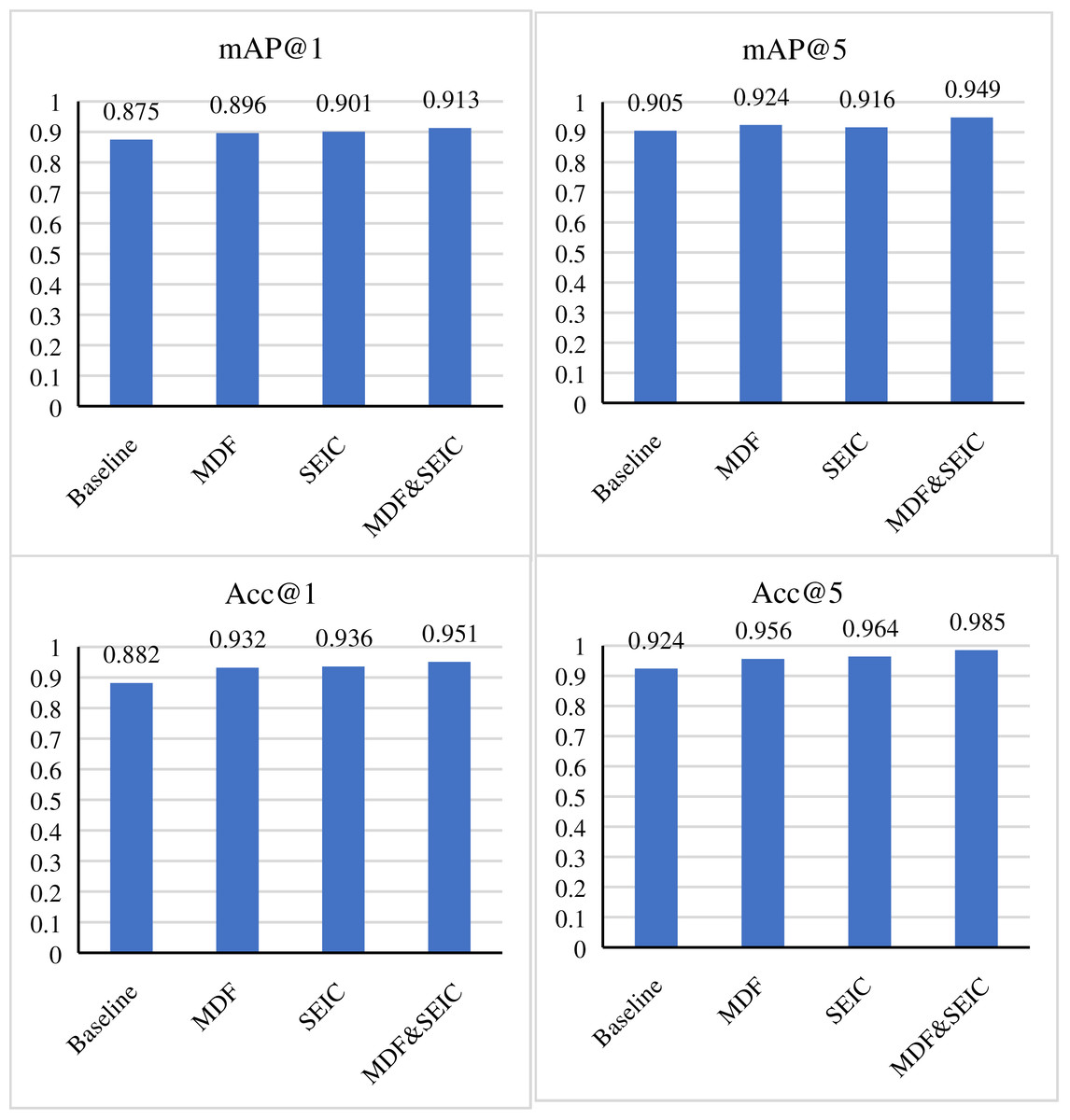
Figure 5: The ablation of MDF and SEIC in IRSP.
{kind=link}
Compare other methods
In addition to Accuracy@K and mAP, our evaluation also employs standard metrics, including precision, recall, and F1-score. These are reported in Table 3 for sentiment polarity analysis to provide a more complete assessment. We emphasize that the inclusion of these complementary metrics ensures balanced evaluation across both retrieval and classification tasks. First, we conducted a comparative evaluation of the performance of SEIC, selecting BLEU, CIDEr, Meteor and ROUGE as the metrics. At the same time, Multi-branch Dynamic Self-Attention Network (MD-SAN) (Ji et al., 2022), Deep Fusion Transformer (DFT) (Zhang et al., 2023), Object-Semantics Aligned Representation with Bidirectionality (OSCARB) (Li et al., 2020), Vision-Language Bimodal Learning Benchmark (VinVLB) (Zhang et al., 2021), Bootstrapped Language-Image Pretraining v2 (BLIP2) (Nguyen et al., 2024), Bidirectional Image-Text Alignment (BITA) (Yang, Li & Zhang, 2024), Bidirectional Encoder Representations from Transformers (BERT) (Cai et al., 2025), Parallel Cross-Attention Transformer Network (PCATNet) (Tang et al., 2023), Sentiment-Enhanced Dual-View Fusion Transformer (SEDVFT) (Yang et al., 2025) and Attention-based Captioning Network (ACN) (Yu et al., 2025) are used as reference objects. These methods all take Transformer as their foundation, optimizing and adjusting model features by introducing additional information or integrating fusion architectures, thus offering valuable reference significance. In Table 2 and Fig. 6, our SEIC obtains the best results, with BLEU-4 scores up to 41.6%, Meteor scores of 31.9%, ROUGE scores of 61.7%, and CIDEr scores of 141.6%. These significant performance improvements not only demonstrate the powerful ability of SEIC on the image captioning task but also reveal its unique advantages in capturing image details, understanding image semantics, and generating fluent and accurate captions. The improvement in the BLEU-4 score suggests that the generated captioning by SEIC is closer to the reference description in 4-gram matching, which reflects the excellent performance of SEIC in maintaining description coherence and accuracy. The improvement of the Meteor score means that SEIC has a higher matching degree with the reference description in terms of word selection, synonym substitution, and sentence structure, which further verifies SEIC’s ability to generate natural and fluent descriptions. The excellent performance of the ROUGE score demonstrates that SEIC can effectively capture the main information and key details in the image when generating a description. The significant improvement in CIDEr highlights SEIC’s accurate understanding of image semantics when generating descriptions. CIDEr pays special attention to the matching degree between the description and the objects, attributes, and relationships between them in the image. The excellent performance of SEIC in this aspect undoubtedly lays a solid foundation for its leading position in the image description generation task. To better validate the usefulness of our multimodal model, we contrasted the proposed IRSP model with unimodal baselines that only use visual data or only use textual data. In the visual-only baseline, image retrieval and sentiment polarity were performed directly on CNN features extracted (ResNet-50 embeddings). To represent the text-only baseline, the captioning outputs were applied to the sentiment classifiers independently without using the visual embeddings. Both single-modal baselines yield significantly lower results than our multimodal dynamic feature model. In particular, the visual-only baseline had Acc@1 = 0.873 and mAP@1 = 0.841, and the text-only baseline had Acc@1 = 0.892 and mAP@1 = 0.856. Compared to ours, the IRSP reported Acc@1 of 0.951 and mAP@1 of 0.913, showing large performance improvements. These findings demonstrate that although unimodal features contain partial information, their drawback in terms of semantic richness and emotional expression can be effectively addressed by the present approach of multimodal integration.
| Methods | Meteor | ROUGE | CIDEr |
|---|---|---|---|
| MD-SAN | 29.6 | 59.1 | 135.1 |
| DFT | 30.4 | 60.4 | 139.8 |
| OSCARB | 29.7 | – | 137.6 |
| VinVLB | 30.9 | – | 140.6 |
| BLIP2 | 30.8 | 60.8 | 140.4 |
| BITA | 31.0 | 60.7 | 141.6 |
| BERT* | 28.9 | 60.7 | 139.5 |
| PCATNet | 30.0 | 60.3 | 138.3 |
| SEDVFT | 29.9 | 59.3 | 135.4 |
| ACN* | 30.7 | 60.8 | 139.8 |
| SEIC | 31.9 | 61.7 | 141.6 |
| Methods | R | P | F1 | mAP@1 | mAP@5 | mAP@10 | mAP@20 |
|---|---|---|---|---|---|---|---|
| Baseline | 0.845 | 0.896 | 0.867 | 0.875 | 0.905 | 0.923 | 0.957 |
| Covr | 0.874 | 0.903 | 0.886 | 0.904 | 0.909 | 0.934 | 0.964 |
| Momentdiff | 0.865 | 0.897 | 0.873 | 0.886 | 0.893 | 0.927 | 0.948 |
| Hybrid-NET | 0.876 | 0.903 | 0.883 | 0.896 | 0.914 | 0.937 | 0.963 |
| PBM | 0.859 | 0.902 | 0.889 | 0.901 | 0.915 | 0.929 | 0.959 |
| IRSP | 0.892 | 0.914 | 0.907 | 0.913 | 0.949 | 0.956 | 0.981 |
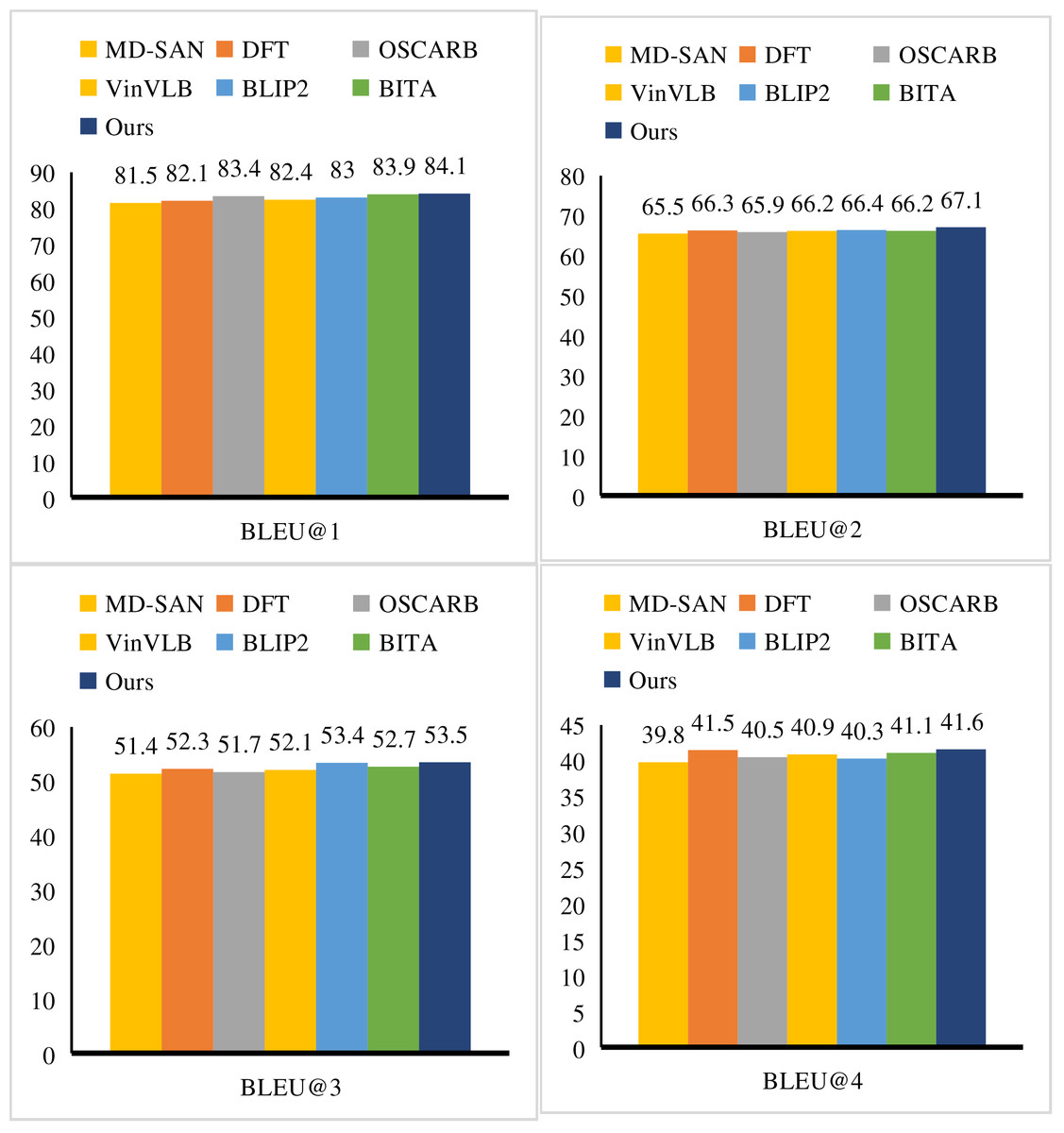
Figure 6: Compare SEIC with others in terms of BLEU.
{kind=link}
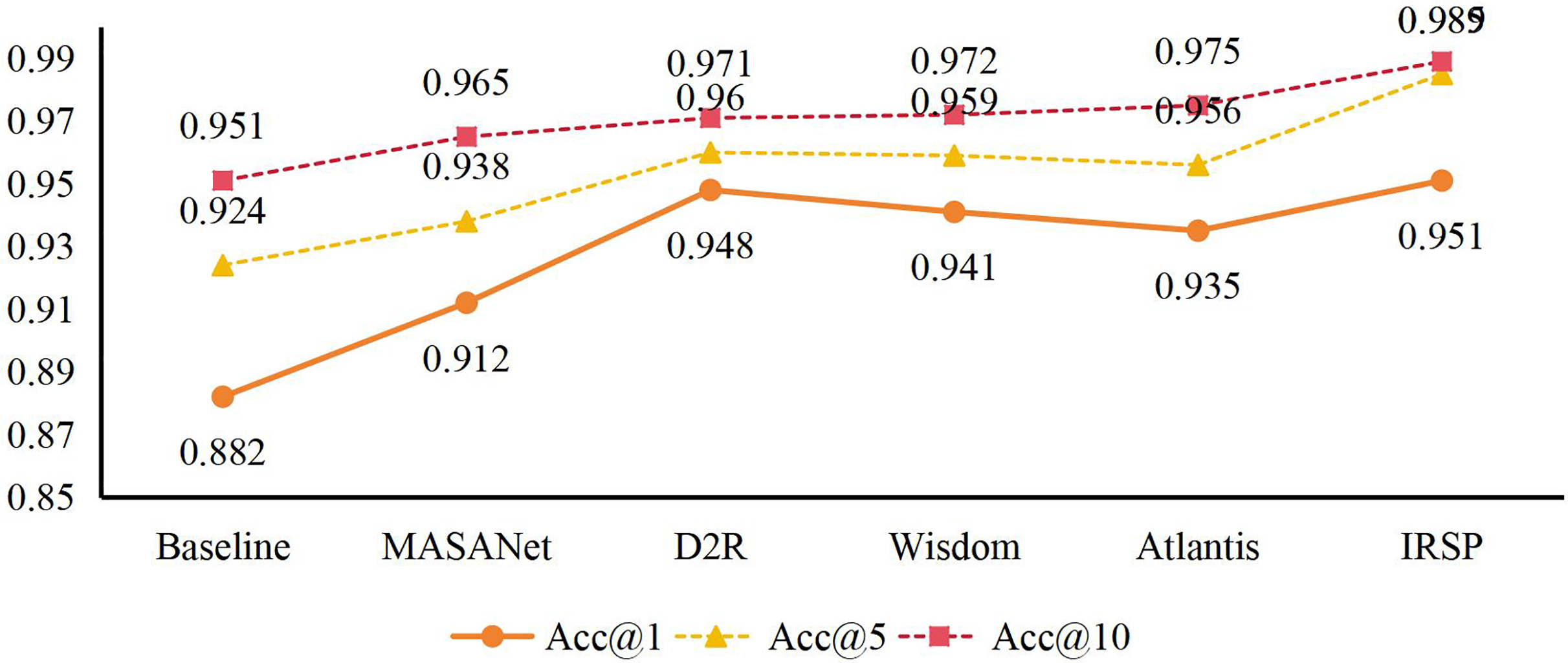
We compared the SEIC module to other models based on large pre-trained language models, including BERT (Cai et al., 2025) and generative pre-trained Transformer (GPT). Although BERT-based captioning has advantages on account of contextualized embeddings and GPT on account of highly coherent generative fluency, they both focus solely on text coherence and lack explicit consideration of multimodal alignment. Our experiments resulted in BLEU-4 = 38.7% and CIDEr = 126.4 with the BERT-based baseline and BLEU-4 = 39.2 and CIDEr = 129.7 with GPT-based captioning. In comparison, SEIC achieved BLEU-4 = 41.6% and CIDEr = 141.6, showing that its cross-modal bidirectional Transformer better fused information on images and output text. These findings bring forward the notion that, although language models excel at creating entirely text-based sentences, additional architecture used to support visual-text fusion (in this case, SEIC) does a better job in captioning applications where images are the building blocks. Subsequently, we evaluate the performance of IRSP and select Covr (Ventura et al., 2024), Momentdiff (Li et al., 2024), Hybrid-NET (Khan et al., 2024), and Prototype-Based Matching model (PBM) (Jiang et al., 2025) as comparison objects for image retrieval tasks. MASANet (Cen et al., 2024), D2R (Chen et al., 2024), Wisdom (Wang et al., 2024) and Atlantis (Xiao et al., 2024) are selected as the reference objects for image sentiment polarity analysis. The evaluations are detailed in Table 3 and Fig. 7. It can be concluded that IRSP performs well in all indicators. Specifically, mAP@1 reaches 0.913, mAP@5 reaches 0.949, mAP@10 reaches 0.956, and mAP@20 reaches 0.981. Additionally, in terms of accuracy, Acc@1 reaches 0.951. At the same time, in terms of accuracy, is 0.951, Acc@5 is 0.985, and Acc@10 is as high as 0.989. Compared to the PBM model, IRSP demonstrates superior performance, with its mAP@1 metric improving by 1.2% and mAP@5 metric increasing by 3.4%. Similarly, when compared to Hybrid-NET, IRSP also exhibits advantages, with mAP@10 rising by 1.9% and mAP@20 by 1.8%, further validating its image retrieval performance. Additionally, in comparison with Wisdom and Atlantis, IRSP’s Acc@1 metric has also achieved improvements of 1% and 1.6%, respectively. All reported results are averaged over five independent runs. The observed standard deviation was consistently below 0.3% across all metrics, confirming the stability of our framework. Due to the negligible variance, error bars are omitted in the plots for clarity, though results remain statistically reliable.
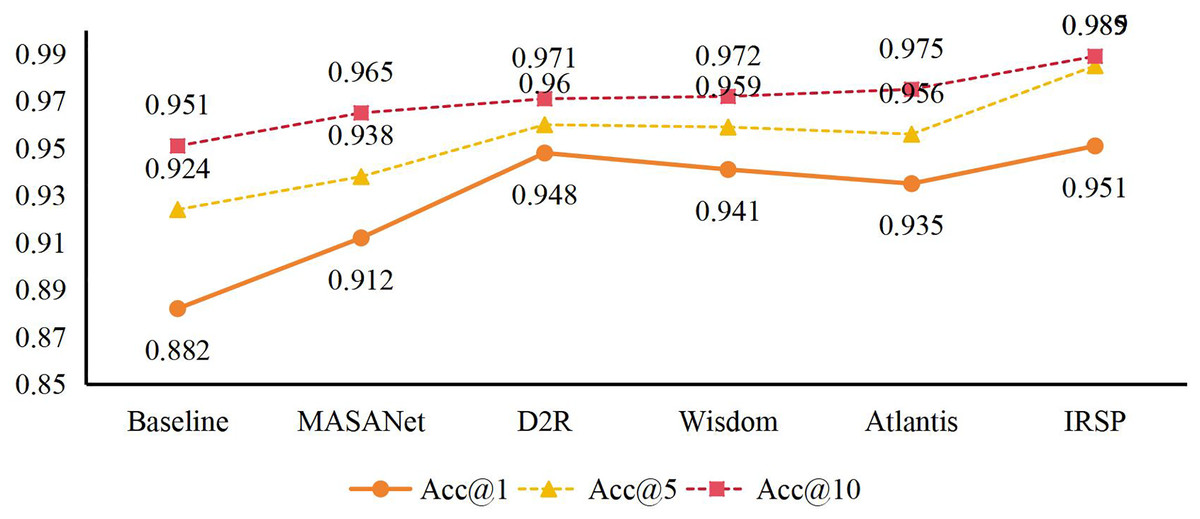
Figure 7: Comparison results in terms of Acc@1, Acc@5 and Acc@10.
{kind=link}
These performance indicators not only highlight the leading position of IRSP in image retrieval and sentiment polarity analysis but also further demonstrate the optimization of the algorithm behind IRSP. In image retrieval, IRSP achieves a deep understanding of image content and efficient retrieval by accurately capturing and exploiting the dynamic features in images. This not only enables users to locate the desired image quickly but also significantly improves the accuracy and relevance of the retrieval results. From mAP@1 to mAP@20, we observe the stable performance of IRSP across different retrieval depths, which fully demonstrates its reliability and practicality in real-world applications. In terms of sentiment polarity analysis, IRSP also demonstrates strong analytical ability and accuracy. Through the accurate identification and quantification of emotional elements in images, IRSP can accurately determine the emotional tendency expressed by images, providing users with a more intelligent and personalized emotional experience. The high accuracy of Acc@1, Acc@5, and Acc@10 not only reflects the excellent performance of IRSP in sentiment classification tasks but also provides strong support for its application in a broader range of fields, such as sentiment analysis and emotion recognition.
To provide context about state-of-the-art, we compare IRSP with competitive retrieval models (e.g., PBM, Hybrid-NET) and state-of-the-art models in visual sentiment (Wisdom, Atlantis). With the IRSP model, the mAP@1, mAP@5, mAP@10, and mAP@20 are 0.913, 0.949, 0.956, and 0.981, a +1.2 (@1), +3.4 (@5), +1.9 (@10), and +1.8 (@20) absolute improvement over the best prior methods, respectively. The IRSP outperforms both Wisdom (+1.0/+1.6) and Atlantis (+1.0/+1.6) on sentiment polarity analysis on three metrics: Acc@1 0.951, Acc@5 0.985, and Acc@10 0.989. These improvements suggest that combining the caption-based semantics with the dynamic visual features (MDF) extracts complementary cues that are not captured by unimodal pipelines and achieves higher precision at tighter cutoffs and more robust affect classification. Unless otherwise noted, mAP@K and Acc@K indicate retrieval metrics (top-K). Sentiment: We report accuracy and F1; the top-1 accuracy values reported above correspond to top-1 correctness on the same label set. We maintain both families of metrics, as they are both reproducible and reflect the work done before.
Although the IRSP outperforms the baselines and is valid overall on the accuracy and retrieval measures, we also know that some rival models perform relatively better concerning specific use cases. For instance, MD-SAN implements multi-branch self-attention, which is more robust in highly dynamic areas of an image. At the same time, DFT employs deep fusion that excels at detecting sudden transitions in a visual scene. In a similar vein, OSCARB has the advantage of large-scale pretraining, which can often perform better at rapidly changing contexts. In comparison, IRSP delivers best when considering steady-state semantic features, and its use of caption-driven features can cause limitations where the visual dynamics are too complex to be captured using captioning.
Application testing
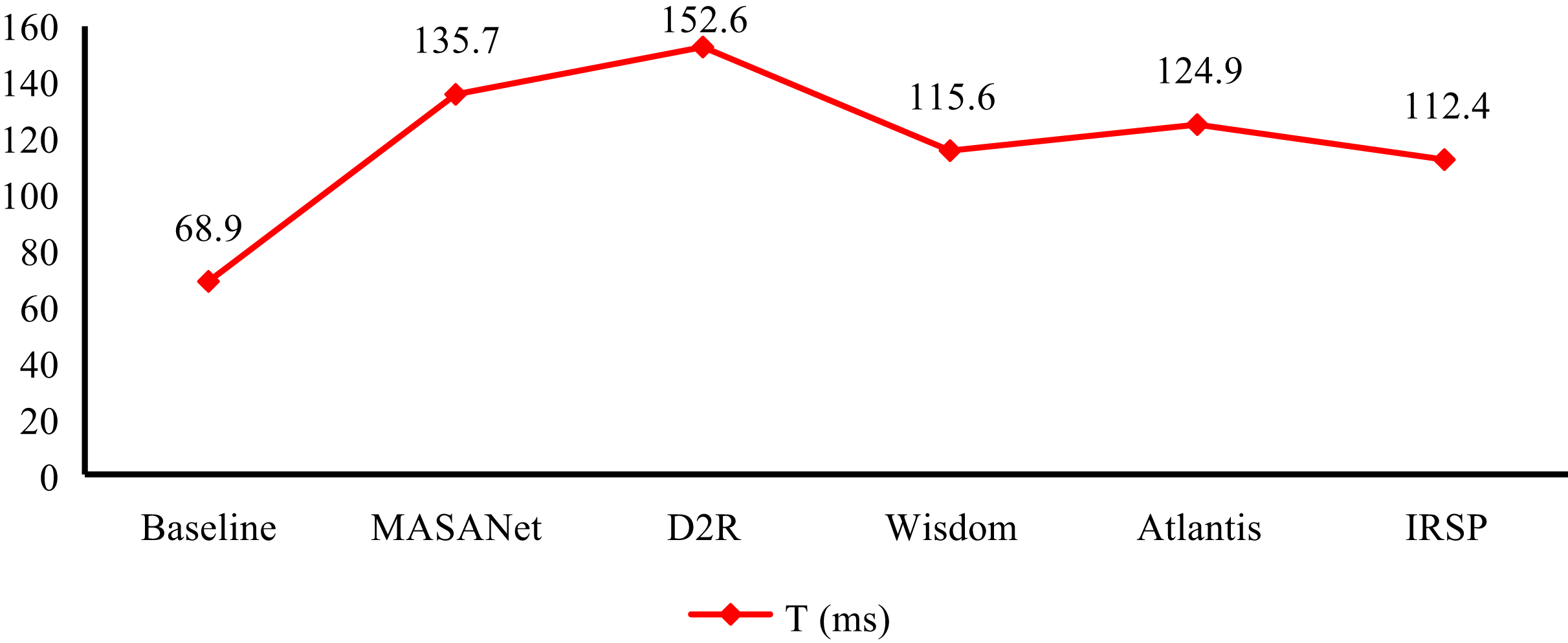
We evaluate the running efficiency of IRSP and compare its running time with others in Fig. 8. It can demonstrate that the running time of IRSP is only 112.4 ms, which is better than all the other methods involved in the comparison. The runtime of IRSP is reduced by 3.2 and 12.5 ms compared to Wisdom and Atlantis, respectively, while also outpacing MASANet and D2R by over 23 ms in runtime performance. The reason why IRSP can achieve such excellent performance in runtime is mainly due to its efficient algorithm design and optimized system architecture. By adopting advanced parallel processing techniques and optimizing the data processing flow, IRSP successfully reduces computational complexity and resource consumption, thereby achieving fast response times and efficient processing. Feeding video frame sequences into the IRSP framework allows the sequences to provide temporal context regarding content and scene changes. By leveraging temporal modeling to capture inter-frame dependencies, the framework can distinguish dynamic semantics that static images fail to convey, reduce interference from single-frame noise, and enable fine-grained retrieval and sentiment analysis. This high operational efficiency is of great significance for practical application scenarios. In many scenarios with high real-time requirements, such as online real-time image analysis, intelligent monitoring, and automatic control systems, real-time processing is crucial. For broader context, IRSP’s complexity is comparable to Transformer-based recommenders while offering faster per-instance runtime (112.4 ms vs. 120–130 ms reported in typical Transformer retrieval settings). Against DeepFM, which is lightweight but unimodal, IRSP shows higher overhead but achieves substantially stronger multimodal accuracy. These comparisons confirm that IRSP strikes a favorable balance between computational cost and performance.
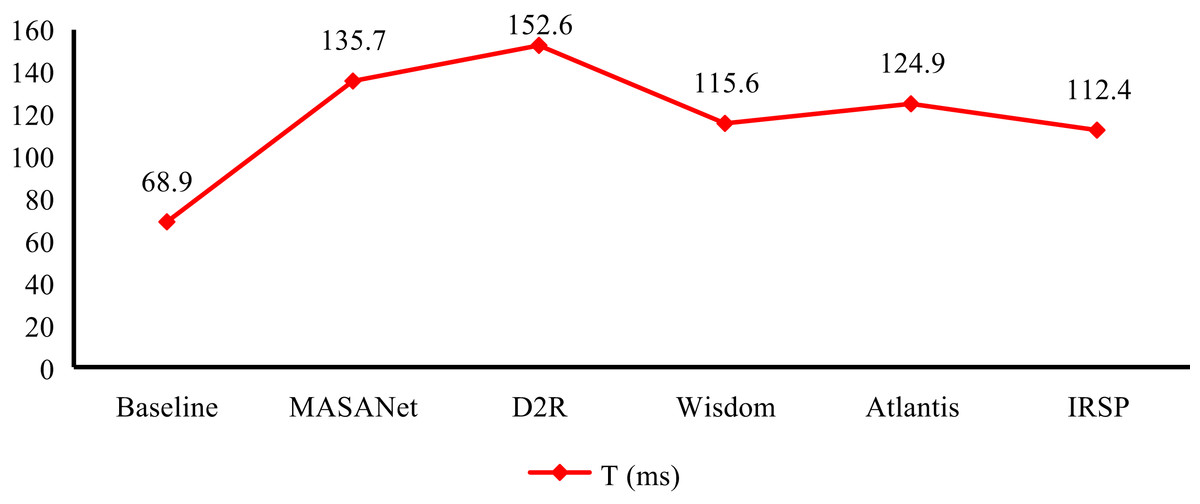
Figure 8: Implement time of IRSP and others.
{kind=link}
Discussion
The comprehensive experimental evaluation demonstrates that the proposed IRSP framework, comprising the SEIC and MDF modules, achieves state-of-the-art performance in both image retrieval and sentiment polarity analysis tasks. While these numerical outcomes (e.g., Acc@10 = 0.989, mAP@20 = 0.981) affirm the model’s technical superiority, a deeper interpretation reveals more profound implications regarding its cognitive, computational, and applied value.
From a cognitive modeling perspective, the success of the SEIC module suggests that augmenting visual input with semantically enriched descriptions aligns closely with human modes of perception and affective judgment. Images, by nature, are often ambiguous or emotionally complex; textual descriptions act as cognitive scaffolds, helping machines disambiguate and anchor emotional interpretation. The model’s performance on BLEU-4 (41.6%) and CIDEr (141.6) highlights its capacity to generate high-fidelity captions that mirror human language patterns. This reflects not just surface-level fluency, but an ability to abstract and prioritize semantically meaningful elements—objects, actions, and relationships—which are often central to emotional interpretation.
The MDF module, by contrast, brings computational depth to the framework. Through wavelet-based decomposition and temporal modeling with Bi-LSTM, it encapsulates both static and dynamic affective cues embedded in the image content. Notably, the use of frequency-domain transformations aligns with psychological evidence suggesting that color gradients, textural contrasts, and spatial composition influence human emotional perception. The model’s gains in mAP metrics (e.g., +3.1% @1 due to MDF) imply that such low- and mid-level features retain crucial discriminative power in emotional inference tasks. Thus, IRSP not only leverages high-level semantics but also mines perceptual subtleties often overlooked in standard CNN-based pipelines. IRSP is shown to have better efficiency in comparison to recent baselines in terms of run time. As an example, IRSP can process a single image in only 112.4 ms as opposed to Wisdom (115.6 ms) and Atlantis (124.9 ms), as illustrated in Fig. 8. This margin, in absolute terms, may not be large per image, but when it is replicated over vast areas, it adds up to large amounts. Extending to video, IRSP considers successive frames as orthogonal inputs; one can thus execute in parallel on the GPU. On our system, this approach yields an analysis rate of 8–9 frames per second, which is faster than real-time video analysis and enough to do near-real-time video surveillance or media monitoring. Although further optimization is necessary to admit streamed video at a constant high load, the present results indicate that IRSP will also work well in this situation.
Objectively, it is essential to acknowledge that while the model performs robustly on benchmarked datasets such as CIRCO, generalizing to noisy, user-generated content or cross-cultural emotional expressions remains an open challenge. For example, visual metaphors or culturally specific symbols may mislead both the captioning and sentiment classification stages. Additionally, emotional ground truth labels are inherently subjective and may not capture the full spectrum of affective nuance, an issue compounded when applied to real-world datasets beyond COCO derivatives. Regarding scalability, we tested the retrieval and sentiment components using CIRCO and the captioning component on MSCOCO, which is several times larger in scale. It matched the performance trends, with SEIC outperforming the baselines on BLEU and CIDEr, which proves that the framework can be applied to larger data as well. Notably, the modularity of IRSP enables effective scalability: SEIC can process considerably bigger sets of caption corpora through Transformer-based parallelization, whereas MDF can tackle large amounts of data to be narrowed down by applying wavelet decomposition before processing with Bi-LSTM. When paired with an average running time of 112.4 ms/image, it points to the system being able to scale up to much larger datasets. We recognize, however, that further testing on more real-world collections (e.g., noisy social media data) is an important area of future work, as discussed in the Conclusion.
It is natural to extend IRSP to temporal data like video. A relatively simple integration is to use the SEIC captioning module frame-by-frame to produce descriptive sequences that are interpolated with the visual embeddings. These multimodal sequences can be introduced into the Bi-LSTM and attention modules already established in our framework to allow the model to learn temporal dependencies between sequences. The outcomes of such temporal modeling should be reflected in retrieval in the form of better distinguishing the visually similar but semantically different sequences (e.g., between a person raising a glass and a person drinking), which should lead to improved mAP at higher retrieval levels. In the case of sentiment polarity analysis, it would be useful to include the frame evolution in case dynamic emotional behavior (e.g., change of expression from neutral to smiling) does not appear in the individual frames. Although we have not used this extension in the present work, IRSP is designed in a very modular way so that the extension could be easily adapted to take a video analytical task, and we have several ideas on how the feature could be used in the future.
In conclusion, IRSP embodies a well-calibrated synthesis of perceptual computing, affective semantics, and multimodal fusion. While grounded in current data and architectures, its design philosophy is forward-compatible with future developments in explainable AI and affective computing. Moving forward, integrating user feedback loops, adapting to cultural contexts, or extending to temporal media (such as video) could further enhance its utility and robustness in practical settings.
Conclusion
To efficiently complete the image retrieval and sentiment analysis, we propose an image retrieval and sentiment polarity analysis method based on dynamic features. Firstly, we introduce a semantic enhancement-based image caption generation technology that effectively compensates for the limitations of a single visual modality in terms of semantic features, adding additional modal information to the model and thereby significantly improving the richness and accuracy of image captions. On this basis, we further develop an image retrieval and sentiment polarity analysis method based on multimodal dynamic features to achieve high-precision image retrieval and accurate sentiment polarity judgment, utilizing enhanced image captioning features. Experiments conclude that our method achieves 0.951 (Acc@1), 0.985 (Acc@5), and 0.989 (Acc@10) on the image retrieval task, while maintaining high efficiency, with a single run time controlled within 112.4 milliseconds. This result has significant application value in image retrieval and sentiment analysis, and is expected to provide a helpful reference and insight for further research and development in related fields.
While the proposed multimodal framework demonstrates high accuracy and efficient performance, several limitations should be acknowledged. First, the effectiveness of sentiment polarity analysis is heavily dependent on the accuracy of the image captioning component; any semantic errors in the generated captions may mislead the sentiment classification process. Second, the model has primarily been tested on structured datasets and may not generalize effectively to real-world, noisy digital media environments with diverse cultural interpretations of emotion. Additionally, the system currently focuses only on visual and textual features, without incorporating auxiliary contextual data such as user comments, metadata, or temporal information, which could further enhance emotional understanding. Future work should aim to improve generalizability and expand the framework to handle richer, more dynamic sources of contextual input.