
Privacy-preserving household load forecasting based on non-intrusive load monitoring: A federated deep learning approach
- Published
- Accepted
- Received
- Academic Editor
- Zhiyi Li
- Subject Areas
- Security and Privacy, Neural Networks
- Keywords
- Federated learning, Non-intrusive load monitoring, Household load forecasting, Privacy-preserving data mining, Integrated prediction, Deep learning
- Copyright
- © 2022 Zhou et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2022. Privacy-preserving household load forecasting based on non-intrusive load monitoring: A federated deep learning approach. PeerJ Computer Science 8:e1049 https://doi.org/10.7717/peerj-cs.1049
Abstract
Load forecasting is very essential in the analysis and grid planning of power systems. For this reason, we first propose a household load forecasting method based on federated deep learning and non-intrusive load monitoring (NILM). As far as we know, this is the first research on federated learning (FL) in household load forecasting based on NILM. In this method, the integrated power is decomposed into individual device power by non-intrusive load monitoring, and the power of individual appliances is predicted separately using a federated deep learning model. Finally, the predicted power values of individual appliances are aggregated to form the total power prediction. Specifically, by separately predicting the electrical equipment to obtain the predicted power, it avoids the error caused by the strong time dependence in the power signal of a single device. In the federated deep learning prediction model, the household owners with the power data share the parameters of the local model instead of the local power data, guaranteeing the privacy of the household user data. The case results demonstrate that the proposed approach provides a better prediction effect than the traditional methodology that directly predicts the aggregated signal as a whole. In addition, experiments in various federated learning environments are designed and implemented to validate the validity of this methodology.
Introduction
Since AC power cannot be stored, the power generation capacity of the power plant must reach a stable dynamic balance with the power consumption (López et al., 2015), in order to guarantee that the power grid can operate stably and efficiently, reasonable power supply plans and power dispatching methods need to be developed, and accurate power forecasting is a necessary condition. With the continuous growth of the world’s population, the demand for energy from mankind is increasing day by day. At present, domestic dwellings account for about 20%–40% of the world's total energy use, and the household demand load often has a significant impact on the peak load of seasonal and daily electricity (Wu et al., 2014). Due to the inherent uncertainty of distributed renewable energy resources (Li et al., 2022a, 2022b), the renewable integration also brings new challenges to household load forecasting. Accurate forecasting of household electricity demand is not only a prerequisite for guaranteeing the safety and stability of the power grid, but also for peaking and flattening valleys by means of floating electricity prices and balancing the supply and demand relationship at peak electricity consumption.
Literature review
At present, load forecasting methods commonly used abroad can be separated into statistical methods (e.g., the non-linear extrapolation method (Wang et al., 2012; Nazih, Fawwaz & Osama, 2011; Sadaei et al., 2019), time series method (Aly, 2020; Gasparin, Lukovic & Alippi, 2022; Wang, Xia & Kang, 2010, etc.) and machine learning forecasting methods (e.g., artificial neural networks (ANN) (Zeng & Qiao, 2013; Yildiz, Bilbao & Sproul, 2017; Cui, Wang & Yue, 2019; Kumar, Mishra & Gupta, 2016), support vector machines (SVM) (Shi, Li & Yu, 2009; Li & Gu, 2013; Liu et al., 2018, etc.). Since a single forecasting method often has various defects, the combined forecasting method is gradually applied to the research of power system load forecasting, and its performance is better than all independent load forecasting models (Ziel & Liu, 2016). Chen & Chang (2004) proposed a load forecasting method based on user clustering. After clustering historical load curves, wavelet analysis is proposed to predict the future 24-h load curve. Reference (Stephen et al., 2015) compared the performance of seven existing load forecasting technologies, including linear regression, ANN, SVM, and their variants on two commercial buildings and three residential household data sets. The results show that these traditional system-level load forecasting methods can provide good forecasts for commercial buildings, but perform poorly on household data. As for load prediction at the household level, there are still few reference works, and most of the existing forecasting methods directly predict the total power, such as Kalman filter (Guan et al., 2013; Sharma et al., 2020; Zheng, Chen & Luo, 2019), Autoregressive comprehensive moving average model (Stephen et al., 2015; Lee & Ko, 2011; Kuster, Rezgui & Mourshed, 2017), etc.
Research on household or residential electricity demand estimation currently takes several different ideas, including evaluating and improving existing load forecasting techniques, developing and researching new methods, or a combination of the two. Wang et al. (2018) introduced a deep recursive neural network to learn and correlate shared information between customers and solve the problem of overfitting. The performance of this method on the Irish housing data set exceeds the autoregressive integrated moving average model (ARIMA), SVM, and classic recurrent neural networks. Ponoćko & Milanović (2018) proposed a convolutional-long short-term memory neural network (CNN-LSTM) model with selective autoregressive characteristics to enhance single-step-ahead power load forecasting. This improvement can be observed in the three spatial granularities of apartments, floors, and building floors and achieves higher prediction accuracy. Recently, some scholars have proposed a household prediction method based on NILM, which can be more accurately used for household-level power prediction. The reason is that certain equipment used alone may have a strong time dependence, such as air conditioning. In summer or winter, we turn on the air conditioner but it is not turned on 24 h a day. In spring or autumn, it is only turned on occasionally, which means that the air conditioner changes over time. When different appliances are aggregated, the time dependence of this single appliance may be broken. Therefore, predicting the total power distribution of the entire family may be less accurate than predicting the power distribution of a single appliance. Li et al. (2021) proposed a method for household electricity consumption prediction based on NILM, which combines the correlation of electrical behavior in its state duration, and the experiment has good accuracy, but this method does not consider time comprehensively information. Fang et al. (2020) developed a NILM algorithm for analyzing the operating characteristics of different appliances. Dinesh, Makonin & Bajić (2020) proposed a new method for single-household electricity consumption prediction based on NILM and aggregated spectral clustering, and used four public data sets for testing. However, this method has a high error, does not take advantage of deep learning, and does not describe the part of data preprocessing. Such deep learning based prediction methods have also been the subject of research in recent years since rich training data yield the expected model performance and deep learning based methods have a great number of trainable parameters. At present, there are very few existing researches on this kind of household-level load forecasting based on NILM.
In addition, if the predictive model is to be applied to a wider range of electricity consumers and appliances, sufficient electricity demand data must be collected from multiple data owners, but multi-source load data may cause privacy disputes (Wang et al., 2021). In practice, some households may be reluctant to share data with others, especially when power data information is stored in a central server or during transmission. Due to the frequent exchange of information, it is easy for a third party to obtain power data (Li et al., 2020). Currently, many countries have promulgated specific laws. For instance, the “Network Security Law” promulgated in 2017 clearly requires that the collected user information should be strictly confidential (Li, Li & Wang, 2022). Thus, to resolve the above-mentioned questions and achieve a balance between consumer privacy protection and data utilization, federated learning is proposed. Federated learning does not need to collect raw data, that is, the private data of family users does not need to be uploaded to the central server for training. Each family participant can conduct model training locally, and finally, just upload the updated model parameters to the cloud server (Yang et al., 2020). The framework proposed by federated learning balances the relationship between data utilization and privacy protection, and in the process improves the performance of the co-training model. At present, there is also a very small part of the literature discussing the application of federated learning in electric energy. For example, Wang et al. (2021) proposed a federated learning method for power consumer feature identification. This method was composed of privacy protection principal component analysis and FL-ANN model. This model has been proven to perform better. Briggs, Fan & Andras (2021) used FL-LSTM for energy demand forecasting, preserving the data privacy of energy consumers, and compared a centrally trained approach with a localized training approach. In addition, how to apply federated learning to the literature at the household load level is also an urgent and challenging issue.
Contribution of this article
In view of the above, most of the current household load forecasts are directly based on the total power forecast as a whole, which will cause large errors. As for the few integrated prediction methods based on NILM, there are also a series of problems such as low prediction accuracy, lack of data preprocessing, not taking advantage of deep learning, or not considering the comprehensive connection of time. In addition, the centralized model is vulnerable to external attacks, which may lead to third parties having the opportunity to obtain load data. In particular, load information may be destroyed when stored in a centralized server or during transmission.
This article presents for the first time a novel federated deep learning prediction model based on NILM. This method integrates federated learning and Bi-directional long short-term memory network-Attention mechanism (BiLSTM-Attention). The following are the main contributions:
(1) This article presents a load prediction method based on federated deep learning (FedDL), which combines federated learning and BiLSTM-Attention. For all we know, this is the first study of federated learning in household load forecasting based on NILM. In this prediction method, under the precondition of guaranteeing the accuracy of the forecast, the data of the users in the house is not leaked, and the data can be isolated to ensure that the data of the users in the house is not leaked, and meet the needs of user privacy protection and data security. On the precondition of guaranteeing the accuracy of the prediction, while reducing the data security risk, it can also learn from the electrical power of other households.
(2) A method based on NILM to predict user household energy consumption is proposed. The NILM technology extracts a single load pattern from the historical total load demand, avoiding the strong time dependence of a single device. Experiments demonstrate that the integrated prediction method based on NILM has better prediction results than the traditional method that directly predicts the aggregated signal as a whole.
(3) Use the data decomposed by the CNN-LSTM hybrid deep learning model to test the proposed federated deep learning prediction model to validate the validity of the proposed model; In addition, experiments in various federated learning environments are designed and implemented to validate the validity of this methodology.
Organization of this article
The main points of this article are as follows: Section 1 introduces the relevant background and relevant work on household load forecasting; Section 2 presents the associated theories of machine learning; Section 3 mainly proposes the federated deep learning model, and introduces the specific process of training this model. Section 4 performs the relevant training and testing of the proposed FedDL model using the data obtained based on the NILM, and analyzes the test results. Section 5 summarizes this article.
Related preliminary work
Convolutional neural network (CNN)
Due to their powerful learning and generalization capabilities, artificial neural networks are widely used to deal with pattern recognition problems in the engineering field (Shi et al., 2008; Hou et al., 2020). This article uses CNN to extract data features in the data preprocessing part. Eq. (1) is the output of the convolutional layer:
(1) where represents the weight of the convolutional layer; indicates the bias term of the filter; and are the input and output in the convolution process (Lawrence et al., 1997), separately. The nonlinear activation function is:
(2)
(3)
The pooling function represents the pooling operation, represents the output after the pooling layer.
Bi-directional long short-term memory network-attention mechanism
Long short-term memory network (LSTM)
LSTM is a typical recurrent neural network, which is particularly suitable for dealing with time-series related pattern recognition problems. Fig. 1 shows the LSTM structure.
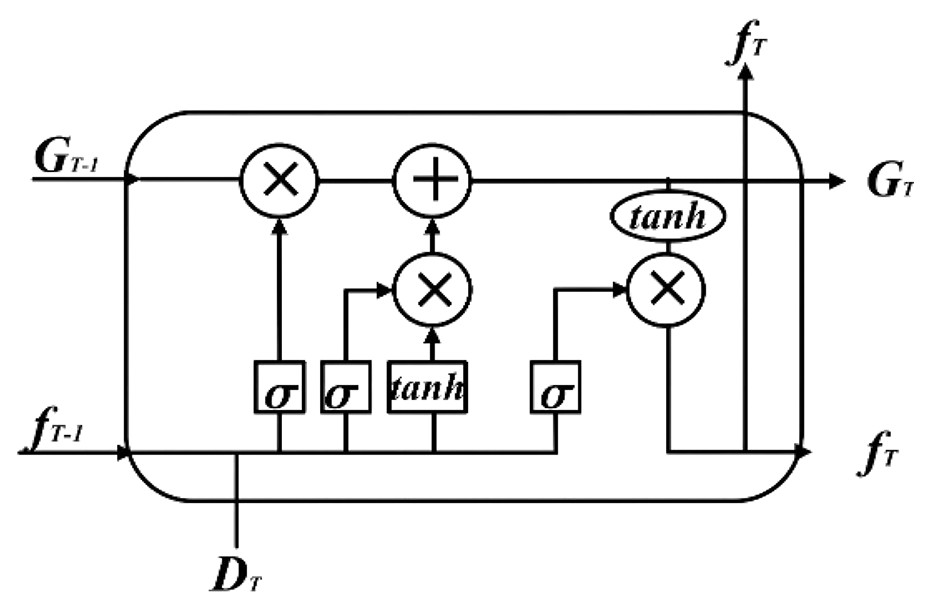
Figure 1: LSTM structure diagram.
{kind=link}
The input parameters are the memory cell state and hidden layer state at time , and the input sequence element value at time T. The output parameters are the memory cell state and the hidden layer state at time T. The corresponding calculation equation in Eqs. (4)–(8):
(4)
(5)
(6)
(7)
(8)
(9) where represent the weight matrix of input gate, forget gate, output gate, and memory unit state respectively; represent the bias terms of each gating unit and memory unit (Lindemann et al., 2021); represents the sigmoid function (Zhang et al., 2021); means that the corresponding elements of the two vectors involved in the operation are multiplied.
BiLSTM
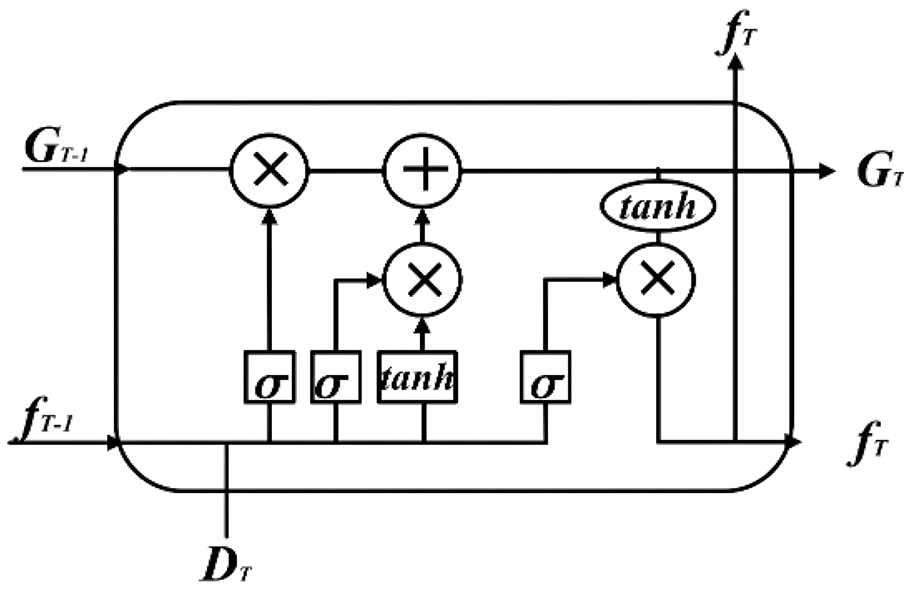
The BiLSTM network has the function of capturing the characteristics of the information before and after (Liu & Guo, 2019). Since in the actual power system, the power load data is a time-varying series of data and non-linear, its load at a certain moment is not only influenced by other factors (such as holidays and social environment), but also simultaneously associated with the past input features, while the future input features can also reflect the present load features to some extent (Liu, Lee & Lee, 2020). Therefore, in order to effectively obtain the time-series variation features about time, BiLSTM is used to mine the intrinsic connection between the current data and the data of past and future moments, which is shown in Fig. 2.
Figure 2: BiLSTM structure diagram.
{kind=link}
The BiLSTM hidden layer state at moment T can be found by the forward hidden layer state and the backward hidden layer state in two parts. The forward hidden layer state is decided by the current input and the forward hidden layer state at moment . The backward hidden layer state is decided by the current input and the backward hidden layer state at moment . The calculation formula is shown below, where ( = 1, 2…, 6) is the weight from one cell layer to another cell layer.
(10)
(11)
(12)
Attention mechanism
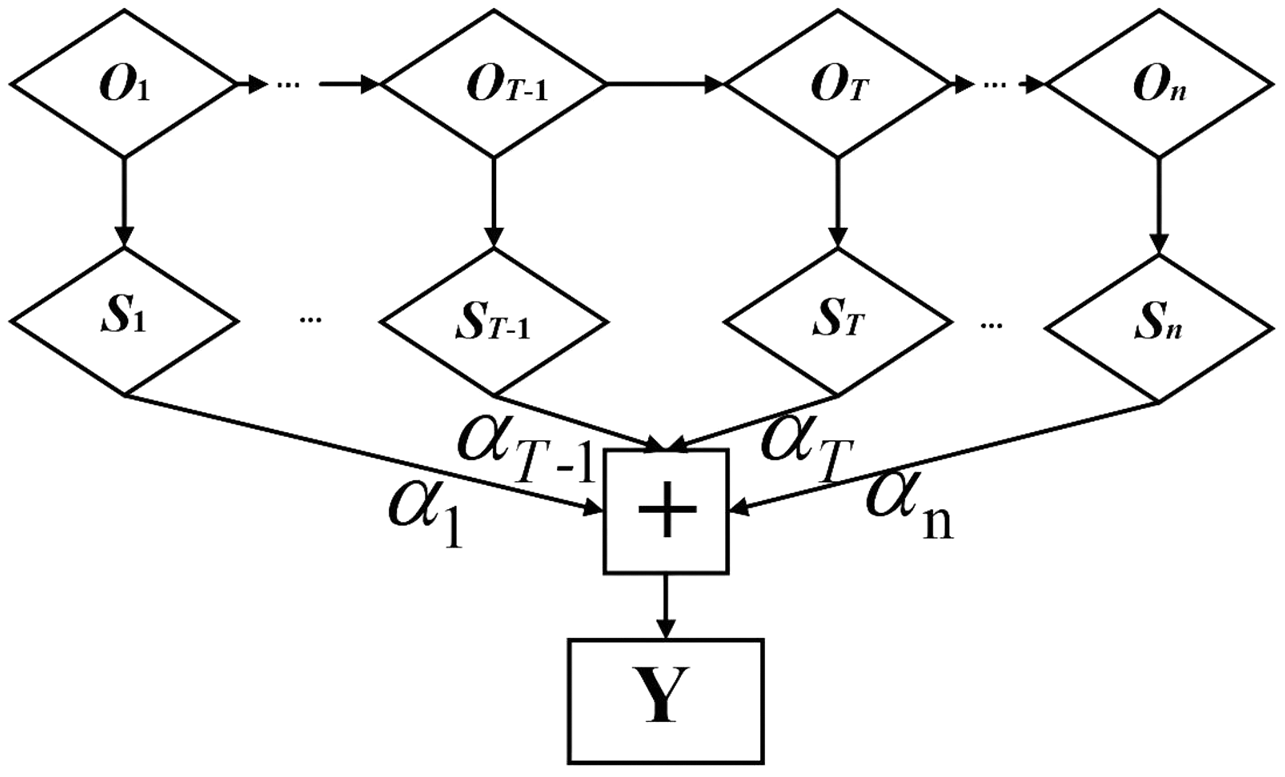
The attention mechanism highlights key information through weight distribution to ensure that features are not lost in the model training process, so it can more effectively mine the long-distance data features of time series with correlation (Bin et al., 2018). The attention mechanism takes the timing sequence of the input power load-related data as the reference object of the neural network (Ji et al., 2019). Combined with BiLSTM, the neural network spontaneously selects to retrieve the information from the BiLSTM. Its basic structure is shown in Fig. 3.
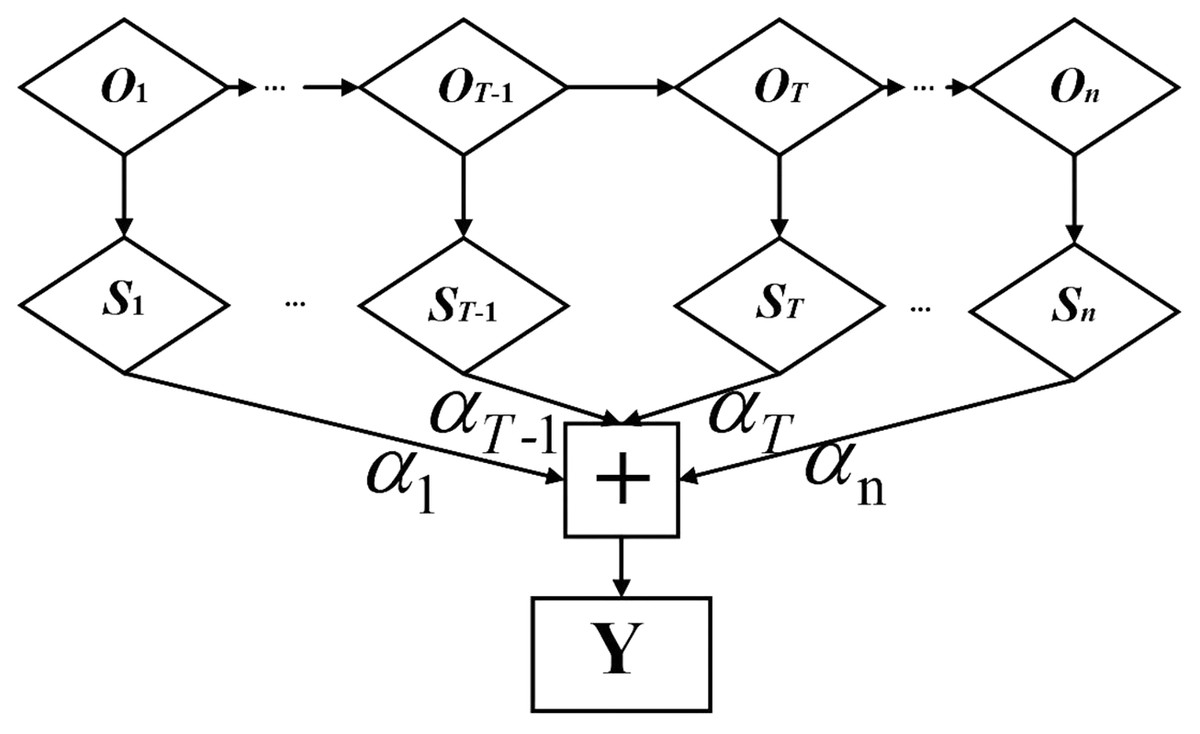
Figure 3: Structure diagram of attention mechanism.
{kind=link}
is the T-th feature vector of BiLSTM network output, which is input into the hidden layer of attention mechanism to obtain the initial state vector , and then the final output state vector Y is obtained by multiplying and summating the corresponding weight coefficient . The calculation formula is as follows:
(13)
(14)
(15) where represents the weight coefficient matrix of the T-th feature vector, and denotes the offset corresponding to the T-th feature vector (Li, Zhang & Chen, 2022).
Federated learning
Federated learning is a distributed training method that uses data sets scattered among the participants, integrates data information from multiple parties through privacy protection technology, and collaboratively builds a global model (Huong et al., 2021). During the model training process, the relevant information about the model (such as model parameters, model structure, parameter gradient, etc.) can be exchanged among participants (The exchange mode can be plaintext, data encryption, adding noise, etc.) (Lu et al., 2019), but the local training data will not leave the local. This exchange does not expose local user data, decreasing the danger of data leakage. Trained federated learning models can be shared and deployed across data participants.
The training process can be organized into three steps:
(1) Task initialization: the server determines the training target, parameters, and participating terminal devices, and passes the global model to the participating equipment.
(2) Local model training and update: global model downloaded from the server, where t represents the current training round. The participant appliance i trains the model locally and updates the parameter this time. The updated local model parameter is expressed as , the goal of training is to find the best local model by minimizing the loss function and upload it to the server:
(16)
(3) Global model aggregation and update: The server receives the model parameters uploaded by the participant devices and aggregates them, and finally updates the global model :
(17)
The above training process is iterated until the convergence or termination condition training technique is satisfied. From the classical training model of federated learning, we can find that the local appliance communicates with the server through model parameters during training, so as to protect privacy.
Proposed prediction model
In this part, the process of each part is explained in detail. Firstly, the data is preprocessed, and the individual load of household appliances is decomposed from the total load demand through the NILM method based on the CNN-LSTM hybrid model. Then the power of individual appliances is predicted separately by the FedDL prediction model, and the predicted power of individual appliances is aggregated to form the overall power prediction. Finally, the validity of the proposed model is evaluated by some evaluation indicators.
Data decomposition
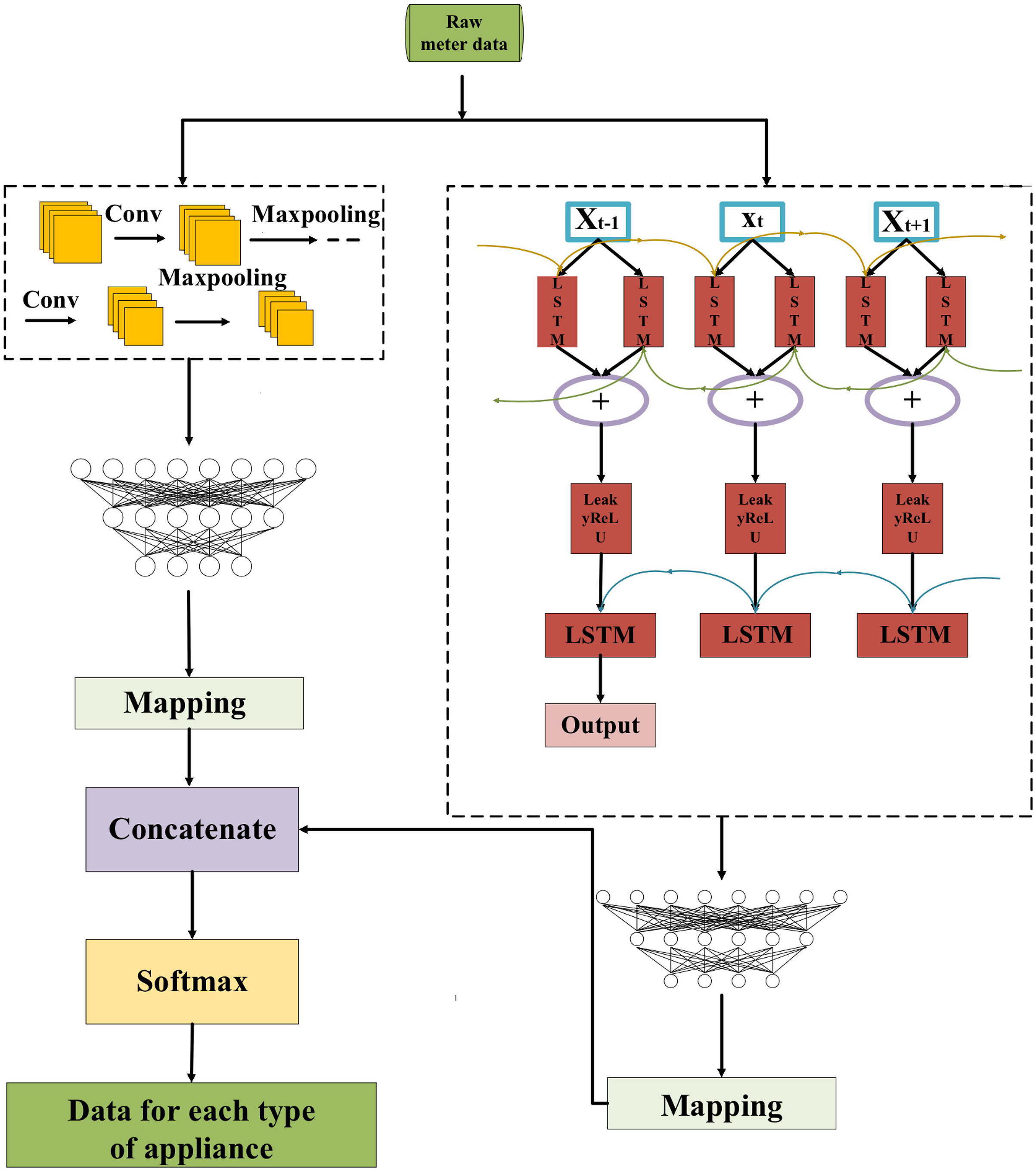
In this article, the NILM method is based on the CNN-LSTM hybrid model to decompose the total load data of the training sample and obtain the energy consumption value of individual appliances. Fig. 4 presents the structure of the CNN-LSTM.
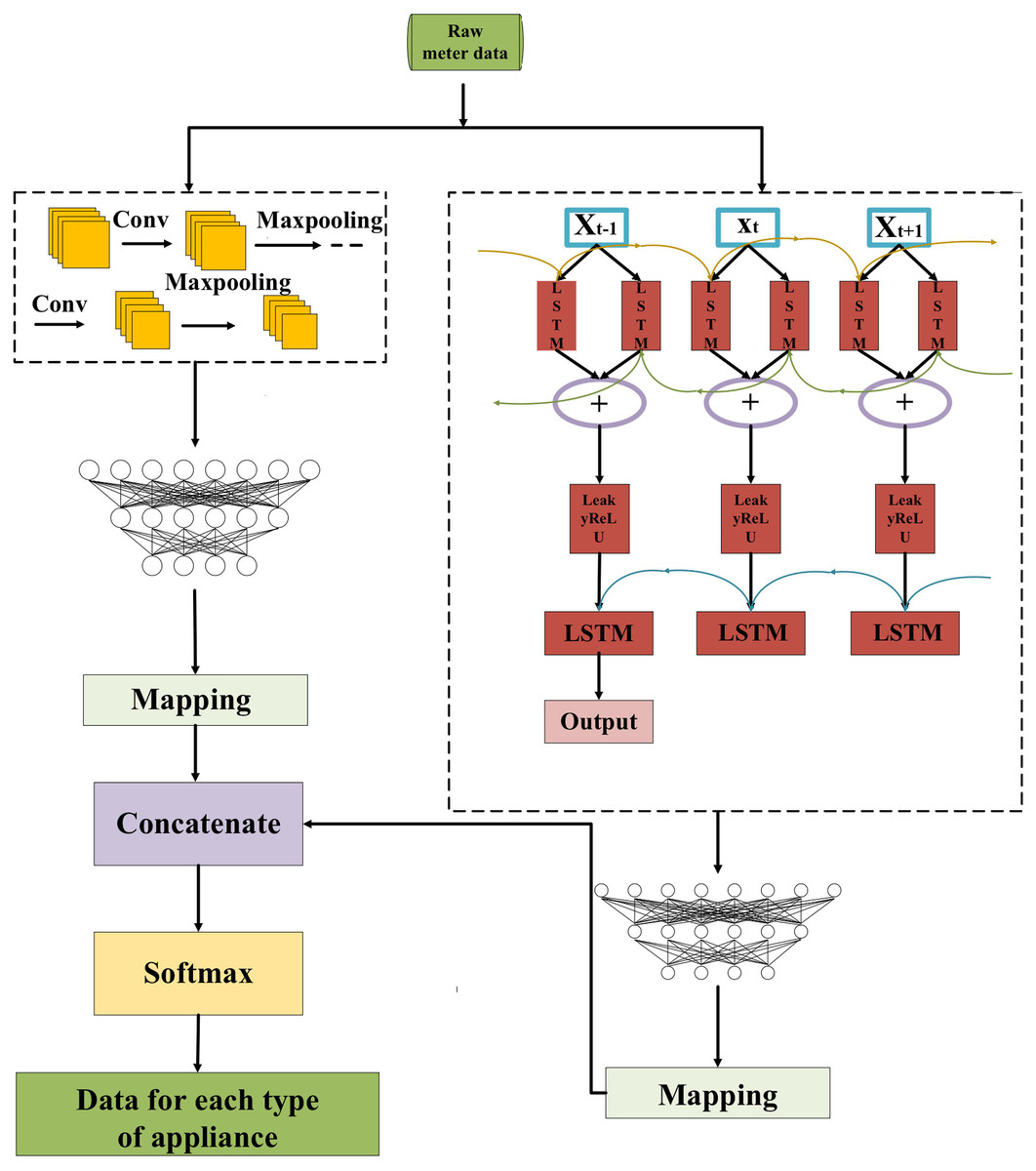
Figure 4: Structure diagram of CNN-LSTM.
{kind=link}
Firstly, the CNN and LSTM are trained separately using the pre-processed data, and then the feature information extracted from each of the two networks is handled as the equal dimension using the mapping layer, and finally, the two are concatenated. For more specifics, please refer to Zhou, Feng & Li (2021).
FedDL-based prediction model
In order to build a better neural network, a large amount of data containing various devices and responding to consumer behavior habits needs to be fed to the network. However, during model training, the local data owner may encounter the risk of privacy leakage and loss of control over the data. To address this potential risk, we use federated learning, which is in sharp contrast to traditional centralized machine learning techniques where all sample data is uploaded to a single server. The flow chart of the proposed FedDL prediction model is shown in Fig. 5.
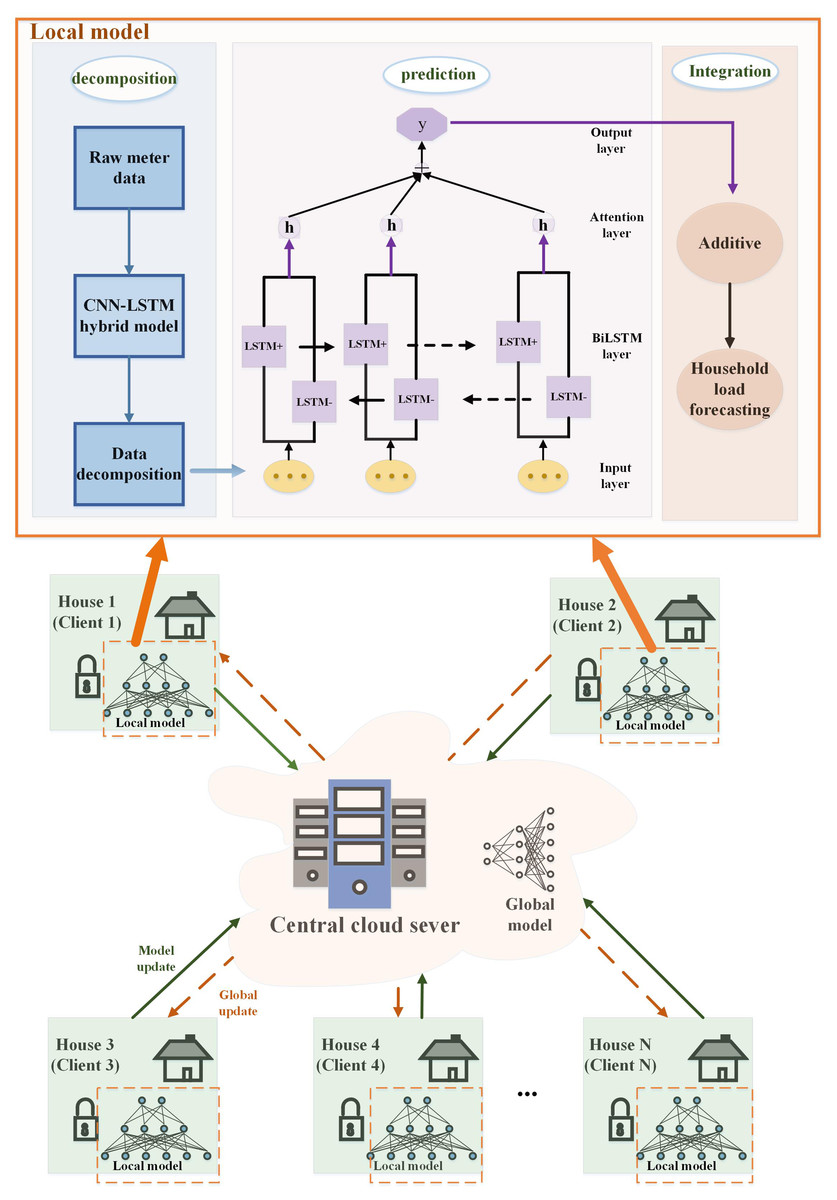
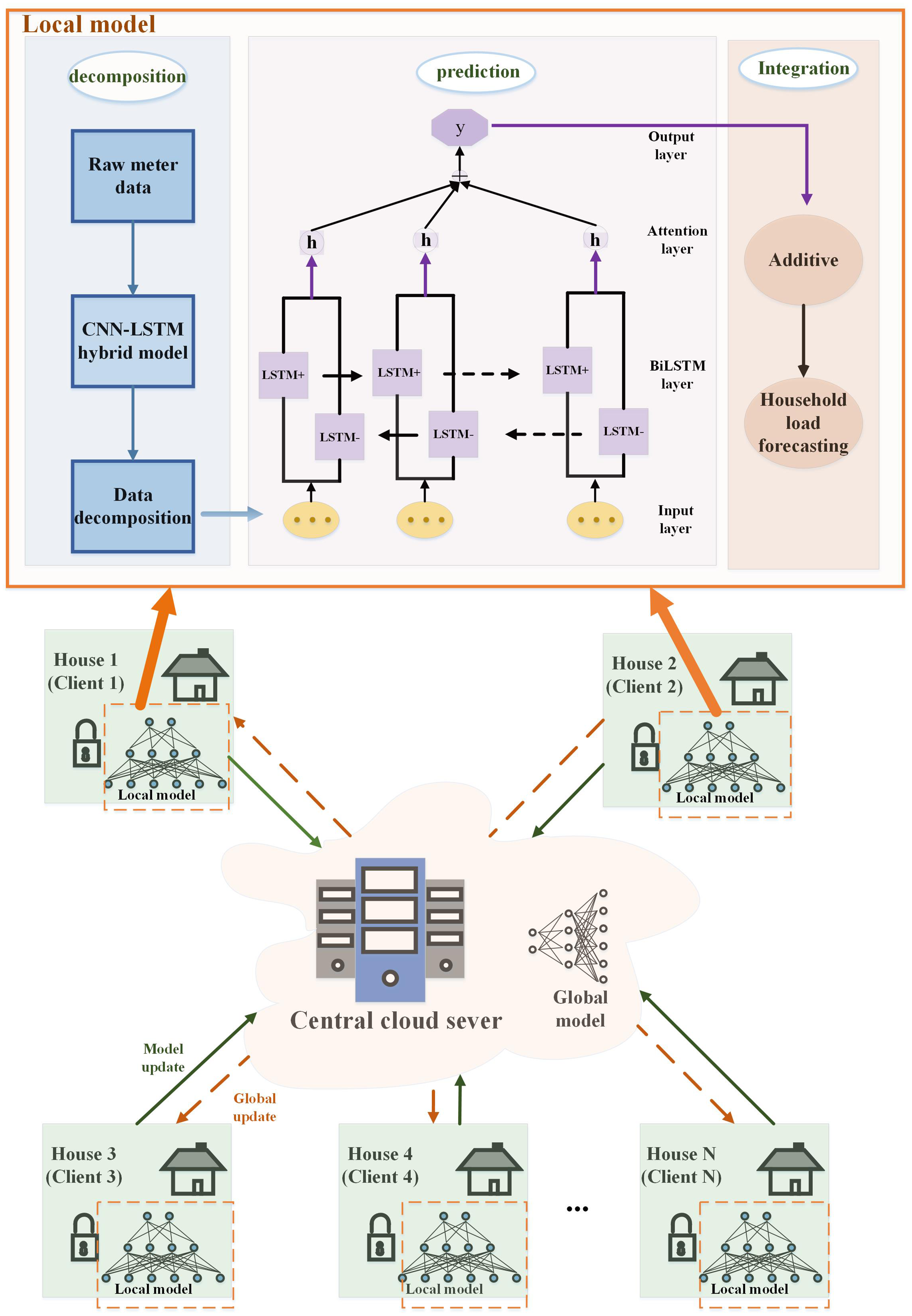
Figure 5: Flowchart of the FedDL prediction model.
{kind=link}
For the purpose of illustrating, we assume that each household has the same computational power, the same hyperparameters (e.g., learning rate, minibatch size) for training in FedDL, and the same optimization algorithm is used.
As shown in Fig. 5, first, the initial global model will deploy its parameters to the client. After receiving the parameters of the global model, the local household will train its local deep learning model based on local data and update its parameters, and then transmit these parameters to the global server. The global deep learning model receives the locally updated parameters and adopts a federated average for the parameters, and then updates the global deep learning model with the results based on the federated average. After that, the updated global parameters will be passed to the local model of each house, and the final global deep learning model will be generated after all the global communication rounds have been run between the local residents and the central server.
We explained it step by step under the local model. The individual load of household appliances is decomposed from the total load demand through the NILM method based on the CNN-LSTM hybrid model. Then the power of individual appliances is predicted separately by the prediction model, and the predicted power of individual appliances is aggregated to form the overall power prediction.
Local model structure parameters
The specific internal structure is shown in Fig. 6. First, the model delivers the pre-processed sequence data to the forward and the backward LSTM hidden layer, and the two are combined with the output vector as the bi-directional timing feature vector of the electric load at the moment T. The attention layer is responsible for assigning attention weights, highlighting the key factors, ignoring irrelevant information, and continuously iterating the optimal weight parameter matrix. Then, in order to obtain the new vector of inputs to the fully connected layer, the weight vector is combined with the shallow layer output. Finally, the predicted load values are obtained by the fully connected layer (sigmoid as the activation function).
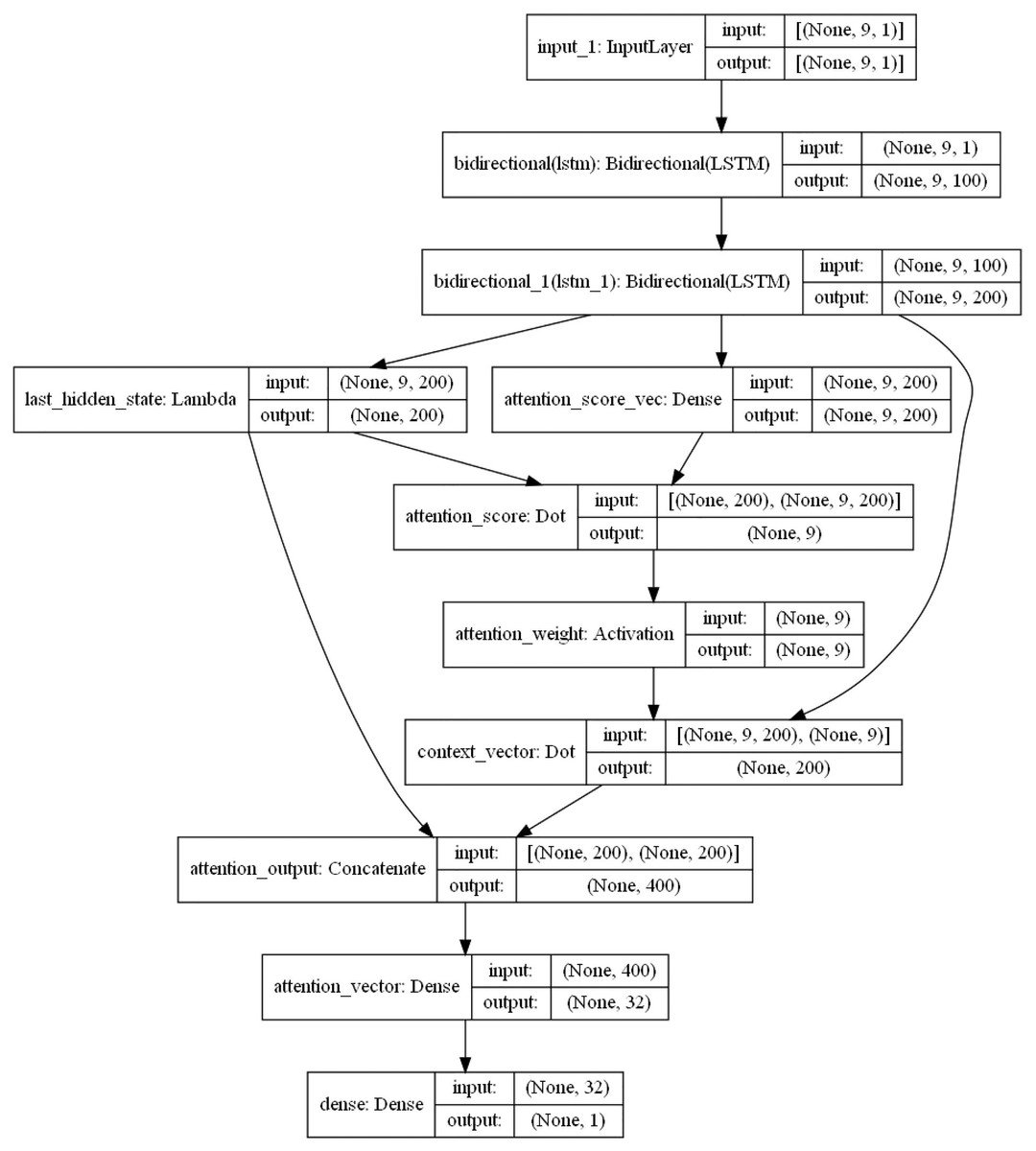
Figure 6: BiLSTM-Attention internal structure diagram.
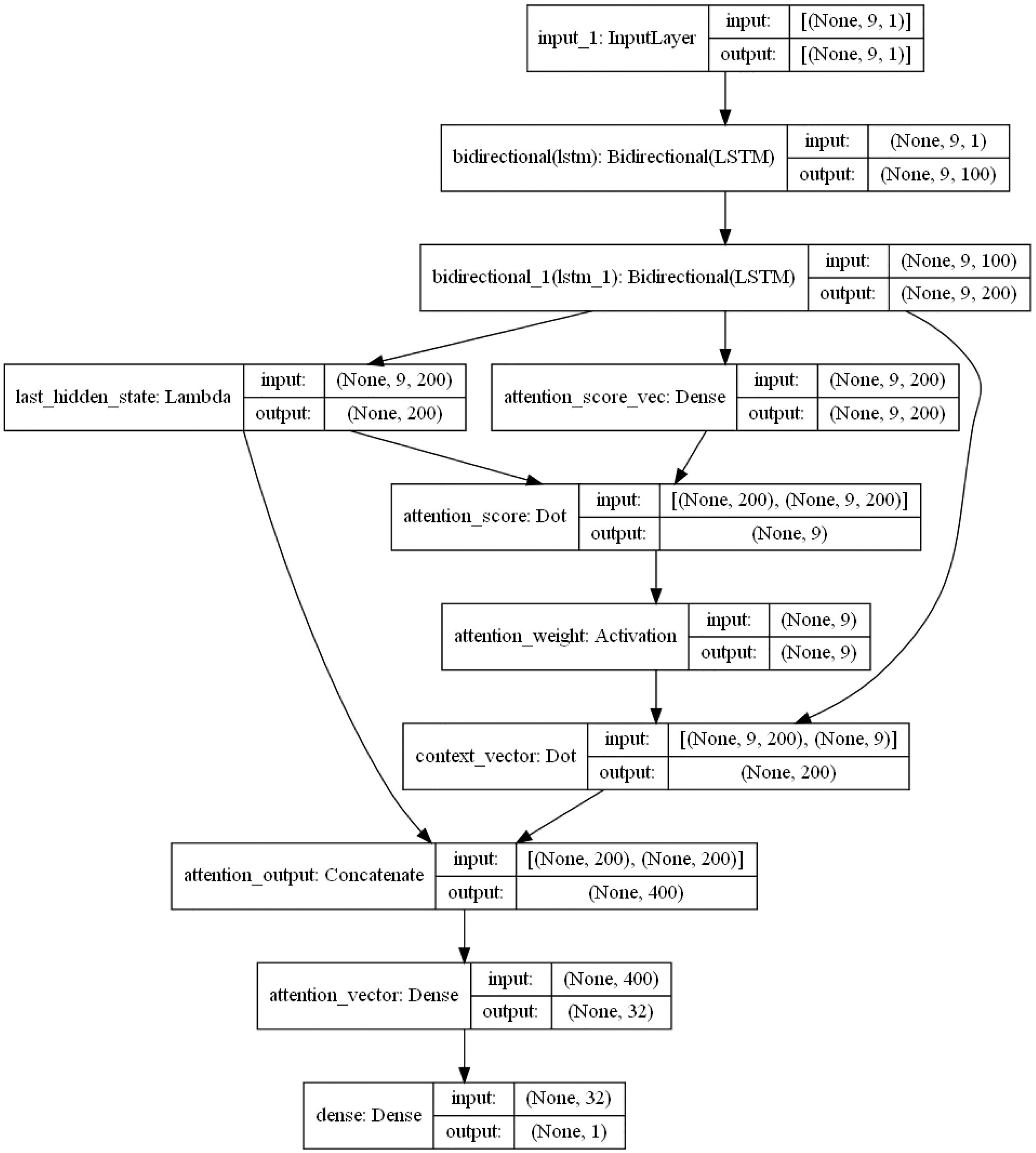{kind=link}
The LSTM layer can remember or forget significant information. In principle, the more layers, the stronger the learning ability. But too many layers will lead to difficult convergence and a long training time. Therefore, in the model of this article, a two-layer LSTM is set. The number of neurons in the first layer is set as 128, and the number of neurons in the second layer is 68.
Evaluation indicators of federated deep learning model
In machine learning, there are two major problems: classification and regression. The essence of both is to predict the input. The difference between the two lies in the type of output results. The output of the classification problem is a qualitative discrete variable, while the output of the regression problem is a quantitative continuous variable. For these two kinds of problems, there are corresponding evaluation indexes to measure the validity of the models and algorithms. As a typical regression problem, power load prediction mainly has the following evaluation indexes:
(1) Mean Absolute Error (MAE): The advantage is that the calculation is simple and the description error is clear. The specific formula is shown in Eq. (18):
(18)
(2) Root Mean Square Error (RMSE): For data whose unit measurement is too large, this operation can retain the original description unit for the data. For example, if the unit of electricity load is KW, the square of the difference will increase by an order of magnitude, which will add trouble to the model description, so RMSE is chosen to maintain the original magnitude. The smaller the original root mean square error, the more accurate the prediction. The specific formula is shown in Eq. (19):
(19)
In Eqs. (18) and (19), and are the true and predicted values, respectively.
Case study
In this part, the integrated power is decomposed into individual device power by the NILM method based on the CNN-LSTM hybrid model, and the power of each device is predicted separately using the federated deep learning model. Finally, the predicted power values of individual appliances are aggregated to form the overall power prediction. The validity of the method is confirmed through qualitative and quantitative evaluation results. In addition, experiments in various federated learning environments are designed and implemented to validate the validity of this methodology. The programming language in the experiment is python and Tensorflow2.0 is used.
In the BiLSTM-Attention model used in this article, a 2-layer LSTM is set. The number of neurons in the first layer is set as 128, and the number of neurons in the second layer is 68. The activation function is tanh, the learning rate is 0.001, Adam is selected as the optimization function, and the batchsize is 512.
Generation of the data set
The data set UKDALE established by British scholars Jack Kelly and William Knottenbelt is used for the experiment (Kelly & Knottenbelt, 2015). The load data set contains information about individual loads in five households as well as the total household electricity consumption. And use the load data from July 1, 2013 to July 3, 2013 of five households in the UKDALE dataset as the data set used in this study. The previous 4,070 min of data were used as the training set, and the remaining 250-min data is employed as the testing set. The data in the dataset is sampled every 6 s.
Experimental results
For ease of analysis without loss of generality, the experimental results shown in this article take household 1 as an example. The experimental results are shown below.
Using CNN-LSTM hybrid model decomposition method to decompose the total load data of the training samples to obtain the energy consumption values of each load device, without considering the simultaneous existence of multiple electrical appliances. The load decomposition results of loading equipment for a certain three days in April are shown in Fig. 7. This step of decomposition sets the stage for the next step of prediction.
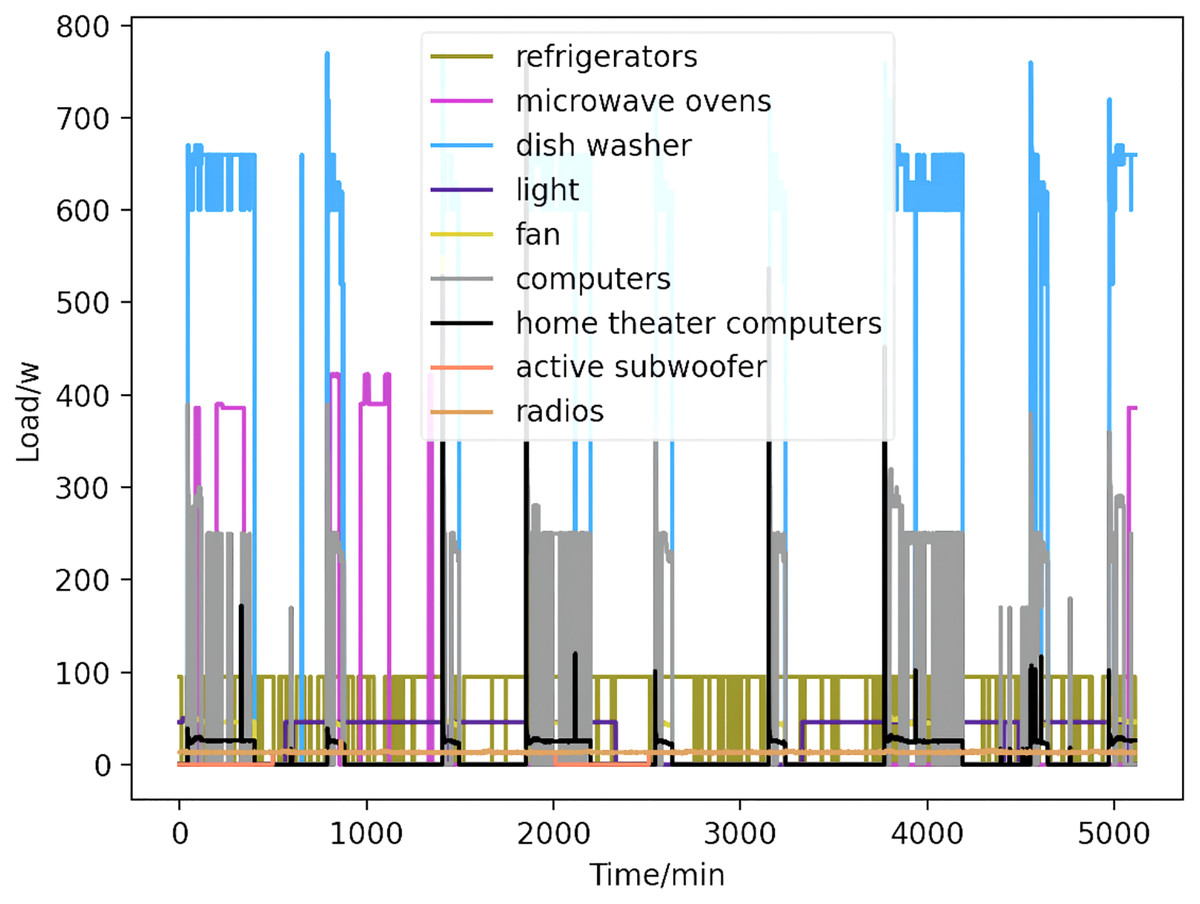
Figure 7: Load curve.
The nine kinds of appliances obtained by decomposition (refrigerators, kettles, home theater computers, microwave ovens, radios, fans, light, active subwoofers, and computers) are shown, with power curves delineated by color.{kind=link}
In Fig. 7, the nine kinds of electrical appliances obtained by decomposition are refrigerators, kettles, home theater computers, microwave ovens, radios, fans, light, active subwoofers, and computers. The power curves of the nine electrical appliances are marked by different colors.
Based on the load decomposition results of nine load devices, nine load prediction models are trained respectively according to the prediction model structure proposed in “Proposed prediction model”. Figs. 8–16 show the real values of nine appliances compared to the predicted values, and Fig. 17 shows the total predicted value of the household loads.
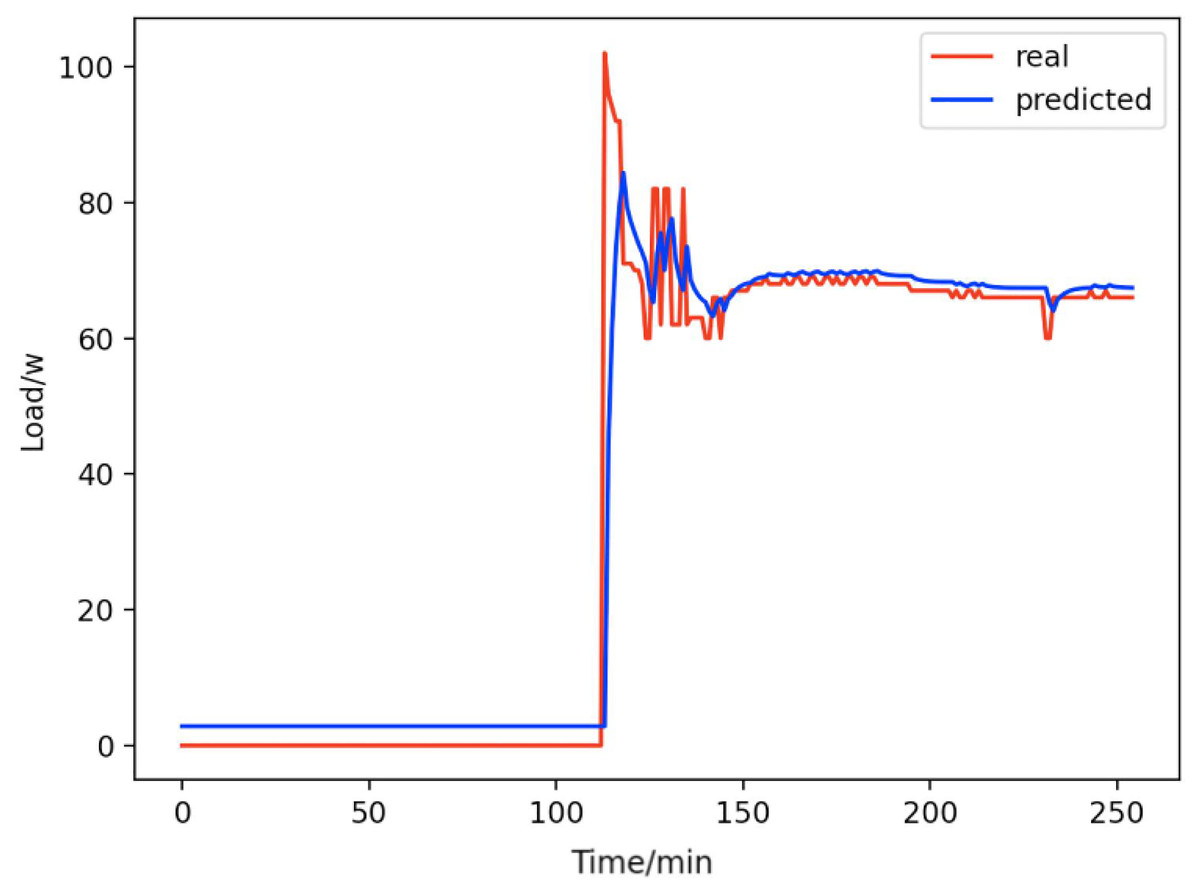
Figure 8: Active subwoofer.
Comparison of actual and predicted values of active subwoofers.{kind=link}
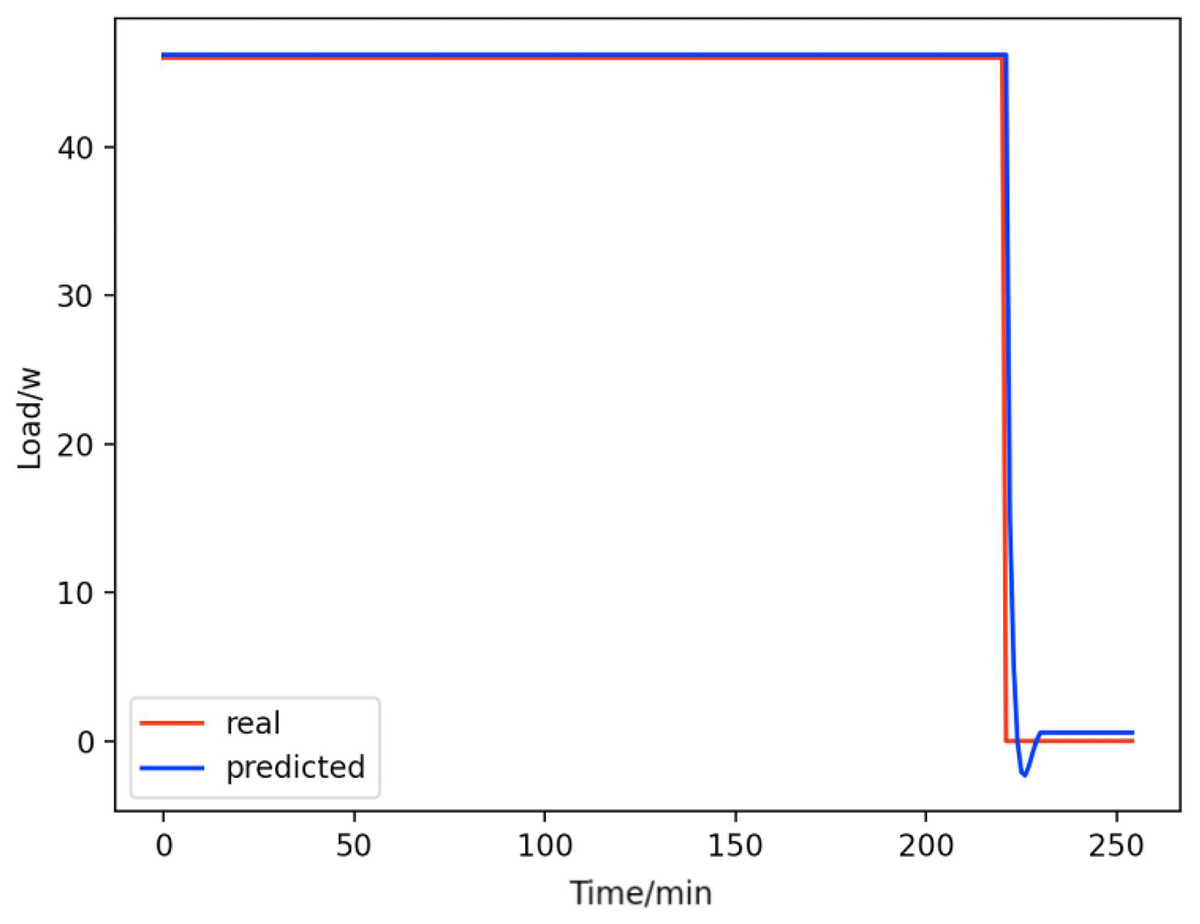
Figure 9: Light.
Comparison of actual and predicted values of lights.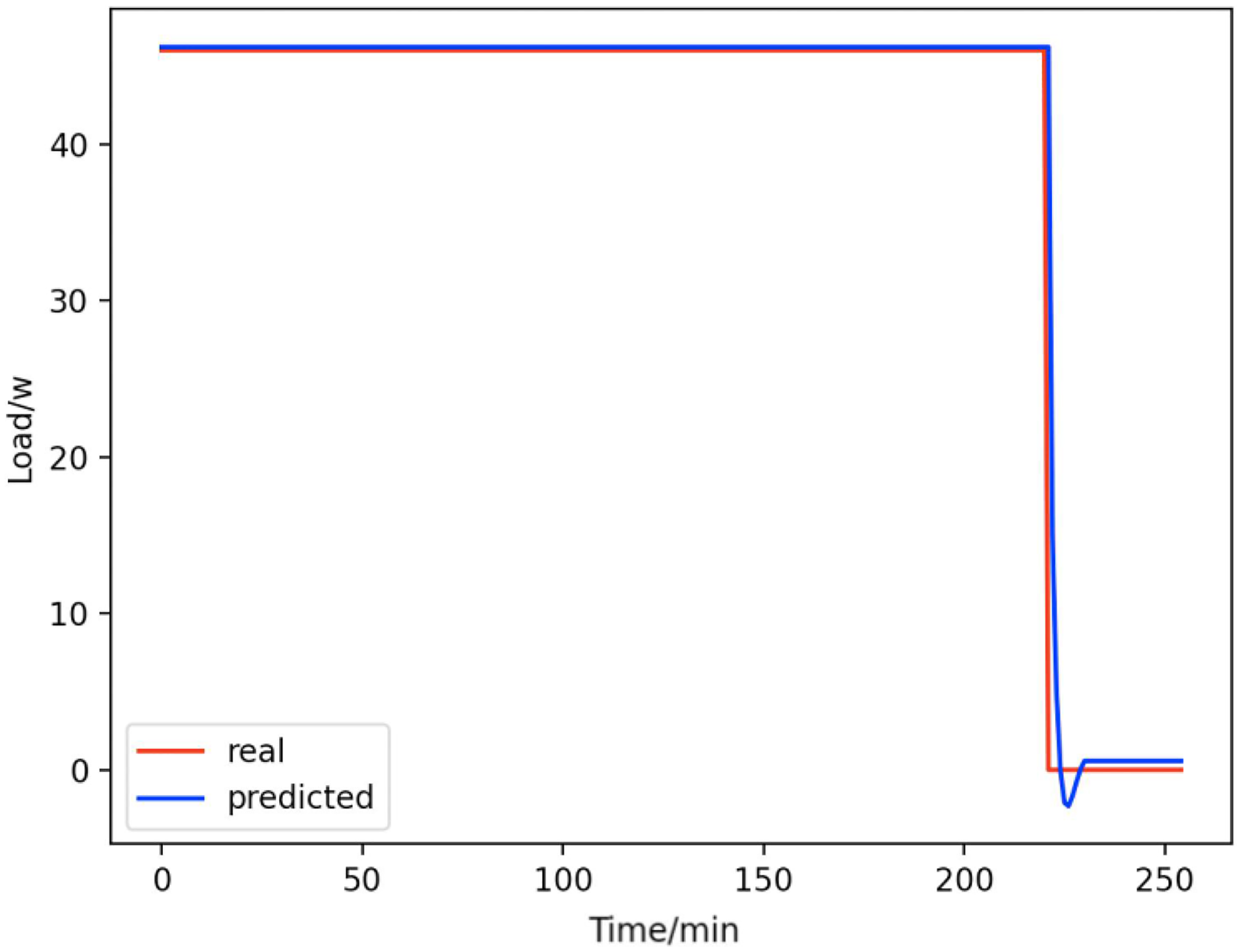{kind=link}
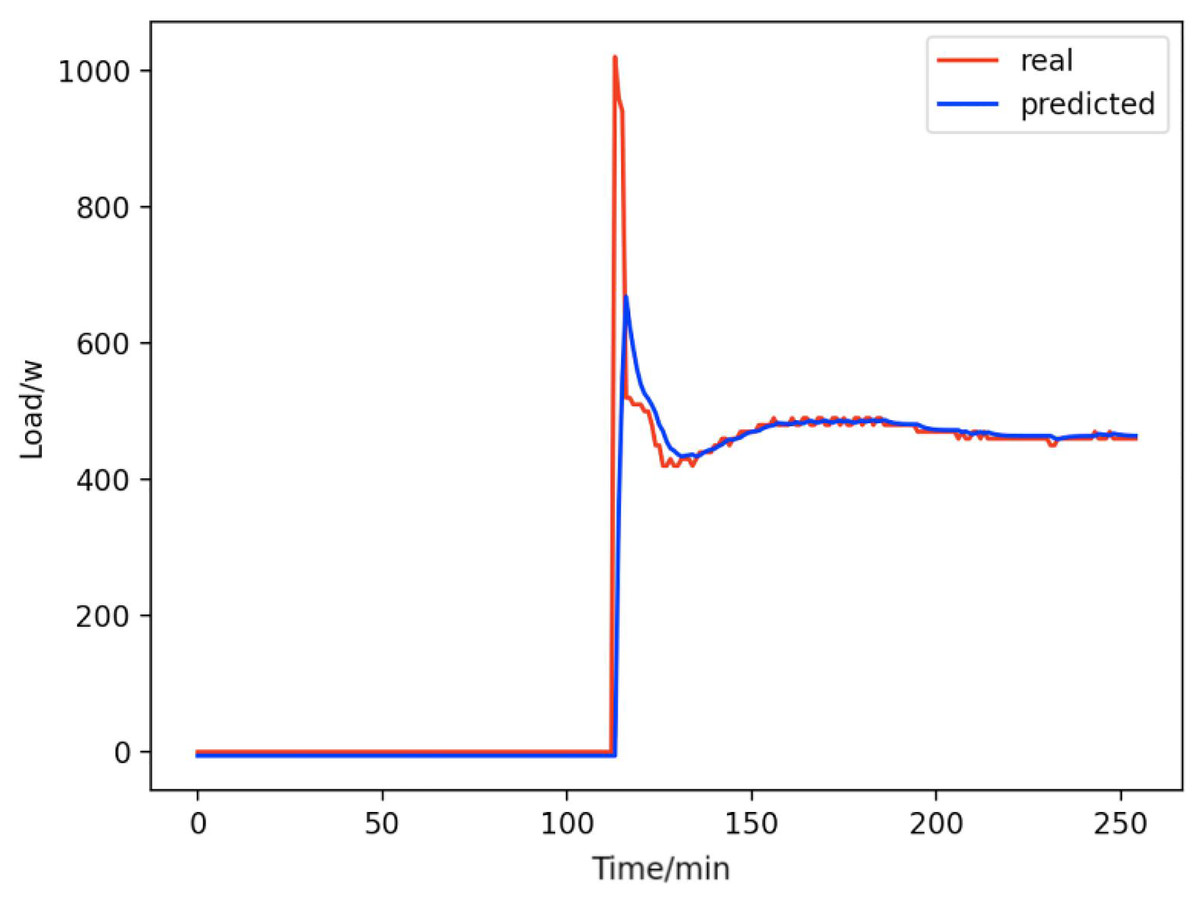
Figure 10: Home theater computers.
Comparison of actual and predicted values of home theater computers.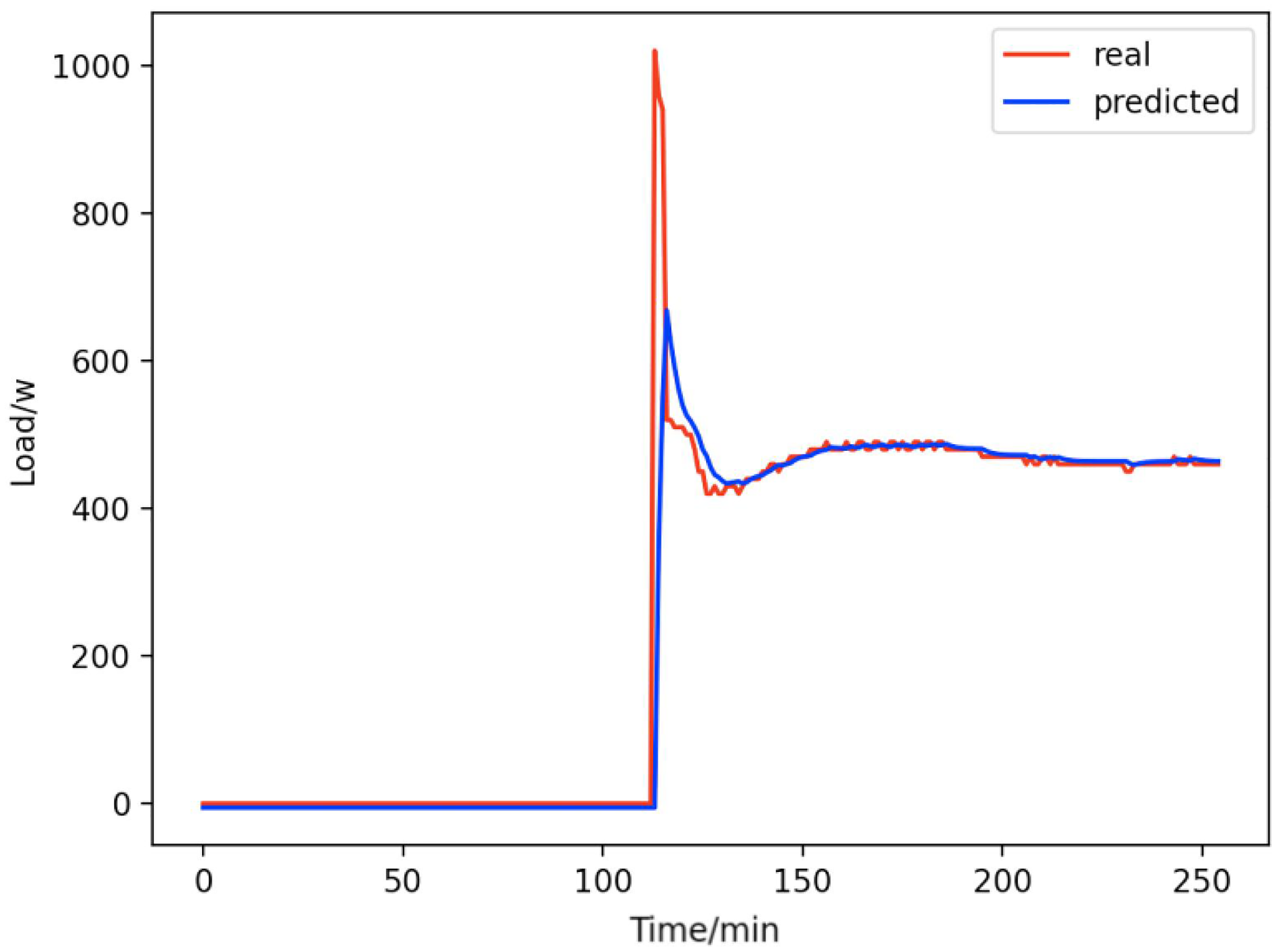{kind=link}
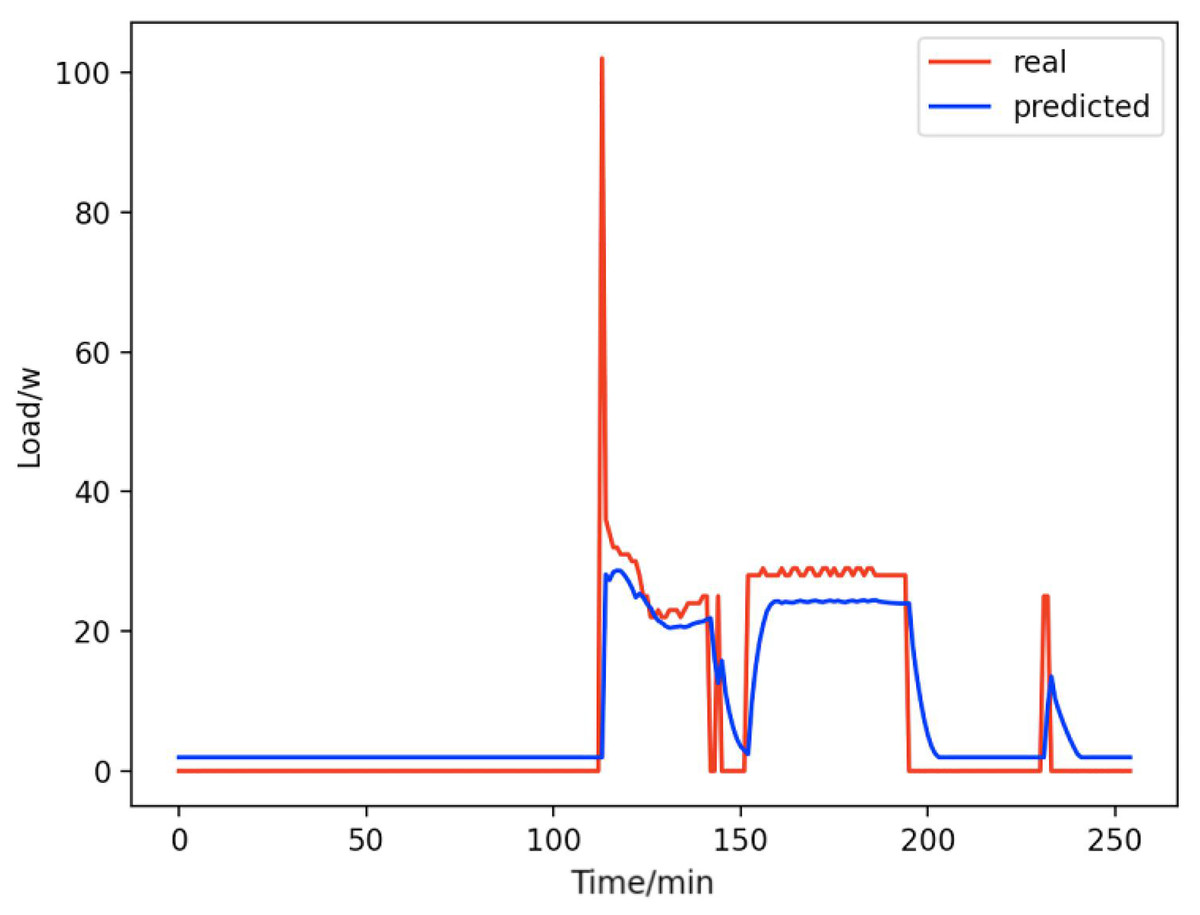
Figure 11: Fans.
Comparison of actual and predicted values of fans.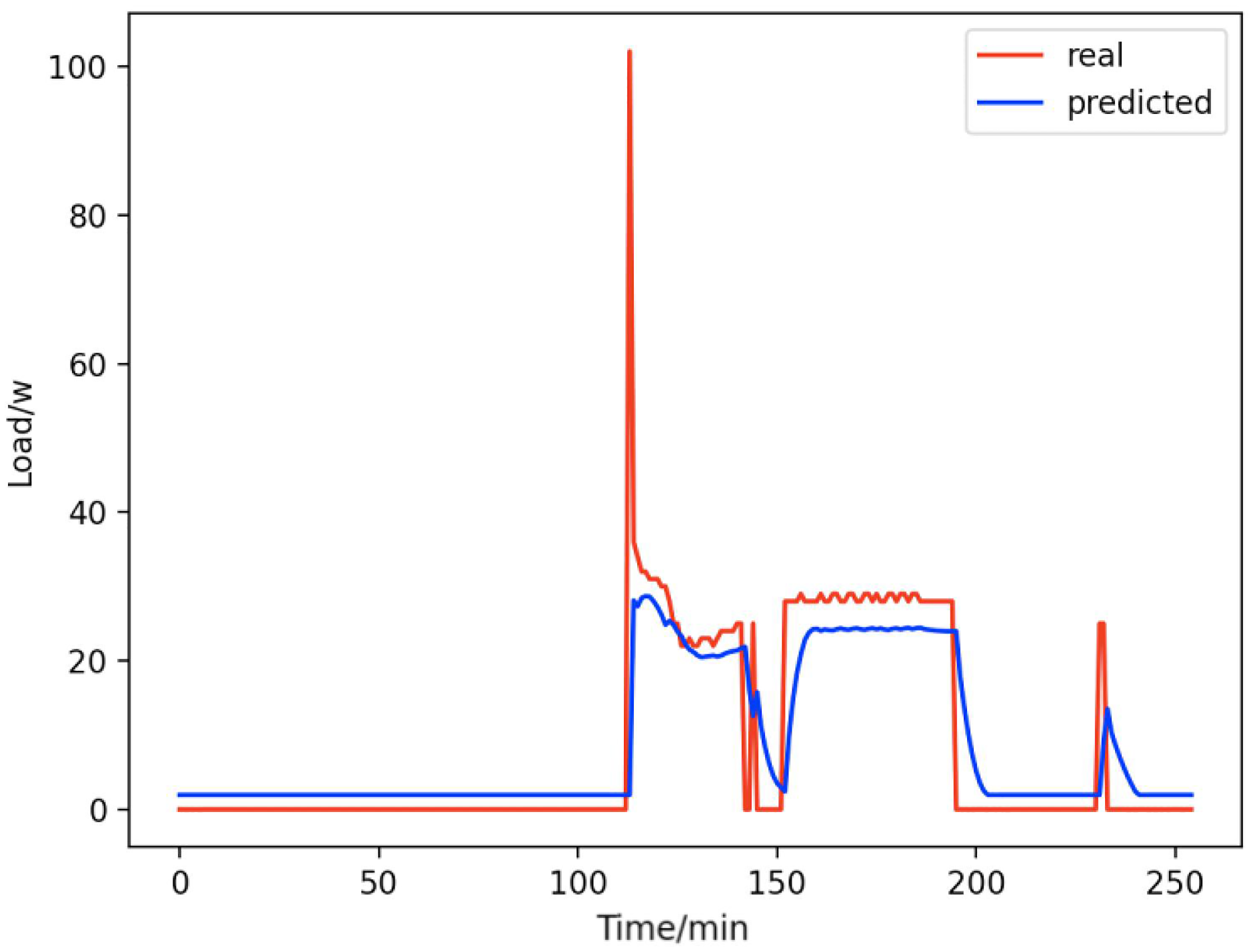{kind=link}
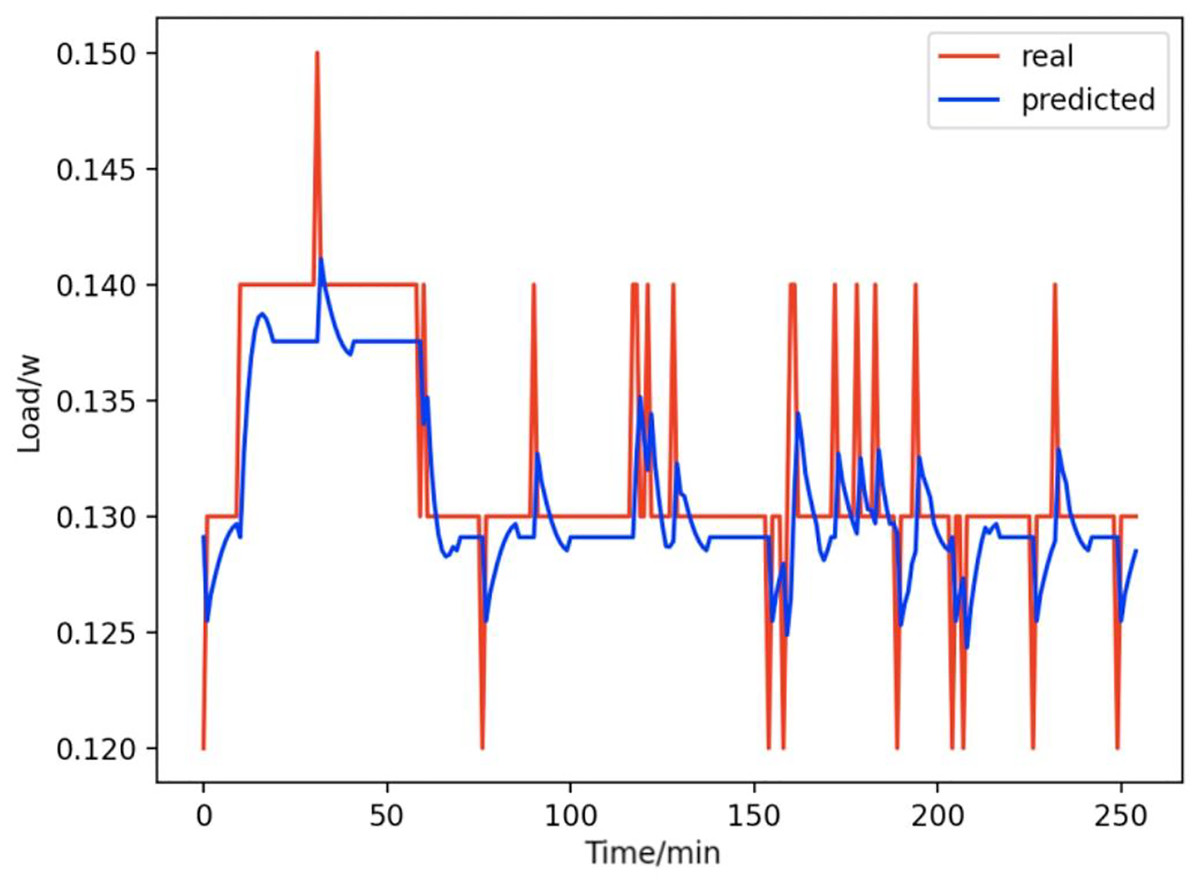
Figure 12: Radios.
Comparison of actual and predicted values of radios.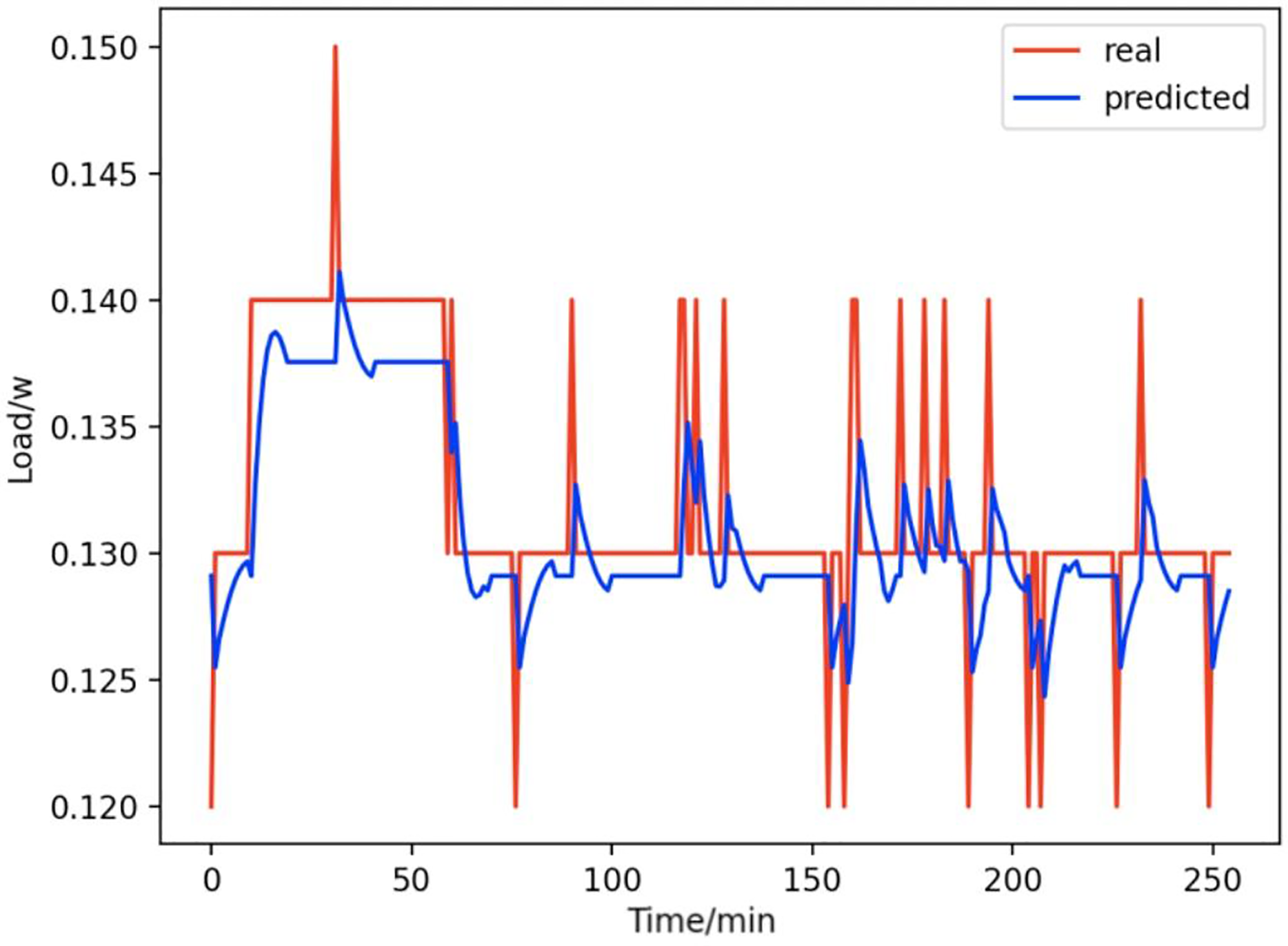{kind=link}
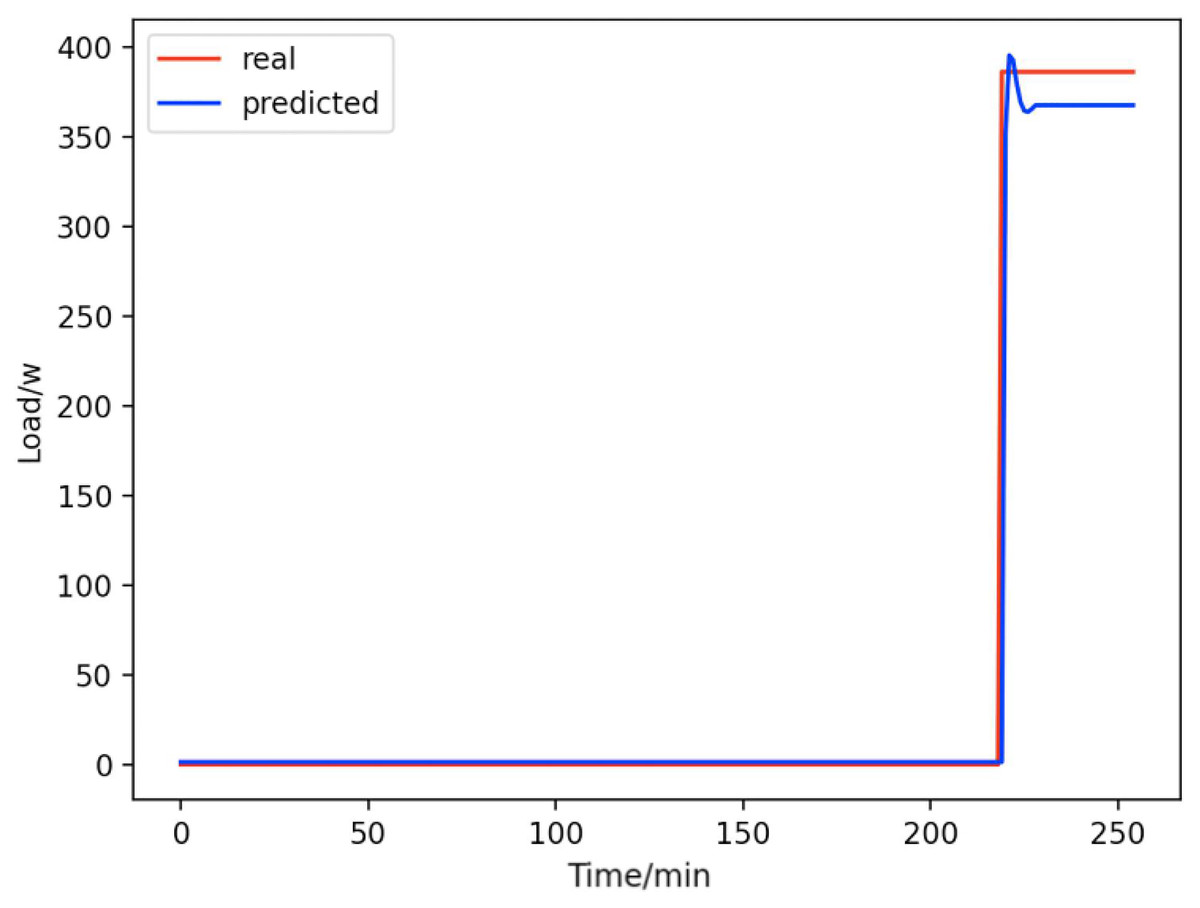
Figure 13: Microwave ovens.
Comparison of actual and predicted values of microwave ovens.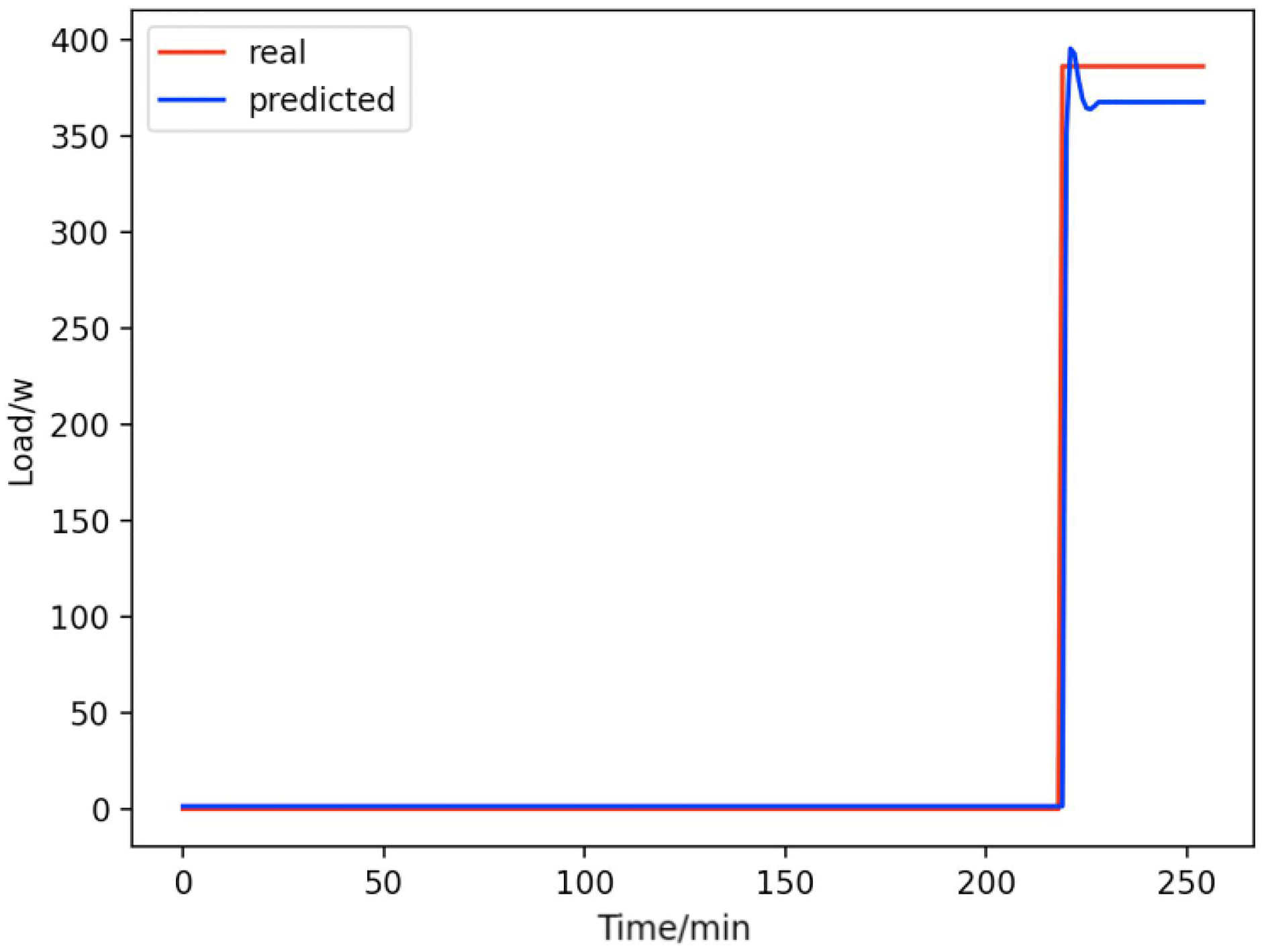{kind=link}
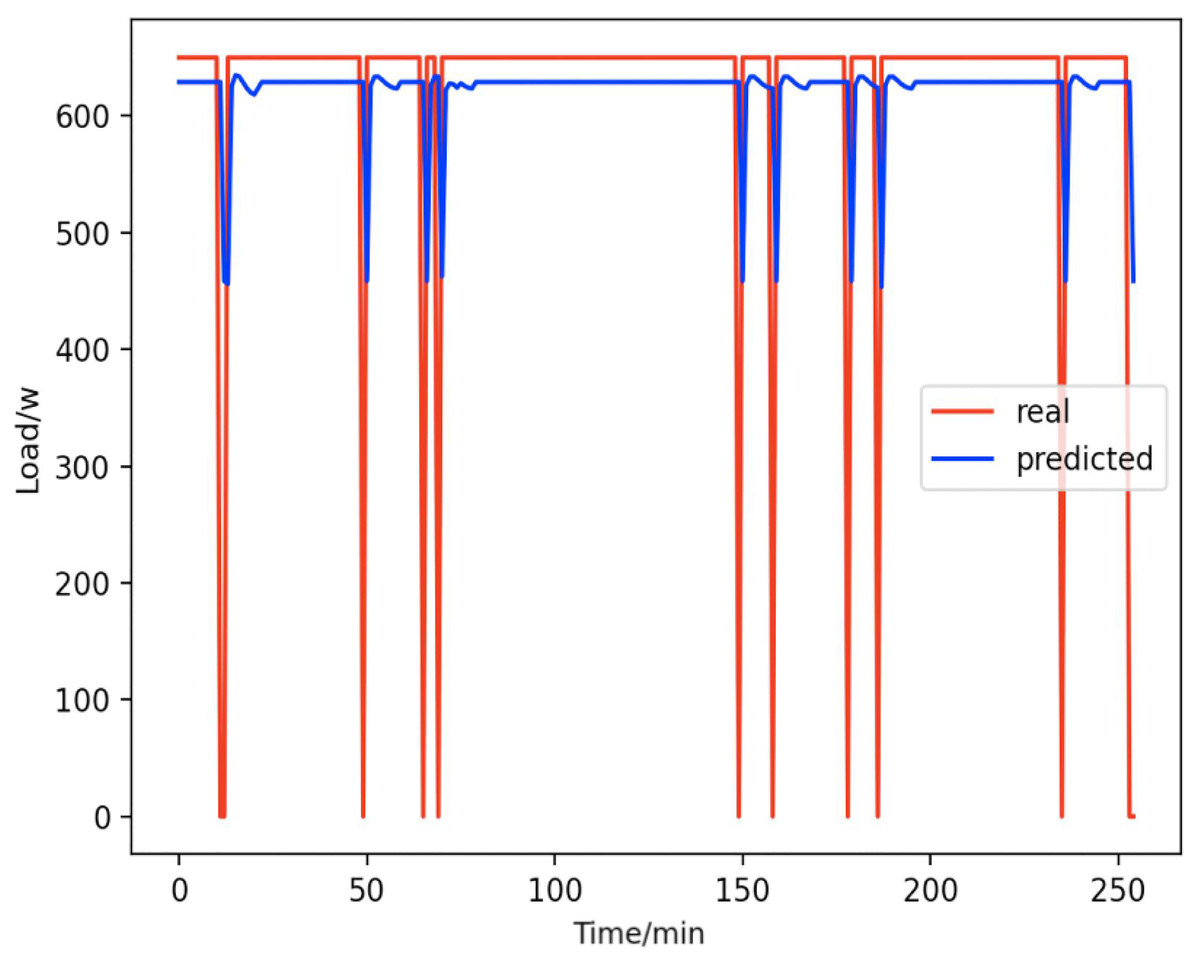
Figure 14: Kettles.
Comparison of actual and predicted values of kettles.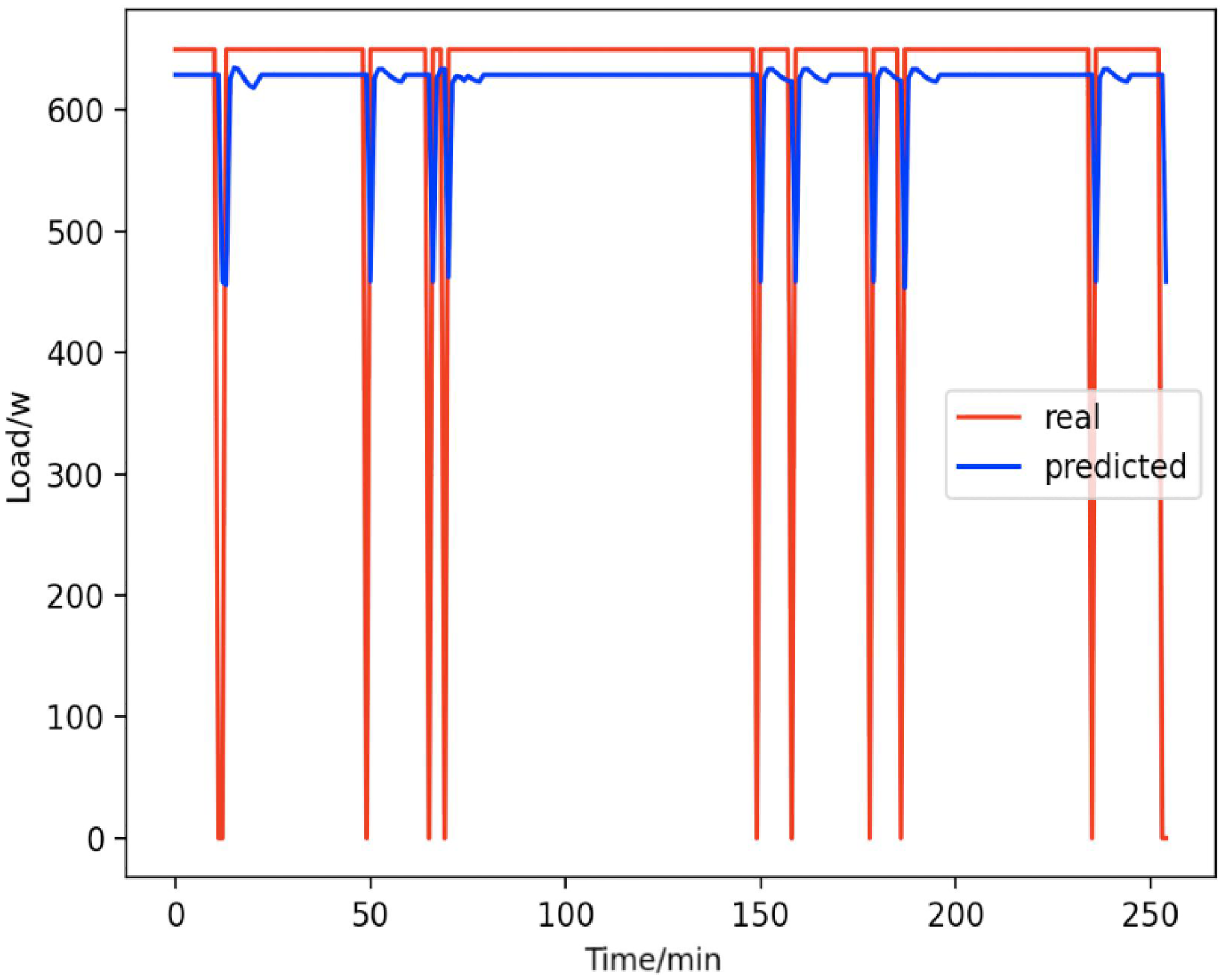{kind=link}
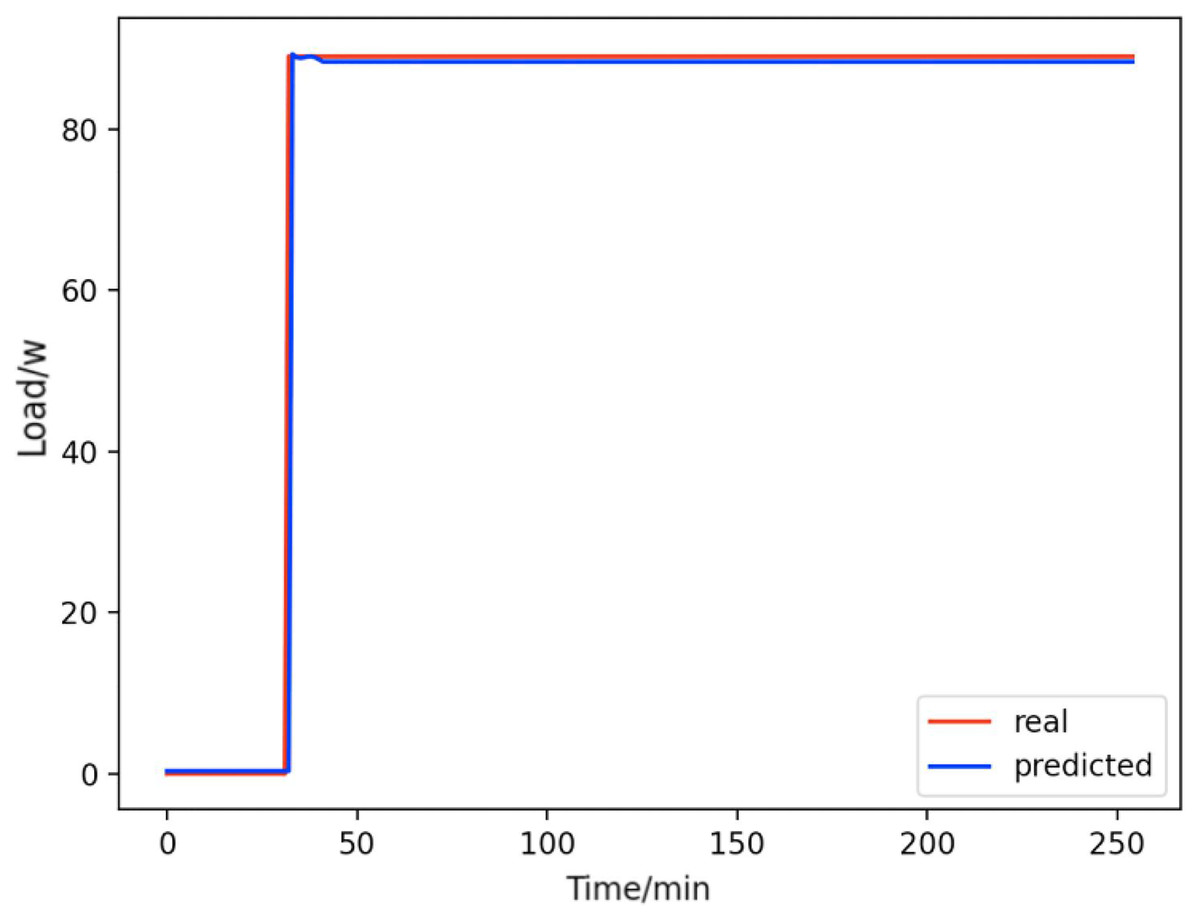
Figure 15: Refrigerators.
Comparison of actual and predicted values of refrigerators.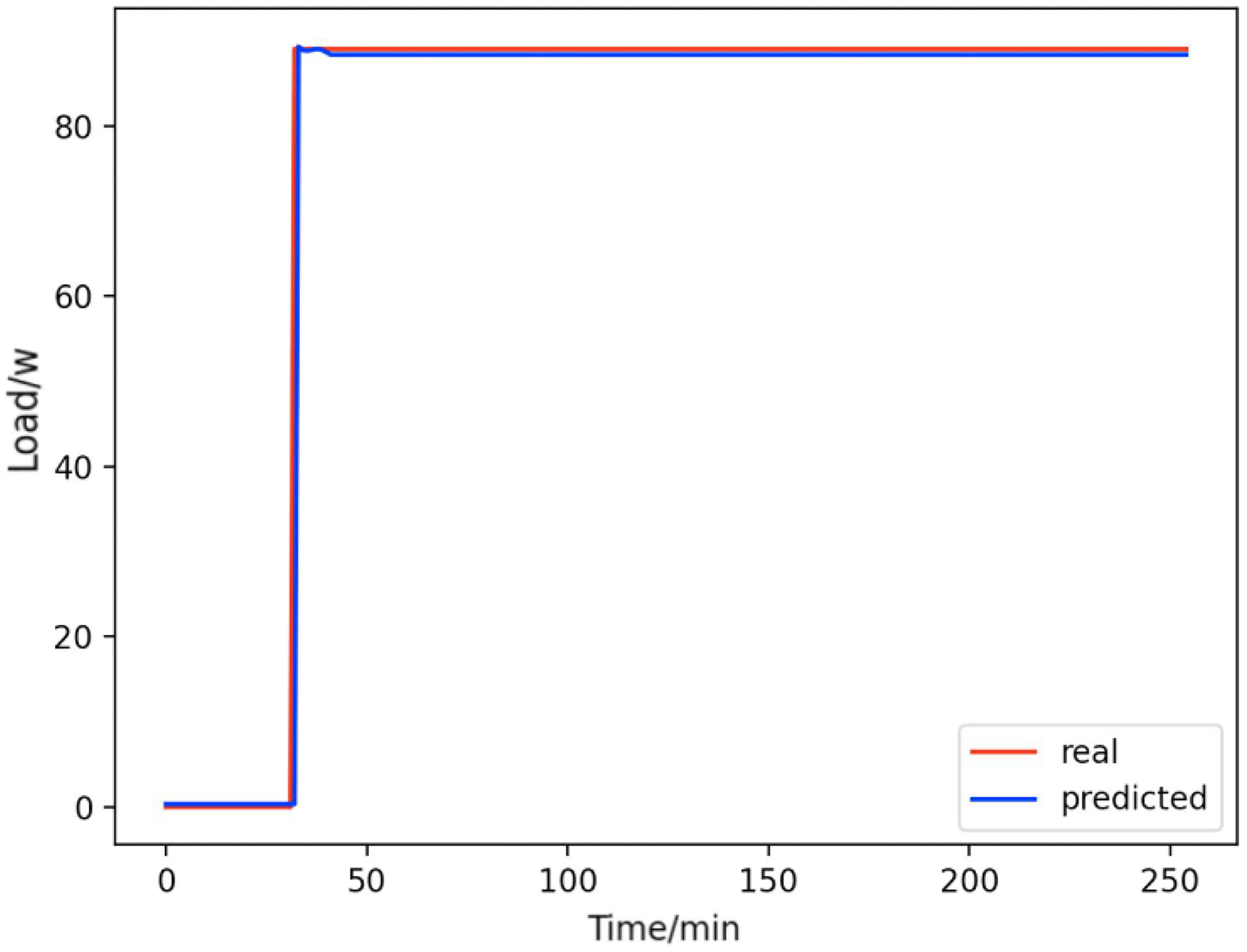{kind=link}
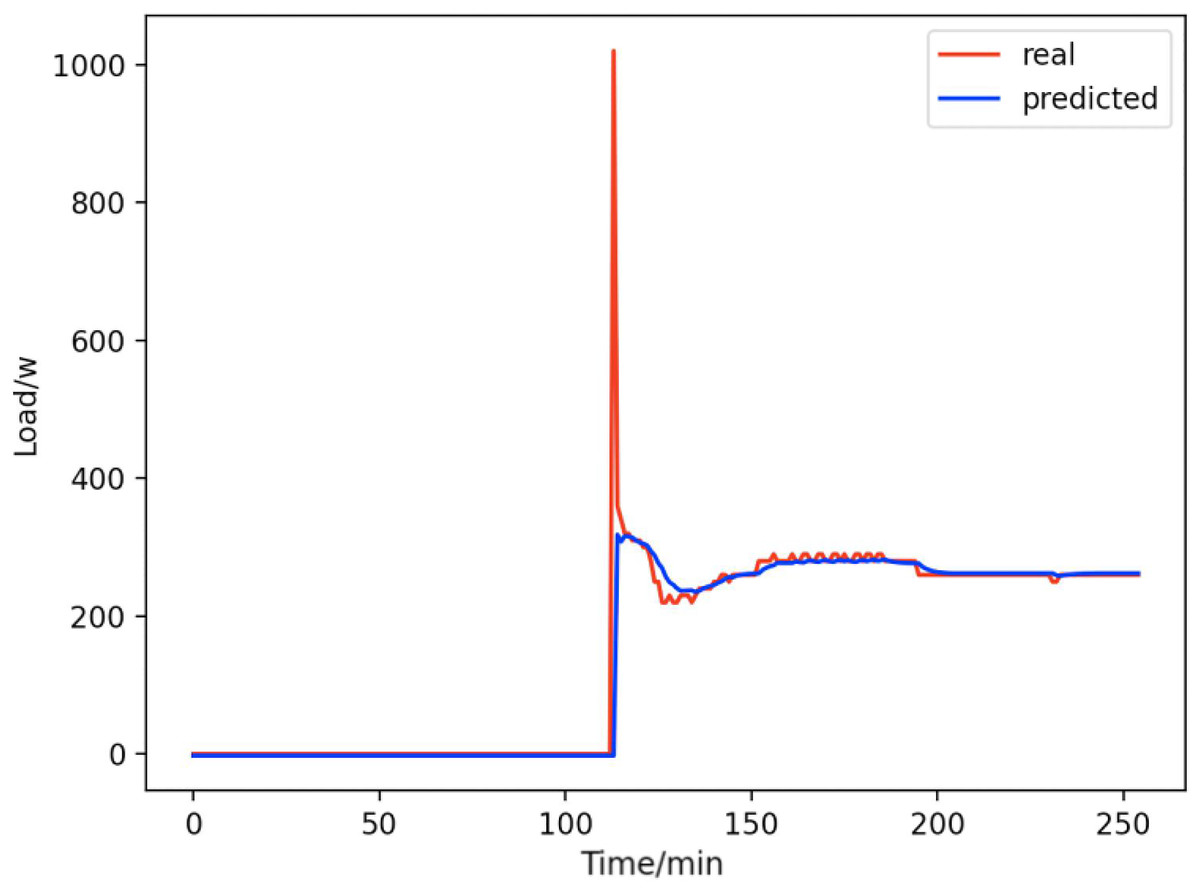
Figure 16: Computers.
Comparison of actual and predicted values of computers.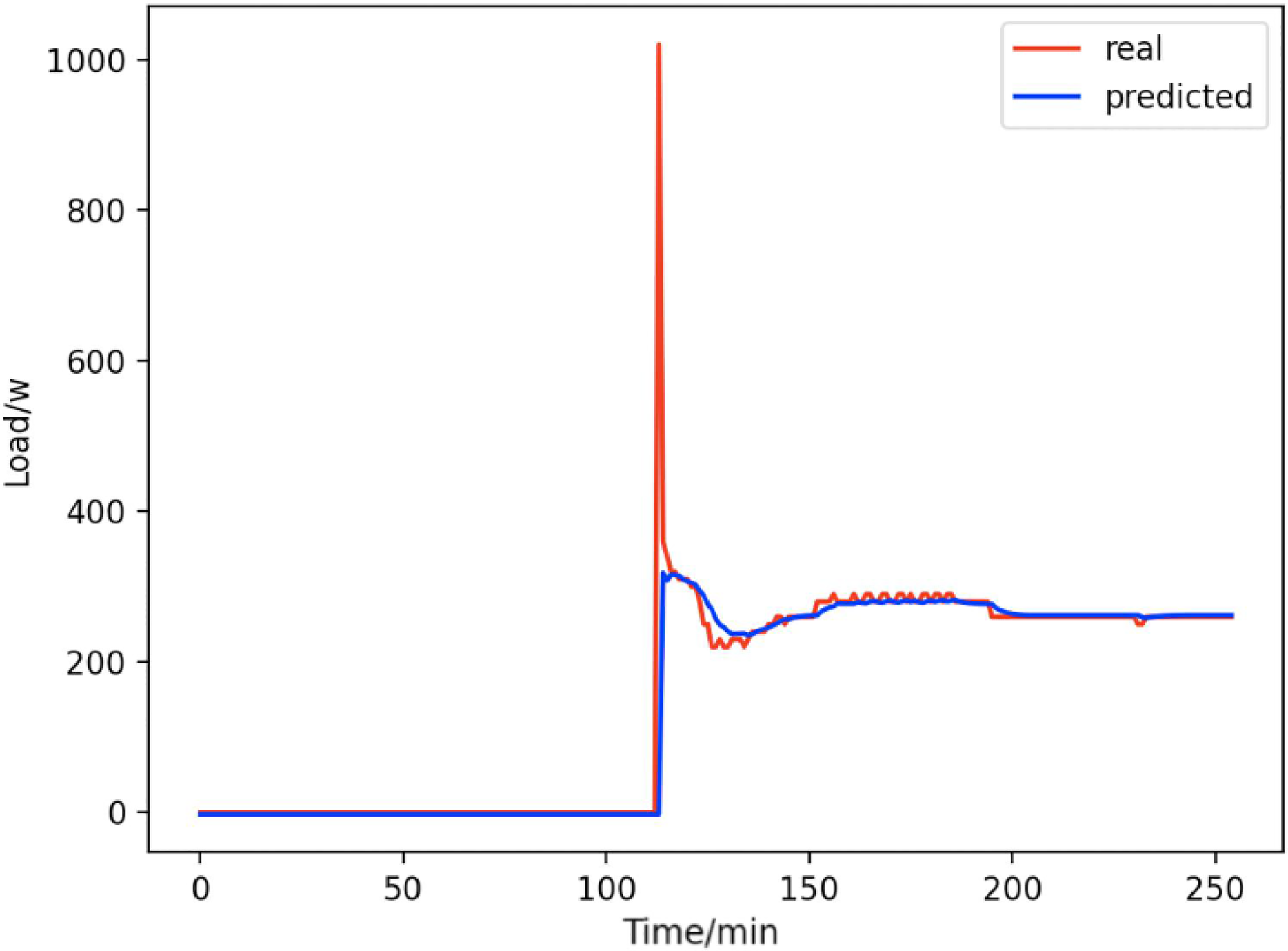{kind=link}
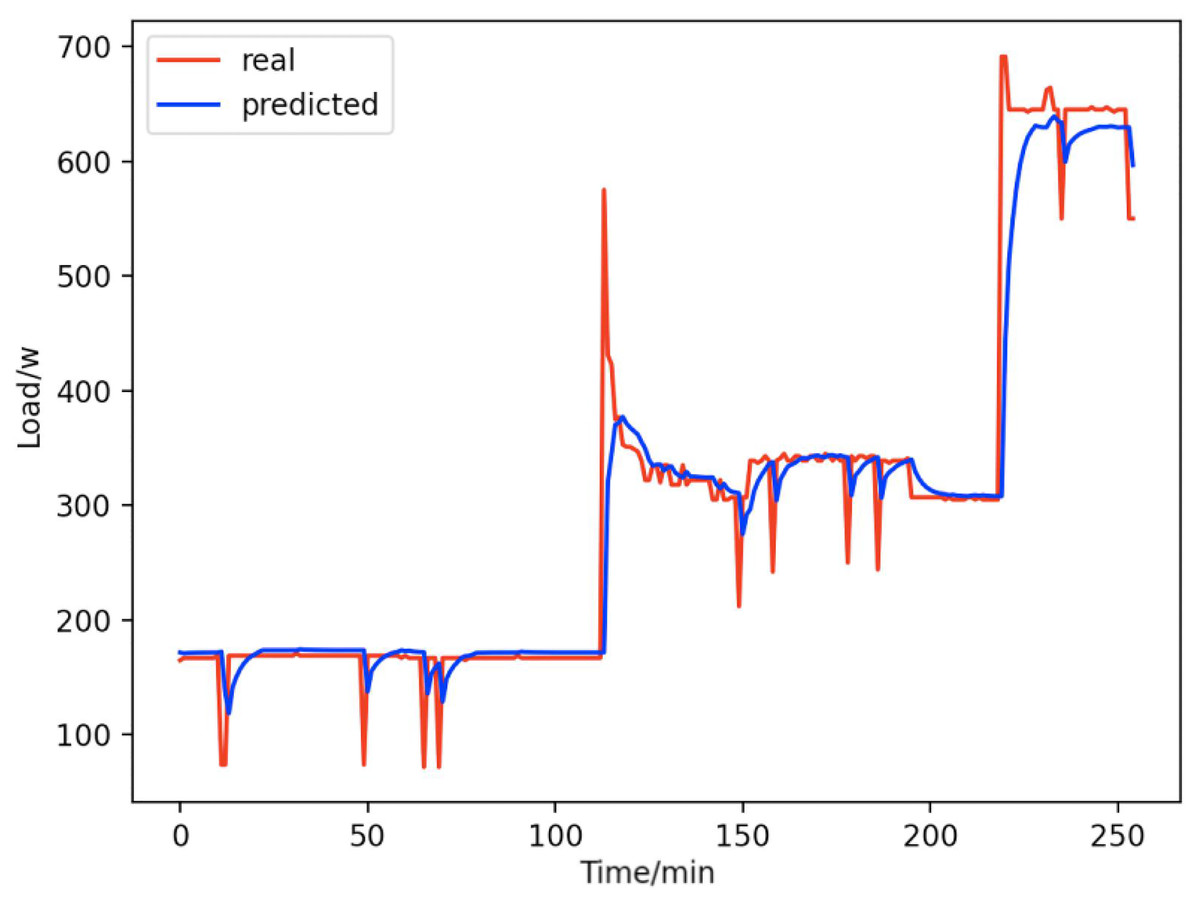
Figure 17: Total forecast.
A comparison of the total true value and predicted value of these 9 appliances (refrigerators, kettles, home theater computers, microwave ovens, radios, fans, light, active subwoofers, and computers).{kind=link}
From Figs. 8–16, we can see that the results of the true and predicted values of each appliance are very close, and Fig. 17 illustrates the total household load forecasting results. Its total true value is also very close to the predicted power with better results. These results demonstrate that the NILM-based load decomposition approach is effective and the FedDL model manages to accurately forecast the household loads.
To prove that the NILM-based integrated prediction methodology provides a better prediction effect than the traditional methodology that directly predicts the aggregated signal as a whole, we conducted a comparative experiment based on integrated prediction after load decomposition and overall direct prediction.
Figure 18 shows the comparison between the integrated prediction based on load decomposition and the overall direct prediction. It is observed that both can reflect the electricity consumption trend of household users, but the method based on integrated prediction and comprehensive prediction has a better fitting ability to the actual load curve. In contrast to the prediction results based on the overall direct prediction, in the overall equipment, different equipment has different power characteristics. In addition, there may be strong time dependence in the power signal of single equipment, and the overall direct prediction ignores the difference in power characteristics between devices, resulting in a large mistake in the overall direct prediction method. However, the load data based on load decomposition can avoid the above problems.
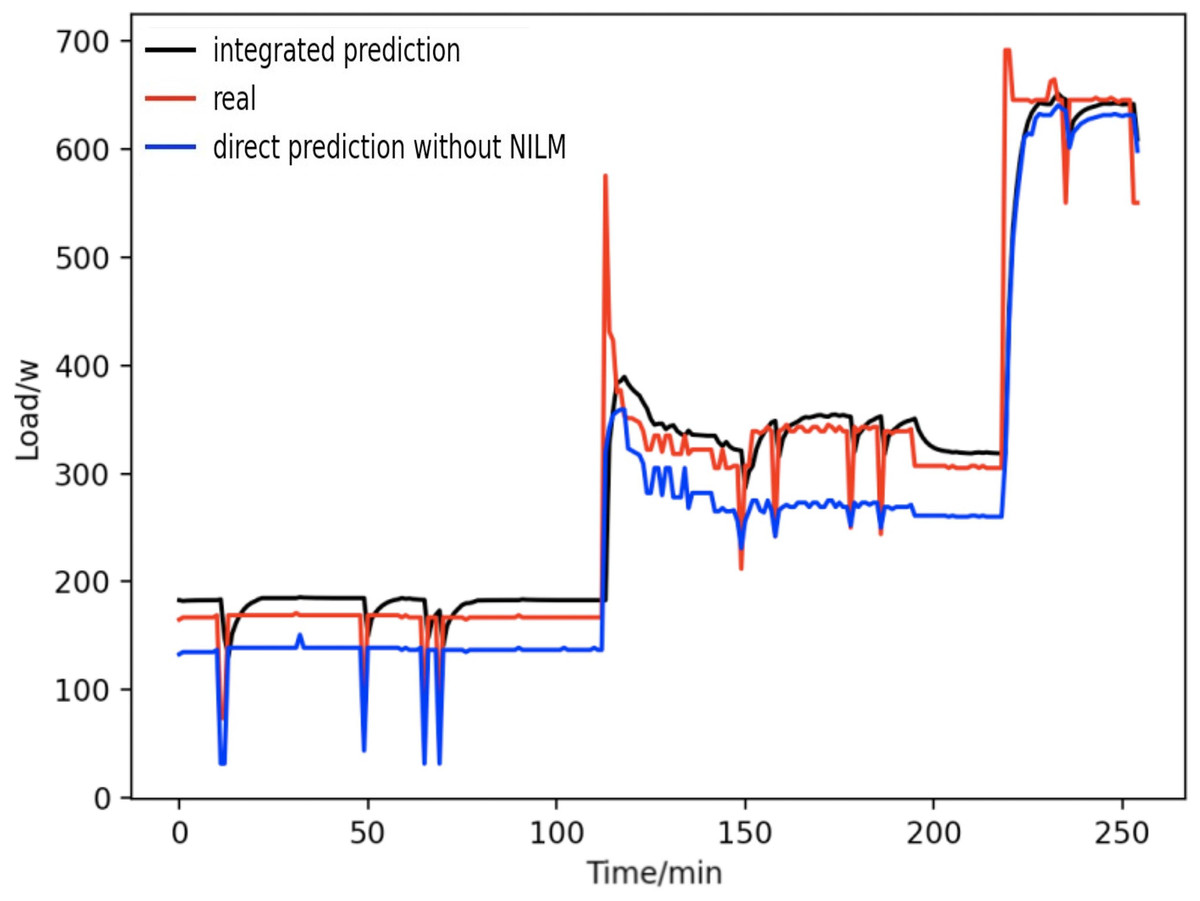
Figure 18: Comparison of overall direct forecast and individual forecast.
{kind=link}
Comparisons with other methods
To reasonably evaluate the performances of the proposed approach, comparisons with other methods have been carried out. For the different models selected in this article, related experiments are done on the basis of NILM load decomposition. The same input samples are used for training the model, and the RMSE and MAE are used as the evaluation indexes of the prediction model.
As can be seen from Table 1, the performance of the FedDL is better than that of all other alternative algorithms (besides the BiLSTM-Attention). However, the FedDL provides better privacy protection for co-modeling participants than the BiLSTM-Attention. In this prediction method, under the precondition of guaranteeing the accuracy of the prediction, the data of household users are not leaked.
| MAE | RMSE | |
|---|---|---|
| Proposed method | 0.08141 | 0.16739 |
| BiLSTM-Attention with NILM | 0.07825 | 0.15956 |
| ANN with NILM | 0.28376 | 0.34675 |
| LSTM with NILM | 0.10956 | 0.18266 |
| FFANN with NILM | 0.27869 | 0.50923 |
| ARIMA with NILM | 0.28865 | 0.55243 |
| SVM with NILM | 0.28914 | 0.52826 |
To further validate the validity of the proposed model in a more profound way, we also test it on the other four families, where the same amount of appliances and data are selected as household 1 (All the selected models are based on NILM load decomposition). Meanwhile, the first three models in Table 1 are selected for comparative experiments, which are shown in the figure below.
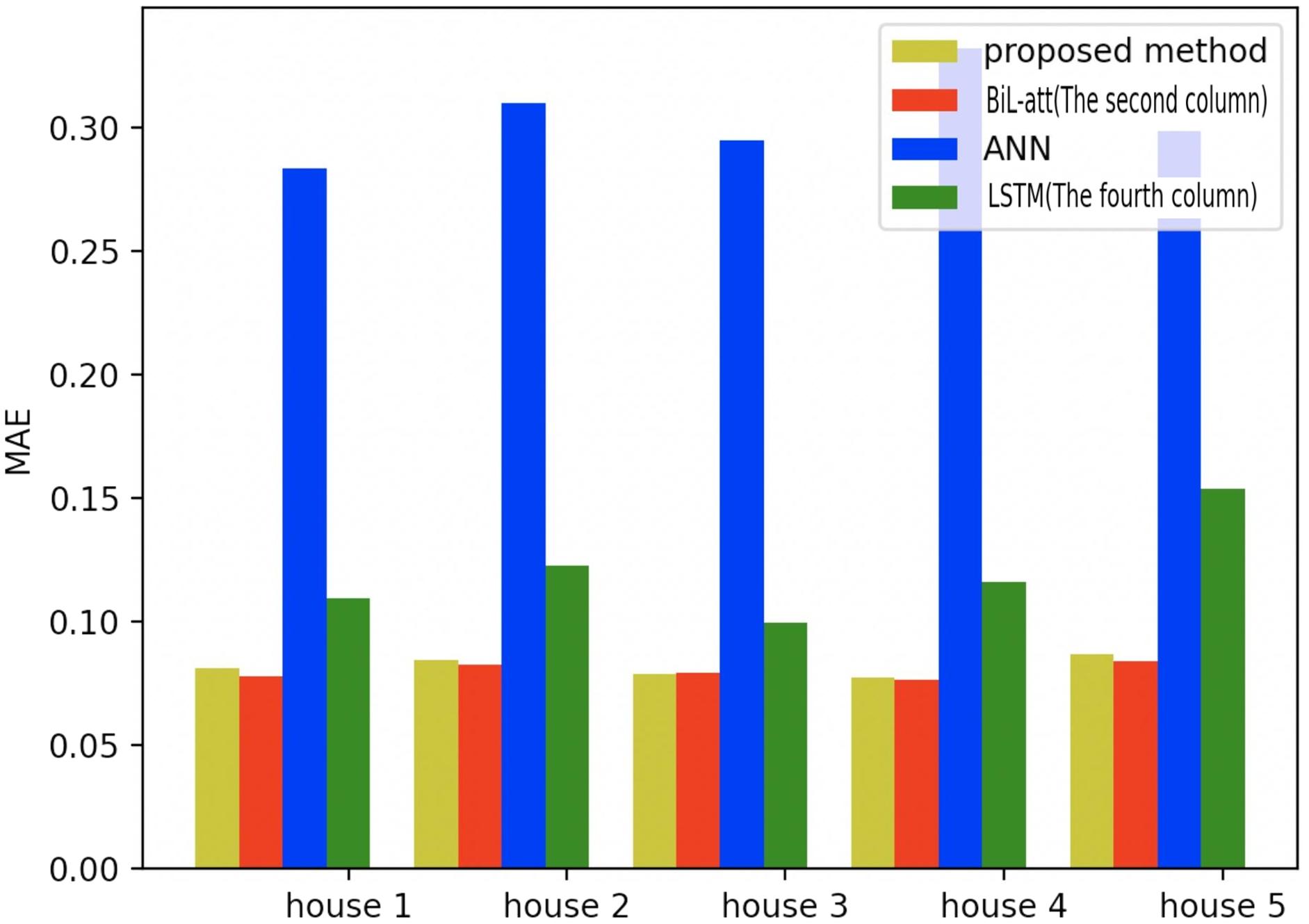
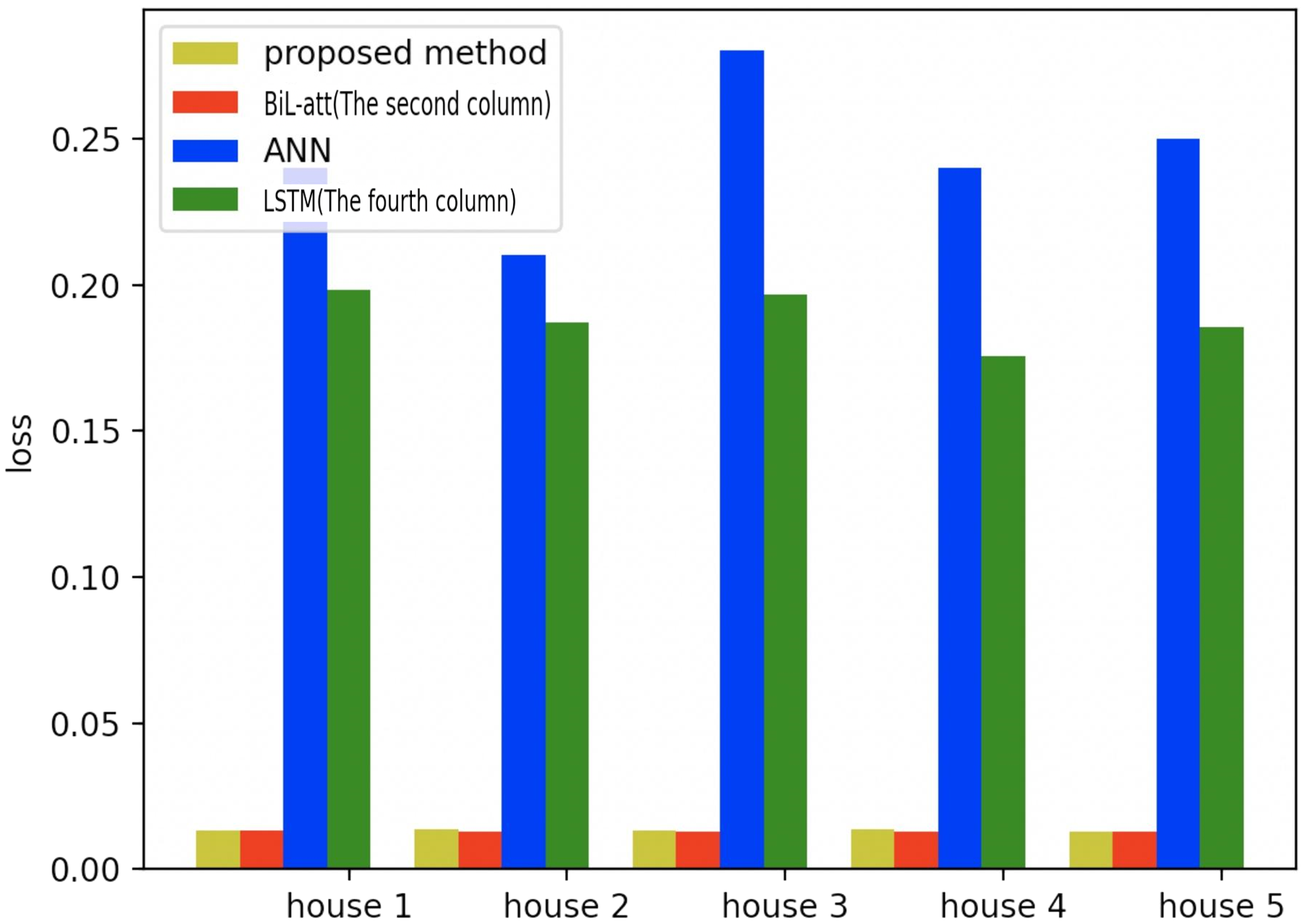
Figures 19–21 provide the comparative error analysis of the five households in the UKDALE data set under different models. As for the comparison with the BiLSTM-Attention, the performance of the proposed model is slightly inferior to that of the BiLSTM-Attention, but the FedDL can effectively protect user privacy. In terms of these two indicators, the FedDL outperforms the LSTM and ANN, which further proves the superiority of the proposed approach.
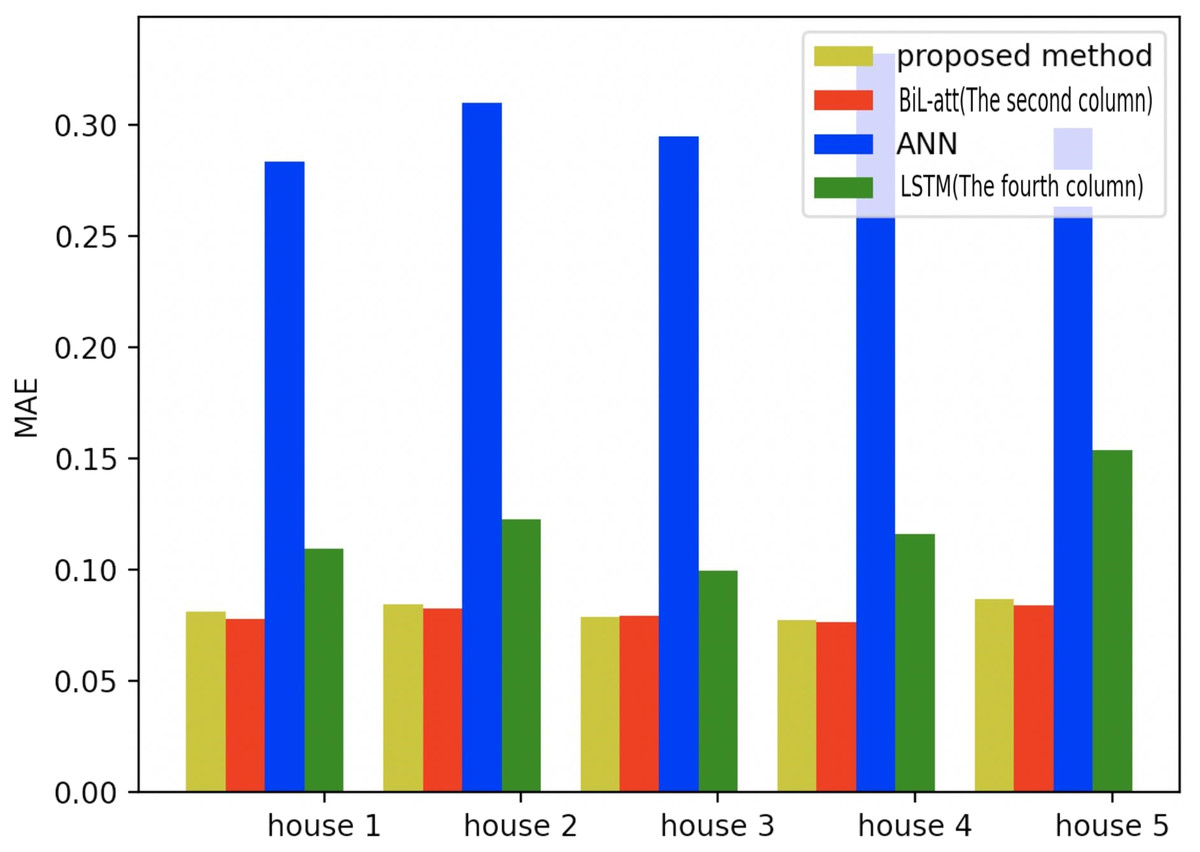
Figure 19: Comparison of five households using MAE using different methods.
{kind=link}
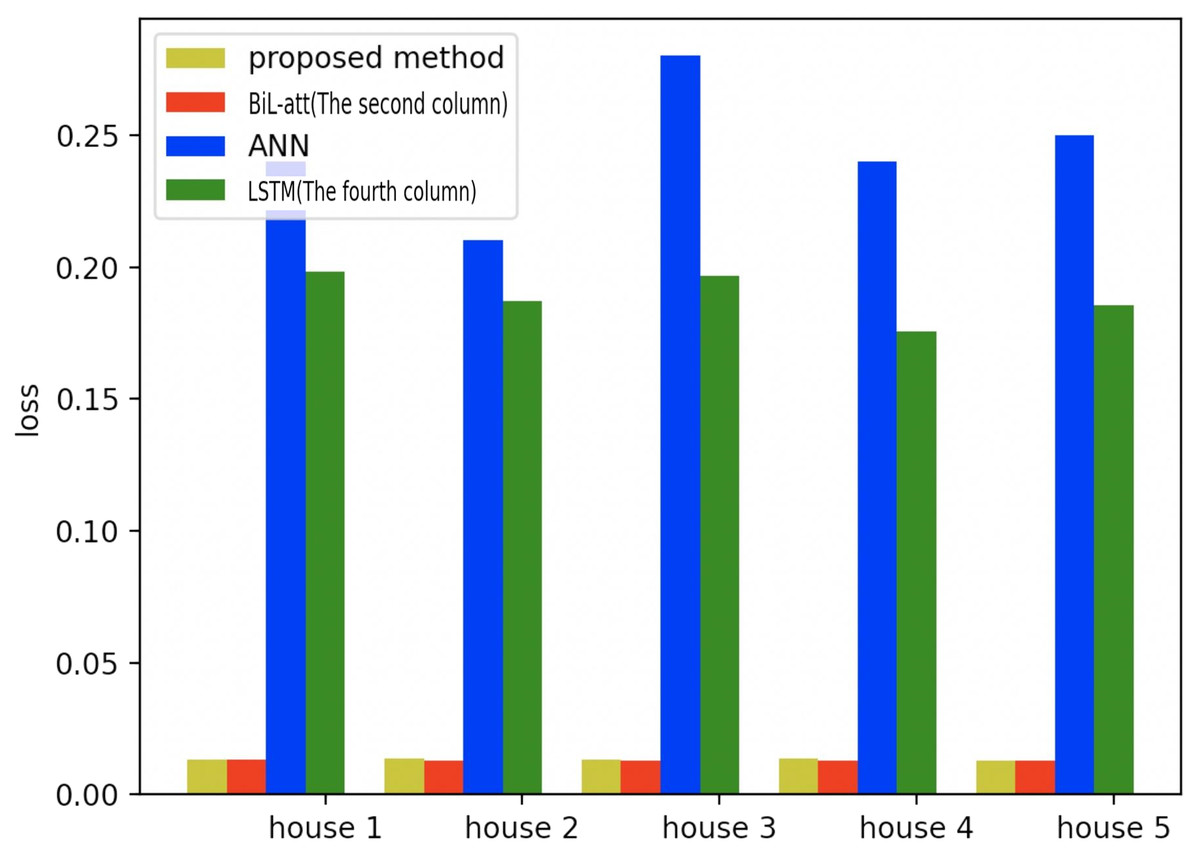
Figure 20: Comparison of five households using loss using different methods.
{kind=link}
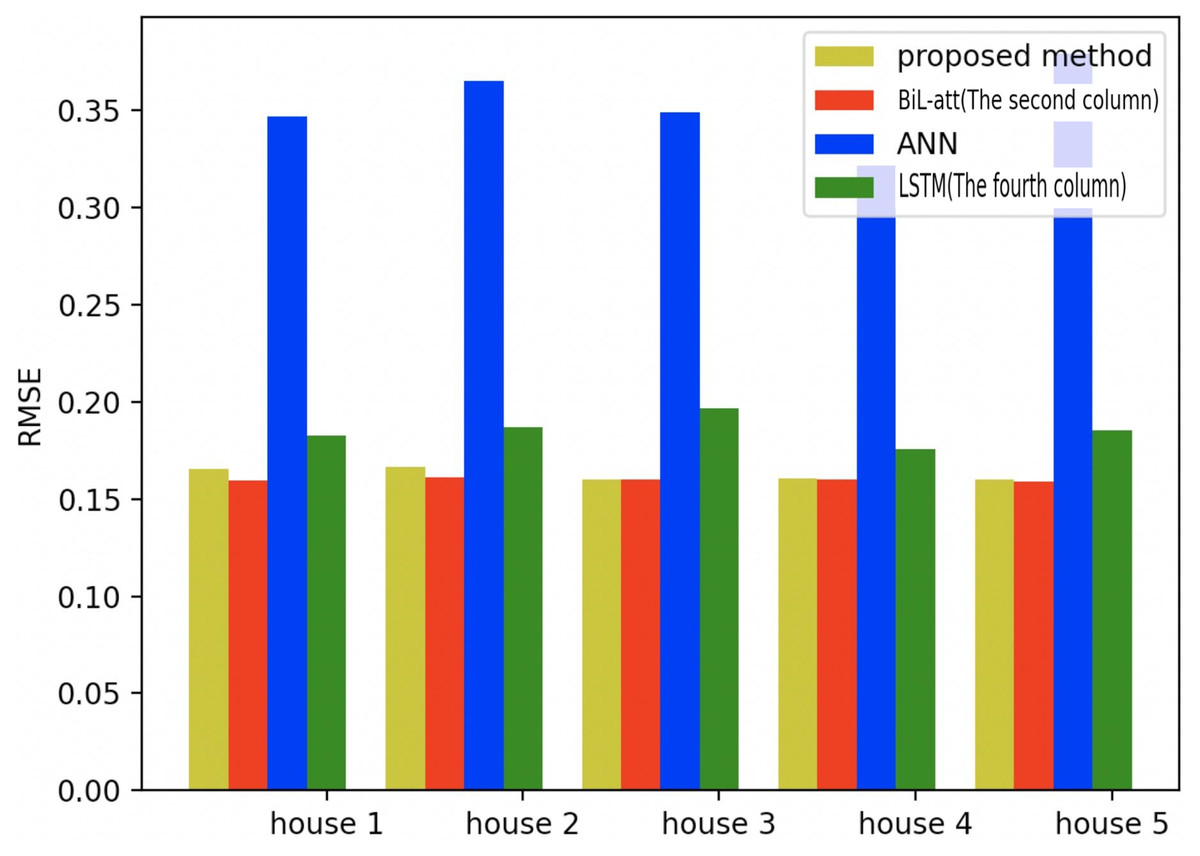
Figure 21: Comparison of five households using RMSE using different methods.
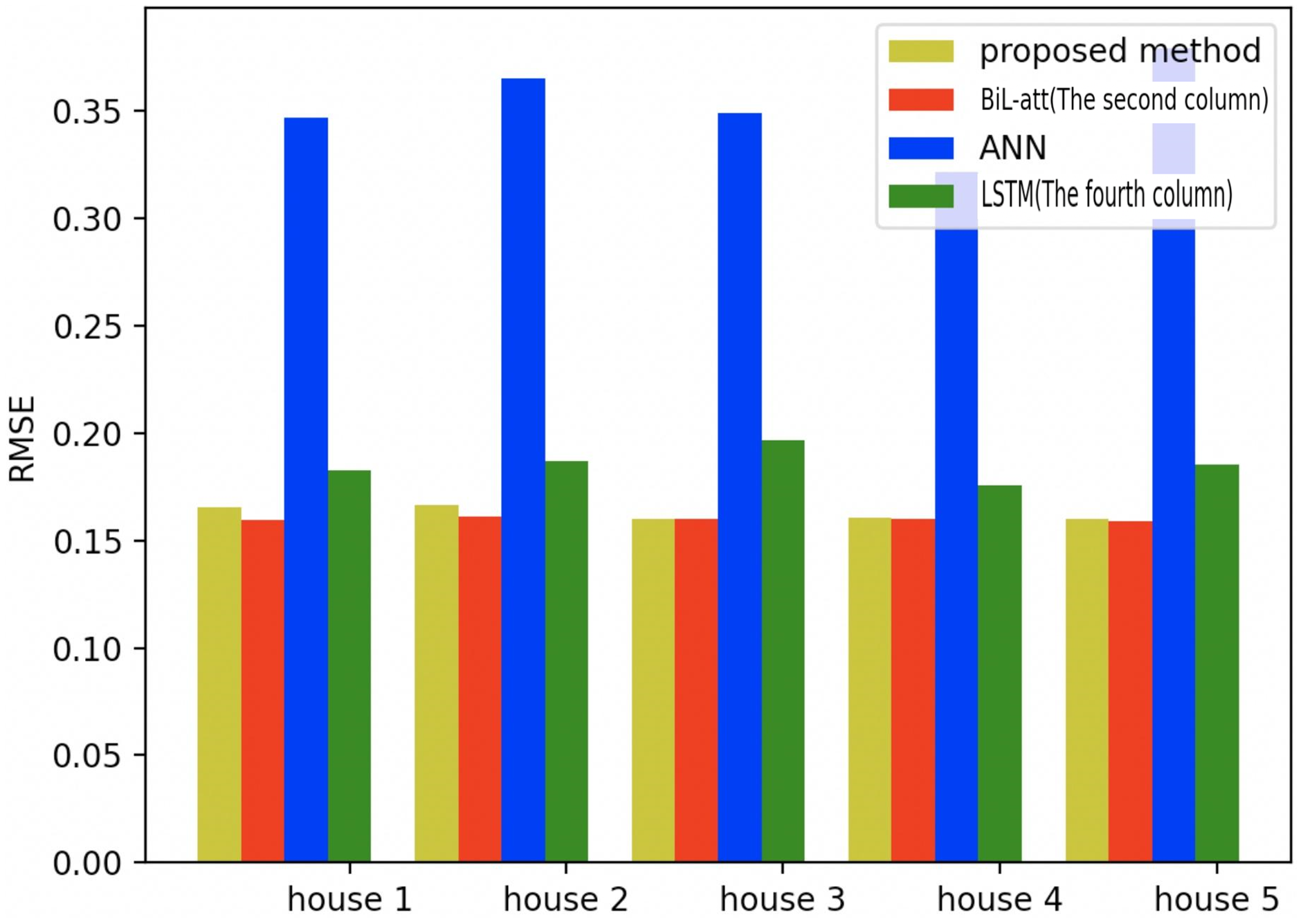{kind=link}
Robustness analysis of federated settings
To evaluate the effect of primary parameters on the robustness of the proposed FedDL prediction model, we design a different experiment with varied local Iteration period E and the client score C that performs calculations during training. Here, the number of local iteration cycles for each round of clients is set to 5, 50, and 80; the scores for the number of clients are set to 50% and 100%. The results are displayed in Fig. 22.
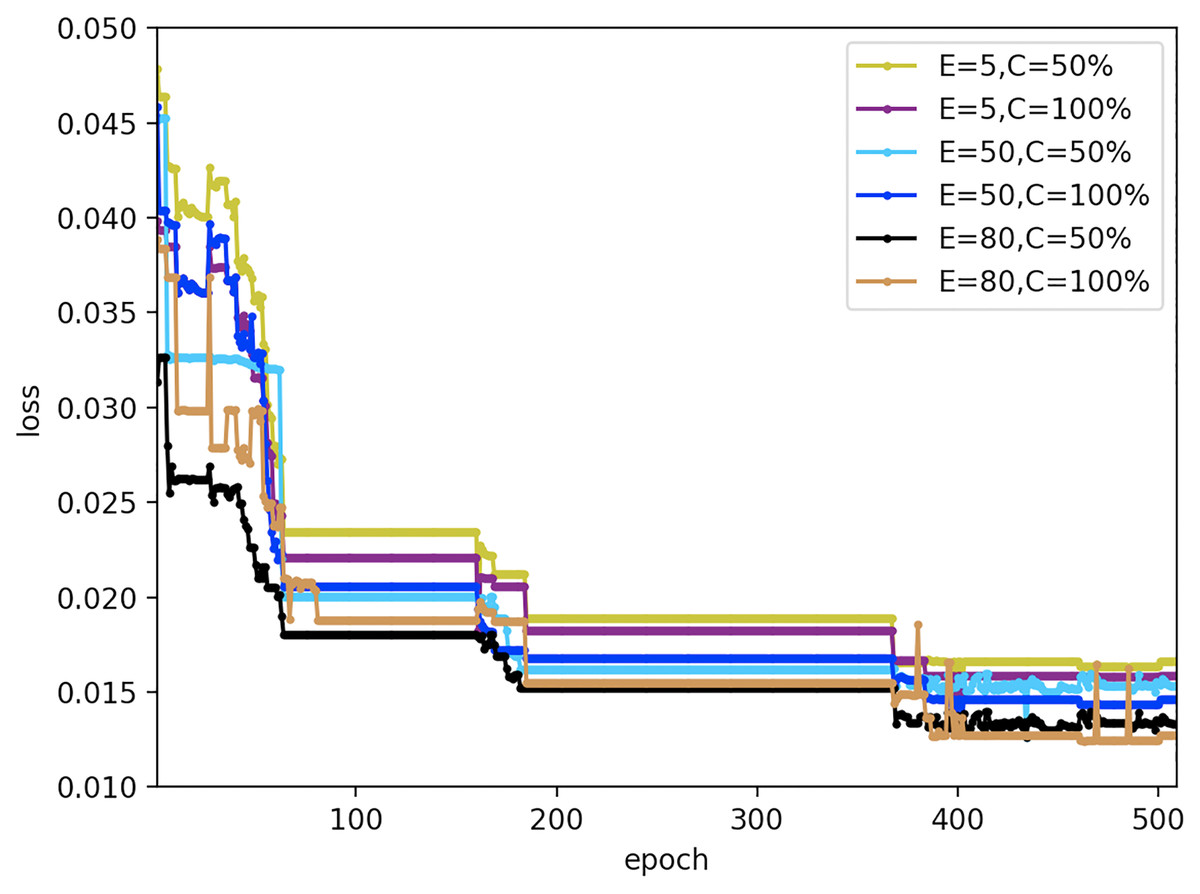
Figure 22: Loss results under different federal settings.
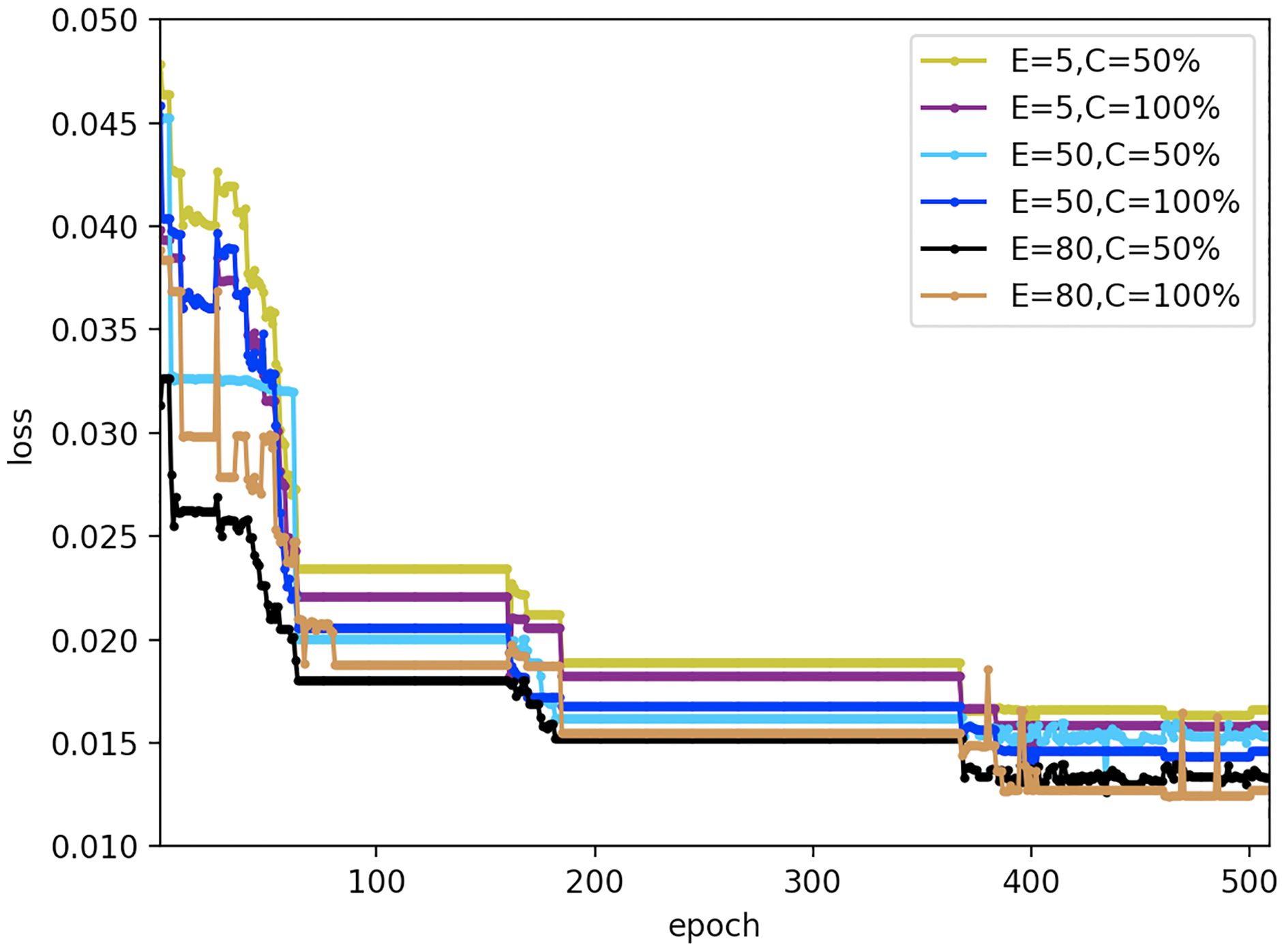{kind=link}
As can be seen from Fig. 22, different federal settings have different effects on FedDL performance. When the local client epochs are fixed, the performance of the model would not change with different local client epochs, which proved that the prediction model has good robustness to different local client epochs. And when the client ratio is fixed, the loss function value of the prediction model reduces slightly with the increase of iterations.
Conclusions
This article proposes a household load prediction method based on federated deep learning and non-intrusive load monitoring. Based on the simulation results, the following conclusions can be drawn:
(1) By combining federal learning with BiLSTM-Attention, this work develops a household load prediction approach based on non-intrusive load monitoring via federated deep learning. In this prediction method, under the precondition of guaranteeing the accuracy of the prediction, the data of household users are not leaked. It can reduce the data security risk and use the electrical power of other households to meet the needs for user privacy protection.
(2) The NILM based on the CNN-LSTM hybrid model is used to decompose the individual load of household appliances from the overall load demand, and the power of each appliance is predicted by the decomposed power of individual appliances, which avoids the strong time dependence of individual equipment. The case results demonstrate that this NILM-based integrated prediction methodology provides a better prediction effect than the traditional methodology that directly predicts the aggregated signal as a whole.
(3) This article uses the data decomposed by the CNN-LSTM hybrid deep learning model to test the proposed federated deep learning prediction model. The load forecasting result is very close to the real loads. And through comparison with other models, the superiority of the proposed method is verified. In addition, experiments in various federated learning environments are implemented to validate the robustness of this methodology.
In this article, external influence factors, such as weather factors and humidity factors, are not taken into account in the prediction process, but these factors need to be considered in more realistic scenarios. It is interesting to extend the proposed NILM algorithm for supporting the energy management of residential integrated energy systems (Sun, Deng & Li, 2020; Li et al., 2022). Besides, using automated reinforcement learning for determining the optimal hyper parameters of the used deep learning model (Li, Wang & Yang, 2022) is also deserved to be investigated. Another interesting topic is to investigate the NILM issues under cyber-attacks (Wang & Srikantha, 2021; Li, Li & Chen, 2019; Iliaee, Liu & Shi, 2021).