Online suicide ideation detection (OnSIDe): a context-aware transfer learning approach using BERT-CNN
- Published
- Accepted
- Received
- Academic Editor
- Davide Chicco
- Subject Areas
- Artificial Intelligence, Data Mining and Machine Learning, Natural Language and Speech, Security and Privacy, Social Computing
- Keywords
- Online suicide ideation, Context-aware, Detection, Transfer learning
- Copyright
- © 2025 Balakrishnan et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Online suicide ideation detection (OnSIDe): a context-aware transfer learning approach using BERT-CNN. PeerJ Computer Science 11:e3239 https://doi.org/10.7717/peerj-cs.3239
Abstract
Background
Online suicide ideation is a global concern because of its anonymity and reach, and while automated detection using technologies like natural language processing and machine learning holds promise, accurately distinguishing between genuine distress and non-harmful discussions remains a challenge. This study developed an online suicide ideation detection model using a context-aware transfer learning deep learning approach.
Method
The bidirectional encoder representations from transformers (BERT), a pre-trained context-aware language model, was used with a convolutional neural network (CNN) to develop our proposed model, OnSIDe bidirectional encoder representations from Transformers-convolutional neural network (BERT-CNN). The model was trained, validated, and tested using an English dataset sourced from Reddit (n = 175,975), and subsequently evaluated on a previously unseen dataset from Twitter (n = 9,119).
Results
Experiments revealed OnSIDe BERT-CNN to outperform the baseline models, with an accuracy of 93.25% and an F-score of 92.88%. A reliable performance was also noted for the Twitter dataset (accuracy = 83.77%; F-score = 83.81%).
Limitation
OnSIDe BERT-CNN was solely trained and tested on English datasets.
Conclusion
A context-aware suicide ideation detection model is more accurate and impactful by considering the specific textual nuances surrounding a person’s expressed distress.
Introduction
Suicide is a significant global public health concern with devastating impacts on individuals, families, and communities. According to the World Health Organization (2021), more than 700,000 people die by suicide worldwide each year, making it the 17th leading cause of death globally. Additionally, it has been reported that for every suicide, there are many more suicide attempts, with a prior attempt being the single most important risk factor for suicide in the general population (Chatterjee et al., 2022). It is estimated that a young adult makes a suicide attempt every 90 min, and there has been a significant upward trend in suicide rates among this age group over the past two decades (Carlyle et al., 2018; Ormiston et al., 2024).
Online suicide ideation refers to the expression of suicidal thoughts or intentions in digital spaces such as social media, forums, or chat rooms, ranging from brief mentions to significant planning, role-playing, and failed attempts. With the increasing use of social media and online communication, individuals express their feelings, suffering, and suicidal ideations through these channels (Xie, 2024; Chatterjee et al., 2022). Vulnerable cohorts, such as depressed individuals and adolescents, are known to use social media to express suicidal thoughts, seek advice on how to commit suicide, and even participate in suicide pacts. These behaviors are often exacerbated by the anonymity offered by the platforms (Memon et al., 2018; Waszak et al., 2024). Therefore, early detection of suicide ideation is considered an effective method for preventing suicide attempts and deaths (Chatterjee et al., 2022; Ji et al., 2021; Wang, Jin & Lu, 2024). Online content, particularly textual communications, has emerged as a potential source for detecting suicidal ideation. A review of the literature shows that attempts have been made to automatically detect suicide ideation online using Artificial Intelligence (AI) approaches, including machine learning (Kumar et al., 2020; Chatterjee et al., 2022; Jain, Srinivas & Vichare, 2022; Lim et al., 2023; Yeskuatov, Chua & Foo, 2024) and deep learning (Gaur et al., 2019; Renjith et al., 2021; Lekkas, Klein & Jacobson, 2021; Young et al., 2023; Wang, Jin & Lu, 2024; Malhotra & Jindal, 2024). However, studies on suicide ideation are relatively scant.
Deep learning and suicide ideation detection
Deep learning is a subset of AI and machine learning that involves training artificial neural networks to perform complex tasks, often involving models consisting of multiple layers of interconnected nodes that process and transform data. It has shown remarkable success in domains such as natural language processing (NLP), image processing, and speech recognition. Its ability to automatically extract features and representations from data, coupled with the advent of robust hardware and large datasets, has propelled deep learning into a revolutionary technology, shaping the landscape of modern AI applications and research. Popular deep learning algorithms include recurrent neural networks (RNN) (Sawhney et al., 2018; Deshpande & Warren, 2021), convolutional neural networks (CNN) (Sawhney et al., 2018; Bayram et al., 2022; Singh, Singh & Singh, 2024), long short-term memory (LSTM) (Sawhney et al., 2018; Singh, Singh & Singh, 2024) and bidirectional-long short-term memory (Bi-LSTM) (Haque et al., 2020; Xie, 2024).
A search of the literature revealed several studies on automated suicide ideation detection, most of which adopt context-independent techniques for word embedding. For instance, Aldhyani et al. (2022) developed a CNN-Bidirectional LSTM model using Word2Vec and TF-IDF. Experiments on a Reddit dataset showed their model to outperform XGBoost in detecting suicidal thoughts, achieving 95% accuracy and 95% F-score. A similar study combined LSTM and CNN to detect suicidal intents based on Reddit postings using Word2Vec (Renjith et al., 2021). The dataset was labeled as “no risk, low risk, moderate risk, and severe danger.” The authors reported an accuracy of 90.3% and an F-score of 92.6%.
Gaur et al. (2019) used CNN to detect suicidal tendencies from Reddit data. They compared its performance with the traditional machine learning models, including Random Forest and Support Vector Machine (SVM). The authors found their CNN model to yield the best results in their experimental setups (i.e., 11 and 12 features), with an F-score of 65% and 64%, respectively. Another study using data in the German language developed a predictive model for acute suicidal ideation using CNN and ensemble algorithms such as XGBoost and LogitBoost. Experiments on Instagram posts revealed that CNN combined with stacked ensemble learners achieved an accuracy of 70.2% and an F-score of 74.1% (Lekkas, Klein & Jacobson, 2021). More recently, Singh, Singh & Singh (2024) developed AP-CBWS, a hybrid feature selection method to improve the performance of models like CNN, LSTM, Random Forest, and SVM in detecting suicide ideation. The combination of CNN with ensemble models yielded the best results.
BERT approaches in suicidal ideation
Recently, researchers have begun to explore context-aware approaches, particularly transformers such as bidirectional encoder representations from transformers (BERT) and its variants. Unlike context-independent word embedding approaches such as Word2Vec or GloVE, which do not take word sequence into consideration, context-aware approaches often yield superior results as they can handle ambiguity issues. For instance, consider the following two sentences:
I love apple, as they say an apple a day keeps the doctors away.
I love apple, its functions and sleek design are simply awesome.
A context-independent approach would treat the word “apple” as a fruit in both the sentences whilst a context-aware approach would treat the word differently (i.e., depending on the context).
BERT is a transfer learning pre-trained language model that was trained on massive amounts of textual data prior to being fine-tuned for specific NLP tasks like text classification, question answering, or sentiment analysis with fewer task-specific examples and training data. This transfer learning approach makes BERT highly effective, as it leverages the broad linguistic knowledge gained during pre-training to excel at a wide range of downstream NLP tasks (Devlin et al., 2019; Acs et al., 2023). BERT and its variants are popularly used in various NLP related studies including in politics (Kaliyar, Goswami & Narang, 2021), natural disasters (Deb & Chanda, 2022), and healthcare (Rasmy et al., 2021).
Very few attempts have been made to detect suicide ideation using pre-trained models. For example, Devika et al. (2023) compared BERT and Bi-LSTM using textual data collected from Reddit to detect indicators of depression and suicide. Using a dataset labeled as “self-harm” and “non-self-harm,” the authors reported an accuracy of 81% for BERT and 72% for Bi-LSTM (Devika et al., 2023). Zhang, Schoene & Ananiadou (2021) developed a transformer-based model called TransformerRNN, mimicking the BERT process, and assessed it using a dataset comprising 659 suicide notes, 431 last utterances, and 2,000 neutral messages. A comparative analysis of machine learning and deep learning models showed that TransformerRNN achieved the highest F1-score of 94.9%. A more recent study by Baydili, Tasci & Tasci (2025) compared various pre-trained language models using multiple social media datasets related to depression and suicidal tendencies. Among all combinations of embeddings and classifiers, BERT-SVM achieved the highest accuracy of 79.96%.
Others such as Ananthakrishnan et al. (2022) compared various transformers in detecting suicide ideation using 9,119 tweets (i.e., intended vs. unintended), with RoBERTa yielding the best accuracy of 95.39%. A similar comparison was conducted by Haque et al. (2020), who found RoBERTa to yield the best results, with an accuracy of 98.4% and an F-score of 95.45, in identifying suicidal texts using 3,549 suicidal suggestive messages. Malhotra & Jindal (2024) compared BERT, RoBERTa, DistilBERT, MentalBERT, PsychBERT, and PHSBERT on four mental health datasets, with results indicating PHSBERT achieving the highest F1-score on dataset 2.
Several scholars combined pre-trained models with deep learning algorithms to enhance suicide ideation detection. For instance, Lin et al. (2024) developed a RoBERTa-CNN model, which outperformed standalone RoBERTa with an accuracy of 97.98%. Similarly, Wu et al. (2023) developed a Monitoring-Tracking-Rescuing system using BERT-LSTM, applied to Chinese/Taiwanese social media posts (2,226 no/low risk; 404 high risk), with results demonstrating sensitivity and specificity scores close to 80% for the model, highlighting BERT’s utility for non-English text.
Gorai & Shaw (2024) proposed a BERT-ensemble CNN model, incorporating multiple convolutional layers for detecting suicide risk across Twitter and Reddit posts. Their model achieved high accuracy scores of 99.4% and 97.1%, respectively. However, their study was constrained by a relatively small training set (e.g., 3,663 Reddit samples), which likely impacted its generalizability. Besides, using many CNN layers makes the model more complex and requires more time, memory, and computing power to train. This added complexity can make the model harder to use in real-time or in settings with limited resources, like mental health monitoring systems. Nonetheless, their results underscore the growing trend and effectiveness of combining transformer-based embeddings with deep learning models to improve performance in this domain.
Table 1 summarizes relevant studies on suicide ideation detection using deep learning. While recent research increasingly explores context-aware, transfer learning-based models, this area remains underdeveloped. Prior studies have primarily followed three directions: (i) comparing different transformer variants (e.g., Ananthakrishnan et al., 2022; Baydili, Tasci & Tasci, 2025), (ii) benchmarking transformers against other deep learning architectures (e.g., Haque et al., 2020; Devika et al., 2023), and (iii) developing hybrid models that combine transformers with CNNs or LSTMs (e.g., Wu et al., 2023; Lin et al., 2024; Gorai & Shaw, 2024). Despite advancements, gaps remain in building generalizable and robust models for suicide ideation detection across multiple platforms. Many existing studies rely on limited datasets, focus on a single social media source, or do not evaluate the cross-platform adaptability of their models. Additionally, while hybrid models combining BERT with CNNs have shown promise, their generalization capability on unseen data, especially from different platforms remains largely untested (Gorai & Shaw, 2024).
| Author | Dataset | Embedding | Model | Best results (%) |
|---|---|---|---|---|
| Aldhyani et al. (2022) | TF-IDF and Word2Vec | CNN-Bi-LSTM XGBoost | CNN-Bi-LSTM: | |
| Accuracy: 95% | ||||
| F- score: 95% | ||||
| Gaur et al. (2019) | ConceptNet | SVM-RBF, SVM-L, RF, FFNN, CNN | CNN: | |
| F-score (64–65) | ||||
| Renjith et al. (2021) | Reddit suicidality dataset | Word2Vec | LSTM-attention-CNN combined model, LSTM-CNN, LSTM, CNN, SVM | LSTM-CNN:Accuracy: 90.3, F-score: 92.6 |
| Lekkas, Klein & Jacobson (2021) | Instagram Post/messages | Not mentioned | CNN XGBoost LogitBoost | (CNN) Accuracy: |
| 70.2, F-score: 74.1 | ||||
| Singh, Singh & Singh (2024) | Bag-of-n-grams + GloVe | CNN-ENS with SVM, RF, LSTM, ANN (final layer classifiers); optimized via AP-CBWS (BWO + CSA) | Accuracy: 96.6%, F1: 0.97 | |
| Devika et al. (2023) | FastText, BERT | Bi-LSTM, BERT | (Bi-LSTM) | |
| Accuracy: 81% | ||||
| Baydili, Tasci & Tasci (2025) | Reddit, Twitter, and mental health corpora datasets (n = 6) | ALBERT,BERT, BioBERT, ClinicaBERT, DistilBERT, Electra, RoBERTa, XLNet,Combined | SVM,kNN, Decision Tree Classifier, Neural Network, Efficient Logistic Regression, Ensemble Model | (SVM) Accuracy: 79.96% |
| Zhang, Schoene & Ananiadou (2021) | Kaggle Suicide notes; Last Statement of Prisoners; Reddit | Transformer | TransformerRNN | F-score: 94.9 |
| Ananthakrishnan et al. (2022) | Transformer | BERT, DistilBERT, ALBERT, RoBERTa, and DistilRoBERTa | RoBERTa | |
| Accuracy: 95.4% | ||||
| Haque et al. (2020) | GloVe (in Bi-LSTM), Transformer | BERT ALBERTA RoBERTa, XLNET, Bi-LSTM | RoBERTa: | |
| Accuracy = 98.4 | ||||
| F-score = 95.4 | ||||
| Wu et al. (2023) | Chinese/Taiwanese social media posts | BERT | LSTM-BERT | Sensitivity: 80 |
| Specificity: 80 | ||||
| Lin et al. (2024) | Suicide and Depression Detection (SDD) dataset from Reddit | RoBERTa | RoBERTa, RoBERTa-CNN | RoBERTa-CNN |
| Accuracy: 97.98% | ||||
| Gorai & Shaw (2024) | Twitter-CEASE | BERT | BERT, CNN, BERT-CNN, LSTM, BiLSTM, SVM, Attention-BiLSTM-CNN, BERT-encoded ensembled CNN (proposed) | Accuracy: 99.4% (Twitter), |
| Reddit-CEASE | 97.1% (Reddit) | |||
| Malhotra & Jindal (2024) | Tweets and reddit | Transformer | BERT, DistilBERT, RoBERTa, MentalBERT, PsychBERT, and PHSBERT. | Reddit: Accuracy: 98%, |
Note:
SVM-RBF, Support Vector Machine-Radial Basis Function; SVM-L, Support Vector Machine-Linear Kernel; RF, Random Forest; FFNN, Feedforward Neural Network; CNN, Convolutional Neural Networks; LSTM, Long Short-Term Memory: Bi-LSTM, Bidirectional LSTM (Bi-LSTM); TransformerRNN, Transformer-Recurrent Neural Networks; XLNET, Generalized Auto-Regressive Transformer-XL model.
To address these challenges, our study introduces OnSIDe BERT-CNN, a hybrid model integrating BERT’s contextual embedding capabilities with CNN’s feature extraction strengths. Our approach is guided by prior evidence that CNN architectures yield substantial performance gains across a variety of embedding strategies. We train and evaluate our model on a large-scale Reddit dataset (n = 232, 074) and assess its adaptability on an unseen raw Twitter dataset to explore cross-platform generalization, unlike (Gorai & Shaw, 2024) who trained their model on each dataset. Ablation study is also conducted for comparison purposes (i.e., BERT, CNN, BERT-CNN).
Materials and Methods
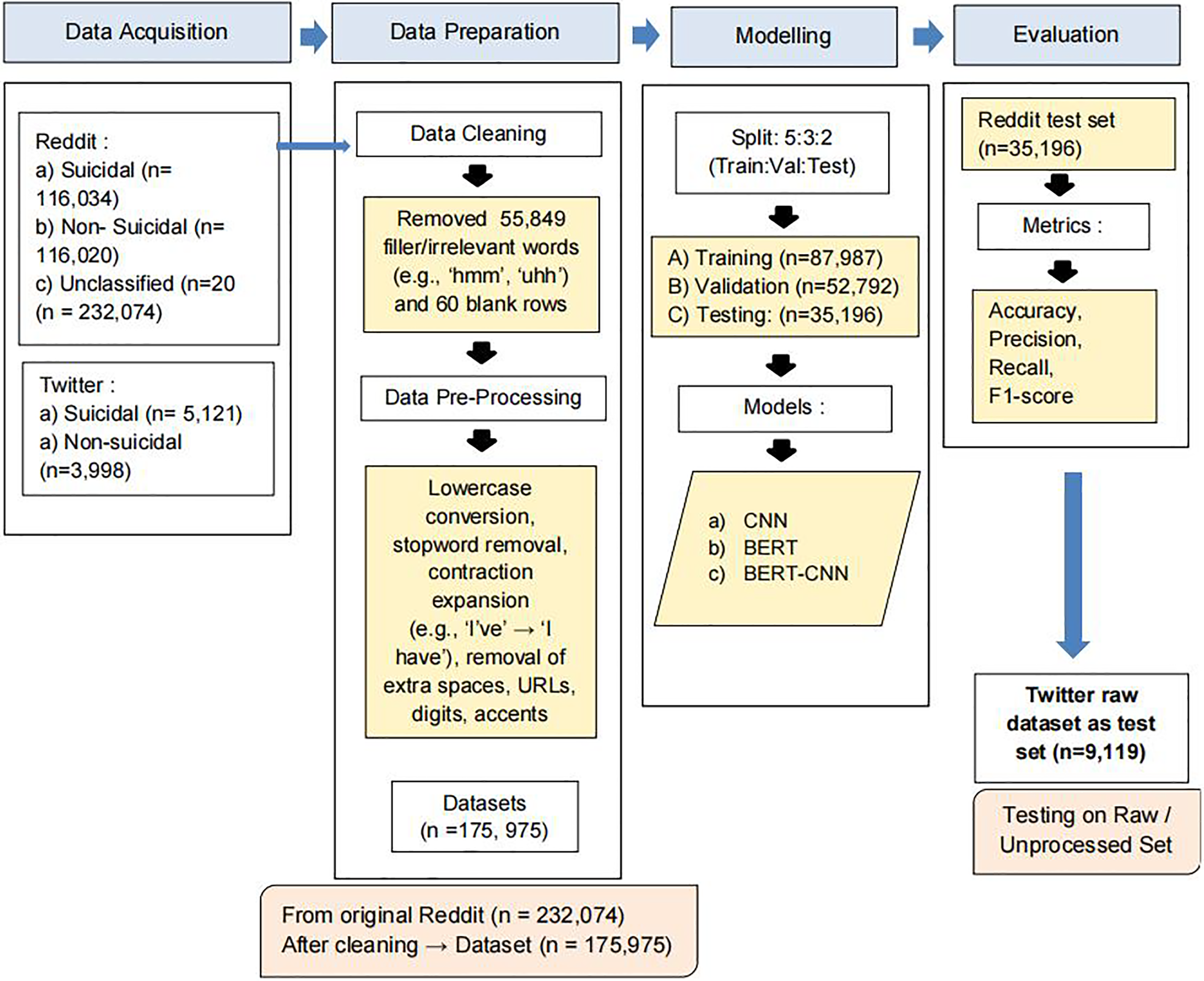
Figure 1 provides a visual overview of the OnSIDe-BERT-CNN pipeline, outlining the process flow involved in model development and testing.
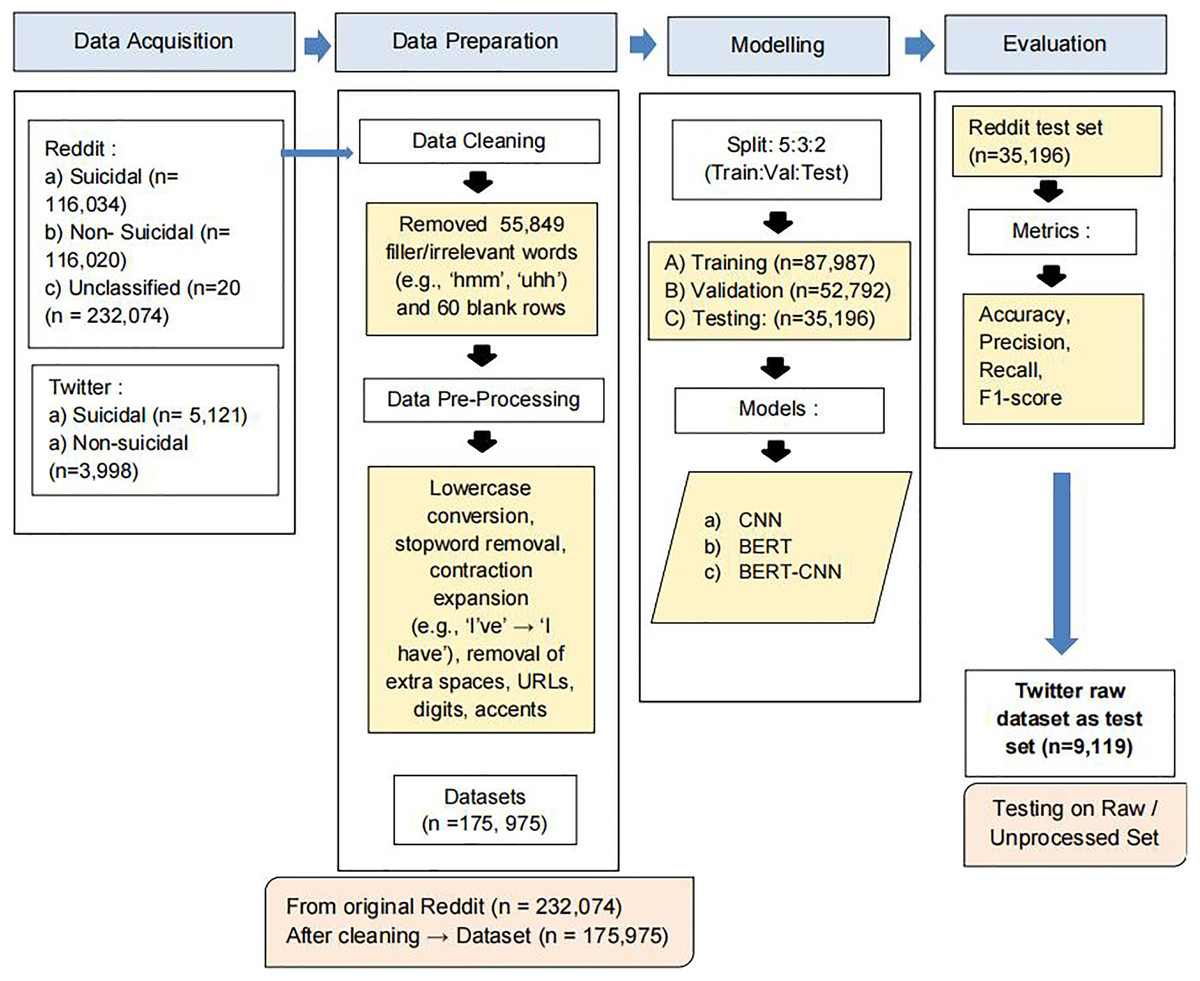
Figure 1: OnSIDe BERT-CNN pipeline.
{kind=link}
Dataset acquisition
In this phase, two labeled social media datasets were sourced, namely from Reddit and Twitter. These were used at different stages of the process flow, as shown in the figure. The OnSIDe BERT-CNN model was trained, validated, and tested using the Reddit dataset (https://www.kaggle.com/datasets/nikhileswarkomati/suicide-watch) (Aldhyani et al., 2022). The dataset contained English textual communication (n = 232,074) scrapped from two subreddits (i.e., SuicideWatch and teenagers). Posts originating from the SuicideWatch subreddit were labeled as suicidal, while those from the teenagers subreddit were labeled as non-suicidal. Contrarily, the Twitter dataset (https://github.com/laxmimerit/twitter-suicidal-intention-dataset) contained 9,119 English tweets, labeled as suicide intended (n = 5,121) vs. unintended (n = 3,998) (Ananthakrishnan et al., 2022).
Data preparation
This stage involves data preparation, specifically cleaning and pre-processing the Reddit dataset. As shown in Fig. 1, data cleaning was performed by removing irrelevant words. For example, we found 55,849 occurrences of filler words such as “hmmm, huh, err etc.”, hence these were removed. Further, 60 blank rows were removed. Next, data pre-processing was performed to standardize the data to facilitate better understanding by the detection model and reduce computational complexity during training. These included converting letters to lowercases (i.e., to ensure case-insensitive analysis and avoid treating the same word with different cases as different words), removing stop words (e.g., “the,” “and,” “is”), extra whitespaces, URLs, accents, digits etc., and expanding contractions (e.g., I’ve to I have). This resulted in a final Reddit dataset containing 175,975 records. It is to note that the Twitter dataset was not subjected to any of these steps as it was meant to be reserved as an unseen raw dataset to assess the generalizability of our final suicide detection model.
Modeling
The next stage involves splitting the Reddit dataset into training, validation, and testing subsets (50-30-20) prior to modeling. This resulted in training (n = 87,987), validation (n = 52,792), and testing (n = 35,196) sub-datasets. Table 2 depicts the breakdown of the binary classes for each of these datasets.
| Labels | Training | Validation | Testing |
|---|---|---|---|
| Suicidal | 34,213 | 20,528 | 13,686 |
| Non-suicidal | 53,774 | 32,264 | 21,510 |
| Total | 87,987 | 52,792 | 35,196 |
We developed three models, namely, BERT, CNN, and BERT-CNN as part of the experiment process. Specifically, BERT and CNN were experimented as baseline models.
BERT
BERT comes in various forms, with the two common categories being small (i.e., base) and large. Their distinctions lie in the depth, parameter count, and capacity for complex text pattern recognition (Devlin et al., 2019; Acs et al., 2023). Specifically, the smaller version (i.e., BERT-base) comprising 12 layers of transformer blocks, 12 attention heads, 110 million parameters with an output size of 768-dimensions was used in this study. This version was chosen as it is more computationally efficient and requires less memory, making it easier to deploy and train on standard hardware compared to BERT-large (Devlin et al., 2019; Ananthakrishnan et al., 2022; Bilal & Almazroi, 2022; Acs et al., 2023).
CNN
CNN is a deep learning algorithm that uses convolutional filters on the input to identify spatial patterns and other data structures (Ajit, Acharya & Samanta, 2020). It is extensively used in tasks involving image and video analyses as it can yield outstanding performances. As CNNs are good in identifying local patterns and categorizing features in the input data, it is also proven to analyze text segments to find complex linguistic patterns that distinguish between content that may indicate suicidal ideation and other content (Ji et al., 2021; Alabsi, Anbar & Rihan, 2023). The CNN model was used in two ways in this study: first, as a baseline model using the conventional Word2Vec embedding technique (CNNWord2Vec) (Gorai & Shaw, 2024). Unlike BERT, this context independent technique represents each word as a single vector as opposed to multiple. Second, CNN was integrated with BERT as an additional layer. This is explained subsequently.
BERT-CNN
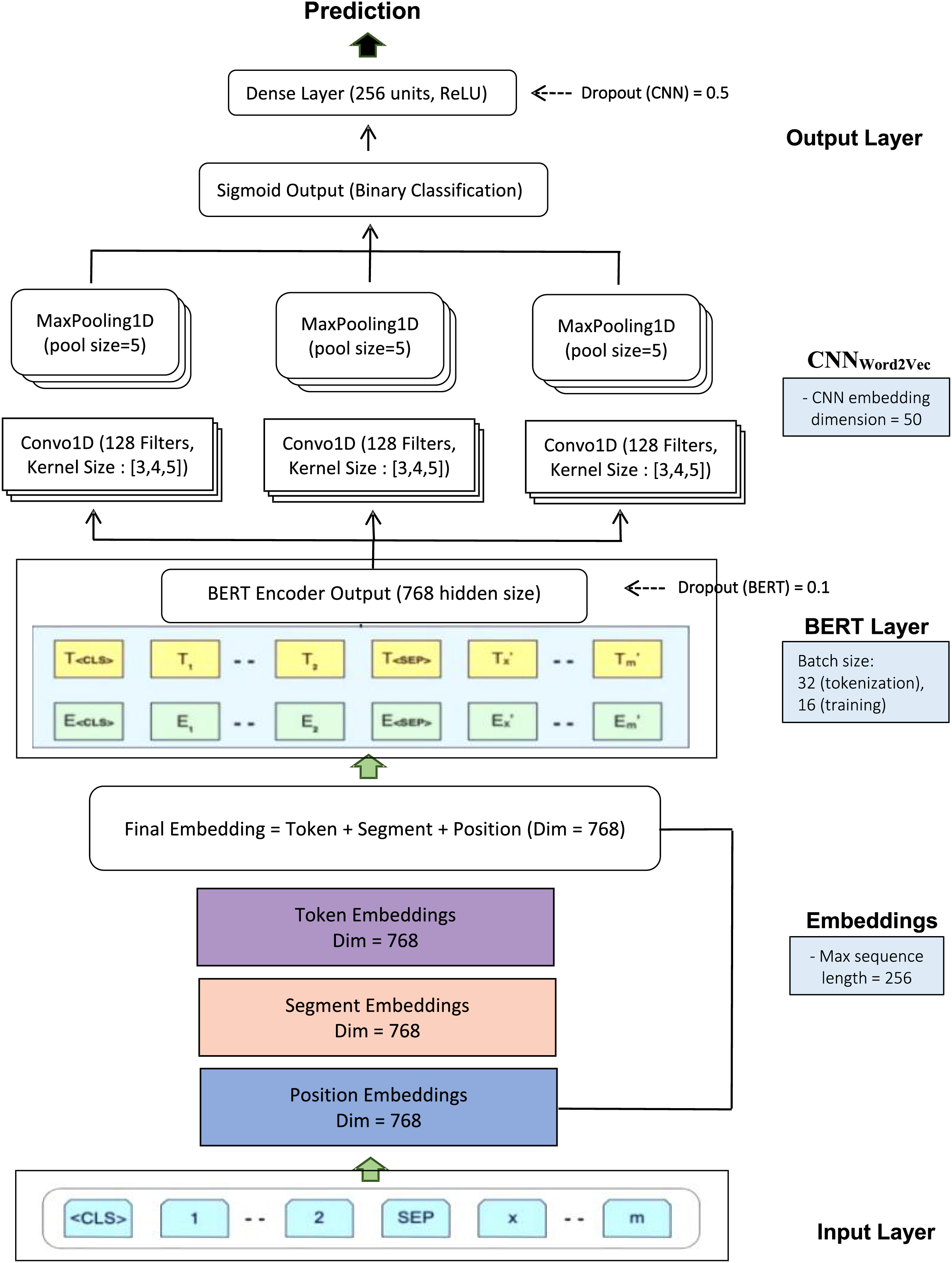
Our OnSIDe BERT-CNN architecture is illustrated in Fig. 2 below, depicting four key layers, input, BERT, CNN and output.
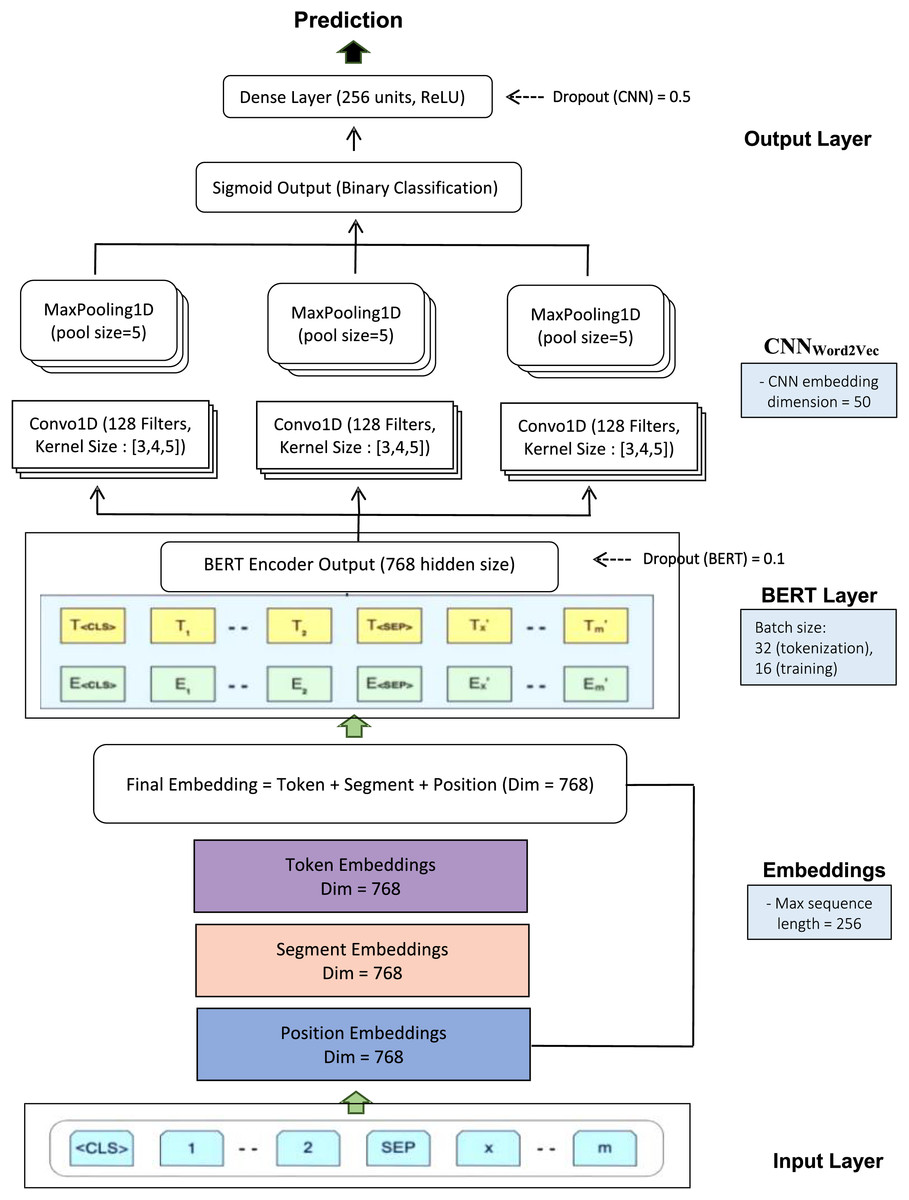
Figure 2: BERT-CNN.
{kind=link}
The input layer accepts texts (as in our study) and converts these into embeddings that capture the meaning (token), position (token position within the sequence), and segment (structure of each token for further processing). This was done using BERT tokenizer (Hugging Face), and each resulting embedding vector has a hidden size of 768, with a maximum sequence length of 256 tokens. These embeddings are summed and passed into the BERT layer, specifically the bert-base-uncased variant (PyTorch), which includes 12 layers, 12 attention heads, and a hidden size of 768. This smaller version of BERT was chosen to balance performance and efficiency, as larger variants like BERT-large (24 layers, 16 attention heads, 1,024 hidden size) impose significantly higher computational demands, making them less practical for resource-constrained environments (Devlin et al., 2019; Balderas, Lastra & Benítez, 2025).
Our BERT model was trained with a batch size of 16 and utilized attention masks to handle padding tokens. The training procedure included optimization using AdamW with a learning rate of 0.00002, a dropout rate of 0.1, and a cross-entropy loss function. The model underwent fine-tuning over three epochs to improve its proficiency in recognizing suicidal content recognition. Training was conducted on a Compute Unified Device Architecture (CUDA)-enabled GPU to accelerate the process.
Following the BERT encoding, the extracted contextual embeddings were fed into the CNN layer, with an embedding layer configured with a vocabulary size of 256 and an embedding dimension of 50. A one-dimensional convolutional layer (Conv1D) with 128 filters and a kernel size of 5 was then applied, using ReLU activation to capture local features. This was followed by a MaxPooling1D layer with a pool size of 5 to reduce spatial dimensions. The output from the pooling layer was flattened and passed through a dense layer with 256 units, also using the ReLU activation function. A drop-out rate of 0.5 was introduced to reduce overfitting.
Finally, a single dense unit with a Sigmoid activation function produced the binary classification output (i.e., suicidal vs. non-suicidal). The CNN model was compiled using the binary cross-entropy loss function and optimized with Adam. Training was conducted over 10 epochs with a batch size of 32, and early stopping (patience = 15) was implemented to prevent overfitting by monitoring validation loss. Although an initial batch size of 32 was set during preprocessing, it was later reduced to 16 during training to address memory limitations on Google Colab.
All the configuration parameters in each layer such as batch size, kernel size and drop-out rate, etc., were determined after iterative testing to balance performance and memory usage. The model configurations, including layer counts, attention heads, optimizers, learning rates, and sequence lengths, are detailed in Table 3 for reproducibility.
| Hyperparameter | BERT | CNN | OnSIDe-BERT-CNN |
|---|---|---|---|
| Layers | 12 | – | 12 |
| Attention heads | 12 | – | 12 |
| Maximum sequence length | 256 | – | 256 |
| Batch size | 16 | 32 | 32 |
| Dropout rate | – | 0.5 | 0.1 |
| Optimizer | AdamW | Adam | AdamW |
| Learning rate | 0.00002 | 0.00002 | 0.00002 |
| Epochs | 3 | 10 | 1 |
| Loss function | Cross-entropy loss | Binary cross-entropy loss | Binary cross-entropy loss |
| Conv1D filters | – | 128 | 32 |
| Kernel size | – | 5 | [3, 4, 5] |
| MaxPooling1D pool size | – | 5 | Adaptive per filter size |
| Dense layer units | – | 256 | Linear layer |
| Output activation | – | Sigmoid | Sigmoid |
| Early stopping patience | – | 15 | – |
| Tokenization max length | 256 | – | 256 |
All the models were developed, trained, and tested using Python 3.7, TensorFlow 2.4.1, Keras 2.4.3, PyTorch 1.7.1, and the Transformers library 4.5.1. These were executed using Google Colab. The complete implementation can be found at DOI 10.5281/zenodo.17422261.
Experiment and evaluation metrics
The final phase involves evaluating the models through experiments, using setups as follows:
- -
CNNWord2Vec—baseline deep learning model using the traditional Word2Vec technique,
- -
BERT—baseline context-aware transfer learning model using the lighter bert-base-uncased variant (BERT-small),
- -
OnSIDe-BERT-CNN—integrated model for online suicide ideation detection using the context-aware transfer learning approach.
All the three models above were experimented on the Reddit dataset. The final OnSIDe-BERT-CNN model was then tested on the unseen Twitter dataset to assess the model’s generalizability to other social media platforms.
The standard evaluation metrics for classification problems were used to assess all the models in this study. These included accuracy, precision, recall, and F-score. Accuracy represents the percentage of correct predictions. Precision measures the accuracy of positive predictions (i.e., the ratio of true positive predictions to the total number of positive predictions) whilst recall measures the model’s ability to capture all relevant instances of a positive class (i.e., the ratio of true positive predictions to the total number of actual positive instances in the dataset) (Ferrell, 2020). The F-score, which balances recall and precision, indicates a model’s accuracy and ability for identifying suicidal content. Higher scores, on a scale from 0 to 1, indicate superior performance for all four metrics (Ferrell, 2020).
Results and Discussion
We present the results of the exploratory data analysis performed on the training dataset, followed by the OnSIDe BERT-CNN performance.
Exploratory data analysis
Figure 3 presents word clouds depicting the top 50 most frequent words in suicidal and non-suicidal texts from the training dataset. In the suicidal class (Fig. 3A), prominent terms such as “want,” “feel,” “think,” “kill,” and “leave” reflect emotional distress, potential self-harm intent, or calls for support. In contrast, the non-suicidal (Fig. 3B) class features more neutral or socially oriented words like “school,” “friend,” “people,” and “day,” indicating every day or casual conversations.

Figure 3: Word cloud for suicidal and non-suicidal posts.
(A) Top keywords in suicidal texts, (B) Top keywords in non-suicidal texts.{kind=link}
The bi-grams of the most used words, detailed in Table 4, further highlight these differences.
| Suicidal text | Non-suicidal text | ||
|---|---|---|---|
| Bigram | Count | Bigram | Count |
| (feel, like) | 6,803 | (feel, like) | 2,144 |
| (want, die) | 3,397 | (year, old) | 821 |
| (want, kill) | 1,477 | (want, talk) | 761 |
| (want, end) | 1,273 | (need, help) | 737 |
| (want, live) | 1,077 | (sub, edit) | 729 |
| (commit, suicide) | 1,075 | (min, craft) | 723 |
| (suicidal, thought) | 1,059 | (good, friend) | 653 |
| (need, help) | 958 | (look, like) | 587 |
| (end, life) | 874 | (want, know) | 548 |
| (year, old) | 815 | (high, school) | 475 |
| (go, kill) | 805 | (girl, like) | 411 |
| (good, friend) | 783 | (want, chat) | 406 |
| (get, bad) | 752 | (discord, server) | 385 |
| (get, well) | 693 | (girl, like) | 376 |
| (die, want) | 661 | (want, play) | 368 |
| (know, anymore) | 650 | (video, game) | 365 |
| (need, talk) | 621 | (like, know) | 350 |
| (anymore, want) | 614 | (text, text) | 338 |
| (feel, bad) | 598 | (feel, bad) | 309 |
| (know, want) | 585 | (year, ago) | 303 |
Suicidal posts commonly include emotionally charged phrases such as “want die,” “commit suicide,” “feel bad,” and “need help,” reflecting ideation, distress, or urgent appeals for support. In contrast, non-suicidal bi-grams like “good friend,” “video game,” “school day,” and “want chat” suggest more routine, everyday interactions. These phrase-level distinctions underscore the emotional and contextual divide between the two classes, reinforcing the presence of intense emotional language in suicidal posts.
Figure 4 shows the text length distribution for both the suicidal and non-suicidal classes. It can be observed that the suicidal text distribution (Fig. 4A) of average text length appears to be more uniformed and even, with most posts falling between 10 to 50 words. In contrast, the non-suicidal text distribution (Fig. 4B) exhibit a right-skewed distribution, with a high concentration of posts under 20 words, indicating that non-suicidal texts tend to be shorter in general. This observation suggests that individuals expressing suicidal thoughts often have more to convey and tend to write longer posts (Litvinova et al., 2017). For model development, this insight supported our decision to set the maximum sequence length to 256 tokens during tokenization, ensuring that longer suicidal posts were not truncated, while maintains the model to handle shorter non-suicidal inputs efficiently.
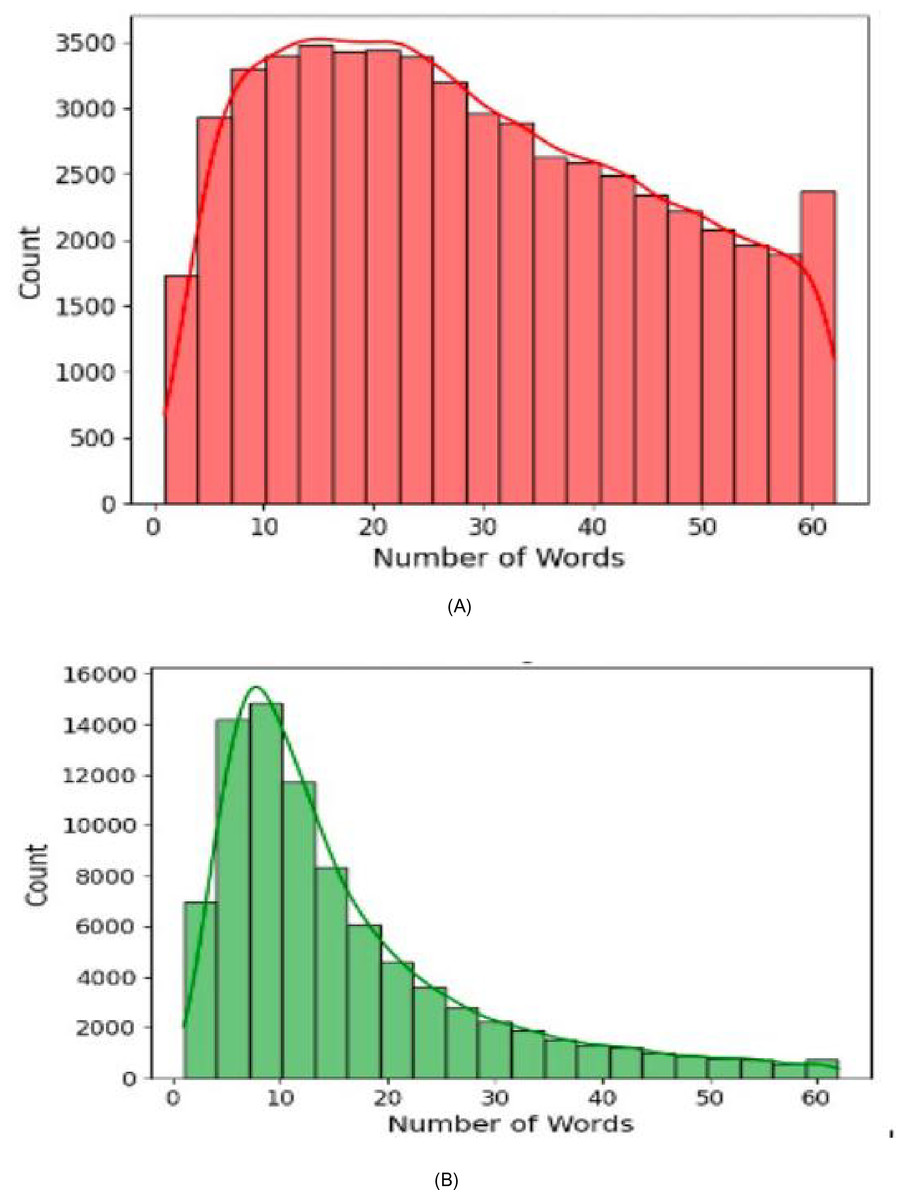
Figure 4: Text length distribution for suicidal and non-suicidal posts.
(A) Distribution of text length—suicidal text, (B) Distribution of text length—non-suicidal text.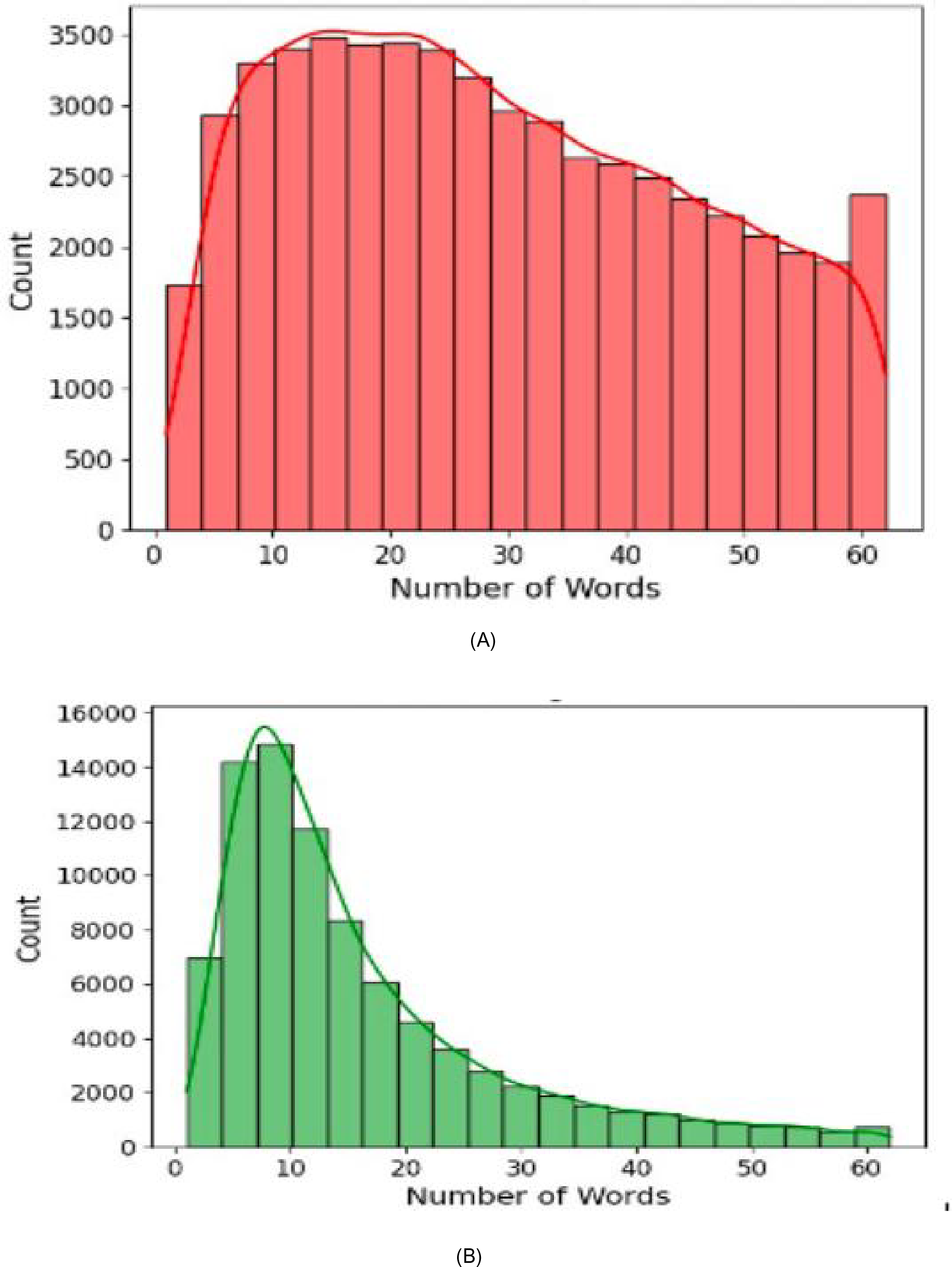{kind=link}
Finally, Table 5 shows the mean scores for sentiment (i.e., positive vs. negative) and emotions analyzed using Valence Aware Dictionary and sEntiment Reasoner (VADER) and the Empathic Prompting through Analysis of Text (EMPATH), respectively. VADER is a sentiment analysis tool that uses a lexicon and rules to analyze text for positive, negative, whilst EMPATH is a tool that uses deep semantic analysis to classify text into different emotional and subject categories, such as sadness, rage, or fear. It can be observed that mean scores for all the negative emotions analyzed were considerably higher for the suicidal texts compared to the non-suicidal texts. Of these emotions, sadness yielded the highest score (i.e., 0.7105). As for sentiment analysis, although positive sentiments were quite similar, a higher negative score was noted for suicidal texts than non-suicidal texts. This observation is consistent with research conducted by Trimble & Chandran (2021) and other studies (Al-Dajani & Uliaszek, 2021) highlighting the significant correlation between sadness and suicidal thoughts and actions. As for sentiment analysis, although positive sentiments were quite similar, a higher negative score was noted for suicidal texts than non-suicidal texts, which also aligns with previous studies (Sumner et al., 2021; Joharee, Hashim & Shah, 2023).
| Analysis | Categories | Suicidal texts | Non-suicidal texts |
|---|---|---|---|
| Emotion analysis | Sadness | 0.7105 | 0.1193 |
| Anger | 0.1926 | 0.0277 | |
| Fear | 0.3960 | 0.0854 | |
| Sentiment analysis | Positive | 0.2126 | 0.2279 |
| Neutral | 0.4663 | 0.5852 | |
| Negative | 0.3211 | 0.1869 |
Online suicide ideation detection performance
Table 6 presents the performance metrics of the three models based on the Reddit dataset (i.e., macro average). Results are presented for both the validation and testing datasets.
| Metrics | Model | |||||
|---|---|---|---|---|---|---|
| Validation | Testing | |||||
| CNN | BERT | BERT-CNN | CNN | BERT | BERT-CNN | |
| Accuracy | 87.50 | 88.50 | 91.00 | 90.00 | 90.50 | 93.25 |
| Precision | 87.00 | 88.50 | 91.50 | 89.00 | 90.00 | 93.00 |
| Recall | 86.50 | 88.00 | 90.75 | 89.00 | 90.00 | 92.76 |
| F-score | 86.75 | 88.25 | 91.12 | 89.00 | 90.00 | 92.88 |
The results show that OnSIDe-BERT-CNN consistently outperformed the baseline models across both validation and testing datasets, yielding performance scores more than 90% for all the metrics. Specifically, the model ranged between 91% and 91.5% in the validation phase, and yielded better performance in the testing phase, with scores ranging from 92.76% to 93.25%. Specifically, the model achieved an accuracy of 93.25% and an F-score of 92.88%. This is probably due to the integration of BERT’s in-depth contextual understanding and CNN’s capacity to extract a variety of features from textual content (Bilal & Almazroi, 2022; Gorai & Shaw, 2024). The model probably benefits from the natural language understanding capabilities of BERT, which aids in its ability to comprehend complex textual nuances connected to suicide ideation. The CNN component, meanwhile, effectively grasps a broad range of information from the input text, improving the model’s ability to recognize minor indicators of suicidal content. The outstanding results of the BERT-CNN is probably a result of the combination of the best features from both architectures.
In contrast, while the independent CNN and BERT models both produce respectable results, their individual approaches may lack the depth and flexibility needed for correctly recognizing suicidal ideation. Further, a comparison between CNN and BERT indicates a slight improvement between CNN and BERT (i.e., 1%) for precision, recall and F-score. Although both the models yielded impressive results, BERT outperformed CNN in detecting suicide ideation. This concurs with previous findings showing BERT or its variants to outperform other conventional models (Haque et al., 2020; Lin et al., 2024;Malhotra & Jindal, 2024; Gorai & Shaw, 2024).
Further, the confusion matrix in Table 7 shows a low proportion of misclassifications relative to correct classifications, offering a more detailed view of BERT-CNN model’s predictive performance. To further illustrate this, Table 8 presents sample posts that were correctly and incorrectly classified, providing insight into the types of content the model handles well and where it may encounter challenges.
| True labels | Predicted labels | Validation set | Testing set | ||||
|---|---|---|---|---|---|---|---|
| BERT | CNN | BERT-CNN | BERT | CNN | BERT-CNN | ||
| Non-suicide | Non-suicide | 29,933 | 29,620 | 30,528 | 20,090 | 19,671 | 20,425 |
| Suicide | 2,331 | 2,644 | 1,736 | 1,420 | 1,839 | 1,085 | |
| Suicide | Non-suicide | 2,465 | 2,769 | 1,907 | 1,420 | 1,708 | 1,292 |
| Suicide | 18,063 | 17,759 | 18,621 | 12,266 | 11,978 | 12,394 | |
| Example posts | Suicidal | Prediction accuracy | |
|---|---|---|---|
| Suicidal | Non-suicidal | ||
| “I am scared that I’m going to kill myself soon, I just want things to stop being shit.” | ✓ | Correct | |
| “My gut is begging me to commit suicide.” | ✓ | Correct | |
| “The reviews on the dildo said weak suction cup. Yet I can lift my whole desk with it.” | ✓ | Correct | |
| “Day 41 of posting until I get a girlfriend. Why do exams exist ahhhhhhhhhhhh.” | ✓ | Correct | |
| “Don’t know how much longer I can carry on. I wake up every morning, cursing myself for not dying in my sleep.” | ✓ | Incorrect | |
| “I feel a certain sense of control and calmness and I’m actually looking forward to the time I have to make the decision.” | ✓ | Incorrect | |
Generalization performance on Twitter
As stated in ‘Data Preparation’, the suicide ideation detection model was tested on raw unseen Twitter dataset to assess its generalizability. Table 9 shows the performance scores.
| Metrics | BERT-CNN |
|---|---|
| Accuracy | 83.77 |
| Precision | 85.44 |
| Recall | 83.77 |
| F-score | 83.81 |
Overall, our model demonstrates strong performance when evaluated on previously unseen data, achieving scores exceeding 83% across all metrics. This indicates that the OnSIDe BERT-CNN model is not only effective but also consistently reliable. The high-performance metrics also demonstrates its real-world applicability and effectiveness in detecting suicidal ideation within online textual communications, making it a valuable tool for identifying and addressing such critical issues in practical scenarios.
Performance comparison with previous studies
A direct comparison between OnSIDe BERT-CNN and models from previous studies is challenging due to variations in datasets and pre-processing methods, even when the data source is the same. However, when evaluated on the Reddit dataset (see Table 1), our model demonstrates superior performance. For instance, compared to scholars who have used context independent embeddings such as by Renjith et al. (2021) and Gaur et al. (2019), our model yielded better suicide ideation detection accuracy, highlighting the advantage of leveraging contextualized embeddings from BERT in capturing nuanced language patterns associated with suicidal expression.
As for studies that have used transformers, OnSIDe BERT-CNN demonstrated improved performance in key metrics. For example, it outperformed the model by Devika et al. (2023), achieving an accuracy of 93.25% compared to 81%. It also surpassed (Wu et al., 2023) in recall (92.76% vs. 80%), although it should be noted that the latter used a dataset containing non-English texts, which may affect comparability.
However, some studies have reported even higher performance using more resource-intensive models. Haque et al. (2020), for example, achieved 95.21% accuracy with RoBERTa on the Reddit dataset, slightly higher than our model’s 93.25%. Similarly, Ananthakrishnan et al. (2022) found that RoBERTa reached an accuracy of 95.4% on the Twitter dataset, compared to 83.77% for OnSIDe BERT-CNN. This performance gap may stem from RoBERTa’s pre-training on a larger and more diverse corpus, which allows it to capture subtle linguistic cues more effectively. Nonetheless, the specific contribution of these factors remains uncertain, as details about training parameters are often limited or unclear (Haque et al., 2020).
A similar pattern was observed among studies that have developed hybrid transformer-CNN models, for example, Lin et al. (2024) reported 97.98% accuracy with a RoBERTa-CNN model, while (Gorai & Shaw, 2024) trained and tested their BERT-ensemble CNN model on both Reddit and Twitter datasets, achieving 99.4% and 97.1% accuracy, respectively. In contrast, OnSIDe BERT-CNN was trained and tested on Reddit and further evaluated on unseen Twitter data, demonstrating stronger generalizability across platforms. Further, Gorai and Shaw’s use of five CNN layers increased model complexity and computational demands compared to our single-layer CNN, which offers a more efficient and scalable solution without sacrificing performance. Overall, OnSIDe BERT-CNN offers a more balanced approach, combining strong performance with practicality for real-world deployment.
Conclusion, limitation and future work
This study showed that context-aware models like BERT can be combined with deep learning (CNN) to detect suicidal thoughts in social media posts. The proposed OnSIDe BERT-CNN model was trained, validated, and tested on Reddit data and further evaluated on unseen Twitter posts. Its strong performance across both datasets highlights its reliability and potential adaptability across platforms. These findings support the growing use of transformer-based embeddings in mental health detection and suggest that hybrid architectures can enhance performance in complex language tasks.
However, there are some limitations. First, the model was developed and tested exclusively on English-language posts, limiting its applicability to multilingual or non-English-speaking populations. While BERT supports multilingual variants, future work should explore language transferability and cross-cultural sensitivity. Second, we excluded other BERT variants such as RoBERTa and DistilBERT as baselines to maintain experimental focus and computational feasibility. Future studies could extend this work by benchmarking OnSIDe BERT-CNN against other transformer-based models to better explore the trade-offs between performance and efficiency, such as how BERT-small’s lighter architecture balances accuracy with lower resource demands compared to other variants such as RoBERTa.
Finally, ethical considerations present a critical limitation. Although this study emphasizes technical performance, the broader societal implications of using AI for suicide detection warrant careful attention. Analyzing user-generated content raises serious concerns around privacy, autonomy, and data governance. There is also a risk that such models may reflect or reinforce biases, particularly across cultural, linguistic, or demographic groups, leading to unequal or even harmful outcomes. Furthermore, the consequences of false positives or negatives in this context can be serious, underscoring the need for cautious, ethically guided deployment. These challenges highlight the need for strong ethical safeguards in the development and deployment of AI-based suicide ideation models.
Our OnSIDe BERT-CNN model delivers strong performance and offers practical advantages that enhance its real-world utility. By combining a smaller BERT variant with CNN, it achieves a balance between accuracy and computational efficiency, making it suitable for real-time use in resource-constrained settings such as mobile apps or online mental health platforms. Its reliable cross-platform performance also supports scalability across different social media sources. This study advances the field by showing that hybrid models can be both effective and deployable, contributing to the development of responsible AI tools for early mental health intervention while reinforcing the need for ethical safeguards in sensitive applications like suicide detection.